
用于MIMO检测的基于NoC的多核动态可重构架构
2024-11-02 00:00:00范文杰周牧也朱凌晓李世平陈铠邓松峰何国强冯书谊宋文清李丽傅玉祥
现代电子技术 2024年21期




摘 "要: 随着无线通信技术的发展,实现多输入多输出(MIMO)系统检测性能与复杂度之间的最优权衡日益困难,深度学习DL为此提供了新方向。文中提出基于片上网络(NoC)的多核动态可重构架构MCDBP,以提高基于DL的MIMO检测算法的性能,并增强架构的可编程性和扩展性。MCDBP通过集成轻量级计算内核及片上网络互连,并行处理矢量⁃矩阵乘法、常数⁃矢量乘法、矢量点积、矢量加法等大多数深度展开网络的基本运算,有效提高复杂MIMO检测性能。架构的创新在于可重构的处理元件PE设计,可以依据DL驱动的MIMO检测需求动态调整。该设计对基于DL的MIMO检测算法共性进行深入分析,支持多种基本运算模式,展现极高灵活性。实验结果显示,MCDBP在执行基于DL的MIMO检测算法时,与通用CPU相比,可以实现12.66~22.98的加速比,算法性能有所提高,可以适应不同应用场景。
关键词: 无线通信; MIMO检测; 深度学习; 数据驱动网络; 模型驱动网络; NoC; 可重构; 多核架构
中图分类号: TN47⁃34 " " " " " " " " " " " " " " 文献标识码: A " " " " " " " " " " " "文章编号: 1004⁃373X(2024)21⁃0001⁃06
Dynamically reconfigurable NoC⁃based multi⁃core architecture for MIMO detection
FAN Wenjie1, 2, ZHOU Muye1, 2, ZHU Lingxiao1, 2, LI Shiping3, CHEN Kai1, 3, DENG Songfeng4,
HE Guoqiang1, 3, FENG Shuyi4, SONG Wenqing1, 2, LI Li1, FU Yuxiang2
(1. School of Electronic Science and Engineering, Nanjing University, Nanjing 210023, China;
2. School of Integrated Circuits, Nanjing University, Suzhou 215163, China; 3. Jiangsu Huachuang Microsystems Co., Ltd., Nanjing 211899, China;
4. Shanghai Aerospace Electronic Technology Research Institute, Shanghai 201100, China)
Abstract: With the advancement of wireless communication technologies, achieving the optimal balance between the detection performance and complexity of multiple⁃input multiple⁃output (MIMO) systems is increasingly challenging. Deep learning (DL) offers a new direction for this. This paper presents a multi⁃core dynamic reconfigurable architecture based on network on chip (NoC). This architecture, termed MCDBP (multi⁃core architecture for dynamic baseband processing), strives to enhance the performance for DL⁃based MIMO detection algorithms and the architecture′s programmability and scalability. The MCDBP leverages integrated lightweight computing cores and NoC interconnects to process the fundamental operations of deep unfolded networks in parallel, such as vector⁃matrix multiplication (VMM), constant⁃vector multiplication (CVM), vector dot product (VDP), and vector addition (VA), so as to improve the performance of complex MIMO detection significantly. The innovation of the architecture lies in the reconfigurable design of the processing elements (PEs), and the architecture can be adjusted according to different DL⁃based MIMO detection algorithms dynamically. This design is grounded in a thorough analysis of the commonalities of DL⁃based MIMO detection algorithms, showcasing extreme flexibility in supporting multiple fundamental operational modes. Experimental results indicate that, in comparison with the general⁃purpose CPU, MCDBP can achieve an acceleration ratio of 12.66~22.98 when implementing DL⁃based MIMO detection algorithms. It can be seen that the performance of the algorithm is improved, so the algorithm can adapt to different application scenarios.
