
多尺度自适应注意力检测模型用于皮革织物瑕疵检测
2024-10-22 00:00李皞刘义凡徐华伟杨可康镇黄梦真欧啸赵雨晨邢同振
丝绸 2024年10期






A multi-scale adaptive attention detection model for leather fabric defect detection
摘要:
在工业皮革织物生产中,缺陷检测是控制工业质量至关重要的一部分。而皮革织物表面的缺陷局部相似程度高,造成不同缺陷类间存在高相似性,导致缺陷检测的效果不佳。为此,文章提出了一种自适应卷积注意力(ACA),并引入骨干网络中增强语义特征表示能力。其次设计了基于自适应卷积注意力的特征金字塔(AC-FPN)改进多尺度融合,进行更低粒度的皮革缺陷区分。最后将传统检测头替换为侧面感知边界定位(SABL)检测头,聚焦皮革缺陷精确位置,有助于网络区分相似和不同类别的缺陷及更精确的定位。文章在自建皮革数据集对ACA及改进后的各个组件进行消融实验,与目前各种主流检测模型进行对比。其中,AP、AP50和AP75三项评估指标分别达到了83.4、89.7、85.6,并且在APS、APM和APL上分别达到了71.3、89.9、88.9。通过实验证明了可行性,为自动皮革缺陷检测方法提供了新的思路。
关键词:
注意力机制;多尺度信息;缺陷检测;卷积神经网络;缺陷分类;皮革织物
中图分类号:
TS57
文献标志码:
A
文章编号: 10017003(2024)10期数0036起始页码10篇页数
DOI: 10.3969/j.issn.1001-7003.2024.10期数.004(篇序)
收稿日期:
20240319;
修回日期:
20240912
基金项目:
湖北省教育厅科技计划项目(D20221604);湖北省重点研发计划项目(2021BBA235);湖北省重点研发计划国家自然科学基金项目(12302243);湖北省青年科学基金项目(2023AFB372)
作者简介:
李皞(1982),男,教授,博士,主要从事红外及光谱信号处理技术与理论,及其在遥感、粮食加工,食品安全、智慧农业等领域中的研究。
皮革制品在服装、制鞋、家具、箱包等领域广泛应用,成为人们生活中不可或缺的一部分[1]。随着人们生活水平的提高,对皮革制品的质量和外观要求也越来越高[2]。但在合成皮革制品的生产过程中,不可避免地会出现一定的缺陷,这些缺陷会直接影响着皮革制品的质量和价格。在生产早期,识别这些缺陷可以避免更多的皮革损耗。目前生产线上缺陷检测技术仍主要依赖人工操作,这导致了高成本、低效率及易受人为因素影响的问题[3]。因此,推动皮革行业实现自动化生产,解放劳动力,使皮革缺陷检测自动化具有重要的实现价值和现实意义,开发一种识别精度高、具备强鲁棒性的皮革缺陷检测算法至关重要[4]。然而,由于皮革织物制品缺陷的局部形态差异及类间相似度高,极容易造成类间错分,进而导致自动化的皮革缺陷检测成为具有挑战性的任务。
为了解决皮革缺陷特征局部形态差异不明显的问题,目前大部分研究者开始使用深度学习方法进行皮革缺陷检测。Aslam等[5]引入了深度学习集成模型技术,用于缺陷和无缺陷皮革样本分类。在相关研究中,Aslam等[6]创建了包含各种皮革缺陷类型的高分辨率数据集,证明了积极的知识转移通过跨领域知识融合有助于皮革缺陷问题的检测。Khanal等[7]讨论使用机器视觉技术开发全自动皮革缺陷检测系统,该系统包括传送系统和摄像头,使用深度学习模型实现皮革图像捕捉和缺陷检测,构建一个从硬件到软件的全自动系统。在MVTEC皮革数据集上,他们的语义分割模型获得了94%的IOU分数。数据集中的所有皮革图像都具有相似的缺陷表现形式,因此,模型在具有类间和类内变化的数据集上可能表现不佳。Gan等[8]提出了一种基于深度学习的数字图像处理方法,实现了自动化的皮革缺陷检测与定位系统。而Zhang等[9]提出了KMDNet,一种新型的皮革分割网络,该网络引入了KPCL层作为新的语义信息提取层。尽管取得了巨大的进步,但基于深度学习的方法对皮革不同缺陷类间存在相似特征的问题上,可能表现不佳,也难以精确定位缺陷位置。
