
基于卷积神经网络和残差结构单元的合同数据识别提取
2024-11-07 00:00:00张纯刘从军
软件工程 2024年11期

摘要:为提升合同中数据项识别和提取的准确率,提出一种基于卷积神经网络(ConvolutionalNeuralNetwork,CNN)和残差结构单元(ResidualBuildingUnit,RBU)结合优化的CNN\|RECR(RealEstateTransactionContractInformationDetectionandRecognitionMethodBasedonImprovedConvolutionalNeuralNetwork)模型,并将其应用到不动产交易平台中合同数据项的识别提取场景。首先,针对提取特征表示能力弱等问题,设计了合同数据文本检测网络(ContractDataTextDetectionNetwork,CDTD\|Net)对合同手写文字的不同尺度特征进行提取;其次,与残差结构单元相结合,设计识别文字与识别数字模型;最后,对实例进行实验,实验结果显示CNN\|RECR模型的识别准确率达到97.62%,证明本方法能有效提高模型的识别性能,为实现低成本运行奠定了基础。
关键词:卷积神经网络;残差结构单元;合同数据;识别提取
中图分类号:TP391.1文献标志码:A
0 引言(Introduction)
在不动产登记交易领域,为了加快数据的处理速度,实现合同的数字化管理成为关键。数字化合同不仅便于备份,还能快速检索合同中的详细信息,确保合同中的数据与相关数据库中的信息一致,保障交易的合法性和准确性[1]。因此高效地进行合同管理、信息的识别和提取,是实现这一目标的重要前提条件。
Hewlett\|Packard公司开发的开源OCR(OpticalCharacterRecognition)引擎Tesseract[2]最早是于1985年由HP(Hewlett\|Packard)实验室的开发团队发布的,通常借助光学字符识别技术(OpticalCharacterRecognition,OCR)将图片中的信息转化为计算机可以处理的数据[3]。ZHOU[4]提出采用改进的连接文本区域网络(CTPN)文本检测算法和卷积循环神经网络(CRNN)模型对自然场景文字进行检测与识别。2016年,DAI等[5]提出了残差网络(ResNet),通过引入残差学习解决了深度神经网络训练中的梯度消失问题。YOLO(YouOnlyLookOnce)[6]是由JosephRedmon和AliFarhadi于2016年提出的目标检测算法,它在实时目标检测方面表现出色。
在数据识别提取的过程中,构建特征库耗时且耗力,提取的图片特征容易被噪声干扰。本文提出一种基于卷积神经网络(CNN)和残差结构单元(RBU)结合优化的CNN\|RECR(RealEstateTransactionContractInformationDetectionandRecognitionMethodBasedonImprovedConvolutionalNeuralNetwork)模型。该模型以卷积神经网络(CNN)为基础,并结合了残差结构单元(RBU)进行优化。通过在数据集上进行实验验证,结果表明CNN\|RECR模型提升了合同处理任务的实用性和可靠性。
1相关理论(Correlationtheories)
