
基于云计算技术的分布式存储系统数据传输功能优化
2024-10-09 00:00:00兰晓天
数字通信世界 2024年9期



摘要:针对分布式存储系统在云计算环境中数据传输效率低下及存储空间率利用不足的问题,该文提出了一种基于数据去重技术的优化方法。这一方法通过识别并消除存储过程中的冗余数据,有效提高了数据传输的效率并节约了存储空间。采用该方法系统将上传的文件分块,并为每个块生成唯一的哈希值以进行快速比对。通过去重检查,系统能够识别出重复的数据块,从而避免了重复存储和传输,显著减少了数据中心的负载。对于新的数据块,则进行存储并更新索引,以支持高效的数据检索。实验结果表明,使用数据去重技术能够在保持数据完整性的同时,显著提高数据传输的速率和存储系统的整体性能。综上所述,该文不仅提出了一种有效的分布式存储系统优化方案,也为云计算环境下的数据管理提供了新的思路。
关键词:分布式存储系统;数据去重;云计算优化
doi:10.3969/J.ISSN.1672-7274.2024.09.024
中图分类号:TP 311.13;TP393.09 文献标志码:A 文章编码:1672-7274(2024)09-00-03
Optimization of Data Transmission Function in Distributed Storage Systems Based on Cloud Computing Technology
LAN Xiaotian
(Guizhou Vocational and Technical College of Economics and Trade, Guiyang 558022, China)
Abstract: This paper proposes an optimization method based on data deduplication technology to address the issues of low data transmission efficiency and insufficient utilization of storage space in distributed storage systems in cloud computing environments. This method effectively improves the efficiency of data transmission and saves storage space by identifying and eliminating redundant data in the storage process. Firstly, the system divides the uploaded files into blocks and generates unique hash values for each block for quick comparison. By performing deduplication checks, the system is able to identify duplicate data blocks, thereby avoiding duplicate storage and transmission and significantly reducing the load on the data center. For new data blocks, store and update indexes to support efficient data retrieval. The experimental results show that using data deduplication technology can significantly improve the data transmission rate and overall performance of the storage system while maintaining data integrity. In summary, this study not only proposes an effective optimization solution for distributed storage systems, but also provides new ideas for data management in cloud computing environments.
