
融合语义信息的城市音频场景识别方法
2024-09-23 00:00:00农文韬孙雨桐梅宇
无线互联科技 2024年17期
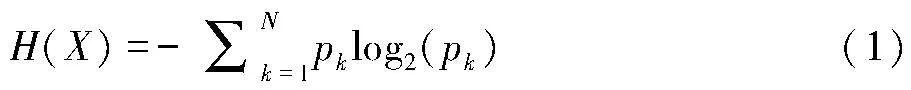
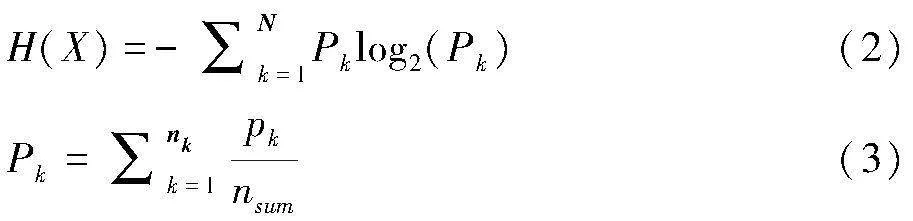
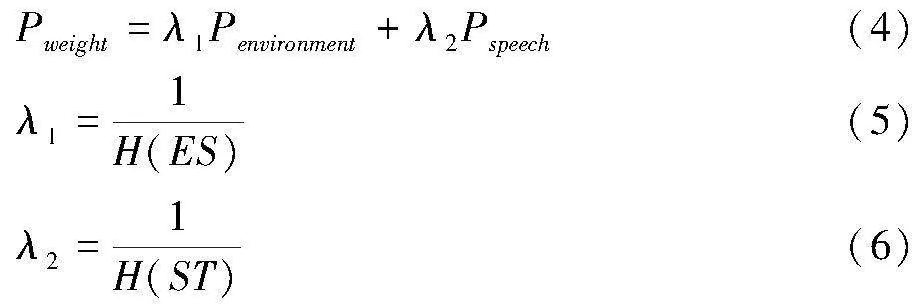
摘要:针对音频场景识别领域中城市场景易混淆、难以区分的问题,文章提出了一种融合语义信息的城市音频场景识别方法。算法首先通过语音活动检测将语音与环境声音分割,然后分别对语音与环境声音进行场景类型识别,再将两者识别的场景概率通过信息熵加权计算,最终得到融合语义信息的音频场景类型。该方法有效解决了传统环境音频场景识别方法对于易混淆、低区分度音频场景分类结果较差的问题。实验表明,文章提出的方法对于篮球场、超市等易混淆城市音频场景的识别效果有较为明显的改进作用,同时识别结果也证明了语义信息对城市音频场景识别的重要性。
关键词:音频场景识别;语义信息;CNN;BiLSTM;信息熵;信息融合
中图分类号:TN912.3 文献标志码:A
0 引言
城市声环境对人们的生活有着重要影响:一方面,人类和社会活动的声音监测对于公共安全有着至关重要的价值[1-2];另一方面,声音数据能有效弥补光线灰暗和物体遮挡对光学传感器采集的影响,是全息地图、视频监控的补充数据源之一[3-4]。因此,环境音频场景识别(EASR)得到了来自声学、计算机科学、地理信息科学等领域的关注。
现有的各种EASR方法主要针对环境声音的时间域、频率域、倒频谱等特征来进行分析与识别音频场景[1]。目前在环境音频场景识别领域,主要的方法有基于生成模型的方法[5-6]、基于判别模型的方法[7-9]、基于深度学习模型的方法和基于混合模型的方法[10-13]。其中,基于深度学习的方法是主流,有着较好的识别率,比较常用的有卷积神经网络(CNN)、深度神经网络(DNN)等。Hamid等[10]使用多通道i-vector和CNN的混合方法从声学场景中捕获互补信息,这种混合方法利用分数融合技术从室内和室外场景中获取补充信息,其在2016年国际声学场景检测及分类挑战赛中获得第一名。
