
基于YOLOv8的安全帽佩戴检测研究
2024-09-23 00:00:00郑英子魏东川王蓓曾景兴
无线互联科技 2024年17期

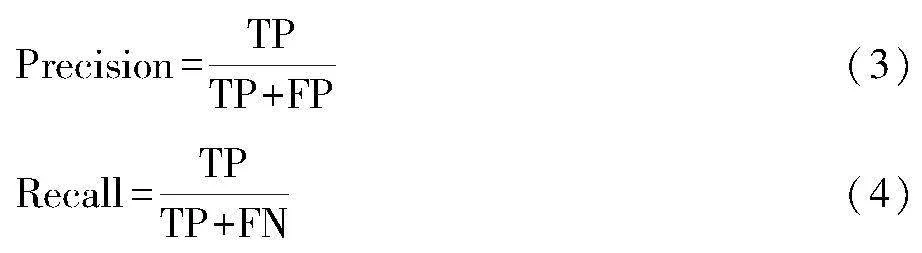
摘要:随着安全生产意识的增强,工地安全监管日益受到重视,检测作业人员是否佩戴安全帽成为保障工地安全的一项重要措施。然而,安全帽的检测也存在不小的挑战,如存在目标尺寸变化、复杂背景干扰等因素。为此,文章提出了一种基于YOLOv8的安全帽佩戴检测方法,通过引入膨胀卷积以及卷积注意力机制,提升网络的特征提取能力,结合定位损失函数、置信度损失函数来进行参数的更新。实验数据显示,该方法的精度比原始的YOLOv8有一定的提升,可以准确地检测员工是否佩戴安全帽。
关键词:YOLOv8;特征提取;神经网络;安全帽检测
中图分类号:TP391.4 文献标志码:A
0 引言
安全生产不仅关系到从业者个人的健康和生命安全,也关系到企业的可持续发展和社会的稳定。在众多安全防护措施中,佩戴安全帽是最基本也是最有效的一种手段。YOLO(You Only Look Once)算法作为一种领先的实时目标检测算法[1],以其快速精准的特点备受关注。YOLOv8是最新的迭代版本,在速度和准确度上均有显著提升,为安全帽佩戴监测的实时性和准确性带来了新的可能。在目标检测的研究中,针对改进YOLOv8的算法主要包括以下几个方面:(1)加入反卷积层、归一化层和拼接层等,以设计出全新的网络架构,提升模型细节捕捉和特征整合的能力[2];(2)利用GCBlock结构,处理和建模更长距离的依赖关系,在YOLOv8的主干网络中使用GCBlock结构来增强模型的特征提取能力[3];(3)使用GSConv新型卷积方式去降低计算量,同时保持良好的特征表示[4];(4)采用SIOU损失函数,优化目标的定位,通过SIOU损失函数取代CIOU损失,解决其局限性并提升模型的检测性能[5];(5)重构特征提取和特征融合网络,降低模型计算量,引入可变形卷积(Deformable Convolution Network,DCN),增加模型的特征捕捉能力[6];(6)开发部署友好结构,通过引入新构建的Faster Block结构,用部分卷积取代原有的Bottleneck结构,并结合SE通道注意力层进一步提升检测准确率。
本文基于YOLOv8,在特征提取阶段引入膨胀卷积,扩大模型的感受野,捕获更广泛的上下文信息,而不增加网络的复杂度,并通过卷积注意力机制,强化模型对上下文信息中重要特征的关注度。本文通过对大量工地作业环境中的真实图像数据进行处理和分析,训练了一套深度学习模型,可以准确检测员工是否佩戴了安全帽。
1 特征提取模块
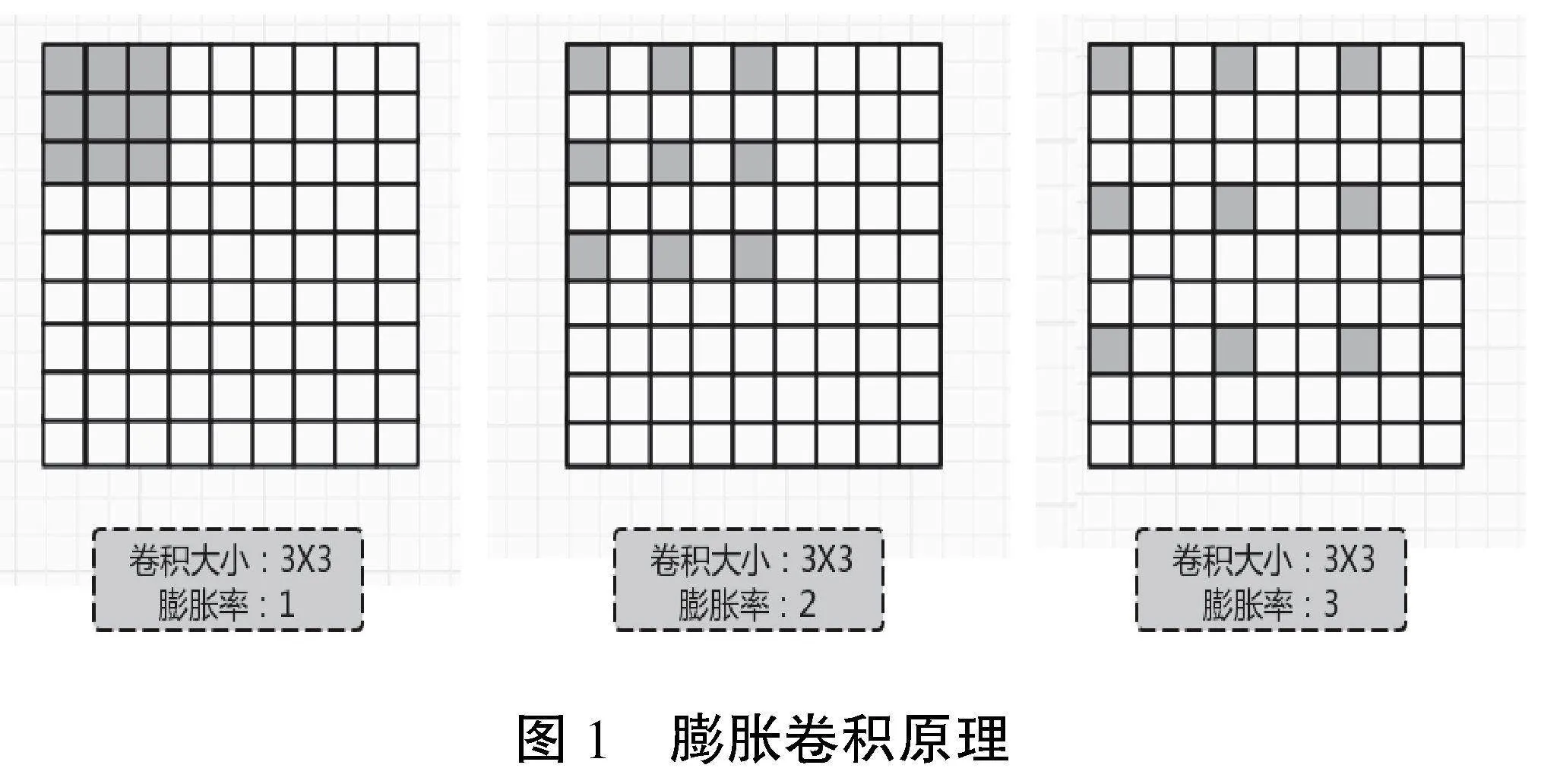
为了减少参数、扩大感受野,通常在提取特征图时,网络会添加池化层来进行图像的下采样。这种做法虽然能有效减少网络的参数并扩展感受野,但这也导致了特征图分辨率的降低,导致部分信息被丢失[7]。针对语义分割时池化导致的图像分辨率下降和信息丢失问题,本研究在卷积层中加入了“膨胀率”这一新参数。通过调整不同的膨胀率,可以控制卷积核在处理数据时的采样间隔,扩大感受野的同时,却没有增加参数量。膨胀卷积的原理如图1所示。
