
面向医疗领域的意图识别方法研究
2024-09-22 00:00:00张卓群王荣波黄孝喜
软件工程 2024年9期






关键词:意图识别;标签拆分;大语言模型;自然语言理解
中图分类号:TP391 文献标志码:A
0引言
(Introduction)自然语言理解[1]是人工智能领域的一个关键分支,其致力于让计算机能够理解和解释人类自然语言的含义。其中,意图识别是自然语言理解的关键技术,它能帮助计算机理解人类的需求,可以提供个性化服务。目前,自然语言理解已广泛应用于虚拟助手、智能客服[2]和语音识别等领域,特别是在辅助问诊中,其可以协助提高医患沟通质量,帮助医生获取更多的病情信息,从而节省诊疗时间,提高工作效率。
本文对医疗领域的意图识别方法进行了相关研究,针对意图标签数量过多带来的识别挑战,提出了一种拆分策略,将复杂的分类任务拆分为两个相对独立的子任务,并在解码层采用双头解码机制,实现同时对两个子任务进行解码。该方法不仅充分考虑了标签之间的内在联系,还能有效学习多个任务,提升了意图识别的准确性和效率。同时,将本文提出的方法与大语言模型进行对比,并深入分析不同模型的表现存在差异的原因,可为医疗领域意图识别的后续研究提供参考依据。
1 相关研究(Related work)
随着深度学习技术的日益成熟,其在意图识别领域的应用取得了显著的进步和一系列成就。杨志明等[3]提出将ICDCNN(双通道卷积神经网络)算法用于意图分类,该方法利用Word2Vec和Embedding层提取问句语义特征,采用双通道卷积运算结合字、词级别词向量的方式,捕捉深层次语义信息;RAVURI等[4]使用RNN(循环神经网络)和LSTM(长短期记忆网络)模型解决意图分类问题,结果显示LSTM 模型的意图识别错误率低于RNN;HOU等[5]针对航空信息领域的意图识别,提出了一种增加门控机制及条件随机场约束条件的双向长短时记忆网络方法,实验证明,该方法提高了识别准确率;魏鹏飞等[6]提出采用注意力循环神经网络解决意图识别问题,该方法在ATIS(Airline Travel Information System)数据集上的表现优异;YAO等[7]提出的基于图卷积神经网络的槽填充框架在多个分类任务基准数据集上的表现较好;华冰涛等[8]提出了一种BLSTM-CNN-CRF(双向长短期记忆网络-卷积神经网络-条件随机场)模型,用于构建意图识别和槽填充的联合模型;GOO等[9]介绍了一种基于槽门控机制的双向关联模式,该模式能有效地结合两项任务的信息进一步探索意图和语义槽之间的关系。随着注意力机制被越来越多的研究者关注,YANG等[10]提出了一种创新的联合模型,该模型的核心在于其位置感知的多头注意机制;樊骏锋等[11]针对现有研究中很少有意图-槽相关性进行明确建模的问题,通过BiLSTM(双向长短期记忆网络)和注意力机制,提出了一种用于联合意图预测和槽填充的新框架;李实等[12]提出了一种基于BiLSTM 和图注意力网络的方法,旨在识别用户话语中的多个意图信息并优化语义槽填充。
2 基于双头解码机制的意图识别方法(Intentrecognition method based on dual-head decodingmechanism)
