
一种加速渲染NeRF烘焙数据的方法
2024-11-07 00:00:00王晓萌方梦园
软件工程 2024年11期


摘要:针对基于神经辐射场的渲染方法虽然具备低人工参与度下的照片级别图像生成能力,但是生成图像的时间过长、难以实现实时渲染的问题,文章聚焦于提升神经辐射场的实时渲染性能,从神经辐射场体渲染环节处着手,以烘焙数据为渲染资产,针对利用八叉树保存体素数据无法达到常数访问时间复杂度的问题,提出了一种基于八叉树的扁平化稀疏体素存储方式,以及相应的渲染采样算法。实验结果表明,在使用神经辐射场(NeuralRadianceField,NeRF)合成数据集渲染800×800分辨率的图像时,可以达到268.83的平均帧率,高于其他对比方法。
关键词:神经辐射场;渲染;稀疏体素;空间数据结构优化
中图分类号:TP37文献标志码:A
0引言(Introduction)
神经辐射场(NeuralRadianceField,NeRF)是一种新兴三维场景表征方法。NeRF[1]能够利用一系列照片生成任意视角下对应的三维对象和场景的逼真图像,这一突破极大地降低了生成照片级别质量图像的建模成本。NeRF凭借其出色的三维重建能力,在自动驾驶[2]、人体建模[3]、医学[4]、文物数字化[5]等领域引起了广泛的关注和探讨。尽管如此,神经辐射场渲染方法仍面临实时渲染的重大挑战,这主要归咎于其极端的采样要求和昂贵的神经网络查询代价,严重制约了该方法在实时渲染场景中的广泛应用。
本文针对神经辐射场的渲染速度问题展开研究,重新组织了八叉树节点的存储形式,设计了一种具有常数访问时间复杂度的体素数据存储结构,将场景的三维信息以一种更加直接和高效的方式存储,减少了渲染时的计算负担。实验结果表明,相比于其他神经辐射场渲染方法,本文方法在渲染时的帧率表现更好,实现了渲染速度的提升。
[BT(3+1*[HJ1mm]1[ZK(]神经辐射场数据的表现形式(DatarepresentationofNeRF)[HJ][BT)]
1.1神经网络
基于神经辐射场的渲染方法通常采用与NeRF[1]相同的做法,将渲染对象以神经网络形式表示,并在此基础上进行优化和调整。FastNeRF[6]分解了神经辐射场网络结构,并为空间中的每个位置紧凑地缓存深度辐射图,使渲染速度得以提高;KiloNeRF[7]通过训练数千个小型多层感知机和稀疏采样加速渲染;Instant\|NGP[8]设计了一种被称为多分辨率哈希编码的方法,可以利用小型网络生成高质量图像,缩短了从输入照片到输出新视角图像的整体时间。然而,此类方法渲染图像时需要经过网络的层层计算,在渲染速度的提升方面仍存在局限性。
1.2烘焙数据
在神经辐射场训练完成后,可以通过特定的采样策略和后处理技术,将场景中的每个体素的颜色和密度信息预先计算并存储下来。在计算机图形学中,这种方法被称作烘焙,相当于将动态的渲染过程转换为静态的数据集采样过程。在渲染过程中使用这类烘焙数据,可以将神经网络推理与合成指定视角图像的过程分离。通过使用预提取的显式体素数据,可以避免重复的神经网络推断,直接获取体素的颜色和密度信息,从而显著提高渲染效率。
