
基于注意力机制和改进DeepLabV3+的无人机林区图像地物分割方法
2024-09-12 00:00:00赵玉刚刘文萍周焱陈日强宗世祥骆有庆
南京林业大学学报(自然科学版) 2024年4期






摘要:【目的】为提取林区主要地物分布信息,基于注意力机制和DeepLabV3+语义分割网络提出一种面向无人机林区图像的地物分割方法Tree-DeepLab。【方法】根据不同的林区地物类型对图像进行标注,标注类型分为法国梧桐(Platanus orientalis)、银杏(Ginkgo biloba)、杨树(Populus sp.)、草地、道路和裸地6类,以获取语义分割数据集。对语义分割网络进行改进:①将带有分组注意力机制的ResNeSt101网络作为DeepLabV3+语义分割网络的主干网络;②将空洞空间卷积池化金字塔模块的连接方式设置成串并行相结合形式,同时改变空洞卷积的扩张率组合;③解码器增加浅层特征融合分支;④解码器增加空间注意力模块;⑤解码器增加高效通道注意力模块。【结果】在自制数据集基础上进行训练和测试,试验结果表明:Tree-DeepLab语义分割模型的平均像素精度和平均交并比分别为97.04%和85.01%,较原始DeepLabV3+分别提升4.03和14.07个百分点,且优于U-Net和PSPNet语义分割网络。【结论】Tree-DeepLab语义分割网络能够有效分割无人机航拍林区图像,以获取林区主要地物类型的分布信息。
关键词:无人机;地物分割;林区图像;DeepLabV3+;注意力机制;ResNeSt
中图分类号:S758;TP391"""" 文献标志码:A开放科学(资源服务)标识码(OSID):
文章编号:1000-2006(2024)04-0093-11
UAV forestry land-cover image segmentation method based on attention mechanism and improved DeepLabV3+
ZHAO Yugang1, LIU Wenping1*, ZHOU Yan1, CHEN Riqiang1, ZONG Shixiang2, LUO Youqing2
(1. School of Information, Beijing Forestry University, Engineering Research Center for Forestry-oriented Intelligent Information Processing of National Forestry and Grassland Administration, Beijing" 100083, China;2. School of Forestry, Beijing Forestry University, Beijing 100083, China)
Abstract: 【Objective】 This study proposes the feature segmentation method Tree-DeepLab for unmanned aerial vehicle (UAV) forest images, based on an attention mechanism and the DeepLabV3+ semantic segmentation network, to extract the main feature distribution information in forest areas. 【Method】 First, the forest images were annotated according to feature types from six categories (Platanus orientalis, Ginkgo biloba, Populus sp., grassland, road, and bare ground) to obtain the semantic segmentation datasets. Second, the following improvements were made to the semantic segmentation network: (1) the Xception network, the backbone of the DeepLabV3+ semantic segmentation network, was replaced by ResNeSt101 with a split