考虑到膨胀卷积在特征提取和参数效率上的优势,本文采用了多个不同膨胀率的膨胀卷积的组合,以模拟多种感受野的效果,实现对图像多尺度信息的捕捉。所使用的特征提取模块基于传统的3×3卷积核,并在此基础上堆叠了3种膨胀率为1、2、3的膨胀卷积核,以提取不同规模的安全帽特征。为了增强模型的性能及其对不同尺度目标的感知力,本文采取了将高层的语义信息与低层的细节信息结合的策略。
2 卷积注意力机制模块
卷积注意力机制包括通道以及空间2部分。卷积注意力机制通过给模型加上“注意力”层,使得模型能够关注输入图像中更加重要的区域[8]。
2.1 通道注意力模块
在通道注意力部分,每一个通道被视为图像的特征提取器,提取纹理、样式等各类特征。特征图在空间维度上通过最大池化和平均池化进行压缩,聚合特征映射的信息[9]。经过一个共享网络逐元素求和合并,再经过Sigmoid激活函数,得到通道注意力图,如图2所示。
(1)结合平均池化和最大池化2种池化方法对特征图进行空间汇集,生成2种通道注意力向量,分别用FCavg,表示FCmax。
(2)将这2个向量输入由一个隐藏层组成的共享MLP(Multi-Layer Perception)网络,并生成2个维数为C×1×1的注意力向量(MLP可以看成一个3层的全连接神经网络)。
(3)将上面得到的2种向量对应位置相加,通过一个Sigmoid函数,生成一个维数为C×1×1的通道注意力向量,命名为MC。
在多层感知器(MLP)中,考虑到计算成本从而减少参数量,把隐藏激活大小设置为C/r×1 ×1,可以理解为中间层的神经元节点减到了C/r个,其中r为减少率。等到输出层的时候再把神经元增加到C个,保证获得和特征图通道数相同的注意力向量维数。这样处理既可以获得全连接网络的非线性,又减少了全连接网络的参数个数[10]。
通道注意力机制的具体表达式如公式(1)所示
MC(F)=Sig(MLP(Avgpooling(F))+MLP (Maxpooling(F)))=Sig(W1(W0(FCavg))+W1 (W0(FCmax)))(1)
其中,Sig是Sigmoid函数,MLP是含有隐藏层的多层感知机,W1和W0分别是MLP的隐藏层权重及输出层权重,W1和W0参数是共享的,Avgpooling是平均池化,Maxpooling是最大池化。
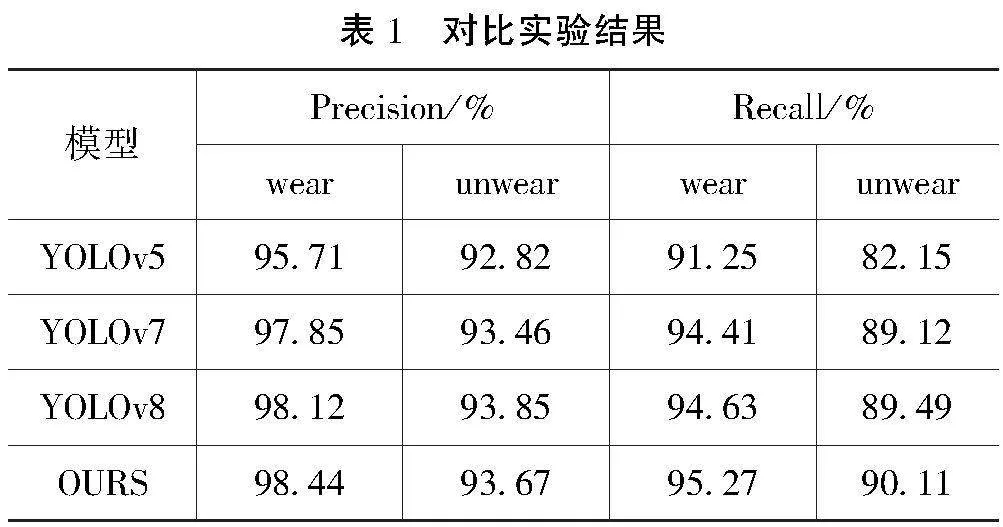
2.2 空间注意力模块
空间注意力机制的输入是由通道注意力部分处理过的数据,完成的工作是对通道进行压缩。将多通道的值压缩到单个通道,经过卷积得到空间的加权信息,如图3所示。
空间注意力模块着重于利用特征之间的空间位置关系来形成空间注意力图。这种空间关注与通道关注不同,它强调了特征在空间上的分布和区位重要性,旨在对通道注意力进行有效补充。通道注意力机制的具体表达式如公式(2)所示。
MS(F)=Sig(f7×7([Avgpooling(F);Maxpooling (F)]))=Sig(f7×7(FSavg;FSmax))(2)
