
改进RepSurf的点云语义分割
2024-09-12 00:00:00高学壮禹龙田生伟伊洋洋张波罗培新
现代电子技术 2024年5期


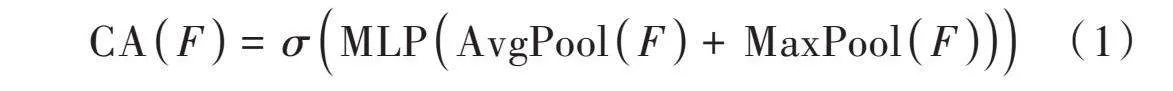



摘" 要: 点云分析一直以来都是一个具有挑战性的问题,主要是因为点云数据的非结构化特性所致。为了解决这个问题,RepSurf基于PointNet++提出了一种多曲面表示局部点云特征的方法。然而,RepSurf中的集合抽象层仅通过一个MLP学习局部特征,这远远不够。为此,引入了两个模块,即倒置残差模块和注意力模块。这两个简单但有效的即插即用模块可以更好地学习局部特征。倒置残差模块通过添加更多的MLP层,丰富了特征提取过程;而注意力模块则包括通道注意力和空间注意力,更加关注关键点特征的学习,使得学习到的特征更具代表性。在公共基准数据集S3DIS上评估了文中的方法,在语义分割任务中mIoU指标达到72.3%,比RepSurf高出2.5%。
关键词: 点云; 语义分割; 倒置残差; 注意力; RepSurf; MLP
中图分类号: TN919⁃34; TP391.41" " " " " " " " " " 文献标识码: A" " " " " " " " "文章编号: 1004⁃373X(2024)05⁃0143⁃05
Point cloud semantic segmentation based on improved RepSurf
GAO Xuezhuang1, YU Long1, TIAN Shengwei1, YI Yangyang1, ZHANG Bo2, LUO Peixin3
(1. School of Software, Xinjiang University, Urumqi 830000, China; 2. Xinjiang Zichang Software Co., Ltd., Urumqi 830000, China;
3. China Railway Urumqi Bureau Group Co., Ltd., Urumqi 830000, China)
Abstract: Due to the unstructured nature of point cloud data, point cloud analysis has always been challengeable. In view of this, RepSurf proposes an Umbrella RepSurf method for representing local point cloud features based on PointNet++. However, the set abstraction layer in RepSurf learns local features by only one MLP (multilayer perceptron), which is far from sufficient. Therefore, two modules, namely the inverted residual module and the attention module, are proposed. These two simple but effective plug⁃and⁃play modules can be used to learn the local features better. The inverted residual module enriches the feature extraction process by adding more MLP layers, while the attention module, including channel attention and spatial attention, pays more attention to the learning of key point features, which makes the learned features more representative. The proposed approach is evaluated on the public benchmark dataset S3DIS. It achieves an mIoU of 72.3% in the task of semantic segmentation, which is 2.5% higher than that of RepSurf.
