
汉语辞书词条自动编纂调查研究
2024-09-25 00:00张永伟刘婷
辞书研究 2024年5期


摘 要 文章以ChatGPT为例,借助问卷考察了大语言模型在汉语辞书词条自动编纂中的表现。研究选取40个词目作为样本,充分考虑词性、词长、义项数的多样性,借助ChatGPT生成释文,并与《现代汉语词典》第7版进行对比分析。问卷调查显示,ChatGPT编纂的词条中有37.5%获得了更多受访者的认可,但整体质量距离全面超越传统辞书仍有差距。ChatGPT在单音字、单一词性词语的标注和单义项词语的释义方面具有优势,但对多音字、兼类词、多义词以及特殊语体词的词条编纂效果明显下降,也暴露出义项遗漏、释义不准确、举例模式化等问题。总体而言,ChatGPT在辞书编纂中展现了生成新义、快速编纂等优势,但严谨性、系统性不足,难以独立完成编纂任务。大语言模型正在不断升级中,未来宜持续关注并将其用作辞书编纂的辅助工具,通过人机互助提高辞书编纂速度,提升辞书编纂质量,推动汉语辞书智能化发展。
关键词 辞书 词条 自动编纂 大语言模型 ChatGPT
一、 引 言
词条又称条目,是词典的基本查检单位,一般包括词目、注音、释义、例证、语用说明和各种挂尾信息。词条释文的编纂是辞书编纂最重要、最费时、最耗精力的工作。自动编纂词条释文可以大幅提高辞书编纂效率,对辞书的现代化编纂具有重要意义。
词条自动编纂的方法包括基于规则的方法(魏雪,袁毓林 2014)和基于深度学习的方法(Noraset et al. 2017;Gadetsky et al. 2018;Kong et al. 2022;范齐楠等 2021)等。近年来,生成式大语言模型的发展为词条自动编纂提供了新方法和新契机,其中具有代表性的是OpenAI公司于2022年11月发布的智能聊天机器人程序ChatGPT。ChatGPT使用超大规模语料训练,集成了指令学习、基于人类反馈的强化学习等一系列创新技术,能够使用自然语言与用户对话,理解、执行用户的请求。ChatGPT最初由GPT-3.5系列模型支持,其后更新的GPT-4模型性能进一步提升,在常识推理、代码生成、阅读理解、多学科测验等任务中表现优异,超越了现有其他模型(OpenAI et al. 2023)。Cai等(2023)让ChatGPT作为被试,进行了包括语音、词汇、语法、语义、语篇、对话等在内的12项经典的心理语言学实验,发现ChatGPT能够复制人类的语言行为模式,在10项实验中达到了接近人类的水平。
随着ChatGPT的流行,辞书编辑开始利用大语言模型辅助辞书编纂,学习者也开始利用大语言模型查询词语的含义与用法。这方面的研究主要集中于英语领域。Phoodai和R0ebd24df93cd6d80555e0d55b3e234a8ikk(2023)选取50个高频英语词,从微观层面对比分析ChatGPT和《牛津高阶学习词典》(Oxford Advanced Learner’s Dictionary)的词条,发现ChatGPT在为英语学习者提供词汇数据项方面整体优于后者(平均分高11%),而在提供上下文信息和互动能力方面存在不足。Lew(2023)邀请4位专家评估ChatGPT(GPT-3.5)生成的
15个词条,与柯林斯在线词典(Collins COBUILD Advanced Online)[1]进行比较,结果表明ChatGPT生成的释义可与后者相媲美,但生成的例句和整体词条获得的评分较低。Rees和Lew(2024)面向二语学习者进行词汇阅读理解测试,分别提供ChatGPT(GPT-3.5)和麦克米伦在线词典(Macmillan English Dictionary Online)[2]的词条,发现ChatGPT和麦克米伦在线词典均能让学生的表现更优,但前者对成绩的提升不显著,后者较显著。ChatGPT在非英语词条编纂领域的调研较少,有代表性的是Tran等(2023)的研究,他们针对斯洛文尼亚语进行释义提取测评,发现释义结构明确、数据量较少时,基于规则的方法效果更好,释义结构宽泛、数据量较大时,Transformer和ChatGPT(GPT-3.5)一类大语言模型的效果更好,其中Transformer的精确率更高,ChatGPT的召回率更高。
本研究面向汉语语文辞书读者,以ChatGPT(GPT-4)作为大语言模型的典型代表,通过问卷形式调查大语言模型自动编纂词条的认可度,分析大语言模型自动编纂的质量与特点,探讨大语言模型为词条自动编纂带来的机遇与挑战。
二、 研 究 方 法
(一) 调查对象
1. 词目选择