1.1卷积神经网络
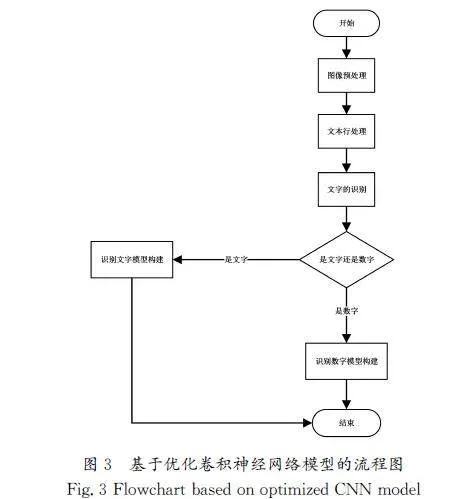
卷积神经网络(ConvolutionalNeuralNetwork,CNN)是一种深度学习模型。计算机科学家YANN在1998年提出了卷积神经网络(CNN)的概念[7],并在手写字符识别等领域展示了其卓越的性能。传统的卷积神经网络在图像处理过程中需要处理的数据量大,图像数字化处理无法保留原有的图像特征,导致图像识别效率低下。相比之下,CNN则通过减少权重数量,相比于传统的卷积神经网络,能有效地提升图像的识别能力。卷积神经网络的拓扑结构如图1所示。
对于房产交易合同中的手写数据项的识别和提取过程,其目标函数是连接主干网络(BackboneNetwork)及文本识别头部(TextRecognitionHead)的综合损失函数,是由3个损失函数加权在一起的,分别为连接时序分类损失(ConnectionistTemporalClassification)、定位损失(LocalizationLoss)、分类损失(ClassificationLoss)。
连接时序分类损失的数学表达式为
其中:S表示训练集;LCTC(S)表示给定序列和输入后,最终输出正确序列的概率。
定位损失的数学表达式为
其中:LNLL(Y,Y′)是一整个数据集中的交叉熵损失,n是样本数量,C是类别数量,yij是第i个样本的实际类别分布,y′[KG-1mm]ij是第i个样本的模型预测的类别概率分布。
对于文字识别,分类损失选取使用交叉熵损失(Cross\|EntropyLoss)作为损失函数,交叉熵损失结合Softmax函数的输出与实际标签之间的差异,用于衡量模型的性能。交叉熵损失的数学表达式为
其中:xi表示真实标签的第i个元素,yi表示模型预测x属于第i个类别的概率。
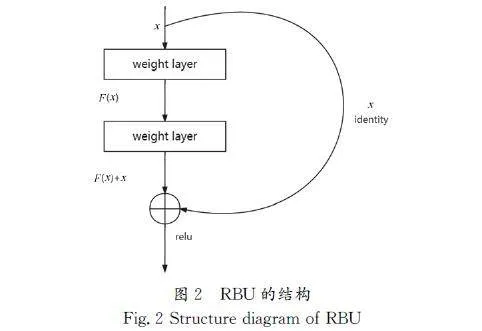
1.2残差结构单元
残差结构单元(RBU)是深度学习中用于构建残差神经网络(ResidualNeuralNetwork,ResNet)的基本组成部分。LIU等[8]的研究表明,RBU模块能有效地提升图像处理任务性能。残差结构单元模块通过引入捷径连接的深度神经网络结构,有效地解决了深层网络训练中的梯度消失问题,它是在提出的CNN模型的基础上进行了优化,旨在得到更高质量的识别结果。本文通过在CNN中引入残差模块解决了深度神经网络训练困难的问题。
本文在文字识别模型中采用了残差结构单元,以缓解梯度消失问题,同时提升特征提取能力并加速模型训练。
RBU结构如公式(4)所示:
特征映射如公式(5)所示,是指未添加捷径连接的公式。
特征映射如公式(6)所示,是指添加了捷径连接后,降低了模型优化难度。在这里,拟合函数属于一种数学模型,通常用于表示观测数据之间的关系,用来学习恒等映射转变成特征映射以及输入的数据之间的差值。
公式(7)表示的是一个残差块,通过引入残差连接,也就是将输入添加到映射F(x),能更好地进行深层次网络训练。
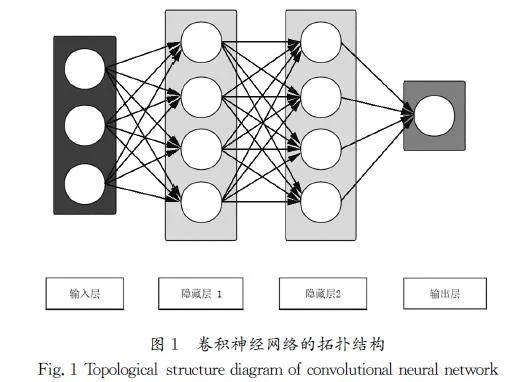
基于优化卷积的神经网络模型是在传统卷积神经网络的基础上构建的,它首先对数据集进行图像预处理,其次在残差结构单元的基础上进行文本行处理及文字识别,判断数据属于哪一种类型,并构建相应的数据模型,最后得到结果输出。