为了解决皮革不同缺陷类间相似特征的问题,本文考虑引入注意力机制。注意力在人类感知[10]中扮演关键角色,Wang等[11]和Hu等[12]的研究探讨了神经网络中的注意力,发现注意力机制能够引导网络更关注目标特征。Zhang等[13]和Li等[14]在通用对象检测和缺陷定位中探索了注意力的应用。受到Woo等[15]的启发,本文提出自适应卷积注意力(ACA),针对性地解决皮革缺陷类间特征方差小的问题。通过残差结构将通道注意力进行加强,增强语义特征的表示能力,使得网络更能准确地区分和识别不同表现形式的皮革缺陷。选用两个不同大小的滤波核进行空间注意力操作,网络可以更好地抽取和强化特征之间的空间信息,自适应的选择皮革缺陷类间差异并放大差异,这有助于解决皮革缺陷类间差异较小的问题,使得网络能够更精确地分辨不同皮革缺陷类别。为了更精确检测到不同尺寸的皮革缺陷并减少计算复杂度,本文选用FPN[16]进行多尺度特征融合,引入ACA后称为自适应卷积注意力特征金字塔(AC-FPN),减少融合时下采样造成的信息丢失,更能精确检测到不同尺寸的缺陷。再配合侧面感知边界定位(SABL)[17]检测头聚焦皮革缺陷精确位置,有助于网络区分相似和不同类别的缺陷及更精确的定位。
此研究贡献主要体现在以下几点:
1) 为了解决皮革缺陷类间方差变化的问题,提出了一种自适应卷积注意力(ACA)模块。将ACA引入骨干网络中,增强语义特征表示能力,提升网络捕捉皮革缺陷类间差异的能力。
2) 为了应对皮革缺陷的不同尺寸,提出了一种新的自适
应卷积注意力特征金字塔(AC-FPN)进一步改进特征表示,有选择地捕获来自不同域的上下文信息,加强特征图中的语义信息,更好地捕获不同尺寸的缺陷,同时减少融合时下采样造成的信息丢失。
3) 为了更精准地定位皮革缺陷位置,本文将传统检测头替换为侧面感知边界定位(SABL)检测头,边界框的每一侧都根据其周围的上下文分别定位,以实现精准的皮革缺陷定位。
1 提出的方法
1.1 自适应卷积注意力(ACA)模块
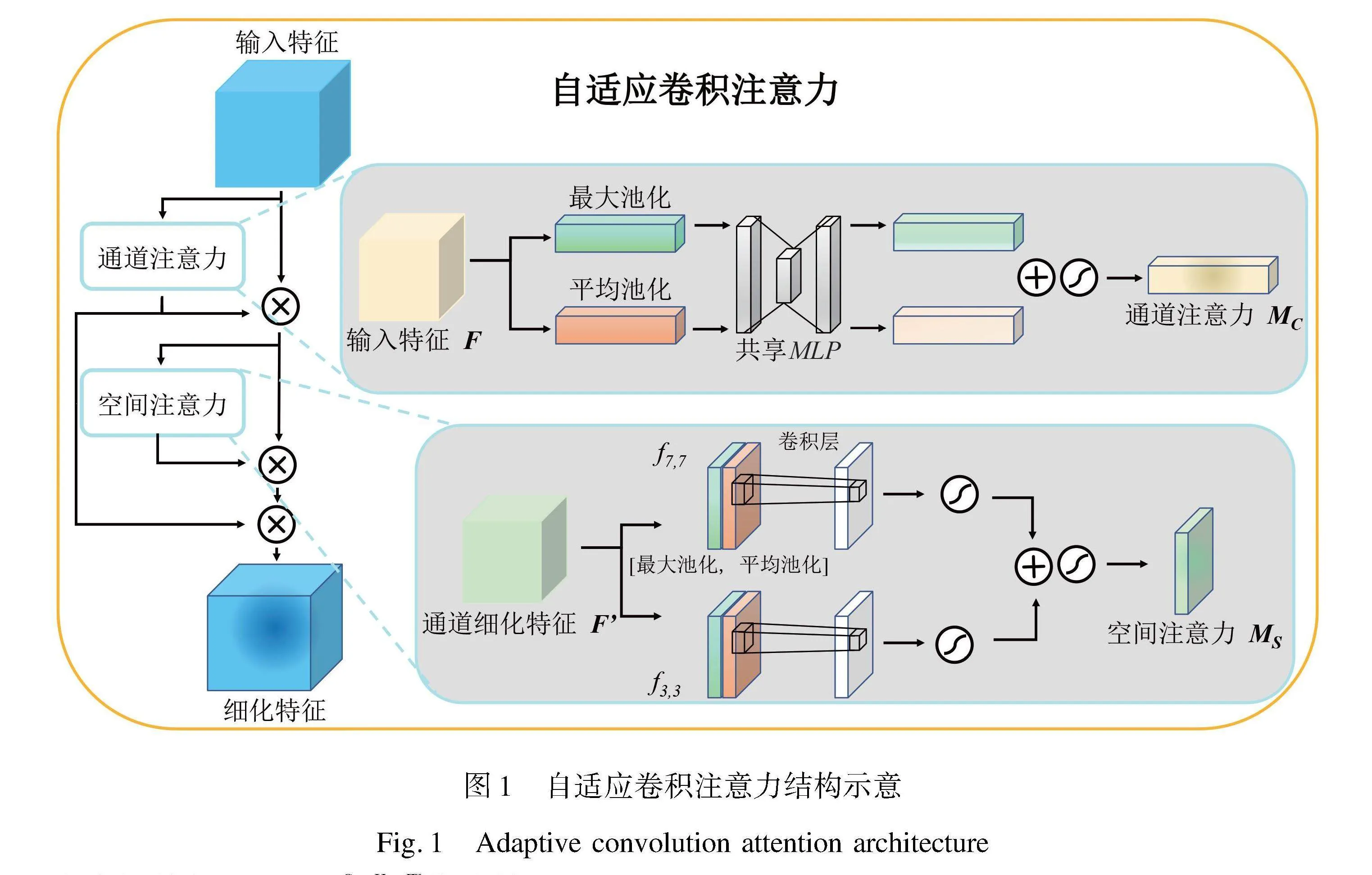
为了解决皮革织物表面缺陷的局部相似程度高、导致类间难以分辨的问题,本文提出自适应卷积注意力(ACA)模块,结构如图1所示。该模块由通道注意力和空间注意力两个部分组成。其中通道注意力可以更好地区分和捕捉皮革缺陷类间差异,提高语义特征的表示能力。而在空间注意力中,本文选用核大小为7和核大小为3的滤波核进行并行的空间注意力操作,以强化皮革缺陷的类与类之间的空间特征,区分缺陷表现形式相似但非同一类的缺陷。在本文中采用注意力机制模块的主要目的在于通过强化信息区域并抑制非相关区域,同时增强语义信息,从而改善特征的表征能力。这种方法使模型能够有效地捕捉有关缺陷部分的关键特征,从而提升皮革缺陷检测的准确性。
图1中,给定一个中间特征图F∈RC×H×W作为输入,ACA依次推断一个1D的通道注意力图MC∈RC×1×1和一个2D的空间注意力图MS∈R1×H×W,最后对空间注意力图和通道注意力图进行融合。整体的注意力过程可以概括为:
F′=MC(F)FF″=(MS(F′)F′)MC(F)(1)
式中:表示逐元素乘法,F′表示经过通道注意力后的特征描述符。在乘法运算过程中,通道注意力值沿空间维度广播,反
之亦然。F″为最终经过精炼处理的输出,通过最后将空间注意力和通道注意力进行逐元素相乘,加强语义信息的表征能力。
1.1.1 通道注意力
通道注意力被应用在学习特征也就是缺陷之间的关系上。关注点在给定输入图像中哪些部分是有意义的[15]。由于特征网络中存在多尺度信息,能够逐步学习更为丰富的特征表示。通过强化通道注意力,网络可以对同一类缺陷中存在的显著差异进行辨认,更好地区分和捕捉这些类内差异,提高语义特征的表示能力。
MC(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Fcavg))+W1(W0(Fcmax)))(2)
式中:F为特征图,σ为sigmoid函数,Fcavg表示使用平均池化特征,Fcmax表示最大池化特征。全连接层的权重用W0表示,输出层用W1表示。
1.1.2 空间注意力
空间注意力是对通道注意力的补充,其关注的焦点是信息存在的空间区域。平均池化和最大池化过程沿着通道轴执行,以计算空间注意力,然后连接以创建有效的特征描述符[15]。当皮革缺陷类间差异较小时,可能需要更强的空间信息来帮助区分这些缺陷。采用核大小为7和核大小为3的两种滤波核,并行地进行空间注意力操作,能够引导网络更好的强化缺陷类间特征的空间信息。
空间注意力模块压缩特征映射F∈RH×W转化为Fsavg∈R1×H×W平均池化结果和Fsmax∈R1×H×W最大池化结果。这些特
征首先被连接,然后使用传统的卷积层进行卷积,以产生2D空间注意力图。
Ff7=σ(f7×7([AvgPool(F);MaxPool(F)]))Ff3=σ(f3×3([AvgPool(F);MaxPool(F)]))MS(F)=σ(Ff7+Ff3)(3)
式中:F为特征图,σ为sigmoid函数,f7×7表示核大小为7的卷积运算,f3×3表示核大小为3的卷积运算,Ff7表示使用核大小为7的卷积特征,Ff3表示使用核大小为3的卷积特征。
1.2 皮革缺陷检测方法
本文所提出的皮革缺陷检测方法通过卷积层和ACA模块来提取图像中的皮革缺陷关键特征。这些特征用来区分不同类型的皮革缺陷,如刀伤、折痕等。在特征提取阶段,皮革缺陷检测网络学习到适用于不同皮革缺陷类型的特征表示。再将特征表示通过分类器层将学习到的皮革缺陷特征映射到输出层,输出层的多个节点代表不同类型的皮革缺陷。整体架构如图2所示,大体上分为三个步骤。
第一步,输入皮革图像被传送到骨干网络,用于提取全局的语义特征。本文选用ResNet[18]作为骨干网络,其中的残差块有助于提高ResNet的准确性。为了更有效地引导网络区分和强化缺陷类间的差异,本文在每个残差块中嵌入了ACA模块,具体结构如图2中的Backbone结构。ACA的引入增强了模型的皮革缺陷感知能力。通过自适应地对特征图中的通道和空间进行加权,使得网络能够更有选择性地关注重要的皮革缺陷特征,从而增强了对局部和全局信息的感知,提升骨干网络对皮革缺陷特征的抽取能力。
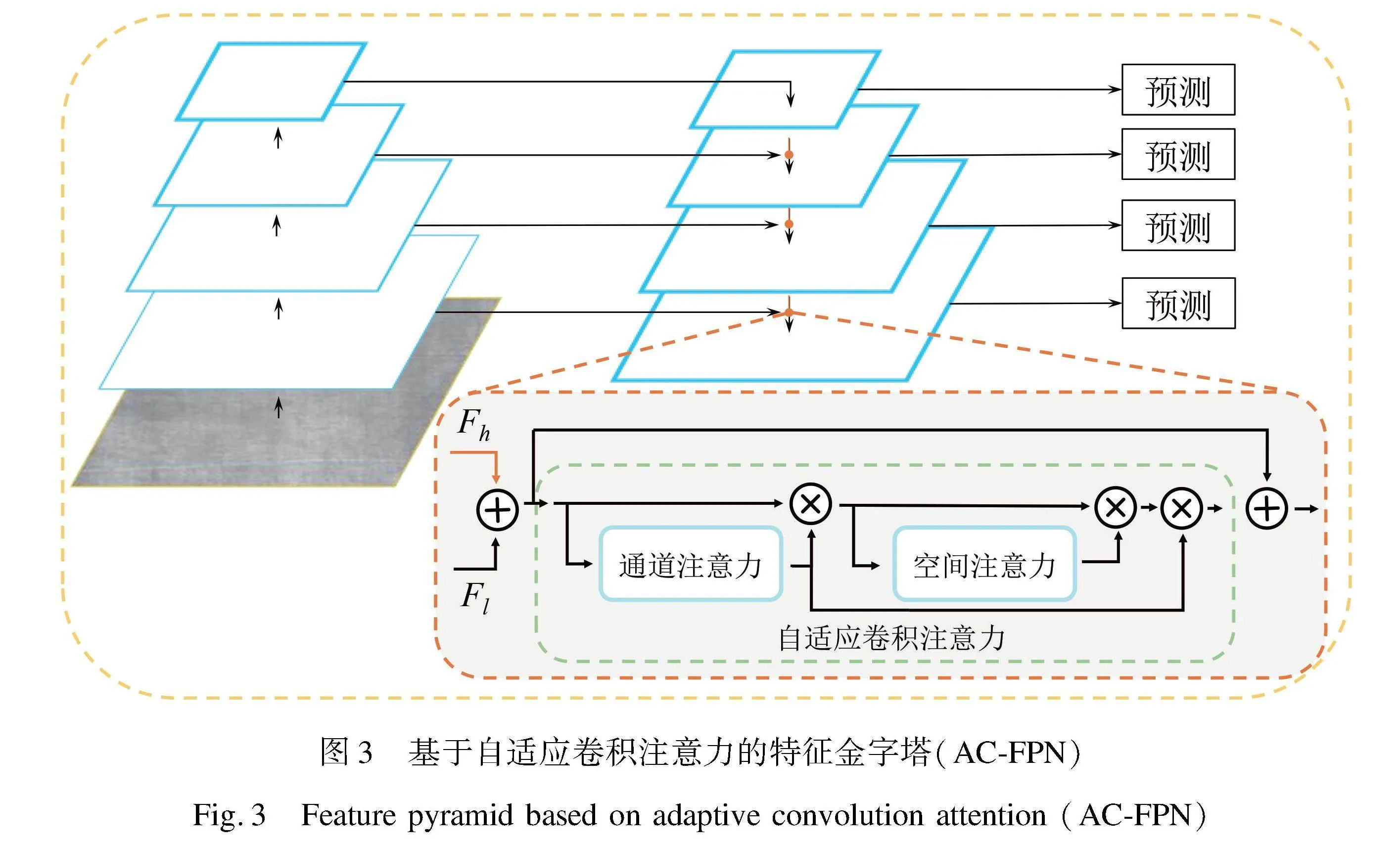
第二步,本文对从骨干网络抽取的特征图进行多尺度信息融合。考虑到特征金字塔(FPN)[16]能够在各个尺度上呈现皮革缺陷特征,因此本文采用AC-FPN,即将特征金字塔(FPN)和自适应注意力(ACA)相结合,具体结构如图3所示。通过将ACA应用于各个尺度的特征融合路径上,以增强语义的特征表示能力,实现多尺度特征提取,并减少因融合时下采样而导致的信息丢失。在能更好地区分和强化缺陷类间较小差异的情况下,更能精确检测到不同尺寸的皮革缺陷,从而确保图像中的大、小特征都能得到良好的捕捉。