attention mechanism; (2) the atrous convolutions of different dilation rates in the atrous spatial pyramid pooling were connected using a combination of serial and parallel forms, while the combination of the atrous convolution dilation rates was simultaneously changed; (3) a shallow feature fusion branch was added to the decoder; (4) spatial attention modules were added to the decoder; and (5) efficient channel attention modules were added to the decoder. 【Result】 Training and testing were performed based on an in-house dataset. The experimental results revealed that the Tree-DeepLab semantic segmentation model had mean pixel accuracy (mPA) and mean intersection over union (mIoU) values of 97.04% and 85.01%, respectively, exceeding those of the original DeepLabV3+ by 4.03 and 14.07 percentage points, respectively, and outperforming U-Net and PSPNet. 【Conclusion】 The study demonstrates that the Tree-DeepLab semantic segmentation model can effectively segment UAV aerial photography images of forest areas to obtain the distribution information of the main feature types in forest areas.
Keywords:unmanned aerial vehicle(UAV); land-cover image segmentation; forestry images; DeepLabV3+; attention mechanism; ResNeSt
精准掌握林区中主要地物的分布信息,对林业政策调整、编制系统的林业经营计划十分重要[1]。无人机是获取高分辨率遥感图像的重要方式之一[2],通过低空飞行,可以快速便捷地采集林区图像。相较于卫星图像[3],无人机航拍图像的分辨率更高,时效性更好,且不易受天气环境影响[4]。通过分割无人机高分辨林区图像中的不同地物,获取林区中主要地物类型的分布信息,是林业研究的重点内容之一[5-8]。
随着图像分析和无人机航拍技术的进步与成熟,无人机林区图像分割算法也在不断发展。张增等[9]通过HSV颜色空间分割无人机航拍森林图像中的火灾区域,并使用支持向量机方法识别无人机航拍森林图像中的火灾区域,实现森林火灾监测;刘文萍等[10]利用二型模糊聚类方法分割出无人机林区图像中的树木树冠,用于树木胸径估值;Martins等[11]利用SLIC超像素分割方法分割无人机林区图像中的树木和其他区域,以获取林区树木分布信息。但这些传统的图像分割方法都需要人工选取特征参数,分割过程较为复杂。近年来,基于深度学习的自动化图像语义分割方法发展迅速。Long等[12]提出的全卷积神经网络(fully convolutional networks,FCN)将图像分类网络中的全连接层去掉,同时将分类网络作为编码器的主干网络,再通过解码器对主干网络输出的具有丰富语义信息的特征图进行解码,实现了图像的像素级分类。随后基于编码器、解码器结构的各种深度学习语义分割网络迅速发展,U-Net[13]、金字塔场景解析网络[14](pyramid scene parsing network,PSPNet)、RefineNet[15]、DeepLab系列网络[16-19]等都实现了图像的精准化语义分割,使无人机林区图像分割算法又有了新的研究思路[20-21]。其中,DeepLabV3+网络的空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)模块可以捕获图像中不同尺度特征,解码器的设计可用于恢复分割对象的边界信息,精准分割各类目标边缘[22],有利于复杂图像分割。
