
基于改进YOLOv8的工厂行人检测算法
2024-12-18 00:00:00陈思涵刘勇何祥
现代电子技术 2024年24期










摘" 要: 针对工厂中行人检测算法精度不足,存在误检、漏检等问题,提出一种基于改进YOLOv8的工厂行人检测算法。首先,在YOLOv8的C2f模块中引入卷积块注意力机制模块(CBAM),以帮助主干网络聚焦于关键特征并抑制非关键特征,从而提升模型对遮挡物和小目标的检测准确度;其次,在Neck网络中将卷积神经网络Conv模块替换成CoordConv模块,以充分利用该模块的定位能力,从而解决目标检测中的定位准确性问题,提升模型对空间位置的感知能力;最后,采用Inner⁃IoU损失函数替代原始的CIoU损失函数,来提高目标检测边界框的回归精度。在自制的工厂行人图像数据集(3 600张图像)上进行了训练和测试,实验结果表明:相较于基础YOLOv8算法,改进YOLOv8算法在平均精度均值(mAP)和每秒帧率(FPS)方面分别提高了2.26%和35.6 f/s,验证了改进算法在检测性能上的提升。
关键词: 行人检测; YOLOv8算法; 深度学习; 卷积块注意力机制模块(CBAM); CoordConv; Inner⁃IoU损失函数
中图分类号: TN911.73⁃34" " " " " " " " " " " " "文献标识码: A" " " " " " " " " " " "文章编号: 1004⁃373X(2024)24⁃0160⁃07
Factory pedestrian detection algorithm based on improved YOLOv8
CHEN Sihan, LIU Yong, HE Xiang
(1. School of Automation and Information Engineering, Sichuan University of Science and Engineering, Yibin 644000, China;
2. Artificial Intelligence Key Laboratory of Sichuan Province, Yibin 644000, China)
Abstract: A factory pedestrian detection algorithm based on improved YOLOv8 is proposed to address the issues of insufficient accuracy, 1 positives, and missed detections in pedestrian detection algorithms in factories. The convolutional block attention mechanism (CBAM) module was introduced into the C2f module of YOLOv8 to help the backbone network focus on key features and suppress non key features, thereby improving the model′s detection accuracy for occlusions and small targets. The convolutional neural network Conv module is replaced by the CoordConv module in the Neck network to make full use of the positioning ability of the module, so as to solving the positioning accuracy in object detection and improve the model's perception of spatial position. The Inner IoU loss function is used to replace the original CIoU loss function to improve the regression accuracy of object detection bounding boxes. A self⁃made pedestrian image dataset in a factory (3 600 images) are trained and tested. The experimental results show that in comparison with the basic YOLOv8 algorithm, the improved YOLOv8 algorithm can improve the average accuracy of the average mAP (mean average precision) and the frame rate FPS (frame rate per second) by 2.26% and 35.6 f/s, respectively, which can verify the improvement of the detection performance of the improved algorithm.
