
数据挖掘技术在计算机网络病毒防御中的实践应用
2024-10-09 00:00:00吕敬兰
数字通信世界 2024年9期

摘要:随着互联网的普及和深入发展,计算机网络病毒已经成为威胁网络安全的重要因素。传统的病毒防御方法,如防火墙、入侵检测系统等,在面对复杂多变的网络病毒时显得力不从心。数据挖掘技术作为一种从海量数据中提取有用信息的方法,为计算机网络病毒防御提供了新的思路。该文将从数据挖掘技术的原理、方法及其在计算机网络病毒防御中的实践应用等方面进行探讨。
关键词:数据挖掘;计算机网络病毒;防御
doi:10.3969/J.ISSN.1672-7274.2024.09.048
中图分类号:TP 393.08 文献标志码:B 文章编码:1672-7274(2024)09-0-03
The Practical Application of Data Mining Technology
in Computer Network Virus Defense
LV Jinglan
(Guizhou Agricultural Vocational College, Guiyang 551403, China)
Abstract: With the popularization and in-depth development of the Internet, computer network viruses have become an important factor threatening network security. Traditional virus defense methods, such as firewalls and intrusion detection systems, appear inadequate when facing complex and ever-changing network viruses. Data mining technology, as a method of extracting useful information from massive data, provides new ideas for computer network virus defense. The article will explore the principles, methods, and practical applications of data mining technology in computer network virus defense.
Keywords: data mining; computer network viruses; defense
随着信息时代的来临,计算机网络日益普及,极大地便利了数据的传输与分享,也为网络病毒的传播提供了更多的机会。网络病毒复杂性不断升级,使工作人员防范工作难度不断加大。探讨数据挖掘技术在计算机网络病毒防范中的应用,能够提升网络安全性,有效应对不断演变的病毒威胁[1]。
1 基于特征选择的分类方法在病毒防御中的应用
1.1 特征选择的概念和意义