《现代汉语词典》是一部久享盛誉的规范型词典。本研究从《现代汉语词典》第7版(以下简称《现汉》)中选取40个调查词目,选取时充分考虑词性、词长、义项数、特殊用法的多样性,用尽可能少的词目覆盖尽可能多的调查项目。40个词目为:哎、彼、不、城、均、了、梅、人、些、咬、包袱、并且、除了、吹填、催泪、第一、短线、感冒、干净、红线、呼啦、回信、剪影、进行、克隆、暌违、龙头、矛盾、美工、逆天、热络、信箱、应该、着调、左右、兜底翻、互联网+、花花搭搭、铁帽子王、阿尔茨海默病。
下面介绍40个词目的涵盖范围。在词性方面,涉及《现汉》标注的所有12个大类,包含实词35个、虚词5个。单类词(单一词性的词)和兼类词的比例为4∶1,单类词以名词、动词和形容词为主,分别占比27.5%、17.5%、12.5%;在词长方面,二字词最多(25个),单字词其次(10个),3字及以上的词目最少(5个);在词义数方面,义项数平均值为2.9,最小值为1,最大值为9,以双义词、三义词和单义词为主,分别为17、7、6个;在语体和语域方面,包含科技词10个,口语词、方言词和文言词共8个,其余为普通语文词;在新词新义方面,包含《现汉》新增词目或新增义项9个,占比22.5%。
2. 自动编纂的词条
本研究借助ChatGPT(GPT-4)实现词条自动编纂,具体步骤为:(1) 打开ChatGPT网页版人机对话窗口,输入提示词,约定自动编纂要求的同时引导ChatGPT在后续对话中直接根据词目生成释文;(2) 输入一个词目,获取ChatGPT自动编纂的释文;(3) 重复步骤(2),直至获取所有词目的释文。
提示词除了明确ChatGPT需要完成的具体任务外,还对释义要求进行了详细的约定,包括释义的体例和风格要与《现汉》保持一致等。提示词的撰写参考了《现汉》凡例,但实验表明将整个凡例提交给ChatGPT并不能获得更好的结果。经过对提示词进行多轮调整和优化,最终选择的提示词如下[3]:
请你充当一个专业的汉语辞书编辑,按照中型现代汉语辞书的标准,为输入词目编纂权威、正确、规范的释义。严格按照以下格式:
圆括号中的内容为可选项,根据词条实际情况选择;读作轻声时注音不标调号,只在拼音前加·;词性标记使用简称,包括{名}{动}{形}{副}{量}{数}{代}{介}{连}{助}{叹}{拟声}十二类;划分出的义项尽可能全面涵盖词目意义和用法;同一类型词目应在释义模式和语言风格上保持一致;举例应简洁明了、典型,其中词目用~代替;词目属于外来音译词时,在释义最后附注外文原文,如:“伏特加”……[俄водка]。三类典型的词目释义方式如下:
1. 单义词
“词目” 拼音{词性} 释义(:举例1 |举例2 |举例3……)。
2. 多义词且所有词性相同
“词目”拼音{词性}①释义(:举例1 |举例2 |举例3……)。②释义(:举例1 |举例2 |举例3……)。③……。
3. 兼类词
“词目”拼音①{词性}释义(:举例1 |举例2 |举例3……)。②{词性}释义(:举例1 |举例2 |举例3……)。③……。
以“热络”和“彼”为例,ChatGPT自动生成并经后处理[4]的词条见下:
热络 rèluò ①形容感情亲密,交往频繁:他们之间的关系很~|~的气氛。②指活动或场合气氛热烈,人际交往频繁:聚会十分~|市场~。(ChatGPT)
彼 bǐ ①指远离说话人和听话人的人或事物:~岸|~处。②用于指代前文已提到的人或事物:~时|~人。③古代文言文中,常用作男子的美称:~生|~君。(ChatGPT)
“热络”和“彼”在《现汉》中的释文见下:
热络 rèluò ①亲热:两人关系~。②热烈:气氛~。③频繁:两国领导人往来~。(《现汉》)
彼 bǐ ①指示代词。那;那个(跟“此”相对):~时|此起~伏|由此及~。②人称代词。对方;他:知己知~|~退我进。(《现汉》)
浏览ChatGPT自动编纂的词条可以发现,ChatGPT自动编纂结果符合预先设计的体例要求,具有较高可读性。但是,对于同一个词目,ChatGPT自动编纂的释文和《现汉》中的释文存在比较明显的差异。
(二) 调查工具
调查采用问卷形式,借助问卷星的微信小程序发放和回收问卷。研究为每个词目设置1个问题,包含两个候选项,即同一词目对应的《现汉》词条和ChatGPT自动编纂的词条,选项之间随机排列,不提示释义来源。问卷导语对作答标准进行了说明:“请参照中型通用现代汉语辞书的标准,从两个选项中选择你认为更合理、质量更高的词条:释义无错误,义项划分更合理,释义更清晰,举例更恰当,更能满足实际查询需求,等等。”
除上述问题外,问卷还收集了受访者年龄、身份、受教育程度、学科、辞书使用频次等5项背景信息。
三、 结果与讨论
(一) 受访者情况