Keywords: pedestrian detection; YOLOv8 algorithm; deep learning; convolutional block attention mechanism module; CoordConv; Inner⁃IoU loss function
0" 引" 言
近年来,目标检测作为深度学习中的一个重要应用领域,在各行各业中都被广泛应用。行人检测作为目标检测领域的一项基本任务,在安防监控、智能交通、人机交互等方面有着广泛的应用[1⁃3]。随着工业自动化和智能化程度的不断提高,工厂中自动化设备逐渐增多,然而设备按照既定指令进行工作时,对工厂行人存在安全隐患。对工厂行人的及时检测能保证行人生命安全,进而保障设备正常运作。
目标检测技术主要分为传统方法和基于深度学习的方法[4]。传统行人检测算法通过提取图像不同区域的特征并使用分类算法进行分类来实现目标检测。但传统方法依赖于人工进行特征提取,当背景变化时难以使用统一的检测模型,导致检测效果较差。近年来,基于深度学习的目标检测算法[5]变得流行,主要分为两类:两阶段目标检测算法和单阶段目标检测算法。在行人检测方面,针对被遮挡问题,文献[6]基于Faster RCNN提出一种IterDet迭代方案,同时利用递归金字塔结构来提升模型特征提取能力。文献[7]在Cascade RCNN的基础上对网络结构进行了改进,使得算法能够更好地利用深层和浅层特征信息。对于密集场景,文献[8]提出一种改进YOLOv5的红外行人检测算法,利用RF⁃gnConv模块来增强模型对各种复杂场景的行人检测能力。文献[9]则提出一种改进的YOLOv7拥挤行人检测算法,引入了BiFormer视觉变换器和改进的高效层聚合网络模块。两阶段检测算法通常具有更高的检测精度,但速度较慢;而单阶段检测算法速度较快,适用于对实时性要求较高的行人检测场景。
2023年,Ultralytics团队提出YOLOv8算法,该算法在实时性和检测精度上性能良好,适用于对工厂行人检测进行针对性改进。因此,本文以YOLOv8算法为基础,通过优化措施提升其检测精度。具体优化包括以下三个方面:首先,在YOLOv8的C2f模块中引入卷积块注意力机制模块(CBAM),以帮助主干网络聚焦于关键特征并抑制非关键特征,从而提升模型对遮挡物和小目标的检测准确度;其次,在Neck网络中将卷积神经网络Conv替换为CoordConv模块,充分利用其定位能力提高目标检测的定位准确性,提升模型对空间位置的感知能力;最后,采用Inner⁃IoU损失函数[10]替代原始的CIoU损失函数,以提高目标检测边界框的回归精度。
1" YOLOv8算法结构