Keywords: wireless communication; MIMO detection; deep learning; data⁃driven network; model⁃driven network; NoC; reconfigurable; multi⁃core architecture
0 "引 "言
多输入多输出(Multiple⁃Input Multiple⁃Output, MIMO)系统通过利用时间、频率资源、多用户和多天线等多个维度,在当前的无线通信系统中实现了更高的性能和能效[1]。由于采用了多输入多输出处理技术,基站可以在蜂窝系统中同时发送或接收来自多个用户的数据。发射机和接收机配备了数十或数百根天线,这也使得MIMO系统的信号处理成为一项复杂的任务。
最佳联合MIMO检测问题是一个非确定性多项式时间难问题(NP⁃hard)[2]和非凸问题。文献[3]介绍了几种流行的多输入多输出检测算法。其中,最大似然(ML)检测器是最优检测器,但需要进行穷举搜索,计算时间随天线数量呈指数增长,因此在大型多输入多输出系统中部署不切实际。因此,人们更加关注性能可接受、复杂度低的近优检测器[3⁃7]。线性多输入多输出检测算法,如迫零(ZF)[3]、最小均方误差(MMSE)[3]等,复杂度较低,但通常需要复杂的矩阵求逆来确定检测器的系数,其性能受到限制。其他近优检测算法也存在问题,如当用户数量和调制阶数增加时,近似信息传递(AMP)的复杂性也会增加[4]。半正定松弛(SDR)算法[5]处理的符号映射有限,并且在实际应用中速度更慢。
近年来,深度学习(Deep Learning, DL)被应用于许多领域,并为多输入多输出检测带来了新方法。深度学习在多输入多输出检测中的应用可分为两类:数据驱动法和模型驱动法[8]。数据驱动法直接从大量数据中学习特征并训练网络[9⁃11],然而,这种方法面临着需要收集大量数据和训练时间密集等挑战;模型驱动法利用深度学习优化现有的未确定参数,或在现有模型中引入补充参数[12⁃15],在模型驱动法中需要深度学习的参数比数据驱动法少得多,从而减少了训练时间。
如今,为了适应无线通信技术的快速发展,不少针对特定MIMO检测算法设计的ASIC芯片被提了出来[16⁃19],以满足更短的执行时间、更低的延迟、更高的带宽和更低的能耗等需求。对于本文面向的基于DL的MIMO检测算法,由于采用深度学习方法训练的神经网络包含多个计算并行度,这使得多核片上互联网络(Network on Chip, NoC)成为一种合适的架构。NoC提供了充足的带宽,多核架构带来了远高于传统单核架构的计算能力,可以实现更低的MIMO检测延迟。另外,不同的MIMO检测方法有不同的优势、劣势,适合于不同的应用场景。为了使提出的架构更加灵活,适应不同的应用场景,本文采用可重构的处理单元(Processing Element, PE)设计。
本文提出的用于MIMO检测的基于NoC的多核动态可重构架构(Multi⁃core Architecture for Dynamic Baseband Processing, MCDBP)的主要贡献如下:
1) 采用多核NoC架构加速基于深度学习的MIMO检测网络的执行,通过利用这些网络中存在的并行度,与通用CPU相比,可以实现12.66~22.98的加速比。
2) 分析了不同模型驱动网络的共性,基于这些共性,提出一种可重构的处理单元设计,处理单元可以配置成不同的模式,以适应不同的应用场景。
1 "多输入多输出检测
1.1 "问题描述
考虑到一个有[N]个发射天线和[M]个接收天线的多输入多输出系统,发送符号向量写为[x∈CN×1]。可以得到接收信号[y]如下:
[y=Hx+n] (1)
式中:[H∈CM×N]是信道矩阵;[n∈CM×1]是加性高斯白噪声(Additive White Gaussian Noise, AWGN)。
在深度学习中,运算总是在实值域中进行的,因此考虑等效的实值表示如下:
[y=Hx+n] (2)
在式(2)中,实部和虚部被分开考虑,有[x=]
[RT(x),IT(x)T],[y=RT(y),IT(y)T],[n=RT(n),IT(n)T],
以及[H=R(H)-I(H)I(H)R(H)]。
为了从接收信号[y]中恢复信号[x],学者们提出了许多多输入多输出检测方法。线性多输入多输出检测算法,如迫零(ZF)[3]、最小均方误差(MMSE)[3],复杂度较低,但通常需要复杂的矩阵求逆来确定检测器的系数。当用户数量和调制阶数增加时,近似信息传递(AMP)等近似最优检测器的复杂度也会增加[4],半正定松弛(SDR)[5]处理的符号映射有限,而且在实际应用中速度更慢。
1.2 "基于深度学习方法