Keywords: distributed storage system; data deduplication; cloud computing optimization
0 引言
在当今数字化时代,分布式存储系统作为数据管理的重要基础设施,在云计算和大数据环境中扮演着至关重要的角色[1]。随着互联网技术的发展和数据量的急剧增长,分布式存储系统不仅需要处理海量的数据,还要确保数据的高可用性和可靠性。这些系统通过在多个网络连接的存储资源上分布式地存储数据,提高数据的访问速度和系统的容错能力[2]。然而,随着存储需求的不断增加,这些系统面临着诸多挑战,尤其是在数据传输和存储效率方面。在分布式存储系统中,数据传输效率尤为关键,因为它直接影响到数据处理和检索的性能。高效的数据传输机制可以显著提高系统的响应速度和处理能力,特别是在面对大规模数据处理任务时[3]。此外,存储空间的优化使用也是分布式存储系统设计的重要考量之一。随着数据的不断积累,优化存储空间,降低存储成本成为系统设计的关键任务[4]。
总的来说,本文提出了一种基于数据去重技术的优化方法,针对分布式存储系统在云计算环境中数据传输效率低下及存储空间利用不足的问题,通过识别并消除存储过程中的冗余数据,有效提高数据传输的效率并节约了存储空间。在保持数据完整性的同时,显著提高了数据传输的速率和存储系统的整体性能。
1 相关技术基础
1.1 云计算技术
云计算技术是一种基于互联网的计算方式,它允许数据和应用程序在网络上的远程大型服务器集群上运行和存储,而不是在本地计算机或专用服务器上。在分布式存储系统的背景下,云计算技术的关键在于提供高度可扩展、灵活和成本较低的存储解决方案。通过云计算,企业和个人用户可以根据需要轻松扩展存储资源,同时享受由服务提供商维护的远程数据中心带来的高可靠性和安全性。在优化分布式存储系统的数据传输功能方面,云计算技术通过其强大的计算能力和大规模数据处理能力,为存储系统提供了必要的支持,使得数据处理、备份和恢复等操作更加高效[5]。
1.2 数据去重技术
数据去重技术是一种数据优化方法,主要用于消除存储系统中的重复数据,从而提高存储效率并减少不必要的数据传输。在分布式存储系统中,数据去重可以显著减少对存储空间的需求和网络带宽的使用。该技术通过识别并存储数据的唯一实例,同时在需要时重建原始数据,有效地避免了冗余数据的重复存储。数据去重通常分为两类:文件级去重和块级去重。文件级去重检查整个文件的重复性,而块级去重则更为精细,它分析文件的各个部分(块),识别和消除重复的块。这种精细化的方法特别适用于分布式存储系统,因为它可以更加有效地处理和传输大量的数据。在优化分布式存储系统的数据传输功能上,数据去重技术因其减少数据冗余和提高传输效率的特性而成为一种关键的优化手段[3]。
2 基于数据去重技术的分布式存储系统
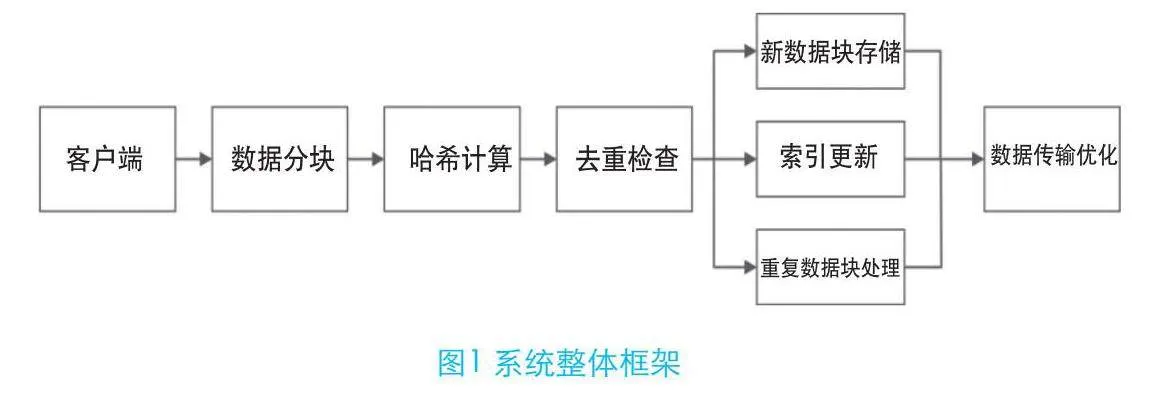
2.1 系统整体框架
基于数据去重技术的分布式存储系统旨在优化数据存储和传输过程中的效率和成本。该系统整体框架设计遵循高效性、可扩展性和安全性的原则,致力于解决传统分布式存储系统中存在的数据冗余和带宽过载问题。
数据去重是整个系统的关键,负责实现数据块级别的去重。通过对上传的数据进行分块、哈希计算,并与现有存储的数据块进行比对,系统能有效识别重复数据,避免存储和传输相同的数据块。系统整体框架如图1所示。
整体而言,该系统的设计旨在通过数据去重技术,提高存储效率,减少不必要的数据传输,从而在保证数据安全的前提下,降低存储成本,提高整体系统性能。
2.2 数据传输功能优化实现
数据传输功能的优化过程如下:
(1)客户端数据上传。客户端数据上传步骤不仅确保了数据的准确传输,还为后续的去重和存储处理奠定了基础。在上传过程中,重要的是使用有效的数据传输协议来保证数据的安全和完整性。传输速率R计算公式如下:
# (1)
式中,是文件大小;是传输时间。
(2)数据分块。文件分块的表达式为:
# (2)
式中,表示合并操作,它将所有分割后的数据块重新组合成原始文件。每个数据块都是文件的一个子集,且整个文件可以通过这些数据块的集合完整地重构。