然而,现有的音频场景识别方法对于易混淆的场景仍难以区分,例如街道交通与餐馆、步行街、市集、商店等。这些音频场景没有显著的区分度,仅凭音频特征难以将它们准确地分类[9-14]。这是因为:(1)在音频信号中,信噪比(SNR)通常非常小,特别是麦克风离声源不太近的情况[2]。(2)音频场景判别信息存在于低频范围[15],难以识别。(3)环境声音场景没有特定的结构,如音素或韵律[16]。这些原因导致易混淆、低区分度的音频场景特征差异并不明显。
针对上述问题,本研究拟通过融合语义信息提升音频场景的识别效果,针对城市中人群活动密集的典型音频场景,通过环境音频场景识别方法确定可能的场景,并结合语音主题分类结果辅助判断,区分易混淆的音频场景,提升识别的正确率。
1 融合语义信息的城市音频场景识别方法
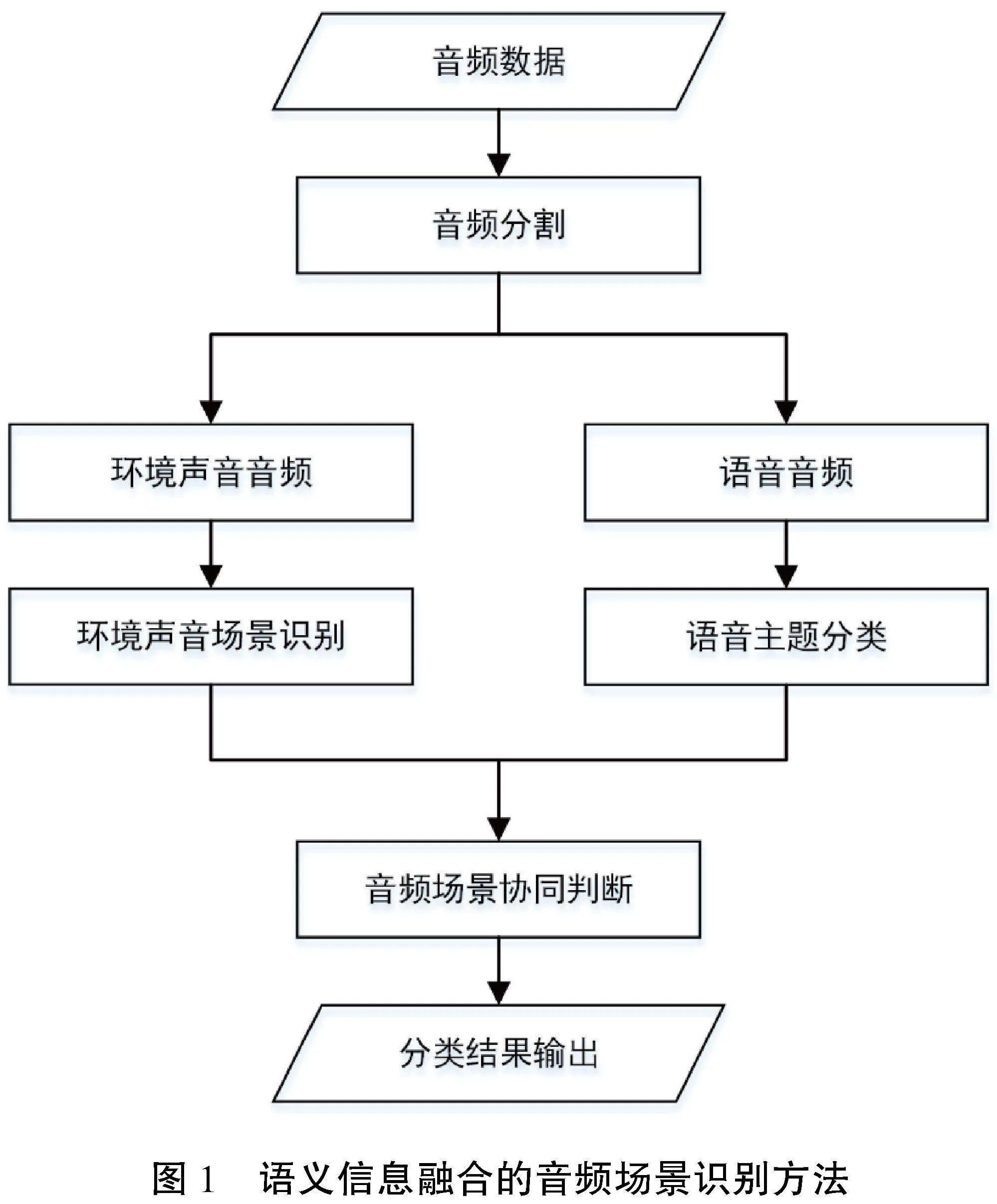
本文提出的融合语义信息的城市音频场景识别方法,主要包括下列步骤:(1)音频分割;(2)环境音频场景识别;(3)语音主题分类;(4)音频场景协同判断。图1展示了方法的大致流程。
在真实城市环境中,语音与环境声音常同时出现。在音频场景识别的研究中,通常不考虑语音信息,但语音中蕴含着人类对周围地理环境的评价、情感等信息,可以作为语义信息辅助音频场景判别。本文提出的方法对同一地点的语音、环境声音进行信息提取与分类,输入的音频数据格式为常用音频格式,例如MP3(.mp3)、WAV(.wav)等,同时包含语音与环境声音。
1.1 音频分割
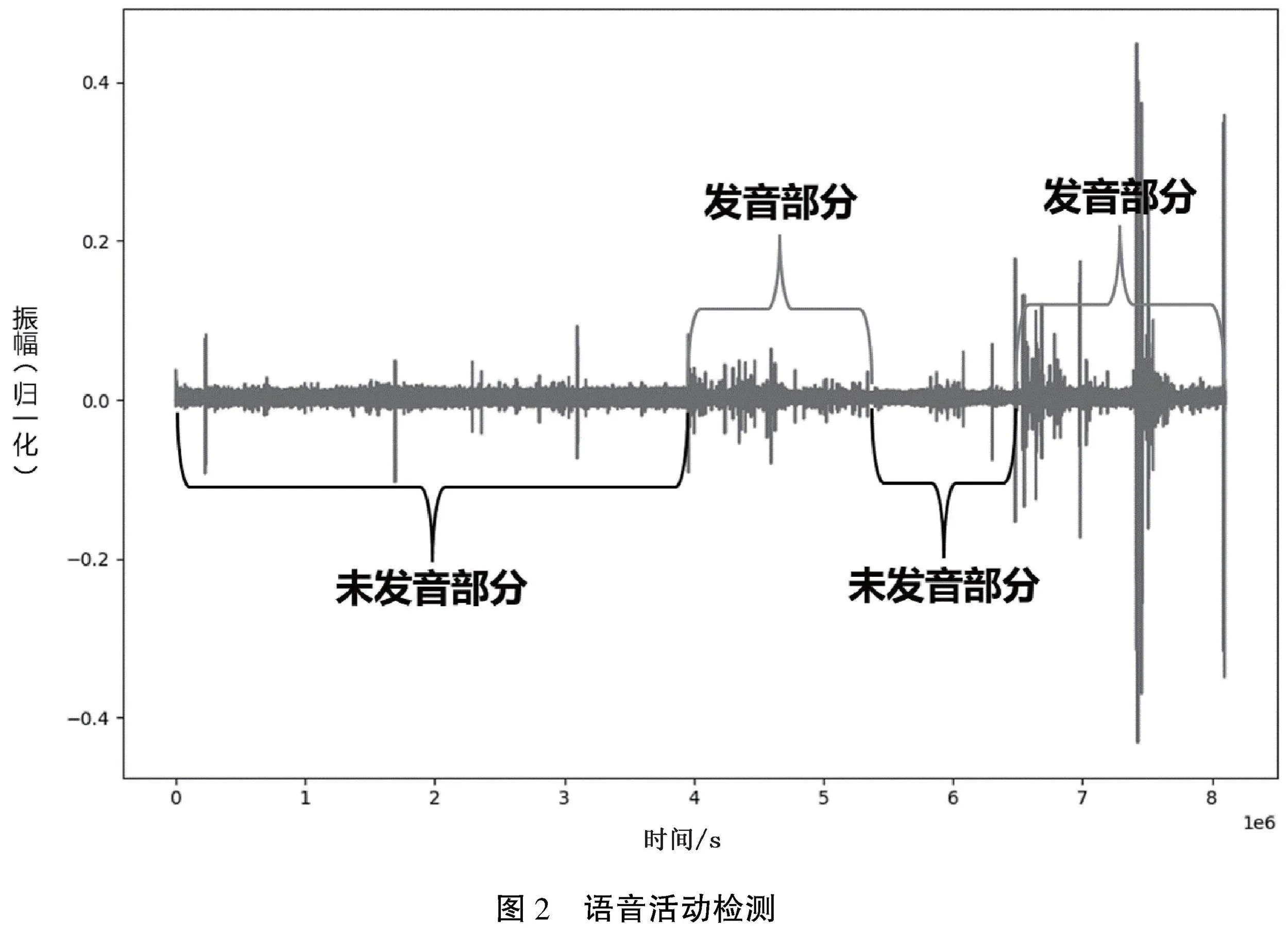
语音活动检测(VAD)是数字语音处理领域不可 或缺的一部分,目的是找到有效语音的端点,从而将其与噪声区分开来,如图2所示[17]。VAD算法具有高效、低计算成本的特点,能快速地进行语音段识别。本文通过VAD方法将音频中的语音与环境声音区分标识,并进行音频分割。
