
基于计算机视觉的图书识别系统
2024-09-23 00:00:00刘春彦张致铭赵孝芬
无线互联科技 2024年17期
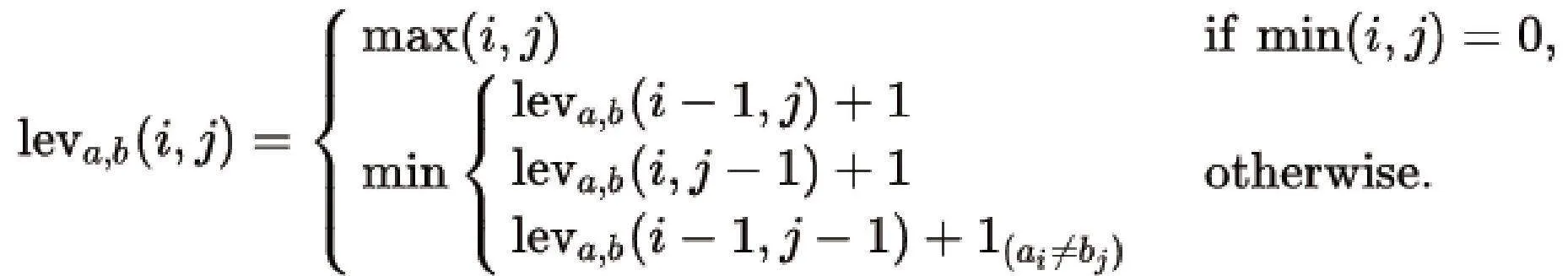

摘要:随着社会的发展,由图书馆中图书流动性增加带来的书籍整理与归档难题日益显著。针对这一问题,文章提出了一种智能化系统,利用计算机视觉技术对图书进行识别,通过与图书馆数据库进行数据匹配,以精确定位每本图书的具体位置。具体操作流程包括:通过图书馆内摄像头进行图像采集和预处理,进行书脊检测,提取出每本书籍的索书号区域,并利用OpenCV库对索书号区域内的字符进行识别,最终实现对图书位置的精确定位。
关键词:智能化系统;计算机视觉技术;OpenCV库;图书馆数字化转型
中图分类号:G251 文献标志码:A
0 引言
随着人们对知识的需求不断增加,图书馆的访客量也随之上升。这一现象却带来了另一个问题——图书整理困难。由于大量图书被借阅和归还,图书馆内的书籍常常被翻乱,书架上的书籍也难以保持整齐有序[1]。这给图书馆工作人员带来了巨大的压力,须要花费更多的时间和精力来整理书籍,以确保图书馆内图书排列井然有序。
随着图书种类的增加,分类和归档的工作也变得更加复杂。图书馆工作人员须要对每一本图书进行仔细的检查,确保它们被放置在正确的位置。由于人力资源有限,这一工作往往难以做到尽善尽美。
随着数字化时代的到来,图书馆的数字化转型成为提升服务质量和效率的重要途径。传统的图书馆管理方式已经难以满足现代社会对信息获取速度和准确性的需求。因此,利用现代信息技术,特别是计算机视觉技术,来改进图书馆的服务和管理,已经成为一个迫切要研究的课题。
为了解决这个问题,许多学者提出了不同的解决方案。比如王海燕[2]提出图书馆要在治理转换的阶段中积极创新,实现管理转型。杨颜僖[3]提出当前信息科技发展迅猛,公共图书馆在管理与服务方面也应不断创新。秦燕等[4]提出基于深度学习识别图书封面。李小燕[5]从机器视觉方向设计了一个基于卷积神经网络的图书识别系统。
本文在以上研究的基础上,通过书库中的摄像获取书架图片,然后对图片进行预处理,再对图片进行书脊检测,提取出索书号,将索书号进行分割及识别后,与所需要的索书号进行对比,提示读者或者图书管理员所需图书的具体位置。本文通过自动化图书识别和定位技术,提高了图书馆的检索效率和管理智能化水平,优化了读者的体验,具有重要的实用价值和广阔的应用前景。
1 系统整体设计
1.1 系统设计
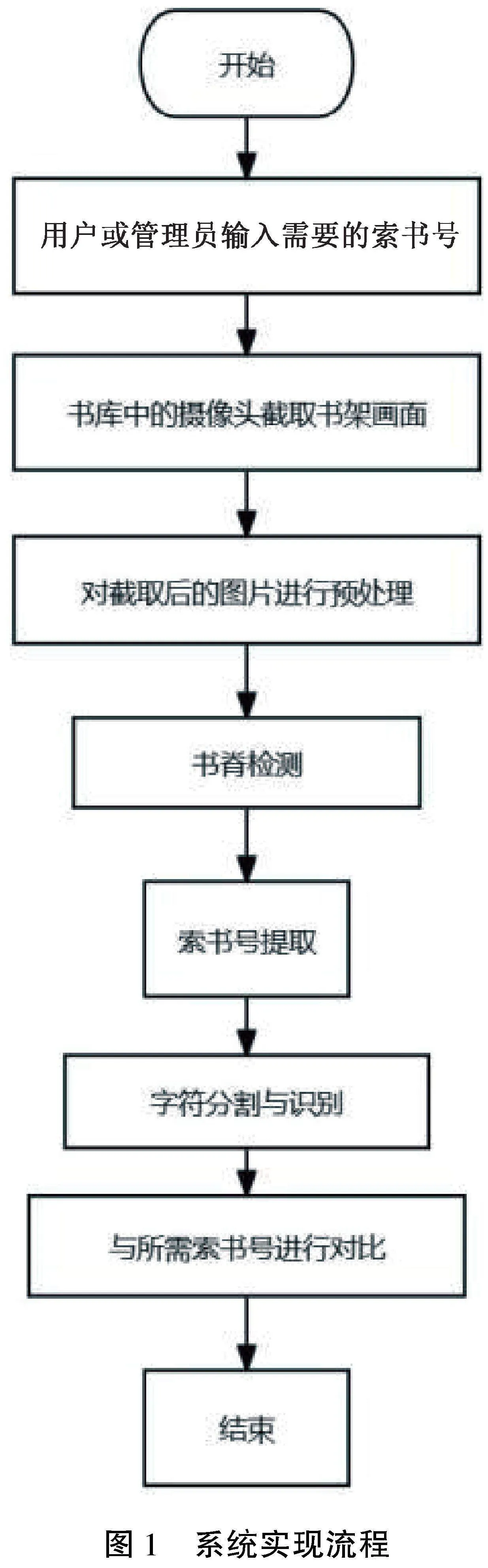
