
基于改进YOLOv4的实时目标检测方法研究
2024-10-09 00:00:00鲁健恒
数字通信世界 2024年9期



摘要:为提升实时目标检测的准确性和稳健性,该文采用增强特征融合技术、网络架构技术、损失函数技术等对YOLOv4算法进行优化。结果表明,改良后的YOLOv4算法在多变环境下对小型目标检测表现出色,展现了其实用性和稳定性,为广泛应用奠定了坚实基础。
关键词:实时目标检测;YOLOv4;特征融合;GIoU损失函数
doi:10.3969/J.ISSN.1672-7274.2024.09.006
中图分类号:TP 31 文献标志码:B 文章编码:1672-7274(2024)09-00-04
Research on Real-time Object Detection Method Based on Improved YOLOv4
LU Jianheng
(College of Artificial Intelligence, Guangzhou Huashang College, Guangzhou 511300, China)
Abstract: To enhance the accuracy and robustness of real-time object detection, this paper optimizes the YOLOv4 algorithm by employing enhanced feature fusion technology, network architecture technology, loss function technology, and other strategies. The results demonstrate that the improved YOLOv4 algorithm exhibits excellent performance in detecting small objects in diverse environments, showcasing its practicality and stability, and laying a solid foundation for its widespread application.
Keywords: real-time object detection; YOLOv4; feature fusion; GIoU loss function
0 引言
在人工智能与视觉科技领域,实时目标检测技术日益凸显其重要性,广泛应用于自动驾驶、视频监控、无人机导航等多个领域。YOLO(You Only Look Once)系列算法,尤其是YOLOv4版本,因其快速且高精度的检测性能而受到关注[1]。然而,YOLOv4在微小目标检测、跨硬件性能一致性等方面仍存在局限性。
1 理论概述
1.1 改进YOLOv4算法的概述