Keywords: point cloud; semantic segmentation; inverted residual; attention; RepSurf; MLP
0" 引" 言
点云数据因其在自动驾驶、增强现实和机器人等各种应用中的优势而引起了相当大的关注。然而,直接从原始点云中学习存在着一些关键挑战。尽管深度卷积网络在结构化的2D计算机视觉任务中表现出了出色的性能,但它们无法直接应用于这种非结构化的数据。
为了处理不规则的点云数据,PointNet[1]这一开创性工作采用了逐点多层感知器(MLP),通过独立学习每个点,并利用对称函数来获取全局信息。PointNet++[2]进一步引入了集合抽象来捕获点云的局部信息。然而,这两种方法都是基于独立点的学习,并没有充分考虑到局部形状感知的问题。
RepSurf[3]基于PointNet++提出了一种多曲面方法,用于表示局部点云特征,然而在S3DIS(Stanford Largescale 3D Indoor Spaces)这样的大规模数据集上,RepSurf中的集合抽象仅通过一个MLP层学习局部特征是远远不够的。观察到当前流行的点云分析模型比原始网络使用了注意力模块和更多的MLP层。因此,将注意力模块和更多的MLP层有效地引入RepSurf是一个值得研究的课题。本文基于RepSurf,改进了数据增强和优化技术,并添加了倒残差模块和注意力残差模块,在S3DIS数据集上取得了出色的效果。
本文主要有以下改进:
1) 注意力残差模块。在集合抽象层的特征学习中引入了注意力残差模块,包括通道注意力模块和空间注意力模块,在S3DIS数据集的语义分割任务中,mIoU指标提升了1.01%。
2) 倒置残差模块。添加了倒置残差模块,将其添加到集合抽象层中的MLP后。在S3DIS数据集的语义分割任务中,mIoU指标提升了1.75%。
3) 改进数据增强和优化技术。本文对数据增强和训练策略进行了研究,通过使用旋转增强数据和余弦衰减的学习率,在S3DIS数据集的语义分割任务中,mIoU指标提升了0.69%。
1" 相关工作
1.1" 基于多视图的方法
基于多视图的方法通常将不同角度的点云投影到二维平面上,然后将这些特征进行融合以得到全局表示。MVCNN[4]是一项开创性的工作,它简单地将多视图特征进行最大池化操作,以获得一个全局描述符。然而,最大池化只保留特定视图中的最大元素,导致了信息的丢失。MHBN[5]则考虑到补丁之间的相似性度量,采用双线性池化来获取全局表示。文献[6]首次利用关系网络和一组视图之间的相互关系,将这些视图聚合起来,获得具有区别性的3D对象表示。View⁃GCN[7]中使用了有向图,将多个视图视为图中的节点。核心层由局部图卷积、非局部消息传递和选择性视图采样组成。最后,将各层级的最大池化节点特征串联起来,形成全局形状描述符。当三维视图被投影到二维平面上时,其几何信息会丢失,如何有效地整合不同视图的特征仍然是一个具有挑战性的问题。
