
融合预训练语言模型的知识图谱在政务问答系统中的应用研究
2024-10-09 00:00:00张朝阳沈建辉叶伟荣
数字通信世界 2024年9期

摘要:该文针对当前政务问答系统面临的复杂语境理解、政策法规解释等问题,探讨了如何将预训练语言模型与知识图谱进行有效融合,以实现更加精准、全面和个性化的政务信息问答服务,构建了政务问答系统框架,利用知识图谱和大模型工具验证了该方法在提高问答准确率、增强上下文理解能力方面的显著优势。
关键词:知识图谱;自然语言处理;预训练语言模型;三元组;知识库
doi:10.3969/J.ISSN.1672-7274.2024.09.063
中图分类号:TP 3 文献标志码:A 文章编码:1672-7274(2024)09-0-03
Research on the Application of Knowledge Graph Integrated with Pre-trained Language Models in Government Question-answering Systems
ZHANG Chaoyang, SHEN Jianhui, YE Weirong
(Zhejiang Public Information Industry Co., LTD., Hangzhou 310000, China)
Abstract: Aiming at the problems of complex context understanding and interpretation of policies and regulations faced by the current government question answering system, this paper discusses how to effectively integrate pre-trained language models and knowledge graphs, so as to realize more accurate, comprehensive and personalized government information question answering service. The framework of government question answering system is constructed, and the significant advantages of this method in improving the accuracy of question answering and enhancing the context understanding ability are verified by using knowledge graph and large model tools.
Keywords: knowledge graph; natural language processing; pre-trained language model; triple; knowledge base