数据分块的过程不仅关乎数据的物理存储,还涉及后续数据处理的有效性。通过将文件分割成更小的单元,系统能够更加精确地进行数据去重,从而有效减少存储空间的需求,提高数据传输过程的效率。
(3)哈希计算。这一步骤涉及对每个分割后的数据块进行哈希值的计算。哈希计算的公式表示为
# (3)
式中,表示哈希函数。
哈希计算的实施不仅提高了数据去重的准确性,还减少了存储系统中的数据冗余,优化了存储空间的使用。
(4)去重检查。该步骤涉及对每个数据块的哈希值进行检查,以确定是否已存在相同哈希值的数据块。这一过程的核心在于识别重复数据,从而避免不必要的重复存储,优化存储空间的利用率。该检查过程可以用指示函数表达式:
# (4)
式中,返回1表示已存在,返回0表示不存在。
去重检查不仅降低了数据存储的冗余度,也减少了数据传输过程中的带宽需求,从而提高了整个存储系统的性能和效率。
(5)新数据块存储。在该步骤中,系统对那些经过去重检查后被识别为唯一的数据块进行存储。这一过程的目的是将未重复的数据块保存在存储系统中,从而保证数据的完整性和可用性。存储操作可以用映射公式表示:
# (5)
式中,是存储函数,它将数据块映射到存储系统中的一个具体位置。函数返回数据块的存储位置。
通过这种方式,新数据块存储步骤确保了所有独特的数据块都被有效地存储,同时避免了重复数据块的不必要存储。
(6)索引更新。在此步骤中,系统更新索引以记录新数据块或现有数据块的存储位置。此过程对于维护数据的完整性和提高数据访问效率至关重要。
索引更新的过程可以用下面的数学公式进行表达,它更加准确地反映了这一操作的数学本质:
# (6)
式中,表示索引函数;表示去重检查的指示函数;返回新数据块的存储位置;函数返回已存在的与匹配的数据块。
这种方法确保了索引准确地反映每个数据块的最新存储位置,无论它是新存储的还是已经存在的。通过维护一个准确的索引,分布式存储系统能够快速响应数据检索请求,提高整体的数据管理效率。
(7)重复数据块处理。重复数据块处理的目的是减少不必要的存储并优化系统效率。如果,不存储,只更新索引。这可以用条件存储表示:
# (7)
式中,表示引用现有数据块的位置。
通过以上步骤,本文提出的基于数据去重技术的分布式存储系统可以提高数据传输的速率和存储系统的整体性能
3 实验设计与结果分析
3.1 实验环境配置
实验环境包括一台装备有Intel Xeon E5-2620 v4处理器和32GB RAM的高性能服务器,此服务器安装了Ubuntu 20.04 LTS操作系统。在软件方面,本实验采用Apache HTTP Server 2.4版本作为Web服务器软件,在数据库管理方面,选择了MySQL 8.0版本。为了准确地模拟和分析数据传输过程,我们使用Wireshark 3.4版本进行网络分析,捕获和分析数据包。此外,实验中还应用了OpenSSL 1.1.1版本实现数据的安全加密和SSL/TLS通信。
3.2 实验结果及分析
为了全面评估基于数据去重技术的分布式存储系统,笔者进行了一系列实验,并记录了关键性能指标数据。实验结果如表1所示。
表1结果表明,应用数据去重技术显著提高了分布式存储系统的数据传输速率,存储空间使用率也得到了显著改善,证明了本文所提方法的有效性。
4 结束语
本文探讨了基于数据去重技术的分布式存储系统,着重分析了该技术在提高数据传输效率和优化存储性能方面的显著贡献。实验结果表明,采用数据去重技术后,系统在数据传输速率、存储空间使用效率和数据处理时间等关键指标上均实现了显著改进。这些性能提升说明了数据去重技术在减少冗余数据、提高存储效率及优化系统运行效率方面的应用价值。
参考文献
[1] 黎志忠.云计算技术在计算机网络安全存储中的实施策略[J].数字技术与应用,2023,41(11):240-242.
[2] 马翊铭.云计算技术在计算机安全存储中的应用与实践[J].数字技术与应用,2023,41(11):231-233.
[3] 甘莹,邹文景,唐良运,等.分布式资源库多路数据同步传输系统设计[J].电子设计工程,2023,31(18):28-31,36.
[4] 蔡玺,张文轩.电网区块链多层次日志数据分布式存储方法[J].电子设计工程,2023,31(23):31-34,40.
[5] 胡媛媛,江春然,甘杜芬.基于群体智能算法的大数据分布式存储方法[J].计算机仿真,2023,40(11):447-451.
