
基于数据增强的MRC水利领域命名实体识别模型研究
2024-09-23 00:00:00朱永明邢丹艳
人民黄河 2024年9期
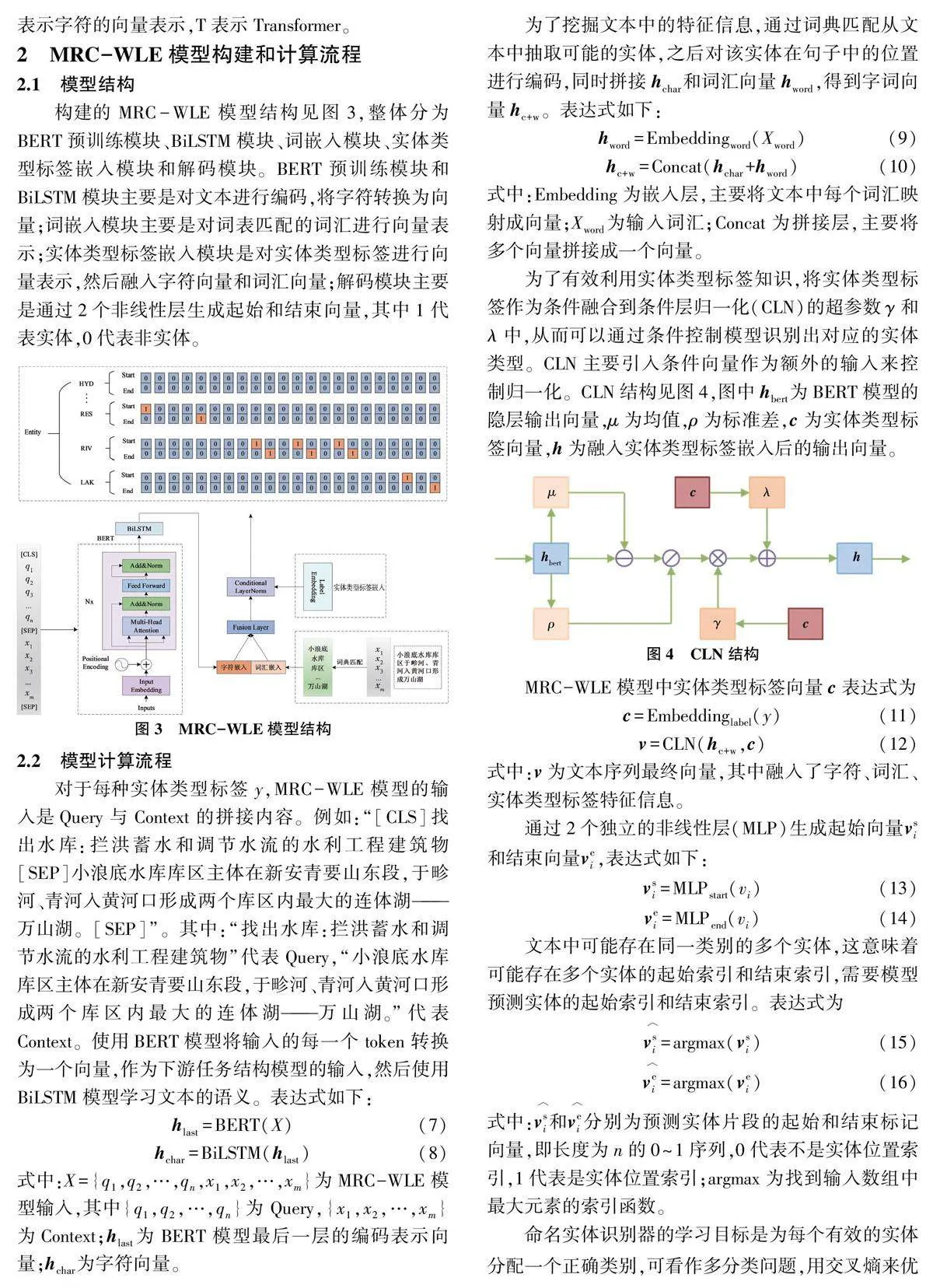


关键词:水利领域;命名实体识别;数据增强;机器阅读理解
中图分类号:TP391.1;TV21 文献标志码:A doi:10.3969/ j.issn.1000-1379.2024.09.023
引用格式:朱永明,邢丹艳.基于数据增强的MRC 水利领域命名实体识别模型研究[J].人民黄河,2024,46(9):156-160.