近年来,注意力机制被广泛应用于图像分析领域。注意力机制主要包含空间注意力机制和通道注意力机制。SE-Net[23]、Cbam[24]、ECA-Net[25]、ResNeSt[26]等网络都分别利用了空间注意力机制或通道注意力机制的思想搭建模型,使模型更易提取图像中的关键特征以提高模型准确率。鉴于DeepLabV3+网络对复杂图像分割能力较强以及加入注意力机制的模型可提高对关键特征的利用率,本研究选择DeepLabV3+语义分割网络作为基础模型,并加入注意力机制。但由于无人机航拍林区图像中不同树种之间的特征差异较小,不同类别之间边缘结构复杂,直接应用DeepLabV3+模型,得到的分割精度较低。为精确掌握林区中的主要地物分布信息,提出一种适用于复杂无人机林区图像的地物分割方法——Tree-DeepLab。通过对DeepLabV3+网络中的编码器和解码器进行改进并加入空间注意力模块(spatial attention,SA)和高效通道注意力模块(efficient channel attention,ECA),以适应无人机林区图像中的不同地物特征,通过大量试验得到最好的语义分割模型,并与常用的语义分割模型U-Net、PSPNet网络进行比较,验证改进模型的优劣性。
1 材料与方法
1.1 研究区概况与数据获取
研究区(118°10′57″E,34°38′10″N)位于山东省临沂市郯城县,是人工种植林区,主要种植树种为杨树(Populus sp.)、银杏(Ginkgo biloba)、法国梧桐(Platanus" orientalis)等,试验区中还有草地(grassland)、裸地(bare ground)、道路(road)等多种地物类型。不同树种间特征差异较小且边缘结构复杂,道路和裸地的特征接近,易被混淆,草地、道路和裸地区域占地面积较小。
利用大疆悟Inspire 1四旋翼无人机采集试验数据。无人机最大飞行高度为500 m,搭载可拆式ZENMUSE X3云台,相机型号为DJI FC350,有效像素为1 240万像素,图片分辨率为4 000×2 250像素,存储格式为jpeg和png。为防止强光照引起大面积阴影,图像采集时间为上午6:00—8:00,飞行高度为100 m。
1.2 数据集建立
原始图像类型为jpg类型,分辨率为4 000×2 250像素,直接使用原始图像参与模型训练会造成显存溢出。因此,将原始图像剪裁成512×512像素,裁剪图像间无重叠,裁剪后图像共1 566幅。训练集和测试集划分比例为7∶3,图像数量分别为1 096和470幅。利用LabelMe标注工具对剪裁后jpg图像进行像素级标注,标注完成后生成相应json文件,然后,使用批处理转换方法将生成的json文件转换为png类型标注图像,标注图像中相同分割类型被标注为同种颜色。图像标注采取人工目视的方式进行数据集图像初标注,并对标注结果进行检查及标注校正,确保标注的准确性和一致性。根据林区地面实际情况,将数据划分为杨树、法国梧桐、银杏、草地、道路及裸地6种类型,部分标注结果如图1所示。由图1可以看出,不同地物类型之间特征差异较小,颜色类似,边缘结构复杂。
1.3 DeepLabV3+语义分割方法
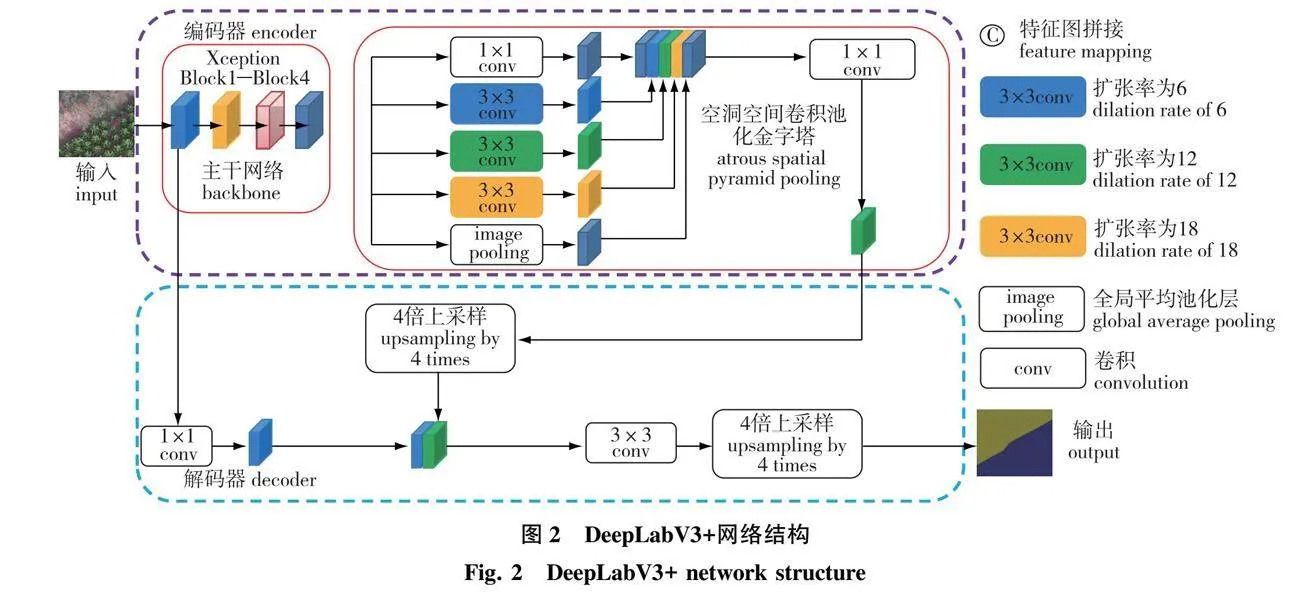
DeepLabV3+由编码器和解码器组成,具体结构如图2所示。编码器首先将输入图像送入主干网络进行特征提取,然后将输出特征图送入空洞空间卷积池化金字塔模块进行加强特征提取。解码器对编码器输出特征图首先进行4倍上采样,然后与主干网络Block1输出特征图进行拼接,以增强特征图空间信息,最后,将拼接特征图进行3×3卷积和4倍上采样,得到最终分割结果。
1.4 Tree-DeepLab语义分割方法
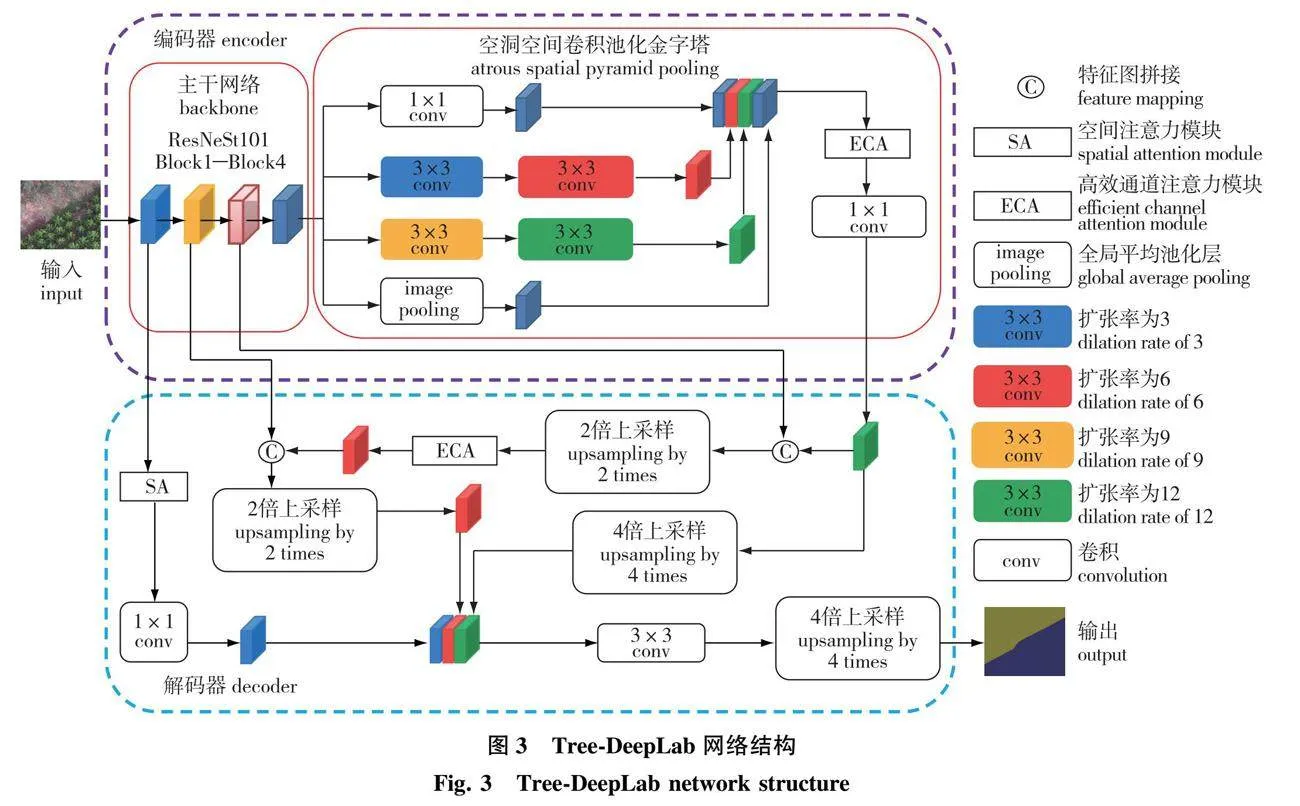
