
基于词模式规则的轻量级日志模板提取方法
2024-11-02 00:00:00顾兆军张智凯刘春波叶经纬
现代电子技术 2024年21期








摘 "要: 传统基于规则的日志解析方法针对每类日志需单独编写规则,且随着系统更新,出现新的日志模式时,需人工再次干预;基于深度学习的日志解析方法虽准确率高,但计算复杂度高。为解决日志解析方法人力成本和计算复杂度高的问题,文中提出一种基于词模式规则的轻量级日志模板提取方法,该方法由初始规则集生成、词模式规则应用、潜在错误样本发掘三个部分构成。首先,原始日志基于自适应随机抽样获取彼此间相似度较低的代表性日志;然后,基于专家反馈提取初始词模式规则集,在词模式规则应用模块对原始日志进行处理并提取日志模板;最后,在潜在错误样本发掘模块检查生成的日志模板聚类,发现潜在的错误分类样本并对其进行规则集更新。经过实验验证,在16个公开日志数据集上,文中方法的平均准确度达到97.8%,与基于深度学习的日志解析算法准确度基本持平;在计算效率方面,文中方法的单线程解析速度达到每秒20 000条,且随着可用内核数量的增加,性能持续提升,满足系统日志的故障诊断和安全分析需求。
关键词: 日志解析; 模板提取; 词模式规则; 正则匹配; 启发式策略; 规则集
中图分类号: TN911⁃34; TP391 " " " " " " " " " "文献标识码: A " " " " " " " " " " 文章编号: 1004⁃373X(2024)21⁃0156⁃09
Lightweight log template extraction method based on word pattern rules
GU Zhaojun1, ZHANG Zhikai2, LIU Chunbo1, YE Jingwei2
(1. Information Security Evaluation Center, Civil Aviation University of China, Tianjin 300300, China;
2. College of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China)
Abstract: In the traditional rule⁃based log parsing methods, writing of separate rules for each type of logs is required. With the update of the system, new log patterns appear, and the manual intervention is needed again. The log parsing methods based on deep learning, however, have high accuracy but high computational complexity. In view of the above, a lightweight log template extraction method based on word pattern rules is proposed to reduce the high human cost and computational complexity. This method consists of three parts, including initial rule set generation, word pattern rule application, and potential error sample discovery. On the basis of the adaptive random sampling, the original logs obtain representative logs with low similarity among each other. Then the initial word pattern rule set is extracted based on expert feedback. The original logs are processed and log templates are extracted in the word pattern rule application module. The generated log templates are examined for clustering in the potential error sample discovery module, so as to find out the potential misclassified samples and update the rule set. After experimental verification, the average accuracy of the proposed method reaches 97.8% on 16 public log datasets. The average accuracy is basically the same as that of the log parsing algorithms based on deep learning. In terms of computational efficiency, the single⁃threaded parsing speed of the proposed method reaches 20 000 entries per second, and its performance continues to improve with the increase of the number of available cores. To sum up, the proposed method can meet the demand of fault diagnosis and safety analysis of system logs.