系统实现流程如图1所示,各流程详述如下。
(1)图像预处理。在输入图像进入神经网络之前,须要进行预处理,包括图像的缩放、裁剪、灰度化、去噪等操作,以便更好地识别图片细节。
(2)书脊检测。使用卷积神经网络(Convolutional Neural Network,CNN)或其他边缘检测方法来定位一张图片中书脊的位置。
(3)索书号提取。使用目标检测算法(如 Faster-RCNN)来提取索书号区域。
(4)字符分割与识别。用OpenCV库识别提取出来的索书号区域的字符。
(5)匹配字符。将识别出的字符和数据库中记录的字符进行对比,查找出该字符对应书籍的正确位置。
1.2 图像预处理
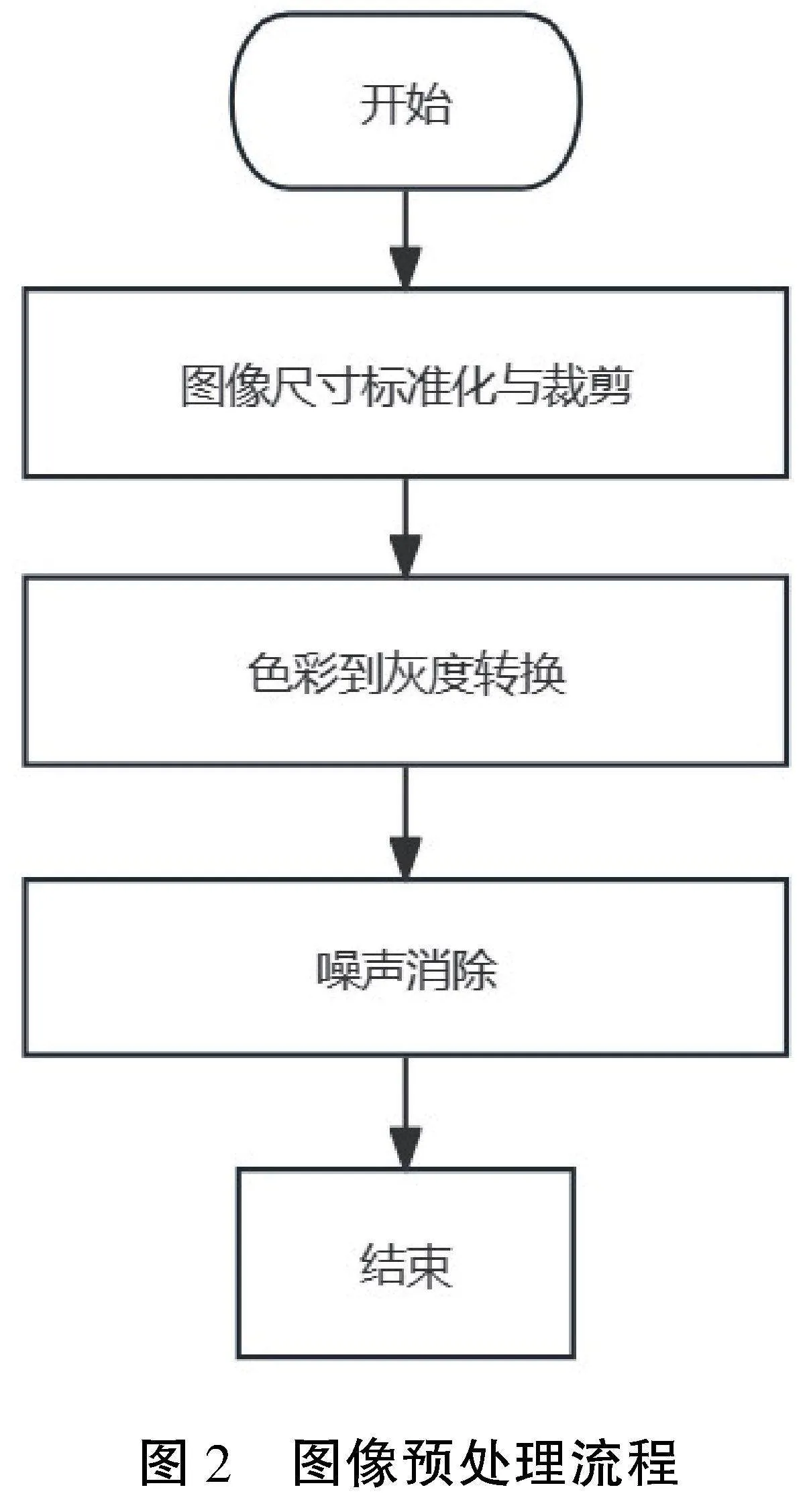
图像预处理是一个关键步骤,其目的在于提升图像品质并优化后续的图像识别与处理流程。本文的图像预处理包括以下几个主要步骤,具体如图2所示。
(1)图像尺寸标准化与裁剪。鉴于输入图像可能存在尺寸上的差异,本文采用尺寸归一化技术,将图像缩放至一致的规格,以适应深度学习神经网络的输入要求。同时,为了排除背景噪声对研究对象的干扰,还实施了图像裁剪操作,仅保留图像中关键的研究区域。
(2)色彩到灰度转换。为了降低图像处理的计算复杂性,同时保持对图像纹理特征的敏感性,采用了灰度化处理,将彩色图像转换为灰度图像。
GRAY=B×0.114+G×0.587+R×0.299
(3)噪声消除。在图像的采集与传输过程中,噪声的产生是难以避免的。为了降低噪声对图像分析的影响,采用了中值滤波技术[6]。
以上步骤确保了图像在进入机器学习模型之前具有良好的质量和处理一致性,对于提升模型的准确性和鲁棒性具有重要意义。
1.3 书脊检测
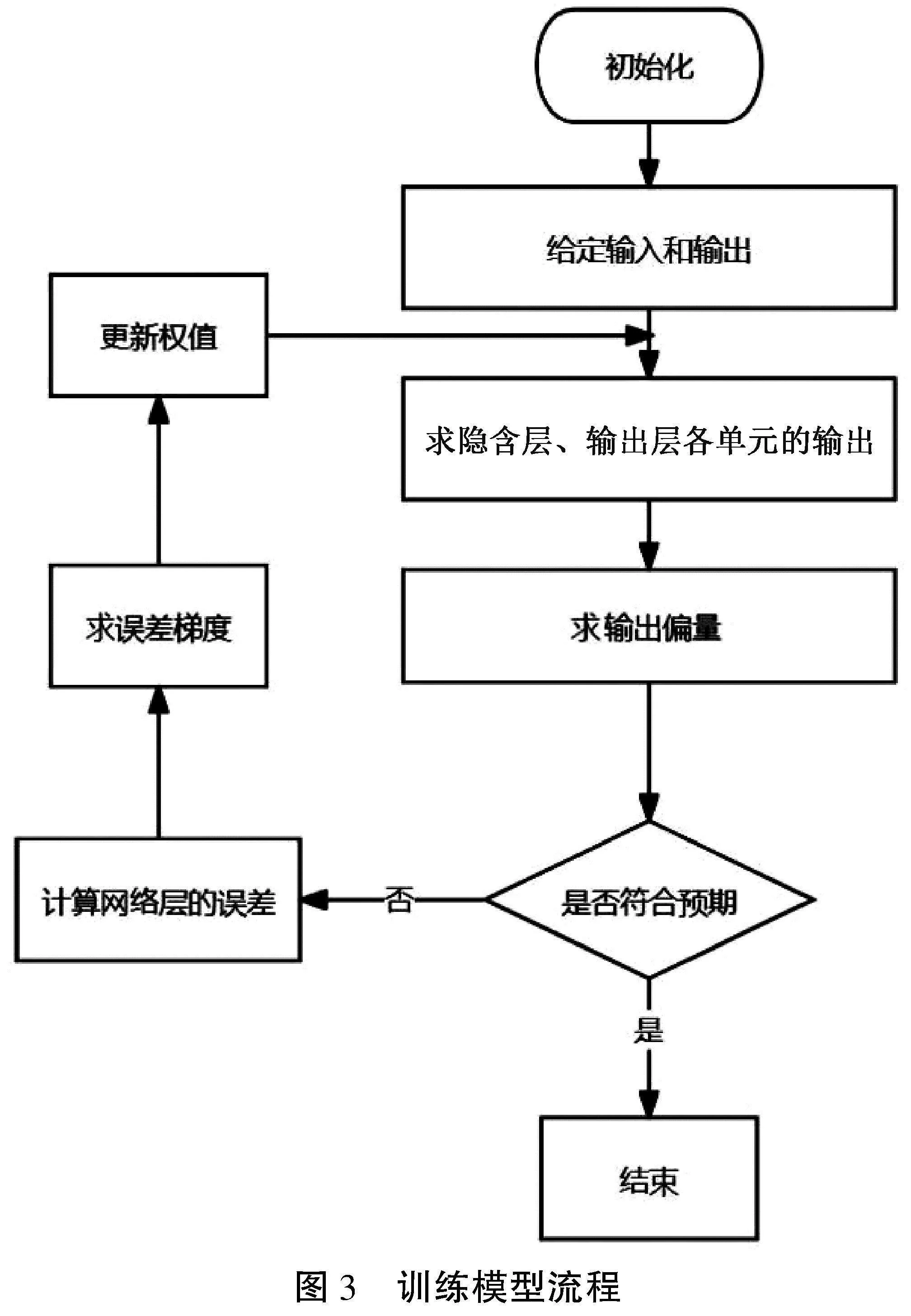
本文使用了一种基于深度学习的图书脊检测算法,该算法能够从复杂场景的图像中精确地定位书脊的位置。为了实现这一目标,本文采用了CNN[7]。这是一种在图像识别和处理任务中表现卓越的深度学习模型,如图3所示。
为了训练CNN模型,本文构建了一个大规模的带有书脊标注的图像数据集。这个数据集包含多种场景、光照条件下的书籍图片,确保模型能够学习到书脊的多样性和复杂性。在训练过程中,本文采用了迁移学习策略,应用在大型图像数据集上预训练的模型作为起点,以增强模型对书脊特征的学习能力。
为了提高检测的准确性和鲁棒性,本文还引入了以下几种算法和技术。
(1)特征融合。本文结合了多种特征提取方法,如边缘检测、纹理分析和形状上下文,以获得更丰富的书脊特征表示。