第三步,将多尺度融合后的特征,馈送到区域提议网络(RPN)[19]中获取目标建议,并将这些建议传递给检测头实现皮革缺陷分类和定位,完成皮革缺陷的检测。为了更好地定位效果,本文将传统检测头替换为侧面感知边界定位(SABL)[19]检测头,以实现更加精准的缺陷定位。SABL检测头有助于减少由于皮革缺陷边界模糊或不清晰而引起的定位误差。在密集目标场景中,SABL有助于减少缺陷之间的干扰,提高多目标场景下的性能。分类、区域提议网络(RPN)及回归任务的损失函数均采用了Wang等[17]提出的SABL方法。本文的损失函数结合了RPN的损失和基于桶化边界框的SABL损失。整体损失表示为:
L=LRPN_cls+LRPN_bbox_reg+Lcls+Lbbox_cls+Lbbox_reg(4)
式中:前两项表示RPN损失,后三项表示SABL损失。
2 实 验
2.1 数据集和实验准备
为了全面捕捉生产线皮革表面的特性,本文从皮革工业生产线获取并筛选了309张分辨率为4 096×4 096像素的图片。在图像采集过程中,本文确保充分涵盖皮革表面的各种缺陷。随后,本文对这些图片进行了大小调整,将它们的尺寸缩减为640×640像素。本文采用了垂直翻转、水平翻转、[0,10]的随机缩放及[-10,10]的亮度调整等增强策略。通过这些数据增强的步骤,成功生成了总计2 549张图片。
为了更深入地理解这些缺陷情况,图4呈现了六种类型中具有代表性的图像,以凸显它们的显著特点。其中,折痕类是指皮革表面出现的明显折痕或褶皱,外观上呈现细长或曲线下陷,下陷程度不深且通常不规整,但部分表现形式会与凹
陷类类似,可通过下陷程度及折痕宽度进行判断。凹陷类是皮革表面出现的深度凹陷或坑洞,外观上呈现细长规整且深度凹陷,通常凹陷宽度不超过1 mm。刀伤类是皮革表面出现的切割或划痕,外观上呈现断裂、撕裂及细小直线或曲线划痕,且伤口较深。划痕类是皮革表面出现的线性或曲线形状的划痕,外观上呈现较为规律的大面积长条状浅表痕迹,极少数呈现规律细小浅表痕迹,与刀伤相比深度较浅。接缝类指在皮革制品的连接部分出现的线状结构,外观上呈现较为明显的大面积缝合或黏合痕迹。污点类皮革表面出现的颜色变化或污渍,外观上通常呈现大面积规律性细小浅表异物或污染物,少部分呈现小面积污点。正因同一缺陷表现形式不同,并且类间存在相似性,导致准确识别和分类这些缺陷需要一个高精度的自动视觉检测系统,能够有效处理类内和类间的变化、尺度的变动及纹理的复杂性。
本文的主要目标在于评估目标检测模型在本文构建的数据集上的性能表现。在获得高平均精度(Average Precision,AP)时,本文特别关注目标(皮革缺陷)的尺寸对结果的影响。对于那些尺寸相对一致的目标,相较于那些尺寸变化较大的目标,实现高AP更加具有挑战性。为了更加细致地了解缺陷检测方法的准确性,本文引入了交并比(Intersection over Union,IoU)来划分不同的AP值,并进行评估。IoU被定义为标签边界框与预测边界框之间的重叠区域与它们的并集之比。换言之,它量化了检测结果与实际目标位置之间的重合程度。因此,当IoU值越高时,说明检测器能够更准确地定位目标缺陷所在位置,从而反映了检测器的性能水平。当IoU阈值设定为0.75时,本文使用AP75作为评价指标;同理,当IoU阈值设定为0.50时,本文使用AP50来衡量目标检测的性能。同时本文还考虑小目标APS、中目标APM、大目标APL的AP测量值,分别是像素面积小于322、像素面积区间在[322,962]、像素面积大于962的目标框AP测量值。
