
基于多模态融合的视频自动剪辑算法的设计与研究
2024-10-23 00:00:00王焕祥
电脑知识与技术 2024年25期




关键词:视频自动剪辑;多模态特征融合;Transformer;自注意力机制
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)25-0040-04
0 引言
视频作为生活中交互信息的载体,人们已经通过一系列设备录制众多视频,但是对视频的浏览与剪辑仍需要耗费一定时间。能从一段长视频自动剪辑出它最重的部分或者自动生成视频摘要将是一件省时省力的工作。这不仅是对视频剪辑者是一件更有效率的工作,对于视频阅读者亦然如此。因此笔者采用了多模态(视觉、声音、文字)的方式对视频的信息尽可能地提取,从而精准地生成原视频的摘要视频[1]。
如今,已经提出一些基于深度学习模型多模态自动视频摘要的生成方法[2]。其中利用RNNs模型[3],但RNN模型难以捕捉长时间的依赖关系和难并行化,这对长视频依赖关系的捕捉产生负面影响,从而影响准确性。本文舍弃传统的RNNs模型,采用了基于自注意力机制的Transformer基准模型(base-line model) [4],并在此基础上进行改进。
自注意力机制和多模态已经被广泛地应用于视频摘要任务中。如文献[5]通过位置编码将局部自注意力和全局自注意力相结合,有效地将局部特征和全局特征相结合。文献[6]中,通过分层次的自注意力机制,充分地将多个模态进行特征级融合。
本文针对多头自注意力机制特征融合程度不够深的问题,提出了一种基于跨模态特征交互和编码器-解码器结构框架的视频摘要模型。本文算法提取原始视频帧的特征,利用注意力模块将多个模态进行融合,最后通过预测头对各个片段进行评分,得到一组连续镜头作为视频的摘要。
1 研究方法
1.1 模型总体结构
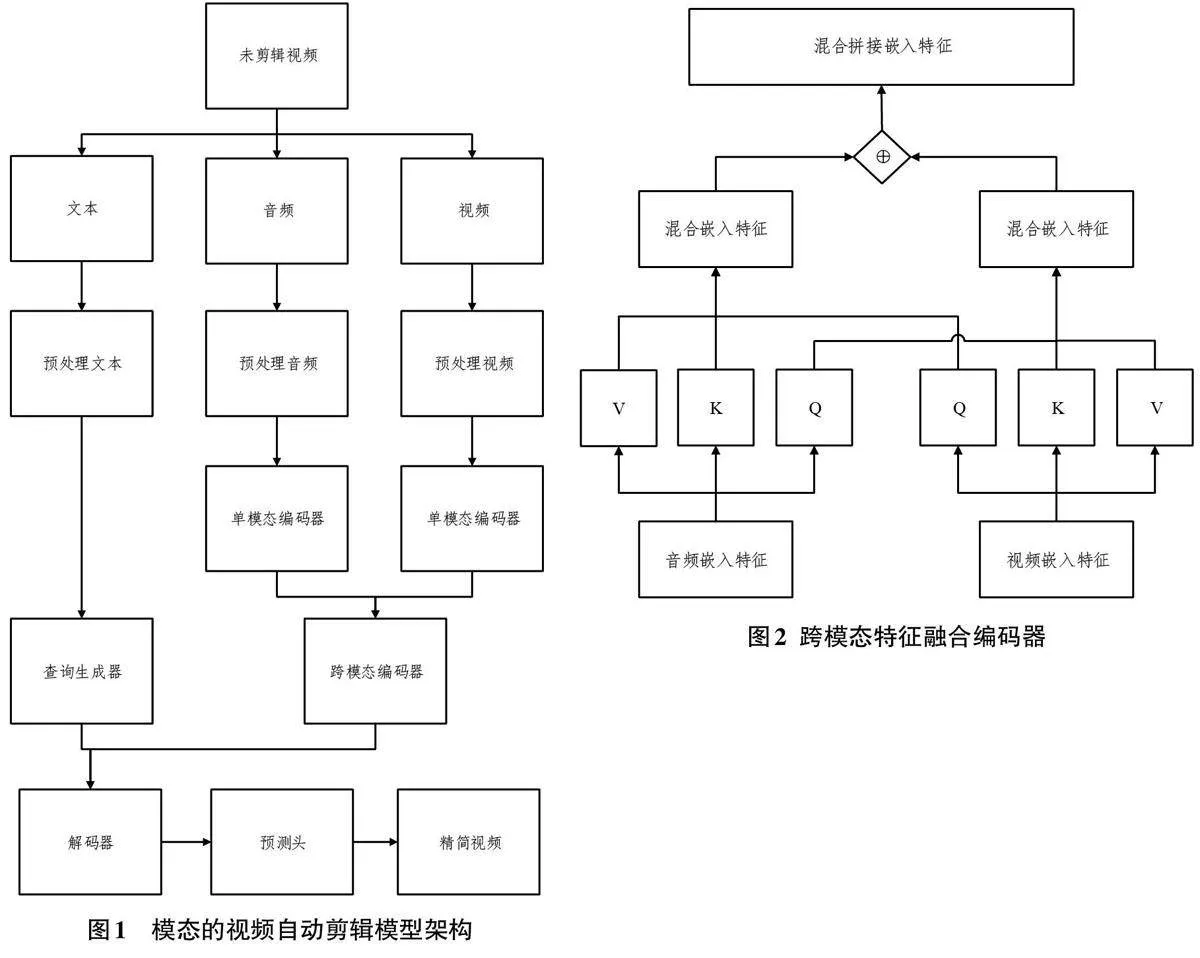
图1展示了本文提出的基于多模态的自动剪辑算法设计框架流程图。文中的模型由单模态编码模块,跨模态编码模块,查询器生成模块,解码模块和预测头模块。各个模态会通过不同的预训练模型提出特征,然后视频和音频会先通过跨模态交互得到两者的编码,再基于音频特征生成查询序列,最后通过解码并且预测头生成视频摘要。
1.3 跨模态特征融合编码器
