
Chat GPT在散文翻译中的适用性
2024-12-18 00:00:00杨睿颖
今古文创 2024年47期
【摘要】随着人工智能技术的发展,大语言模型应运而生,标志着翻译模式的变革。Chat GPT作为代表性的大语言模型之一,其翻译性能研究具有重要意义。为探究Chat GPT在散文翻译中的适用性,以老舍的《想北平》为原文本,张培基译本为人译目的语语料,Chat GPT译本为机译目的语语料,对比分析两个译本,从而分析Chat GPT在散文翻译中的表现。研究结果表明,Chat GPT在散文翻译中既有优势也有劣势。优势包括三方面:快捷的背景资料查询、准确的多义词翻译、贴切的原文风格再现;劣势包括四方面:不准确的文化负载词翻译、不完整的内容补充、不清晰的逻辑关系分析以及欠缺情感表达。
【关键词】Chat GPT;散文翻译;适用性;《想北平》
【中图分类号】H315 【文献标识码】A 【文章编号】2096-8264(2024)47-0095-04
【DOI】10.20024/j.cnki.CN42-1911/I.2024.47.025
随着全球化的不断发展,跨语言交流变得越来越频繁,各类大语言模型应运而生。Chat GPT是美国人工智能研究实验室Open AI推出的一款大语言模型,因为其敢于质疑用户提出的问题、综合理解用户的多轮对话、主动承认自己回答错误等方面的优势广受欢迎,同时也将机器翻译带入了全新模式[1]。在参照国内Chat GPT研究现状的基础上,本研究聚焦于散文翻译领域,以老舍的《想北平》为原文本,对比分析张培基译本和Chat GPT译本,总结Chat GPT在散文翻译领域的优势和劣势,为深入了解当前Chat GPT在散文翻译中的表现提供参考,进而推动翻译技术的进步。
一、研究概述
以“Chat GPT翻译”为主题词,统计中国知网的发文情况,截至2024年,知网共收录146篇相关文章,其中核心期刊文章共30篇,且都是2023年发表的,硕士论文共2篇。从发文年限和高质量论文占比来看,国内对Chat GPT翻译方面的研究起步较晚,研究层次不高。现有研究主要集中于Chat GPT发展概述,各类机器翻译性能比较以及Chat GPT翻译在各个领域发挥的作用。
Chat GPT自2018年问世以来,已经历经了6年的发展。不少文章梳理了Chat GPT各个版本发布的年份、模型参数量变化以及功能更新。其中有代表性的研究有张超的《Chat GPT与知识生产和复用:赋能、挑战与治理》和郑世林的《Chat GPT新一代人工智能技术发展的经济和社会影响》[2][3]。此类文章对Chat GPT进行了较为全面的介绍,但只是稍有提及Chat GPT的翻译功能,并没有深入探究其具体表现。Chat GPT翻译功能虽强大但也不是完全可靠。对Chat GPT的翻译质量进行严格的测评尤为重要。此类研究集中在以下两方面:1.各类大语言模型之间的性能比较。赵雪等人依据ROUGE、MAUVE等测评指标,测评了16个大语言模型在5个典型语言处理任务上的表现,总体而言Chat GPT的翻译性能最优[4]。2.Chat GPT与传统机器翻译的比较。王天恩的《Chat GPT的特性、教育意义及其问题应对》指出Chat GPT在多个方面的性能都超过了传统的机器翻译,翻译的准确度大大提升[5]。此类研究以真实的数据展现了Chat GPT的翻译质量,证明了Chat GPT在翻译领域有着广阔的应用前景,但目前研究主要是其翻译表现的综合测评,缺乏结合翻译实例的人工测评。Chat GPT的翻译功能在众多领域发挥了重要作用,已有学者关注到了Chat GPT翻译为教育、财务和编辑出版行业带来的便利,例如郭亚军、束开和徐敬宏等[6][7][8]。此类文章共14篇,但是关于Chat GPT翻译功能的论述所占篇幅较短。当然Chat GPT在翻译方面存在局限性,其翻译结果是由训练语料决定的,有时候会输出带有偏见性、敏感性的翻译,对于文化负载词的翻译也不准确。其中有代表性的有汤景泰的《Chat GPT给谣言治理带来严峻挑战》和崔茹茹的《〈蒙古族翻译史研究〉汉英翻译实践报告》[9][10]。此类文章只有4篇,可见只有较少学者关注到了Chat GPT翻译方面的劣势,研究比较零散,研究水平也层次不齐。
