
基于深度学习的ChatGPT中文语音自动识别方法
2024-09-23 00:00郑瑶
无线互联科技 2024年17期
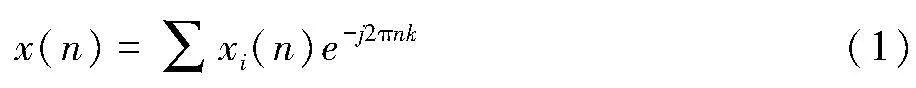




摘要:针对传统中文语音信息识别对语音噪声处理不足、影响识别效果的问题,文章提出了一种基于深度学习的ChatGPT中文语音自动识别方法。该方法首先对原始语音信号进行离散傅里叶变换,并利用美尔标数将线性频率映射到美尔非线性频谱,提取中文语音频谱特征。然后,计算倒谱的频率响应和,引入深度卷积神经网络对提取的特征进行匹配分析,确定最终的识别结果。最后,应用实验证明所提方法的先进性,测试结果表明,该方法应用后,噪声对识别结果的影响被显著减弱,整体CCER均值为9.34%,应用效果较好。
关键词:深度学习;中文语音识别;离散傅里叶变换;美尔标数
中图分类号:TP391 文献标志码:A
0 引言
随着ChatGPT等人工智能技术的飞速发展,语音识别技术作为其关键部分,展现出显著进步与广阔应用前景[1]。因此,深入研究语音识别技术对于理解其实际应用价值、优化性能及拓展新应用场景至关重要[2-3]。在语音识别研究中,姜囡等[4]提出了一种基于注意力机制与语谱图特征的语音识别技术,该技术通过注意力机制解决了长句错误对齐和信息丢失问题,从而提高了识别准确性,但该技术对计算资源需求高,限制了其在资源有限环境中的应用。再如郭嘉等[5]则提出了融合提示方法与知识蒸馏的口语语音识别模型,该模型有效降低了计算资源和存储空间消耗,使其更适用于嵌入式和物联网设备,同时保持了好的性能与实时性。基于此,文章提出了一种基于深度学习的聊天生成型预训练变换模型(Chat Generative Pre-trained Transformer,ChatGPT)中文语音自动识别方法研究。
1 中文语音自动识别方法设计
1.1 中文语音频谱特征提取
为提高识别效果,文章先对原始中文语音信息的频谱特征进行分析,并将其作为后续识别的执行基础。在具体提取阶段,处理函数可以表示为:
其中,x(n)为DFT处理后的中文语音数据信号,xi(n)为中文语音数据信号在单位时间窗内的时域分布,k为时域信号的分布阈值。
对于离散傅立叶变换(Discrete Fourier Transformation,DFT)处理后的中文语音数据信号,文章利用美尔标数将中文语音数据信号表现出的线性频率映射到美尔非线性频谱中。利用离散余弦变换(Discrete Cosine Transform,DCT)对中文语音数据信号进行反变换,求取倒谱对应的频率响应之和,其公式可表示为:
结果,a为人耳感知信号频率的度量单位的常数值,f为中文语音数据信号的线性频率参数,λ为与音调有非线性对应关系的物理频率系数。基于上述内容,文章结合了给定中文语音数据帧信号的倒谱系数特征,并利用一阶导数delta为梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)特征设置了时间标签,以赋予其动态属性。该处理过程可通过以下函数进行表示:
其中,Δcm(n)为具体动态属性的中文语音数据信号MFCC特征参量。
按照上述方式,实现中文语音频谱特征提取,以为后续语音自动识别提供可靠依据。
1.2 基于深度卷积神经网络的中文语音识别