基于优化卷积的神经网络模型的流程如图3所示。
2.1图像预处理
图像预处理是在将图像输入计算机视觉或图像处理任务之前,对图像进行的一系列操作和变换,旨在准备和优化数据。图像预处理有利于提高模型的性能,减少噪声和一些不必要的信息,并且可以让模型容易学习到有用的特征。图像预处理的模块包括图像的锐化、图像二值化、图像形态学运算及模板匹配等。
对于房产交易合同的图像预处理,通常是在准备图像的同时进行一些其他任务,比如数据分析、文本提取等。该模块对房产交易合同的扫描图像输入进行整体分析,并匹配每个数据项的位置坐标。其中使用高斯模糊技术对图像中的噪点和一些不必要的要素进行去除,不仅可以提高图像的质量,还能对识别到的合同数据图像进行平滑处理。公式(8)为高斯函数的概率密度函数。
2.2文本行处理
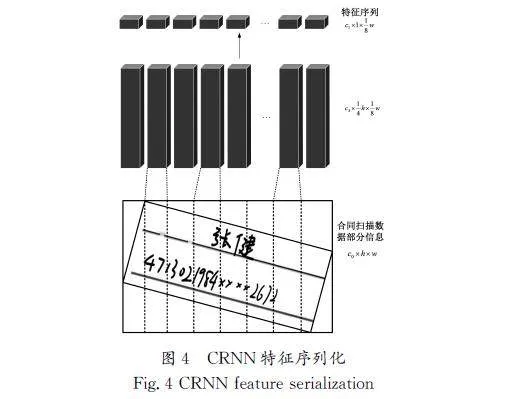
文本行处理是指房产交易合同中的文本行处理模块提取文本行的操作。进行扫描的合同是经过审核且留有档案的合同,要求对每项对应的数据项和数据类型进行识别和处理。但是,对倾斜的文本进行识别和处理时,提取到的特征向量中字符特征发生了形变。在传统的CRNN模型中,由于其具有时序性,因此有时会导致对输入的图像识别不完整的情况,要对特征f沿h维度进行平局池化,以此得到序列特征f∈Rc1h×1×〖SX(〗1〖〗8〖SX)〗w。如图4所示,模型无法识别图像中的“张”与“健”,无法确定与标签相对应的关系,图4中c、h、w分别为输入图像的统一通道数量、通道高、通道宽。
2.3文字的识别
在房产交易合同中的识别任务可以理解为是对数据的分类任务。通过统计分析,观察到文本内容存在文字和数字混合的情况。针对两种不同类型的数据进行分析,本文设计了CDTD\|Net检测算法用于提取不同尺度特征并进行融合,该网络基于FPN(FeaturePyramidNetworks)进行了改进和优化,增加了特征提取层,它可以用于检测和识别更小的手写文字,CNN\|RECR模型包含识别文字模型和识别数字模型。
2.3.1识别文字模型构建
识别文字模型的构建步骤如下。
步骤1:图像获取和预处理。
初始阶段,通过在图像采集过程获取输入图像,并对获取图像进行预处理操作,保证之后的分析可以在优化的数据表示上进行。
步骤2:文字载体的识别获取。
通过模型进行图像识别,识别所有的文字载体[9],判断其数据类型,若是文字,则将其转换为对应的文本表示,若不是文字,则跳过该数据。在这一阶段中,模型用捕获文本信息和记录文字在图像中位置信息的方式,建立文字的空间分布信息。
步骤3:转换为对应的文字。
判断识别的文字数据类型,若是文字,则将其转换为对应的文本表示。
步骤4:记载文字的位置。
通过识别文字具体的方位信息并进行记载,有利于精确定位图像中的文字,让模型在文本的具体位置上提供更准确的信息。
步骤5:获取语句结构分布情况。
通过RBU,模型对特征向量进行处理并对模型的参数量进行修改,同时通过捷径连接加速模型参数向前传递。经过RBU之后,模型执行一维卷积层的转换,将特征向量转换为多维形式,获取到语句结构的分布情况[10]。最后取识别的中间特征向量中概率最大的索引值为识别结果。
识别文字模型的流程图如图6所示。
3 实验结果与分析(Experimentalresultsandanalysis)
3.1实验数据及环境配置