在模型训练过程中,本文使用了mmdetection作为代码库。所有实验都是在NVIDIA GeForce RTX 4080 graphics card上进行的。对于模型训练,采用了以下超参数:初始学习率设定为0.002,权重衰减率为0.000 1。在实验中,本文采用随机动量梯度下降(SGDM)优化器,具体参数如下:学习率为0.001,动量值为0.900,权重衰减率为0.000 1。考虑到GPU内存的限制,本文将批处理大小设置为6。所有检测器的训练都是基于MS-COCO[20]数据集的权重进行。
2.2 实验结果
2.2.1 消融实验
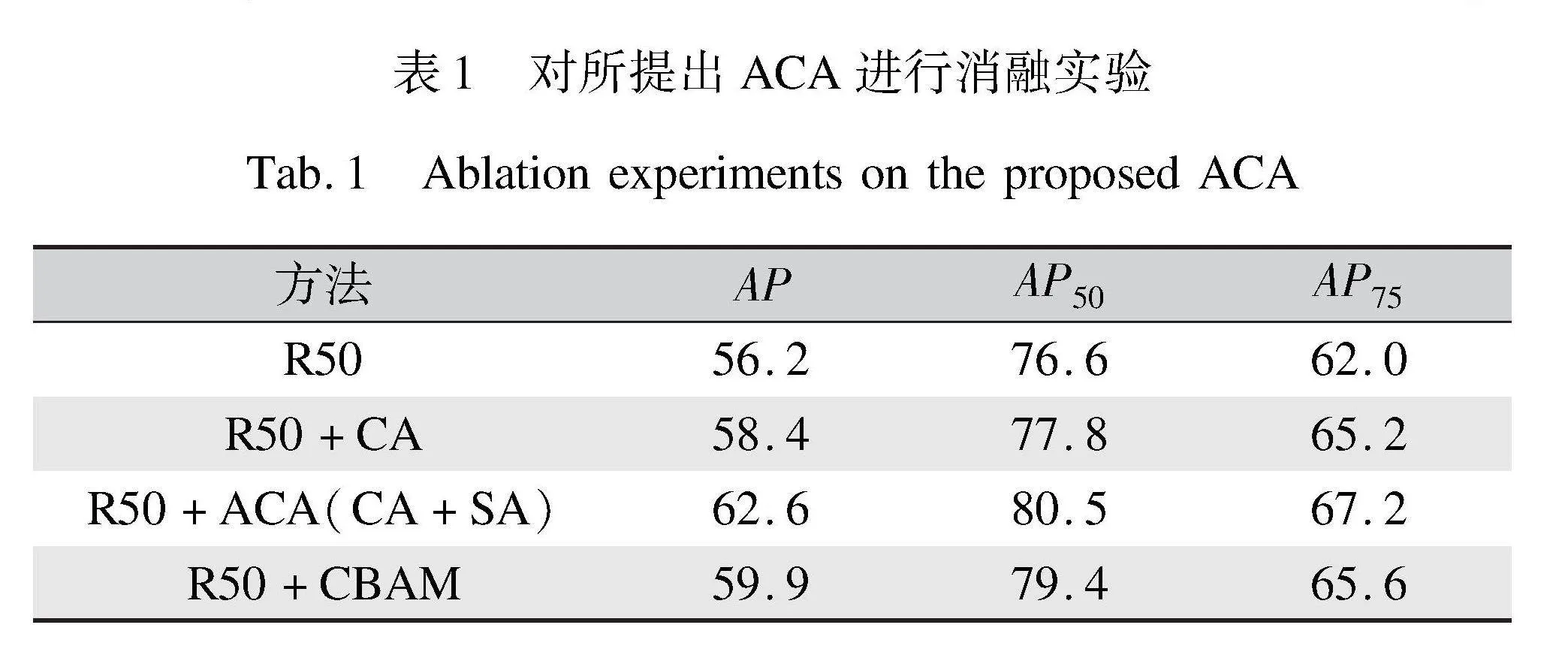
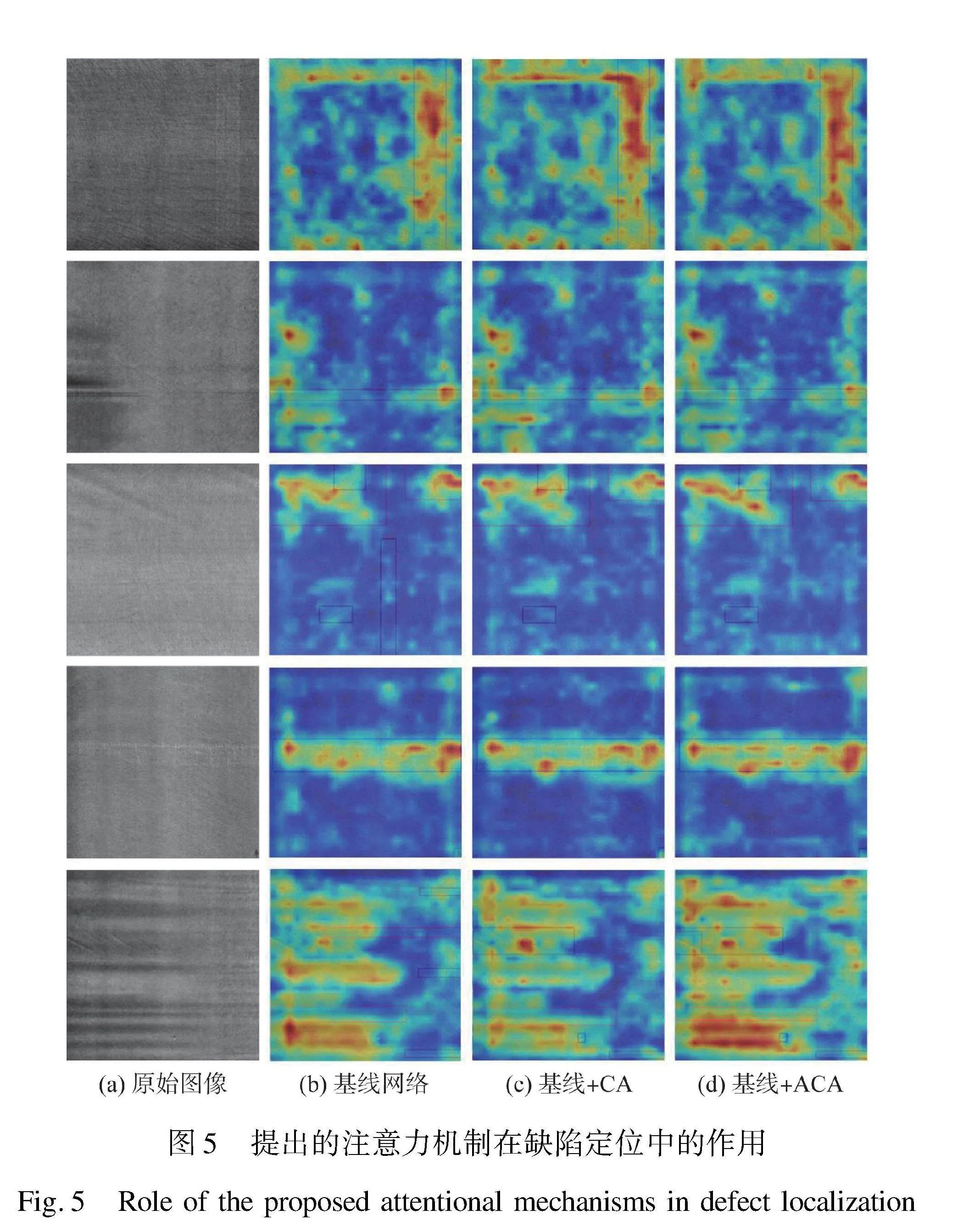
为了更好地理解ACA的贡献,本文进行了消融实验。本文先以ResNet50骨干网络作为基准模型,再通过逐步移除组成ACA中的通道注意力和空间注意力,然后将其和骨干网络组合,并记录模型性能,对实验结果进行分析,确认各个部件对基准模型地影响。具体而言,本文将图2中Backbone部分的ACA位置通过替换为CA、CBAM这两种模块,构建了本文消融实验所需的三种基准方法变体。在图5中比较了使用Grad-CAM[21]的框架对组件进行粗定位图。本文对比了基准方法ResNet50与三种基于注意力的变体ResNet50+CA组合、ResNet50+ACA(CA+SA)组合和ResNet50+CBAM组合。本文给出了这四类方法中具有代表性例子的粗略可视化结果。由图5(d)可以看出,基于ACA的方法更突出了缺陷区域,通过加强通道引导的特征和空间引导的定位,语义和空间信息得到提升,缺陷区域更加突出。从第1、3、4、5行的图像可以看出,ResNet50+ACA能对缺陷进行更精细的定位。
本文所提方法在AP方面的比较如表1所示。由表1可以得到几个重要结果是:1) 基线和基于注意力变体的量化结果证实了图5所示的视觉表征结果。2) 提出的ResNet50+ACA获得了比CBAM更好的性能,在AP、AP50和AP75分别提升了2.7%、0.9%和1.6%。这可以归因于ACA的特征表达能力。
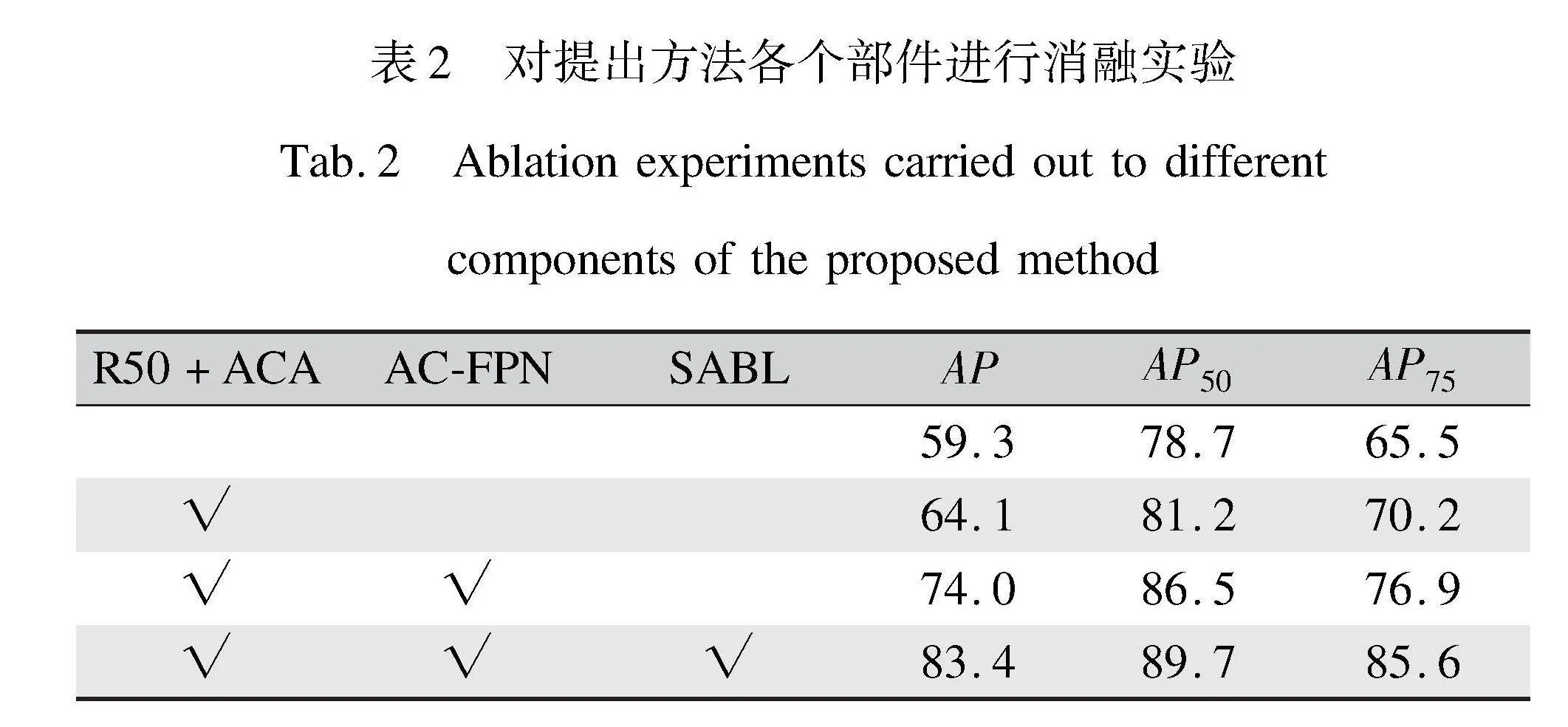
为了更好地理解所提出方法中各个部件的贡献,本文对方法中各个部件进行了消融实验,如表2所示。在表2中,本文对比了基准方法Cascade-RCNN(R50)[22]与骨干网络改进变体、多尺度融合改进变体及检测头改进变体三种,并分别对应所提出方法中的每一步。
由表2可以看出,基线和三种变体的量化结果,证实了各个部件都对皮革缺陷检测性能有不同程度的提升。在组合了三个改进部件后在AP上效果达到最好,相比一个改进组件和两个改进组件分别提升了18.9%和9.4%。
2.2.2 性能对比
选择最先进的方法和基准方法进行比较,包括Faster-RCNN、YOLOv3、Cascade-RCNN[22]及YOLOX和DAB-DETR检测网络和本文提出的方法进行比较。
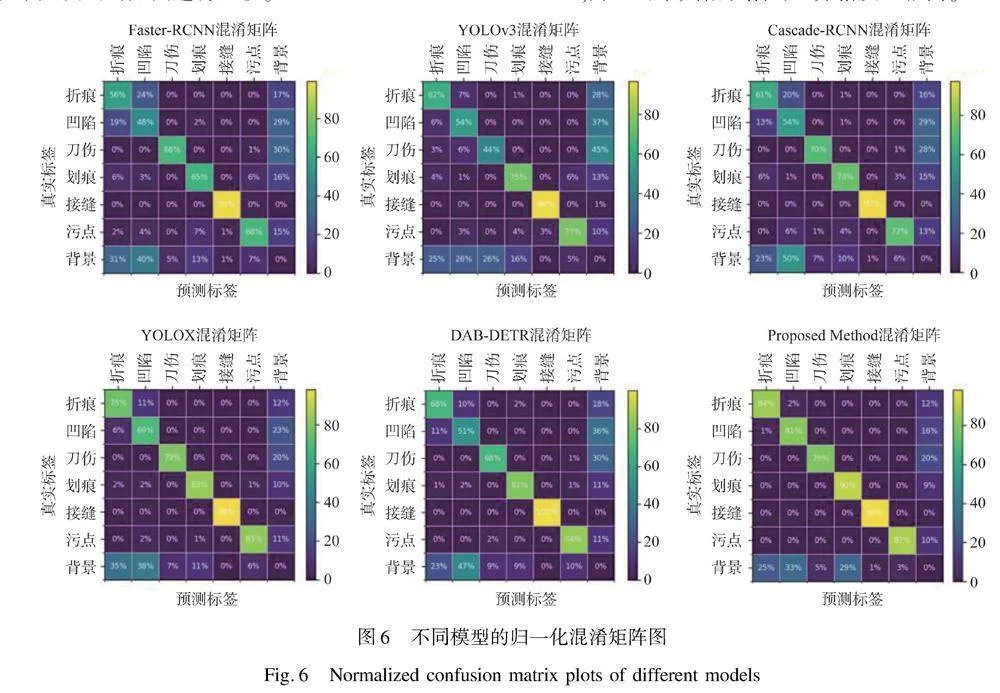
归一化混淆矩阵能够使本文更全面地了解模型的性能,尤其是在多类别分类问题中。与单一精度指标不同,归一化混淆矩阵可以展示每个类别的准确性和召回率,从而揭示不同类别之间的性能差异。由图6可以看到,除了本文提出的方法外,其他网络对于折痕类和凹陷类难以检测,精度较低,同时难以区分两类间的区别。而本文的方法能够很好地区分这两种类别的同时,相比其他检测网络准确性高了10%~30%,并且对于其他缺陷的区分精度也很高。