(2)多尺度检测。通过在不同尺度上应用CNN,提高了模型对不同尺寸和比例的书脊的检测能力。
(3)上下文信息利用。在检测过程中考虑了书脊周围的上下文信息,以帮助区分书脊与其他类似结构。
(4)损失函数优化。本文采用了改进的损失函数,如焦点损失(Focal Loss),以解决类别不平衡问题,提高模型对少数类别的学习能力。
(5)数据增强。通过旋转、缩放、裁剪等多种数据增强技术,极大地提高了训练数据的多样性,增强了模型的泛化能力。
(6)注意力机制。引入了注意力机制,使模型能够聚焦于图像中与书脊相关的关键区域,从而提高检测的准确率。
1.4 索书号提取
本文专注于图书识别领域的一个重要环节:索书号的自动提取。索书号不仅是图书的唯一标识,而且是实现图书识别和管理的核心。为了精确地从图像中提取索书号区域,采用了先进的目标检测算法,如Faster R-CNN,该算法在对象识别和边界框定位方面具有较高的准确性和效率。
为了训练目标检测模型,本文构建了一个大规模的带有索书号标注的图像数据集。这个数据集包含多种场景、不同字体风格、大小和排列方式的索书号,确保了模型能够学习到索书号的多样性和复杂性。在训练过程中,模型通过学习这些标注索书号图像的特征,能够从实际图像中准确地定位和提取出索书号区域。
为了进一步提高模型性能,本文采用了以下几种技术和策略。
(1)深度特征融合。结合了卷积神经网络的不同层次的深度特征,以获得更丰富的索书号特征表示,增强了模型对索书号的识别能力。
(2)区域提议网络(Region Proposal Network,RPN)。在Faster R-CNN的基础上,利用区域提议网络来生成更准确的候选索书号区域,提高了目标检测的准确性和效率。
(3)损失函数创新。采用了平衡损失函数,如焦点损失(Focal Loss),以解决类别不平衡问题,提高模型对少数类别的学习能力。
(4)数据增强和预处理。通过旋转、缩放、裁剪等多项数据增强技术和图像质量提升预处理技术,显著提升了训练数据的多样性,最终增强了模型的泛化能力。
(5)多尺度训练和检测。在训练和检测过程中考虑了不同尺度,确保模型能够适应不同尺寸的索书号。
通过这些技术和策略的综合运用,目标检测模型在图书索书号提取任务上表现出色,能够高精度地从各种图像中定位并提取出索书号区域,为实现自动化的图书识别和管理提供了强有力的技术支持。
1.5 字符分割与识别
在图书识别系统中,准确提取索书号后,紧接着的任务是对索书号中的字符进行精确的分割和识别[8]。这一步骤对于确保图书信息能够被正确索引和检索至关重要。本文采用了一系列先进的图像处理和深度学习技术来实现这一目标,如图4所示。