综上所述,现有研究让我们对Chat GPT从诞生至今的发展历程,其在翻译任务中所展现出的性能以及它在不同领域的应用情况有了一个初步的认识。然而,目前关于Chat GPT的学术研究相对较少,且研究的深度和广度都有待提升。尽管已有一些文献尝试对Chat GPT的翻译效果进行综合性的评估,但这些评估往往缺乏具体翻译实例的支撑,使得研究结果的说服力有限。此外,专门针对Chat GPT在某一特定体裁文本翻译表现的研究更是寥寥无几。
二、文本特点分析
《想北平》是一篇文笔优美的散文佳作,作者运用独特的语言艺术,通过质朴真挚的词汇、流畅而富有节奏感的句子构造,以及层次分明、情感递进的篇章布局,成功地将对北平的无限眷恋和深情怀念呈现给了读者。
词汇层面,《想北平》中含有大量文化负载词和多义词。文化负载词是凝聚着中国人独特的思想文化的“中华思想文化术语”,这类术语是中国人创造的,现已形成了固定的表达形式,其中蕴含着中华民族独特的哲学智慧、思考方式、文化精神、价值理念[11]。《想北平》中的“北平”便是一个例子。多义词是具有多种相关意义的词,例如散文中“空闲”一词。但在具体的语境中,多义词表示的意义是确定的、单一且不变化的。句子层面,文章多处使用了省略的手法,省略不言自明的内容,从而达到言有尽而意无穷的效果。篇章层面,《想北平》的遣词造句十分考究,注重作者的情感表达。
《想北平》有着独特的散文语言特点,因此要想产出优质的散文翻译并不是一件易事,这对Chat GPT来说是一大挑战。
三、Chat GPT在散文翻译中的优势
Chat GPT在翻译领域有着广阔的应用前景,其准确性和流畅度已经逐步接近人类翻译的水平,在背景资料查询、多义词翻译和原文风格再现方面表现突出。
(一)背景资料查询
Chat GPT可以进行自然语言查询。用户可以用自然的语言形式提出问题,而不必拘束于特定的关键词或查询语法,这使得搜索过程更加直观和人性化。译者可以借助Chat GPT查询散文中难以理解的概念,打破知识的壁垒,从而判断机译结果是否正确。例如“单摆浮搁”是一个充满地方色彩的的词汇表达。在Chat GPT中输入“单摆浮搁是什么意思?”给出的答案是:“单摆浮搁”是一个中国的俗语,意思是没有选择或无法表达自己的意见。在这个上下文中,可以理解为仅仅简单随意地描绘北平,但是所描写的事物之间缺乏联系。张培基将这个词翻译成了“exclusively”,Chat GPT将其翻译成了“shallow”。可见张培基译本和Chat GPT都将这层含义表达了出来。
翻译工作者们在面对复杂的语言转换任务时会面临不同程度的挑战。不同于电脑可以轻易地存储和检索各行各业的海量知识,翻译工作者的大脑容量是有限的,他们无法像计算机那样快速地访问和处理广泛的信息。因此,必要时译者可以借助Chat GPT来搜索资料,验证机器翻译的正确性。
(二)多义词翻译
传统的机器翻译常出现多义词翻译错误的情况,翻译出的结果不符合该句语境。而Chat GPT与传统机器翻译的一个最大不同就是它有着更严谨的语言逻辑,因为其纳入了人类语境并且进行大数据训练,而且通过机器学习深耕,获得逻辑严密性。刘洋指出当前的人工神经网络机器翻译应用的编码器—解码器首先会将每个词汇转换成向量表示,递归神经网络将各个词汇的向量联系起来形成整个句子的向量。目的语端的递归神经网络将整个句子的向量解码成英文句。每个词汇的向量中同时包含着左侧和右侧词的信息,因此神经网络可以动态计算出该词最符合上下文语境的意思[12]。
文中“空闲”一词有两个意思,一方面可以指没有事情可做的人;另一方面则指没有被使用或占用的物品。在这种情况下,Chat GPT通过分析词汇所包含的上下文向量信息,准确判断出此处“空闲”是用来修饰物品的,即指这片土地是未被占用的。因此,Chat GPT将“空闲”翻译为英文中的“open”,而不是表示时间空闲的“leisure”。这一翻译不仅传达了原文的字面意思,更准确地捕捉了原文的深层含义。张培基的翻译同样采用了“open”这一译法,这不仅与Chat GPT的翻译结果一致,而且进一步印证了Chat GPT在处理多义词翻译时的准确性和可靠性。