YOLO算法是一种单阶段目标检测算法,旨在实现实时对象检测。在YOLO系列中,YOLOv1相较于两阶段目标检测算法具有更快的检测速度。YOLOv2采用Draknet19网络架构,从预测准确性、速度和对象识别能力三个方面进行了改进。YOLOv3引入了特征金字塔(FPN)结构和空间池化金字塔(SPP)模块,提高了语义信息的获取效率。YOLOv4[11]采用Mosaic数据增强方法,提升了模型对复杂场景和遮挡目标的识别能力。YOLOv5采用轻量型的模型结构,易于部署。YOLOv6[12]选用EfficientRep作为骨干网络,并构建了Rep⁃PAN结构以精确定位。YOLOv7[13]引入扩展高效层聚合网络(E⁃ELAN)和重新参数化卷积,增强了网络的学习能力。现今,YOLO算法已经发展到YOLOv8版本。相较于之前的版本,YOLOv8在检测精度、计算量和参数量等方面均有提升。
YOLOv8的网络结构如图1所示。
YOLOv8由Backbone骨干网络、Neck颈部网络和Head输出端组成。Backbone骨干网络由Conv、C2f和SPPF三个模块组成。C2f模块可以增强卷积神经网络的特征融合能力,提高推理速度。在尾部采用SPPF模块增加感受野以得到更多特征信息。Neck颈部网络将C2f模块与Backbone三个阶段输出的不同尺寸的特征图进行融合,使得局部特征与深层特征融合。Head部分采用解耦头结构,将分类和定位预测分开,以化解分类和定位关注信息侧重点不同存在的冲突。在候选框上,YOLOv8采用Ancher⁃Free替换了以前的Ancher⁃Base,采用Ancher⁃Free框架可以提高长宽不规则目标的检测精度。YOLOv8的分类损失函数为VFL Loss,回归损失函数为DFT Loss和CIoU Loss。在样本匹配方面,YOLOv8由以前的IoU匹配或边长比例分配转换为Task⁃Aligned Assigner匹配方式。
2" YOLOv8算法改进
2.1" CBAM
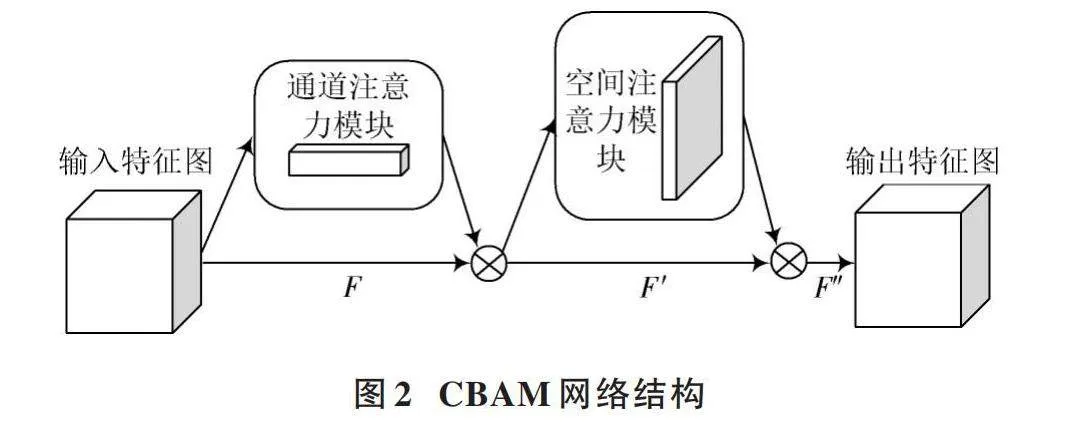
由于工厂中环境复杂,为了提高模型对行人的检测能力,在YOLOv8的C2f模块中引入CBAM。卷积块注意力机制模块(CBAM)是一种用于前馈卷积神经网络的注意力模块,它将跨通道信息和空间信息结合在一起来提取信息特征,有助于模型关注重要特征并抑制不重要的特征,提高模型的检测能力。CBAM可以添加到模型的多个位置,且不会带来过多的计算量和参数量。CBAM网络结构如图2所示。
由于CBAM能让模型自适应地学习通道重要程度和空间位置重要程度,帮助模型关注重要特征并抑制不重要的特征,所以,本文将CBAM引入C2f模块的Bottleneck中。Bottleneck本质由多个卷积核组成,将CBAM添加到Bottleneck模块内部的卷积操作之后,利用Bottleneck模块中的特征图对不同尺度的特征进行注意力加权,从而提高网络对多尺度信息的感知能力。