一个优秀的模型能够充分利用数据集中的信息准确捕捉用户的意图,从而提升意图识别的准确性和效率。因此,在进行意图识别任务时,需要在实际应用中根据具体任务需求和资源条件,选择最适合的模型进行意图识别,确保任务的顺利完成和取得良好的效果。
2.1IMCS(Intelligent Medical Consultation System)数据集中意图标签的拆分
为了促进自动化医疗问诊的发展,复旦大学大数据学院在复旦大学医学院专家的指导下,构建了IMCS数据集,该数据集收集了真实的在线医患对话,并进行了多层次的人工标注,标注方式采用句子级标注,包含命名实体、对话意图、症状标签、医疗报告等。IMCS数据集中标注了医患对话行为,共定义了16类意图,对话意图的类别的定义如表1所示。
输入的是多轮对话语句组成的整段医患对话;输出为每一条对话语句的句子级意图标签。通过仔细观察表1中的16种对话意图可以发现,除了“诊断”和“其他”两个特殊标签,剩余的14种标签都是由“A-B”的形式构成,并且是A和B的笛卡尔积的形式,因此将14种标签进行拆分:A定义为意图标签,有2个取值,分别是“提问”和“告知”;B定义为行为标签,有7个取值,分别是“症状”“病因”“基本信息”“已有检查和治疗”“用药建议”“就医建议”“注意事项”。对于“诊断”和“其他”两类特殊的标签,选择将其视为“诊断-诊断”和“其他-其他”分别放入意图标签和行为标签两个集合中。对IMCS数据集意图标签的拆分如图1所示。由于模型在解码过程中存在一定概率生成不存在的标签,如“其他-症状”,为了提升模型的识别准确性和可靠性,将这不存在的标签进行简单归类,统一归为特定的标签,例如将“其他-症状”归类为“其他”“诊断-症状”归类为“诊断”。
2.2 双头解码模型框架设计
多层感知机(Multilayer Perceptron,MLP)是一种基于前馈神经网络的深度学习模型。MLP由多个神经元层组成,其中每个神经元层与前一层全连接。这种结构使得MLP可以帮助模型学习非线性特征,提高模型的表征能力。MLP模型的基本结构包括输入层、隐藏层和输出层(图2)。
MLP的输入层接收的输入数据通常是一组特征向量。每个隐藏层包含若干个神经元。这些神经元通过激活函数将输入数据进行非线性转换,以便捕捉更复杂的特征。常用的激活函数包括Sigmoid函数、ReLU函数等。根据任务需求,输出层可以为一个或多个神经元。在分类问题中,通常使用Softmax函数将输出转换为概率分布。在此任务中进行预测时,输入的是一整段对话,但Softmax函数是一种局部的解码方法,可以独立地对每个类别进行预测。CRF是一种全局的解码方法,对句子之间的意图转移进行解码,能够考虑标签之间的依赖关系,通过全局学习标签序列的概率分布,进一步提高标签预测的准确性。所以,在解码层采用MLP+CRF的结构形式,其中MLP负责特征提取和转换,将输入数据映射到特征空间;CRF负责考虑标签之间的关系和约束,以及对整个序列进行联合标签分类。
整个意图标签分类任务的模型结构编码层由BERT+BiLSTM框架构成,通过BERT提取单条对话语句的句子级语义特征,使模型可以更好地理解上下文信息,BiLSTM 捕捉文本中的句子结构和顺序信息,对每条句子提取对话中的上下文语义特征。解码层对拆分后的两个标签集合通过双头MLP+CRF进行解码,双头解码机制通常会有两个头部(或者称为任务),每个头部对应一个不同的标签集合。通过学习状态之间的转移概率,模型可以预测每个时刻的最佳标签,同时考虑两个标签集合之间的关系,以便更好地处理多标签分类问题,并增强模型的泛化能力。BERT+BiLSTM+MLP+CRF模型框架如图3所示,拆分后的两个标签集合共享同一个特征编码器,使用不同的解码器进行解码。