针对复杂无人机林区图像特点,对DeepLabV3+网络做了一系列改进,改进后的Tree-DeepLab网络结构如图3所示。首先,为增强编码器特征提取能力,改进网络将原始编码器的主干网络——Xception网络替换为带有分组注意力机制的ResNeSt101网络。其次,为实现对输入特征图的密集采样,改进网络以串行和并行相结合的形式连接ASPP模块中不同扩张率的空洞卷积,并改变空洞卷积的扩张率组合。然后,为提升解码器的解码能力,增强分割结果空间分布的连续性,解码器增加浅层特征融合分支。为过滤复杂背景信息对分割结果的影响,解码器增加空间注意力模块。最后,为提高模型对特征图中关键通道的利用率,提升分割精度,解码器增加高效通道注意力模块。
1.4.1 主干网络改进
原始DeepLabV3+网络的主干网络是Xception[27],使用了类似ResNet[28]的残差连接结构。由于Xception的网络层数较少,所以语义特征提取能力较差。而无人机林区图像中不同地物类型间特征差异较小,Xception不能准确提取复杂无人机林区图像中的地物特征。
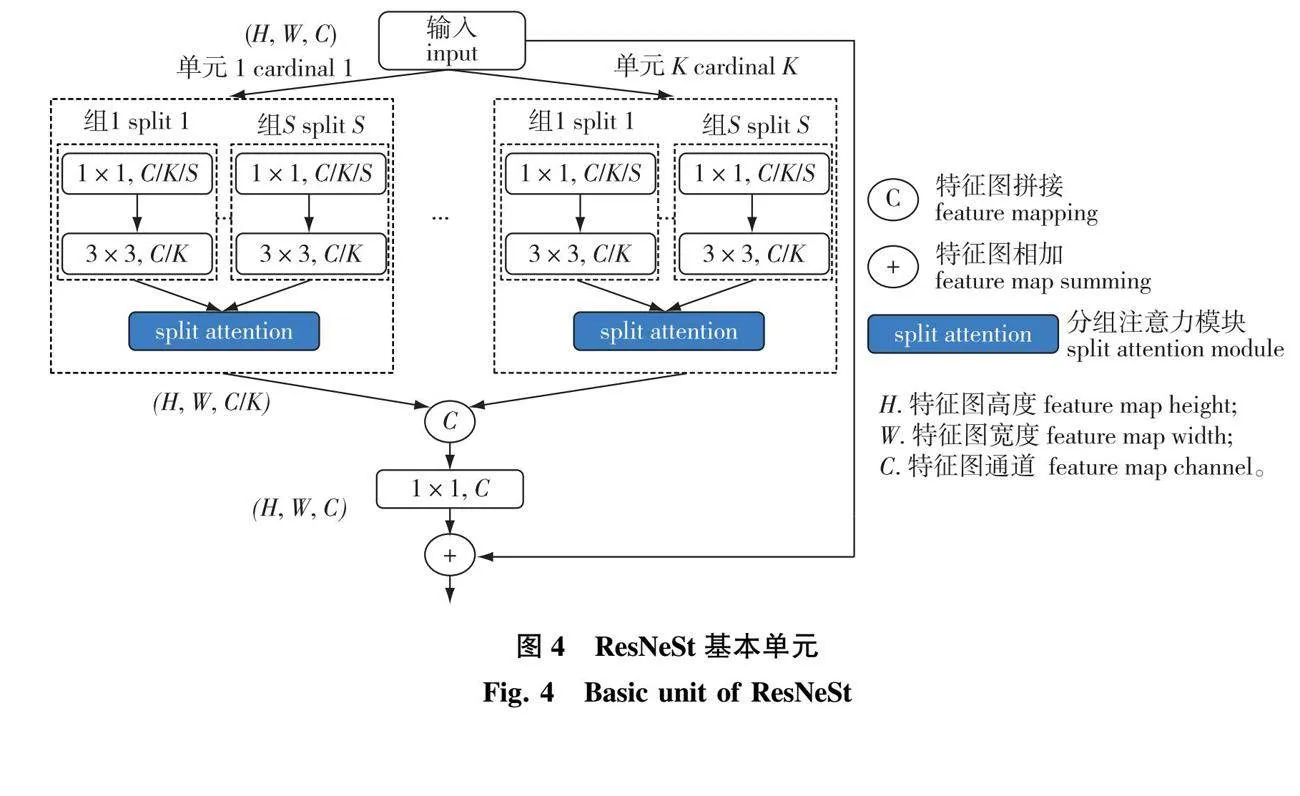
ResNeSt网络残差块单元如图4所示。在通道方向,ResNeSt网络将输入特征图在通道方向划分成K×S个小组,然后赋予每组不同的权重,权重会随着训练轮次的迭代而更新,以突出不同组的重要程度,即分组注意力机制。将K个单元的输出在通道方向进行拼接,得到最终的输出特征图,第K个单元的输出VK计算公式为:
VK=∑Sm=1aKi(F)US(K-1)+i。(1)
式中:F为第m小组输入特征图且F∈RH×W×(CK/S),R为实数集,H为特征图高度,W为特征图宽度,C为特征图通道数,aKm(F)为第m小组注意力权重,US(K-1)+m为第m小组输出特征图。
与Xception网络相比,ResNeSt网络层数更多,且具有分组注意力机制,特征提取能力更强,可有效降低无人机林区图像中不同地物类型间特征差异较小和边缘结构复杂对分割结果的影响。因此将Tree-DeepLabV3+的主干网络替换为ResNeSt。
1.4.2 空洞空间卷积池化金字塔模块改进
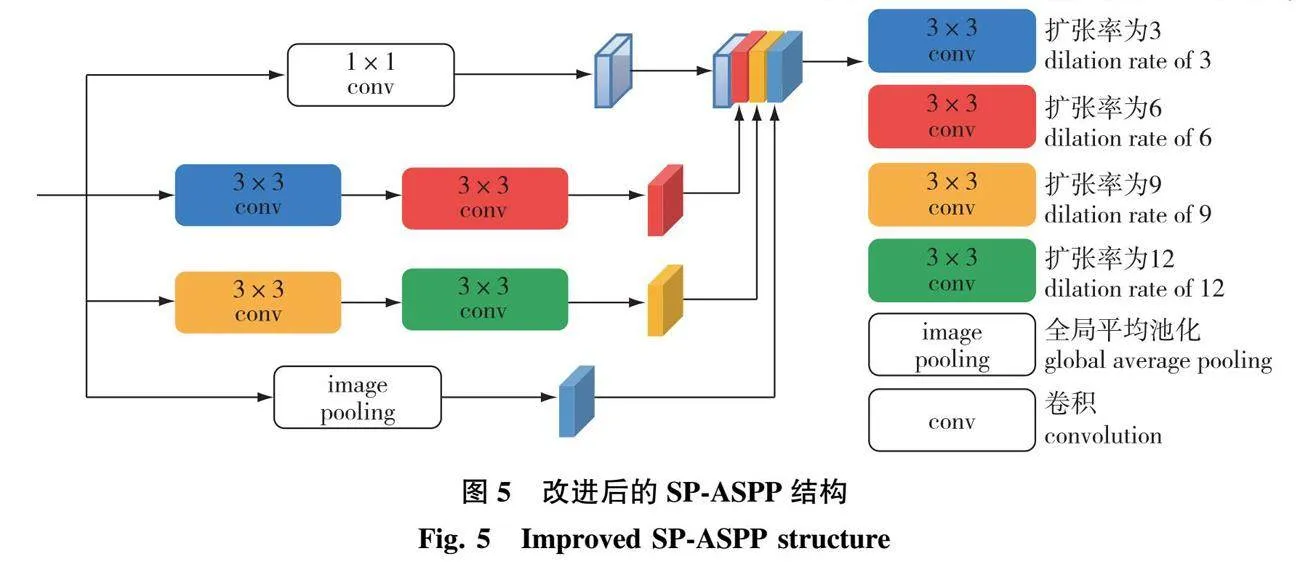
改进后的SP-ASPP模块如图5所示。
数据集中道路、裸地和草地像素数量较少,且经过主干网络特征提取后,输出特征图尺寸变为输入特征图的1/16,造成传入ASPP模块中的道路、裸地和草地像素较为稀疏。为降低像素稀疏对分割结果的影响,本研究对原始ASPP模块进行改进,将ASPP模块中不同扩张率的空洞卷积使用串行(serial)与并行(parallel)相结合的形式进行连接。
不同扩张率的空洞卷积串行连接,可实现对输入特征图的密集采样[29]。密集采样可提高ASPP模块对输入特征图的像素采样量。同时,将SP-ASPP模块中的空洞卷积扩张率组合变为(3,6,9,12),对输入特征图进行更加密集的采样。因此,改进后的SP-ASPP模块可密集采样输入特征图,解决图像中道路、裸地和草地像素较少的问题,降低像素稀疏对分割结果的影响。
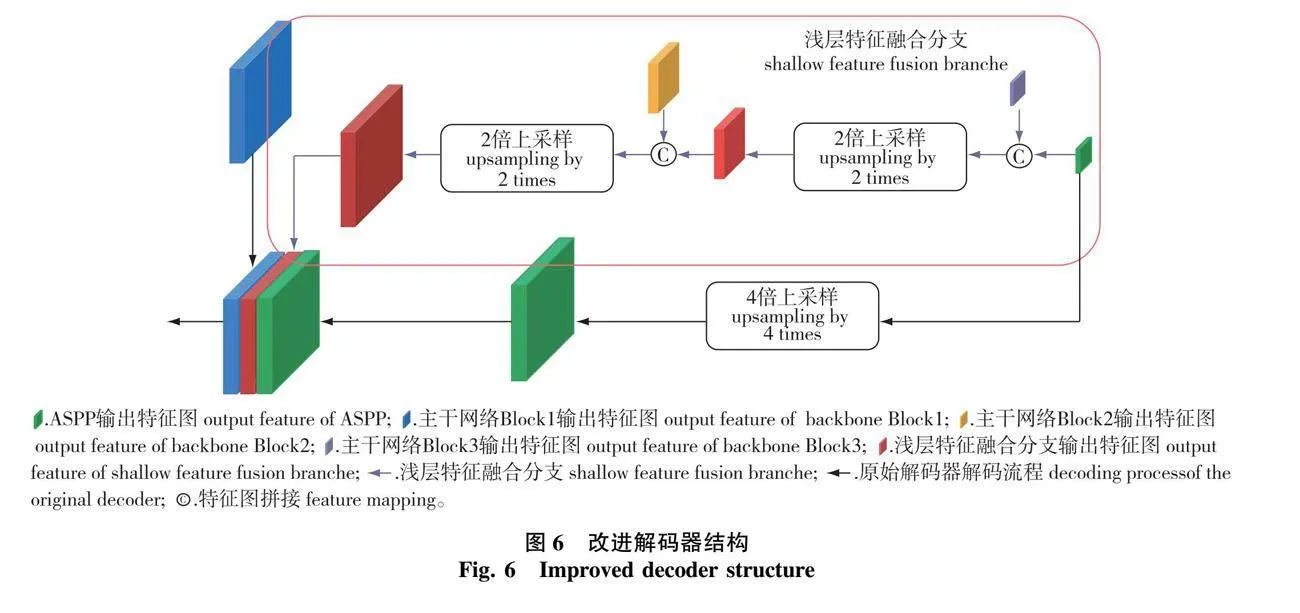
1.4.3 增加浅层特征融合分支
改进解码器结构如图6所示,紫色箭头为浅层特征融合分支,黑色箭头为原始解码器解码流程。
DeepLabV3+解码器主要对编码器深层特征图进行解码,以得到最终分割结果。然而,编码器中的深层特征图空间信息匮乏,浅层特征图富含更多的空间信息。因数据集中不同地物类型间边缘结构较复杂,为使模型在数据集上的分割结果更加连续,在解码器中增加浅层特征融合分支。ASPP模块输出特征图首先与Block3输出特征图拼接,然后采用双线性插值方法进行2倍上采样。其次,上采样得到的特征图与Block2输出特征图拼接,再采用双线性插值方法进行2倍上采样。最终,将浅层特征融合分支输出特征图,经过4倍上采样的ASPP模块输出特征图以及Block1输出特征图拼接,再经过3×3卷积和双线性插值2倍上采样,得到最终分割结果。
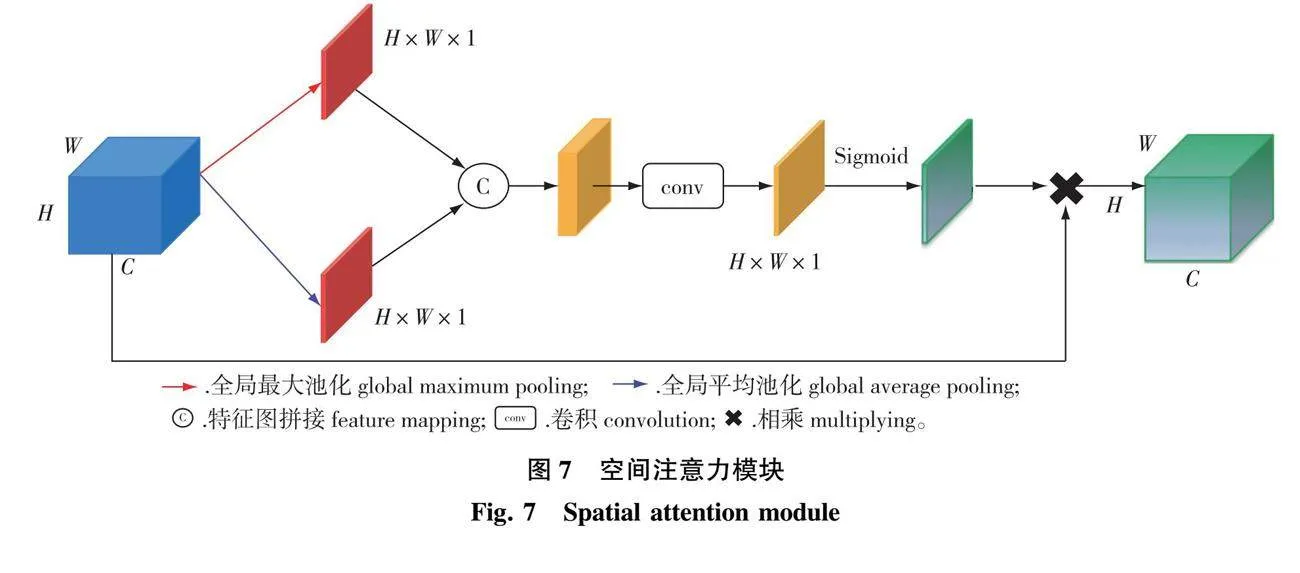
1.4.4 增加空间注意力模块
空间注意力模块如图7所示,输入特征图分别沿通道方向进行全局平均池化和全局最大池化,将所得特征图经过拼接、卷积、Sigmoid函数激活后,得到尺寸为H×W×1的特征图,该特征图中各单元含有不同权重。将所得特征图和输入特征图相乘,得到输出特征图。空间注意力MS(F)计算公式为:
MS(F)=σ[f7×7[IConcat(IAvgPool(F),IMaxPool(F))]]。(2)
式中:σ()为Sigmoid激活函数,F为输入特征图且F∈RH×W×C,f 7×7为7×7卷积,IAvgPool为平均池化操作,IMaxPool为最大池化操作,IConcat为特征图拼接操作。