1.2" 基于体素的方法
VoxNet[8]将点云表示为体积元素的网格,实现了相对快速的三维物体识别。3D ShapeNet[9]将三维样本的形状表示为三维体素二元变量的概率分布数据,并利用3D⁃CNN获取三维样本的全局特征表示。PointGrid[10]利用3D⁃CNN处理在网格单元中采样固定数量的点,实现高效的点云处理。然而,这些方法在平衡性能和计算成本方面存在一定的挑战,因为随着分辨率的增加,计算成本也会增加。为了解决这个问题,研究人员引入了更紧凑的层次结构(例如树结构)以降低计算成本。这些方法试图通过在点云数据上创建层次结构并将复杂的计算任务转化为层次结构上的操作来提高计算效率。然而,这些方法在平衡性能和计算成本方面仍然面临一些挑战。
1.3" 基于点的方法
PointNet[1]是点云处理领域的一个重要里程碑,然而,其忽略了点云中每个点之间的局部结构特征关联。为了解决这个问题,PointNet++[2]将点云数据划分为多个不同的邻域,并利用每个局部邻域的层次结构学习几何特征,最后将它们聚合为全局特征表示。Mo⁃Net[11]使用有限矩集作为输入。PATS[12]利用相邻点的绝对位置和相对位置表示每个点,并使用GSA捕获点之间的关系,最后使用GSS层学习层次特征。PointWeb[13]利用AFA模块根据局部邻域的上下文信息优化点的表示。SRINet[14]提出了点投影特征来获取点云的旋转不变表示,然后使用基于点的骨干网络和基于图的网络分别提取全局特征和局部特征。RepSurf[3]基于PointNet++提出了三角形和多曲面表示法,用于表示局部点云特征。然而,RepSurf中的集合抽象层仅通过一个MLP学习局部特征,这远远不够。为此,添加了两个模块,即倒置残差模块和注意力模块。
2" 方" 法
在本节中将介绍如何改进RepSurf[3](见图1,改进部分用黑色实线框标识)。
本文研究主要集中在引入注意力残差模块、添加倒置残差模块、改进数据增强和优化技术三个方面。
2.1" 注意力残差模块
2.1.1" 通道注意力
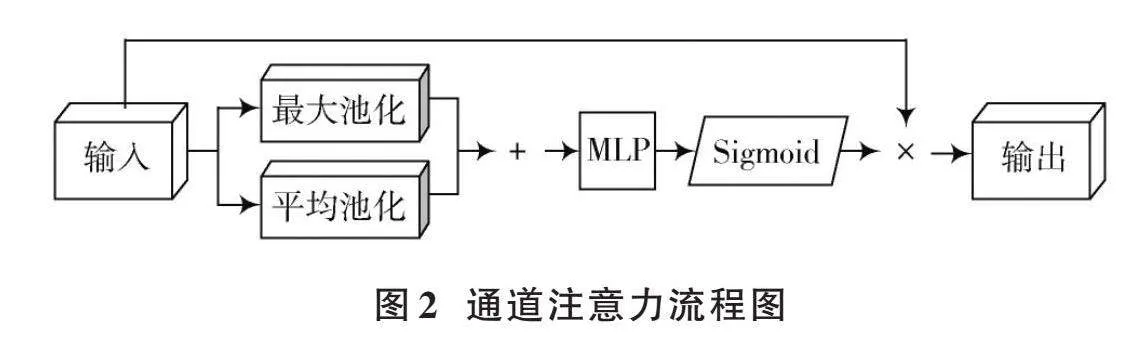