VAD方法的基本思路是根据语音和环境声的不同特征进行判断。由于清音(unvoiced sound)和环境声的特性非常相似,但浊音(voiced sound)的特性与环境声有明显的区别[17]。因此,清音/浊音检测方法非常常用,通常算法会将音频信号划分为发音部分(voiced)、未发音部分(unvoiced)和静默部分(silence)。VAD方法的大致流程如下:
(1)将音频信号进行分帧处理;
(2)从每一帧中提取特征;
(3)在一个已知语音和环境声音信号区域的数据帧集合上训练一个分类器;
(4)对未知类别的数据帧进行分类,判断其属于语音信号还是环境声信号。
将输入的音频记为A,通过VAD方法将音频分割为语音音频集S={si|i=0,1,…,n}与环境音频集E={ej|j=0,1,…,m},这里n与m分别为分割得到的语音音频数量与环境音频数量。
1.2 环境音频场景识别
卷积神经网络(CNN)是深度学习方法中广泛使用的架构之一,通过CNN方法进行环境音频场景识别,可以同时考虑音频时间域与频率域的特征[10,18-23]。CNN包括输入层、隐含层与输出层,其中隐含层包括卷积、池化与全连接层。
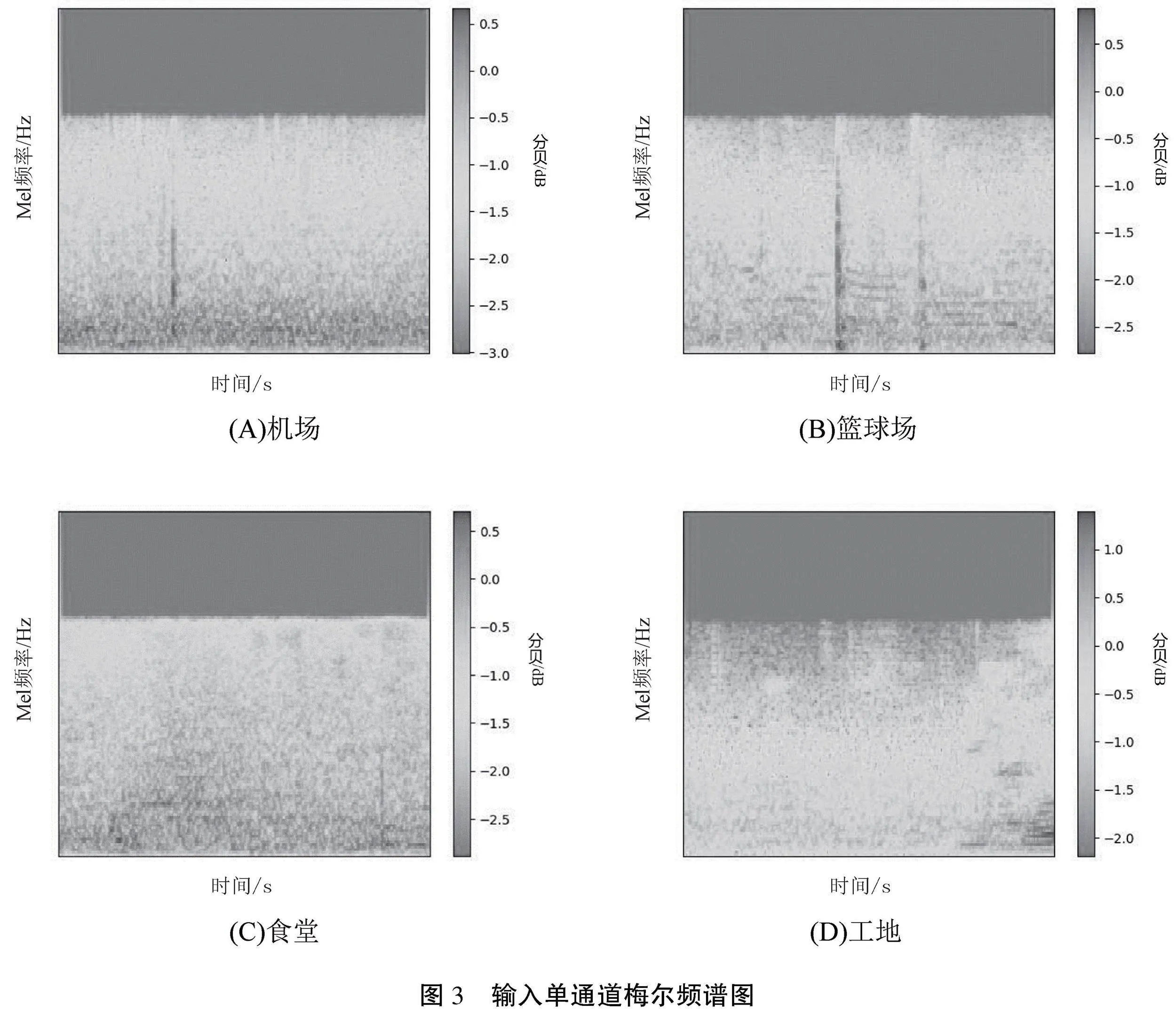
研究采用的CNN模型部分遵循Visual Geometry Group(VGG)风格[10],输入大小是一个128×345的单通道频谱图,如图3所示。本文使用的卷积神经网络结构包含多个并行的卷积块,每个卷积块使用了不同大小的卷积核,可以帮助模型捕捉不同大小和方向的特征。通过将4个并行卷积块的输出相加,模型可以综合这些特征以提高性能。在卷积层之后,模型使用全局平均池化层(Global Average Pooling)来减少参数数量,降低计算复杂度,同时防止过拟合。模型使用一个全连接层(Dense层)将特征连接到不同的类别,并通过Softmax激活函数将输出转换为概率分布,通过输出具有最高概率的类别作为预测结果。
