
基于大语言模型的金融合规系统设计与实现
2024-10-23 00:00:00于琦
电脑知识与技术 2024年25期

关键词:大语言模型;金融制度合规;系统响应时间
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)25-0008-03
近年来,随着人工智能、大数据、5G等先进技术的迅速发展,金融制度合规系统的智能化发展速度也越来越快,新兴技术在金融机构内部管理和业务开展中的重要作用日益凸显。大语言模型凭借其强大的自然语言处理能力[1],在金融合规领域展现出巨大的应用潜力。大语言模型能够理解复杂的金融法规和内部规范,并自动完成文本生成、信息提取等任务,为金融合规业务的智能化转型提供了技术支撑。
1 系统设计与实现的难点分析
在数字经济背景下,提升金融合规系统的监管效率、降低监管成本至关重要。将大语言模型应用于金融合规系统,能够打造智能助手,协助合规人员处理制度撰写、材料审核、规范答疑等事务,有效减少人员日常工作量。然而,大语言模型自身的局限性也为金融合规系统的应用带来了一些挑战。一方面,金融合规系统涉及的文档通常篇幅较长,超过了大语言模型的上下文限制。因此,系统设计需要引入合适的框架对长文档进行拆分处理。另一方面,金融合规业务的提示词往往较为复杂,导致大语言模型的响应时间较长。因此,需要对系统响应时间进行优化,以保证系统的流畅性。
2 系统设计的整体方案
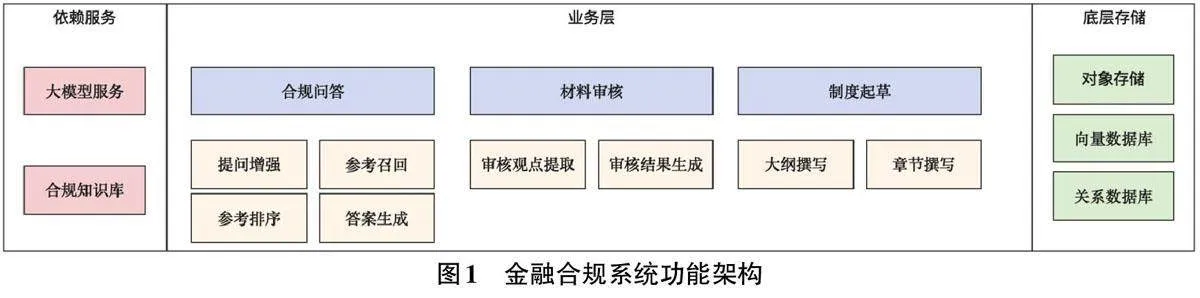
基于大语言模型所设计的金融合规系统从整体上看主要分为业务层、依赖服务、底层存储这三个部分(如图1所示)。其中,大语言模型在业务层的重点应用主要体现在合规问答、材料审核、制度起草这三种功能上。
对于合规问答而言,该功能主要基于检索增强的文本生成技术(RAG,Retrieval Augmented Generation) 来实现[2]。基本原理是根据用户问题智能检索制度文档集合中相关的条款,以这些条款作为参考信息来请求大语言模型,进而在系统中由大语言模型反馈回相应的问答结果。制度起草与合规问答类似,也是以用户检索的相关制度信息作为参考,请求大语言模型进行制度文本的撰写、续写或者重新改写等。材料审核则是通过将输入系统的长文档切分为短文档,进而完成审核要点的提取及审核结果生成等子任务。
业务支撑层主要为业务层的各类智能功能提供基础和保障,主要包括大语言模型服务及合规知识库两部分。其中,合规知识库是一个由原始金融合规制度文档加工而成的信息集合,通过对原始制度按照条款进行切分并构建索引,以便提供给业务层作为用户检索时的参考信息使用。底层存储层在设计上主要引入了对象存储、关系数据库及向量数据库这三种持久化工具。对象存储主要用于存储形成合规知识库所需的原始合规规则、制度等文档,关系数据库用于记录用户检索历史、用户信息等关系型数据,而向量数据库主要能够构建金融规章制度的文档切片索引,以实现语义检索功能[3]。