在卷积操作之后添加CBAM可以使得通道注意力机制考虑到更丰富的特征信息,进一步优化特征图的表征能力。
2.2" CoordConv坐标卷积神经网络
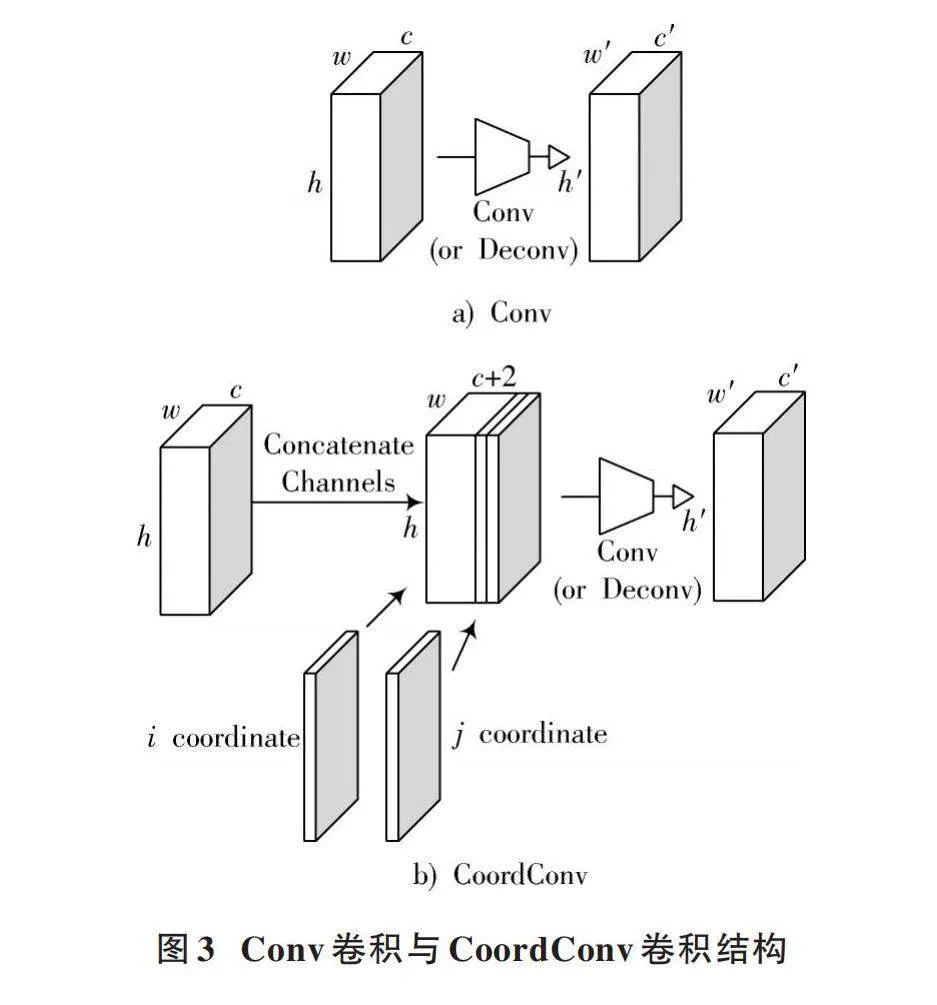
YOLOv8模型中的卷积神经网络Conv使用卷积核进行运算时,仅能感知到局部信息,无法感知到位置信息,而CoordConv卷积神经网络通过在输入特征图中新增对应的通道来感知位置信息,提高模型的目标检测能力。
由于工厂环境的复杂性,常常会出现物品或器件遮挡行人,以及行人之间相互重叠等问题,这些情况会降低检测效果。因此,在检测过程中,对目标位置信息的感知变得尤为重要。本文将特征融合部分的Conv替换成CoordConv,以提高空间感知能力,与图3a)卷积神经网络Conv相比,图3b)CoordConv增加了额外的两个通道,分别是i坐标通道和j坐标通道,将这两个通道与输入特征图沿通道维度进行拼接,再进行卷积操作。在这个过程中,两个坐标经历了线性变换,并在[-1,1]区间内进行了归一化处理。
2.3" Inner⁃IoU损失函数
IoU是预测框与真实框的交并比,该指标用于评估目标物体检测的准确性,IoU数值越大,代表预测框与真实框重合程度越高,模型预测越准确。YOLOv8采用CIoU[14]作为边界框回归损失函数,CIoU的损失函数计算公式如下:
[LCIoU=1-IoU+ρ2(b,bgt)c2+αv] (1)
式中:[b]和[bgt]分别为预测框和真实框的中心点;[ρ2]表示两个中心点之间的欧氏距离;[c]为覆盖预测框和真实框的最小包围框的对角线长度;[α]是正权衡参数,用来平衡长宽比的影响;[v]用来衡量预测框和真实框长宽比的一致性,若两框长宽比一致,则[v=0]。
CIoU引入了中心点距离和长宽比的相似性,可以有效加速模型收敛并提高检测性能,但基于IoU的边框回归仍在通过加入新的损失项来加速收敛,并未考虑IoU损失本身的合理性。因此本文采用Inner⁃IoU来代替CIoU。Inner⁃IoU是基于辅助边框的IoU损失函数,引入尺度因子ratio来控制辅助边界框的尺寸,进而计算损失,加速模型收敛。Inner⁃IoU的定义如下:
[bgtl=xgtc-wgt·ratio2," bgtr=xgtc+wgt·ratio2] " " (2)
[bgtt=ygtc-hgt·ratio2," bgtb=ygtc+hgt·ratio2] (3)
[bl=xc-w·ratio2," br=xc+w·ratio2] (4)
[bt=yc-h·ratio2," bb=yc+h·ratio2] (5)
[inter=(min(bgtr,br)-max(bgtl,bl))·" " " " " " "(min(bgtb,bb)-max(bgtt,bt))] (6)