在测试集上对各种模型进行测试,使用AP、AP50、AP75、APS、APM和APL比较了所有这些模型的性能。由表3的比较结果表明,本文提出的方法极大地提升了皮革缺陷检测的性能,尤其对于AP和APS两个参数,其中AP为83.4,AP50为89.7,AP75为85.6。可以看出,尽管本文提出的方法在AP50上相比DAB-DETR高了1.6%,但在AP上有13.4%的提升,并且小目标、中目标及大目标上与DAB-DETR均有较大提升。提出的方法在小目标的检测上,比DAB-DETR提升了32.0%,在中目标的检测上提升了38.1%,大目标提升了19.5%。
与基线网络相比,AP从原本的60.8提升到了83.4,AP50从原本的84.4提升到了89.7,AP75从69.2提升到了85.6。对小、中、大目标的检测效果均有明显提升。可以看出本文的方法对皮革瑕疵检测能力提升明显,尤其在小瑕疵和中瑕疵上提升明显。
图7中,折痕类用红色(#DC143C)检测框表示,凹陷类用暗红色(#770B20)检测框表示,刀伤类用深蓝色(00008E)检测框表示,污点类用淡蓝色(0000E6)检测框表示。由图7检测对比可以看出,本文的方法能够在没有漏检和误检的情况下,很好区分折痕类和凹陷类这两种相似的缺陷类型。在第2行刀伤类的检测上本文的方法提升明显,检测结果和原始图像的检测框基本一致,更精准地检测出小尺寸的缺陷。在第3行图像中,提出的方法比baseline+CBAM减少了误检框,比DAB-DETR更精确地检测出红色检测框的折痕类;在深蓝色检测框的刀伤类中,提出方法对目标的定位最接近与原始图像的检测框。在第e1abaee7b9af960f761e5911ac23d5bd9d736cafba947f0cd2339288bc998e0a4行图像中,本文的方法对深蓝色小目标的漏检好于其他模型,对暗红色凹陷类不存在漏检,缺陷定位效果也好于其他模型。在第5行图像中,baseline+CBAM最右侧的凹陷类存在漏检,DAB-DETR凹陷类均未检出,而本文方法全部检出同时不存在误检漏检。
为了进一步验证本文方法的优越性,对不同尺寸的缺陷与其他方法进行了对比。图8展示了检测算法在小型缺陷数据上的结果,刀伤类用深蓝色检测框表示,凹陷类用暗红色检测框表示。相比基线网络,本文的方法消除了漏检。相比baseline+CBAM,本文方法检测出的结果置信度更高。同时在缺陷定位的准确性上,本文的方法更接近与标注框。
为了深入分析所提出的方法再皮革织物缺陷尺寸识别方面的有效性,本文针对最小缺陷和最大缺陷的情况做出了结果展示,如图9所示。经过本文测量,第2行最小缺陷的像素大小为5×3共15个像素点,占整幅图像面积的0.03‰。第1行最大缺陷的大小为637×241像素,共153 517个像素点,占整幅图像面积的37.4%。由此可以看出,本文提出的方法能够很好地在不同尺寸上进行皮革织物缺陷的检测,小至15个像素点,大至153 517乃至更大的缺陷目标。
2.3 结果分析
经过对图5和表1的分析可以发现,本文提出的ACA方法在处理皮革缺陷区域时具有更强的聚焦能力,能够有效凸显与背景相似的缺陷。具体来看,从图5的第3行中,ACA的注意力明显集中在图像的上半部分,成功地强化了缺陷,特别是不明显的缺陷。本文认为这主要归因于ACA中空间注意力使用不同大小的卷积核,当卷积核大小为3时,空间注意力更多地关注缺陷的细节特征;而当卷积核大小增至7时,空间注意力则更关注缺陷细节与整体图像的关系。这两种不同尺寸的卷积核相互配合,能够有效增强缺陷之间的差异性,将注意力集中在目标特征上,从而减少对背景信息的干扰响应。这一优势也在图7的第4行中得到了验证,与其他检测网络相比,本文的检测结果更接近于标注数据,以确保检测的准确性。