加入SA模块会使模型对图像中关键特征利用率更高,降低无用背景信息对分割结果的影响。因无人机林区图像中不同地物类型之间特征接近,边缘结构复杂,为使分割结果更加准确,在Tree-DeepLab解码器中加入SA模块,如图3所示。Block1输出的特征图首先传入空间注意力模块,再经过1×1卷积进行通道降维。
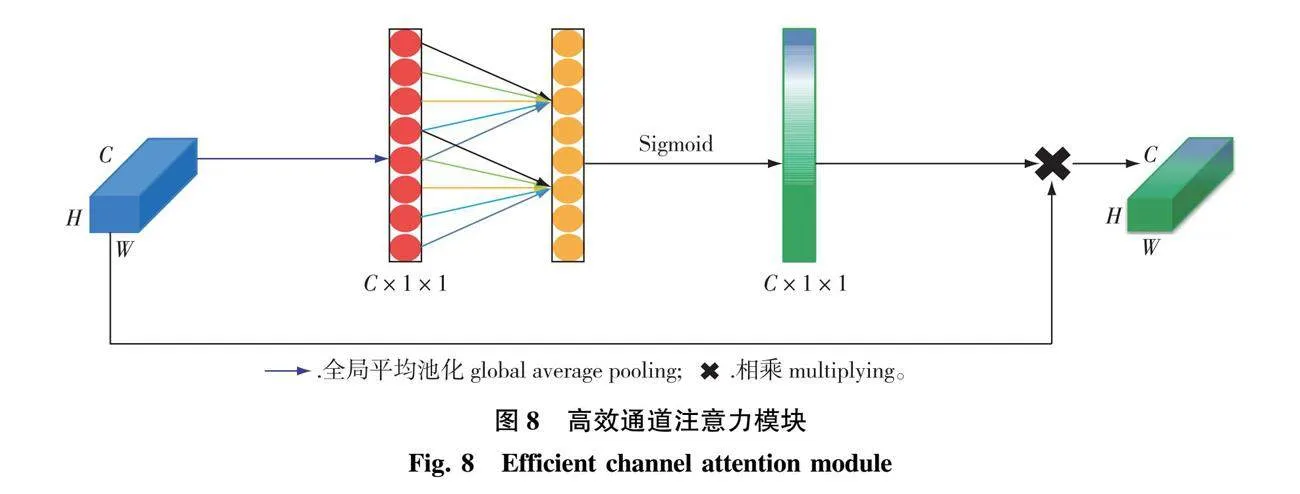
1.4.5 增加高效通道注意力模块
高效通道注意力模块如图8所示。
输入特征图经过全局平均池化,尺寸为C×1×1,所得特征图经过卷积核大小为k的1维卷积以及Sigmoid函数后,得到尺寸为C×1×1的输出特征图,该特征图各单元含有不同的权重。将所得特征图和输入特征图相乘,得到输出特征图。卷积核大小k的计算公式为:
k=log2Cγ+bγodd(3)
式中:C为特征图通道数;γ和b都为超参数,本研究分别设置为2和1;odd为奇数性质,用于筛选出绝对值为奇数的变量。
因Tree-DeepLab模型含有大量通道拼接过程,所以,在Tree-DeepLab中加入ECA模块,以提高模型对关键通道的利用率。如图3所示,一共加入2个ECA模块。首先,ASPP模块输出的特征图,经过ECA模块,再进行1×1卷积;其次,在浅层特征融合分支中,ASPP模块输出特征图和Block3模块输出特征图在拼接、上采样后,经过ECA模块,再和主干网络Block2输出特征图拼接。
1.5 试验环境与评价指标
试验在Ubuntu18.04操作系统、NVIDIA GEFORCE GTX1080Ti(11G)显卡下进行,深度学习框架为Pytorch,对训练数据以随机剪裁的方式进行数据增广。随机剪裁尺寸为480×480像素,试验训练参数批处理大小为4,迭代次数为32 880,优化器为随机梯度下降,初始学习率为0.001,动量为0.9,权重衰减率为0.000 04。
使用平均像素精度(mPA,式中记为ImPA)和平均交并比(mIoU,式中记为ImIoU)作为评价指标对分割结果进行定量评价。mPA和mIoU的计算公式分别为:
ImPA=∑ci=0Pii∑ci=1∑cj=0(Pij+Pii)×100%;(4)
ImIoU=1c+1∑ci=0Pii∑cj=0Pij+∑cj=0Pji-Pii×100%。(5)
式中:c为数据集中分割类别数,i为正类别、j为负类别,Pii为将像素i预测为像素i,Pij为将像素i预测为像素j,Pji为将像素j预测为像素i。
2 结果与分析
2.1 不同ASPP模块试验结果分析
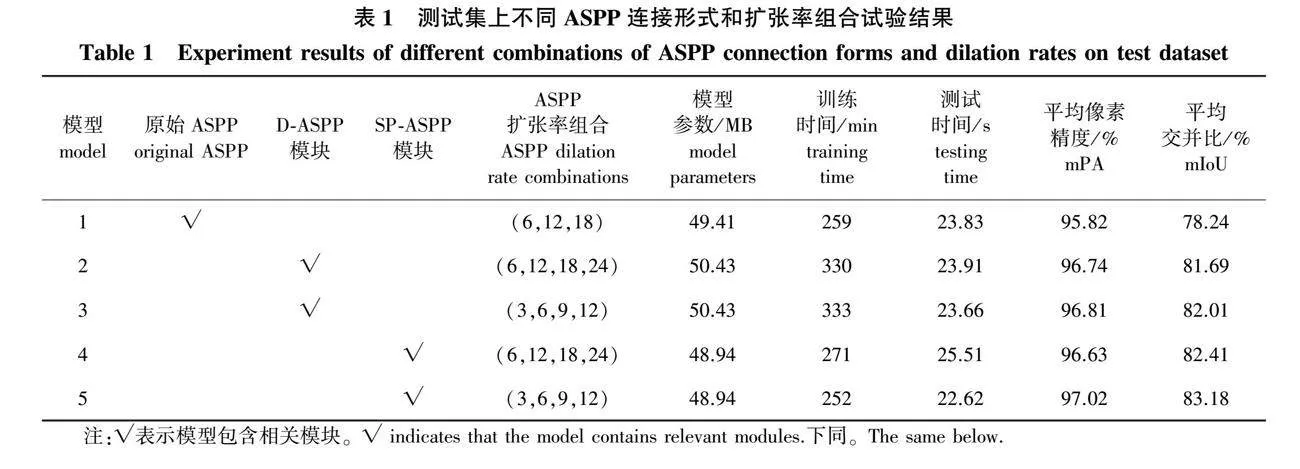
将原始DeepLabV3+的ASPP模块、Tree-DeepLab的SP-ASPP模块和同样具有密集采样原理的DenseASPP[29]模块(以下简称D-ASPP)做多组试验,并在测试数据集上测试,试验结果如表1所示。
试验结果表明:将ASPP模块设置成密集连接的形式以及适当降低ASPP模块扩张率可有效提升模型分割精度。但与SP-ASPP模块相比,D-ASPP模块参数量较高,且加入D-ASPP模块的模型训练时间远大于加入SP-ASPP模块。模型5和模型3相比,ASPP模块扩张率组合相同,模型5的模型参数量比模型3低1.49 MB,训练时间少81 min,测试时间少1.04 s,但mPA提升0.21,mIoU提升1.17个百分点。因此,Tree-DeepLab模型将ASPP设置为SP-ASPP连接形式,并使用(3,6,9,12)扩张率组合。
2.2 DeepLabV3+改进试验结果分析
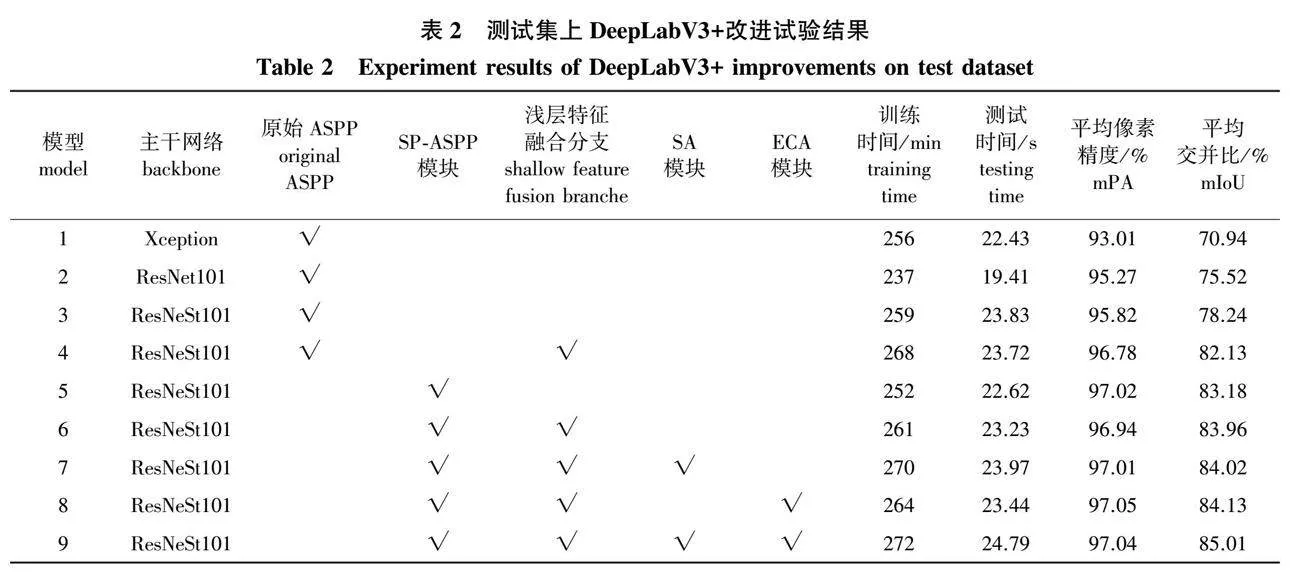
针对DeepLabV3+的编码器和解码器做多组改进,并在测试数据集上测试,试验结果如表2所示。
试验结果表明:将原始DeepLabV3+网络的编码器主干网络Xception网络替换为ResNet101网络得到模型2,模型层数加深,特征提取能力增强,平均像素精度(mPA)提升2.26个百分点,平均交并比(mIoU)提升4.58个百分点。将模型2的编码器主干网络替换为具有分组注意力机制的ResNeSt101网络得到模型3,模型特征提取能力进一步增强,mPA提升0.55个百分点,mIoU提升2.72个百分点。在模型3的解码器中添加浅层特征融合分支得到模型4,模型解码能力提升,mPA提升0.96个百分点,mIoU提升3.89个百分点。同时,将模型4的ASPP设置成SP-ASPP连接形式得到模型6,模型可对输入特征图进行密集采样,mPA提升0.16个百分点,mIoU提升1.83个百分点。在模型6中加入空间注意力机制(SA)和高效通道注意力机制(ECA)得到模型9,改进模型可自适应提取输入特征图的特征,提高关键特征利用率,mPA提升0.10个百分点,mIoU提升1.05个百分点。总之,当把原始DeepLabV3+模型的主干网络Xception替换为ResNeSt101,ASPP结构更改为SP-ASPP结构,解码器加入浅层特征融合分支和SA、ECA注意力模块后,得到的Tree-DeepLab,相较于原始DeepLabV3+,其训练时间仅增加16 min,测试时间仅增加2.36 s,但mPA提升4.03个百分点,mIoU提升14.07个百分点。