特征选择是机器学习和数据挖掘中的一项关键技术,旨在从原始数据集中挑选出最相关、最具代表性的特征子集,用于构建分类模型。在病毒防御中,特征通常指的是病毒或恶意软件的各种静态和动态属性,如代码片段、行为模式、网络活动等。
随着网络技术的不断进步,病毒和恶意软件的复杂性也同步增长,使特征选择技术也变得尤为重要。其不仅能显著降低病毒数据的维度,剔除冗余信息,减少计算的复杂性和存储需求,还能提高分类器的准确性,帮助分类器更专注于病毒行为的紧密相关特征。此外,它能够增强模型的可解释性,为安全专家提供更易理解的分析依据。在面对不断变异的病毒威胁时,特征选择有助于捕捉病毒的本质特征,保持对新型威胁的检测能力。在实时病毒检测中,特征选择更是能够优化性能,降低处理时间和资源消耗,使得实时防御成为可能,为网络安全加固了防线。
1.2 基于特征选择的分类方法的原理和流程
在网络病毒防御中,特征选择分类方法的核心思想是从大量病毒数据中筛选出最具区分能力的特征,用于训练分类器以准确识别未知文件。这种方法强调“精益求精”,即使用少量但高质量的特征,而非全部特征,实现高效分类。通过特征选择,进一步去除冗余和不相关的特征,降低数据维度,提高分类器的性能和效率。精心选择的特征子集还能增强模型的可解释性,使安全专家能够更容易理解和信任模型的决策过程。在面对不断演变的病毒威胁时,特征选择的分类方法可提供一种有效的方式来保持防御系统的实时性和准确性,进而加固网络安全的防线[2]。
1.3 实际案例分析:基于特征选择的病毒识别模型的构建和应用
针对KDD数据集,特别是其20%的子集,特征工程的处理至关重要。由于数据集中每个样本包含41个特征值,并且部分特征是字符型的,直接用于机器学习模型可能会导致性能不佳或结果不准确。对于KDD数据集,特别是含有字符型特征的数据,one-hot编码常常被用于转换这些特征,但是会导致特征空间的急剧增加,进而产生大量的冗余特征,增加计算的复杂性,导致过拟合,影响模型的泛化能力。为了有效解决这一问题,结合粒子群优化算法和决策树的方法进行特征选择是较为可行的方法。粒子群优化算法能够智能地搜索特征空间,找出与输出变量最相关的特征子集,而决策树则能够基于这些选定的特征构建分类模型,实现高效的检测分类[3]。
one-hot编码是一种将类别变量转换为机器学习算法易于利用的格式的方法。具体来说,对于每一个字符型特征值,one-hot编码都会创建一个新的二值特征。举个例子,假设特征1包含“ABC”三种字符型特征值,采用one-hot编码后,原始的特征1将被删除,取而代之的是三个新的特征,即特征1_A、特征1_B和特征1_C。如果样本在原始特征1上的值是A,那么在新的特征1_A上的值就是1,在特征1_B和特征1_C上的值就是0,即表示为100。同理,如果原始值是B或C,则分别表示为010和001。
经过对KDD数据集的one-hot编码处理,虽然成功地将字符型特征转换为数值型特征,但同时也导致特征维度的显著增加,每个样本的特征数由原来的41个增加到118个,增加了计算的复杂性,更重要的是其中包含大量的冗余和不相关特征,对分类器的性能产生负面影响,导致分类精度降低。为了解决这一问题,采用粒子群优化(PSO)算法进行特征选择。PSO算法是一种模拟鸟群觅食行为的优化算法,通过粒子之间的信息共享和协作,能够在复杂的搜索空间中找到最优解。在特征选择中,每个粒子代表一个特征子集,通过不断迭代更新粒子的位置和速度,搜索到一组最优特征子集,使基于这组特征子集的分类器能够达到最高的分类精度[4]。