球谐光照是一种计算机图形学三维空间照明技术。球谐函数为球谐光照技术的数学工具,为一组基函数,可以通过不同的系数对不同的原函数进行模拟,从而获取近似值。不同阶数的球谐函数可以不同程度地还原光照信息。PlenOctree[9]将球谐函数用于体渲染环境中,使神经网络输出球谐函数系数[WTHX]k[WTBX]和体素空间密度值σ。
使用球谐函数系数代替RGB颜色作为输出,可以从神经网络中将体素数据显式地提取出来,在渲染时直接作为像素颜色的生成数据,节省了神经网络的推理时间。
针对神经辐射场渲染方法的实时性问题,本文使用烘焙数据进行渲染,以避免渲染过程中神经网络的密集推理进程。
2研究方法(Researchmethod)
2.1问题描述
对于体渲染来说,一个重要挑战就是在保证渲染质量的同时,尽量减少所需的体数据访问次数和计算时间,满足不断增长的渲染需求和变化的应用场景。在光线投射算法中,体素的存储方法对于访问次数具有非常重要的影响。
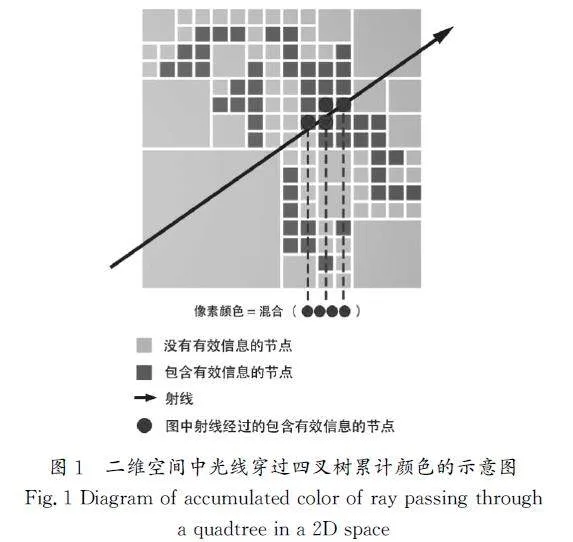
稀疏体素八叉树是一种利用八叉树结构存储稀疏体素的结构。相比于神经网络采用网络函数隐式地存储体素数据,八叉树存储的是离散的显式数据,这意味着渲染时可以直接使用指定位置存储的颜色信息,从而可以节省大量的推理计算时间。除此之外,八叉树的分支结构与稀疏体素的分布特性相契合,空间中体素密集的区域对应八叉树深层次的分叉,体素稀疏区域则对应八叉树浅层部分的叶节点。这些位于八叉树上层的叶节点,在空间上表征大尺寸的空白区域,在光线穿过这些节点时,可以实现长距离的跳跃,在渲染时就可以避免持续在对颜色无贡献的区域选取采样点。如图1所示,四叉树为二维空间中的八叉树,用层级结构表达体素的空间位置,固定分叉数的树形结构可合并邻近的稀疏空间。光线在不同尺寸的节点间跳跃前进,遇到满足阈值条件的节点时,就会累计颜色。
使用八叉树存储体素数据,可以在渲染时实现更高效的访问与采样。然而,随着所存储的体素数据分辨率的提高,八叉树会向更深的方向扩展,从根节点到叶节点的查询路径可能会更长。这种无限的增长机制,使随机访问体素数据的时间代价不可控,限制了体渲染速度的进一步提升。
2.2基于八叉树的扁平化稀疏体素存储方式
针对神经辐射场渲染方法存在的实时性挑战,本文使用烘焙数据进行渲染,旨在避免渲染过程中神经网络的密集推理进程。同时,重新组织八叉树节点的组织形式,设计了一种具有常数访问时间复杂度的体素数据存储结构,将场景的三维信息以一种更加直接和高效的方式存储,减少了实时渲染时的计算负担。
相比于八叉树,使用均匀网格存储体素时,射线只需要对其穿过的每个单元进行一次查询,因为每个单元的位置是预先确定的,与其他单元并不存在父子关系,所以不需要进行额外的搜索。但是,均匀网格无法合并大量的空白区域,在渲染时,光线每经过一个体素单元格就要进行一次访问,这限制了光线行进速度的提升。
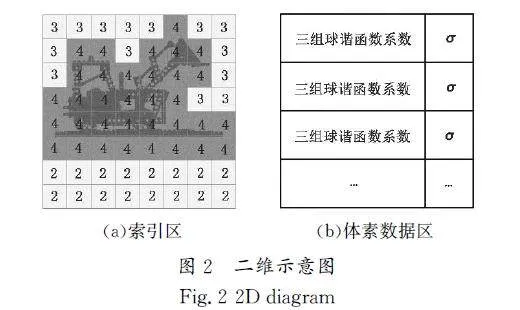
本小节提出了一种能提供八叉树层级指引信息的扁平数据结构用来存储体素,以此实现对数据的高效组织和管理。总体而言,对于从神经网络中预提取出的数据(球谐函数系数和密度)存储至八叉树后,首先将八叉树层级信息单独提取至一个指定分辨率水平的均匀网格,以下称其为索引区;其次重新排布体素数据至一个连续的列表,以下称其为体素数据区。二维空间的索引区和体素数据区如图2所示。