0 引言
政务问答系统的核心在于如何更好地建模语言、理解和输出文本信息,本文以政务服务垂直领域在线咨询问答场景为例,探索预训练语言模型与知识图谱的融合应用。
1 理论基础及相关工作
1.1 预训练语言模型研究进展
预训练语言模型[1]是近年来自然语言处理领域的重要突破,其核心思想是通过大规模无标签文本数据进行自监督学习,从而获得对语言深层次结构和语义的理解能力。2017年,谷歌团队提出了Transformer模型。基于此,Devlin等人提出了BERT预训练模型,极大地提高了机器阅读理解模型的性能,BERT[2]采用了双向Transformer编码器,GPT系列则使用了单向Transformer解码器。GPT-4[3]等后续模型则主要通过因果关系模型来预测下一个单词。预训练语言模型经历了从ELMo[4]到BERT,再到GPT、T5、RoBERTa、ALBERT[5]等一系列迭代升级,涌现出诸多基于BERT模型的变体,如Macbert[6]、ALBERT和AMBERT等。国内科技公司和科研机构纷纷发力相继推出了百度“文心一言”、腾讯“混元”大模型、阿里“通义千问”、华为盘古大模型、智谱清言、讯飞星火等一系列国产大模型。预训练语言模型在数字政府领域应用场景涉及智能客服与问答、文档理解和信息提取、舆情分析与事件监测、政务知识图谱等。
1.2 知识图谱在问答系统中的作用
1.2.1 政务问答系统的挑战
政务问答系统在实现智能化即时互动的同时,面临诸多挑战。政务数据分布在不同部门和系统中,整合难度大。用户咨询的问题可能涉及复杂语境、多种表达方式,系统需具备高精度的自然语言处理能力,理解用户的真实意图。问答系统应能快速适应新出台的法律条文,不断引入AI、深度学习等前沿技术,降低维护成本并提高服务效能。
1.2.2 知识图谱在问答系统中的作用
针对政务问答系统面临的以上挑战,利用知识图谱技术能够显著提升问答系统的性能和智能化程度。知识图谱提供了丰富的语义上下文和关系结构,使得问答系统能够理解问题背后的复杂意图,并通过关系推理来找到答案。基于知识图谱,问答系统可以进行高效且精准的信息检索,利用实体之间的关联快速定位相关信息,从而给出准确的答案。
1.3 融合预训练模型与知识图谱的最新研究
张鹤译[7]等提出,融合大型语言模型与专业知识库基于提示学习的问答系统范式,并实证了该方法有助于解决专业领域问答系统数据+微调范式带来的灾难性遗忘问题。在医学大模型BioLAMA和MedLAMA中,通过利用医学知识图谱来探索大语言模型中的医学知识应用。医疗大模型华驼(本草)在参考中文医学知识图谱的基础上,基于中文医学知识的LLaMA微调模型,采用了公开和自建的中文医学知识库,使语言模型具备像医生一样的诊断能力。百度“文心一言”、通义千问等国产大模型在训练过程中也融入了丰富的知识资源,增强了模型的知识理解和推理能力。
2 知识图谱在政务领域的构建策略
2.1 政务知识库