(三)原文风格再现
周领顺指出作品风格是文学家的生命,文学翻译的作者也十分重视风格再现,因此能否实现风格再现是评价翻译质量的一个标准[13]。Chat GPT风格再现方面的表现可圈可点,主要表现在词汇层面的人称显化处理、句子层面的句式模仿和篇章层面的句长把控。
词汇层面,《想北平》是一片抒情散文,频繁使用第一人称有助于抒发作者的真情实感,但有时候作者也会省略人称,形成无主句。因此,译文中的人称显化,一方面可以明晰原文的含义,另一方面有助于引发读者情感共鸣。例如Chat GPT将“真愿成为诗人”翻译成“I wish I were a poet”,增译了第一人称“I”并且用了虚拟语气,帮助读者了解到这句话是作者内心的愿望,且实现的可能性不大。张培基译文将这句话处理成了“If only I were a poet”,同样增加了第一人称。
句子层面,原文多处运用排比的修辞技巧,例如将北平与其他城市进行对比,突出北平的优势;将自己对北平的爱与对母亲的爱进行类比,使得情感更加充沛。排比句的使用可以达到增强节奏感和气势的效果。因此,译文可以通过再现这种句法结构来还原原文的语言风格。例如原文中作者将自己对北平的爱与对母亲的爱进行类比,表达自己对北平爱得深沉,Chat GPT将“在我……的时候,我……;在我……的时候,我……”排比句式译为“When I think of doing something to please her,I smile quietly to myself; when I worry about her health,tears well up in my eyes”。原文中“在我……的时候,我……”的结构重复了两次,形成排比句,Chat GPT在处理这话的时候同样使用了排比的句式,“When I...”的结构出现了两次,中间以分号隔开,实现了与原文句式结构上的对等。张培基译文同样使用了排比句式,“When I...when I...”重复两次,进一步印证了Chat GPT在还原语言风格方面的优异表现。
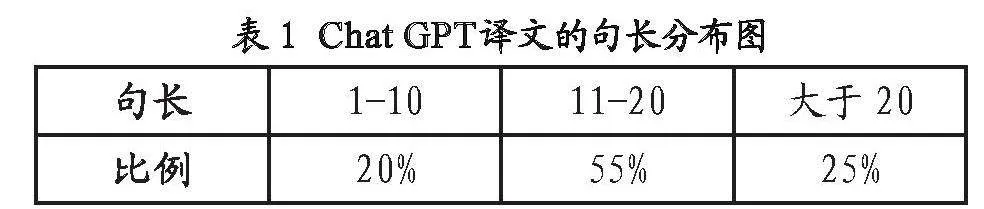
篇章层面,原文通过简短而有力的句式来增强语言的冲击力。文章中,作者采用了一贯的平民化语言风格,让读者能够直接感受到文字背后的真挚情感。要想再现朴素平实风格,译文同样也需要采用简短句子来切合原文语体。表1为Chat GPT译文的句长分布图,以10为基本单位,1—10为一组,11—20为一组,20以上为一组。根据《英汉互译实用教程》中对英文短句的定义(20个词以下为短句),可以计算出Chat GPT译文中的短句占比75%[14]。因此,译文使用的主要是简短的句子,贴合原文简洁朴素的风格。
表1 Chat GPT译文的句长分布图
句长 1-10 11-20 大于20
比例 20% 55% 25%
四、Chat GPT在散文翻译中的劣势
Chat GPT在散文翻译中存在着局限性。人类语言的产生是一个复杂的过程,而机器是人类将自己的思想转化为行动的一个产物。相比较而言,机器要比人脑简单得多,对于人们所说的一些语言以及产生的一些思想活动,机器是无法解读或破译的。Chat GPT翻译的劣势主要表现在内涵理解,内容补充,逻辑分析和情感表达四个方面。
(一)内涵理解不准确
Chat GPT在内涵理解方面的缺陷主要表现在对文化负载词的翻译上。汉语词汇与文化是相互影响的,正如萨丕尔所说的词汇承载着文化,语言史和文化史是一同发展的[15]。因此,汉语词汇常常含有丰富的象征意义、风俗习惯或历史知识,这是Chat GPT所不能理解的。
原文中出现了多次“北平”,张培基将“北平”翻译成了“Peiping”,但是Chat GPT直接翻译成了“Beijing”。这两种翻译虽然指的是同一个地方,但是反应的历史含义完全不一样。1928年,北京改名为北平。而《想北平》写作时北京的名字仍然是北平。名字里附带着特定的历史信息,如果译作Beijing一定程度上属于错译。