将1.1小节中分割得到的环境音频E切分为1 s长度的短音频,标记后通过上述模型进行训练,得到环境音频场景识别预训练模型。此模型可以识别一段短音频ej可能的环境音频场景及其概率。输入环境音频集E,得到每段短音频ej、环境音频场景esj及其概率pj,统计esj得到A的环境音频场景集合ESA={esj|j=0,1,…}及其概率PAes={pj|j=0,1,…}。
1.3 语音主题分类
语音文本主题分类旨在对文本集按照一定的分类体系或标准进行自动分类标记,属于一种基于分类体系的自动分类方法。对语音文本进行场景主题分类,能为音频场景识别提供额外的信息。根据上一节提取出的环境音频场景集合ES,结合语音文本主题分类结果,可以对识别的音频场景进行校正。在文本分类领域中,双向长短期记忆网络(BiLSTM)算法较为经典且准确度较高,本文采用BiLSTM+Attention对语音文本进行主题分类。BiLSTM由前向LSTM与后向LSTM组成,可以更好地捕捉双向的语义依赖,非常适合用于对文本数据的建模。Attention机制[24]是模仿人类注意力而提出的一种解决问题的办法,简单地说就是从大量信息中快速筛选出高价值信息,主要用于解决BILSTM模型输入序列较长时很难获得合理向量表示的问题。Attention的机制是保留BILSTM的中间结果,用新的模型对其进行学习,并将其与输出进行关联,从而达到信息筛选的目的。
在进行模型训练前,需要进行文本数据增强,以识别更多特征。Easy Data Augmentation(EDA)是一种简单但有效的文本数据增强方法[25], 能提高文本分类任务的性能。EDA方法有4种数据增强操作,包括同义词替换、随机插入、随机交换、随机删除。EDA方法的优点在于:生成增强数据时会引入一定程度的噪声,有助于防止模型过拟合;可以通过同义词替换和随机插入操作引入新的词汇,增强模型的泛化性。