为满足政务信息智能问答需求,需收集涵盖各政府部门、公共服务机构及社会关注热点的所有相关政策、法规、办事指南、常见问题解答等信息,构建政务知识库。统一知识条目的分类、编码、格式等标准,便于检索、管理和使用。
2.2 政务问答知识抽取与建模
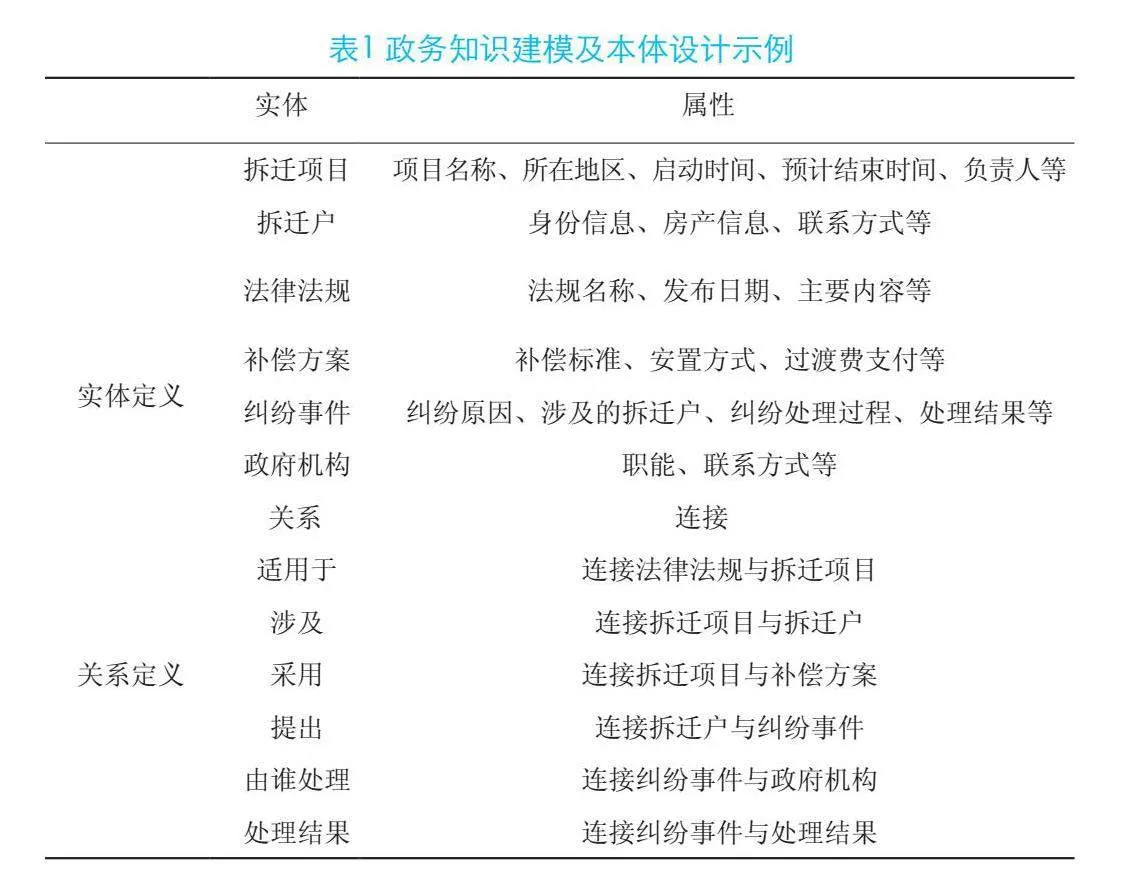
政务知识图谱的知识建模与本体设计过程是将政务领域内的实体、属性和关系以一种结构化和标准化的方式来表示。通过设计政务领域专属本体,定义实体类别、属性以及关系类型,构建适合政务场景的知识表示框架。将抽取出来的实体及其关系整合到知识图谱中,通过链接和推理填补缺失信息,形成一个结构化的知识网络,如表1所示。
3 融合大模型与知识图谱的问答系统构建方法
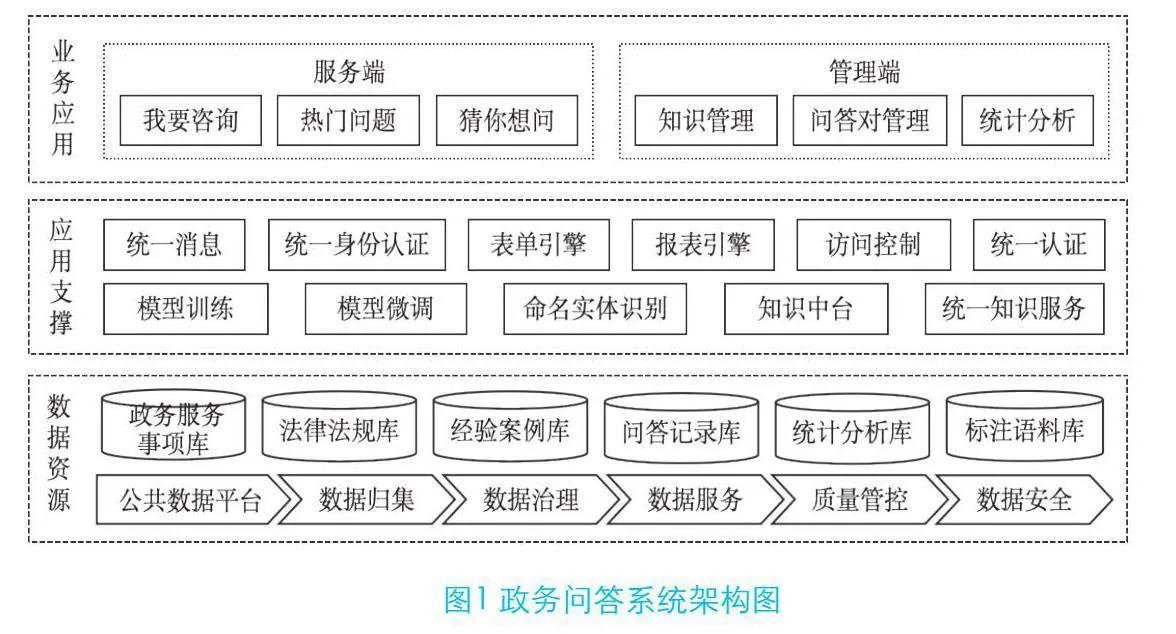
3.1 系统总体框架
政务问答系统基于政务知识库,通过大模型和知识图谱融合进行预训练和微调,完成信息抽取、知识分类等任务,并通过知识推理、问答交互支撑服务端的在线咨询交互场景。
3.2 融合预训练模型与知识图谱的问答机制
利用预训练模型对政务知识进行知识抽取主要包括以下几个主要步骤:
(1)选择预训练模型。大部分预训练模型基于或参考了BERT的多层Transformer结构。标注语料经过BERT预训练语言模型获得相应的词向量,之后再把词向量输入到BiLSTM模块中做进一步处理,最终利用CRF模块对BiLSTM模块的输出结果进行解码,得到一个预测标注序列,然后对序列中的各个实体进行提取分类。
(2)数据集准备及预处理。数据集包括开源文本集、法规政策文件、权力事项清单、常用典型问答等,由业务专家辅以标注处理,对原始文本数据进行分词、词语切分、填充或截断等预处理操作,使其符合预训练模型的输入格式要求。本文选择开源中文本数据集和自有业务数据作为实验数据,包括THUCNews数据集、MSRA数据集、PKU人民日报语料库、法律法规、典型案例问答。
(3)模型微调。对选定的预训练模型进行适应性训练,加载预训练模型权重;根据具体任务构建下游任务的模型架构,例如,在预训练模型顶部添加额外的分类层或序列标注层,将预训练模型应用于知识抽取任务的数据集上,通过反向传播和优化算法更新模型参数,使模型能够学习到抽取所需知识的规律。本文通过业务专家标注和注入专业知识库方式增强回答的专业性。
(4)任务适配。对不同知识抽取任务进行任务适配,实体识别模型需要预测每个词的标签,标识出文本中的实体边界及其类别,关系抽取模型需要同时考虑实体对及其上下文信息,预测实体之间的关系类型,事件抽取模型要识别事件触发词和事件角色。本文利用HanLP生成三元组数据用于构建知识图谱,再将知识图谱中的实体和关系转化为向量表示,与语言模型进行融合。
(5)融合训练、验证及优化。将数据集划分为训练集、验证集和测试集,在预训练模型的基础上添加知识图谱嵌入层,让模型在处理文本时能访问知识图谱中的信息。在语言模型的中间层插入知识图谱嵌入层,使模型生成答案时考虑到知识图谱提供的实体和关系信息。
4 实验结果