不过令人欣慰的是通过明确的指令,Chat GPT可以修正自己的错误。以“考虑历史因素,北平应该翻译成Beijing还是Peiping?”进行提问,Chat GPT给出了以下解释“考虑到历史因素,北平通常会被翻译成Peiping,因为在20世纪早期和中期,Peiping是北平的英文名称。然而,自1949年中华人民共和国成立后,北平的名称被改为北京。因此,根据时间和历史语境,Peiping可能更适合早期的文本,而Beijing则更适合现代和当代的文本。”
(二)省略内容补充不完整
胡壮麟认为中文经常会省略掉一些不言而喻的内容,从而使文章结构更加紧凑,这些被省略的内容可以在上下文中找MdJ8PdMej02PIgLlXHn/fQdvipjXfr2GOBzxBYPt2YU=到[16]。因此,省略的信息并不会给源语读者造成理解上的障碍。但是Chat GPT在翻译的时候无法根据上下文语境补充出中文文本中省略的内容,导致英文读者不能获得完整信息,甚至造成误解。例如原文中“我的北平”是一个省略表达,完整的意思应该是“和完整的北平相比,我知道北平只是……”因此,张培基增译了该部分省略的信息,使得译文更加流畅易懂。但是Chat GPT无法补充出该部分的意思,只是直译成“my Beijing”,容易让读者将此处的修饰关系理解为所属关系。
(三)逻辑分析不清
汉语是意合型语言,上下句的逻辑是通过意思来展现的而不是逻辑词,而英语是形合型语言,注重逻辑词的使用[17]。因此,汉英翻译中要将逻辑词显化,从而表达得更加严谨。崔启亮表示机译错误主要是因为机器不能理解复杂的句间逻辑[18]。此外,由于中文语料在Chat GPT训练中占比较小,所以Chat GPT很难理解中文句子之间隐性的逻辑关系[19]。例如原文中将巴黎与北京对比,进而突出北京的好,Chat GPT将其翻译成“In Paris,there are many places that can be exhausting,so coffee and wine are necessary for stimulation;in Beijing,a cup of mild fragrant tea is enough”。原文两句话运用了对比的手法,但两句话之间并没有出现转折连词。译文中转折意义的表达既可以通过转折连词实现也可以通过分号来实现。分号虽然有转折的用法,但是日常使用较多的是并列用法。但其对比意味不如转折连词,读者需要自己通过上下文语境去体会句间的转折含义。张培基译文用“while”来体现两个城市之间的对比关系,北平的优势更为凸显。Chat GPT却只是用分号来连接两句话,其对比意味明显不如转折连词“while”。
为了测试Chat GPT能否在逻辑连接方面做出改进,输入指令“增强上句的转折意味”。Chat GPT输出的结果是:“In Paris,where the hustle and bustle can drain one’s energy,coffee and wine serve as vital pick-me-ups;whereas in Beijing,amid a more tranquil ambiance,a soothing cup of fragrant tea suffices to revitalize the spirit.”可以发现,这次的结果使用了转折连词“whereas”,增强了对比含义。
(四)情感表达欠缺
散文十分注重表达作者内心体验和抒发作者内心情思[20]。但是Chat GPT无法体会文章的情感,难以选择恰当的词来传达作者的真情实感。蒋跃指出机译译文在情感表达方面不够丰富,在这一点上是远远比不上人工译者的[21]。例如文中“我心中有个北平”表达了作者对北平的热爱,以至于心被北平占满了。张培基译文用“possessing”表示“有”的概念,表明北平已经占据了“我”的心,突出表达作者的思乡之情。Chat GPT只是将“有”翻译成了“have”,读来十分平淡,使读者不能感受到作者对北平的思之切爱之深。