利用特征通道间关系生成通道注意力图。由于每个通道都被视为一个特征检测器,因此通道注意力关注的是输入点云中的“什么”是有意义的。为了高效计算通道注意力,对输入特征的空间维度进行了压缩。在对空间信息进行聚合时,同时使用了平均池化和最大池化。通道注意力流程图如图2所示。
首先使用平均池化和最大池化操作来聚合特征映射的空间信息,得到两个不同的空间上下文描述符:平均池化特征和最大池化特征;然后,将这两个池化的结果在通道维度上相加,将它们传递到共享网络中,生成本文的通道注意力图,它的形状为1×[C]×1,其中[C]表示通道的数量;最后,将通道注意力图输入Sigmoid函数进行映射,使其取值范围在0~1之间。通道注意力的计算过程如下所示:
[CAF=σMLPAvgPoolF+MaxPoolF] (1)
式中[σ]表示Sigmoid函数。共享网络由多层感知器(MLP)和一个隐藏层组成。为了减少参数的开销,隐藏层的激活大小被设置为[Cr],其中[r]是减少率。
2.1.2" 空间注意力
利用特征之间的空间关系来生成空间注意力。与通道注意力不同,空间注意力关注的是信息的位置,是对通道注意力的补充。为了计算空间注意力,首先在通道维度上应用平均池化和最大池化操作,并将它们连接起来生成一个有效的特征描述符。通过在通道维度上应用池化操作,可以有效地突出显示信息区域。然后,应用一个多层感知器层在连接的特征描述符上生成一个空间注意力图。空间注意力流程图如图3所示。
使用两个池化操作来聚合特征图的通道信息,生成两个2D图:avg∈[M]×1×nsample和max∈[M]×1×nsample。每个图表示通道上的平均池化特征和最大池化特征,然后它们经过一个标准的MLP层,最后,将通道注意力输入Sigmoid函数以将其映射到0~1之间的范围。空间注意力的计算如下所示:
[SAF=σMLPAvgPoolF,MaxPoolF] (2)
式中[σ]表示Sigmoid函数。
2.1.3" 注意力顺序
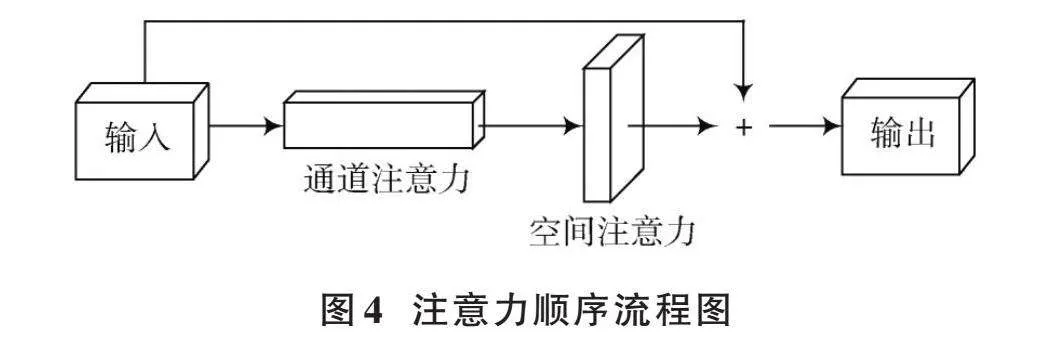
对于给定的输入点云和两个注意力模块,即通道注意力和空间注意力,它们分别关注点云的“什么”和“在哪里”。考虑到这一点,按顺序将这两个模块放置。通过实验证明,将通道注意力放在前面可以获得更好的结果(详见3.2.3节)。此外,还在输入和输出之间添加了一个残差连接,以解决梯度消失的问题,特别是在网络深度增加时。注意力顺序流程图如图4所示。
2.2" 倒置残差模块
RepSurf是一个相对较小的网络,其编码器在分割上只包含4个阶段。每个阶段中仅通过一个MLP层学习局部特征是远远不够的。观察到当前流行的点云分析模型比原始网络使用了更多的MLP层,因此,将更多的MLP层有效地引入RepSurf[3]是一个值得研究的课题。
