
基于Dorfman原理的误差分组检测的参数估计问题探究
2024-10-23 00:00:00谢东津罗广权
电脑知识与技术 2024年25期





0 引言
在庞大的人口体系中,众多学者对人体的血样分组检测法进行了大量的研究。最早的分组检测在1943年德国科学家Dorfman在对罕见疾病进行大样本研究时发现,对样本进行分组检测可以快速有效地识别出患病个体,此研究成果一出就引发了医学界的震动[1]。1957年,Swallow指出在样本分组检测中利用极大似然估计方法得到的分组结果存在一定误差[2]。对于大规模的血液检测,单体检测需要花费大量的时间和资金的投入。通过建立不同的样本分组,替换掉原始的单个体检测的方法,减少血液检测的次数从而提高检测的效率。尽管分组方法被提出后受到众多学者的关注,但对实验进行样本分组,组大小的确定是一直以来学者们探讨的难题。 虽然在使用近似最优组大小进行样本分组实验相比于传统Dorfman单体检测可以获取更大的效益,但是这种实验失败的风险也是巨大的[3]。对庞大的人口体系进行分组检测并不是分组检测人数越多越好,也不是分组人数越少越好,只有通过恰当的分组才能有效地降低检测的次数[4]。张乐成在血液检测分组模型中,给出了分组检测模型中求导迭代判断的最佳K值计算方法及计算机程序,该方法的检测存在一定的误差影响[5]。检测过程的环境和手段都可能给检测结果造成一定的影响。检测个体一般分为阳性个体和阴性个体,在检测过程中常会出现把真实状态为阳性的个体检测为阴性,真实状态为阴性的个体检测为阳性等现象,使得检测过程中患病率p 和最优组大小的估算产生误差[6]。李浩研究稀释效应下针对分组检测数据的参数估计问题,利用EM算法求得参数估计,并进行模拟计算,该方法在检测误差中可以有效提高检测效率[7]。为了更加准确地估计总体患病率p 和确定最优分组大小k,本文采用数学期望值最小化原则推导出患病率q 的估计区间,并提出一种新的逐步调整分组大小的迭代算法,快速准确地确定最优分组大小k。本文方法计算简单高效,可为传染病的分组检测提供更加精确的参考。
1 分组检测模型建立