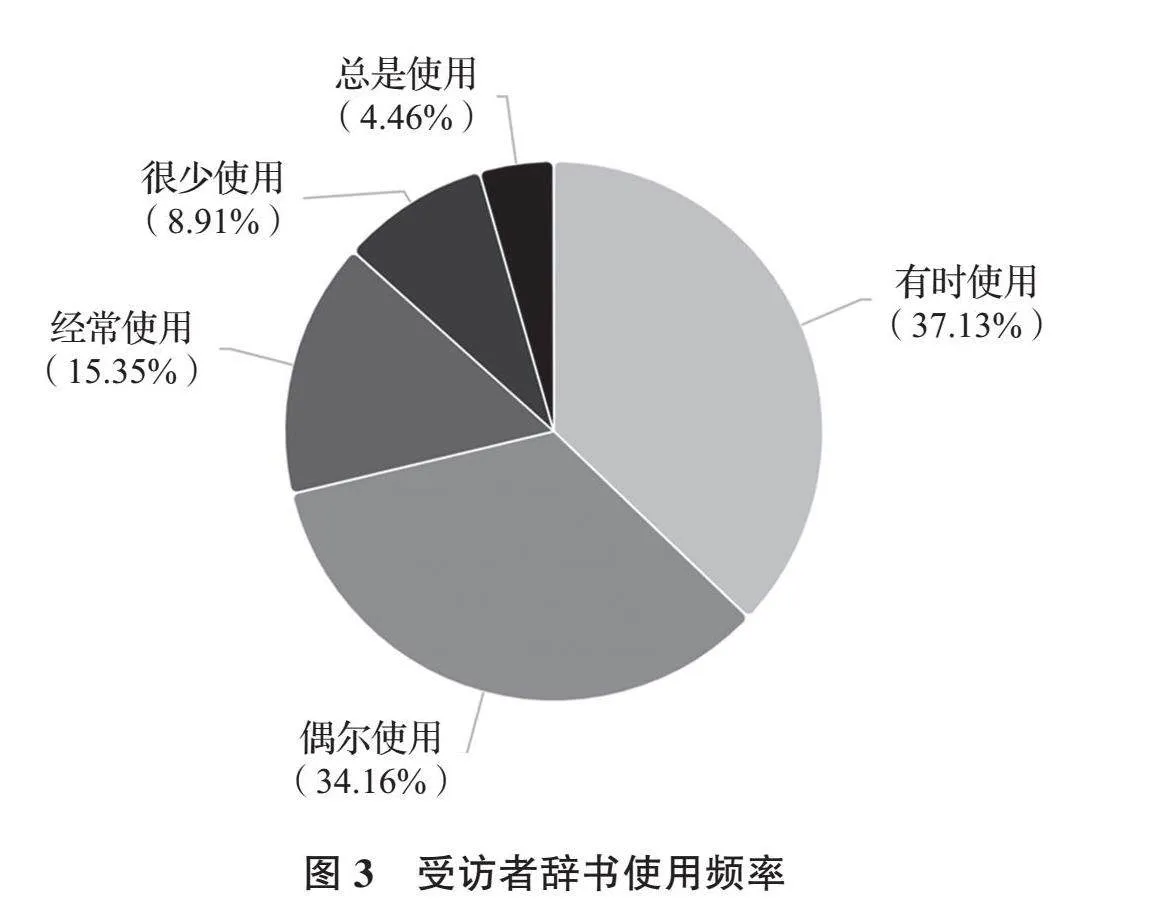
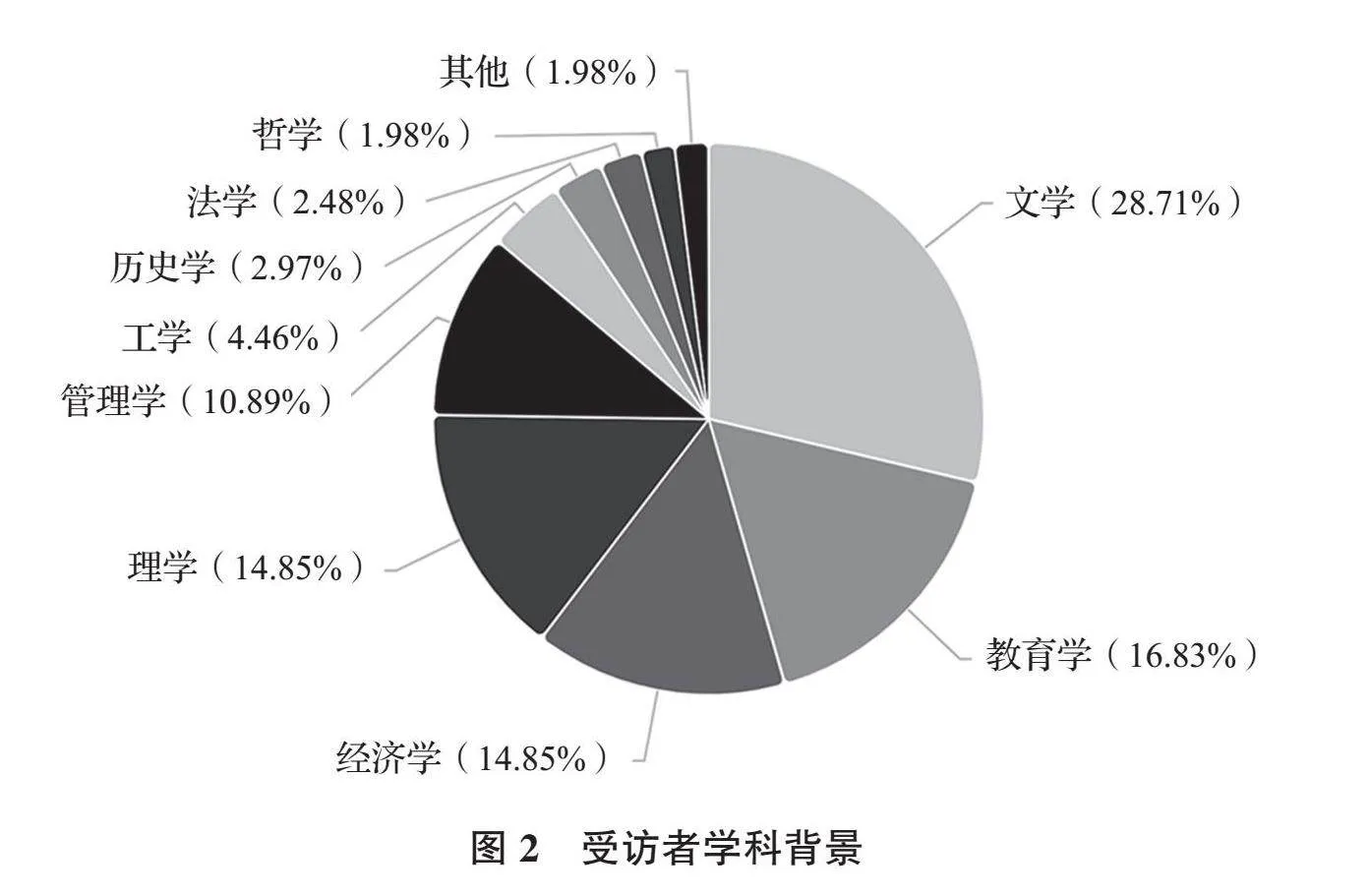
调查共回收202份有效问卷,平均填写时长为10分钟。所有受访者均为汉语母语者,平均年龄为23岁。学生群体占比最大(93.07%),学生家长和教师占比较小(6.93%)。受访人群的受教育程度以本科(64.36%)和硕士(32.67%)为主,详见图1。受访群体来自多元学科,以文学专业(28.71%)和教育学专业(16.83%)为主,详见图2。受访者辞书使用频率多为偶尔使用(37.13%),有时使用(34.16%)和经常使用(15.35%)次之,详见图3。总体来说,本次受访对象主要为接受过高等教育、有一定辞书使用需求和习惯的年轻学生群体,具备对词条优劣进行准确判断的能力。
(二) 大语言模型词条自动编纂整体表现
1. 词条自动编纂的整体表现
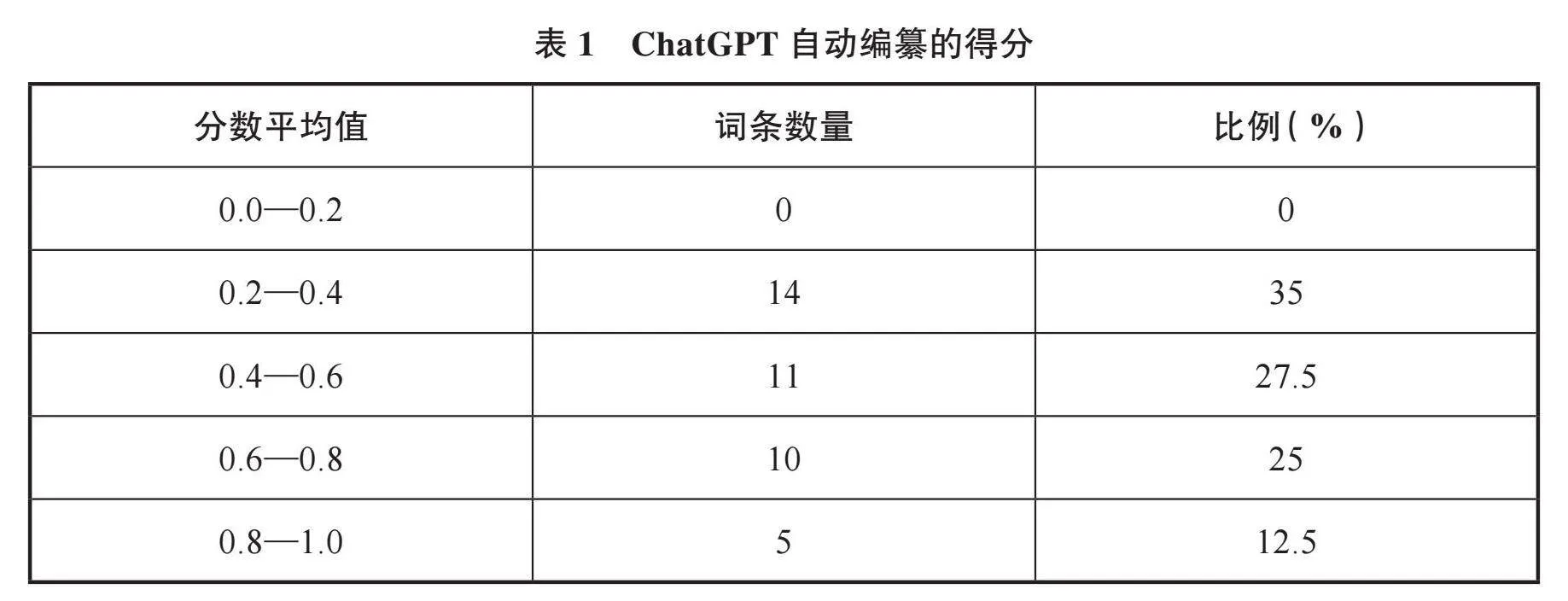
为评估ChatGPT在词条自动编纂上的整体表现,本研究选择每个问题中支持ChatGPT编纂词条的受访者比例,作为该词目在自动编纂任务上的得分。全部词目自动编纂的平均得分为0.548,中位数为0.579,标准差为0.199。40个词目中有15个得分大于0.5,占比37.5%,说明ChatGPT编纂的词条中有37.5%被更多的受访者判定为优于
《现汉》。为进一步分析ChatGPT自动编纂的整体效果,本文将0.0至1.0的得分区间划分为5个,每个区间的宽度为0.2。各区间的词条数量及其占比如表1所示:
表1显示,最低得分区间(0.0—0.2)的词条数量为0,表明所有由ChatGPT编纂的词条中,没有一条被超过80%的受访者认为比《现汉》差。换言之,每个ChatGPT编纂的词条至少有20%的人认为其质量更好。在得分最高的区间(0.8—1.0)内,只有5个词条,仅占总数的12.5%。这表明,被超过80%的受访者认为优于《现汉》的ChatGPT编纂词条数量较少。ChatGPT自动编纂呈现出平均分越高、词条数量越少的趋势,意味着大部分ChatGPT自动编纂的词条质量尚未达到很高的水平,明显优于传统词典释义的词条数量相对较少。总的来说,尽管所有ChatGPT编纂的词条都有一定的支持者,但其整体质量距离全面超越传统词典还有一定差距,特别优秀的词条只占少数。ChatGPT在词条编纂领域展现出了一定的潜力,但要达到更高的水平仍需进一步提升。
2. 不同类型词条自动编纂的整体表现
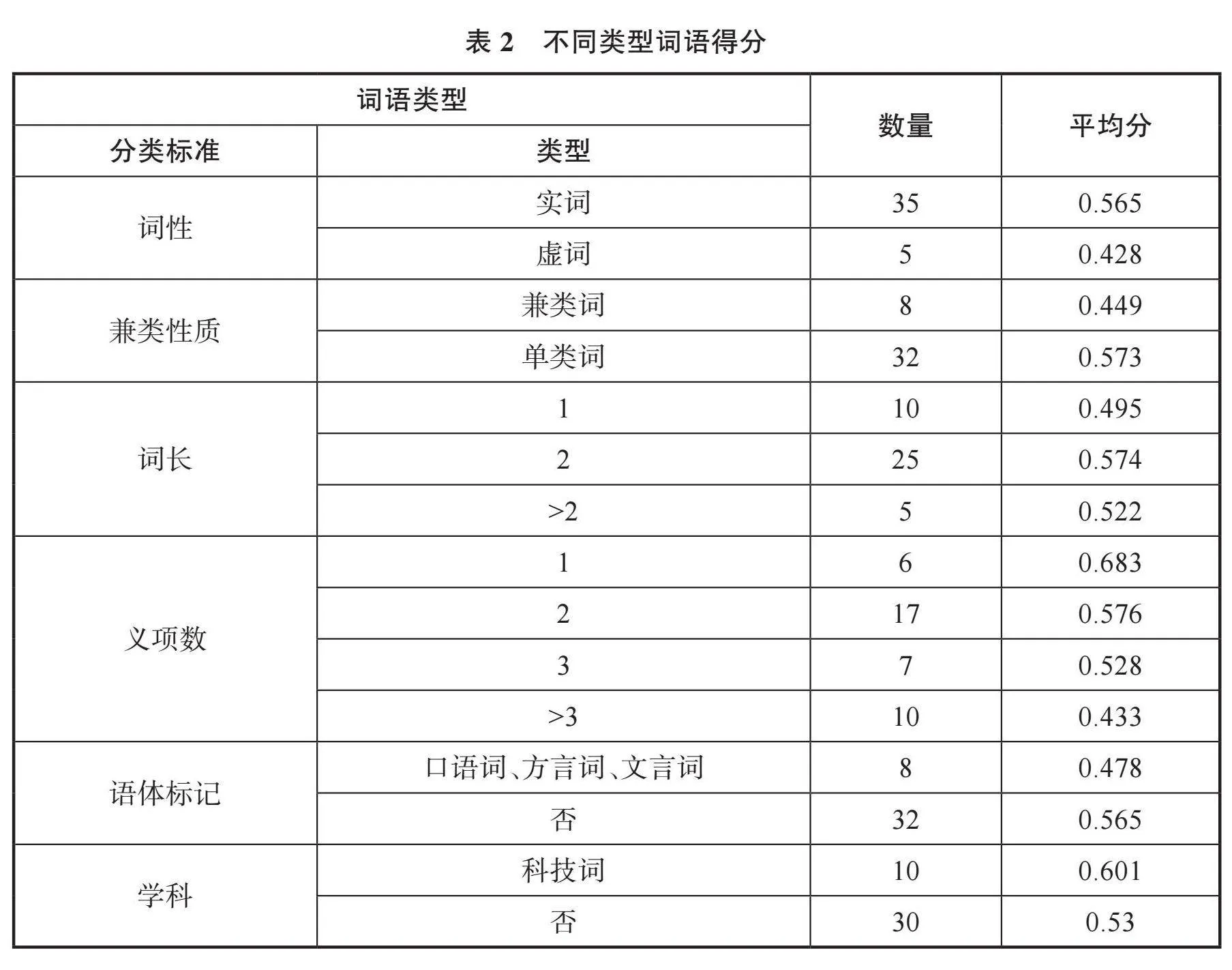
为进一步探究ChatGPT自动编纂释文在不同词语类型上的表现差异,本研究按照词性、兼类性质、词长、义项数、语体标记和学科6个维度,分类统计词条平均分,结果如表2所示:
表2显示,在词性方面,实词平均分为0.565,高于虚词的0.428,表明ChatGPT在实词释义上的表现优于虚词。这可能是由于实词承载了词语的主要意义信息,而虚词更多表达语法功能,前者更容易通过大规模语料学习并生成相关解释。在兼类性质方面,单类词平均分为0.573,高于兼类词的0.449,表明词性越单一,生成的释文越容易被认可。对于兼类词而言,由于其在不同语境下展现出不同语法功能,增加了自动编纂的难度。在词长方面,二字词的平均分最高,为0.574,多字词平均分为0.522,单字词的平均分最低,为0.495。现代汉语中二字词分布最普遍,ChatGPT为这类词语自动编纂的释文能够获得一定的认可度,而单字词中一部分兼做语素,功能和用法更加多样,自动编纂的释文认可度有所下降。在义项数量方面,单义项的词平均分最高,为0.683,义项数大于3的词平均分最低,为0.433。义项数越多的词语,相对而言语义越丰富,用法越复杂,ChatGPT释文不全面、不准确的概率也随之增加。相反,对于单一义项的词语,ChatGPT的释文能够获得更多的认可。在语体方面,口语词、方言词、文言词的平均分仅为0.478,低于一般词语的0.565。可见当前ChatGPT对口语词、方言词、文言词等语体词语的自动编纂能力还有待提升。在学科领域方面,科技词条的平均分达到了0.601,优于其他词语的0.53,表明ChatGPT在科技术语的自动编纂上具有一定优势,这可能得益于训练语料中包含了大量的科技文本,使其能够较好地掌握科技术语的概念。
(三) 大语言模型词条自动编纂的细节表现
本研究中,词条由读音、词性、一个或多个义项、挂尾信息等组成,每个义项又包含释义和例句等信息。问卷调查结果仅反映受访者对词条整体质量的评判,缺乏对词条组成部分的细致考察。为了更全面地评估,本研究对词条各组成部分进行分析,从更多视角评估大语言模型的自动编纂表现。