Keywords: log paring; template extraction; word pattern rule; regex match; heuristic strategy; rule set
0 "引 "言
近年来,智能运维[1](Artificial Intelligence for IT Operations, AIOps)兴起,日志分析仍然是追溯问题的重要证据[2]。日志是丰富的信息来源,同时日志作为审计材料在软件系统中普遍可用,适合用于支持运维工作。然而,随着软件系统的复杂性增加,日志数据的体积往往呈现庞大的趋势。据微软报告[3]显示,仅微软内部某项服务每天平均产生约50亿条日志,相当于每小时产生约2亿条。庞大的数据量使得人工检查和分析日志文件变得不切实际。因此,自动化的日志分析方法变得流行,并被应用于异常检测[4]、故障诊断[5]、系统理解[6]以及用户行为分析[7]等领域。
日志解析是日志分析的关键步骤,其目标是对原始日志数据进行清理,实现非结构化日志数据的结构化和向量化。庞大的日志数据量对日志解析算法的运行性能提出了要求,现代软件系统通常采用流式处理数据的方式,将来自系统内各个组件的日志汇总至日志平台进行进一步分析。如果解析算法的处理速度不能跟上日志产生的速度,那么基于日志的实时异常检测、故障预测等任务将难以顺利进行。从另一个角度来说,更高性能的轻量级日志解析算法在同等计算资源下提供了将更多系统组件日志纳入统一的日志分析平台的可能性,更丰富的信息来源使得下游任务能够更加深入地分析系统组件之间的复杂关系。
目前日志解析方法多是基于日志模板规则,即通过正则表达式匹配整个日志模板进行日志解析,如Grok过滤器技术[8]。这类方法的问题是,每项Grok过滤器规则对应一类日志模板,这意味着对于包含大量异构日志事件类型,并且在持续更新的现代软件系统中,Grok规则库持续膨胀,难以维护和扩展。其次,每项新增的Grok规则都会导致额外一次对整个日志行的正则匹配,如果存在大量的规则,将会显著拖慢解析器的整体运行效率。
故多位学者提出了基于预定义的启发式规则的日志解析方法,首先发现日志数据中的固有特征,再利用特征进行模板提取,以用于日志分析。基于频繁词统计的SLCT(Simple Log Cluster Tool)认为在日志文件中出现次数较多的词是常量,此方法在初步解析中有效,但难以识别出频率低、罕见的日志模板[9]。LFA(Log File Analyzer)考虑词的位置进行统计[10],Logram则采用n⁃gram类方法作为统计指标,从而将词的上下文信息纳入考虑[11]。IPLoM(Iterative Partition Log Mining)提出了迭代划分的思路,通过基于日志长度和词的位置特征不断将日志划分为小的聚类[12]。Drain是近年来广泛使用的日志解析算法,它是基于日志的前缀解析树,本质是迭代划分算法的树形表达[13]。Prefix⁃Graph将从前缀树扩展出的概率图结构应用于日志解析[14]。PosParser从自然语言处理领域的触发词概念中获得启发,将日志中词的词性作为常变量判别的依据之一[15]。随着深度学习技术的发展,深度学习技术从标注的日志数据集中学习日志的常/变量特征,在日志解析中也有良好的表现。其中,UniParser是基于对比学习策略的LSTM网络[16],用于进行日志的上下文编码,而LogPPT则直接利用RoBERTa网络进行日志序列的特征提取[17]。
上述方法均未在准确率和运行效率上达到理想平衡,本文提出了利用细粒度启发式规则解析日志的一种新模式,基于数字特征的常/变量判别策略作为基础,根据日志特征生成少量正则表达式,将匹配范围从整条日志缩小到数个关键性的词,从而高效构造日志模板,在此基础上实现了基于词模式规则的轻量级日志模板提取方法。
1 "日志解析问题描述
日志解析是通过分析日志数据,推断出生成日志的源代码输出语句的格式[18]。图1是典型的日志解析过程。一条日志中的内容分为两类:一类是静态内容,即固定在源代码中的词,这些词构成的句子被称为日志模板,用于描述某些系统事件,这类词被称为日志常量;另一类是动态内容,即在源代码中使用通配符表示的词,它们随着程序运行状态变化而变化,被称为日志变量。
