
融合实体-语句特征信息的中医医案实体识别研究
2024-09-22 00:00:00王丰陈根浪吴创
软件工程 2024年9期


关键词:特征融合;命名实体识别;BERT;中医
中图分类号:TP391 文献标志码:A
0 引言(Introduction)
中医医案中蕴含着中医专家丰富的诊疗经验和理论,因此有效提取医案中的草药、症状、证、剂量等信息[1]对于后续探寻诊疗规律[2]、构建诊疗模型[3]具有重要意义,是传承中医学的重要实践方式。
在中医领域,命名实体识别(Named Entity Recognition,NER)被用于提取症状、中药等实体信息,是中医知识图谱构建的重要技术之一。中医命名实体具有复杂、长度不确定等特点,并且存在许多嵌套实体,因此中医实体识别更具挑战性。考虑到中药之间的配伍关系和症状的共现性,本文提出了一种中医实体融合识别方法。该方法将每个实体向量和语句向量相融合,获得带有全局特征信息的实体向量,进一步将实体向量和语句向量进行连接以获得融合后的特征向量。本文使用多组基于BERT(Bidirectional Encoder Representation fromTransformers)的模型进行了实验与测试。实验结果表明,本文提出的方法在中医医案的实体识别任务上的精确率有显著提高,可为中医医案的实体识别提供有益的参考。
1 相关工作(Related work)
命名实体识别是中医领域信息提取的关键任务,也是中医数据挖掘和构建中医辅助诊断系统的重要步骤。医学命名实体识别方法可分为基于规则和领域词典的字符匹配的方法、基于机器学习的方法和基于深度学习的方法。
早期的实体识别方法主要依赖专家构造语法和语义规则,根据规则进行模式匹配来完成对实体的抽取。中医师们利用医学字典和专业人员的临床专业知识构建模板和规则。ZINGMOND等[4]通过研究医学语料库中的规则,并结合处理医学文本报告的自然语言处理方法,构造了一个文本处理器。FRIEDMAN等[5]设计了一种通用自然语言文本处理器,用于提取医学报告中的临床信息。这类方法存在准确性过度依赖模板质量和可移植性的问题。