通过分析图7的第3行,本文可以观察到将FPN与ACA相结合后,缺陷定位相对于其他网络表现出更高的准确性,与标注数据一致,且没有漏检或误检情况。这表明改进后的AC-FPN在缺陷定位方面取得了显著效果,借助ACA增强的特征信息,在不同尺度之间进行流动,使网络能够更精细地区分缺陷与背景,从而确保准确地定位皮革织物缺陷。同样的结论也可以从第5行中得出,并且本文通过观察图7第4行可以发现,同时出现多个缺陷时,本文的方法依旧能够精准地将每一个缺陷检测出来,也能进行不同类型的区分。这一结果本文认为归因于AC-FPN和SABL检测头的组合作用,AC-FPN负责将不同尺度的缺陷特征信息进行结合,实现不同尺度下对缺陷的识别,SABL负责将识别出的缺陷进行精确的定位。
根据表2的消融实验结果,随着不同改进的逐步叠加,皮革织物缺陷检测效果逐渐提升,最终在三种改进结合的情况下达到最佳效果。通过表3和图7的观察,可以发现本文所提出的方法能够动态学习和调整不同通道之间的特征重要性,使网络更加专注于关键特征,减少对冗余信息的关注,从而获得比其他缺陷检测网络更优异的检测效果。该方法能够有效适应不同尺度和位置的目标,以提高检测的鲁棒性和准确性。
尽管本文的方法具有上述优势,但仍存在一些局限性:首先,本文的方法需要大量图像才能实现良好的检测性能,而且这些图像中可能存在多种形式的皮革缺陷;其次,与背景相似的皮革缺陷对于本文的方法仍然会导致误检,这与其他方法面临的问题类似;此外,目前本文所使用的数据集主要包含灰度图像,这可能会降低对于部分彩色皮革缺陷的有效信息提取能力。未来的研究方向可以考虑采用彩色相机获取皮革缺陷图像,并针对误检问题展开更深入的探讨。
3 结 论
本文提出了一项新的方法用于检测生产线上的皮革织物瑕疵,以解决不同织物缺陷类间相似特征的问题,并且构建了工业皮革数据集。所提出的方法采用了一种创新的多层次残差卷积注意力(ACA),能够很好地区分和捕捉缺陷类内差异并强化缺陷类间较小的差异。该模块通过残差结构将通道注意力进行加强,增强语义的特征表示能力,选用两个不同大小的滤波核进行空间注意力操作,以增强网络抽取特征的语义信息和空间信息。并且将ACA与特征金字塔相结合,提出了一种新的基于通道和空间的注意力特征金字塔,有选择地捕获来自不同域的上下文信息,并产生更多的鉴别性特征,充分利用了多尺度和跨通道的特征信息,增加语义信息。再结合SABL检测头使得皮革缺陷定位更加准确。因此,本文的方法能够有选择地保留关键特征,以实现鲁棒的检测和定位,很好地区分和捕捉缺陷类内差异并强化缺陷类间较小的差异,同时抑制不必要的信息。与目前领先的检测网络相比,本文的方法表现出了竞争力强的性能,从而为皮革织物表面自动化缺陷检测提供了新的思路及可行性。
《丝绸》官网下载
中国知网下载
参考文献:
[1]韩小龙, 吕晓峰. 计算机图像处理皮革瑕疵自动检测分级技术研究[J]. 中国皮革, 2023, 52(1): 25-28.
HAN X L, L X F. Automatic detection and classification of leather defects by computer image processing[J]. China Leather, 2023, 52(1): 25-28.