2.3 不同语义分割模型试验结果分析
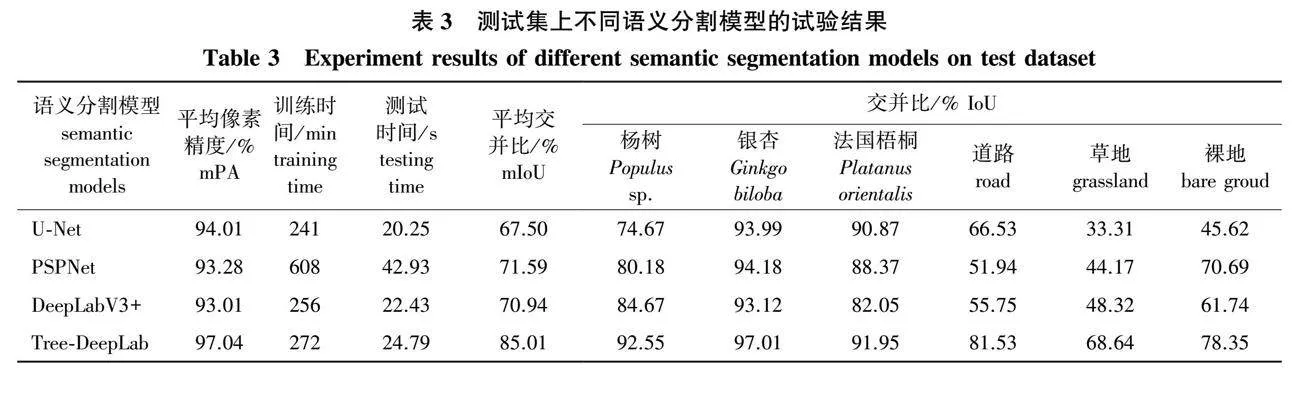
为验证本次算法的有效性,将DeepLabV3+、U-Net、PSPNet语义分割模型和Tree-DeepLab语义分割模型同时在数据集上进行训练和测试,并对分割结果进行比较,各模型试验训练参数保持一致,试验结果如表3所示。
试验结果表明:U-Net、PSPNet和DeepLabV3+网络的mPA均低于95%,mIoU均低于80%。其中,由最能体现语义分割精度的mIoU指标可知,U-Net网络表现最差,mIoU仅为67.50%,且草地和裸地的分割效果较差。相较于其他3种语义分割模型,改进的Tree-DeepLab模型表现最好,训练时间和测试时间远低于PSPNet,并且与U-Net、DeepLabV3+接近,但mPA和mIoU都有大幅度提升,mPA达到97.04%,mIoU达到85.01%,且3种不同的树种(杨树、银杏、法国梧桐)类型的mIoU均高于90%。
2.4 分割结果分析
U-Net、PSPNet、DeepLabV3+和Tree-DeepLab语义分割模型的部分分割结果如图9所示。在U-Net网络的分割结果中,不同类别的分割准确度较低,分割边界不清晰,尤其对裸地和草地的分割效果很差,这可能与U-Net的网络结构有关。U-Net网络编码器各层的输出结果直接连接到同层的解码器,模型不能充分利用深浅层语义信息,使模型语义分割精度较低。PSPNet网络的分割效果是可以被接受的,但该模型分割结果中的道路不连续,易与周围区域像素混淆。PSPNet的金字塔池化模块虽可捕获图像中的多尺度信息,但易丢失图像的细节信息。DeepLabV3+网络的分割结果中,部分分割类别间存在毛边现象。草地、银杏区域分割效果较差,因两者颜色特征接近,故错分率较高。DeepLabV3+网络对像素稀疏的道路区域分割效果较差,说明该网络的编码器特征提取能力较差,易丢失图像中的细节信息。Tree-DeepLab网络分割效果最好,能精准分割图像中容易错分的道路、草地和裸地,并能准确分割图像中的杨树、银杏和法国梧桐区域,分割结果边界连续,误分、错分较少。
3 讨 论
无人机林区图像存在不同树种间特征接近、边缘结构复杂以及部分地物类型像素较稀疏等问题,给无人机林区图像分割研究带来一定挑战。李丹等[30]研究的基于FCM和分水岭的无人机林区图像分割方法,虽可精准分割图像中的樟子松(Pinus sylvestris var. mongolica)树冠,但分割效果和特征参数的选取相关,模型自适应能力较差。刘旭光等[31]研究的基于多尺度分割的方法,虽可有效分割无人机林区图像中的植被区域,但研究中设置的分割类别较少,与实际的林区植被类别数量差异过大,使分割结果具有一定的局限性。为此,本研究自制了无人机林区图像数据集,该数据集包含了法国梧桐、银杏、杨树3种不同的树种以及草地、道路和裸地3类典型的非林木地物类型,使试验结果具有更好的通用性。在此数据集基础上,本研究提出了无人机林区图像地物分割模型Tree-DeepLab,该模型以DeepLabV3+为基础,针对无人机林区图像特点进行了优化,并在自制数据集上进行多次训练,以提高模型的自适应能力。
首先,为增强模型特征提取能力,本研究将DeepLabV3+模型主干网络替换为具有分组注意力机制的ResNeSt101,并且在模型中添加空间注意力模块和高效通道注意力模块,以解决无人机林区图像中不同树种间特征较接近的问题。其次,为使分割结果空间分布更加连续,本研究在DeepLabV3+模型中添加浅层特征融合分支,以解决无人机林区图像中不同地物间边缘结构复杂的问题。最后,为实现对输入特征图的密集采样,本研究将DeepLabV3+网络中的原始空洞空间卷积池化金字塔模块中不同扩张率的空洞卷积设计成串并行相结合的连接形式,同时降低空洞卷积扩张率,以解决无人机林区图像中部分地物类型像素较稀疏的问题。