机器学习方法将实体识别任务转换为字符(Token)级别的多分类问题或是序列标注问题,在构造标注数据的同时,通过学习将不同字符映射成为不同标签。例如,隐马尔可夫模型、支持向量机、条件随机场(Conditional Random Field,CRF)模型等常见的机器学习算法均被广泛应用于实体识别。高佳奕等[6]将条件随机场模型应用于中医实体识别,在名老中医临床肺癌医案实体识别任务中取得了满意的效果。任宋洁[7]使用条件随机场模型对药品说明书进行实体识别。这些方法虽然减少了对人工构建模板的需求,但是仍然需要大量的特征工程。
深度学习方法避免了烦琐的特征工程,采用向量化表示以及神经网络式的传导求解探索隐藏的语义信息。DENG等[8]构建了双向长短期记忆递归神经网络并结合条件随机场模型识别中医药专利中的实体,并取得了良好的效果。在Transformer提出后,两段式训练被广泛应用。双向Transformer编码器的BERT预训练语言模型则提升了词向量的语义表征能力,使其在命名实体识别上有较大的性能提升。何涛等[9]使用BERT模型配合条件随机场模型从电子病历中提取实体,并验证了BERT-CRF模型应用在中文实体识别中尤其是在中医实体识别任务上的有效性。
2 模型架构(Model architecture)
2.1 模型概述
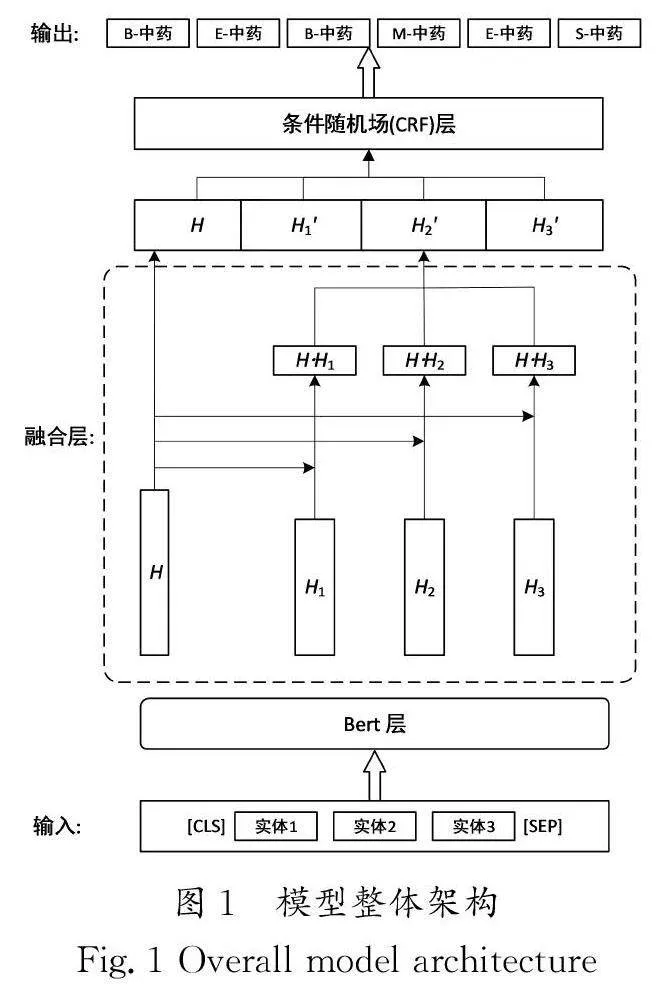
本文提出的模型整体架构如图1所示。在输入文本序列添加特殊标记[CLS]和[SEP]后,经由BERT模型的嵌入层对输入序列进行编码,生成语义向量表示。虚线框是本文提出的融合模块,将实体向量Hn 和语句向量H 相乘,获得的融合向量H'n 包含了单个实体与语句环境的特征信息,之后将添加语义信息后的融合向量H'n 与原始语句向量H 连接,得到保留上下文实体关系的融合特征向量。该方法可以捕捉实体之间的依赖关系并提取出更丰富的语义特征。条件随机场模型负责对融合向量进行解码,计算得分最高的标签,可以获得最佳的训练标签序列。下文将详细介绍模型的每一模块。
2.2BERT预训练模型
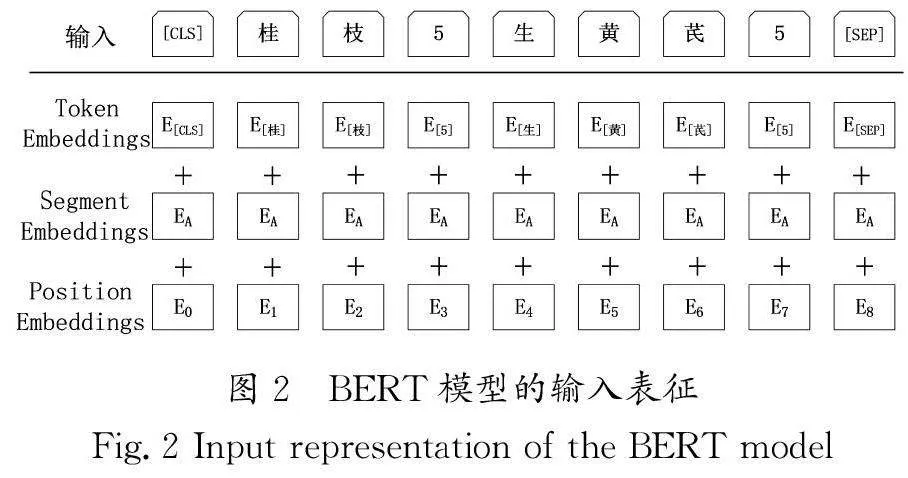