对于一组日志输入[L={l1,l2,…,ln,…,lN}],其中,[n∈[1,N]],记映射[T(ln):L→T]将日志[li]映射至其真实日志模板,其中[T={t1,t2,…}]为该组日志输入[L]所涉及的全部日志模板;日志解析算法[P(l):L→P]将[L]映射到类别集合[P]上,其中[P={p1,p2,…}]为解析算法[P(l)]在日志输入[L]下产生的所有日志模板分类。
[P]与[T]之间的关系可用二分图[G=(V,E)]表示,其中顶点集[V]是[P]与[T]的并集,即[G=({P,T},E)];边集[E]有如下定义:
[E=px,tyP(l)=px, T(l)=ty, ∀l∈L] (1)
记[G]的全部[I]个极大连通子图为[{G1,G2,…,Gi,…,GI}],对于任一极大连通子图[Gi=({Pi,Ti},Ei)],有如下五种情况。
1) [Pi=1且Ti=1],代表日志解析产生的某类别与某日志模板严格对应,该类别包括且仅包括全部某一日志模板下属日志,代表日志解析算法正确分类了该类日志;
2) [Pi=1且Tigt;1],日志解析产生的某一类别与多个实际日志模板对应,说明日志解析粒度过粗,一部分日志处于欠分类状态;
3) [Pigt;1且Ti=1],日志解析产生的多个类别与同一日志模板对应,说明日志解析粒度过细,一部分日志处于过分类状态;
4) [Pigt;1且Tigt;1],说明日志解析算法在涉及到的日志子集上分类失败,解析结果基本不具备任何参考价值,分类是混乱的;
5) [Pi=0且Ti=1],说明对于某部分日志,解析算法未能产生解析结果,此时称解析算法是不完全的。一些早期的日志解析算法会具备这类不良性质,本文中不做过多讨论。
从分类意义上讲,日志解析的目的是找到一种映射[P′(l):L→P′],使得[P′]与[T]所成关系图[G]的每一极大连通子图[G′i=({P′i,Ti},E′i)],均有[P′i=1且Ti=1]。
2 "轻量级日志模板提取方法
2.1 "方法概述
基于词模式规则的轻量级日志模板提取方法的总体框架如图2所示,由自适应随机抽样与初始规则集生成、词模式规则应用、潜在错误样本发掘与规则集更新三个部分构成。图2中用实线箭头表示算法的离线训练流程,虚线箭头表示算法的在线解析流程。首先,基于最长公共子序列(Longest Common Sequence, LCS)和特殊符号相似度对原始日志进行抽样,获取日志间相似度最低的代表性日志;然后,基于专家反馈或大语言模型在代表性日志集中提取基本的词模式规则,并由规则处理模块对原始日志进行处理并提取日志模板;最后,基于模板相似度(Template Similarity, TS)和变量词频统计(Variable Frequency, VF)两类启发式规则检查生成的日志模板聚类,发现潜在的错误分类样本并将其送回产生词模式规则。算法迭代执行直至规则集不再发生变化,此时算法的训练步骤宣告结束,最终产生的规则集被应用于整个原始日志数据集上,进行高效的日志解析。
2.2 "代表性日志抽样模块
为了产生词模式规则使用的关键性词模式信息,提出一种代表性日志抽样算法。
首先,使用通用分隔符对日志进行分词;其次,按日志行中包含词的数量与日志中的特殊符号集合对所有日志进行初步分类;然后,对于产生的每个日志簇,使用自适应随机测试[17]中的自适应随机抽样算法获得多样且分布均匀的样本集。算法1描述了基于自适应随机抽样的代表性日志抽样算法。
算法1以原始日志数据集[D]和采样数量[K]为输入。在第1行,[D]中所有的日志项被处理为(日志长度,日志中所有特殊符号集合,原始日志)的三元组。第2行创建一个集合[Drep]作为算法的结果,初始化为空。在第3~21行,每次循环中算法基于与[Drep]已有元素的相似度迭代地抽样新的日志项,直至[Drep]拥有[K]个日志项。在第4~7行,算法以日志长度和日志中的特殊符号为线索,从[L]中选取[η]个候选日志储存在[C]中。随后在第8~17行,对于[C]中的每个候选者,算法计算它与[Drep]最相近元素的相似度。在第18、19行,根据上述计算结果,算法选择[C]中与已有元素距离最远的日志项加入采样集[Drep]。