基于BiLSTM的语音文本主题分类模型训练的具体步骤如下。
(1)语音转写及文本预处理:对语音音频训练集Strain进行文本转换并进行预处理,包括分词与去除语气词。
(2)文本数据增强:采用EDA方法进行训练集文本增强。
(3)特征词生成唯一编码:根据统计得到的特征词,生成唯一的编码。
(4)将文本转化成编码序列:将特征词编码转化成相同长度的序列,并将序列左侧补齐,得到语音文本训练集Sttrain。
(5)训练集Sttrain 随机化:打乱语音文本训练集Sttrain数据的顺序,让数据随机化,避免模型过拟合。
(6)训练模型:将Sttrain中数据转化为词向量,构建BiLSTM网络结构,并训练模型,通过Softmax激活函数将输出转换为概率分布。
将1.1小节中分割得到的语音音频集S通过音频转写方法转换为语音文本数据集,通过上述方法进行训练,得到语音主题分类预训练模型。此模型可以识别一段语音文本可能所在的语音主题场景及其概率。输入语音音频集S,得到每段短音频si的语音主题场景sti及其概率pi,统计sti得到A的语音主题场景集STA={sti|i=0,1,…}及其概率PAst={pi|i=0,1,…}。
1.4 音频场景协同判断
信息熵是信息的期望值,用于描述信息的不确定度[26],如公式1所示。集合信息的熵越大,混乱程度就越高,其包含的信息价值就越少。信息熵被广泛地用于信息的量化度量。信息增益是对信息前后变化量的描述,当集合信息的熵减小时,其包含的信息就更有序,价值更高;反之则信息变得更混沌,信息价值降低。
公式(1)中, p 代表概率,这里 “X” 表示进行信息熵计算的集合。在音频场景识别领域中,可以按各个场景类别的占比(占比越高,该类别纯度越高)来理解公式(1),其中 N 表示场景类别的数目,而 pk表示类别 k在子集中的占比。
语音文本与环境声中都蕴含场景信息,环境声可以获得所在场景的音频特征信息,而语音可以获取额外的实体信息、属性信息、关系信息等。由于城市声音的复杂性与多样性,其包含的语音地理信息十分繁杂。通过信息熵可以衡量语音与环境声音中场景信息的价值,协同2个模态(文本、声音)的信息进行音频场景的判别。