此模块的跨模态是基于跨自注意力的基础上实现跨模态。此前文献[7]已经证明跨模态和跨自注意力有助于特征融合。因此,在单模态编码之后,还需要使用一个额外的跨模态编码器来捕捉跨模态的全局相关性。在跨模态编码器中,将两个视觉模态和音频模态的信息进行交互并融合,能够形成视觉语言共同注意力。跨模态编码器的计算流程和单模态编码器的计算流程一样,但两种模态计算注意力块时的query相互交换。在处理视觉模态以声音条件进行多头自注意力计算,在处理声音模态以视觉为条件进行多头自注意力计算。最后再将两个混合后的特征进行拼接操作(concatenation) 如图2。
1.4 查询生成器
由于Transformer最初是为语言翻译任务而引入的,因此输入和输出序列的长度可能不尽相同。输出序列的长度由输入Transformer的查询嵌入决定。输出序列的长度由输入解码器的查询嵌入决定。当Transformer延展到视觉任务时,查询嵌入会在训练过程中随机初始化和学习。查询嵌入应自然而然地指导表示解码过程。因此,该模型引入了一个查询生成器,以根据自然语言输入自适应地生成时间对齐的时刻查询。该模块也是由多头注意力层构建的,其中视觉和听觉混合特征充当query,文本特征是key 和value。我们的假设是,通过计算视频片段和文本查询之间的注意力权重,每个片段可以了解它是否包含文本中描述的哪些概念,并预测一个查询嵌入,该查询嵌入可用于对所学信息进行解码,以满足不同需求。
2 实验与结果分析
2.1 数据集
该实验的训练集使用QVHightlights[10]数据集进行训练并使用TVSum[11]数据集验证。QVHightlights数据集包含裁剪成10 148个短片段(150个长片段)的视频,每个片段至少有一个描述其相关时刻的文本查询注释。每个查询平均约有1.8个不相关时刻,注释在不重叠的2秒长片段上。TVSum包括10个领域,每个领域有5个视频。我们按照传统随机0.8/0.2的比例进行训练和测试。
2.2 评定方法
该实验使用了IoU阈值为0.5和0.7的Recall@1、IoU阈值为0.5和0.75 的平均精度(mAP)以及一系列IoU 阈值[0.5:0.05:0.95]的平均mAP来进行检索。这些方法衡量摘要效果都是分数越高该方法摘要效果越好。
2.3 对比实验
2.4 消融实验
从表4得知,通过预训练得到的文本模态,确实有更好的表现。
3 结束语
本文提出一种基于多模态特征融合的自动剪辑算法。该模型分别通过单模态特征提取、跨模态特征融合、中心点和窗口的片段选取进一步提高准确度。在QVHighlight 和TvSum数据集下的实验结果证明,本文提出的MFFAC视频自动剪辑算法优于其他同类型的算法。