但值得注意的是,不同季节的无人机林区图像特征存在一定差异性,比如秋冬季节林区树木叶子、草地颜色会变成黄色,部分树木存在落叶现象。此时,再使用Tree-DeepLab分割无人机林区图像,分割效果可能较差。因此,后续将采集更多季节的无人机林区图像,以丰富本研究数据集,提升Tree-DeepLab模型泛化能力。同时,后续将在模型大小、分割速度和分割精度等方面继续优化,使模型更轻量化的同时拥有更好的分割性能。
4 结 论
1)针对无人机林区图像特点,本研究对DeepLabV3+做了一系列试验和改进,包括更换主干网络、增加注意力模块、添加浅层特征融合分支和更改空洞空间卷积池化金字塔模块结构,得到无人机林区图像地物分割模型Tree-DeepLab。
2)本研究构建的Tree-DeepLab模型对草地、道路、裸地、杨树、银杏和法国梧桐的语义分割准确率均有明显提升,平均像素精度达到97.04%,平均交并比达到85.01%。相较于原始DeepLabV3+模型,Tree-DeepLab模型训练时间和测试时间仅小幅度增加,但平均像素精度提高4.03个百分点,平均交并比提高14.07个百分点,并优于经典语义分割模型U-Net和PSPNet,能够实现复杂无人机林区图像的精准分割。
参考文献(reference):
[1]王静, 高建中. 林地地块特征对农户林业生产效率的影响[J]. 林业经济问题, 2021, 41(6): 577-582. WANG J, GAO J Z. The effects of the characteristics of forest land parcels on farmers’ forestry production efficiency[J]. News For Econ, 2021, 41(6): 577-582. DOI: 10.16832/j.cnki.1005-9709.20210072.
[2]DALPONTE M, RKA H O, GOBAKKEN T, et al. Tree species classification in boreal forests with hyperspectral data[J]. IEEE Trans Geosci Remote Sens, 2013, 51(5): 2632-2645. DOI: 10.1109/TGRS.2012.2216272.
[3]BLANCO S R, HERAS D B, ARGELLO F. Texture extraction techniques for the classification of vegetation species in hyperspectral imagery: bag of words approach based on superpixels[J]. Remote Sens, 2020, 12(16): 2633. DOI: 10.3390/rs12162633.
[4]THANH NOI P, KAPPAS M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using sentinel-2 imagery[J]. Sensors, 2017, 18(1): 18. DOI: 10.3390/s18010018.
[5]YUAN Y, HU X Y. Random forest and objected-based classification for forest pest extraction from UAV aerial imagery[J]. Int Arch Photogramm Remote Sens Spatial Inf Sci, 2016, XLI-B1: 1093-1098. DOI: 10.5194/isprs-archives-xli-b1-1093-2016.
[6]赵庆展, 江萍, 王学文, 等. 基于无人机高光谱遥感影像的防护林树种分类[J]. 农业机械学报, 2021, 52(11): 190-199. ZHAO Q Z, JIANG P, WANG X W, et al. Classification of protection forest tree species based on UAV hyperspectral data[J]. Trans Chin Soc Agric Mach, 2021, 52(11): 190-199. DOI: 10.6041/j.issn.1000-1298.2021.11.020.