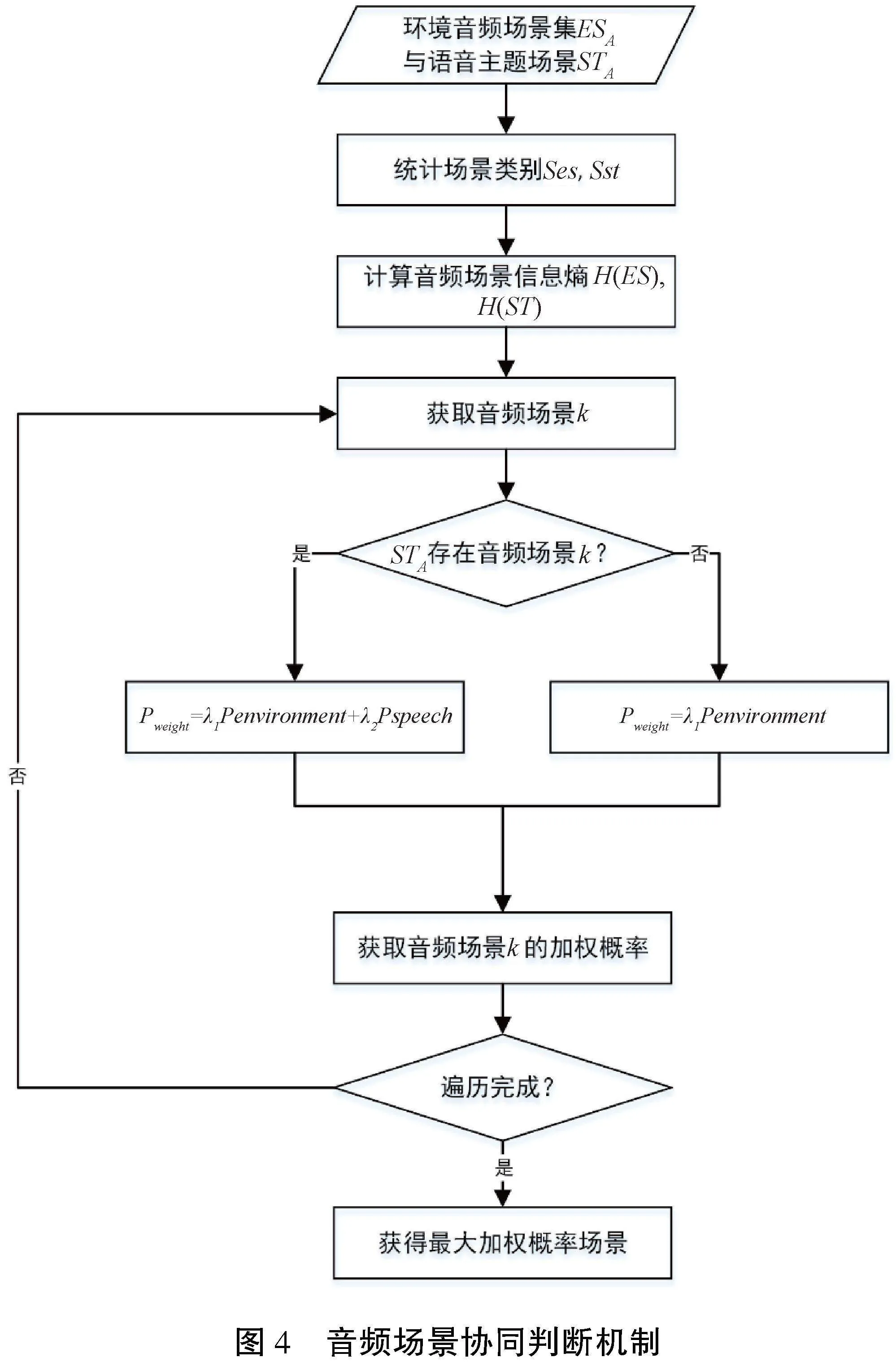
本文提出的基于信息熵的音频地理场景协同判断机制流程如下,具体如图4所示。
(1)输入环境音频场景集合ESA={esj|j=0,1,…}、语音主题场景集合STA={sti|i=0,1,…},统计ESA、STA的场景类别,得到环境音频场景类别集合Ses={sa|a=0,1,…}、语音主题场景集合Sst={sb|b=0,1,…}。
(2)根据公式(2)分别计算环境音频场景信息熵H(ES)、语音主题场景信息熵H(ST),公式(3)计算场景k的总概率。
其中,N表示X集合中出现的场景类别的数目,nk表示场景k在X集合中出现的次数,nsum表示在X集合中所有场景的音频段数目,pk表示短音频ej的场景k概率。
(3)根据公式(4)—(6)计算Ses中所有场景的加权概率Pweight,Pweight最大的场景即为音频A的场景。
其中,Penvironment表示场景在环境声中的总概率,Pspeech表示场景在语音中的总概率,当Ses中场景类别不存在Sst时,Pspeech=0。
2 实验
2.1 实验数据
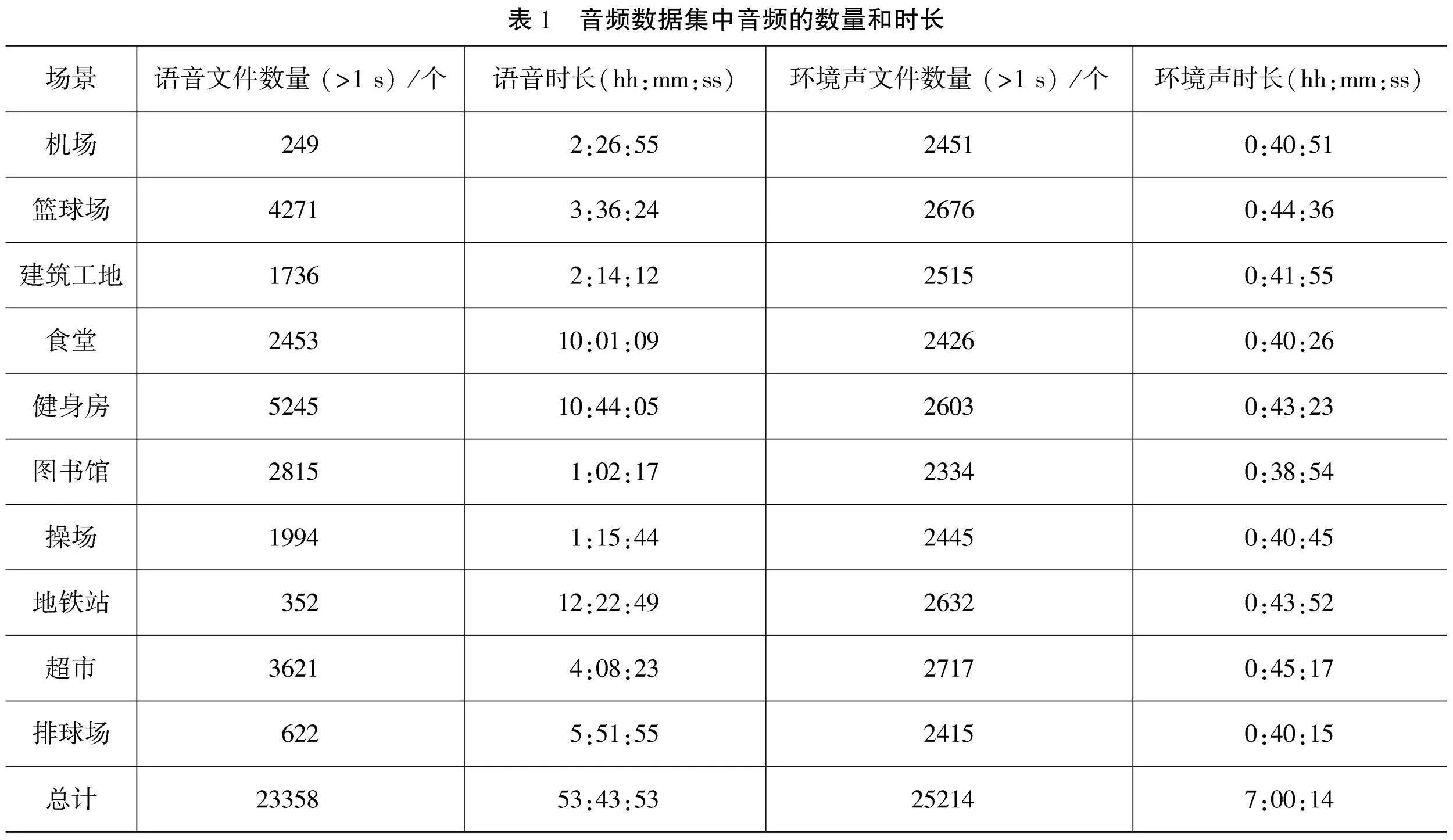
实验数据采集区域位于南京市机场、地铁、超市、体育馆、图书馆等人流密集区域。对于采集的音频数据,需进行语音与环境声音分割以训练语音主题分类与环境音频场景分类模型。在实验区内,共采集了将近100 h的音频,包含10个场景类别的语音与环境声音。经过音频分割处理,去除了部分无意义的音频,最后进行预训练的音频数据集如表1所示。这些数据通过索尼(SNOY)数码录音棒ICD-TX650采集,原始音频格式为WAV。训练开始前,将音频数据集以4∶1∶1 的比例随机划分为训练集、验证集和测试集。
2.2 实验结果