[union=(wgt·hgt)·ratio2+(w·h)·ratio2-inter] (7)
[Inner⁃IoU=interunion] (8)
式中:[xgtc]和[ygtc]为真实框的内部中心点;[xc]和[yc]为预测框的内部中心点;[bgtl]、[bgtr]、[bgtt]和[bgtb]为真实框的左、右、上、下边界,由真实框中心点、宽高和尺度因子ratio计算而得;[bl]、[br]、[bt]和[bb]为预测框的左、右、上、下边界,由预测框中心点、宽高和尺度因子ratio计算而得;[inter]表示真实框与预测框的交集部分;[union]表示真实框与预测框的并集部分;Inner⁃IoU则由[inter]与[union]比值计算而得。
3" 实验结果
3.1" 数据集
通过对工厂的场地环境进行实地考察调研,借助智能行车上的监控摄像头收集场地内图像数据,共采集有效工厂图像720张。由于数据集数量较少,为增强模型的鲁棒性和避免训练模型出现过拟合现象,对原始数据集进行水平翻转、旋转、亮度变换、增加噪声等四种数据增强,将数据集扩充至3 600张,并通过标注工具LabelImg对图像中的行人进行标注,最后将数据集按8∶1∶1的比例进行随机划分,得到训练集、验证集和测试集,分别为2 880、360、360张图像。
3.2" 实验环境
本次实验基于Windows 11操作系统,使用开源深度学习框架PyTorch作为网络架构,具体的实验平台参数见表1,训练模型参数见表2。
3.3" 评价指标
本文采用的评价指标有精确率(Precision)、召回率(Recall)、平均精度均值(mAP)、FPS。FPS指每秒帧数,更高的FPS意味着模型能更快地对输入图像进行处理。精确率和召回率是评价分类任务的常见指标,mAP综合考虑了精确率和召回率,用来衡量模型的性能。精确率是指在预测为正类别的样本中,真正的正类别所占的比例,定义如下:
[Precision=TPTP+FP] (9)
召回率是指模型正确预测的样本中,正类别的比例,定义如下:
[Recall=TPTP+FN] (10)
式中:TP指模型正确预测为正类别的样本数量;FP指模型错误预测为正类别的数量;FN指模型错误预测为负类别的概率。
mAP是n个类别的平均精度均值,由各个类别的精确率⁃召回率曲线面积构成。mAP根据阈值不同又可分为mAP50和mAP50~95,mAP50是在IoU阈值为0.5时的平均精度均值,mAP50~95是在不同IoU阈值(从0.5~0.95,步长0.05)上的平均精度均值,mAP定义如下:
[mAP=1ni=1n01Precision(Recall)d(Recall)] (11)
3.4" 结果分析
3.4.1" 改进前后的算法对比分析
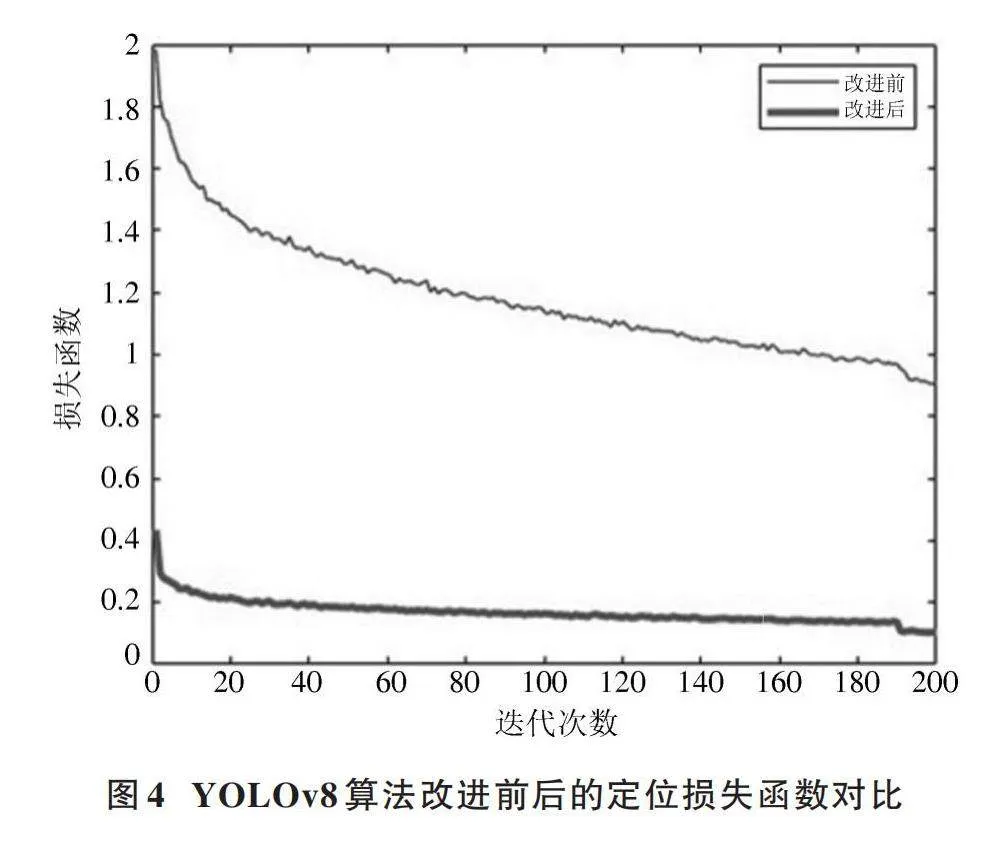