将倒置残差模块(见图1)添加到集合抽象层中MLP的后面,通过倒瓶颈设计,将MLP的输出通道扩展了4倍,以丰富特征提取的能力,然后再将通道数压缩回原来的数量。同时,还在输入和输出之间添加了一个残差连接,以缓解梯度消失的问题,特别是在网络深度增加时。
通过实验证明,添加倒置残差模块可以显著提高性能(详见3.2.4节)。
2.3" 改进数据增强和训练策略
2.3.1" 数据增强
数据增强是提高神经网络性能的重要策略之一。以RepSurf[3]为基线开始研究,使用原始数据增强对其进行训练。在实验中,发现通过添加数据随机旋转,在S3DIS数据集上进行语义分割任务时取得了显著的改善效果,mIoU指标提升了0.38%。
2.3.2" 优化技术
优化技术对于神经网络的性能至关重要,其中包括损失函数、优化器、学习率调度器和超参数的选择。在RepSurf[3]的实验中,使用了相同的优化技术,包括交叉熵损失、AdamW优化器、指数学习率衰减和相同的超参数。以RepSurf为基线开始研究,使用原始优化技术对其进行训练。通过实验,发现将指数学习率衰减替换为余弦衰减在S3DIS[15]数据集的语义分割任务中取得了显著的改善效果,mIoU指标提升了0.31%。
3" 实" 验
采用在S3DIS[15]语义分割任务评估本文模型,S3DIS是一个具有挑战性的数据集,由6个大型室内区域、271个房间和13个语义类别组成。此外,还进行消融研究,以评估设计模块的有效性。
3.1" 对比实验
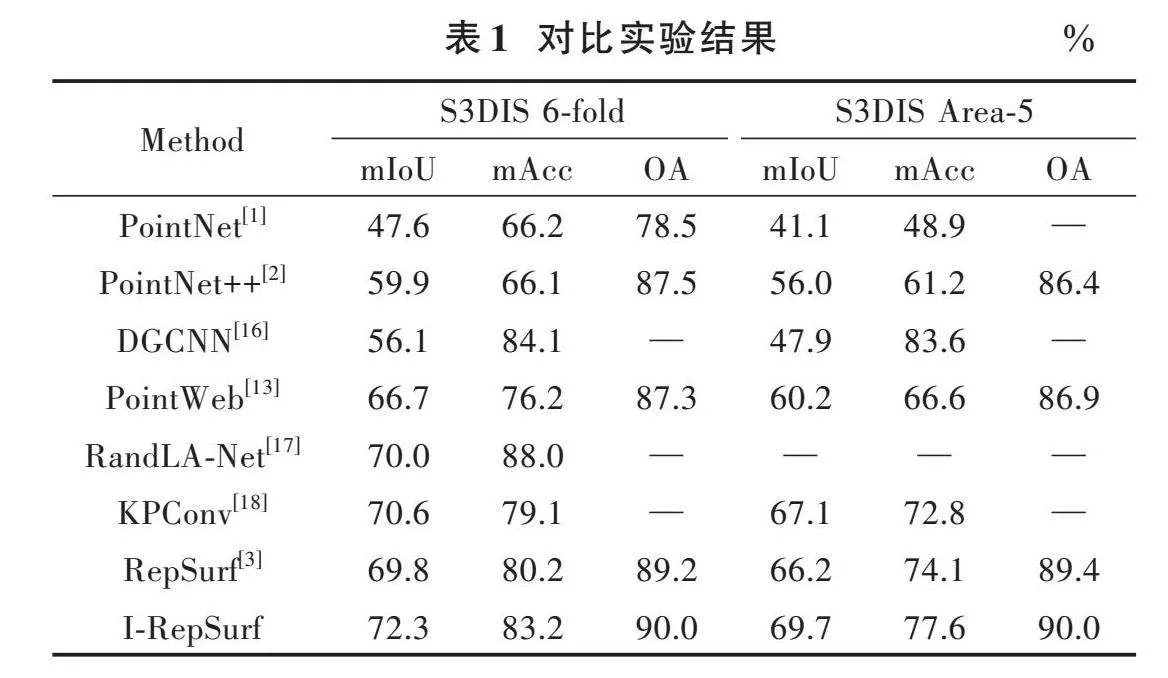
实验设置:使用AdamW优化器的交叉熵损失函数训练,初始学习速率[lr]=0.006,余弦衰减,批量大小为2,GPU为16 GB的V100。对比实验如表1所示,其中RepSurf指标是本文复现的结果。
表1报告了S3DIS语义分割任务的6⁃fold和Area⁃5结果,I⁃RepSurf超越了目前主流模型。在Area⁃5任务中,I⁃RepSurf相比RepSurf,在平均交并比(mIoU)、平均精度(mAcc)和总体精度(OA)方面分别提高了3.5%、3.5%和0.6%。
3.2" 消融实验
在S3DIS[15]语义分割任务上对本文方法的一些重要设计进行了深入的探索。
3.2.1" 模块消融实验
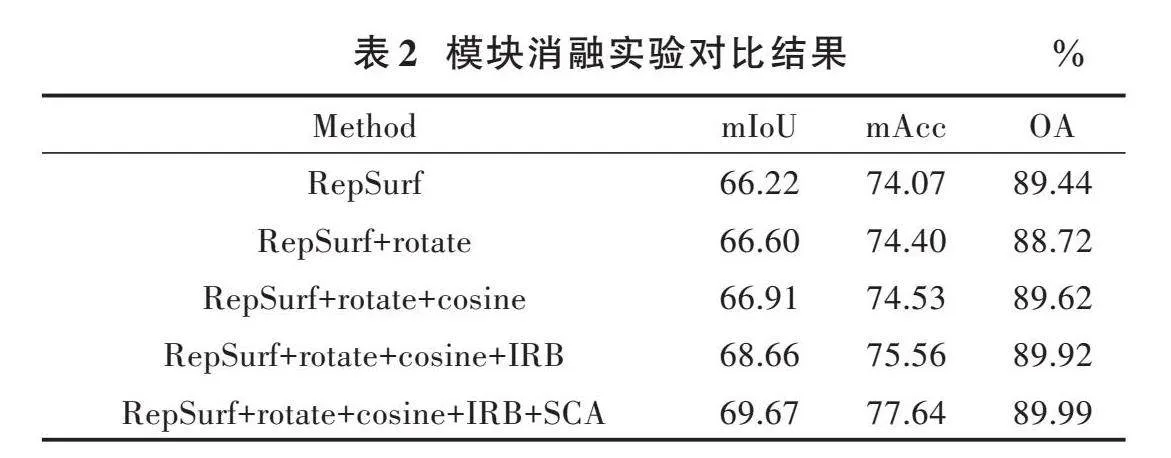
以原始的RepSurf[3]为基线,逐渐加入各个模块,在S3DIS语义分割任务Area⁃5上进行验证,结果见表2。其中,rotate是数据随机旋转,cosine是学习率衰减,IRB是倒置残差模块,SCA是注意力模块。