如图1所示,在特征抽取的网络结构内,采用改良的主体结构,利用多个残差块层(包括Resblock_body层)逐步提取特性,在此每个组件的参数配置及其重复频次均有所区别,有效提升了特性描述的深度,输入图像历经卷积操作和批量归一化层(Conv2d BN)传输至网络结构,紧跟着在历经Mish激活处理处理完成后,用于维持非线性特性[2]。然后,利用若干Resblock_body组件逐渐降低采样率并从中提取特性,最后在SPP(Spatial Pyramid Pooling)模块中整合多尺度最值池化,显著充实了特性信息,在特征融合阶段,引入了改良版PANet(Path Aggregation Network),借助层次化分离卷积有效提高特征融合效率。在PANet架构里,在实施上,采样与下采样过程(UpSampling、DownSampling)反复进行特征融合与卷积操作如执行make_five_conv过程,实现了有效整合了多个尺度的特征数据[3],最终,网络架构在三种不同尺度(YOLO Head1、YOLO Head2、YOLO Head3)实现检测能力,从而提升了对各种尺寸目标的检测精度和效率性。
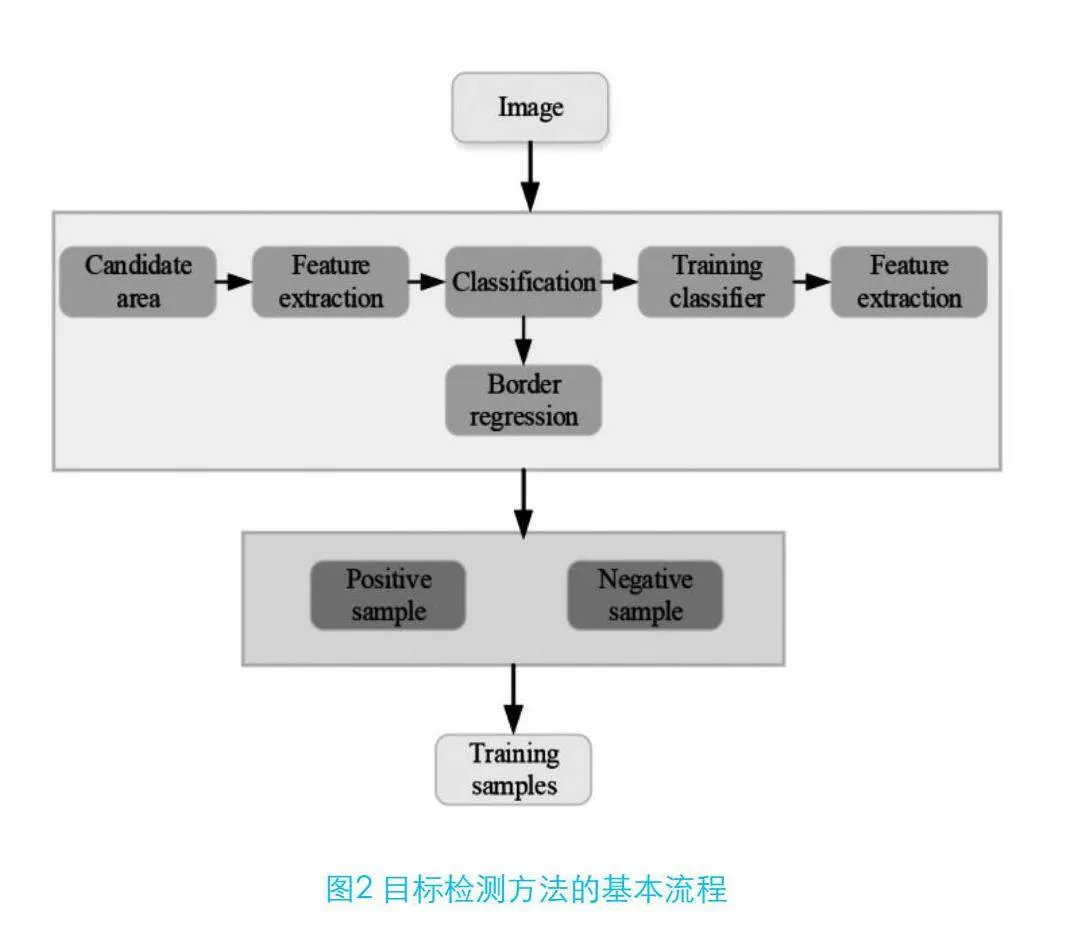
1.2 目标检测方法概述
该技术首先对输入图像进行处理,识别可能包含目标物体的潜在区域。随后,利用深度卷积神经网络等先进技术对这些区域进行特征抽取,提炼出用于目标识别的精细特征。通过特征识别执行分类处理,确定潜在区域中是否包含目标实体及其种类。接着,采用边界回归技术精确捕捉目标物体的边界框[4]。在训练阶段,通过构建包含正反面实例的训练数据集,训练分类和回归算法模型,以提升目标识别的精确度和效率。该策略综合考虑了潜在区域、特征辨认、分类判定和边界描绘,显著提高了目标识别的实时性和准确性,在自动驾驶、视频监控等领域得到广泛应用[5]。
2 实验设计
2.1 数据集选择与预处理
COCO数据集涵盖了80种常见物体类别,包含超过330 000张图像及详尽的标注数据,其中标注框超过200 000个,广泛涵盖各种复杂场景与不同尺寸的目标物体。选择COCO数据集的理由在于其详尽的标注和广泛的环境,能够准确评价改进算法在各种情境下的识别能力。数据预处理是模型训练成效的核心环节,本文首先将图像大小统一调整为416×416分辨率,以满足YOLOv4模型输入要求。随后,运用随机剪裁、水平翻转等增强手段增加数据多元性,避免模型过拟合。同时,对标注边界进行调整,确保标注准确度,并通过颜色调整和加入噪声等手段模拟复杂场景,增强模型稳健性。最终,将处理后的数据集分为训练集、验证集和测试集,用于模型训练、超参数调整和性能评估。
2.2 实验环境
实验所用计算机系统配备NVIDIA GeForce RTX 3090图形处理单元,该单元拥有24 GB GDDR6X显存,提供强大的并行处理能力和高速存储读写能力。同时,系统搭载AMD Ryzen 9 5950X处理器,具备16核32线程和3.4 GHz的时脉频率,可有效处理大量数据和复杂计算任务。系统配置32 GB DDR4内存,确保大数据处理和机器学习训练过程中内存充足。实验软件平台基于Ubuntu 20.04操作系统,采用TensorFlow 2.4和PyTorch 1.7深度学习框架,均支持GPU加速。选用NumPy、Pandas、Matplotlib等数据处理工具,结合CUDA 11.1和cuDNN 8.0加速库提升GPU处理速度。采用Docker容器技术,确保实验环境可复制且部署高效,实现了高效的开发和测试流程。
2.3 实验流程
2.3.1 数据集准备与划分
COCO数据库包含80个目标种类,提供118 287张训练图像和5 000张验证图像,所有图片统一尺寸为416×416像素,用此方法检验符合YOLOv4模型的所需规格,在此步骤中对标注信息进行标准化,保证位置信息与图像大小一致,在具体操作中,标注框的归一化采用公式如下:
(1)
式中,、是标注框的左上角坐标;、是图像的宽度和高度;、是标注框的宽度和高度。
在数据集分割过程中,将全部数据划分为训练集、验证集和测试集,占比分别为70%、15%和15%。具体操作如下:精心选择70%的图片及其注释作为训练数据集,用于模型训练和参数调优;挑选15%的图像资料及相应文字描述构成验证数据集,以在训练过程中评估模型表现,并调优超参数和模型选择;保留剩余15%的图像和注释作为测试数据集,用以评估模型在未知数据上的性能。此外,为提升训练数据的多样性和难度,我们实施了数据增强策略,包括随机裁剪、水FV04U1+6WZOtYJKbt90yRQ==平翻转、调整光线和对比度等,以增强模型的健壮性,避免过拟合,确保模型在实际应用中的表现和稳定性。
2.3.2 模型训练
为提升模型性能,选定了适当的极其关键的参数,涵盖初始学习率、批量尺寸和训练周期,初始学习速度设定为0.001,批量尺寸为16,训练周期为百次,以此确保人工神经网络在不同成长阶段拥有有效收敛性,在训练过程中,使用余弦衰减学习速率调整策略,公式表示为
(2)
式中,是第t次迭代时的学习率;和分别为最小和最大学习率;T为总迭代次数。在训练过程中,使用交叉熵损失函数处理分类任务,公式如下:
(3)
式中,为目标类别的真实标签;为模型预测的概率。此外,采用改进的GIoU损失函数进行边界框回归,以提高定位精度,公式如下:
(4)
式中,B为预测框;为真实框;C为最小包围框。在训练阶段,利用跟踪验证数据集给出的损失和精度指标,执行调优超参数和提前结束策略,防止过度拟合难题,在每个训练周期终止时,储存最优算法模型的参数,并周期性评估模型与验证数据集表现,保证改进的YOLOv4算法在众多评价准则上获得明显改进。
2.3.3 模型测试
模型训练过程终止后,应用事先安排的测试数据集对优化后的YOLOv4算法执行性能评价,以评价它在实际使用场景中的表现,测试阶段至关重要在于精确衡量模型的辨识效能和效率,首先采取的行动是,应用已经训练完毕的模型至测试数据集内每一幅图像,估计预测边界框的坐标和类别确信度,评定成效与实际分类相比较,采用平均精确度(mAP)和每秒处理的帧数(FPS)作为主要性能衡量标准,通过以下公式计算不同类别的平均精度:
(5)
式中,N为类别数;为第i类的平均精度。平均精确度的评定手段涵盖精确性和召回率整体衡量,在运算阶段采用不同设定情境精确度与召回率,每秒画面更迭次数则用来衡量模型的实时表现,公式如下:
(6)
在验证阶段,对模型生成的预测和实际标记进行对比校验,通过IoU(Intersection over Union)衡量预测的边界框和实际边界框一致性,公式表示为
(7)
一般当交并比超过预定阈限0.5时,判断预测的界限为可靠鉴别,通过梳理所有测试样本表现数据,计算出整体平均精度地图和每秒帧数,进而综合评价模型的精确性与反应速率,另外,务必要在复杂多变的条件下检测模型的稳定性,如各种照明条件、遮挡状况和多对象拥挤场景。
3 结果分析
3.1 实验结果
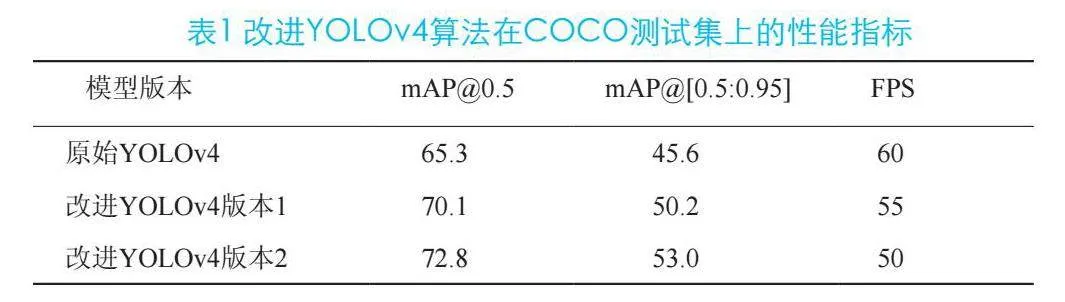