随着我国水利信息技术的发展,水利行业积累了大量数据,然而这些数据没有被有效利用。水利知识涵盖范围广,涉及河流、湖泊、水库等多种管理对象,以及水旱灾害防御、水资源管理、水土保持等多种业务,知识来源有结构、半结构、非结构化数据[1] 。自然语言处理技术具有强大的语义处理能力,可以将非结构化数据转化为结构化数据,充分发掘数据的价值,实现水利信息资源的高效利用。命名实体识别是信息处理的基础,通过命名实体识别技术可以充分利用文本中的宝贵信息。水利领域命名实体识别是指识别水利文本中具有特定意义的实体,包括河流(RIV)、湖泊(LAK)、水库(RES)、水电站(HYD)、大坝(DAM)等。科研人员利用命名实体识别技术识别出重要信息,这些信息可以服务于水利智能问答系统构建[2] 、水利知识图谱构建[3] 等。
神经网络具有自动提取特征、能够找到更深层次和更加抽象的特征的优点,因此基于神经网络的命名实体识别在各个领域逐渐得到广泛应用。刘雪梅等[4] 基于水利工程巡检文本,利用BERT-BiLSTMCRF模型智能识别巡检文本中的风险事件、工程等实体。顾干晖等[5] 利用BERT 预训练语言模型对自建水利文本语料进行训练,并引入FreeLB 增强训练模型的泛化能力,最后通过条件随机场(CRF)识别水利实体。段浩等[1] 在2021 年提出了水利综合知识体系的描述方法,使用BiLSTM-CRF 模型识别非结构化和半结构化实体。伴随着ChatGPT、文心一言、讯飞星火等大模型的出现,学者们陆续把研究重心放到大模型上。清华大学开源了一个具有62 亿参数的支持中英双语对话的语言模型ChatGLM - 6B。