为了验证本文提出的CNN\|RECR模型对于房产交易合同文字进行提取和识别的效果,在实验过程中采用存量房房产交易签约合同图片数据集进行模型的性能测试,并对比其他模型的数据项识别提取效果[12]。
3.1.1实验数据
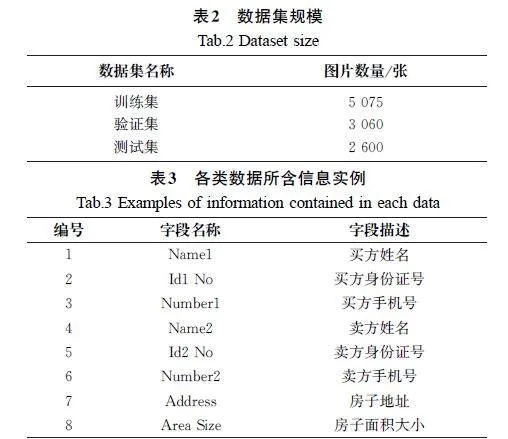
存量房房产交易签约合同图片数据集的数据集规模如表2所示;各类数据所含信息实例如表3所示。
3.1.2环境配置
实验使用了Python编程语言和PyTorch框架,训练和测试的硬件环境是AMDRyzen54500UCPU,软件环境基于Python3.11版本实现。
3.2实验结果分析
3.2.1手写文本检测算法验证
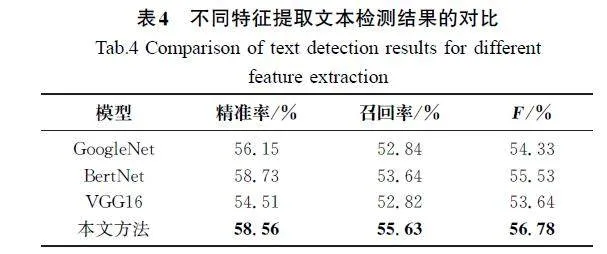
本文采用精确率、召回率及加权调和的平均F作为合同中手写文本检测效果的指标,并与一些特征提取模型进行了实验对比,如GoogleNet[13]、BertNet[14]及VGG16[15]等,验证CDTD\|Net在特征提取方面的优势,对比结果如表4所示。实验结果表明,相比于其他的算法,CDTD\|Net在提取文本特征准确率方面有了明显的提高。
3.2.2不同模型对于文本识别结果对比
其中:precision(精准度/插准率)指被分类器判断为1中预测正确的比重,recall(召回率/查全率)指被预测为正例的占总正例的比重。
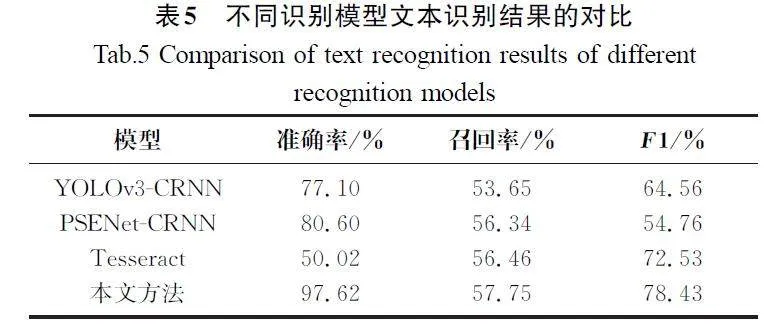
本文提出了一种优化的卷积神经网络算法。该算法使用CNN\|RECR模型,结合了残差结构单元,提高了对合同中数据项的识别、提取速度和精度。在以下4个不同的模型上进行了数据识别提取实验,选取了YOLOv3\|CRNN[16]、PSENet\|CRNN[17]及Tesseract[18]3个模型与本文提出的CNN\|RECR模型在对数据项的识别准确性方面进行了对比(图8),实验结果显示YOLOv3\|CRNN模型的识别准确率为77.10%,PSENet\|CRNN模型的识别准确率为80.60%,Tesseract模型的识别准确率为50.02%,本文提出的CNN\|RECR模型的识别准确率为97.62%。
根据图8和表5中的数据可以看出,在房产交易合同数据项的识别、提取过程中,在相同的数据集条件下,与YOLOv3\|CRNN、PSENet\|CRNN及Tesseract相比,CNN\|RECR模型的识别准确率分别提高了20.52百分点、17.02百分点、47.60百分点。CNN\|RECR模型可以明显地提高模型的识别准确率。
4结论(Conclusion)
本文基于FPN构造了CDTD\|Net,旨在提取手写数据的不同特征,并提出了基于优化卷积神经网络的房产交易合同数据识别方法,设计了CNN\|RECR模型。CDTD\|Net可以使难以完整识别的手写数据更准确地被识别,结合CNN与残差结构单元,减轻了模型的优化难度,增强了其特征表示能力,同时提高了网络对于文字特征的抽取能力。实验结果表明,与传统的CNN模型相比,本文提出的方法对文本数据提取和识别的准确率更高,并降低了存储开销和计算复杂性。
参考文献(References)
[1]赵旭升,赵前.电子合同的应用与展望[J].中国石油企业,2021(9):77\|80.