1. 注音准确性分析
40个词目样本中,ChatGPT对36个词目的注音完全正确,仅有4个词目注音错误,错误率为10%。“着调”“铁帽子王”“花花搭搭”“除了”的读音分别被错标为“zhuótiáo”
“tiěmàozǐwáng”“huāhuādādā”“chúle”,标注错误集中在多音字或轻声音节。然而,ChatGPT具备按提示词标注轻声音节的能力,比如“了”的拼音被准确标注为“·le”。
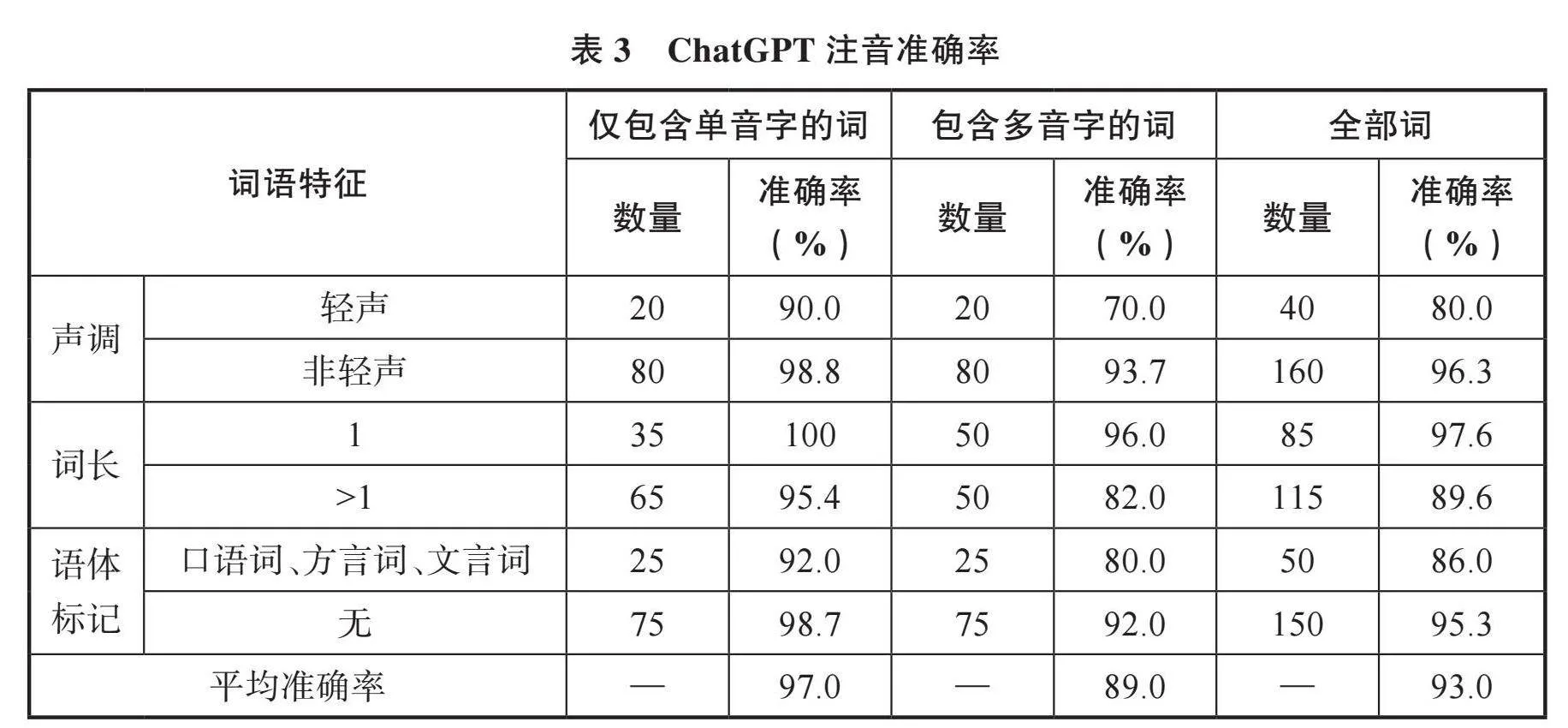
为更准确评估ChatGPT的注音能力,本研究从《现汉》中另外选取200个词语作为样本,其中仅包含单音字的词和包含多音字的词各100个。每个词语从《现汉》中抽取对应的1个例句,由ChatGPT自动标注词语读音。不同类型词语的注音准确率如表3所示:
200个词语中,ChatGPT的平均注音准确率为93.0%,有14个词注音错误。在读音方面,仅包含单音字的词语注音错误数量为3,平均准确率为97.0%;包含多音字的词语注音错误数量为11,平均准确率为89.0%。根据声调、词长、语体标记等特征进一步细分时,包含多音字的词的准确率均低于前者,说明ChatGPT为单音字注音时准确率较高,为多音字注音时更容易出错,其中当标注对象同时包含多音字和轻声字时,注音准确率最低,仅为70.0%。在声调方面,对于不含轻声的词语,ChatGPT的注音准确率为96.3%;对于轻声词,ChatGPT的注音准确率降至80.0%,比如例句“红霞映山崖呃!”中,“呃”读为“·e”,ChatGPT标注为“è”。可见ChatGPT在轻声字的标注上仍有较大的提升空间。在词长方面,单字词的注音准确率为97.6%,二字词和多字词的注音准确率为89.6%,说明词长增加时,ChatGPT标注错误的概率增大。在语体标记方面,一般词语的注音准确率为95.3%,口语词、方言词、文言词等特殊语体词语的注音准确率为86.0%,比如例句“累累若丧家之狗”中,“累累”为书面词,读为“léiléi”,ChatGPT标注为“lěilěi”。根据抽样结果,ChatGPT对多音字、轻声字、多字词、口语词、方言词、文言词等特殊类型字词的注音准确率均低于90.0%,更依赖人工检查和修正。
2. 词性标注准确性分析
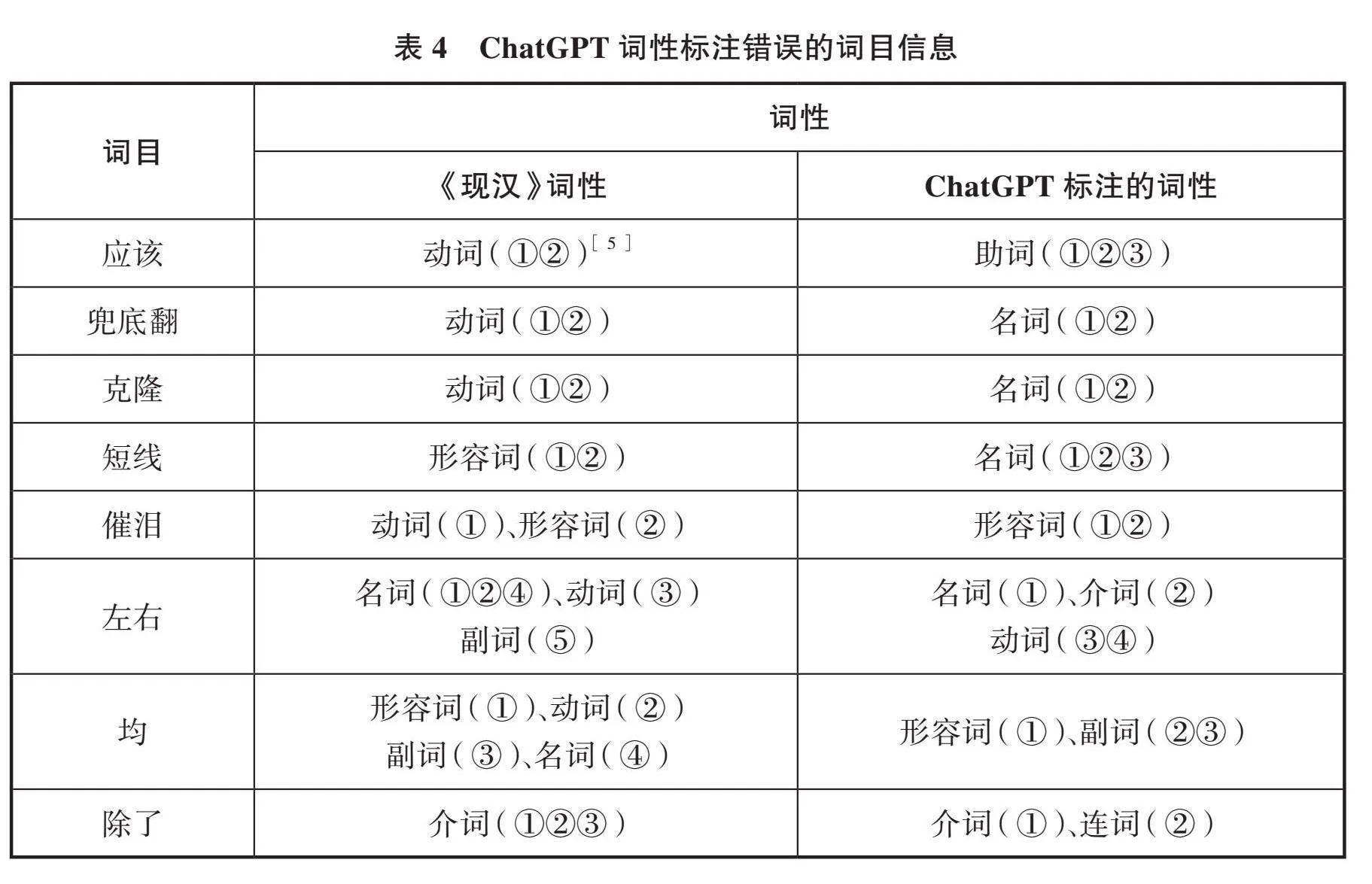
ChatGPT为40个词目生成了102个义项,其中32个词目的词性标注完全准确,占全部词目数的80%;87个义项的词性标注准确,占全部义项数的85.3%。ChatGPT识别为多义词的35个词目中,27个词目的同性标注完全正确,占比为77.1%。词性标注错误的词语均为多义词,其中4个多义词的所有词性均标注错误,4个多义词的词性同时包含正确标注和错误标注。由此可见,ChatGPT对单义词的词性标注较为准确,标注多义词的词性时,性能更加不稳定,可能出现标注错误。ChatGPT词性标注错误详情如表4所示:
词性标注属于自然语言处理领域的基础任务,目前中文词性标注已经达到了较高精度。以通用的PFR《人民日报》标注语料库为例,袁里驰(2023)的方法在该数据集上的词性标注精确率和召回率分别为97.67%、97.48%。相比单纯对给定文本进行词性标注,词条释文生成与词性标注相结合的任务难度更大。本研究中,ChatGPT的义项词性标注精确率和召回率分别为85.3%和75.0%,标注错误的概率较高。一种错误情形是对于单一词类的多义词,ChatGPT将词目所有义项或部分义项的词性标注错误,比如“应该”属于动词中的助动词小类,ChatGPT将所有义项统一标注为助词;“除了”只有介词词性,ChatGPT生成了两个义项,词性分别标注为介词、连词。另一种错误情形是对于兼类词,ChatGPT将部分义项的词性标注错误,比如“催泪”涉及动词和形容词词性,ChatGPT生成了两个义项,都标注为形容词。
3. 义项划分合理性分析
义项划分指将多义词的不同词义按照一定标准加以区分和排列。合理的义项划分有助于准确表达词目含义、揭示词义关联、提高词条可读性。然而,编纂目的不同,辞书读者群体不同,义项划分标准也不尽相同。辞书编纂人员在进行义项划分时同样面临诸多挑战,不同编纂人员的词义划分结果也可能存在差异。因此,义项划分准确性的评判往往具有一定的主观性。本文仅以《现汉》的义项划分作为参照,评估模型义项划分的合理性。