实验证明,引入注意力模块和倒置残差模块可以使模型更好地学习局部特征,从而显著提高性能指标。随机旋转有助于模型解决视角问题,提高性能。余弦衰减策略有助于优化模型参数,从而进一步提高性能。
3.2.2nbsp; 通道注意力模块消融实验
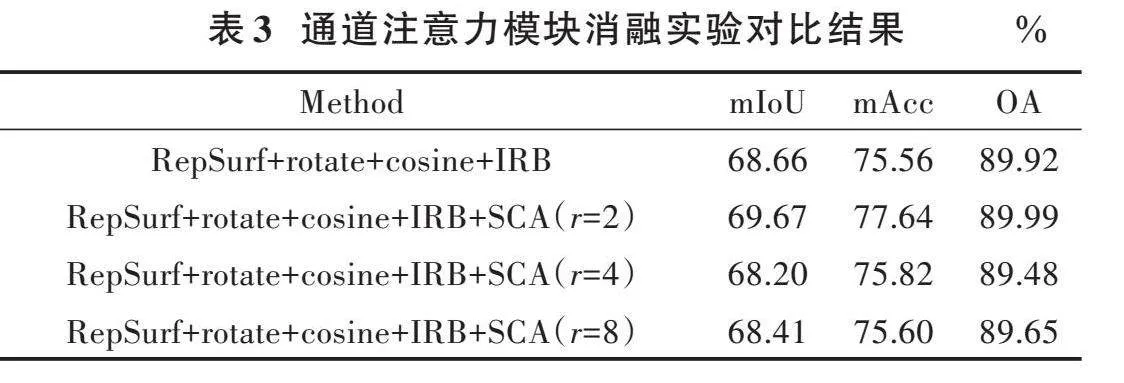
通道注意力中隐藏的激活大小设置为[Cr],其中[r]是减少率。对[r]参数进行消融实验,在S3DIS Area⁃5语义分割任务上验证。
表3总结了在不同[r]参数下进行实验的结果,其中,SCA为注意力残差模块,可以清楚地发现,在[r]=2时,语义分割性能更好。
3.2.3" 注意力模块顺序消融实验
考虑到空间注意力和通道注意力关注点不同,排列顺序可能对整体性能产生影响。比较了空间注意模块和通道注意模块的两种不同排列顺序。注意力模块顺序消融实验对比结果如表4所示。其中,CSA表示通道注意力在前,SCA表示空间注意力在前。通过表4的实验结果发现,将通道注意模块放在前面,语义分割性能更好。
3.2.4" 倒置残差模块消融实验
RepSurf中有4个集合抽象层,对每个层添加几个倒置残差模块进行消融实验,在S3DIS Area⁃5进行验证,基线为RepSurf+rotate+cosine。倒置残差模块消融实验结果如表5所示。其中,IRB(1 1 1 1)表示在每个Set Abstration层中添加1个倒置残差模块。
在实验中发现,当添加IRB(1 1 2 1)时,mAcc指标达到了75.98%,然而,与添加IRB(1 2 1 1)相比,mIoU和OA指标分别下降了0.58%和0.17%,因此本文设置为IRB(1 2 1 1)。
4" 结" 论
本文提出了倒置残差模块和注意力模块作为改进局部特征学习的方法。倒置残差模块通过增加更多的MLP层,学习了更丰富的特征信息。注意力模块包括空间注意力和通道注意力,其中空间注意力学习哪些点是关键的,通道注意力学习哪些通道是有用的,以获得更具代表性的特征。在S3DIS基准上进行了大量实验,证明了倒置残差模块和注意力模块的有效性,并在语义分割任务中取得了显著的改进效果。
注:本文通讯作者为禹龙。
参考文献
[1] QI C R, SU H, MO K, et al. PointNet: Deep learning on point sets for 3D classification and segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 77⁃85.