3 系统的详细设计
由于大语言模型在金融合规体系中的应用主要集中在业务系统中,本文将重点对业务系统中合规问答、材料审核及制度起草这三种智能应用的详细设计展开分析。
3.1 合规问答系统设计
合规问答系统的设计原理是以现有的金融合规制度、规则作为参考知识库,通过智能客服的形式解答用户提出的合规相关问题,主要包括线下知识库构建与线上合规问答两部分,其主要通过检索增强的文本生成技术(RAG) 来实现。
首先,线下知识库构建方面,主要将业务支撑层中的合规知识库进行信息加工,加工成大语言模型可以识别的切片索引,每个制度切片均包含若干完整的条款及相关章节标题,以确保信息的完整性。其次,线上合规问答的设计包括问题增强、参考信息召回与排序及答案生成。问题增强主要通过大语言模型对用户所提问题进行扩展,如问题概述、提取关键词、模拟答案等,以提高检索参考信息的召回率。参考信息召回主要通过用户提问及问题增强生成的相关问题从所构建的线下知识库进行检索,并获取知识库中的相关制度、规则信息。与此同时,使用RRF(Recipro⁃cal Rank Fusion) 等算法对所获取的相关信息进行优先级排序[4]。最终根据相关性最高的制度、规则信息生成提示词来请求大语言模型,进而形成用户问题的答案。
3.2 制度起草系统设计
制度起草是基于大语言模型功能完成金融合规制度的智能撰写,包括合规制度的目录大纲、各分章节具体内容等。其中,目录大纲的撰写主要依据合规知识库中原始的金融合规制度大纲范式进行撰写,各章节具体内容则是通过相应的章节标题来检索合规知识库,基于检索出的相关制度片段作为参考进行撰写。这样设计的合理性在于,它基于已有的金融合规制度、规则文档,模拟了人类制度起草时由整体到局部的思考逻辑。但是该方案存在系统响应时间长的问题,因为大语言模型输出复杂内容一般需要5~20 秒的时间,耗时较长。由于制度撰写整个过程的实现涉及多次大语言模型交互与参考信息的检索,完成时间预计会超过5分钟,用户体验较差。为此,本文提出以下两种解决方案:一是采用大语言模型服务提供的流式输出方案。大语言模型可以通过服务端事件协议(Server Side Events, SSE) 对外提供流式输出,页面能够显示类似打字机的输出效果。经过测试,该种方案可以在5秒以内输出响应内容。二是采用并发调用大语言模型服务的方案。虽然该方案无法获取流式输出效果,但可显著缩短在制度起草完成后全文输出的时间。经过测试,该种方案输出制度全文的平均响应时间约为30秒。
3.3 材料审核系统设计
基于大语言模型的金融合规业务中材料审核系统主要包括审核点抽取及审核结果获取两个模块。审核点抽取是从合规知识库中总结提取若干审核点,并提交审核结果获取模块进行智能审核处理。审核结果获取模块会根据审核点对用户提交的被审核材料进行智能阅读,并输出审核结果及改进意见。