2.3 实验设计与结果分析
2.3.1 实验设置与评价指标
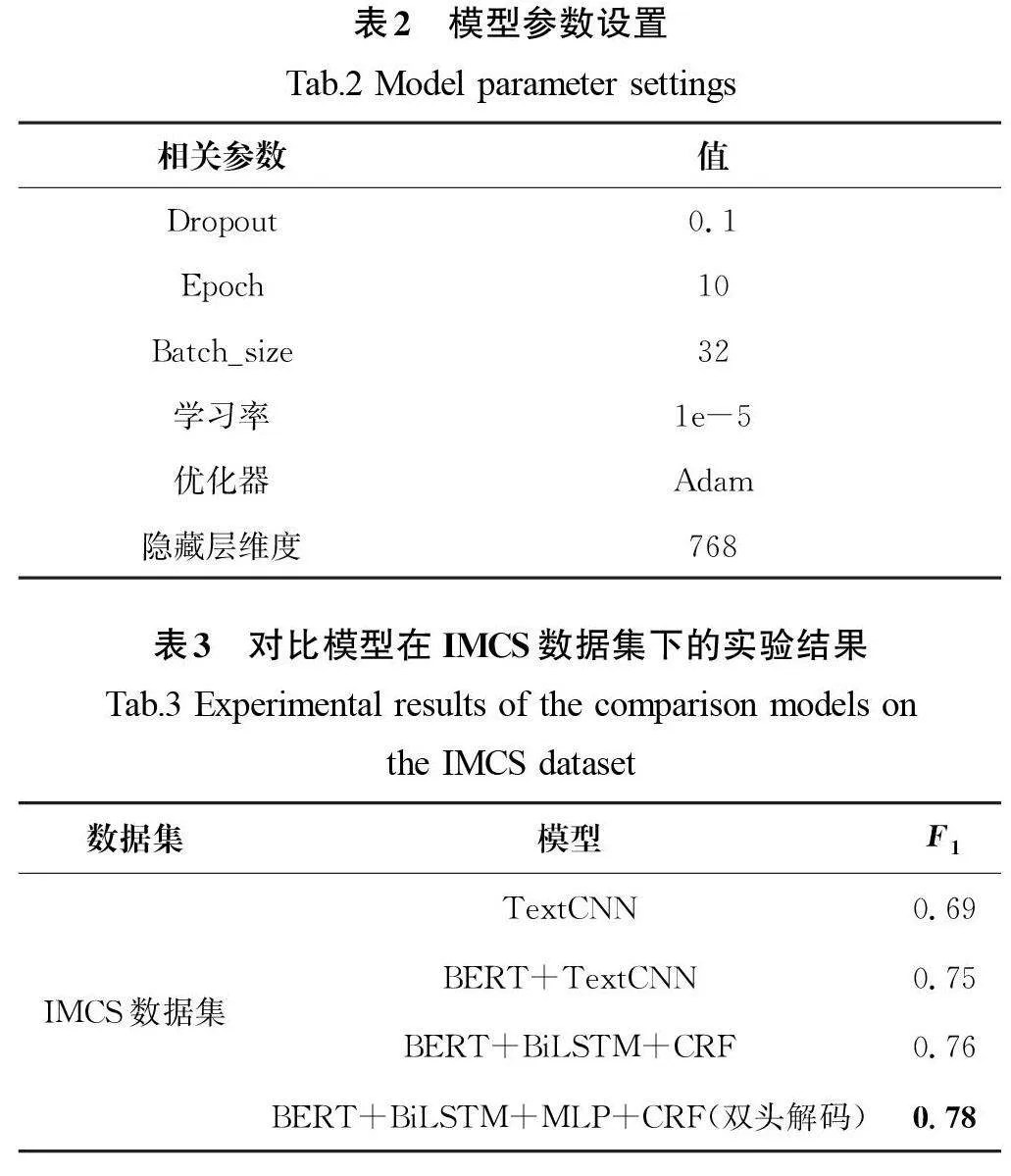
该实验模型由PyTorch深度学习框架、Python 3.7版本的编程语言构建。在实验过程中不断对模型参数进行调整,得到最适合模型的参数。模型参数设置如表2所示,选择F1 值作为评价指标对实验结果进行评估。
2.3.2 实验结果分析
为了验证该模型应用在IMCS数据集意图识别任务上的有效性,选取TextCNN(卷积神经网络文本分类模型)、BERT+TextCNN(基于Transformer的双向编码器表示+卷积神经网络文本分类模型)和BERT+BiLSTM+CRF模型作为对照实验组,最终实验结果如表3所示。
由表3可以看出,基于双头解码机制的意图识别方法在IMCS数据集上的F1 值达到了78%,相比于其他3种分类模型的F1 值,分别提高了9百分点、3百分点、2百分点,也证明了该方法的有效性。将16类意图标签拆分为两大类标签,从而间接减少了类别数量,使得学习难度下降。通过编码层提取话语级、对话级特征输入解码层,再由双头解码机制处理多个标签集合。每个头部对应一个任务或标签集合,对拆分后的两大类标签进行单独的解码,得到医患对话中每条语句对应的对话意图,这种细粒度的划分更有利于缓解流水线式多任务学习之间的误差传递。
3 基于大语言模型的意图识别方法(Intentrecognition method based on large language model)
本文“第2章节”采用的意图识别方法是基于深度学习的方法开展研究,而此类方法的训练通常需要大量数据进行标注。如今,大语言模型[13](Large Language Model,LLM)在对话式AI领域发挥了越来越重要的作用,它能生成丰富严谨的文本,但实质还是文本补全。LLM 因具备多项优势而受到学者对其摘要、分类和生成功能的广泛探索。本文提出一种基于LLM的医疗领域意图识别方法,并与前文所提出的BERT+BiLSTM+MLP+CRF模型进行比较和分析。
3.1 大语言模型的实现方法
BERT模型的发布证明了预训练模型与Transformer架构的优越性,语言模型的参数量大幅度增加,自然语言处理随之进入大型语言模型时代。LLM 是以Transformer架构为主,并利用多个Transformer编码器的堆叠深入理解句子中各个位置的关联性,从而更有效地捕捉上下文信息。同时,模型融入了自我注意力机制,从而更出色地处理长文本和序列间的依赖关系。通常情况下,LLM 的预训练过程是在通识知识的基础上进行的,因此当面临特定场景的任务时,需要通过模型的微调或提示学习等方式,提升其在下游任务中的应用能力。本节所提出的意图识别方法基于ChatGPT(Chat Generative PretrainedTransformer)大语言模型,设计了一种特定的输入格式,涵盖识别意图类型列表、具体需求指令及规定输出格式的指令等关键要素。按照规定的“提示”指令,将问题输入ChatGPT中,可以对得到的输出结果进行分类和分析。