如今,随着越来越多的研究关注深度学习在多输入多输出检测中的应用,提出了许多基于深度学习的多输入多输出检测技术,这些技术可分为数据驱动法和模型驱动法两类。数据驱动法[9⁃11]直接从大量数据中学习特征并训练网络。根据通用近似定理,经过充分的数据训练后,神经网络有能力近似任何连续函数[20]。文献[9]构建了一个用于多输入多输出检测的全连接多层网络。文献[10]提出了三种用于多输入多输出检测的网络,分别是基于深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)。文献[11]利用带有监督训练的DNN解决了联合多输入多输出检测和信道解码问题。
模型驱动方法[9,12⁃15,21]使用深度学习来优化参数或在现有模型中添加一些参数,这些方法利用现有的数学模型对训练时间和数据集提出了更低的要求。通过巧妙地展开现有的迭代算法,模型驱动网络由许多相同的层组成,算法的迭代次数决定了网络的层数。例如,DetNet的结构就是通过将投影梯度下降算法的迭代展开成网络而获得的[9]。文献[21]将DetNet简化为稀疏连接神经网络,即ScNet。文献[12]基于文献[6]中提出的迭代算法构建了一个模型驱动网络。文献[13]基于非精确交替乘法(ADMM)算法[7],提出了非精确ADMM网络。JC⁃Net结构是通过展开阻尼雅可比检测器并为每层添加三个可训练参数而设计的[14]。GS⁃Net在现有高斯⁃赛德尔检测模型的基础上增加了一些可学习的参数,并展开了高斯⁃赛德尔检测方法的迭代过程[15]。
考虑到模型驱动方法结合了深度学习和传统数学模型的优点,对训练时间和数据集的要求较低,本文的工作主要集中在模型驱动方法的实现上。
2 "用于MIMO检测的可重构NoC设计
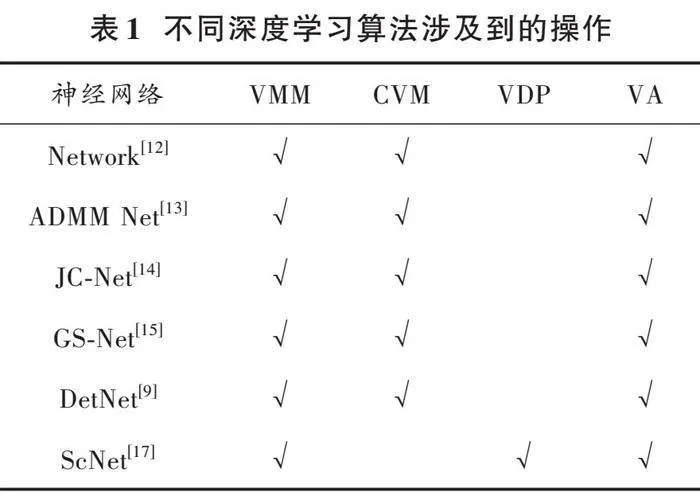
本节将介绍用于多输入多输出检测的可重构NoC架构MCDBP。该多核架构充分利用了基于深度学习的网络中的并行性维度,采用可重构处理单元设计,使所提出的架构更加灵活,能够适应不同的应用场景。不同的多输入多输出检测方法有不同的优点、缺点和应用场景,例如文献[12]中的网络针对多用户干扰消除进行了优化,而文献[13]中的网络可以解调高阶调制符号。本文总结了不同深度展开网络所涉及的操作,结果如表1所示。
从表1可以得出:矢量⁃矩阵乘法(Vector⁃Matrix Multiplication, VMM)、常数⁃矢量乘法(Constant⁃Vector Multiplication, CVM)、矢量点积(Vector Dot Product, VDP)、矢量加法(Vector Addition, VA)是大多数深度展开网络的基本运算,也就是说,这些网络可以分解为这四种基本运算。所有这些操作都涉及多个维度,因此可以并行化,并行化策略将在第2.2节中介绍。进一步细分,所有这些操作都由乘法和加法组成,这意味着它们都可以由乘累加单元(Multiplier and Accumulation, MAC)完成。基于这一观点,设计了下文所述的可重构处理单元,它可以配置为上述四种基本模式。
2.1 "可重构处理单元设计
可重构处理单元的可重构性体现在其内部结构和功能的动态可配置性。
1) 计算阵列的多模式配置:计算阵列由多个乘累加单元(MAC)构成,可根据需要进行控制,完成不同的计算任务。
2) 配置寄存器:通过配置寄存器,可在运行时调整处理单元的功能,以匹配特定的处理需求。
3) 后处理单元:处理单元完成计算后,后处理单元可以进行激活函数、量化处理等,其行为也可以根据需要进行配置,以支持不同的网络层需求。
4) 迭代计数器:通过设置迭代计数器的迭代次数,以适应不同深度展开网络的网络层数需求。
可重构处理单元的基本结构如图1所示。
可重构处理单元的主要组件包括:
1) 输入缓冲区:用于存储输入激活。
2) 计算阵列:完成乘积计算,并可配置为不同模式,计算阵列的基本单元是一组MAC。
3) 配置寄存器:存储配置参数,控制计算阵列的模式,并完成整体时序控制。
4) 迭代计数器:记录迭代次数,当迭代计数器达到设定的层数时,计算终止。
5) 权重缓冲区:用于存储权重。
6) 后处理单元:负责完成每轮计算的后处理操作,如截断和激活函数。
7) 网络接口:完成路由包的打包和解包。
对于深度展开网络,将其分解为基本操作,每个操作将映射到一组处理单元上。这些处理单元将根据配置寄存器的设置配置计算阵列的模式。映射过程将在第2.2节中讨论。
2.2 "模型驱动网络的映射算法
本节介绍将模型驱动的多输入多输出检测网络映射到NoC平台的过程,并介绍本文使用的映射算法。