智能阅读与问答和撰写类似,也是一种大语言模型的应用形式,其主要用于解决输入文档过长的问题,其在系统设计中主要借鉴了大数据技术中的MapReduce计算框架[5]。该框架分为Map与Reduce两个阶段,Map 阶段主要处理拆分后的文档切片,Re⁃duce阶段则负责将上述处理结果进行汇总。这样设计可以审核和处理远超单次请求大语言模型提示词长度上限的制度、规则文档,并可以高效完成相应的材料审核任务(图2) 。例如在金融合规制度或规则文档的翻译任务中,Map阶段主要进行文本翻译,而Re⁃duce阶段则合并翻译结果。
4 系统测试结果分析
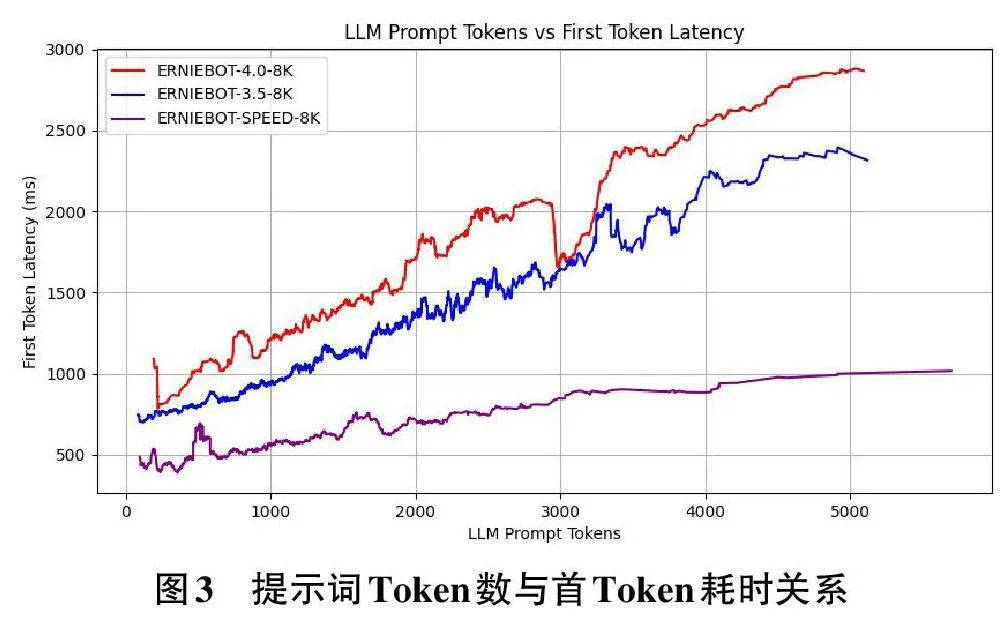
基于大语言模型所设计的金融合规系统的响应时间主要由大语言模型服务的首Token响应时间决定,而响应时间的长短将直接影响用户的使用体验。为此,在保证系统功能的前提下,对系统设计中所使用的文心一言系列[6] 的3 个模型(erniebot-4.0-8k、erniebot-3.5-8k 与erniebot-speed-8k) 的响应时间进行测试与对比,重点关注各类大语言模型单次请求的提示词Token数与接收到首个Token所耗时之间的关系,具体测试结果如图3所示。由于这三个模型在性能上依次减弱,根据测算结果,在相同的输入长度前提下,效果越好的大语言模型其响应速度越慢。这是因为效果越好的大语言模型其模型参数与相应的计算资源也越多,请求所需要的时间就越长。因此,在系统设计中选择大语言模型时,需要根据自身业务特点在模型性能与响应时间之间做出平衡。
同时,根据以上测试结果,这三种大语言模型首Token延迟随着提示词Token量的增加而整体呈上升趋势。这是因为大语言模型,如GPT-3和BERT,通常使用Transformer架构[1]。该架构在处理输入时,需要对每个Token与其他所有Token的关系进行计算,输入Token的数量会直接影响模型的计算复杂度。如果输入的Token数量增加一倍,模型需要处理的Token 对(Token pairs) 的数量会变为原来的四倍,导致模型的响应时间明显增加。因此,在基于大语言模型的金融合规系统设计中,还需要在用户输入问题复杂度和模型响应时间之间做出平衡。例如,可以根据上述曲线对用户输入问题的提示词长度进行截段,或者在进行问答时减少参考信息的条数,从而减少输入提示词长度,进而达到较为理想的响应时间,提升用户对系统的使用体验。
5 结束语
基于大语言模型应用成本低、操作灵活性强等优势,本文设计了一套集合规问答、制度起草、材料审核等智能化功能于一体的金融合规系统。同时,本文通过合规系统中提示词长度与不同类型大语言模型响应时间关系的模拟与测算,为智能金融合规系统中大语言模型响应时间的合理优化与控制提供了解决方案和相应策略。