将环境音频场景识别的结果、语音主题场景识别结果、协同判断的场景结果与真实场景结果与人工识别结果进行对比,以验证方法的有效性。进行场景识别的专家经过高等教育且长期生活在南京市,对于音频场景的辨别能力较强。
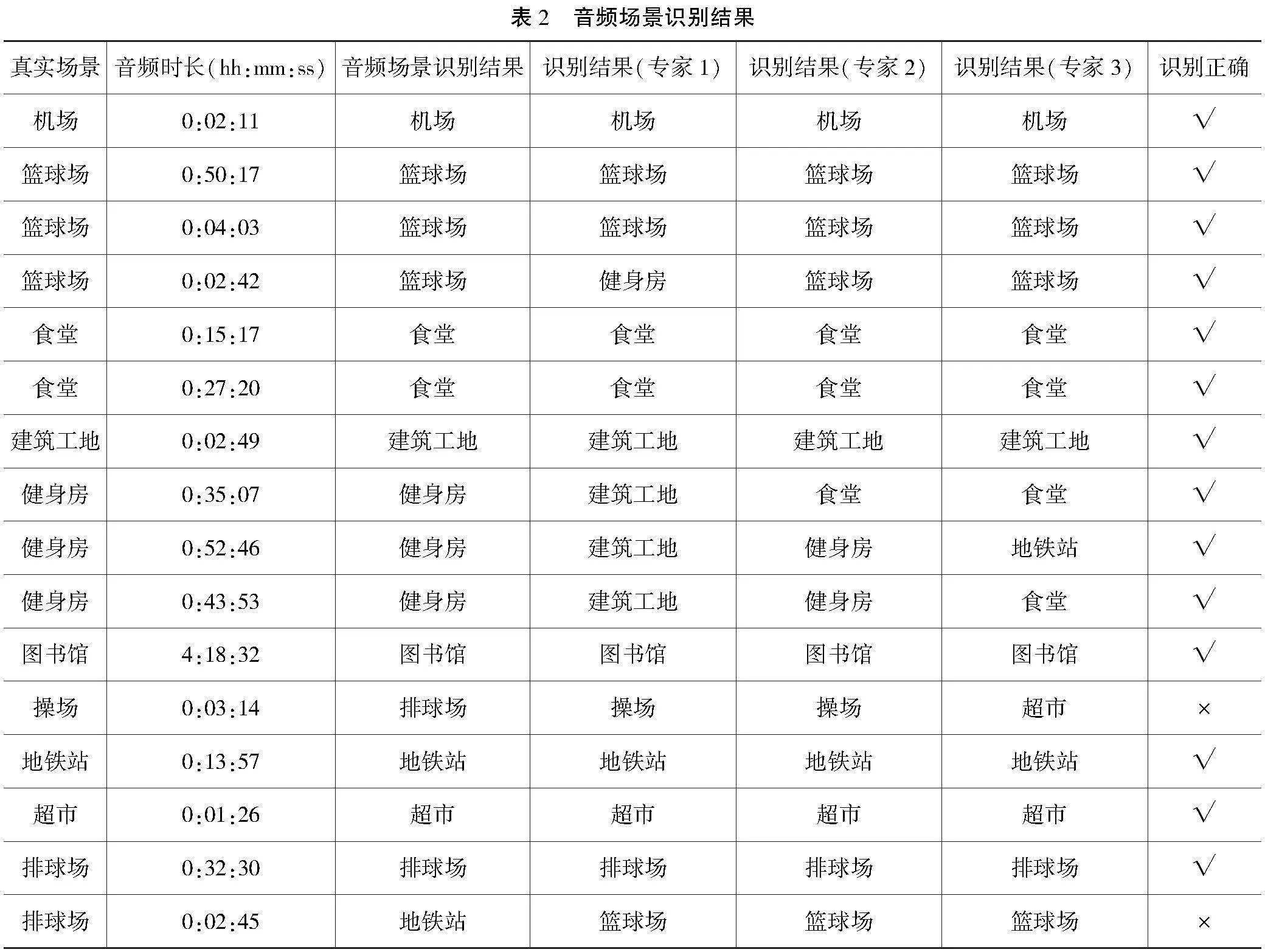
本文方法识别的结果如表2所示。与真实场景对比可知,在此实验中有14个地理场景被正确识别, 总体准确率为87.5%。从识别结果可以看出,机场、食堂、超市等语音特征明显的场景识别准确率较高,而篮球场、排球场等区分度较低的场景识别正确率较低。
2.3 实验结果分析
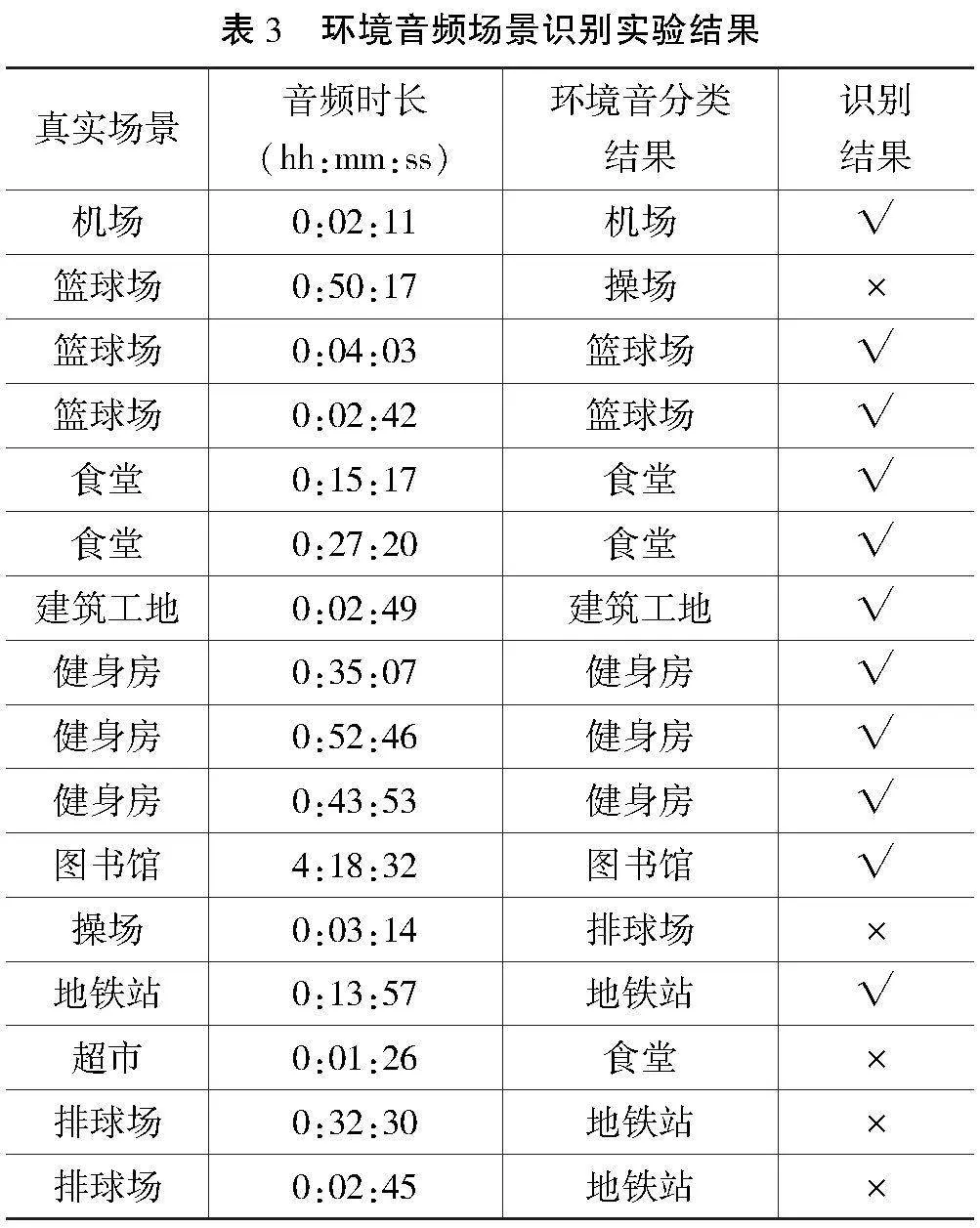
本文通过消融实验验证融合语义信息的城市音频场景识别方法的有效性。去除语音数据输入及BiLSTM语音分类模块,直接通过CNN环境音频场景识别模型进行音频场景分类,测试结果如表3所示。
由表3可知,与融合语义信息的城市声场景识别方法相比,直接使用环境音频特征的场景识别方法的准确率降低。由此可知,使用语义信息能提升城市音频场景的识别准确率,在本实验数据集上有18.75%的提升。
3 结语
本文针对音频场景识别领域中城市场景难以区分的问题,提出了一种融合语义信息的城市音频场景识别方法。该方法通过补充场景语义信息,并利用信息熵权重来计算场景的概率,综合考虑语音与环境声音中的场景信息,从而提升音频场景识别的精度。实验证明,本文提出的方法对于篮球场、超市等音频场景识别结果有较为明显的改进。本文的方法同样可以推广到其他易混淆音频场景,提升音频场景识别结果的正确率。
参考文献
[1]CHANDRAKALA S,JAYALAKSHMI S L.Environmental audio scene and sound event recognition for autonomous surveillance:a survey and comparative studies[J].ACM Computing Surveys(CSUR),2019(3):1-34.
