
基于案例推理的通用案例检索模型研究
2024-10-23 00:00:00张洁叶颖张洪胜方厚加
电脑知识与技术 2024年25期







关键词:案例推理;文本词频;检索模型
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)25-0011-05
0 引言
案例推理(Case-Based Reasoning, CBR) 技术起源于美国耶鲁大学Roger Schank 于1982 年在其专著《Dynamic Memory》中的描述,是人工智能领域中较新兴的一种重要的基于知识的问题求解和学习方法[1-10]。随着人们对CBR研究的不断深入,CBR的应用领域不断拓宽,已涉及机器故障诊断、医药医疗诊断、企业咨询决策、法律案例评估和天气预报等多个领域。因此,程序设计者难以获取并表达专业知识的问题日益突出,因此,对基于案例推理的通用案例检索模型的需求不断上升。
1 基于案例推理的通用案例检索模型框架
通过对不同领域中引入案例推理技术进行案例检索的比较,提出一个基于案例推理的共用案例检索模型框架,如图1所示。
在基于案例推理的通用案例检索模型中,首先要对案例进行标准化描述,以特征向量的形式来映射各属性,通过检索来查找案例库中与新问题案例最接近的匹配案例。如果找到相同或相似度在阈值范围内的案例,则可以直接重用旧案例的知识;否则,根据最相似的若干匹配案例重新修改评估方案,形成新案例,并将其保存进入案例库。
2 基于案例推理的通用案例检索模型关键技术
案例推理过程主要包括案例知识表示、案例检索、案例重用/案例修改以及案例学习4个关键技术。
2.1 案例知识表示
随着社会经济的发展、CBR研究的不断深入以及数据量的急剧增加,CBR的应用领域越来越广泛。但在使用CBR之前,首先要进行数据的清洗和整理。我国各行各业各个机构都存有大量的可用数据,但由于地方性差异,很多数据除了在时间aqNyNxllI03MFKOajguWkQ==和空间上分散外,还存在存储结构、评价内容和属性特征等方面的差异,因此很多数据很难在同一个平台上进行比较。
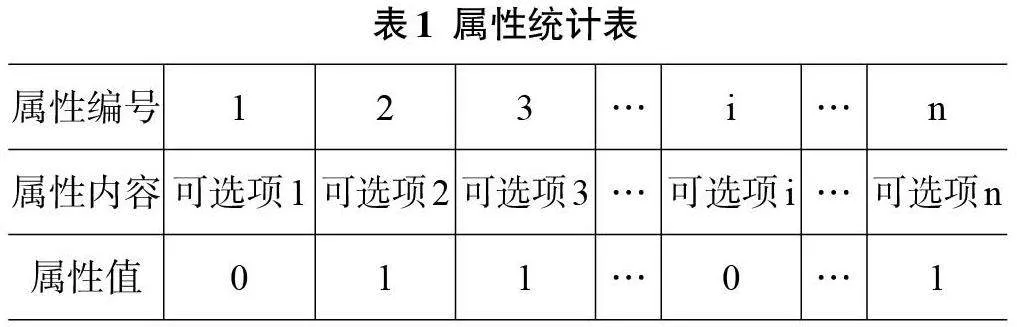