索引区的每个单元格都存储了一个编码,编码为32位,前5位表示当前体素立方体的尺寸,后27位表示该单元在体素数据区的索引。若该单元格对应体素块内的数据为空,则将后27位用0填充。体素数据区的每一个单元格存储了一个体素对应的三组球谐函数系数和体素空间密度。图2(a)索引区单元格内的数字代表了可在渲染时进行的体素块跳跃度量标准。以图2为例,光线行进至所含数字为2的单元格时,可沿光线方向跳跃〖SX(〗1〖〗22〖SX)〗个标准立方体(三维空间中包围所有体素的边界正方体)。二维单元格所映射的三维空间范围大小与八叉树的层级信息相对应,由cube表示。cubemax为八叉树存有颜色及空间密度信息的叶节点所代表的体素块层级信息,可以用于表示体素块的大小。体素数据区的项数为八叉树所包含的有效体素个数,即存在渲染对象颜色和密度信息的体素个数。这种存储方式将一棵八叉树“拍平”成一个均匀网格和一个数据列表,是一种扁平化的存储方式。
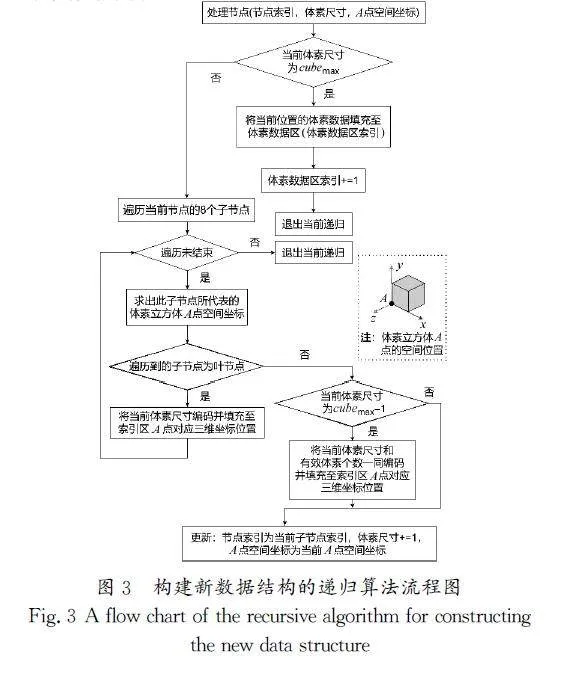
图3展示了构建新数据结构的递归算法流程图,详细描绘了如何使用处理节点函数,从八叉树中递归构建索引区和体素数据区的过程。在该流程中输入八叉树根节点索引、标准正方体体素尺寸和原点坐标至处理节点函数后,即可生成本文使用的体素存储结构。
2.3渲染过程中的快速访问算法
渲染时需要根据体渲染公式沿光线方向计算出像素颜色。对于行进中的光线,使用轴对齐包围盒(Axis\|AlignedBoundingBox,AABB)算法与三维空间中的体素立方体进行碰撞检测。
算法1给出了像素着色算法的伪代码。确定射线与数据边界的空间关系,算法1中的t为光线行进的时间点。若射线与数据边界不相交,则像素颜色等于背景颜色;若射线与数据边界相交,计算出交点P之后,射线自适应调整步长前进,累计颜色信息,直到超出空间范围。函数AcuqireDataFromSparseVolume首先读取P点对应的CubeSize和位置索引,其次按照此位置索引读取体素数据区存储的球谐函数颜色系数color和体素空间密度sigma。若P处对应位置为空,则color和sigma为0。
依照此算法进行光线投射,可达到常数访问时间复杂度。具体而言,只需一次查询即可定位空间位置的体素数据。此外,本文设计的体素存储结构用索引区保留了八叉树的稀疏存储信息,因此渲染时仍然能够自适应地调整采样步长。
3实验分析(Experimentalanalysis)
3.1实验环境和实验数据集
本文实验是在配备单个NVIDIAGeForceRTX3070GPU和i7\|11800HCPU的笔记本电脑上进行的。项目通过跨平台的渲染库bgfx构建。
NeRF合成数据集为NeRF[1]生成的数据集,本文选择了其中6个模型来运行实验:麦克风、椅子、热狗、乐高、鼓和船。每个模型有100张视图作为输入,200张视图用于测试,所有图像均为800×800像素。
此外为了实现移动端的实时渲染,我们使用由PlenOctree[9]提供的用于网络端渲染的预提取体素数据。
3.2实验结果
本文选择以下几种方法与本文方法进行实验对比:NeRF[1]、PlenOctree[9]和Instant\|NGP[8]。