图4所示为原始YOLOv8算法与改进后YOLOv8算法的定位损失函数对比。改进算法在30轮次时已经趋于收敛,并且损失函数的收敛值明显减小,这表明改进后的网络模型在定位上效果更好且收敛速度更快。
图5为改进后YOLOv8算法的训练结果,左侧三列曲线图为训练集和验证集的损失函数,分别是定位损失(box_loss)、分类损失(cls_loss)和置信度损失(obj_loss),右侧两列曲线图分别是精确率(Precision)、召回率(Recall)和平均精度均值(mAP50、mAP50~95)。图中显示,模型的Precision和Recall在经过100轮训练后趋于稳定,而mAP的数值最终稳定在96%,表明改进算法具有较好的检测性能。
表3展示了消融实验结果,旨在逐一比较不同改进算法,以观察其性能特征,并验证改进算法的检测效果。表中包含4组算法模型,第1组为原始YOLOv8模型,第2组~第4组为添加不同模块的网络模型。基础YOLOv8算法的mAP为94.10%,FPS为113.6 f/s。第2组引入CBAM注意力机制,提升主干网络的特征提取能力,使得mAP增加了1.4%,但由于添加了CBAM模型,模型计算量增加,FPS下降了5.4 f/s。第3组在CBAM的基础上加入了CoordConv,引入坐标卷积增强了模型对空间位置的感知能力,相较原模型,mAP提高了2%,FPS增加了10.1 f/s。第4组在第3组的基础上将CIoU损失函数替换为Inner⁃IoU,其引入尺度因子ratio来控制辅助边界框的尺寸,加速模型的收敛速度,mAP相较原模型提高了2.26%,FPS提高了35.6 f/s。
消融实验结果表明,相较于基础YOLOv8算法,改进后的算法在Precision、Recall、mAP和FPS方面分别提高了1.68%、3.72%、2.26%和35.6 f/s,验证了改进算法检测性能的提升。
3.4.2" 不同检测算法的对比分析
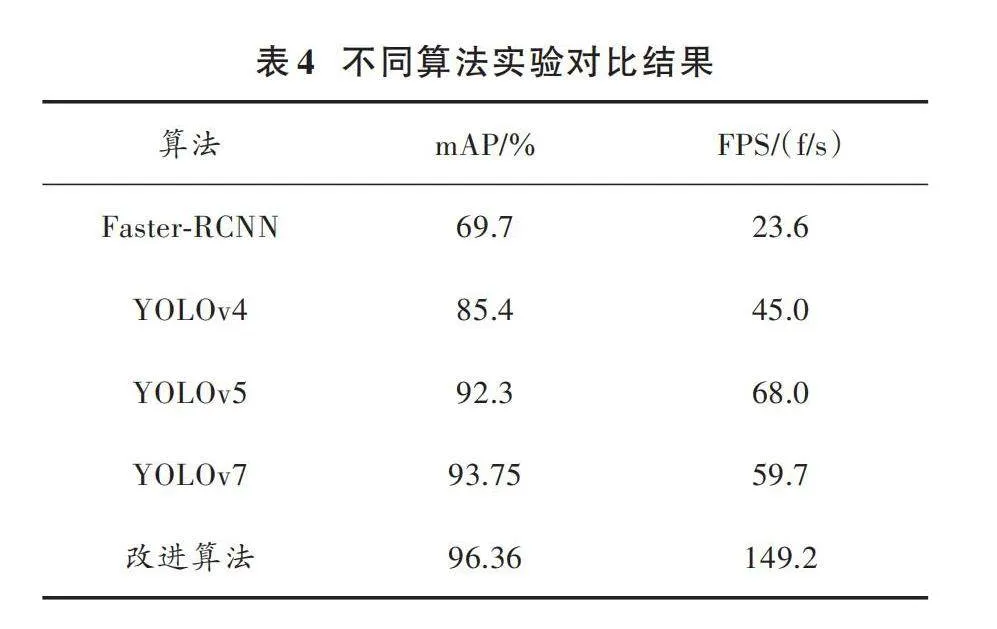
为验证改进算法的有效性,将其与现有目标检测算法Faster⁃RCNN、YOLOv4、YOLOv5、YOLOv7进行对比实验。实验采用本文构建的数据集,并以mAP和FPS为评价指标,实验对比结果如表4所示。
从表4可以看出:YOLOv5算法作为近年来泛化能力较强的目标检测算法,mAP和FPS较为均衡;而YOLOv7由于引入了更深的网络结构,在检测速度上不如YOLOv5;与这些目标检测算法相比,改进后的YOLOv8算法在速度和精度方面均有显著提升。
3.4.3" 检测效果对比