其中,得到带有通道注意力权重的特征图后,采用2种池化方法(平均池化和最大池化),得到2个维数相同的特征图,分别命名为FSavg,FSmax,维数为1×H×W。把得到的FSavg、FSmax串行拼接在一起,得到一个特殊的特征图。利用一个7×7的卷积对这个特征图进行卷积,然后输入Sigmoid函数,得到一个特征图维数相同的加上空间注意力权重的空间矩阵。把得到的空间注意力矩阵对应相乘到原特征图上,得到的新的特征图命名为MS。
3 实验与结果分析
3.1 数据集
数据集选择的是Hard Hat Workers Dataset,这是一个公开的数据集,数据集中包含大约5000张图像,可以直接用于训练和测试安全帽检测模型,是最接近安全帽检测任务需求的数据集之一。模型进行训练时,随机选择80%作为训练集,20%作为测试集。
3.2 损失函数
定位损失(Localization Loss)用来评估模型预测的边界框与真实边界框之间的一致性,与模型如何精确地定位图像中物体的位置和大小直接相关。置信度损失(Confidence Loss)用于度量模型预测边界框中是否包含目标以及对包含目标的边界框置信度水平的准确性。对于负责检测物体的边界框,置信度损失将评价模型预测的置信度(通常是物体存在的概率)与实际存在物体的边界框之间的误差。对于不包含对象的边界框,模型也须要给出一个接近零的置信度,这时的置信度损失是用来惩罚那些错误地高估了对象存在概率的预测,以提高模型的总体准确度和鲁棒性。
3.3 评价指标
本文使用精度(Precision)、召回率(Recall)对模型性能进行评估,计算公式如下:
其中,TP检测正确,FP为检测错误,FN为漏检。
3.4 对比实验
将本文的模型与YOLOv5、YOLOv7、YOLOv8进行对比,结果如表1所示。由实验结果可知,本文的模型在精度和召回率上都有一定的提升。
4 结语
本文从提升网络特征提取能力的角度出发,通过引入膨胀卷积和卷积注意力机制,提高了检测模型的性能。膨胀卷积增加了感受野,使得模型能够捕捉更多的上下文信息,而不会丧失分辨率。同时,卷积注意力机制加强了模型专注于图像关键部分的能力,从而提高了其区分安全帽和非安全帽物体的能力。这些改进不仅提升了模型对安全帽检测的准确度,还加强了其在复杂场景中的鲁棒性。
参考文献
[1]田鹏,毛力.改进YOLOv8的道路交通标志目标检测算法[J].计算机工程与应用,2024(8):202-212.
[2]郭爱心.基于深度卷积特征融合的多尺度行人检测[D].合肥:中国科学技术大学,2018.
[3]罗会兰,陈鸿坤.基于深度学习的目标检测研究综述[J].电子学报,2020(6):1230-1239.
[4]鲍禹辰,徐增波,田丙强.基于YOLOv8改进的服装疵点检测算法[J].东华大学学报(自然科学版),2024(4):49-56.
[5]戚玲珑,高建瓴.基于改进YOLOv7的小目标检测[J].计算机工程,2023(1):41-48.
[6]汪昱东,郭继昌,王天保.一种改进的雾天图像行人和车辆检测算法[J].西安电子科技大学学报,2020(4):70-77.