结合1.1部分对中文语音频谱特征的提取结果,文章引入卷积神经网络(Convolutional Neural Network,CNN)进行语音识别。先设置由权值矩阵构成的卷积核作为关键可辨别特征的提取载体,其权值参数可以表示为:
W(t+1)=W(t)+bδ(t)Δcm(n)(4)
其中,W为卷积核中的权值参数设置,b为卷积核中偏置参数设置,δ(t)为误差项。
卷积核的神经元按照局部连接的方式,经过激活函数与池化层的相邻神经元建立连接关系,并在权值共享模式下对特征匹配的语音信息进行计算,这一过程具体可以表示为:
其中,dj-1j为激活函数与池化层相邻神经元之间的连接系数,u和v分别为特征图谱的层数和单元构成数。按照上述所示方式,实现对中文语音的有效识别,从而在最大限度上保障识别结果的可靠性。
2 应用测试
2.1 测试准备
在分析测试文章设计的中文语音识别方法的性能时,文章基于一个中文语音数据库进行了对比测试。在测试过程中,本次采用了THCHS-30、AISHELL等公开可用的中文语音数据集,以保证数据的多样性和丰富性。为能够更加客观地对设计识别方法的性能作出评价,文章还分别设置姜囡等[4]提出的以注意力机制语谱图特征为基础的语音识别技术,以及郭嘉等[5]提出的以提示方法与知识蒸馏融合为基础的口语语音识别模型作为测试的对照组,通过对比分析3种方法的测试结果,评价设计方法的应用效果。
2.2 测试评价指标设置
在对3种不同方法的测试结果进行分析时,文章将识别结果评断因子CCER作为具体的评价指标,对应的计算方式可表示为:
其中,CCER为识别结果评断因子,I为识别结果词序列与测试语音数据词序列真实值达到一致状态执行插入操作的词汇总数,D为识别结果词序列与测试语音数据词序列真实值达到一致状态执行删除操作的词汇总数,S为识别结果词序列与测试语音数据词序列真实值达到一致状态执行替换操作的词汇总数,N为标准测试语音数据词序列中的词汇总数。识别结果评断因子CCER的值越小,表示对应的识别效果越好,相反地,识别结果评断因子CCER的值越大,表示对应的识别效果越差。
2.3 测试结果与分析
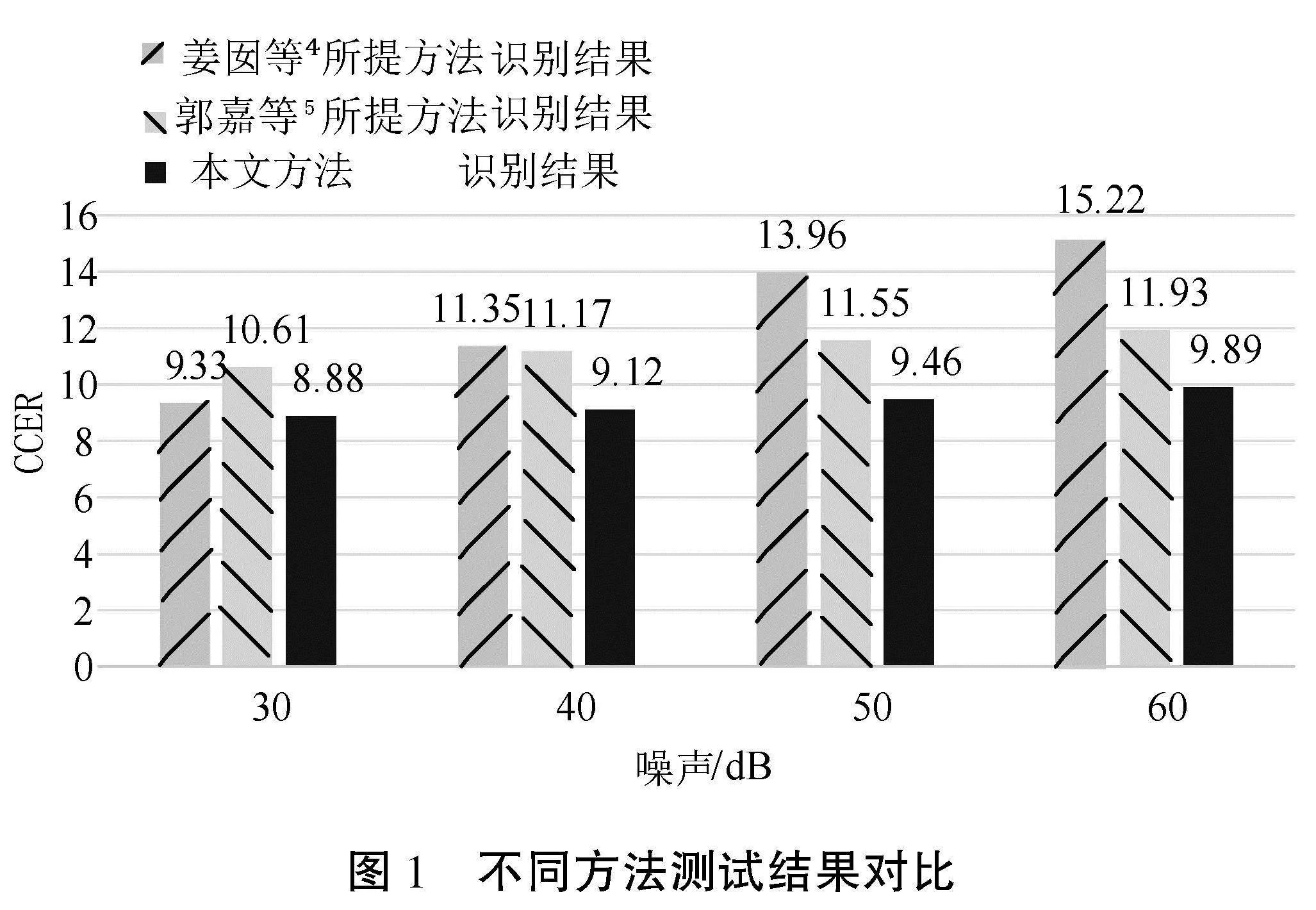
以上述为基础开展测试,得到对比结果如图1所示。
结合图1的测试结果,3种语音识别方法的性能对比如下:姜囡等[4]的方法在噪声影响下表现出较明显的性能下降,随着语音噪声从30.0 dB增加到60.0 dB,CCER从9.33显著增加到15.22,涨幅显著。郭嘉等[5]的方法对噪声的鲁棒性较强,CCER整体稳定在12.00以内,但均值为11.31,表明其性能仍有进一步优化空间。相比之下,文章设计的方法在噪声环境下表现更为稳定,CCER始终保持在10.0以内,即使在60.0 dB的噪声下,CCER最大值也仅为9.89,整体识别结果的CCER均值为9.34,明显优于对照组。综上所述,文章设计的中文语音自动识别方法能够有效应对不同质量的语音信息,在ChatGPT的研发中具有显著应用价值。
3 结语
随着ChatGPT等AI技术的发展,语音识别技术将在更多领域发挥关键作用。通过深入研究语音识别技术、探索新应用场景并优化算法性能,可极大地提升生活品质和工作效率。文章提出的基于深度学习的ChatGPT中文语音自动识别方法,可实现多语义环境下语音信息的有效识别,应用效果较好。希望未来可进一步推动ChatGPT在中文应用领域的开发,以为用户提供更优质的使用体验。
参考文献