[2]ANSHORI M F, PURWOKO B S, DEWI I S, et al. Cluster heatmap for detection of good tolerance trait on doubled-haploid rice lines under hydroponic salinity screening[J]. IOP Conference Series: Earth and Environmental Science, 2020, 484(1): 012001.
[3]崔扬. 图像检测技术在皮革缺陷检测中的应用研究[D]. 杭州: 浙江大学, 2004.
CUI Y. Study on Image Detection Technique and Its Application on Detecting Defects of Leather[D]. Hangzhou: Zhejiang University, 2004.
[4]ASLAM M, KHAN T M, NAQVI S S, et al. Putting current state of the art object detectors to the test: Towards industry applicable leather surface defect detection[C]//2021 Digital Image Computing: Techniques and Applications (DICTA). New York: IEEE, 2021.
[5]ASLAM M, KHAN T M, NAQVI S S, et al. Learning to recognize irregular features on leather surfaces[J]. Journal of the American Leather Chemists, 2021, 116(5): 169-178.
[6]ASLAM M, KHAN T M, NAQVI S S, et al. Ensemble convolutional neural networks with knowledge transfer for leather defect classification in industrial settings[J]. IEEE Access, 2020(8): 198600-198614.
[7]KHANAL S R, SILVA J, MAGALHAES L, et al. Leather defect detection using semantic segmentation: A hardware platform and software prototype[J]. Procedia Computer Science, 2022(204): 573-580.
[8]GAN Y S, LIONG S T, ZHENG D, et al. Detection and localization of defects on natural leather surfaces[J]. Journal of Ambient Intelligence and Humanized Computing, 2021(14): 1785-1799.
[9]ZHANG Z L, FU Y, HUANG H L, et al. Lightweight network study of leather defect segmentation with Kronecker product multipath decoding[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13782-13798.
[10]ITTI L, KOCH C, NIEBUR E. A model of saliency-based visual attention for rapid scene analysis[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1998, 20(11): 1254-1259.
[11]WANG F, JIANG M, QIAN C, et al. Residual attention network for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Hawaii: IEEE, 2017: 3156-3164.
[12]HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 7132-7141.
[13]ZHANG X N, WANG T T, QI J Q, et al. Progressive attention guided recurrent network for salient object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 714-722.
[14]LI T P, SONG H H, ZHANG K H, et al. Recurrent reverse attention guided residual learning for saliency object detection[J]. Neurocomputing, 2020(389): 170-178.
[15]WOO S, PARK J, LEE J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). Berlin: Springer Science, 2018: 3-19.
[16]LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Hawaii: IEEE, 2017: 2117-2125.
[17]WANG J, ZHANG W, CAO Y, et al. Side-aware boundary localization for more precise object detection[C]//Computer Vision-ECCV 2020: 16th European Conference (ECCV). Glasgow: Springer International Publishing, 2020: 403-419.
[18]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2016: 770-778.
[19]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[20]LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: Common objects in context[C]// Computer Vision-ECCV 2014: 13th European Conference (ECCV). Berlin: Springer International Publishing, 2014: 740-755.
[21]SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2017: 618-626.
[22]CAI Z W, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 6154-6162.
A multi-scale adaptive attention detection model for leather fabric defect detection
ZHANG Chi, WANG Xiangrong
LI Hao1, LIU Yifan1, XU Huawei2, YANG Ke1, KANG Zhen1, HUANG Mengzhen1, OU Xiao1, ZHAO Yuchen1, XING Tongzhen1
(1.School of Mathematics & Computer Science, Wuhan Polytechnic University, Wuhan 430048, China;2.Hexin Kuraray Micro Fiber Leather (Jiaxing) Co., Ltd., Jiaxing 314003, China; 3.Institute ofFlexible Electronics Technology of THU, Jiaxing 314006, China)
Abstract:
Leather products are widely used across various fields, permeating every aspect of daily life. However, during the production of synthetic leather fabrics, defects are inevitable, directly affecting the quality and price of leather products. Early identification of these defects in the production process can prevent further production losses. Nevertheless, the high local similarity of defects on leather fabric surfaces causes significant similarities between different types of defects, leading to poor detection results. To address this issue, the article proposed an end-to-end defect detection method for leather fabric surfaces, achieving finer granularity in distinguishing leather defects.
To address the high similarity between defect classes, this paper introduced an adaptive convolutional attention (ACA) module. This module comprises channel attention and spatial attention, integrating the channel and spatial attention information through a residual structure to generate more discriminative features. Two different-sized convolutional kernels in the spatial attention work in concert to effectively enhance the differences between defects, focusing attention on target features and thus reducing the interference response to background information. To amplify the differences between leather fabric defect classes, ACA was incorporated into the backbone network to enhance the semantic feature representation capabilities. This integration not only improves the network’s ability to differentiate between defect types but also ensures more accurate detection outcomes. Then, the article designed a feature pyramid network based on adaptive convolutional attention (AC-FPN) to improve multi-scale fusion. By leveraging the feature information enhanced by ACA, the network enables the flow of information between different scales, allowing for finer differentiation between defects and background. Such enhancement significantly improves the detection capability of defects at different scales, achieving finer granularity in leather defect differentiation. The multi-scale fusion process ensures that defects of various sizes and shapes are accurately detected, regardless of their scale, contributing to a more robust detection system. Finally, the traditional detection head was replaced with the side-aware boundary localization (SABL) detection head, enabling precise localization of leather fabric defects. The SABL detection head is specifically designed to enhance the accuracy of defect localization by focusing on the boundaries of defects, ensuring that even the smallest and most subtle defects are accurately identified and localized. This replacement is crucial for improving the overall precision of the defect detection system, making it more reliable for practical applications in leather fabric production.
The article validated the proposed method using a self-constructed leather fabric dataset and compared it with different methods. Experimental results demonstrate that the proposed method achieves better performance in distinguishing between different defect types with similar appearances. Compared to other methods, this method exhibits superior detection accuracy across various defect types, with AP, AP50, and AP75 evaluation metrics reaching 83.4, 89.7, and 85.6, respectively. This provides a new perspective for automated surface defect detection of leather fabrics. The improved accuracy metrics indicate that the proposed method is highly effective in identifying and classifying defects, with significant improvement over existing methods.
The proposed defect detection method for leather fabrics demonstrates better performance compared to other methods, offering new feasibility for defect detection. Despite the advantages mentioned above, the use of a dataset primarily comprising grayscale images may reduce the ability to extract effective information for some colored leather defects. In future research, color cameras can be used to capture images of leather defects and incorporate color information to distinguish some leather fabric surface defects. Additionally, exploring advanced image processing techniques and integrating them with the current approach could further enhance the defect detection capabilities, so as to make the system more versatile and applicable to a wider range of leather products.
Key words:
attention mechanism; multi-scale information; defect detection; convolutional neural network; defect classification; leather fabric