在这里,笔者借助布尔型特征向量来进行案例知识的表示。由于不同领域的评估侧重点不同,且数据大多为非结构化数据。因此,首先建立一个属性统计表,即将某些行业某些领域的评估指标进行整合,并分解为一些可选项。并建立如表1所示的属性统计表。
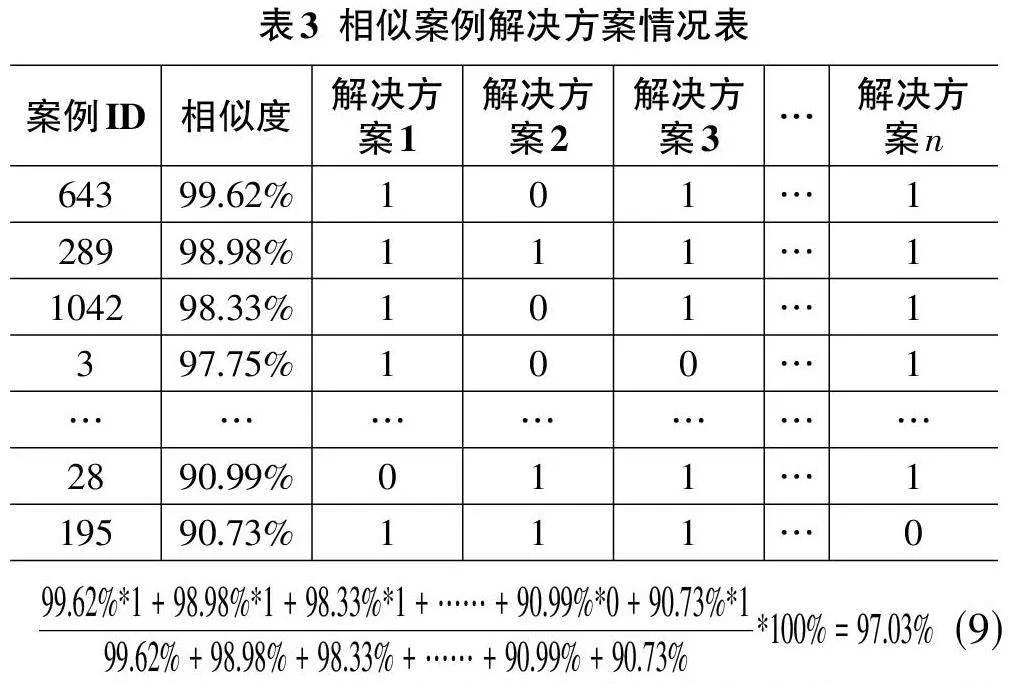
假设在案例库中,所有案例的诊疗方案经过综合并分解后,可得到n 条可选的布尔型解决方案。通过案例检索,我们找到了与当前未知案例情况最相似的前50条相似案例,其相似案例与新案例的相似度及相似案例的解决方案如表3所示:
当新案例的所有解决方案采用率都计算出来,并经过人工干预给出案例采用率的阈值后,新案例的解决方案即可确定。例如:经过人工干预,设定解决方案采用率在95%以上的为必要解决方案,新案例解决方案采用率在80%~95%为可选解决方案,新案例解决方案采用率在60%~80%为参考解决方案等。即如果新案例的某个解决方案采用率大于等于95%,则直接作为新案例的解决方案;若该解决方案采用率在80%~95%,则作为新案例的推荐解决方案;若该解决方案采用率在60%~80%,则作为新案例的可选解决方案,而采用率小于60%的解决方案则不推荐给用户使用。由此可以得到新案例的个性化辅助决策方案,对于推荐和可选方案,可以将采用率附在后面,为用户决策提供参考。
2.4 案例学习
在案例个性化干预过程中,除了提供新案例的辅助决策方案之外,还可以用于扩充案例库。如果在案例相似度检索过程中,新案例与案例库中的案例相似度均低于某个阈值(例如:相似度均低于95%) ,则新案例的辅助决策案经过人工干预后可以作为案例库的新案例被添加到案例库中。通过这样的不断操作,逐步完善案例库。当新的案例加入案例库中时,整个案例库的权重向量需要进行调整。权重向量中的每一个权重均是通过log(D/Di)计算得出。
3 方法测试
为了验证本文所提出的基于案例推理的通用案例检索模型的准确性,选用Visual Studio 2010作为开发平台,C#为开发语言,案例保存在SQL Server 2010中,对方法的准确性进行简单测试。
在测试过程中,模拟了1500条老年人健康评估案例,其中1300条为训练案例,200条为测试案例。在测试中,我们首先根据调研来的案例建立了如下表4所示的老年人健康评估表。