首先利用OpenCV库中的图像处理功能对提取的索书号区域进行字符分割。这一步骤通过图像分割算法实现,旨在将连续的索书号文本区域分解为独立的字符图像。这一过程涉及图像轮廓检测、区域生长等算法,以确保每个字符都能被准确地分割出来。
为了对分割后的字符进行识别,采用了一个预训练的深度学习模型,专门设计用于字符识别任务。该模型基于CNN架构,已经在大量字符数据上进行了训练,能够识别包括字母、数字以及其他特殊字符在内的多种字符。
在字符识别阶段,将分割后的单个字符图像作为输入,通过预训练的模型进行识别。模型会输出每个字符的概率分布,据此选择概率最高的字符作为最终的识别结果。为了提高识别的准确率,还在模型训练过程中采用了数据增强技术,如字符旋转、缩放等,以增强模型的泛化能力。
通过这一系列技术的应用,该系统能够实现图书索书号中字符的高精度分割和识别,为图书馆自动化管理、在线图书检索系统等提供了强有力的技术支持。此外,该系统还可以扩展应用于其他需要字符分割和识别的场合,如文本编辑、自动抄写等。
1.6 匹配字符
最后阶段,采用了字符匹配技术确保识别出的字符能够准确地对应到数据库中的记录。鉴于识别过程中可能存在的误差,选择了模糊匹配算法,以提高匹配过程的容错性和准确性。
在字符匹配阶段,将识别出的字符序列与数据库中存储的正确字符序列进行对比。为了计算2个字符串的相似度,采用了Levenshtein距离[9],这是一种衡量字符串之间差异的度量方法。Levenshtein距离考虑了字符替换、插入和删除操作,能够准确地反映2个字符串之间的编辑距离,算法公式如下:
在匹配过程中,设定了一个阈值,以确定何种程度的不匹配是可以接受的。模糊匹配算法能够容忍一定程度的不匹配,从而提高了匹配的准确性。这意味着即使识别出的字符序列与数据库中的字符序列存在一定的差异,只要这些差异在阈值范围内,算法仍然能够判断它们为匹配。
通过这一系列的匹配过程,该系统能够有效地找出识别出的字符在数据库中的正确位置,从而实现图书的准确识别和检索。这种模糊匹配算法在处理计算机视觉任务中的字符识别和匹配问题时显示出独特的优势,尤其是在处理噪声和错误容忍的场景中。
2 结语
本文成功开发了一套基于深度学习的图书识别系统,能够自动从图像中提取索书号,对索书号中的字符进行精确的分割和识别。通过采用先进的图像处理技术和深度学习模型,该系统在字符分割和识别方面取得了较高的准确率和效率。