[1]相增辉,张国梁,庞渊源,等.基于深度卷积神经网络的智能机器人语音自动识别方法[J].自动化技术与应用,2024(4):43-46.
[2]高鹏淇,黄鹤鸣.基于ASGRU-CNN时空双通道的语音情感识别[J].计算机仿真,2024(4):180-186.
[3]魏佳楠,孙颖,张雪英.基于SAE-LS-CGAN数据增强的语音情感识别[J].太原理工大学学报,2024(27):1-12.
[4]姜囡,庞永恒,高爽.基于注意力机制语谱图特征提取的语音识别[J].吉林大学学报(理学版),2024(2):320-330.
[5]郭嘉,彭太乐.基于提示方法与知识蒸馏方法的口语语音识别模型构建[J].西华大学学报(自然科学版),2023(6):59-67.
ChatGPT Chinese speech automatic recognition method based on deep learning
Abstract: In view of the problem that the traditional Chinese speech information recognition handles the speech noise insufficient and affects the recognition effect, this paper proposes a ChatGPT Chinese speech automatic recognition method based on deep learning. This method first performs the discrete Fourier transform of the original speech signal, and maps the linear frequency to the linear nonlinear frequency spectrum to extract the Chinese speech spectrum features. Then, the frequency response sum of the inverted spectrum is calculated, and a deep convolutional neural network is introduced to match the extracted features to determine the final identification results. Finally, the experiment is applied to prove the advancement of the proposed method. The test results show that the influence of noise on the recognition result is significantly weakened, and the overall CCER average of the method is 9.34%, and the application effect is good.
Key words: deep learning; Chinese speech recognition; discrete Fourier transform; merrill standard number