从第1.2节的介绍中可以了解到,模型驱动网络通常基于现有的迭代算法,这意味着模型驱动网络中的不同层具有相同的架构。可以将网络的不同层映射到相同的处理单元上,以时分复用的方式完成整个网络的计算,即只需将一层映射到NoC平台的处理单元上,然后迭代利用这些处理单元完成其他各层的计算。每个处理单元将负责该层的一个基本操作。要开始下一层的计算,产生输出的处理单元需要将输出传送给接收输入的处理单元,不同操作之间的依赖关系构成了不同处理单元之间的数据流。
图2展示了将文献[12]中提出的网络映射到NoC平台的示例,图2a)展示了文献[12]中提出的网络一层的流程图。图2b)将原始模型转换为基本操作,原始模型可细分为9个基本操作。在图2c)中,图2b)中的基本操作被映射到处理单元上,每个处理单元下的数字与图2b)中的操作相对应。
在并行化策略方面,采用输出并行策略。不同配置模式下的并行维度如下:
//矢量⁃矩阵乘法PE级
parallel_for p1=[0:P1):
//矢量⁃矩阵乘法MAC级
for p2=[0:P2):
parallel_for p3=[0:P3):
for k=[0:K):
p=(p1*P2+p2)*P3+p3;
O[p]+=I[k]*W[k,p];
//矢量点积PE级
parallel_for p1=[0:P1):
//矢量点积MAC级
for p2=[0:P2):
parallel_for p3=[0:P3):
p=(p1*P2+p2)*P3+p3;
O[p]=I1[p]*I2[p];
//矢量加法PE级
parallel_for p1=[0:P1):
//矢量加法MAC级
for p2=[0:P2):
parallel_for p3=[0:P3):
for k=[0:K):
p=(p1*P2+p2)*P3+p3;
O[p]+=Ik[p];
//常数⁃矢量乘法PE级
parallel_for p1=[0:P1):
//常数⁃矢量乘法MAC级
for p2=[0:P2):
parallel_for p3=[0:P3):
p=(p1*P2+p2)*P3+p3;
O[p]=C*I[p];
对于PE级,不同的输出将在不同的PE中同时计算。对于MAC级,在每个PE中,MAC阵列将以组内串行、组间并行的方式计算输出。
与传统的神经网络映射问题相比,模型驱动网络映射问题更为复杂,其产生输出的处理单元仍需将输出传送给接收输入的处理单元,不同操作之间的依赖关系会产生类似ResNet的残差连接。如何找到一个能带来低通信延迟的良好映射是一个更大的挑战。在这项工作中,本文基于文献[22]中提出的GAMMA算法进行映射,这是一种基于遗传算法(GA)的方法,专门针对硬件映射问题而设计。
3 "实验结果
3.1 "实现细节
本节将提供所提出的可重构NoC平台在不同模型下的实验结果。本文的仿真是基于CNN⁃Noxim[23]进行的,这是一种基于NoC的周期精确卷积神经网络仿真器。本文修改了CNN⁃Noxim中的处理单元模块,以支持模型驱动网络中的上述四种基本操作。同时,采用了2.2节中介绍的映射策略,以减少NoC中的通信延迟。
不同操作类型的处理单元有不同的计算时间。VMM的计算时间见式(3)。CVM、VDP和VA的计算时间见式(4)。
[TVMM=Nin×Nout+NMAC-1NMAC+Nout+NMAC-1modNMAC+1] (3)
[Tother=Nout+NMAC-1NMAC+Nout+NMAC-1modNMAC+1] (4)
式中:[Nin]代表输入维度的长度;[Nout]代表输出维度的长度;[NMAC]代表计算阵列中的MAC数量。
表2列出了配置参数。其中,分组规模决定了[Nout]的最大值。
3.2 "性 "能
将文献[12]中的网络、ADMMNet[13]和DetNet[9]三种模型驱动网络映射到NoC平台,使用的MIMO规模为32×32,比较这些网络的总执行时间。
将MCDBP与CPU的性能进行对比。CPU的算力为486.4 GFLOPs,多核架构MCDBP对应的算力为1 TOPs,表3显示了三个神经网络的实验结果。与CPU相比,多核架构MCDBP在文献[12]提出的网络中可以实现12.66的加速比,在ADMM网络中可以实现14.65的加速比,在DetNet中为22.98。从图中可以得出另一个结论,DetNet比其他模型驱动网络更耗时,这是由于DetNet的架构更为复杂。
3.3 "资源开销
对可重构处理单元进行了硬件实现,使用Synopsys Design Compiler在28 nm工艺下进行了综合,最终得到在1 GHz的频率下面积为0.047 mm2、功耗为9.95 mW,8×8的MCDBP多核架构的面积为3.563 mm2,功耗为0.724 W。
4 "结 "语
本文重点讨论了模型驱动多输入多输出检测网络的硬件加速问题,利用这些网络中的并行维度将它们配置到多核NoC架构MCDBP中。分析了不同模型驱动网络的共性,基于这些共性,提出了一种可重新配置的处理单元设计,以适应不同的应用场景。与通用CPU相比,本文提出的架构可以实现12.66~22.98的加速比。