3.1.1 提示设计
随着大语言模型的成熟和广泛应用,人们开始研究如何优化大语言模型的输出结果,以减少不相关或者错误回复的概率。用于改善大语言模型输出结果的方式有提示词工程(Prompt Engineering)。提示词(Prompt)是指对计算机程序或人工智能模型提供的输入或指令,在用户和ChatGPT对话时输入的文字就是提示词,它用于告知模型要执行什么任务或回答什么问题。提示学习(Prompt-Based Learning)是一种基于大语言模型的学习方法。通过在预训练模型中添加特定的提示,用于引导模型在特定任务上进行学习,使得模型能够在小数据集上进行快速微调,以实现高效的迁移学习。提示学习具有简单易用、灵活性强、快速迭代等优点。
提示词工程是指使用大语言模型时,通过精心设计和调整的输入提示引导模型生成特定的输出,可以将模型集中在某一特定领域,在短时间内获得符合自己要求的结果。设计一个完美的提示可以高效地完成给定的任务,指导模型生成准确输出。在设计提示时,遵循一定的原则与策略至关重要。首先,在向大模型提出问题之前要提供任务的背景或者情景信息,在提问时尽可能地把问题的背景和需求全部描述出来。大模型可以很好地理解用户给出的背景和情境,并给出相应的回答。其次,将单个复杂的问题拆分成多个小问题进行提问,从而提高大模型输出的准确度。最后,可以通过约束性的提示限制模型的输出,例如规定输出必须满足某些语法结构或者逻辑关系。在医疗领域的意图识别任务中,将意图和意图样例一起放入Prompt,采用OpenAI接口的方式直接调用GPT 模型(Generative Pre-trained Transformer)并解析结果。若不加入意图对应的样例,大语言模型只能根据意图的名字进行判断,则可能无法预测出正常的意图。规定的提示模板如表4所示。
3.1.2 编码和向量化
GPT处理的输入对象是向量,同样输出的对象也是向量。每个字符都会使用相同长度的向量表示。GPT将所有字符组合成词汇库,为每个字符分配值,每个字符被转换为一个点编码向量。ChatGPT使用字节编码(Byte Pair Encoding,BPE)进行高效编码,词汇表中的“单词”是频繁出现的字符组合。GPT使用50 257维向量,主要由0组成,导致空间效率显著降低。为了克服该限制,输入嵌入层的下一步将使用一个嵌入矩阵以实现对由50 257维的二进制输入向量组成的数据进行压缩,将其转化为长度为n 的简洁数值向量。
3.2 实验设计与结果分析
3.2.1 实验设置
在IMCS数据集的基础上增加本文“第2章节”提出的BERT+BiLSTM+MLP+CRF(双头解码)模型与大语言模型的对比实验。使用ChatGPT大语言模型中的gpt-3.5-turbo 模型,它具有更高的性能和效率,以及更强的语言能力。对于衡量模型在识别意图时表现的评价指标,本文采用准确率,即模型正确预测的意图数量与总样本数量之比。
3.2.2 实验结果与分析
由于数据集和访问ChatGPT的成本较高,因此抽取IMCS数据集中各类数据200条。IMCS数据集作为一个中文多轮医疗问答数据集,包含了许多诸如“您好”“再见”等噪声语句。为应对此问题,在数据抽样过程中采取分层处理的策略,确保每一层都能得到公正且随机的抽样。此外,为了提高数据集的质量,在构建测试集时进行了长度筛选,排除了文本长度小于5个中文字符的样本,以建立更加精确和高效的测试集。在测试集上的具体实验结果如表5所示。