百川智能公司基于Transformer 结构在大约1.2 万亿tokens 上训练了一个具有70 亿参数的大规模预训练语言模型baichuan-7B。学者们针对各个领域任务微调这些大模型,取得了不错的效果。然而,已有方法在预测精度和适应性上还有提升空间,没有充分利用水利文本中一些潜在特征信息,比如词汇特征信息和实体类型标签特征信息。本文以MRC 模型为主架构,结合数据增强技术,提出MRC-WLE 命名实体识别模型,基于水利文本数据集验证MRC-WLE 模型的有效性,以期更好地服务于水利智能问答系统、水利知识图谱构建等。
1相关理论介绍
1.1机器阅读理解(MRC)
MRC 是一种自然语言处理技术,让机器能够理解文本内容并回答问题,针对某一问题在文本中提取答案所在片段,即预测答案所在片段的开始位置和结束位置。
MRC 步骤如下:1)将传统的命名实体识别数据集的标注格式转换为三元组格式( Query, Answer,Context)。对于每种实体类型都用一个自然语言问题进行描述,将Context(文本)与Query(实体类型描述)进行拼接,若有m 种实体类型,则构造m 种实体类型描述,从而生成m 条新文本。2)用预训练模型对生成的文本进行编码。3)通过2 个全连接层识别每条文本中实体的头和尾,译码匹配采用就近原则,头位置索引找离它最近的尾位置索引,从而构造出一个实体。
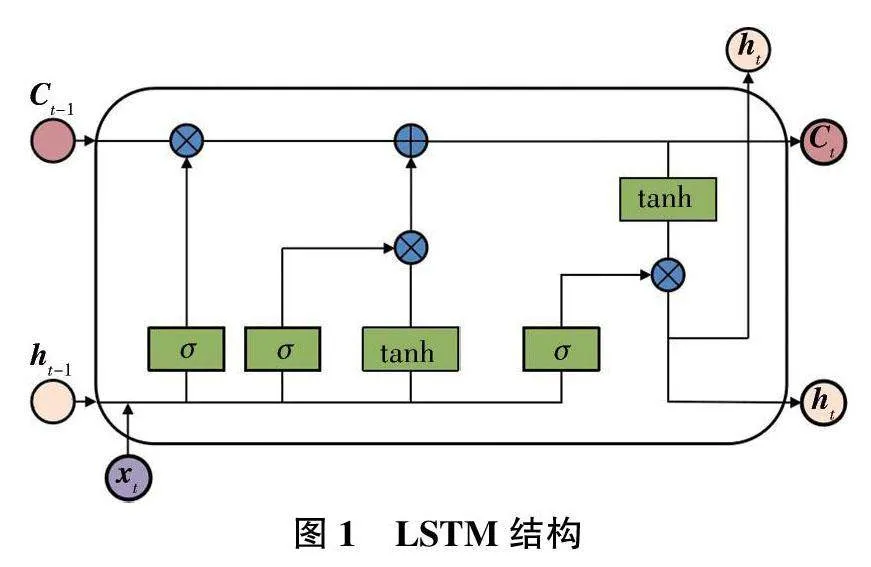
1.2长短期记忆网络(LSTM)
LSTM[6-8] 对循环神经网络(RNN)进行了一定改进,主要用来解决长距离依赖问题。LSTM 在RNN 的基础上增加了门控机制和一个单元状态(cell state),用来获得长期的序列状态,其结构见图1。
1.3BERT模型