随后,我们根据训练案例及相应的测评标准,在SQL Server 2010中建立了一个包含24个属性(不包括诊断结果或结局方案属性)、1300个元组的基本数据表,如图1所示。
通过对属性进行分类,建立了一个包含82个分类属性的布尔型数据表,如图2所示。
根据对分类属性的统计结果(如图3所示),我们可以计算出每个分类属性的权重,如表5所示。
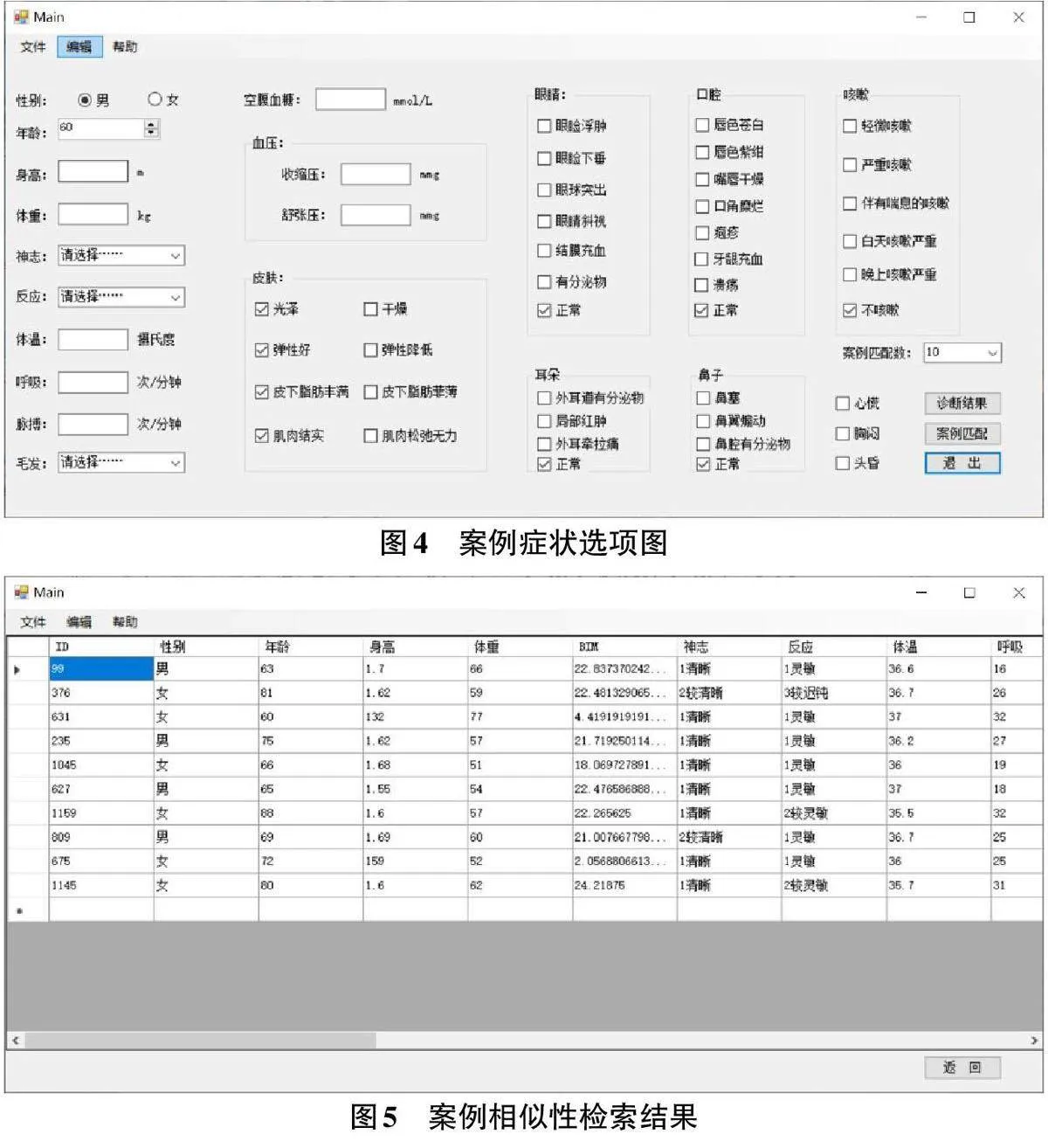
完成以上准备工作后,即可根据图4所示的案例症状选项图对新案例的症状进行描述。
描述后的案例将被表示为带权向量,并与案例库中的案例进行相似度检索,检索结果如图5所示。
测试结果显示,案例检索的准确性在90%以上。
4 结束语
本文提出了一种基于案例推理的通用案例检索模型,并介绍了推理过程中的几个关键技术。该模型具有通用性,在应用过程中只需将案例属性进行转换,对应到模型中的相关属性上即可进行案例推理。例如:在测试过程中,我们将健康指标对应为相应属性,从而将该通用模型转化为老年人健康评估模型。此外,该模型的建立方法简单易懂,且实现较为简单,经过实验验证,具有较高的准确性。然而,此次测试仅单纯验证了方法的准确性,其在实际系统应用中的有效性尚待检验,并且在几个关键技术上仍有一些问题需要解决。
首先,通过将各个案例整合并分解为一个个可选项的方法进行案例知识表示。这种知识表示方法简单易行,适用于大多数可选项,但对于一些有参考数据的指标(例如数值型、文本型等),其适用性较差。
其次,在用特征向量表示知识时,由于所分解的多个可选项常常是一个指标中分解出来的,因此在同一案例中只能选择一项,结果是所用的特征向量实际上是一个稀疏向量。此外,案例重用技术中提到的阈值t 也需要专业人士进行设定,这无疑增加了人工干预的程度。因此,在实际应用中,如何在保证有效性的基础上通过稀疏矩阵的运算法则简化现有算法,以及如何尽可能降低人工干预的程度以提高工作效率,都是今后的研究方向之一。
最后,算法应用过程中的有效性与案例库的大小相关。然而,随着案例库的不断扩张,案例相似度检索将会变得越来越复杂。因此,提高算法效率也是今后研究的一个方向。