整个分组检测算法从两个方面展开分析,其一不考虑外部环境等影响因子的Dorfman模型,其二是考虑诊断误差影响的模型。对于流行性的传染性疾病来说,由于检测仪器精密程度不同、人为操作的不规范等原因,造成检测分组的最优组大小k 值和患病率q 估计错误,造成实验的失败。如果能够尽早地检测出患病者,并进行相应的隔离治疗措施,可以极大地降低疾病的传播风险,尽可能地降低检测成本、人力物力等一系列的投入。快速地找到传染源且在有效的时间内控制疾病的传播,是非常必要的。在疾病检测中需要考虑检测误差,尽可能使得检测结果更加精确,则引入了敏感性和特异性的定义,基于Dorfman原理,给出样本分组检测的分布函数和计算出函数的数学期望值,需要采用数学期望值取得极值问题推导出患病率q 的取值范围和在q 取确定值下的k 值,并且采用新的逐步递增或递减1个单位的方法,直到函数的前一项和后一项异号,即得到最优的分组大小k。
从表1可以看出,当最佳分组人数取111时,函数F (k) > 0,则需要采用逐级加1法,当取112时,使得函数F (k) < 0,函数的前一项和后一项异号,则最佳分组数取112。
为了验证上述最佳分组人数的有效性,本文通过计算机语言Python进行模拟验证,取同样的条件,通过循环语句,当效益函数取最小值时,即取到最佳的分组人数,算法如下:
由图1显示,循环结果的最佳分组人数也为112,则上述方法进一步证实本文运用的方法与模拟结果一致,当存在检测误差时,能够得到最佳的分组人数使得检测效益达到最优。
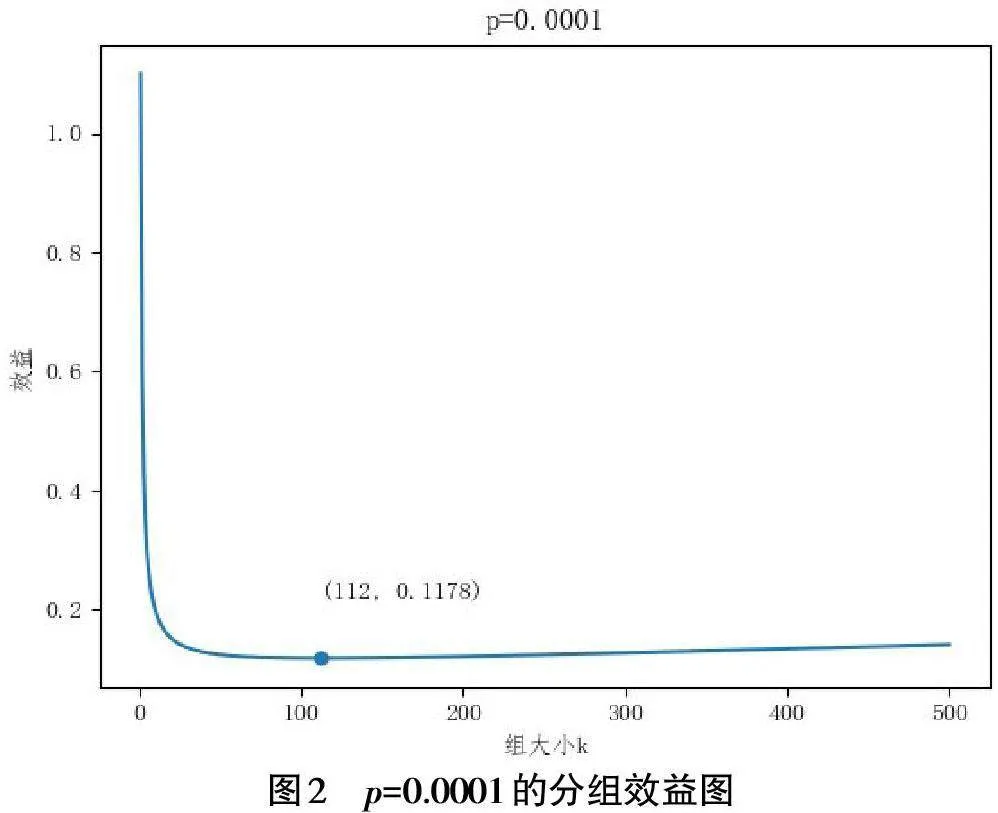
从图2可以看出,函数曲线是一个凹函数,随着分组的增加,函数逐渐递减,当组大小k=112取到极小值时,函数随后缓慢递增,其最佳的分组人数为112,效益约为0.1178。
当Se = 0.9,Sp = 0.9时,考虑在不同的p 值下的最佳分组人数以及最佳分组下的检测效率如下表所示。
由表2发现,不同患病概率p 值下,人群中患病概率越低,进行分组检测的最优分组人数相对较大,患病概率越大,为了更加精确地检测出患病个人,减少感染的风险,则需要的最佳分组人数需要相对较小,才能保证检测的精度,当患病率达到p=0.659,则需要进行单体检测。
3 结论
本文在考虑检测误差影响的情况下,基于Dorf⁃man分组检测原理,采用数学期望值最小化原则推导出患病率q 的估计区间,提出一种新的逐步调整分组大小的迭代算法,快速准确地确定最优分组大小k。通过Python语言给出了最优分组检测算法,且模拟出的结果与迭代算法计算出的结构一致,充分证明新方法在误差检查下,可以有效地估算出最佳的分组大小。本文方法计算简单高效,可为传染病的分组检测提供参考。