本文采用部分测试集图像,在YOLOv8、YOLOv5、YOLOv7和改进YOLOv8算法四个模型上进行测试,检测结果如图6所示。测试图像涵盖了工厂不同场景下的行人活动情况。在场景1中,行人数量较少,四种模型均成功检测出行人。在场景2中,YOLOv8算法出现误检现象,对于被遮挡行人情况误将其识别为两个目标。在场景3中,行人目标较为密集且存在被遮挡行人及小目标行人,YOLOv5算法对于左侧密集行人存在误检。场景4为工厂器件复杂场景,YOLOv5算法误将背景设备识别为行人,YOLOv7虽成功检测出行人,但其行人置信度较低。本文改进YOLOv8算法在检测中表现较为理想,成功识别了所有行人目标,并且未出现误检和漏检情况。
4" 结" 论
针对工厂中的行人检测问题,本文对比了近年来目标检测算法在精度、特征提取和检测速度方面的表现,鉴于现有算法存在的问题,以YOLOv8算法为基础,提出了一种改进YOLOv8的工厂行人检测算法。具体改进包括:首先,在YOLOv8的C2f模块中引入卷积块注意力机制模块,以提高模型对遮挡物和小目标的检测准确度;其次,在Neck网络中将卷积神经网络Conv模块替换为CoordConv模块,以提升模型对空间位置的感知能力;最后,采用Inner⁃IoU损失函数替代原始的CIoU损失函数,以提高目标检测边界框的回归精度。实验结果表明,改进后的算法模型平均精度均值达到了96.36%,检测速度达到了149.2 f/s。验证了该模型能够快速、准确地检测出工厂行人目标。
未来的研究重点是将模型部署在资源受限的检测设备中,以轻量化为目标,对模型进行完善。
注:本文通讯作者为刘勇。
参考文献
[1] 姜小强,陈骋,朱明亮.基于红外传感的视频监控行人检测方法[J].煤炭技术,2022,41(10):223⁃225.
[2] 王清芳,胡传平,李静.面向交通场景的轻量级行人检测算法[J].郑州大学学报(理学版),2024,56(4):48⁃55.
[3] 李林,王家华,周晨阳,等.目标检测数据集研究综述[J].数据与计算发展前沿(中英文),2024,6(2):177⁃193.
[4] ZOU Z, SHI Z, GUO Y, et al. Object detection in 20years: a survey [J]. Proceedings of the IEEE, 2019, 111(3): 257⁃276.
[5] 郭庆梅,刘宁波,王中训,等.基于深度学习的目标检测算法综述[J].探测与控制学报,2023,45(6):10⁃20.
[6] 贺宇哲,徐光美,何宁,等.迭代Faster R⁃CNN的密集行人检测[J].计算机工程与应用,2023,59(21):214⁃221.
[7] 刘艳萍,刘甜.改进的Cascade RCNN行人检测算法研究[J].计算机工程与应用,2022,58(4):229⁃236.
[8] 高正中,于明沆,孟晗,等.基于改进YOLOv5算法的红外图像行人目标检测[J].中国科技论文,2024,19(2):209⁃214.