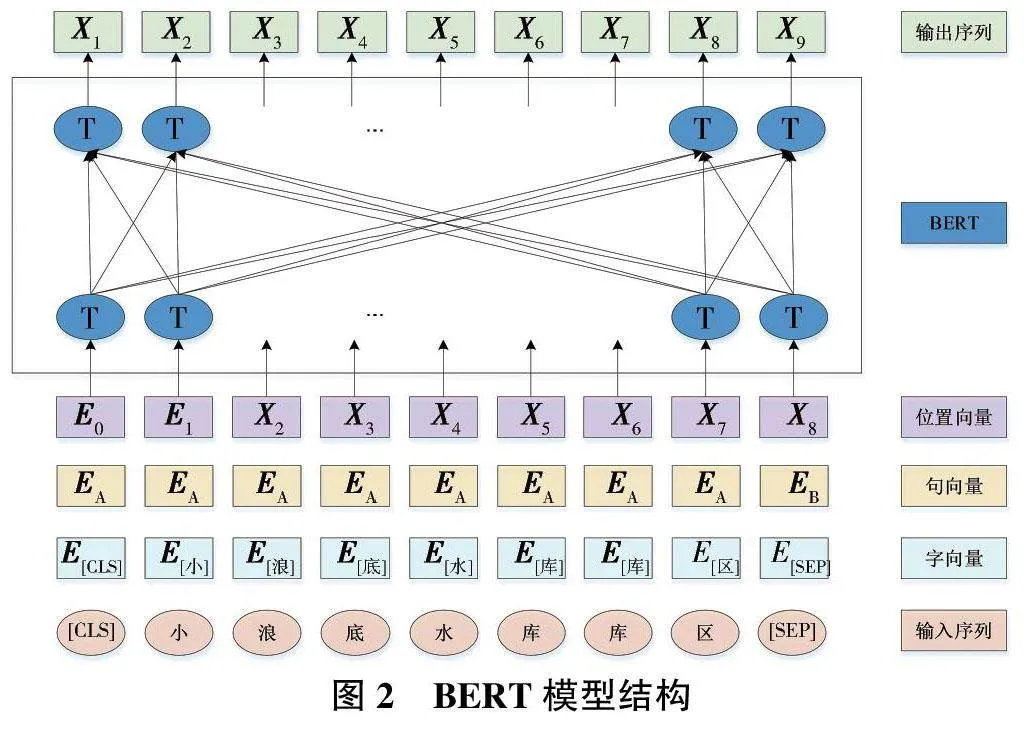
传统的word2vec 无法处理一词多义问题。BERT(Bidirectional Encoder Representation from Transform⁃ers)[9] 模型采用捕捉语义能力更强的双向编码器Transformer 进行训练,可以获得每一层文本双向特征信息,有效解决一词多义问题。Transformer 是一种新的序列建模方法,采用self-attention 机制替代传统的卷积神经网络(CNN)或RNN,这种机制能够更好地捕捉序列中的依赖关系。Transformer 具有可并行计算、长距离依赖建模等性能,目前被广泛应用于自然语言处理的各个下游任务,并取得较好的效果。
BERT模型的输入根据下游任务确定,模型结构见图2,其可将中文字符用向量表示。
图2 中以“[CLS]小浪底水库库区[SEP]”为例,[CLS]用于标记文本的开头,[SEP]表示文本结尾,E表示字符的向量表示,T 表示Transformer。
3MRC-WLE模型性能测试及评价
3.1测试数据
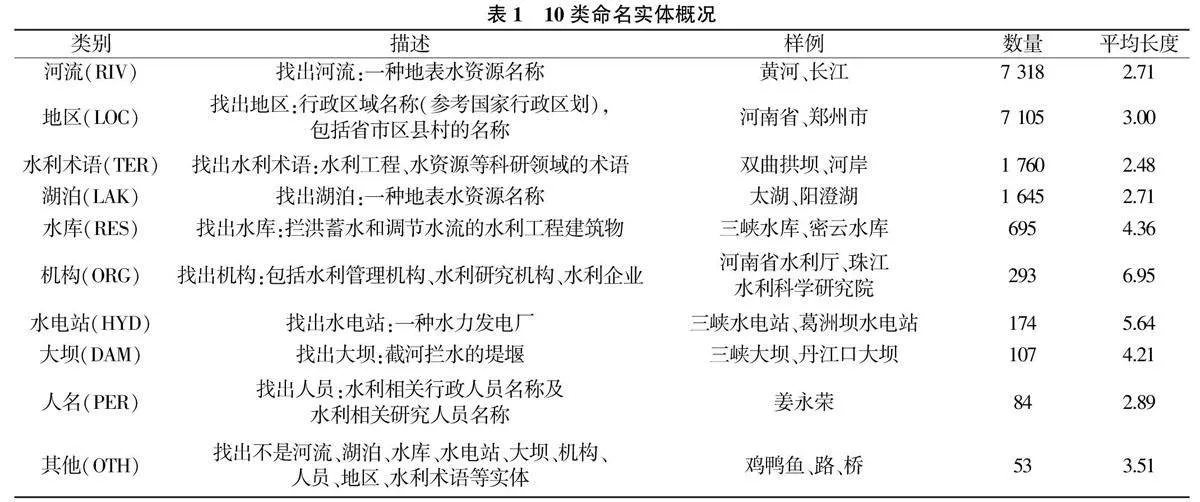
采用中国水利水电科学研究院在中国工程科技知识中心水利专业知识服务系统开放的水利标注数据测试MRC-WLE 模型的性能,其中:水利文本数据共4 919条,命名实体类型共10 类。10 类命名实体概况见表1。水利领域命名实体识别实验中使用随机分层抽样的方式将数据集划分为训练集、验证集、测试集,三者数据量比例为8∶1∶1。
3.2设置训练参数及评价指标