虽然第一次机译结果缺乏情感,但Chat GPT可以对其润色。输入指令“润色上述语句以体现作者对北平的爱”。Chat GPT给出的回答是:“I cannot fall in love with Shanghai and Tianjin,for in my heart,Beijing holds a special place.”这次将“有”翻译成了“holds a special place”(在心里占据特殊的位置)明显比第一次更能体现作者情感。
五、结论
Chat GPT是一款通用的大参数预训练自然语言生成模型,在翻译领域获得了越来越广泛的应用。本文以老舍的《想北平》为原文本,深入分析了张培基的经典译本与Chat GPT生成的译本之间的差异,旨在评估Chat GPT在散文翻译这一特定领域的表现和能力。研究结果表明,Chat GPT在资料查询,多义词翻译和散文风格再现方面有突出优势。但是Chat GPT也有自身的局限性。Chat GPT无法准确理解文化负载词的内涵,无法补充出省略的内容并且无法自动选取贴合文章情感的词汇。
参考文献:
[1]何哲,曾润喜,秦维等.Chat GPT等新一代人工智能技术的社会影响及其治理[J].电子政务,2023,(4):2-24.
[2]张超,韩虓,王芳.Chat GPT与知识生产和复用:赋能、挑战与治理[J].图书与情报,2023,(3):52-60.
[3]郑世林,姚守宇,王春峰.Chat GPT新一代人工智能技术发展的经济和社会影响[J].产业经济评论,2023, (3):5-21.
[4]赵雪,赵志枭,孙凤兰等.面向语言文学领域的大语言模型性能评测研究[J].外语电化教学,2023,(6):57-65+114.
[5]王天恩.Chat GPT的特性、教育意义及其问题应对[J].思想理论教育,2023,(4):19-25.
[6]郭亚军,郭一若,李帅等.Chat GPT赋能图书馆智慧服务:特征、场景与路径[J].图书馆论坛,2023,(2):30-39+78.
[7]束开,郭奕.Chat GPT在财务领域的应用探索[J].财务与会计,2023,(22):56-59.
[8]徐敬宏,张如坤.Chat GPT在编辑出版行业的应用:机遇、挑战与对策[J].中国编辑,2023,(5):116-122.
[9]汤景泰.Chat GPT给谣言治理带来严峻挑战[J].探索与争鸣,2023,(3):33-35.
[10]崔茹茹.《蒙古族翻译史研究》汉英翻译实践报告[D].内蒙古大学,2023.
[11]陈海燕.浅析中国思想文化术语翻译中的难点[J].中国翻译,2015,(5):13-17.
[12]刘洋.神经机器翻译前沿进展[J].计算机研究与发展,2017,54(6):1144-1149.
[13]周领顺.译者行为批评“行为-社会视域”评价系统[J].上海翻译,2022,(5):1-7+95.
[14]宋天锡.翻译新概念:fiXfQ+MqG+im7pdWQEXe/Q==英汉互译实用教程[M].北京:国防工业出版社,2007.
[15]爱德华,萨丕尔.语言论[M].北京:商务印书馆, 2003.
[16]胡壮麟.语篇的衔接与连贯[M].上海:上海外语教育出版社,1994:76.
[17]沈家煊.“零句”和“流水句”——为赵元任先生诞辰120周年而作[J].中国语文,2012,(5):403-415+479.
[18]崔启亮.论机器翻译的译后编辑[J].中国翻译, 2014,(6):68-73.
[19]郑丽芬.赋能与重构:AIGC驱动下的出版业[J].出版发行研究,2023,(4):37-44.
[20]方遒.散文学总论[M].合肥:安徽教育出版社,2004: 178.
[21]蒋跃.人工译本与机器在线译本的语言计量特征对比[J].外语教学,2014,(5):98-102.
作者简介:
杨睿颖,女,河北沧州人,河北工业大学外国语学院MTI在读硕士研究生,研究方向:人文社科翻译。