[9] 徐芳芯,樊嵘,马小陆.面向拥挤行人检测的改进YOLOv7算法[J].计算机工程,2024,50(3):250⁃258.
[10] ZHANG H, XU C, ZHANG S. Inner⁃IoU: more effective intersection over union loss with auxiliary bounding box [EB/OL]. [2023⁃11⁃07]. https://arxiv.org/abs/2311.02877?context=cs.
[11] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [2023⁃07⁃18]. https://arxiv.org/abs/2004.10934.
[12] LI C Y, LU L L, JIANG H L, et al. YOLOv6: a single⁃stage object detection framework for industrial applications [EB/OL]. [2023⁃05⁃12]. https://arxiv.org/abs/2209.02976.
[13] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag⁃of⁃freebies sets new state⁃of⁃the⁃art for real⁃time object detectors [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, BC, Canada: IEEE, 2023: 7464⁃7475.
[14] ZHENG Z, WANG P, LIU W, et al. Distance⁃IoU loss: faster and better learning for bounding box regression [EB/OL]. [2023⁃09⁃17]. https://arxiv.org/abs/1911.08287.
作者简介:陈思涵(2000—),女,四川广安人,硕士研究生,研究方向为深度学习、目标检测。
刘" 勇(1987—),男,四川南充人,博士研究生,讲师,研究方向为信号与信息处理。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
意林(2021年5期)2021-04-18 12:21:17
电子制作(2019年11期)2019-07-04 00:34:38
扬子江(2019年1期)2019-03-08 02:52:34
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