从义项数量上看,《现汉》对本次调查的40个词目划分的义项数最小为1个,最大为9个,平均义项数为2.9个。ChatGPT对40个词目划分的义项数最小为1个,最大为5个,平均义项数为2.55个。这一结果表明,与参照辞书相比,ChatGPT生成的词条在义项数量上总体较为精简。
从义项内容上看,ChatGPT能生成《现汉》未收录的义项,让部分词条得到受访者更高的认可度。然而,ChatGPT在义项划分方面也存在一些不足,主要表现为常用义划分粒度过细,罕用义存在遗漏。以“红线”“哎”“进行”“人”和“感冒”为例,ChatGPT生成的词条和《现汉》词条见下:
红线 hóngxiàn ①用红色染料染成的线:~布。②比喻不可逾越的界限或原则:这是一个政策的~|~问题不容触犯。③中国民间传说中的一种象征性物品,常用以表示天注定的缘分,特别是婚姻:相传月老用~将有缘人连在一起。④在地图或图表上用红色线条标示的线,常用以表示特定的数据或趋势:地图上的~表示铁路线路|销售额的~持续上升。
(ChatGPT)
哎 āi ①表示惊讶、感叹或召唤时的发声:~,你看那边!|~,小张,过来一下。②表示悲伤、叹息或无奈时的发声:~,怎么会这样?|~,真是没办法。③用于语句开头,引起对方注意,没有实际意义:~,我告诉你一个好消息|~,这件事情是这样的。(ChatGPT)
进行 jìnxíng ①表示开始并继续做某事:~调查|项目~中。②指沿着一定路线前进:队伍~了三公里|~式游行。③进展,发展:谈判~得很顺利|工作~得怎么样?(ChatGPT)
人 rén ①指人类,是地球上智力最高的生物:~类|~口。②指个体,通常指成年的男性或女性:外国~|老~。③指有某种身份或特征的人:学~|好~。④指工作人员或服务人员:服务~员|技术~才。⑤用于计算人数的量词:三个~|一大群~。(ChatGPT)
感冒 gǎnmào ①一种常见的呼吸道感染疾病,通常由病毒引起,症状包括发热、咳嗽、鼻塞、喉咙痛等:~症状|预防~。②指患上感冒:他~了|小心不要~。(ChatGPT)
《现汉》中的释义见下:
红线 hónɡxiàn ①指一以贯之的正确理论或思想:唯物辩证法是贯穿全书的一根~。②指划定禁区范围的界线:守住耕地保护的~|制度~,不容越过。(《现汉》)
哎 āi ①表示惊讶或不满意:~!真是想不到的事|~!你怎么能这么说呢!②表示提醒:~,我倒有个办法,你们大家看行不行?(《现汉》)
进行 jìnxínɡ ①从事(某种活动):~讨论|~工作|~教育和批评|会议正在~。
“进行”总是用在持续性的和正式、严肃的行为,短暂性的和日常生活中的行为不用“进行”,例如不说“进行午睡”,“进行叫喊”。②前进:~曲。(《现汉》)
人 rén ①能制造工具并使用工具进行劳动的高等动物:男~|女~|~们|~类。
②每人;一般人:~手一册|~所共知。③指成年人:长大成~。④指某种身份或职业的人:工~|军~|主~|介绍~|电影~|媒体~。⑤别人:~云亦云|待~诚恳。⑥指人的品质、性格或名誉:丢~|这个同志~很好|他~老实。⑦指人的身体或意识:这两天~不大舒服|送到医院~已经昏迷过去了。⑧指人手、人才:~浮于事|我们这里正缺~。⑨(Rén)姓。(《现汉》)
感冒 ɡǎnmào ①传染病,病原体是病毒,在身体过度疲劳、着凉、抵抗力降低时容易引起。症状是咽喉发干、鼻塞、咳嗽、打喷嚏、头痛、发热等。②患这种病。||也叫伤风。
③〈口〉感兴趣(多用于否定式):他对打牌从来就不~。(《现汉》)
关于词条“红线”,尽管ChatGPT生成的义项①价值不大,但义项③和④却具有一定的参考价值,最终86.1%的受访者认为ChatGPT生成的词条更优。
关于词条“哎”和“进行”,与《现汉》相比,ChatGPT对“哎”的义项划分更为细致,但义项并不是分得越细越好,过于细分反而容易使词义不够清晰,给读者查找和定位义项带来困难;ChatGPT为“进行”生成的义项①和③意思相近,《现汉》处理为同一个义项。Jakubíček和Rundell(2023)提到了类似的现象,即ChatGPT倾向于用不同的方式解释同一个意义,这可能导致模型生成的词条中出现信息冗余,需要人工进行甄别和修改。
关于词条“人”和“感冒”,“人”属于基本词,用法较多,ChatGPT只生成了“人”的一些常用义项,而没有生成《现汉》中⑥—⑨对应的义项,这些义项与汉语特定的文化背景和表达习惯密切相关,反映了“人”用法的多样性和灵活性;ChatGPT生成了“感冒”在医学领域的义项,但未生成“感冒”在口语中的用法。可见,处理具有特殊语体色彩的词语时,ChatGPT的表现不够理想,容易遗漏一些非常用义或“地道”的表达方式。