BERT模型的输入表征如图2所示。输入由词嵌入向量(Token Embedding)、分段嵌入向量(Segment Embedding)和位置嵌入向量(Position Embedding)组成。文本数据被转换为向量,并且为每个句子的开头和结尾添加特殊标志[CLS]和[SEP],经过词嵌入后的向量被转换成一个768维的向量。分段嵌入层使用两种向量表示法为句子对中的两个句子分配不同的向量表示,用于区分两个句子的前后顺序。位置嵌入层为每个位置学习一个代表序列顺序信息的向量和一个大小为(512×768)的查找表用于表示序列中各个位置的特征。3个嵌入层的向量按元素相加得到BERT编码层的输入。
BERT预训练模型的实现基于多层双向Transformer编码器且采用掩码语言模型用于预训练,生成融合上下文信息的深层双向语言表征。本文实验选择使用中文维基百科相关语料的预训练BERT-base-Chinese模型,其结构为12层编码器,每层有12个端口,向量维数为768维。
2.3 融合层
在中医文本中,实体之间存在一些固定的上下文信息。例如,前人把单味药的应用同药与药之间的配伍关系称为药物的“七情”,例如“桂枝配白芍”二药配伍,一温一寒,一敛一散,针对卫强营弱,可调和营卫。“柴胡配黄芩”二药配伍,具有较好的和解少阳、疏散肝胆郁热的作用。药物配合使用,药与药之间会发生某些相互作用,有的能增强或降低原有药效,有的能抑制或消除毒副作用。在症状描述中,患者的某些症状往往伴随产生,如“鼻涕多、鼻塞”“久咳多痰”等通常会伴随某种疾病出现。为了更好地适配中医医案文本的药物配伍关系和症状的共现性,获得更丰富的实体间特征,本文提取文本中的单个草药实体和其他实体,并将草药实体放入中药处方语境中。同样,将症状实体放入其经常出现的语境中进行实体融合,使得实体不仅具有自身的特征,还具备文本中其他实体的语境特征。因此,与单个实体向量相比,融合向量拥有更多关于每个实体与整个语句之间关系的特征信息。融合模块的具体算法流程如下。
3 实验(Experiment)
3.1 数据预处理