Algorithm 1: 代表性日志抽样算法
Data:[D],日志数据集;[K],采样数量
Result:[Drep],[K]条抽样日志集合
1 /* [L={len,punc,orig}]:日志长度,符号集合,原始日志 */
2 [L←process(D)];
3 /* 初始化采样集 */
4 [Drep←∅];
5 while [K]gt;1 do
6 /*初始化候选集*/
7 " [C←{random c∈L∣c.len∉Drep or c.punc∉Drep};]
8 " for [i=1←η] do
9 " " "[C.add({random c∈L∣c.len∈C and c.punc∈C});]
10 "end
11 "/* 计算[C]中日志与[Drep]的相似度 */
12 "[Δ←∅];
13 "for each [c∈C] do
14 " " [δ←0;]
15 " " "/*搜索[c]在[Drep]中的最近邻,并计算两者间相似度*/
16 " " for each [l∈Drep] do
17 " " " [δ←MAX(δ,similarity(c.org,l.org));]
18 " " end
19 " " [Δ.add(δ);]
20 "end
21 "/*选择与[Drep]中最近邻拥有最远距离/最小相似度的候选者加入采样集*/
22 "[Drep.add{c∈C∣Δc is smallest};]
23 "[K←K-1;]
24 end
25 return [Drep];
2.3 "词模式规则处理模块
本文提出以基于数字特征的常/变量判别策略作为基础,将算法所需的知识输入策略分为三类,即非数字变量判别、含数字常量判别、分隔符指定。
2.3.1 "过滤含数字词
算法使用基于数字特征的常/变量判别策略作为基础。为了与后续三类额外策略相适应,同时处理部分边缘情况,将过滤规则设定如下:
1) 词(token)不能包含任何数字字符;
2) 词不能完全由a~f组成,即不能是十六进制数;
3) 词不能只包含一个符号字符;
4) 词不是变量被替换产生的通配符。
基础策略无法处理如下两类特殊词。
不含数字的变量:
Invalid user test from 52.80.34.196
包含数字的常量:
ARPT: 7915: wl0: MDNS: IPV4 Addr: lt;Addrgt;
ARPT: 6289: wl0: MDNS: IPV6 Addr: lt;Addrgt;
2.3.2 "非数字变量判别
通过词所在的上下文可以有效地区分不包含数字的变量,例如现有深度学习方法从大量标注数据中学习常/变量所在的不同上下文特征。本文方法使用抽样算法和反馈步骤从大量未标注日志中筛选出潜在包含该类情况的日志样例,基于专家知识或大语言模型生成正则表达式匹配所需的上下文信息。在基础策略的基础上,非数字变量判别解决了日志解析的过分类问题。
2.3.3 "含数字常量判别
对于判别日志中的常量,更关注其高精确率,而对召回率的要求较低。如2.3.1节特殊词,即使忽略词“IPV4”,根据剩余的常量三元组(ARPT:, MDNS:, Addr:),算法仍然可以正确地区分该类日志与其他类别的日志。但从更细粒度的角度上看,此时无法区分IPV4事件和IPV6事件。另一方面,见如下常量判别策略实例,端口名“alt0”具有明显的变量特征,但有时运维人员根据实际业务需求,需要将来自不同接口的网络连接视为不同的日志类型,故将某种机制“alt0”指定为常量。含数字常量判别作为补充,解决了上述两类日志解析中的欠分类情况。
原始日志
…… available network connection on network 172.16.0.0/16 via interface alt0
…… available network connection on network 10.0.0.0/8 via interface wlan42
现有的一部分日志解析方法类似地采用正则替换作为预处理步骤。本文方法的目标更有针对性,不再是宽泛的“为算法输入领域知识”,并为如何高效展示这类知识提供了指导性步骤。