注:本文通讯作者为傅玉祥、李丽、宋文清。
参考文献
[1] GOLDSMITH A, JAFAR S A, JINDAL N, et al. Capacity limits of MIMO channels [J]. IEEE journal on selected areas in communications, 2003, 21(5): 684⁃702.
[2] VERDÚ S. Computational complexity of optimum multiuser detection [J]. Algorithmica, 1989, 4(3): 303⁃312.
[3] ALBREEM M A M, JUNTTI M J, SHAHABUDDIN S. Massive MIMO detection techniques: A survey [J]. IEEE communications surveys amp; tutorials, 2019, 21(4): 3109⁃3132.
[4] ZENG J, LIN J, WANG Z F. Low complexity message passing detection algorithm for large⁃scale MIMO systems [J]. IEEE wireless communications letters, 2018, 7(5): 708⁃711.
[5] LUO Z Q, MA W K, SO A M C, et al. Semidefinite relaxation of quadratic optimization problems [J]. IEEE signal processing magazine, 2010, 27(3): 20⁃34.
[6] MANDLOI M, BHATIA V. Low⁃complexity near⁃optimal iterative sequential detection for uplink massive MIMO systems [J]. IEEE communications letters, 2017, 21(3): 568⁃571.
[7] BOYD S P, PARIKH N, CHU E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers [J]. Foundations and trends in machine learning, 2011, 3(1): 1⁃122.
[8] YANG S S, HANZO L. Fifty years of MIMO detection: The road to large⁃scale MIMOs [J]. IEEE communications surveys amp; tutorials, 2015, 17(4): 1941⁃1988.
[9] SAMUEL N, DISKIN T, WIESEL A. Learning to detect [J]. IEEE transactions on signal processing, 2019, 67(10): 2554⁃2564.
[10] BAEK M S, KWAK S, JUNG J Y, et al. Implementation metho⁃dologies of deep learning⁃based signal detection for conventional MIMO transmitters [J]. IEEE transactions on broadcas⁃ting, 2019, 65(3): 636⁃642.
[11] WANG T T, ZHANG L H, LIEW S C. Deep learning for joint MIMO detection and channel decoding [C]// 30th IEEE Annual International Symposium on Personal, Indoor and Mobile Radio Communications. New York: IEEE, 2019: 1⁃7.
[12] LIAO J Y, ZHAO J H, GAO F F, et al. A model⁃driven deep learning method for massive MIMO detection [J]. IEEE communications letters, 2020, 24(8): 1724⁃1728.