[7]左静,巴玉林.基于多尺度融合的深度人群计数算法[J].激光与光g4Ucr+fVlKRhOko2m/2Wlw==电子学进展,2020(24):315-323.
[8]GU W C,SUN K X.AYOLOv5:Improved YOLOv5 based on attention mechanism for blood cell detection[J].Biomedical Signal Processing and Control,2024(Part C):105034.1-105034.8.
[9]朱张莉,饶元,吴渊,等.注意力机制在深度学习中的研究进展[J].中文信息学报,2019(6):1-11.
[10]蒋弘毅,王永娟,康锦煜.目标检测模型及其优化方法综述[J].自动化学报,2021(6):1232-1255.
Research on safety helmet wearing detection based on YOLOv8
Abstract: With the increasing awareness of safety production, construction site safety supervision is increasingly valued, and testing whether workers wear safety helmets has become an important measure to ensure the safety of construction sites. However, there are also significant challenges in the detection of safety helmets, such as changes in target size and complex background interference. This article proposes a safety helmet wearing detection method based on YOLOv8, which improves the network’s feature extraction ability by introducing dilated convolution and convolutional attention mechanism, and updates parameters by combining localization loss function and confidence loss function. The experimental data shows that the accuracy of this method has been improved compared to the original YOLOv8, and it can accurately detect whether employees are wearing safety helmets.
Key words: YOLOv8; feature extraction; neural network; helmet detection