2 聚类分析在病毒防御中的应用
2.1 聚类分析的概念和算法
聚类分析在病毒防御中具有不可或缺的应用价值,核心理念是将相似或相关的对象集结成群,区分不同的数据模式。在网络安全领域,它能够高效识别网络异常,为专家提供及时的威胁预警。具体而言,聚类分析在网络流量监控中能够识别不寻常的流量模式,进而揭示潜在的网络攻击。在恶意软件检测方面,聚类分析根据软件的行为和代码结构进行分类和识别,无论是已知还是未知的恶意软件。此外,通过聚类分析可分析系统日志和用户行为数据,能够发现异常登录和非法访问等入侵行为。
在算法层面,聚类分析有划分法、层次法,以及基于密度、基于网格和基于模型的方法等多种实现方法,其各有特色,适用于不同的数据和应用场景。在实际运用中,选择哪种聚类算法取决于具体的数据特性和分析需求。可见,聚类分析凭借其强大的数据分类和模式识别能力,已成为病毒防御体系采用的关键技术,为网络安全提供了有力的技术支撑。
2.2 实际案例分析:基于聚类分析的病毒家族发现与分析
Android平台是智能手机上最流行的操作系统之一,其上有数百万个应用程序供用户选择。这些应用丰富了用户的生活,提供了便捷的服务和娱乐。然而,随着其普及,Android手机也成为了恶意软件的目标。由于Android允许用户从多种来源安装应用,如应用市场和论坛,导致恶意软件易于传播。根据报告,2022年恶意安装包数量激增,是2021年的3倍多。尽管Android有权限系统限制恶意软件的安装,但用户往往忽视权限请求的重要性,使这一安全措施的效果大打折扣。因此,恶意应用往往能绕过Android权限系统的限制,对用户构成威胁。
3 关联规则挖掘在病毒防御中的应用
3.1 关联规则挖掘的概念和算法
在病毒防御中,项可以是网络请求、系统调用或特定的文件操作,而频繁出现的项集可能揭示了恶意软件的特定行为模式。随着网络攻击和恶意软件的日益猖獗,病毒防御技术也在不断演进。关联规则挖掘作为一种重要的数据分析工具,被广泛应用于识别和防御恶意行为。其中,Apriori和FP-growth是两种代表性的算法。
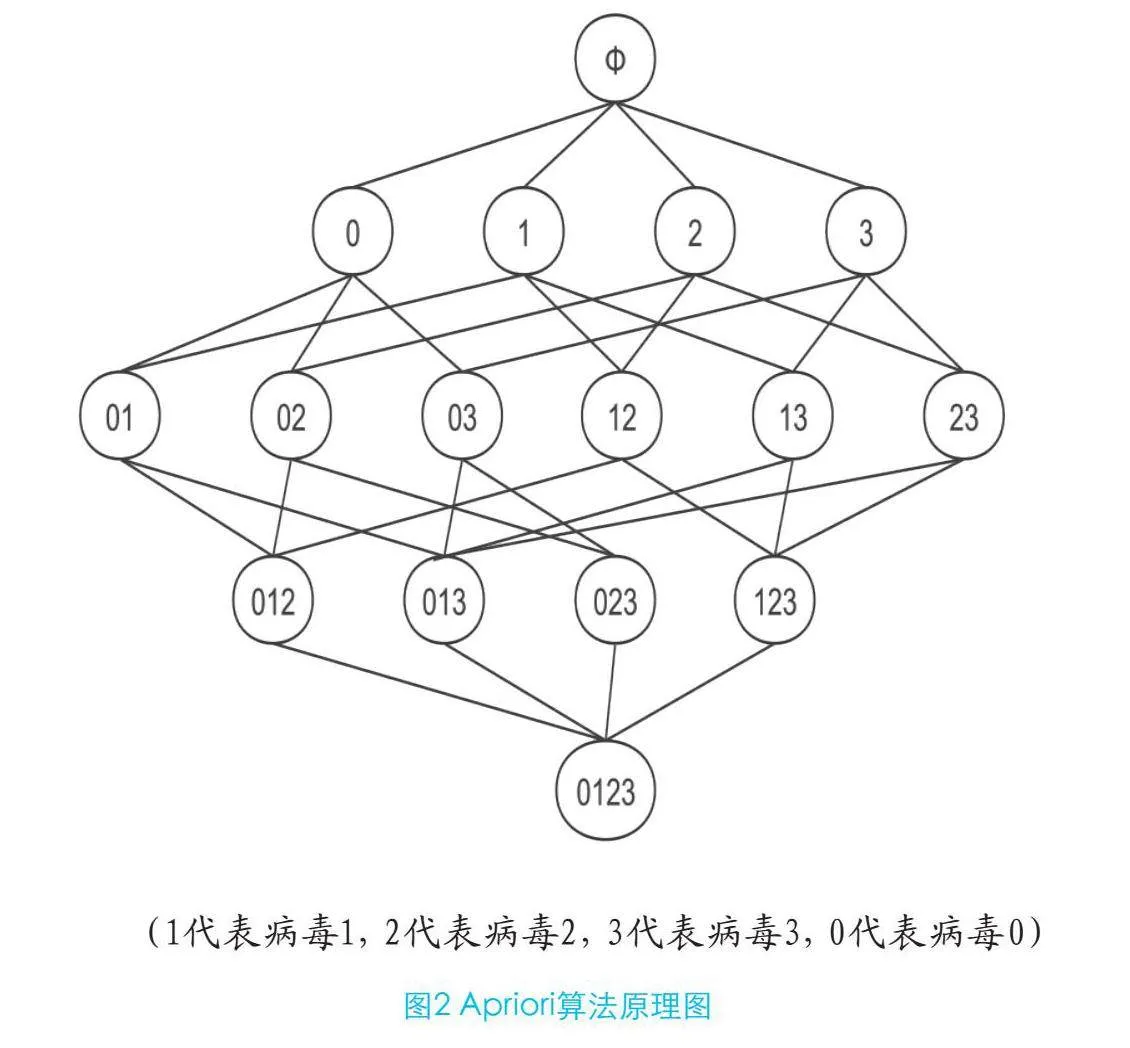
Apriori算法是关联规则挖掘的经典之作,其工作原理是通过逐层搜索的迭代方法,从数据集中找出频繁项集。这种方法基于一个核心性质,即如果一个项集是频繁的,那么它的所有非空子集也必须是频繁的。这一性质大大减少了搜索空间,提高了算法的效率。在病毒防御中,Apriori是帮助安全专家识别恶意软件的常见行为模式,其原理如图2所示。
在处理大量数据以寻找频繁项集时,计算所有组合的支持度是一项巨大的任务。例如,仅考虑3个病毒,需计算15次不同组合的支持度。随着病毒数量的增加,这种计算量将急剧上升,呈指数增长,这在计算上是非常不经济的。