[13] KIM M, PARK D. Learnable MIMO detection networks based on inexact ADMM [J]. IEEE transactions on wireless communications, 2021, 20(1): 565⁃576.
[14] CAO Q, LI F, LI T, et al. Adaptive signal detection method based on model⁃driven for massive MIMO systems [C]// 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP). New York: IEEE, 2021: 1⁃5.
[15] WANG Q, HAI H, PENG K Z, et al. A learnable Gauss⁃Seidel detector for MIMO detection [C]// 2020 IEEE/CIC International Conference on Communications in China (ICCC). New York: IEEE, 2020: 107⁃111.
[16] HAN K N, HU J H, CHEN J N, et al. A high performance massive MIMO detector based on log⁃domain belief⁃propagation [C]// 2015 IEEE 11th International Conference on ASIC (ASICON). New York: IEEE, 2015: 1⁃4.
[17] LI Z Q, LIN L Y, CHEN Y, et al. Implementation of a pipeline division⁃free MMSE MIMO detector that support soft⁃input and soft⁃output [C]// 2017 23rd Asia⁃Pacific Conference on Communications (APCC). New York: IEEE, 2017: 1⁃5.
[18] SUIKKANEN E, JUNTTI M J. ASIC implementation and performance comparison of adaptive detection for MIMO⁃OFDM system [C]// 49th Asilomar Conference on Signals, System and Computers. New York: IEEE, 2015: 1632⁃1636.
[19] ATTARI M, SÁNCHEZ J R, LIU L. A floating⁃point 16 × 16 SVD accelerator for beyond⁃5G large intelligent surfaces [C]// IEEE 66th International Midwest Symposium on Circuits and Systems (MWSCAS). New York: IEEE, 2023: 967⁃971.
[20] CYBENKO G. Approximation by superpositions of a sigmoidal function [J]. Mathematics of Control, Signals, and Systems, 1989, 22(2): 303⁃314.
[21] GAO G L, DONG C, NIU K. Sparsely connected neural network for massive MIMO detection [C]// 2018 International Conference on Innovative Computing and Cloud Computing. [S.l.: s.n.], 2018: 397⁃402.
[22] KAO S C, KRISHNA T. GAMMA: Automating the HW mapping of DNN models on accelerators via genetic algorithm [C]// Proceedings of the 39th IEEE/ACM International Conference on Computer⁃aided Design. New York: IEEE, 2020: 1⁃9.
[23] CHEN K C J, WANG T Y. NN⁃Noxim: High⁃level cycle⁃accurate NoC⁃based neural networks simulator [C]// 2018 11th International Workshop on Network on Chip Architectures (NoCArc). New York: IEEE, 2018: 1⁃5.
作者简介:范文杰(2000—),男,江苏南京人,硕士研究生,研究方向为集成电路设计。
周牧也(1998—),男,江苏连云港人,硕士研究生,研究方向为集成电路设计。
朱凌晓(2000—),男,江苏南通人,硕士研究生,研究方向为集成电路设计。
李世平(1987—),男,安徽安庆人,研究员级高级工程师,研究方向为集成电路设计。
陈 "铠(1979—),男,江苏南京人,高级工程师,研究方向为集成电路设计。
邓松峰(1979—),男,山东青岛人,研究员,研究方向为星上数据处理。
何国强(1977—),男,江苏常州人,研究员级高级工程师,研究方向为集成电路设计。
冯书谊(1984—),男,湖南岳阳人,研究员,研究方向为遥感图像处理。
宋文清(2000—),女,山东泰安人,博士研究生,研究方向为集成电路设计。
李 "丽(1975—),女,黑龙江双鸭山人,教授,研究方向为集成电路设计。
傅玉祥(1990—),男,江苏南京人,博士研究生,副教授,研究方向为集成电路设计。
猜你喜欢
摄影世界(2022年1期)2022-01-21 10:50:14
净水技术(2022年1期)2022-01-13 00:45:28
中学生数理化·高一版(2021年11期)2021-09-05 12:21:24
科技资讯(2021年10期)2021-07-28 04:04:53
环境卫生工程(2021年3期)2021-07-21 05:34:36
广东通信技术(2020年7期)2020-08-13 06:01:42
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
商周刊(2017年6期)2017-08-22 03:42:36
山东大学法律评论(2016年0期)2016-08-16 03:24:12
现代防御技术(2016年1期)2016-06-01 12:13:28
