
基于深度学习的疾控中心电子信息系统智能化优化研究
2024-10-09 00:00:00谭书香
数字通信世界 2024年9期

摘要:随着社会的不断发展,面对日益增长的数据量和日趋复杂的公共卫生问题,传统的信息系统已难以满足快速准确处理信息的需求,从而影响了公共卫生处理的效率。因此,该文通过整合最先进的深度学习模型,对疾控中心电子信息系统智能化的优化策略进行分析研究。研究结果表明,与现有系统相比,所提出的优化方案显著提升了信息处理的准确性和时效性,为健康风险评估和资源分配提供了更加可靠的科学依据。
关键词:深度学习;疾控中心;电子信息系统;智能化
doi:10.3969/J.ISSN.1672-7274.2024.09.012
中图分类号:G 270.7;TP 315 文献标志码:A 文章编码:1672-7274(2024)09-00-03
Research on Intelligent Optimization of Electronic Information Systems
in Centers for Disease Control and Prevention Based on Deep Learning
TAN Shuxiang
(Yuncheng County Center for Disease Prevention and Control, Heze 274700, China)
Abstract: With the continuous development of society, facing the increasing amount of data and increasingly complex public health problems, traditional information systems are no longer able to meet the needs of fast and accurate information processing, thereby affecting the efficiency of public health processing. Therefore, this article analyzes and studies the optimization strategies for the intelligence of electronic information systems in disease control centers by integrating the most advanced deep learning models. The research results indicate that the proposed optimization scheme significantly improves the accuracy and timeliness of information processing compared to existing systems, providing a more reliable scientific basis for health risk assessment and resource allocation.
Keywords: deep learning; center for disease control and prevention; electronic information systems; intelligence
当前,虽然疾控中心已广泛采用电子信息系统进行日常运作,但仍存在数据孤岛、处理效率低下和预警准确性不高等问题。因此,需要重视对深度学习技术的应用,建立基于深度学习的电子信息系统框架,通过整合多源数据、增强数据处理能力及自动化决策支持,提升疾控中心针对传染病的监控和干预效率。
1 疾控中心电子信息系统现状分析
疾控中心电子信息系统是集数据收集、处理、分析和报告功能为一体的综合性平台,对现代疾病防控有着巨大影响。随着全球化和城市化进程的加快,疾病传播的风险日益增加,疾控中心需要迅速做出反应,并及时预警发布相关信息。值得注意的是,虽然现有的电子信息系统在数据管理和流行病学调查等方面发挥了重要作用,但是其发展现状仍不容乐观。
就数据采集和更新方面而言,系统多依赖于手动输入,不仅效率低下,而且容易出错,同时系统的数据整合能力有限,特别是在多来源和异构数据环境下的信息融合效率较低,对于大规模和复杂数据的处理与分析能力不足,无法有效支持实时、准实时的数据处理需求[1]。