实验数据说明,优化后的YOLOv4算法在各项评价准则之中均有显著提高明显优化,改进后的 YOLOv4(版本 1)在 mAP@0.5 和 mAP@[0.5:0.95] 上分别提升了 4.8% 和 4.6%。虽然帧数有所降低,但仍处于可行的实时检测范畴内。而改进后的 YOLOv4(版本 2)进一步提高了识别准确性,mAP@0.5 和 mAP@[0.5:0.95] 分别达到了 72.8% 和 53.0%,展现出较高的辨识效率。不过,其辨识速度略有减缓。表1列出了改进YOLOv4算法于COCO数据集的主要评价指标,涵盖平均精确度(mAP)以及帧每秒(FPS)不同条件下的测试结果。
在测试阶段,模型的可靠性也得到了验证,在各种光线照射、阻挡以及众多紧凑排列的目标环境中,优化YOLOv4继续维持较高的识别准确度和效能,这些数据证实了我们所提出的改良策略在增强检测效率期间,一并考虑了实际应用需求,展现了出色的稳健性和适应力。
3.2 结果讨论
通过对YOLOv4的优化,在mAP@0.5和mAP@[0.5:0.95]上分别实现了显著提升,版本1提升至4.8%和4.6%,同时保持了高效的检测速度,每秒帧数仅略有下降,仍维持在55 FPS的标准。这表明,引入改良后的主网络和特征融合技术,有效提升了特征抽取效率和多尺度特征融合效果,进而显著提高了目标识别的准确性。版本2进一步优化了结构与功能,mAP@0.5和mAP@[0.5:0.95]分别增至72.8%和53.0%,尽管FPS略降至每秒50帧,但仍能满足实时应用需求。改良算法在各种光照、遮挡和复杂多目标环境下均表现出高识别准确度和效率,展现了出色的稳定性和适应性。这些优化方法不仅提升了识别能力,还增强了不同尺寸目标检测的效率,展现出对多种环境的适应性和稳定性。
4 结束语
改进后的YOLOv4算法在实时目标检测中展现出显著提升的效率,尤其在多变环境和细小目标侦测方面表现卓越。未来我们将聚焦于提升模型实时表现力和资源利用率,旨在推动实时目标检测技术的进步及其应用的拓展。
参考文献
[1] Jiang Z, Zhao L, Li S, et al. Real-time object detection method based on improved YOLOv4-tiny[J]. arXiv preprint arXiv:2011(04):244,.
[2] Fan Y C, Yelamandala C M, Chen T W, et al. Real-time object detection for lidar based on ls-r-yolov4 neural network[J]. Journal of Sensors, 2021: 1-11.
[3] Zhou Y, Wen S, Wang D, et al. MobileYOLO: Real-time object detection algorithm in autonomous driving scenarios[J]. Sensors, 2022(9): 3349.
[4] Yao G, Sun Y, Wong M, et al. A real-time detection method for concrete surface cracks based on improved YOLOv4[J]. Symmetry, 2021(9): 1716.
[5] Kumari N, Ruf V, Mukhametov S, et al. Mobile eye-tracking data analysis using object detection via YOLO v4[J]. Sensors, 2021(22): 7668.