水利领域命名实体识别实验使用的编程语言为Python,深度学习框架为Pytorch、Transformers,批数据量为8,训练次数为10 次,学习率为2×10-5,损失函数采用交叉熵损失函数。评价模型时选用微平均F1 值作为主要评价指标,以精准度(Precision) 和召回率(Recall)作为辅助评价指标。
3.3模型测试和评价结果
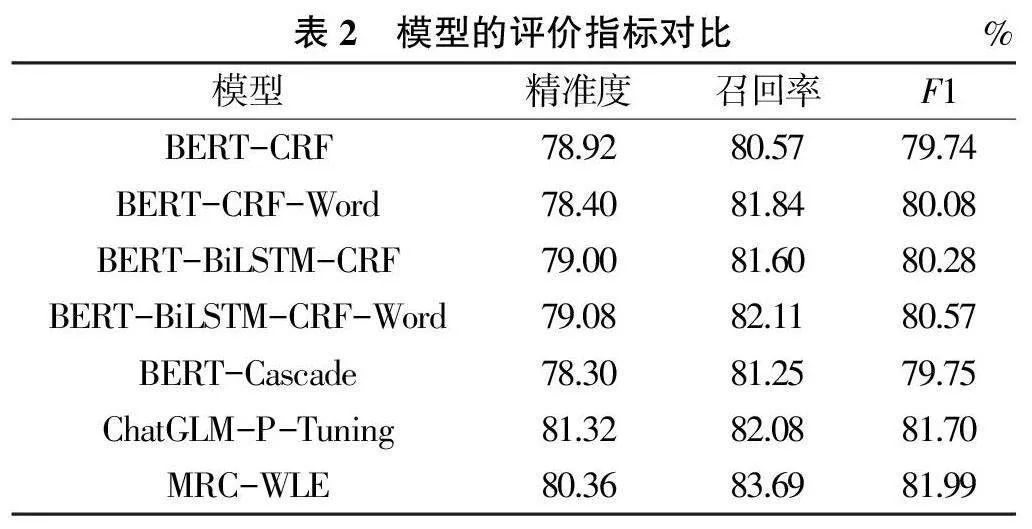
为更好地评价模型的性能,引入BERT -CRF、BERT - CRF - Word、BERT - BiLSTM - CRF、BERT -BiLSTM- CRF - Word、BERT - Cascade、ChatGLM - P -Tuning 模型作为对照。模型的评价指标对比见表2,可以看出,MRC-WLE 模型的评价指标值整体高于其他模型的。
各模型的优缺点如下:BERT-CRF 和BERT-BiL⁃STM-CRF 模型不能很好地利用文本信息,识别实体的时候会出现实体断链现象。BERT-Cascade 模型是基于多任务学习方法的命名实体识别模型,其任务是抽取实体和判断实体类型,该模型虽缩减了标签词表规模,但是先抽取实体会出现实体传播错误问题,导致后续判断实体类型错误。BERT-CRF-Word 和BERTBiLSTM-CRF-Word 模型虽然同时对字符和词汇进行编码,有效地利用字符级信息和词汇级信息,但是分词工具不能完全适用于水利领域,因此会造成实体词汇错误传播,进而容易造成识别错误。ChatGLM -P -Tuning 模型是对ChatGLM-6B 基座大模型进行领域微调,具有强大的对话能力,因此ChatGLM-P-Tuning 模型能根据指令从文本中抽取出完整的实体。