[7]戴鹏钦, 丁丽霞, 刘丽娟, 等. 基于FCN的无人机可见光影像树种分类[J]. 激光与光电子学进展, 2020, 57(10): 36-45. DAI P Q, DING L X, LIU L J, et al. Tree species identification based on FCN using the visible images obtained from an unmanned aerial vehicle[J]. Laser Optoelectron Prog, 2020, 57(10): 36-45. DOI: 10.3788/LOP57.101001.
[8]张军国, 冯文钊, 胡春鹤, 等. 无人机航拍林业虫害图像分割复合梯度分水岭算法[J]. 农业工程学报, 2017, 33(14): 93-99. ZHANG J G, FENG W Z, HU C H, et al. Image segmentation method for forestry unmanned aerial vehicle pest monitoring based on composite gradient watershed algorithm[J]. Trans Chin Soc Agric Eng, 2017, 33(14): 93-99. DOI: 10.11975/j.issn.1002-6819.2017.14.013.
[9]张增, 王兵, 伍小洁, 等. 无人机森林火灾监测中火情检测方法研究[J]. 遥感信息, 2015, 30(1): 107-110, 124. ZHANG Z, WANG B, WU X J, et al. An algorithm of forest fire detection based on UAV remote sensing[J]. Remote Sens Inf, 2015, 30(1): 107-110, 124. DOI: 10.3969/j.issn.1000-3177.2015.01.018.
[10]刘文萍, 仲亭玉, 宋以宁. 基于无人机图像分析的树木胸径预测[J]. 农业工程学报, 2017, 33(21): 99-104. LIU W P, ZHONG T Y, SONG Y N. Prediction of trees diameter at breast height based on unmanned aerial vehicle image analysis[J]. Trans Chin Soc Agric Eng, 2017, 33(21): 99-104. DOI: 10.11975/j.issn.1002-6819.2017.21.012.
[11]MARTINS J, JUNIOR J M, MENEZES G, et al. Image segmentation and classification with SLIC superpixel and convolutional neural network in forest context[C]//IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium. Yokohama, Japan: IEEE, 2019: 6543-6546. DOI: 10.1109/IGARSS.2019.8898969.
[12]LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 3431-3440. DOI: 10.1109/CVPR.2015.7298965.
[13]RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241. DOI: 10.1007/978-3-319-24574-4_28.
[14]ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 6230-6239. DOI: 10.1109/CVPR.2017.660.
[15]LIN G S, MILAN A, SHEN C H, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 5168-5177. DOI: 10.1109/CVPR.2017.549.
[16]CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[DB/OL]. (2014-09-14)[2022-05-25]. https:// arXiv.org/abs/1412.7062. DOI: 10.48550/arXiv.1412.7062.
[17]CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Trans Pattern Anal Mach Intell, 2018, 40(4): 834-848. DOI: 10.1109/TPAMI.2017.2699184.
[18]CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[DB/OL]. (2017-07-19)[2022-05-05]. https://arXiv.org/abs/1706.05587. DOI: 10.48550/arXiv.1706.05587.
[19]CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision. Cham: Springer, 2018: 833-851. DOI: 10.1007/978-3-030-01234-2_49.
[20]韩蕊, 慕涛阳, 赵伟, 等. 基于无人机多光谱影像的柑橘树冠分割方法研究[J]. 林业工程学报, 2021, 6(5): 147-153. HAN R, MU T Y, ZHAO W, et al. Research on citrus canopy segmentation method based on UAV multispectral image[J]. Journal of Forestry Engineering, 2021, 6(5): 147-153. DOI: 10.13360/j.issn.2096-1359.202011021.
[21]刘文定, 田洪宝, 谢将剑, 等. 基于全卷积神经网络的林区航拍图像虫害区域识别方法[J]. 农业机械学报, 2019, 50(3): 179-185. LIU W D, TIAN H B, XIE J J, et al. Identification methods for forest pest areas of UAV aerial photography based on fully convolutional networks[J]. Trans Chin Soc Agric Mach, 2019, 50(3): 179-185. DOI: 10.6041/j.issn.1000-1298.2019.03.019.
[22]徐辉, 祝玉华, 甄彤, 等. 深度神经网络图像语义分割方法综述[J]. 计算机科学与探索, 2021, 15(1): 47-59. XU H, ZHU Y H, ZHEN T, et al. Survey of image semantic segmentation methods based on deep neural network[J]. J Front Comput Sci Technol, 2021, 15(1): 47-59. DOI: 10.3778/j.issn.1673-9418.2004039.
[23]HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7132-7141. DOI: 10.1109/CVPR.2018.00745.
[24]WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3-19. DOI: 10.1007/978-3-030-01234-2_1.
[25]WANG Q L, WU B G, ZHU P F, et al. ECA-net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020: 11531-11539. DOI: 10.1109/CVPR42600.2020.01155.
[26]ZHANG H, WU C R, ZHANG Z Y, et al. ResNeSt: split-attention networks[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New Orleans, LA, USA: IEEE, 2022: 2735-2745. DOI: 10.1109/CVPRW56347.2022.00309.
[27]CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 1800-1807. DOI: 10.1109/CVPR.2017.195.
[28]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 770-778. DOI: 10.1109/CVPR.2016.90.
[29]YANG M K, YU K, ZHANG C, et al. DenseASPP for semantic segmentation in street scenes[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 3684-3692. DOI: 10.1109/CVPR.2018.00388.
[30]李丹, 张俊杰, 赵梦溪. 基于FCM和分水岭算法的无人机影像中林分因子提取[J]. 林业科学, 2019, 55(5): 180-187. LI D, ZHANG J J, ZHAO M X. Extraction of stand factors in UAV image based on FCM and watershed algorithm[J]. Sci Silvae Sin, 2019, 55(5): 180-187. DOI: 10.11707/j.1001-7488.20190520.
[31]刘旭光, 肖啸, 兰玉彬, 等. 应用可见光遥感影像的林区植被分割方法[J]. 东北林业大学学报, 2023, 51(4): 62-67. LIU X G, XIAO X, LAN Y B, et al. Forest vegetation segmentation method with UAV visible light remote sensing images[J]. Journal of Northeast Foresrty University, 2023, 51(4): 62-67. DOI: 10.13759/j.cnki.dlxb.2023.04.008.
(责任编辑 李燕文)
收稿日期Received:2022-09-24""" 修回日期Accepted:2022-11-01
基金项目:国家林业和草原局重大应急科技项目(ZD202001);国家重点研发计划(2021YFD1400900)。
第一作者:赵玉刚(15621377528@163.com)。
*通信作者:刘文萍(wendyl@vip.163.com),教授。
引文格式:赵玉刚,刘文萍,周焱,等.
基于注意力机制和改进DeepLabV3+的无人机林区图像地物分割方法[J]. 南京林业大学学报(自然科学版),2024,48(4):93-103.
ZHAO Y G, LIU W P, ZHOU Y, et al.
UAV forestry land-cover image segmentation method based on attention mechanism and improved DeepLabV3+[J]. Journal of Nanjing Forestry University (Natural Sciences Edition),2024,48(4):93-103.
DOI:10.12302/j.issn.1000-2006.202209055.
猜你喜欢
英语世界(2023年12期)2023-12-28 03:36:00
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
红土地(2018年8期)2018-09-26 03:19:16
现代园艺(2018年2期)2018-03-15 08:00:01
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