与Apriori不同,FP-growth并不直接生成候选项集,而是通过构建一棵称为FP树的数据结构来挖掘频繁项集。这种方法不仅减少了数据库扫描的次数,还通过共享前缀的方式压缩了数据结构,从而显著提高了算法的效率。在病毒防御中,FP-growth算法能够迅速识别出隐藏在大量数据中的恶意行为模式,为安全专家提供及时的警报和应对建议。尤其是在面对不断演变的恶意软件和复杂的网络攻击时,FP-growth的高效性能为防御系统提供强大的支持。
3.2 关联规则挖掘在病毒传播路径分析和异常行为检测中的应用
关联规则挖掘作为一种强大的数据挖掘技术,在病毒传播路径分析和异常行为检测中发挥着重要作用。面对不断变化的网络威胁和恶意软件攻击,有效分析病毒传播路径和准确检测异常行为对于保护信息安全至关重要。在病毒传播路径分析中,关联规则挖掘能够帮助安全专家发现恶意软件在网络中的传播模式,分析感染主机之间的关联关系,如通信记录、共同访问的恶意网站等,揭示出病毒传播的路径和趋势,及时阻断病毒的传播链,防止感染范围进一步扩大。
3.3 实际案例分析:基于关联规则挖掘的病毒传播路径分析
近年来,随着网络技术的快速发展,恶意软件的传播方式和攻击手段也变得越来越复杂。如在某次严重的病毒爆发事件中,关联规则挖掘技术发挥了重要作用,帮助人们深入分析了病毒的传播路径。该病毒主要通过电子邮件附件和网络下载进行传播,感染用户计算机后,会窃取用户的敏感信息,并通过网络将这些信息发送到攻击者的服务器。为了有效应对这一威胁,安全团队采用关联规则挖掘技术对病毒的传播路径进行深入分析。
团队收集了受感染主机的网络通信记录、系统调用序列等相关日志数据,利用关联规则挖掘算法分析数据,寻找与病毒传播相关的频繁项集和关联规则。在分析中,团队发现一些有趣的模式。例如,受感染主机在感染前都曾经访问过某个特定的恶意网站,并从该网站下载了恶意软件。此外,这些主机在感染后的网络通信行为也表现出一定的规律性,如定期向某个特定的IP地址发送数据。基于这些发现,团队进一步构建病毒传播路径的可视化图谱,清晰地展示病毒从感染源到目标主机的完整传播链,帮助安全团队快速定位并清除了感染源。
4 结束语
在信息化、网络化时代,数据挖掘技术已经成为计算机网络病毒防御的有力武器。关联规则挖掘等技术,能够帮助人们从海量的数据中提取出有价值的信息,及时发现和应对网络威胁。新技术手段分析病毒的传播路径,准确检测异常行为,为构建高效、智能的防御系统提供了强有力的支持。然而,随着技术的不断进步,恶意软件的攻击手段也在不断演变,未来需要在数据挖掘的基础上,结合深度学习、人工智能等其他先进技术,共同构建一个更加完善、智能的病毒防御体系。
参考文献
[1] 刘娜.数据挖掘技术在计算机网络病毒防御中的应用研究——评《数据挖掘概念与技术》[J].现代雷达,2021(13):98-99.
[2] 赵娇,谭卫东.数据挖掘技术在计算机网络病毒防御中的应用探讨[J].信息与电脑,2023,35(10):43-45.
[3] 郑刚.数据挖掘技术在计算机网络病毒防御中的应用探讨[J].信息与电脑,2022(3):98-99.
[4] 刘婉莹.数据挖掘技术在计算机网络病毒防御中的应用[J].科学技术创新,2022(10):76-77.