本文选用具有62亿参数的语言模型ChatGLM-6B,GeForce RTX 4090系列显卡。将同一问题分别输入以下三种问答工具:①基于传统神经网络算法的问答系统;②未注入专业知识的GLM-6B;③融合专业领域知识图谱的GLM-6B,并根据三组输出答案来评估相应工具的准确率、满意度等。
综合来看,知识图谱能够有效地辅助语言模型在处理问题时找到正确的答案,特别是在涉及事实性问题、领域专业知识和复杂推理的任务中,知识图谱的作用尤为突出。
5 结束语
预训练模型模型融合知识图谱在政务问答系统的应用将朝着更智能、个性化、跨领域、多模态交互等方向发展,系统将能够处理更复杂的查询,包括多跳推理、语义理解等,结合用户画像和用户历史交互数据,政务问答系统将能够提供更加个性化的服务。同时,政务问答系统应注重安全与隐私保护。在大模型多模态交互应用方面,有望支持多种交互方式,包括文本、语音、图像等,提供更自然和便捷的用户体验。
参考文献
[1] 王昀,胡珉,塔娜,等.大语言模型及其在政务领域的应用[J/OL].清华大学学报(自然科学版),2024,64(4):1-10.[2024-03-11]. https://doi.org/10.16511/j.cnki.qhdxxb.2023.26.042.
[2] DEVLIN J, CHANG M W, LEE K,et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Minneapolis, USA: Association for Computational Linguistics,2018:4171 4186.
[3] Openai.GPT-4 technical report [R/OL]. .https://arxiv.org/abs/2303.08774.2023.
[4] 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans, USA: Association for Computational Linguistics,2018:2227 2237.
[5] LANZZ,CHEN M D,GOODMANS,etal.ALBERT:A lite BERT for self-supervised learning of language representations[J/OL].arXiv.(2019-09-26)[2023-06-12].https://arxiv.org/abs/1909.11942.
[6] CUI Y, CHE W, LIU T, et al. Revisiting pre-trained models for Chinese natural language processing[EB/OL]. [2023-07-17]. http://arxiv.org/abs/2004.13922.
[7] 张鹤译,王鑫,韩立帆,李钊,陈子睿.大语言模型融合知识图谱的问答系统研究[J/OL].计算机科学与探索,2023,17(10):2377-2388.