实验选取了4000多份患者的临床病历,经过数据清洗和冗余处理等预处理步骤,保障了数据的可靠性。结合特定领域的知识以及专家的见解对数据进行标注并构建了一个中医语料库,其中包括20 400个草药实体和26072个症状实体。
考虑到中医实体具有很强的领域专业性,需要制定规范的标注策略以更好地确定实体之间的差异性,保证标注数据的完整性。标注规范描述如下。
(1)同一中药材采用不同的炮制方法会产生不同的功效,因此标注上要进行区分。例如:生麦芽具有回乳消胀的功效;炒麦芽有健胃消食的作用。
(2)症状中存在大量嵌套实体,因此对嵌套的症状要进行区分。例如:舌红苔白和舌红苔白厚腻表示不同症状。
(3)专业的中医师在描述症状时存在一定的口语化特点,部分症状描述可能会采用缩写形式,因此对症状描述的差异性要进行标注上的区分。例如:手心萎黄和手黄。
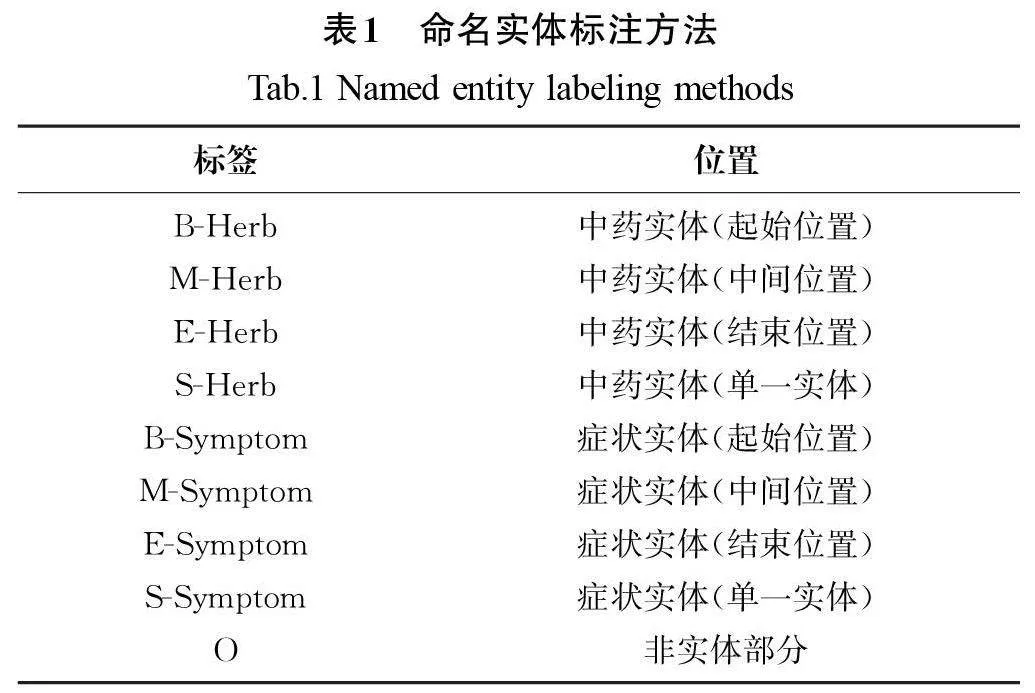
本文数据集采用BMES(Beginning Middle End Single)标注方法,具体格式如表1所示。其中:B代表实体的起始位置,M代表实体的中间位置,E代表实体的结束位置,S代表单一实体,O代表非实体部分。数据按6∶2∶2的比例分为训练集、验证集和测试集。
3.2 实验环境
本实验基于Pytorch框架构建神经网络模型,具体实验环境配置如表2所示。
3.4 实验参数
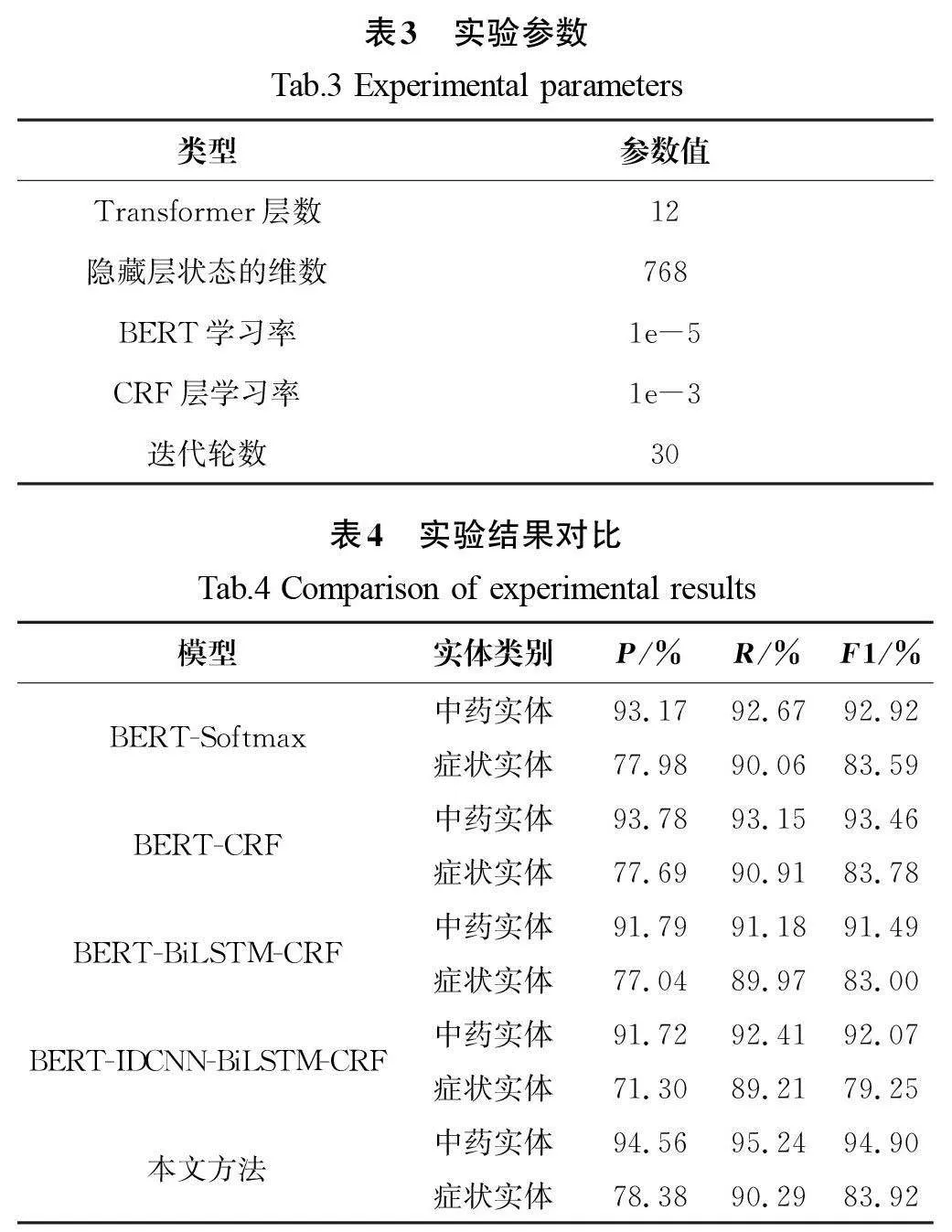
实验中使用BERT 预训练模型为12层Transformer网络,隐藏层状态的维数为768,BERT预训练模型的学习率为1e-5,CRF层的学习率为1e-3,以30轮迭代训练的最优结果作为最终训练结果。实验参数如表3所示。
3.5 结果与分析
将实体识别抽象为序列标注问题后,本研究首先使用Softmax函数对融合层的输出向量进行分类,以获取训练好的标注序列。考虑标签的预测相对独立,实体识别的准确率是将实体包括边界作为整体计算,因此将Softmax函数替换为条件随机场模块,确保标签之间的约束性。在症状实体的精确度上,添加Softmax函数在BERT模型后的表现略好于条件随机场模块,而F1分数和召回率则稍差。在中药实体方面,添加条件随机场模块在P、R、F1三个指标上的表现更胜一筹。不同模型的实验结果对比如表4所示。