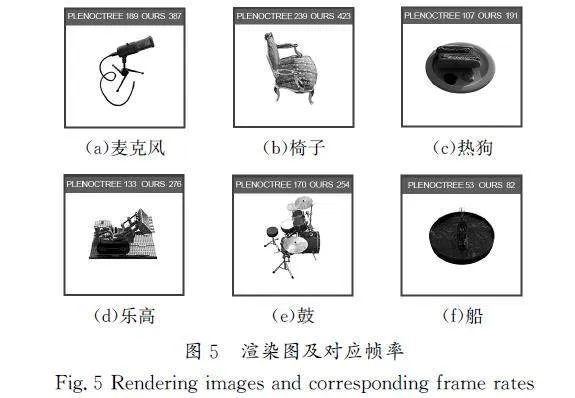
本文提出的混合渲染方法可以在NeRF合成数据集上以268.83的平均帧率渲染800×800像素的图像。图4展示了使用不同方法渲染乐高模型的图像。
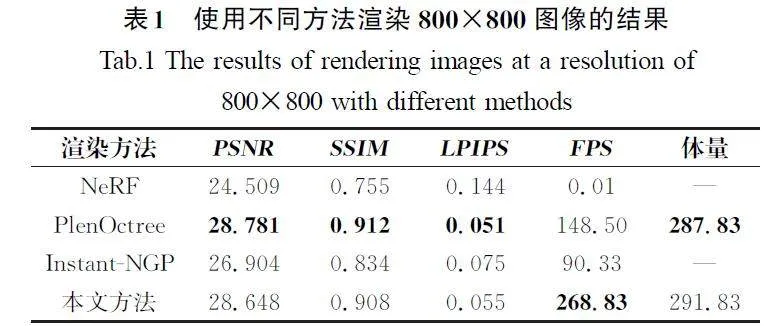
表1列出了使用几种方法渲染800×800像素的图像平均质量和渲染速度比较结果。具体比较了峰值信噪比(PSNR)、结构相似性(SSIM)、学习感知图像相似度(LPIPS)和每秒帧数(FPS)。PSNR数值越大,代表图像间的相似度越高。SSIM数值处于[-1,1],数值越大,代表图像间的相似度越高。LPIPS数值越小,代表图像间的相似度越高。其中,体量表示预提取体素数据文件的大小,单位为MB。各指标最佳结果使用粗体显示。
由表1可知,作为一种烘焙数据的渲染方法,本文方法在保持高渲染质量的同时具有更快的渲染速度,而且使用的存储空间与PlenOctree[9]基本持平。
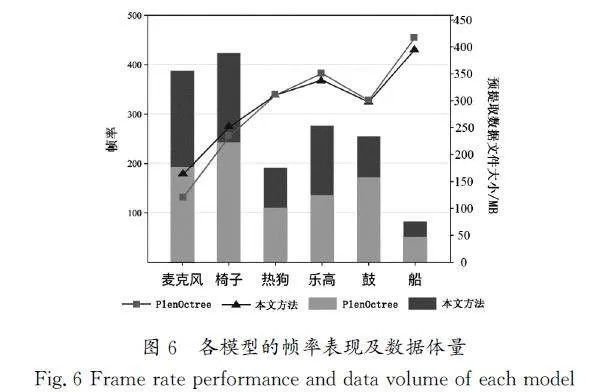
本文方法与PlenOctree[9]均使用了对普通设备更适用的烘焙数据方式,鉴于此共性,下文将重点对这两种方法进行比较分析。图5具体展示了各种模型的渲染图,同时在上方列出了PlenOctree和本文方法在渲染时的帧率数值。
图6使用折线图和柱状图对两种方法进行了更加直观的比较。折线图显示了PlenOctree和本文方法对各种模型的预提取数据文件大小;柱状图展示了使用PlenOctree和本文方法渲染各种模型时的帧率。
4结论(Conclusion)
神经渲染能够以三维场景为主体生成高质量的图像,但其巨大的计算需求一直是实时渲染领域的一大难题。因此,本文针对神经辐射场的实时渲染问题展开研究,在渲染时采用烘焙数据,并设计了一种基于八叉树的扁平化稀疏体素数据存储结构和对应的访问算法,提高了渲染速度。未来,基于神经辐射场的渲染方法的发展需要考虑更多的应用场景,期待本文提出的渲染方法能为神经辐射场在更广泛渲染应用中的实践提供有益借鉴。
参考文献(References)
[1]MILDENHALLB,SRINIVASANPP,TANCIKM,etal.NeRF:representingscenesasneuralradiancefieldsforviewsynthesis[M]∥Springer.ProceedingsoftheSpringer:VEDALDIA,BISCHOFH,BROXT,etal.LectureNotesinComputerScience.Cham:SpringerInternationalPublishing,2020:405\|421.
[2]成欢,王硕,李孟,等.面向自动驾驶场景的神经辐射场综述[J].图学学报,2023,44:1091\|1103.
[3]ISIKM,RNZM,GEORGOPOULOSM,etal.HumanRF:high\|fidelityneuralradiancefieldsforhumansinmotion[J].ACMtransactionsongraphics,2023,42(4):1\|12.