2.3.4 "分隔符指定
算法从词的模式角度对日志进行常/变量判别。因此,需要更加深入地探究分词技术的优化,以提高日志解析的准确性和效率。分词对解析的影响如下:
StackScroll: overlapAmount:220.0
StackScroll: state.clipTopAmount:204
如上两类日志,若不使用冒号作为分词符号,则每条日志将会被分隔成两个词。然而,由于后两个词中都包含数字,基础策略无法考虑这些词,两类日志将被映射到同一组“StackScroll”,无法被区分。相反,如果使用冒号作为分词符号,两类日志能够分别映射到“StackScrolloverlapAmount”和“StackScrollstate.clipTopAmount”,算法可以准确区分这两类日志。
代表性日志抽样算法中设计了基于日志包含符号集的自适应随机抽样,能够多样化地抽取特殊符号样例,为规则产生模块识别上下文并选取分词符提供线索。
因不同系统日志格式差异大,即使是基于大量多种日志数据集训练的神经网络模型,也难以保证在新数据集上不进行微调即可使用[16]。采用以上三类额外策略,旨在将原始日志尽可能地转化为更具格式化的形式。词模式规则处理示例如图3所示。
图3中:①分词算法应当认识到在tty.NODEVssh中和在25.4.0.6中,“.”的概念并不同;②变量处理算法通过获取其上下文特征判别NODEVssh这类变量;③尽管alt0具有明显的变量特征,有时出于实际的业务需求要将其视为常量,算法提供了这样的机制;④与Drain那样在一棵树上查找目标日志所在聚类的方法不同,规则处理模块直接使用日志模板作为键值,将目标日志映射至其在散列表中的聚类。
2.4 "启发式规则反馈
规则处理模块根据词模式规则集处理日志数据,生成日志模板及其聚类,所有出现在日志模板中的词构成了日志数据的常量集,其他未出现的词构成日志数据的变量集。算法针对生成的日志模板进行潜在错误分类样本的发现及反馈,分为两个方面。
1) 基于词频统计的潜在常量识别:算法统计全体日志集[L]中每个词的出现频率。当发现某个词的出现频率过高且不出现在常量集中时,算法会重新抽样其所在聚类,并形成新的代表性日志集。这些新的代表性日志会重新输入至规则产生模块,产生新的数字常量识别规则,在新一轮的迭代中发现潜在的欠分类样本。
2) 基于最长公共子序列(Longest Common Sequence, LCS)的潜在变量识别:若归属于某一日志模板的变量被错误地划分为常量,则可能产生数个高度相似的日志模板。算法利用最长公共子序列计算生成的日志模板之间的相似度,当相似度超过设定阈值时,算法标记这些模板为潜在的过分类样本。对于这些相似的模板,算法分别在它们所在的聚类中重新抽样形成代表性日志集,由规则产生模块生成新的非数字变量识别规则。
规则反馈模块通过循环迭代方式来优化规则集,使其能够更好地适应系统的变化和日志数据的演化,从而提升运维人员在日志分析和故障排查方面的效率和准确性。
3 "实 "验
3.1 "数据集及实验环境
在LogPai团队[19]提供的16个日志数据集上开展实验,评估算法的有效性和效率。数据集涵盖分布式系统(HDFS、Hadoop、Zookeeper、OpenStack、Spark),超级计算机(BGL、HPC),客户端应用(Proxifier、Thunderbird),服务器应用(Apache、OpenSSH),移动应用(HealthApp),操作系统(Windows、Linux、Mac、Andriod)。对于每类数据,LogPai团队采样了2 000条具有代表性的日志并进行了人工标注。
实验在一台AMD Ryzen™ 7 5800H 3.2 GHz处理器的PC机和一台搭载两块Intel® Xeon® Silver 4210R 2.40 GHz处理器的服务器上进行。Ryzen 7 5800H处理器拥有8颗物理核心,每块Silver 4210R处理器拥有10颗物理核心。
3.2 "评价指标
在日志解析领域,常用组准确率(Group Accuracy, GA)来评估解析结果的质量,GA是日志解析领域被广泛采用的评价指标,它是指有多大比例的日志被正确解析了。GA定义为:
[GA=i=0nI(Gi)*Count(T1i)L] (2)
式中:[L]为数据集中日志的总数;[T1i]表示[Ti]的首元素,在公式所限定的条件下也是[Ti]唯一的元素;示性函数[I(Gi)]指示[G]的某一最大连通子集是否代表一类正确分类情况。
[I(Gi)=1, " " Pi=1且Ti=10, " " 其他] (3)
组准确率认为一个聚类是被正确分类的,要满足以下两个条件:
1) 该聚类中的所有日志属于且只属于实际数据中的一个类别;
2) 该聚类和实际数据中对应的类别具有相同数量的日志。
换言之,该聚类和实际数据中的某一类别在集合意义上完全相等。根据这一定义,同一实际类别中的所有日志共享正确性,因此被称为组准确率。
在运行效率测试阶段,使用百万行量级的HDFS日志数据对算法进行速度测试。通过这个大规模数据集的测试,全面评估算法在处理大型日志数据时的运行效率和性能表现。五种日志解析方法在不同数据集上的组准确率比较如表1所示。
3.3 "解析精度对比实验
在所有16个数据集上比较了本文算法与下述4种先进日志解析算法的解析精度。
1) Drain[14]:基于前缀树对日志进行解析,是当前热门的被广泛应用的解析算法,准确率、速度、稳健性各个方面的性能都备受认可。
2) PosParser[16]:来源于自然语言处理领域的触发词概念,以日志中词的词性为线索提取功能词序列作为特征表示,克服了Drain在处理变长日志问题上的不足。
3) UniParser[17]:采用了基于对比学习策略的LSTM网络,学习日志中常量与变量不同的上下文特征;与一般的NLP问题做法不同,UniParser使用了字符级的分隔符嵌入,这种技术更贴合日志数据的特点。UniParser是一种预训练模型,期望能够在一部分有标注的日志数据集上训练,并将经验迁移至未知数据集。
4) LogPPT[18]:LogPPT使用RoBERTa模型作为网络的主干。与UniParser不同,LogPPT提出了基于预训练的小样本学习策略,将注意力集中在当获得未知数据集时,如何有针对性地从数据集中采样并标注少量具有代表性的日志数据,对网络进行重训练以提高在新数据集上的性能。
UniParser在公开日志数据集上做预训练,并直接应用于目标日志;LogPPT利用预训练的自然语言模型,并在目标日志数据集上做少量标注,做小样本的重训练;而本文算法没有预训练过程,但需要人工在目标日志上给出更高程度抽象的“标注”。
表1中的实验结果表明,本文方法能够达到与基于现代神经网络的日志解析方法相近的解析精度,这一结果证明了通过人工给出少量预处理规则来提高日志解析性能这一策略的有效性。与启发式日志解析方法PosParser对比,在Mac数据集和OpenSSH数据集上的性能提升也证明了本文所提出的使用少量预设规则来补充启发式算法的必要性。
需要注意的是,本文算法在Linux数据集上表现不佳。这是因为在数据集中,工具包提供的真实情况(ground truth)存在标注错误。为了与其他方法公平对比,没有直接进行修正。但值得一提的是,通过特殊常量指定机制,能够获得与真实情况相符的结果,但在上述实验中并没有使用。
3.4 "运行效率对比实验
本文算法在进行日志解析时,并不需要过多依赖其他数据或者上下文信息,因此具有良好的并行特性,能够充分发挥现代多处理器技术的优势。这些特征使得执行效率方面相较于其他日志解析算法具有显著的优势。
图4展示了本文算法使用不同数量的计算核心在一千万量级的日志数据下的性能表现,随着计算核心数量的增加,算法的处理速度得到了提升。
在实验所涉及的两类现代处理器上,每颗物理核心可以拥有两个超线程,但由于实验是基于Python语言的简单验证,全局解释器锁的限制导致Python解释器无法充分利用超线程,造成Ryzen 7 5800H处理器在核心数量8~16、Silver 4210R处理器在核心数量20~40处,算法性能没有展现出应有的线性提升。如果只考虑物理核心,算法表现出近似线性加速比的并行性能。
算法的运行时间由目标日志数据集中日志的平均长度和使用正则表达式的数量共同决定。日志平均长度决定运行时间的基准,每条额外的正则表达式使算法对日志多遍历一次,运行时间与两者的乘积成线性关系,如图5所示。