[2] QI C R, YI L, SU H, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space [C]// Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017. [S.l.: s.n.], 2017: 5099⁃5108.
[3] RAN H X, LIU J, WANG C J. Surface representation for point clouds [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2022: 18920⁃18930.
[4] SU H, MAJI S, KALOGERAKIS E, et al. Multi⁃view convolutional neural networks for 3D shape recognition [C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2015: 945⁃953.
[5] YU T, MENG J J, YUAN J S. Multi⁃view harmonized bilinear network for 3D object recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 186⁃194.
[6] YANG Z, WANG L. Learning relationships for multi⁃view 3D object recognition [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 7505⁃7513.
[7] WEI X, YU R X, SUN J. View⁃GCN: View⁃based graph convolutional network for 3D shape analysis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 1847⁃1856.
[8] MATURANA D, SCHERER S A. VoxNet: A 3D convolutional neural network for real⁃time object recognition [C]// 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). New York: IEEE, 2015: 922⁃928.
[9] WU Z R, SONG S R, KHOSLA A, et al. 3D ShapeNets: A deep representation for volumetric shapes [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2015: 1912⁃1920.
[10] LE T, DUAN Y. PointGrid: A deep network for 3D shape understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 9204⁃9214.
[11] JOSEPH⁃RIVLIN M, ZVIRIN A, KIMMEL R. Mo⁃Net: Flavor the moments in learning to classify shapes [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. New York: IEEE, 2019: 1⁃8.
[12] YANG J C, ZHANG Q, NI B B, et al. Modeling point clouds with self⁃attention and gumbel subset sampling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 3323⁃3332.
[13] ZHAO H S, JIANG L, FU C W, et al. PointWeb: Enhancing local neighborhood features for point cloud processing [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 5565⁃5573.
[14] SUN X, LIAN Z H, XIAO J G. SRINet: Learning strictly rotation⁃invariant representations for point cloud classification and segmentation [C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: IEEE, 2019: 980⁃988.
[15] ARMENI I, SENER O, ZAMIR A R, et al. 3D semantic parsing of large⁃scale indoor spaces [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 1534⁃1543.
[16] PHAN A V, LE NGUYEN M, NGUYEN Y L H, et al. DGCNN: A convolutional neural network over large⁃scale labeled graphs [J]. Neural networks, 2018, 108: 533⁃543.
[17] HU Q Y, YANG B, XIE L H, et al. Learning semantic segmentation of large⁃scale point clouds with random sampling [J]. IEEE transactions on pattern analysis and machine intelligence, 2022, 44(11): 8338⁃8354.
[18] THOMAS H, QI C R, DESCHAUD J E, et al. KPConv: Flexible and deformable convolution for point clouds [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 6410⁃6419.
猜你喜欢
软件工程(2024年7期)2024-12-31 00:00:00
交通科技与管理(2024年13期)2024-12-31 00:00:00
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
计测技术(2020年6期)2020-06-09 03:27:12
电脑知识与技术(2019年6期)2019-05-22 10:27:32
科教导刊·电子版(2019年6期)2019-04-11 11:49:42
科技创新与应用(2019年6期)2019-03-22 02:35:30
电子技术与软件工程(2018年23期)2018-02-28 09:38:04
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