此外,还引入了模糊匹配算法,以处理识别过程中可能出现的误差。通过计算字符串之间的Levenshtein距离并设定合适的阈值,该系统能够容忍一定程度的不匹配,从而提高匹配的准确性。
实际应用表明,该图书识别系统在图书馆自动化管理、在线图书检索等领域具有广泛的应用前景。未来将继续优化模型性能,提高系统的准确率和鲁棒性,使其更好地服务于图书管理和识别领域。
尽管本文的研究已经取得了显著的成果,但仍然存在一些可以改进的地方。
(1)数据集的多样性和规模。为了进一步提高模型的泛化能力,可以收集更多不同场景、光照条件、字体风格和大小不同的图书图像,以扩充数据集的规模和多样性。
(2)模型解释性。虽然深度学习模型在图书识别任务上表现出色,但其内部决策过程缺乏解释性。可以尝试使用一些可解释性技术,如注意力机制或集成解释性方法,来揭示模型的决策依据。
(3)实时性能优化。在实际应用中,图书识别系统需要快速响应用户的操作。为了提高系统的实时性能,可以对模型进行进一步优化,如模型压缩和量化,以减少模型的计算复杂度和存储需求。
(4)多语言支持。系统主要针对特定语言的索书号进行识别。为了使其更具通用性,可以考虑支持多语言的索书号识别,这涉及对模型进行多语言训练 或引入外部语言资源。
(5)跨领域应用。除了图书识别之外,字符分割和识别技术还可以应用于其他领域,如文本编辑、自动抄写等。可以探索其他应用场景,并将该技术推广到更广泛的领域。
(6)对抗性样本处理。在实际应用中,攻击者可能会尝试使用对抗性样本来欺骗识别系统。为了提高系统的鲁棒性,可以研究对抗性样本的检测和处理方法,以防止系统被恶意攻击。
总之,本文的研究在图书识别领域取得了一定的成果,为自动化图书管理提供了有力的技术支持。随着人工智能技术的不断进步,未来的图书识别系统将更加智能化、高效化,为人们的阅读和学习带来更多的便利。
参考文献
[1]李昊,杨燕勤.基于B/S结构的高校图书馆管理系统的开发与应用[J].现代情报,2010(1):154-158.
[2]王海艳.从管理到治理图书馆改革在路上[J].文化产业,2024(7):58-60.
[3]杨颜僖.公共图书馆管理与服务创新路径探究[J].参花,2024(7):140-142.
[4]秦燕,连玮.一种基于深度学习的图书封面文字自动检测识别系统[J].长治学院学报,2023(2):56-60.
[5]李小燕.基于机器视觉的图书智能识别系统研究[J].自动化与仪器仪表,2022(5):122-126.
[6]刘光宇,曹禹,王帅,等.基于自适应中值滤波的图像去噪技术研究[J].安徽电子信息职业技术学院学报,2022(5):1-6.
[7]黄佳美,张伟彬,熊官送.基于深度卷积神经网络的汽车图像分类算法与加速研究[J].现代电子技术,2024(7):140-144.
[8]王帅,刘光宇,李俊松,等.基于模板匹配的车牌字符识别算法研究[J].武汉船舶职业技术学院学报,2024(1):97-102.
[9]崔竞松,薛慧,王兰兰,等.LEDA:一种基于Levenshtein距离的DNA序列拼接算法[J].武汉大学学报(理学版),2022(3):271-278.
Computer vision-based book recognition system
Abstract: With the development of society, the problem of book sorting and archiving is becoming more and more obvious due to the increasing mobility of library books. In order to solve this problem, an intelligent system was proposed to use computer vision technology to identify books and match the data with the library database to accurately locate the specific location of each book. The specific operation process includes: image acquisition and preprocessing are carried out by cameras in the library, spine detection, extraction of the call number area of each book, and the use of OpenCV library to identify the characters in the call number area, and finally realize the accurate determination of the location of the book.
Key words: intelligent systems; computer vision technology; OpenCV library; digital transformation of libraries