在智能化方面,当前系统的功能性相对较弱,如利用人工智能和机器学习技术进行模式识别、趋势预测和决策支持等功能还较为初级,且用户体验效果存在明显不足,界面直观性和交互设计仍有提升空间。
2 基于深度学习的疾控中心电子信息系
统智能化优化策略
2.1 系统架构设计
系统架构设计包括三个层面,分别为数据层、模型层以及应用层。数据层是整个系统的基础,负责收集、存储和管理来自疾控中心的各类数据,例如,收集各种流行病学调查数据、患者临床数据、公共卫生监测数据以及相关的社会经济数据等,该层架构采用先进的数据库管理系统,结合数据库理念实现数据的高效存取和动态扩展。为了保证数据质量,技术人员引入数据清洗和预处理模块,并通过特征工程抽取有效信息以供模型层使用[2]。模型层是系统的核心,主要以多种深度学习模型为主,例如,卷积神经网络(CNN)用于图像数据分析,循环神经网络(RNN)和变换器(Transformer)模型用于时序数据预测。在模型的选择和训练中,技术人员需要了解和掌握疾控中心的业务需求和数据特性。模型层设有模型评估和优化组件,可以对负责模型参数展开调整,以此来确保预测和分析的准确性。应用层直接面向疾控中心的工作人员和决策者,能够提供良好的人机交互界面(UI),允许用户轻松地访问系统功能,如数据可视化、报告生成、预警机制等。
2.2 数据收集处理
在数据收集过程中,需要明确数据收集的来源,确保数据来源的合法性和可靠性,从而为后续工作奠定良好的数据基础。在收集数据时需遵循相关隐私保护条款,如HIPAA(健康保险便携性和责任法案)等,从而确保个人信息安全,在数据预处理的过程中,需要对数据进行清洗,完成归一化处理。完成编码转换后,方可对缺失值进行处理。在进行异常值检测的过程中,可以使用插值方法填充缺失值,通过Z-score标准化方法来处理异常值,或者采用独热编码将分类变量转换为数值型变量。特征选择也是预处理的关键环节,目的是剔除冗余特征,保留对建模有实际意义的特征,以减少过拟合风险并提高模型性能。考虑到深度学习模型对数据量的依赖性,需要进行数据增强。尤其是在医疗数据不足的情况下,利用数据增强技术,如图像旋转、平移、裁剪、颜色调整等,增加数据多样性,进而提高模型泛化能力。最后,经过预处理的数据将被划分为训练集和测试集,通常会采取随机抽样或分层抽样的方式进行划分,以确保数据集之间分布的一致性,训练集用于模型的学习,而测试集则用来评估模型的泛化能力[3]。
2.3 深度学习模型选择
考虑到公共卫生监测数据往往具有时间性特征,传统的全连接神经网络(FCNN)对于捕捉这种时序关系不够高效。因此,在深度学习模型选择中应侧重考虑卷积神经网络(CNN)和循环神经网络(RNN)及其变体。
CNN在图像识别和处理领域表现出色,强大的空间特征提取能力可用于挖掘时间序列数据中的局部特征,该能力的运行机理为借助卷积层功能,从原始数据层中提取出具有价值的核心数据。并通过卷积层降低这些表示的空间尺寸,增强了模型对位置偏差的预测性。RNN设计则可以对序列数据进行处理,能够在当前输入和先前状态之间建立连接,但标准RNN容易出现梯度消失或者爆炸的问题,因此需要进行有效改进。其中长短期记忆网络(LSTM)作为RNN的一个改进型,能够对多个们控制机制进行引进,使得模型可以在更长的序列中维持信息并捕获远距离依赖关系。在利用LSTM网络来捕捉和预测流行病数据中的长期依赖关系过程中,将数据集分为若干时间窗口,然后每个时间窗口的数据被输入到LSTM网络,最后LSTM的输出将被用来预测未来的趋势或进行分类任务。
2.4 模型训练与验证
模型训练和验证结果能够直接影响所构建的深度学习系统的性能和可靠性,在验证的过程中,需要从疾控中心收集大量健康记录,并将流行病数据中分割出一部分作为训练集,该训练集将用于模型的初始学习过程,剩余的数据会被用作测试集,以评估模型在未知数据上的表现。为减少过拟合的风险并提高模型的泛化能力,可实施交叉验证策略。特别是K折交叉验证,其可以将整个训练集会分为K个小组(folds),模型将轮流使用其中的K-1组进行训练,并用剩下的一组进行验证,这一过程将重复K次,每次都换一个不同的验证组,以此来保证评估结果的稳定性和可靠性。
在模型训练过程中,可将准确率、召回率、F1分数等作为评估指标,这些指标可以帮助技术人员对模型在正确分类和检测疾病爆发方面的表现进行评估,同时技术人员也需要对模型的学习曲线是否平衡给予关注,即没有过拟合(在训练数据上表现很好但在测试数据上表现不佳)或欠拟合(在训练和测试数据上都表现不佳)的情况。通过反复的实验调整和参数优化确定最终的模型配置,并且在全量的测试集上进行最终的评估。
2.5 数据库设计