综上所述,ChatGPT在义项划分上展现出了一定的创新性,能够从新颖的角度提供具有启发性的义项,是其优势所在。与此同时,ChatGPT在常用义和罕用义的处理上还存在一些不足,如义项划分颗粒度把握不当、对部分义项的遗漏等。这些问题的存在凸显了人机协作的必要性,即由专业编纂人员对机编义项进行审核和调整,在提高编纂效率的同时,为用户呈现更加准确、全面且富有特色的义项划分。
4. 释义准确性分析
释义是对词义的解释,是词条最核心的组成部分,直接影响着用户对词目的理解和使用。词条释义应该准确、简明、规范,清楚地阐释词语的意义、用法和语法特点等信息。ChatGPT熟练掌握了“指”“形容”“比喻”“表达”等辞书释义用词,生成的释义语言简洁、通俗易懂,没有明显的语法错误,例如“回信”和“逆天”:
回信 huíxìn ①对收到的信件作出的答复:收到一封~|期待你的~。②对收到的信件进行回复:请尽快~。
逆天 nìtiān 网络流行语,原指违背自然法则或常理,后泛指某人或某事物的能力、表现远超常人或常规,达到了令人难以置信的程度:他的记忆力简直~|这款游戏的难度~。
然而,ChatGPT生成的释义也存在一些问题,主要包括以下两种情况:
(1) 完全虚构释义。幻觉现象是大语言模型普遍存在的问题,ChatGPT生成的释义可能与事实不符。虚构的释义缺乏真实性和可靠性,容易误导读者。例如,“兜底翻”的ChatGPT释义和《现汉》释义如下:
兜底翻 dōudǐfān ①指在体操、杂技或其他运动中,以双脚为轴心进行的一种翻转动作,身体形成一个圆弧:完成一次~|~训练。②泛指在其他领域中进行的类似翻转、翻身的行动或变化:事业上的~|策略上的~。(ChatGPT)
兜底翻 dōudǐfān ①比喻把底细全部揭露出来:对这起事故的原因要~,彻底查,决不姑息。②比喻彻底换掉:工作要有连续性,不要换一届领导就~。(《现汉》)
“兜底翻”原指为寻找某物将所有东西都翻出来,常用来借指彻底推翻原有的计划、方案,《现汉》收录了该词的两个比喻义。ChatGPT将“兜底翻”解释为一种运动动作,不符合实际。
(2) 释义不准确。有时ChatGPT仅给出词目中个别语素的含义,以偏概全。例如,ChatGPT为“左右”生成的释义如下:
左右 zuǒyòu ①表示方位,与“右”相对:他站在我~|~手。……(ChatGPT)
义项①的释义实际是“左”的含义,ChatGPT生成时忽略了“右”,使用“左”来代表“左右”,未能准确表达“左右”作为方位词的意义。
有时ChatGPT对词目概念的描述不够严谨、不够清晰。例如,ChatGPT为“矛盾”生成的释义如下:
矛盾 máodùn ①古代兵器,一端是矛,另一端是盾。……(ChatGPT)
义项①前半部分“古代兵器”符合“矛盾”的性质,但进一步的描述存在问题,“一端是矛,另一端是盾”容易让读者误以为“矛”和“盾”是同一兵器的两个部分,但实际上“矛”和“盾”是两种兵器。
5. 举例准确性分析
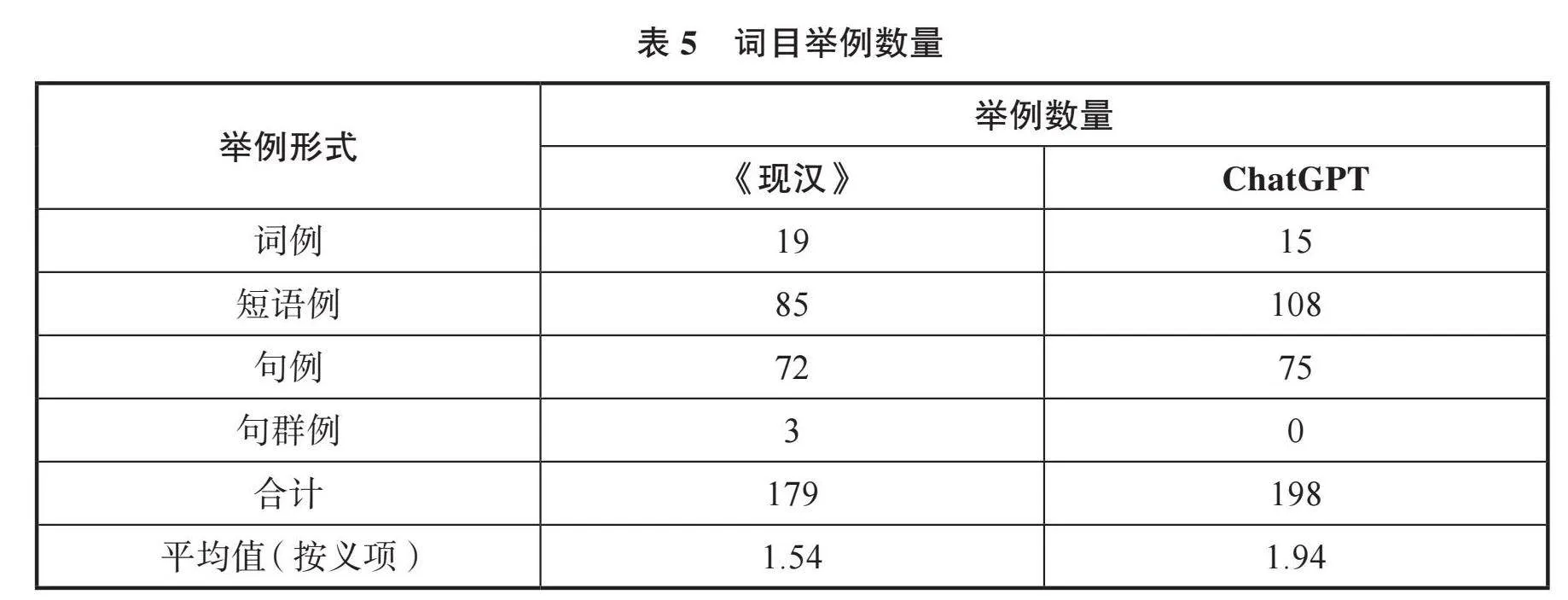
辞书编纂中的举例按照形式可分为词例、短语例、句例、句群例等。传统的举例编纂方式包括自编、改编和书证,而随着自然语言处理技术的发展,大语言模型已经能够自动生成不同形式的举例,即机编例子。40个词目不同形式的举例的数量见表5所示:
ChatGPT生成的举例数整体上高于《现汉》,以短语例(54.55%)为主,其次是句例(37.88%),词例数量较少(7.58%),未生成句群例;《现汉》举例以短语例(47.49%)和c/ICAlStMK7KjOiSx8G7vSgRnee0iycDKX0rt0qm8vw=句例(40.22%)为主,词例数量较少(10.61%),此外包含少量句群例(1.68%)形式。相比于《现汉》,ChatGPT生成词目的举例类型更为单一,短语例出现最为频繁,词例、句例和句群例的比例均略低于《现汉》。尽管在词条自动编纂释文的提示词中,举例被描述为可选项,但ChatGPT为所有词目无一例外地生成了举例。ChatGPT和《现汉》词条中各个义项举例数量的标准差分别为0.27和1.51,可见ChatGPT举例数量整体分布较平均,相比之下,《现汉》对用法多的词目集中举例,非必要不举例,兼顾了典型性和针对性。
《〈现代汉语词典〉编纂细则》(吕叔湘2004)在总则中论述了辞书举例的指导思想,“举例要注意思想内容,语言生动活泼,并且多样化。切忌内容庸俗,形式大同小异,语言僵硬单调”。经过检查,ChatGPT生成的举例存在虚构和重复等问题。比如,ChatGPT为词目“干净”“不”“左右”生成了“干净官”“不胜似败”“成败由左右”等例子,汉语中不存在这些用法。举例重复问题以“着调”为例:
着调 zhuótiáo ①形容事物调和,搭配得当:这套家具的颜色很~|装饰得~。②指言行得体,合乎情理:他做事总是很~|谈吐~。③形容人或事物有特色,引人注目:这个设计很~|她的穿搭风格很~。(ChatGPT)
“着调”三个义项的举例都反复出现“很~”结构,虽然整体能够体现词语的语义搭配用法,但句法形式缺乏变化,存在公式化问题,同时内容不够精简,占用较大篇幅。
综上所述,ChatGPT虽然能快速生成举例,但其多样性、灵活性、针对性有待提高。可以通过优化提示词、提供包含词目的语料等方式,进一步提升机编例子的质量,使其在句法结构和语义表达上更加丰富多样,更好地满足辞书举例实际需求。此外,也可以限定举例形式和数量,让ChatGPT有针对性地生成更多举例,供辞书编纂人员挑选。
四、 余 论
本文以ChatGPT为例,调查了大语言模型在汉语辞书词条自动编纂中的表现。结果表明,ChatGPT在注音和词性标注方面展现出较高的准确率,尤其对单音字和单一词性词的标注效果更佳。ChatGPT能够从新颖角度提供具有启发性的义项,体现出一定的创新性。在释义方面,ChatGPT生成的释文语言简洁通俗,无明显语法错误。同时,ChatGPT能快速、批量生成举例,节省人力。然而,ChatGPT在处理多音字、轻声字、多义词、口语词、方言词、文言词等特殊词语时,注音和词性标注的准确率有待提高,对义项划分把握也欠佳,容易遗漏非常用义项。此外,ChatGPT生成的释义可能出现虚构或不准确等情况,包括举例形式单一、内容重复、针对性不足等问题。
ChatGPT等大语言模型为传统辞书编纂模式带来了新的启示。一方面,ChatGPT可作为辞书编纂的辅助工具,通过高效生成词条初稿,实现人机协同,节省编纂时间,提升编纂质量。另一方面,针对性优化大语言模型在辞书编纂中的应用,如专门训练或微调模型、完善释义机制、丰富举例形式等,将有助于提高机编辞书的整体水平。此外,充分发挥大语言模型的技术优势,积极探索辞书编纂的创新路径,如拓展义项划分视角、实现辞书动态更新、满足用户个性化需求等,也是值得关注的发展方向。同时,在语料选取、模型架构设计、评估体系构建等技术层面进行持续优化,将为大语言模型赋能辞书编纂提供更加坚实的基础。
随着人工智能的发展,大语言模型必将助力汉语辞书向智能化方向发展,但此间也将面临诸多挑战。辞书编纂模式变革、查检方式创新固然值得期待,但编纂理念更新、知识产权保护、人才队伍建设等问题也同样值得关注。推动汉语辞书编纂理论和实践的创新发展,需要在借鉴大语言模型等前沿技术的同时,加强传统编纂理论与人工智能技术的深度融合,建立健全人机协同的辞书编纂新范式。只有在坚持传承与创新并重的基础上,加强多学科交叉融合,才能更好地推进汉语辞书编纂事业的智能化发展,为广大读者提供更加优质、高效、个性化的辞书服务。
本研究的不足主要有:(1) 设计问卷时,考虑到受访者作答时间因素,将最初的100个词目降为40个词目,样本数量的减少一定程度上影响了样本的代表性和结论的可靠性。(2) 研究主要采用问卷调查的方式,通过受访者的主观判断来评估ChatGPT编纂词条的整体质量,评估指标较为单一。(3) 文章重点关注ChatGPT在词条自动编纂中的表现,但缺少与其他自动编纂方法的对比,缺少不同大语言模型之间的对比。(4) 提示词的编写有许多策略,本文对这些策略的使用不够充分。未来可针对上述不足进一步扩展本研究。
附 注
[1] 主页:https://www.collinsdictionary.com/dictionary/english。
[2] 主页:https://www.macmillanenglish.com。
[3] ChatGPT使用该提示词生成GI1ooJzO4umsAqz4J1HmGTorE+8fjuvGwpRKZc+Vq2A=释义的时间为2024年1月23日。
[4] ChatGPT直接生成的词条见下:
“热络” rèluò {形}①形容感情亲密,交往频繁:他们之间的关系很~|~的气氛。②指活动或场合气氛热烈,人际交往频繁:聚会十分~|市场~。(ChatGPT)
“彼” bǐ {代} ①指远离说话人和听话人的人或事物:~岸|~处。②用于指代前文已提到的人或事物:~时|~人。③古代文言文中,常用作男子的美称:~生|~君。(ChatGPT)
为便于同《现汉》词条对比,我们对ChatGPT生成的词条进行了后处理:词目删除双引号,词性外加方框。
[5] 括注内的序号表示标注了当前词性的义项号。
参考文献
1. 范齐楠,孔存良,杨麟儿,等.基于BERT与柱搜索的中文释义生成.中文信息学报,2021(11):80-90.