由于算法结构上的轻量性和并行性,本文算法在运行效率上远优于其他方法。表2展示了在百万量级的HDFS日志数据集上与其他算法的运行效率对比,其中OurMethod⁃[n]([n]=1、20)指算法使用[n]个线程并行。实验在Silver 4210R处理器上进行。
几种解析算法在百万条日志数据集上的运行时间对比实验结果如表2所示。
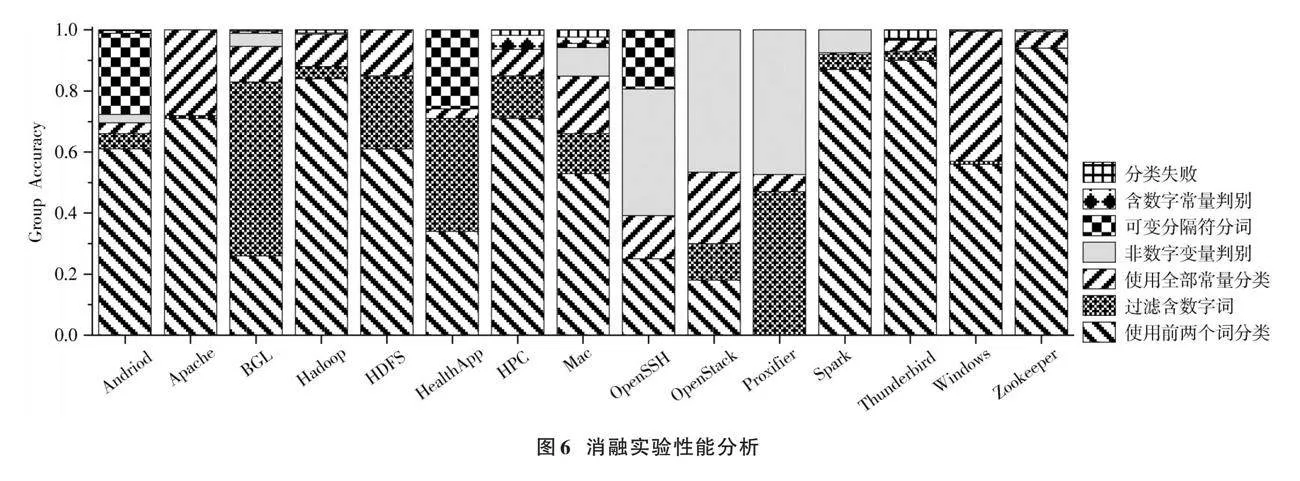
3.5 "消融实验
由于Linux数据集存在一些标签标注错误的问题,实验在剩余15个日志数据集上进行;使用组准确率作为评价指标。为了更清楚地说明,下面重新列举本文算法的几个步骤。
1) 基础方法:类似于Drain的做法,基于日志开头处出现常量的概率高于其他位置的粗略假设,认为日志的前两个词一定是常量,并基于这两个词对日志进行分类。
2) 数字过滤:在日志中去除所有包含数字的词,实验证明这样的策略可以极大提高所挑选词是常量的概率。
3) 使用全部常量进行分类:数字过滤使得对常/变量的判断更加自信,因此不再使用前两个词而是使用所有常量进行分类。
4) 非数字变量判别:这一步是数字过滤的补充,在此阶段专注于处理“不包含数字的变量”。
5) 含数字常量判别:这一步骤是数字过滤的另一项补充,在这一阶段专注于处理“包含数字的常量”。
6) 可变分隔符分词策略:在这一步中,会使用比“按空格分开的词”更复杂的分词策略。实验证明这种策略对于部分数据集是必须的。
从最简单的只使用前两个词对日志进行分类到使用全部机制,每个步骤对最终实验结果的贡献如图6所示。实验表明每种策略对应了日志解析中的一类特定问题,对完整的日志解析都有着不可或缺的作用,在所有步骤的共同作用下,日志解析的准确率最终可以达到接近100%的水平。
过去的研究已经证明,高精度的日志解析需要算法通过某种方式增加对系统知识的了解。Drain使用粗略的正则替换预处理;UniParser从训练集中学习日志的一般性特征;LogPPT对目标日志系统中的少量代表性日志做人工标注。实现高精度日志解析所需的系统知识输入的界限未知,为了更好地解决这个问题,本文提出了基于词模式规则的日志解析方法,它尽可能地缩减了复杂的算法结构,突出先验知识输入对算法性能的影响。由“不包含数字的词就是常量”的假设作为日志的一般性特征,通过非数字变量判别、含数字常量判别和可变分隔符分词三个步骤允许运维人员向算法输入领域知识。图6显示了在不同数据集上三个步骤对最终解析结果的影响力。实验结果表明,完全通过启发式规则向算法输入领域知识的代价是可以接受的。
4 "结 "语
相较于传统的启发式日志解析算法,本文算法需要运维人员提供更多的正则预处理策略,这种投入所带来的回报是更高的准确率和更快的运行速度。实验结果证明,给出额外的正则表达式作为系统知识的代价是可控且可以接受的。相较于使用庞大的神经网络在日志中学习常量/变量的特征,算法对运维人员提出了额外的要求,但这也使得在运行效率上具有明显优势,在面对格式与过往经验完全不同的新数据集时,算法的调整更加灵活。本文算法在性能方面表现优秀,且实现简单,是一种高效、可靠的日志解析工具。在不对现有系统设备增加过多负担的场景下,其优势更加突出。后续研究将考虑采用大语言模型等高精度但低效率的工具,对少量日志进行预训练,辅助运维人员提取系统知识。
注:本文通讯作者为顾兆军。
参考文献
[1] DANG Y N, LIN Q W, HUANG P. AIOps: Real⁃world challenges and research innovations [C]// Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering. New York: IEEE, 2019: 4⁃5.
[2] HE S L, HE P J, CHEN Z B, et al. A survey on automated log analysis for reliability engineering [J]. ACM computing surveys, 2022, 54(6): 1⁃37.