[2]CROCCO M,CRISTANI M,TRUCCO A,et al.Audio surveillance:a systematic review[J].ACM Computing Surveys(CSUR),2016(4):1-46.
[3]李权.面向安全监控的异常声音识别的研究[D].长沙:湖南师范大学,2015.
[4]余卓渊,闾国年,张夕宁,等.全息高精度导航地图:概念及理论模型[J].地球信息科学学报,2020(4):760-771.
[5]RABAOUI A,LACHIRI Z,ELLOUZE N.Using HMM-based classifier adapted to background noises with improved sounds features for audio surveillance application[J].International Journal of Computer and Information Engineering,2009(11):2609-2618.
[6]MESAROS A,HEITTOLA T,VIRTANEN T.TUT database for acoustic scene classification and sound event detection:2016 24th European Signal Processing Conference(EUSIPCO),29 Aug.-2 Sept.,2016[C].New York:IEEE,2016.
[7]MESAROS A,HEITTOLA T,DIMENT A,et al.DCASE 2017 challenge setup:tasks,datasets and baseline system:DCASE 2017-Workshop on Detection and Classification of Acoustic Scenes and Events,2017,November 16,2017[C].New York:IEEE,2017.
[8]DHANAKALASHMI P,PALANIVEL S,RAMALINGAM V.Classification of audio signals using AANN and GMM[J].Applied Soft Computing,2011(1):716-723.
[9]RAKOTOMAMONJY A,GASSO G.Histogram of gradients of time-frequency representations for audio scene classification[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2014(1):142-153.
[10]HAMID E Z,BERNHARD L,MATTHIAS D,et al.A hybrid approach with multi-channel i-vectors and convolutional neural networks for acoustic scene classification:2017 25th European Signal Processing Conference(EUSIPCO),28 Aug.-2 Sept.,2017[C].New York:IEEE,2017.
[11]PETETIN Y,LAROCHE C,MAYOUE A.Deep neural networks for audio scene recognition:2015 23rd European Signal Processing Conference(EUSIPCO),31 Aug.-4 Sept.,2015[C].New York:IEEE,2015.
[12]CHIT K M,LIN K Z.Audio-based action scene classification using HMM-SVM algorithm[J].International Journal of Advanced Research in Computer Engineering & Technology,2013(4):226865838.
[13]ZIEGER C,OMOLOGO M.Acoustic event classification using a distributed microphone network with a GMM/SVM combined algorithm:INTERSPEECH 2008-9th Annual Conference of the International Speech Communication Association,September 22-26,2008[C].New York:EI,2008.
[14]NTALAMPIRAS S,POTAMITIS I,FAKOTAKIS N.Probabilistic novelty detection for acoustic surveillance under real-world conditions[J].IEEE Transactions on Multimedia,2011(4):713-719.
[15]CHACHADA S,KUO C J.Environmental sound recognition:a survey[J].APSIPA Transactions on Signal and Information Processing,2014(3):1-9.
[16]COWLING M,SITTE R.Comparison of techniques for environmental sound recognition[J].Pattern Recognition Letters,2003(15):2895-2907.
[17]YANG X,TAN B,DING J,et al.Comparative study on voice activity detection algorithm:2010 International Conference on Electrical and Control Engineering,June 25-27,2010[C].New York:IEEE,2010.
[18]HAN Y,LEE K.Convolutional neural network with multiple-width frequency-delta data augmentation for acoustic scene classification:IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events[C].New York:IEEE,2016.
[19]PHAN H,KOCH P,HERTEL L,et al.CNN-LTE:a class of 1-X pooling convolutional neural networks on label tree embeddings for audio scene classification:2017 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),June 16,2017 [C].New York:IEEE,2017.
[20]DONG X,YIN B,CONG Y,et al.Environment sound event classification with a two-stream convolutional neural network[J].IEEE Access,2020(8)8:125714-125721.
[21]MUSHTAQ Z,SU S.Environmental sound classification using a regularized deep convolutional neural network with data augmentation[J].Applied Acoustics,2020,167:107389.
[22]SHARMA J,GRANMO O,GOODWIN M.Environment Sound Classification Using Multiple Feature Channels and Attention Based Deep Convolutional Neural Network:INTERSPEECH,October 25-30,2020[C].New York:IEEE,2020.
[23]SU Y,ZHANG K,WANG J,et al.Environment sound classification using a two-stream CNN based on decision-level fusion[J].Sensors,2019(7):1733.1-1733.15.
[24]VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[EB/OL].(2023-08-02)[2024-05-23].https://arxiv.org/pdf/1706.03 762.pdf.
[25]WEI J,ZOU K.EDA:easy data augmentation techniques for boosting performance on text classification tasks[EB/OL].(2019-01-31)[2024-05-23].https://arxiv.org/pdf/1901.11196v1.
[26]SHANNON C E.A mathematical theory of communication[J].The Bell System Technical Journal,1948(3):379-423.
Urban audio scene recognition method integrating semantic information
Abstract: In response to the problem of urban scenes being easily confused and difficult to distinguish in the field of audio scene recognition, this paper proposes a city audio scene recognition method that integrates semantic information. The algorithm first segments speech and environmental sounds through voice activity detection, then identifies the scene types for both speech and environmental sounds separately, and finally calculates the scene probabilities of both by weighted information entropy to obtain the audio scene type that integrates semantic information. This method effectively solves the problem of poor classification results for easily confused and low discrimination audio scenes in traditional environmental audio scene recognition methods. Experiments show that the proposed method has a significant improvement effect on the recognition of easily confused urban audio scenes such as basketball courts and supermarkets, and the recognition results also prove the importance of semantic information for city audio scene recognition.
Key words: audio scene recognition; semantic information; CNN; BiLSTM; information entropy; information fusion