2. 吕叔湘.《现代汉语词典》编写细则. //中国社会科学院语言研究所词典编辑室编.《现代汉语词典》五十年.北京:商务印书馆,2004.
3. 魏雪,袁毓林.基于规则的汉语名名组合的自动释义研究.中文信息学报,2014(3):1-10.
4. 袁里驰.基于BiLSTM-CRF的中文分词和词性标注联合方法.中南大学学报,2023(8):3145-3153.
5. 中国社会科学院语言研究所词典编辑室编,现代汉语词典(第7版).北京:商务印书馆,2016.
6. Cai Z,Haslett D,Duan X,et al. Do Large Language Models Resemble Humans in Language Use? arXiv preprint arXiv:2303.08014,2023.
7. Gadetsky A,Yakubovskiy I,Vetrov D. Conditional Generators of Words Definitions. //Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics,2018(2):266-271.
8. Jakubíček M,Rundell M. The End of Lexicography? Can ChatGPT Outperform Current Tools for Post-editing Lexicography? //Proceedings of the eLex 2023 Conference,2023:518-533.
9. Kong C,Chen Y,Zhang H,et al. Multitasking Framework for Unsupervised Simple Definition Generation. // Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics,2022(1):5934-5943.
10. Lew R. ChatGPT as a COBUILD lexicographer. Humanities and Social Sciences Communications,2023(10):1-10.
11. Noraset T,Liang C,Birnbaum L,et al. Definition Modeling:Learning to Define Word Embeddings in Natural Language. // Proceedings of the AAAI Conference on Artificial Intelligence,2017(31):3259-3266.
12. OpenAI,Achiam J,Adler S,et al. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774,2023.
13. Phoodai C,Rikk R. Exploring the Capabilities of ChatGPT for Lexicographical Purposes:A Comparison with Oxford Advanced Learner’s Dictionary within the Microstructural Framework.
//Proceedings of the eLex 2023 Conference,2023:335-365.
14. Rees G,Lew R. The Effectiveness of OpenAI GPT-Generated Definitions Versus Definitions from an English Learners’ Dictionary in a Lexically Orientated Reading Task. International Journal of Lexicography,2024(1):50-74.
15. Tran H,Podpečan V,Tomazin M,et al. Definition Extraction for Slovene: Patterns,Transformer Classifiers and ChatGPT. //Proceedings of the eLex 2023 Conference,2023:19-38.
(张永伟 中国社会科学院大学文学院/中国社会科学院辞书编纂研究中心 北京 102488;
刘 婷 中国社会科学院大学文学院 北京 102488)
(责任编辑 郎晶晶)