数据库设计是确保数据结构得到合理组织、存储和高效检索的关键。数据库不仅需要存储患者数据、流行病学调查数据、实验室检测结果等,还需存储基因组数据、地理信息系统(GIS)数据以及实时监控数据。鉴于系统涉及的数据多样性和复杂查询需求。可以采用NoSQL数据库如MongoDB提供灵活的文档结构,以此来适应不同类型数据的存储与快速变化的查询需求,对于高度事务性的数据,如患者的基本信息和诊断结果,采用SQL数据库如PostgreSQL将更加适合[4]。
2.6 用户界面设计
为了确保采用深度学习优化后的电子信息系统用户界面既实用又高效,技术人员可以采用多步骤的设计方法,首先利用用户研究方法,包括访谈、问卷调查及现场观察,收集疾控中心工作人员的操作习惯和任务流程,从而揭示关键的用户需求和界面设计的核心功能点,然后依据收集的数据,运用用户体验(UX)设计原则创建初步的线框图,确定信息架构和界面布局,通过快速迭代设计方法进行多个设计周期,不断地测试和修改线框图,以达到最佳的用户体验。
在设计界面时,要求确保所有的信息显示清晰,并保证按钮和图标标记直观,工作人员能够一目了然地找到他们需要的功能。保持颜色配色、字体大小、按钮风格等界面元素的一致性,以减少用户的学习成本。界面可以适配不同尺寸的屏幕,确保从台式机到平板电脑,再到智能手机等各种设备都能够良好展现。此外,需要提供明确的反馈机制,当用户完成某项操作时,系统能够通过视觉或声音提示给予反馈,提升用户的操作信心。
2.7 安全性与隐私性保护策略
可以借助身份验证和访问控制机制,如多因素认证(MFA),以确保只有授权用户才能访问系统资源,或者应用基于角色的访问控制(RBAC),可以限定不同级别的用户对敏感数据的操作权限,进一步降低非法访问的风险。
此外,可以广泛应用加密技术,以保护存储和传输过程中的数据,对于静态数据而言,技术人员可以借助AES等标准加密算法进行磁盘加密。在数据传输过程中则可以利用TLS/SSL协议,确保数据在网络中的安全,针对数据库中的PHI,可实施字段级加密或令牌化处理,在数据泄露时最大限度地减少信息暴露。
3 优化效果评估
3.1 系统性能评估
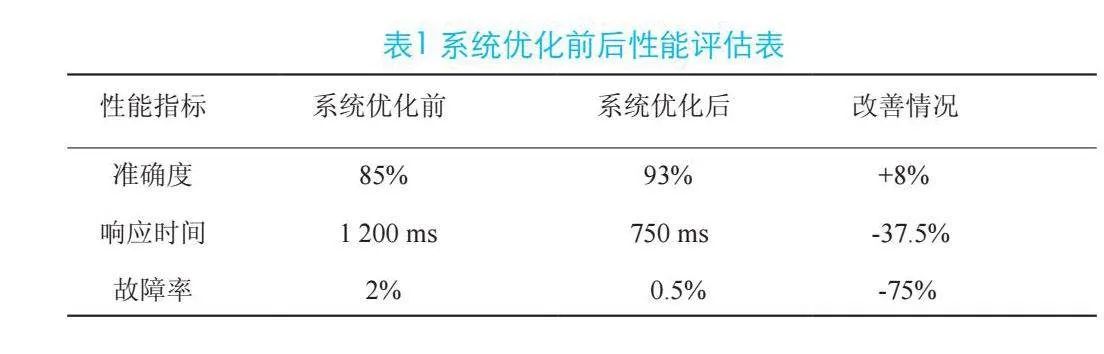
系统性能评估指标包括准确度、响应时间和可靠性。准确度是对系统执行任务的准确率进行评估,需要通过比较系统输出与事先验证过的真实值来计算准确度指标。响应时间指系统接收输入到产生输出所需的时间,该指标通常采用时间测试来衡量,包括数据处理、模型推理以及结果展示的总时间。可靠性主要评价系统在各种条件下持续正常运行的能力。以某电子信息系统为例,对系统优化前与优化后的性能指标改善情况进行对比,详细内容如表1所示。
从表1可看出,优化后系统准确度提升到93%,系统响应时间缩短到750ms,显著快于系统优化前的1200ms,可看出系统经过优化后能够更快地处理信息,此外优化后系统B的故障率降低至0.5%,说明优化后系统利用更健壮的模型设计和更好的错误处理机制使系统变得更加稳定。
3.2 用户体验评估
用户体验评估涵盖便捷性、信息呈现方式以及用户满意度调查三个方面,某疾控中心在优化电子信息系统上线运行一个月后,对50名用户进行了满意度调查,以衡量使用便捷性、信息呈现方式及总体满意度,评估采用了1到5的评分标准,其中,1表示非常不满意,5表示非常满意,详细内容如表2所示:
从表2中可以看出,在使用便捷性方面,通过优化界面设计和用户交互流程,实现了从2.8到4.2的提升,信息呈现方式经过优化,以更直观的图表和清晰的导航功能提高了用户体验,得分从3.0提升至4.5,同时总体的用户满意度也显著提高,从3.1增长到4.4,以上数据表明优化后系统用户体验整体幅度提升,表明优化措施的有效性。
4 结束语
综上所述,利用深度学习技术对疾控中心电子信息系统进行优化,能够进一步强化对数据处理的效率,优化系统性能,提高准确度,减少系统故障出现概率,同时也能够进一步增强用户的体验程度。为此需要进一步提高其重视,将深度学习技术理论应用于实际操作环境中,以此建立更加安全高效的智能化信息系统,最终促进我国公共服务质量的提升。
参考文献
[1] 张军凯,李欣,韩俊先,等.深度学习算法下的采摘机器人系统优化研究[J].农机化研究,2024,46(4):58-62.
[2] 梁沁雯.基于深度强化学习的综合能源系统优化方法研究[D].北京:华北电力大学(北京),2023.
[3] 吴玉寒.基于深度学习场景生成的含电氢转换综合能源系统优化调度研究[D].济南:山东大学,2023.
[4] 卜凡金.基于深度强化学习的海岛综合能源系统优化调度研究[D].吉林:东北电力大学,2023.