从表5可以看出,ChatGPT在IMCS数据集上的表现相比本文“第2章节”提出的双头解码机制下的深度学习方法更出色,主要原因如下。
(1)IMCS数据集是一个医患多轮对话的数据集,参与对话的身份角色包含医生和患者,对话意图与说话人的角色有关。例如,患者的对话出现诊断意图的可能性不大,医生告知患者已有检查结果的可能性不大。因此,大多数对话的意图可以由某一个角色主导,对话意图与对话角色存在关联。由于输入的对话文本包含说话人的身份,所以在ChatGPT中存在角色引入标记,能够帮助其在进行意图识别时考虑到角色特征,进而得到更准确的意图。
(2)每一条对话语句在整段对话中都有独一无二的位置信息,位置信息很可能与对话意图有关,比如有关提问的意图早于告知的意图、对话刚开始时医生一般不会进行诊断等。根据日常经验可以描述出一个医患在线问诊的普遍流程:首先,讨论患者的主诉症状,其次,询问患者的基本信息和已有的检查及治疗结果,在此医生进行初步诊断并分析病因,提出用药建议和注意事项,最后提出进一步的就医建议。因此对话意图与对话进展存在关联,ChatGPT在对话生成过程中能够考虑到对话历史信息,包括前几轮的对话内容和对话的整体上下文,用于帮助理解当前对话的意图和位置信息,从而达到更准确的识别效果。
虽然大语言模型在IMCS数据集上的意图识别能力比基于双头解码机制的意图识别模型更出色,但是对于每一个话语,每次都需要提供完整的意图列表及其主题描述。然而,对弈垂直领域的研究,大语言模型的应用面临一项挑战:硬件资源的高需求难以满足。每个API调用的成本可能只有0.000 1美元,但如果乘以数千个对话,就是一个非常大的数字。相比之下,双头解码模型与大语言模型的识别效果相差不大,但在实际部署和使用时受到的限制较少,因此不失为一种优秀的医患对话文本意图识别方法。此外,本文的实验进一步证明了在处理包含角色、位置等信息的数据时,大语言模型能够更深入地学习并提取丰富的知识信息,从而实现更精确的意图识别。
4 结论(Conclusion)
本文以医疗领域的意图识别为研究任务,首先针对多轮对话数据集中标注的16类对话意图提出了一种创新的解决方案,即将复杂的16类意图分类任务拆分成两个独立的分类任务,在解码层引入双头解码机制,使模型能够同时对两个分类任务进行解码。这种设计使模型能并行学习多个任务,从而显著提升性能,在处理多标签分类时尤为出色。通过并行解码,模型能全面考虑标签之间的联系,准确预测多个标签,大幅提升预测精度。此外,本文还提出了一种面向医疗领域的大语言模型意图识别方法,其在处理含角色、位置等多样化信息数据时,凭借其卓越的学习能力,可以深入挖掘丰富的知识,实现精准的意图识别。对提出的深度学习模型方法在识别结果上进行了详细的比较与分析,为进一步理解和改进模型提供了重要的参考依据。
作者简介:
张卓群(1999-),女,硕士生。研究领域:自然语言处理,人工智能。
王荣波(1978-),男,博士,副教授。研究领域:自然语言处理,机器学习。
黄孝喜(1979-),男,博士,副教授。研究领域:自然语言理解,人工智能。