[2]SMITHR.AnoverviewoftheTesseractOCRengine[C]∥IEEE.ProceedingsoftheNinthinternationalconferenceondocumentanalysisandrecognition(ICDAR2007.LosAlamitos:ntix4PGVjgSyva785hN5R2fnzHHL5Y5TZcrhhRlatB0=IEEEComputerSociety,2007,2:629\|633.
[3]SABUAM,DASAS.ASurveyonvariousOpticalCharacterRecognitionTechniques[C]∥IEEE.Proceedingsofthe2018ConferenceonEmergingDevicesandSmartSystems.Piscataway:IEEE,2018:152\|155.
[4]ZHOUY.ResearchontextdetectionandrecognitionalgorithmbasedonCNNinnaturalscene[D].Shanxi:shanxiuniversity,2020:14\|34.
[5]DAIJF,HEKM,SUNJ.Instance\|awaresemanticsegmentationviamulti\|tasknetworkcascades[C]∥IEEE.Proceedingsofthe2016IEEEconferenceoncomputervisionandpatternrecognition.Piscataway:IEEE,2016:3150\|3158.
[6]REDMONJ,DIVVALAS,GIRSHICKR,etal.Youonlylookonce:Unified,real\|timeobjectdetection[C]∥IEEE.Proceedingsofthe2016IEEEconferenceoncomputervisionandpatternrecognition.Piscataway:IEEE,2016:779\|788.
[7]BONTARJ,LECUNY.Computingthestereomatchingcostwithaconvolutionalneuralnetwork[C]∥IEEE.Proceedingsofthe2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2015:1592\|1599.
[8]LIUX,SUGANUMAM,SUNZ,etal.Dualresidualnetworksleveragingthepotentialofpairedoperationsforimagerestoration[C]∥IEEE.Proceedingsofthe2019IEEE/CVFconferenceoncomputervisionandpatternrecognition.Piscataway:IEEE,2019:7007\|7016.
[9]刘影,余进,陈莉.基于改进卷积神经网络的多标签文本自动化分类研究[J].自动化与仪器仪表,2023(11):62\|66.
[10] 徐欢,张喜铭,杨秋勇,等.基于卷积神经网络算法的电网数据治理方法[J].南京邮电大学学报(自然科学版),2023,43(6):102\|111.
[11]王治学.基于图卷积神经网络的主题模型文本分类探究[J].科技创新与应用,2023,13(36):83\|86.
[12]陈暄,吴吉义.基于优化卷积神经网络的车辆特征识别算法研究[J].电信科学,2023,39(10):101\|111.
[13]SIMONYANK,VEDALDIA,ZISSERMANA.Descriptorlearningusingconvexoptimisation[M]∥LectureNotesinComputerScience.Berlin,Heidelberg:SpringerBerlinHeidelberg,2012:243\|256.
[14]LIUW,ANGUELOVD,ERHAND,etal.Ssd:Singleshotmultiboxdetector[C]∥Springer.ProceedingsoftheComputerVision\|ECCV2016:14theuropeanconference,amsterdam,thenetherlands,October11\|14,2016,proceedings,partI14.springerinternationalpublishing.Berlin:Springer,2016:21\|37.
[15]SINGHS,GARGNK,KUMARM.VGG16:offlinehandwrittenDevanagariwordrecognitionusingtransferlearning[J].Multimediatoolsandapplications,2024,83(29):72561\|72594.
[16]WUQM,SONGYT.TextdetectioninnaturalscenesbasedonYOLOv3andCRNN[J].Computerengineeringanddesign,2022,43(8):2352\|2360.
[17]YUEB,ZHANGZT.Englishbillboardtextrecognitionusingdeeplearning[J].Journalofphysics:conferenceseries,2021,1994(1):012003.
[18]ZENGY,MAMD.ResearchontextrecognitionbasedonTesseractOCR[J].Computertechnologyanddevelopment,2021,31(11):76\|80.