MRCWLE模型针对每种实体类型都生成一条新文本,在每一条文本中只识别Query 对应的实体,并且该模型能够利用实体类型的先验知识,很好地解决实体易混淆问题。此外,MRC-WLE 模型同时对字符和词汇进行编码,提高了模型识别实体边界的准确率,召回更多的实体。
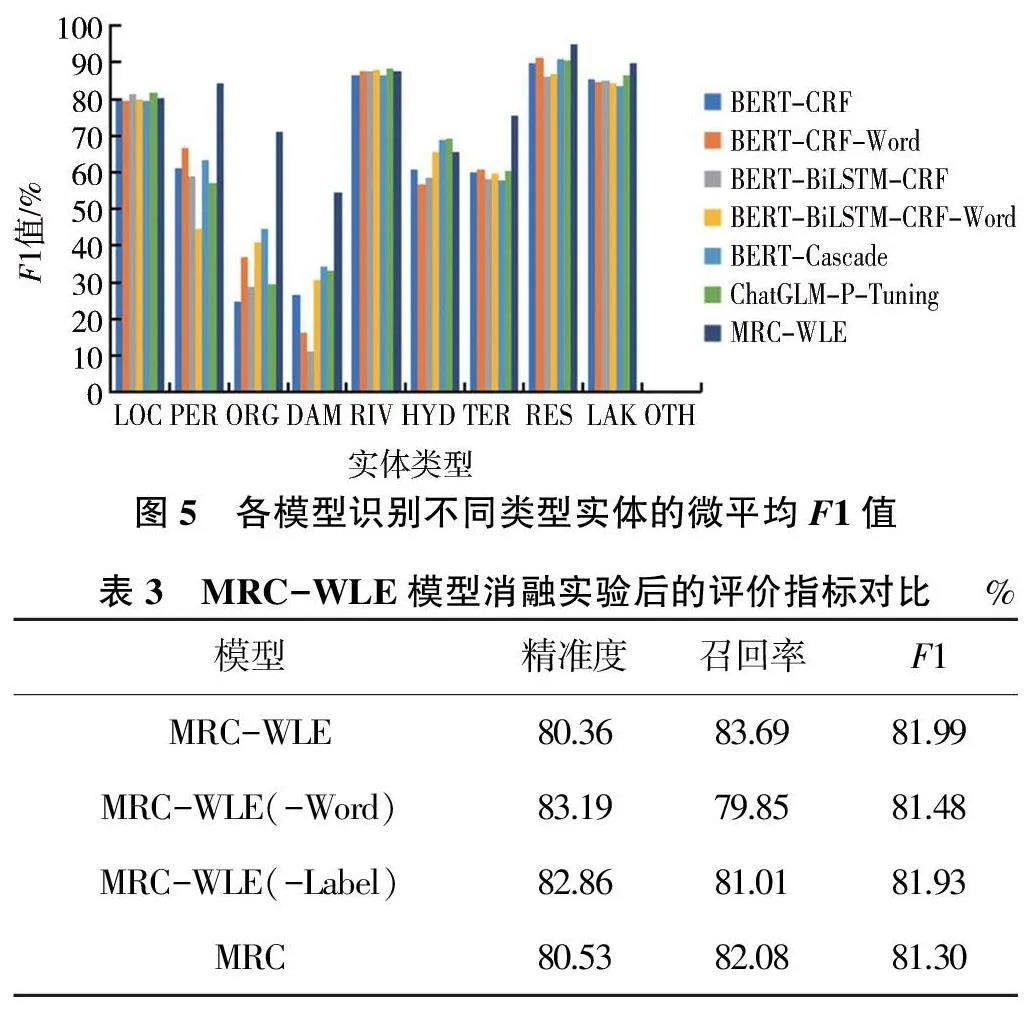
不同模型识别不同实体的微平均F1 值见图5。相较于其他模型,MRC-WLE 模型识别湖泊、人名、机构、大坝、水利术语、水库实体类型的F1 值最高。原因是这些实体内部都有一定的构成规则,比如湖泊类型的实体大部分以湖结尾,MRC-WLE 模型引入实体类型嵌入,输入一定的指令,能较好地将实体识别出来。此外,所有模型识别OTH 的F1 值都为0%,这可能与该类型实体数量较少且构成规律比较复杂有关。
为研究词汇特征信息和实体类型标签特征信息对模型的影响,基于数据集对MRC-WLE 模型进行消融实验,评价指标见表3。与MRC-WLE 模型相比,去掉词嵌入模块( - Word)、实体类型标签嵌入模块(-Lable)后微平均F1 值都有所降低,去掉词嵌入模块(-Word) 的降幅较大。与MRC 模型相比,MRCWLE模型的微平均F1 值提高了0.85%。
4结论
本文针对水利领域命名实体识别提出了一种基于数据增强的MRC 模型,在编码层引入词汇特征信息和实体类型标签特征信息,通过学习字符与字符、词汇与词汇、词汇与实体类型标签之间的内在相关性,获得文本语义特征信息,提高了水利领域命名实体边界和类型识别的准确性。基于机器阅读理解的方法可以较好地引入知识信息,今后将引入部首、字形、拼音等多粒度语言学特征信息,将多任务学习纳入机器阅读理解框架,以提升模型识别长实体的能力。