在BERT-CRF模型的基础上,加入双向长短期记忆递归神经网络(Bi-directional Long Short-Term Memory,BiLSTM)获取上下文特征信息。BiLSTM 通过其门控结构控制神经元的传输,从而学习中药和症状文本中存在的上下文关系。加入上下文特征后,训练结果并未得到显著改善。本文分析认为BiLSTM可能忽略了局部特征,因此加入了空洞卷积神经网络(Iterated Dilated Convolutional Neural Network,IDCNN)模块。空洞卷积在不使用池化损失信息的情况下扩大了感受野,使每个卷积输出都包含更大范围的信息。然而,添加空洞卷积神经网络结构和双向长短期记忆递归神经网络并未对实体识别效果带来明显的提升。
为了使模型能够更好地获取中医上下文特征信息,本文提出了实体特征融合的结构,添加特征融合模块后的中药实体识别效果提升显著,这主要得益于中药之间的配伍关系更加密切。由于本文的特征融合方法更好地关注到了上下文特征信息,在中医语料上实体识别效果优于其他方法。与BERT-CRF模型相比,中药实体识别F1分数提高了1.44百分点,症状实体提高了0.14百分点。与BERT-IDCNN-BiLSTM-CRF模型相比,中药实体识别F1分数提高了2.83百分点,症状实体提高了4.67百分点。
4 结论(Conclusion)
本研究通过融合BERT预训练模型提取的语句特征向量和实体特征向量,更有效地捕捉到了中医实体之间的特征信息。将融合向量输入条件随机场模块,在标签序列预测过程中降低了非法序列的发生概率,从而提高了标签预测的准确性。实验结果表明,本文提出的方法在对中医命名实体识别的效果上优于其他方法。未来的研究将进一步完善数据集和方法,以提高对相似文本实体的准确识别率。
作者简介:
王丰(1999-),男,硕士生。研究领域:中医智能化技术及应用。
陈根浪(1978-),男,博士,教授。研究领域:大数据及人工智能,生命健康领域。
吴创(1998-),男,硕士生。研究领域:中医智能化技术及应用。