[3] WANG X H, ZHANG X, LI L Q, et al. SPINE: A scalable log parser with feedback guidance [C]// Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2022: 1198⁃1208.
[4] ZHANG X, XU Y, LIN Q W, et al. Robust log⁃based anomaly detection on unstable log data [C]// Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2019: 807⁃817.
[5] DU M, LI F F, ZHENG G N, et al. DeepLog: Anomaly detection and diagnosis from system logs through deep learning [C]// Proceedings of the ACM SIGSAC Conference on Computer amp; Communications Security. New York: ACM, 2017: 1285⁃1298.
[6] FU Q, LOU J G, WANG Y, et al. Execution anomaly detection in distributed systems through unstructured log analysis [C]// The 2009 Ninth IEEE International Conference on Data Mining. New York: IEEE, 2009: 149⁃158.
[7] HUANG S, LIU Y, FUNG C, et al. HitAnomaly: Hierarchical transformers for anomaly detection in system log [J]. IEEE transactions on network and service management, 2020, 17(4): 2064⁃2076.
[8] Elastic N.V. Grok filter plugin [EB/OL]. [2023⁃10⁃05]. https://www.elastic.co/guide/en/logstash/current/plugins⁃filters⁃grok.html.
[9] VAARANDI R. A data clustering algorithm for mining patterns from event logs [C]// Proceedings of 3rd IEEE Workshop on the IP Operations amp; Management. New York: IEEE, 2003: 119⁃126.
[10] NAGAPPAN M, VOUK M A. Abstracting log lines to log event types for mining software system logs [C]// 2017 7th IEEE International Working Conference on Mining Software Repositories. New York: IEEE, 2010: 114⁃117.
[11] DAI H T, LI H, CHEN C S, et al. Logram: Efficient log parsing using n⁃gram dictionaries [J]. IEEE transactions on software engineering, 2022, 48(3): 879⁃892.
[12] MAKKANJU A A O, ZINCIR⁃HEYWOOD A N, MILIOS E E. Clustering event logs using iterative partitioning [C]// Procee⁃dings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: IEEE, 2009: 1255⁃1264.
[13] HE P J, ZHU J M, ZHENG Z B, et al. Drain: An online log parsing approach with fixed depth tree [C]// Proceedings of the 2017 IEEE International Conference on Web Services. New York: IEEE, 2017: 33⁃40.
[14] CHU G J, WANG J Y, QI Q, et al. Prefix⁃Graph: A versatile log parsing approach merging prefix tree with probabilistic graph [C]// Proceedings of the 2021 IEEE 37th International Conference on Data Engineering. New York: IEEE, 2021: 2411⁃2422.
[15] 蒋金钊,傅媛媛,徐建.基于词性标注的启发式在线日志解析方法[J].计算机应用研究,2024,41(1):217⁃221.
[16] LIU Y D, ZHANG X, HE S L, et al. UniParser: A unified log parser for heterogeneous log data [C]// Proceedings of the ACM Web Conference. New York: ACM, 2022: 1893⁃1901.
[17] VAN HOANG L, ZHANG H Y. Log parsing with prompt⁃based few⁃shot learning [C]// IEEE/ACM 45th International Conference on Software Engineering. New York: IEEE, 2023: 2438⁃2449.
[18] XU W, HUANG L, FOX A, et al. Detecting large⁃scale system problems by mining console logs [C]// Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles. New York: ACM, 2009: 117⁃132.
[19] ZHU J M, HE S L, LIU J Y, et al. Tools and benchmarks for automated log parsing [C]// 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice. New York: IEEE, 2019: 121⁃130.
[20] HE P J, ZHU J M, XU P C, et al. A directed acyclic graph approach to online log parsing [EB/OL]. [2018⁃08⁃13]. http://arxiv.org/abs/1806.04356.
作者简介:顾兆军(1966—),男,山东蓬莱人,博士研究生,教授,主要研究方向为网络与信息安全、民航信息系统。
张智凯(1997—),男,辽宁朝阳人,硕士研究生,主要研究方向为日志解析、日志异常检测。
刘春波(1976—),男,天津人,硕士研究生,副教授,主要研究方向为网络安全智能检测。
叶经纬(1998—),男,湖北孝感人,硕士研究生,主要研究方向为日志异常检测。
