
一种节省资源的矩阵运算单元硬件微架构设计
2024-09-12 00:00:00潘于田映辉张伟杨建磊申奇
现代电子技术 2024年5期
关键词:人工智能






摘" 要: 为了实现人工智能和高性能计算在不同应用领域下的快速运算,需借助人工智能加速器(NPU)或者通用图形处理器(GPGPU)对其进行加速。由于矩阵运算是人工智能和高性能计算的核心运算,文中提出一种节省资源的矩阵运算单元架构的实现方案。通过对矩阵运算单元中每个子运算单元中的乘法器和加法器数量进行扩展,并将输入数据按行列广播到矩阵运算单元上的各个子运算单元可实现对矩阵运算的加速。通过利用PE矩阵之间的数据共享,采用新型的PE矩阵互联方案,可达到在减少带宽资源的同时提升算力的目的。与现有NPU或GPGPU的矩阵运算实现方案相比,所提方案使用更少的加法器和寄存器即可实现相同的算力,且在更低的时钟延迟和带宽消耗下即可完成对相同规模矩阵运算的加速。
关键词: 人工智能; 高性能计算; 矩阵运算; 节省资源; 低时钟延迟; GPGPU
中图分类号: TN02⁃34; TP183" " " " " " " " " " " "文献标识码: A" " " " " " " " " " 文章编号: 1004⁃373X(2024)05⁃0160⁃07
Design of hardware microarchitecture of resource⁃efficient matrix operation unit
PAN Yu1, TIAN Yinghui1, ZHANG Wei1, YANG Jianlei2, SHEN Qi3
(1. Hygon Information Technology Co., Ltd., Beijing 100193, China;
2. Beihang University, Beijing 100191, China;
3. China Unicom Smart City Research Institute, Beijing 100037, China)
Abstract: It is necessary to use artificial intelligence accelerator NPU (neural processing unit) or GPGPU (general⁃purpose graphics processing unit) for acceleration, so as to realize the fast computation of artificial intelligence and high performance computing in different fields. Since the matrix operation is the core operation of artificial intelligence and high performance computing, an implementation scheme of resource⁃efficient matrix operation unit architecture is proposed. By expanding the number of multipliers and adders in each sub⁃unit of matrix arithmetic unit and broadcasting the input data to each sub⁃unit of matrix arithmetic unit by row and column, the acceleration of matrix arithmetic unit can be realized. By using the data sharing between PE matrix and adopting the new PE matrix interconnection scheme, the purpose of reducing bandwidth resources and increasing computing power can be achieved. In comparison with the existing implementation scheme of matrix operation of NPU or GPGPU, the proposed one can achieve the same computing power with fewer adders and registers, and can complete the acceleration of the same scale matrix operation with low clock latency and bandwidth consumption.
Keywords: artificial intelligence; high performance computing; matrix operation; resource⁃efficient; low clock latency; GPGPU
0" 引" 言
随着人工智能技术的不断发展,其已经在许多领域得到了广泛的应用。伴随着各种应用需求,出现了越来越多复杂的深度学习网络模型[1⁃5],这些模型通常具有网络层数多、运算量巨大的特点,因此运算的实时性成为这些应用的瓶颈。为了保证运算的实时性,通常使用NPU和GPGPU来实现对各种深度学习网络模型的加速。深度学习网络模型的底层核心是卷积运算和矩阵运算,而通常可使用矩阵运算来实现卷积运算,因此为了更好地实现对各种深度学习网络的加速,对矩阵运算进行加速至关重要。最新的NPU[6⁃9]、GPGPU以及矩阵加速器[10]都有专门的模块来实现对矩阵运算的加速。
而在其他应用领域,如生命科学、气象、图像处理、航空航天及石油勘探等领域,同样需要GPGPU对其进行加速。这些高性能计算应用中许多也都需要用到矩阵运算。
因此,设计一款高性能、低功耗以及面积开销小的适用于实现矩阵运算的硬件单元对于NPU或者GPGPU至关重要。目前业界最知名的NPU/GPGPU处理器设计厂商如谷歌、英伟达和AMD的产品都可以实现对矩阵运算的加速。谷歌公司基于脉动阵列的思路设计了TPU(Tensor Processing Unit)[11]来实现对矩阵运算的加速;英伟达公司在其GPU中专门设计了TENSOR CORE[12]来实现对矩阵运算的加速;AMD的GPU中并没有设计单独的矩阵运算单元来实现对矩阵运算的加速,其利用内部的向量运算单元将矩阵运算拆解为并行的乘加运算来实现对矩阵运算的加速。
本文提出了一种节省资源的PE矩阵(矩阵运算单元)架构的实现方案,该PE矩阵可实现矩阵乘法运算。通过对PE矩阵中每个PE单元(子运算单元)进行变化,将每个PE单元中的乘法器个数增加,并在每个PE单元中实现多个乘法器结果的累加,使每个PE单元可实现多对数据的乘累加以达到向量运算的目的。相比于业界现有矩阵运算加速单元每个PE单元只有一个乘法器的实现方案,本文方案使用更少的加法器和寄存器数即可实现相同的算力。同时,通过将输入数据按行、按列广播到PE矩阵上的各个PE单元,本文方案可在更短的时钟延迟下完成对相同规模矩阵运算的加速。另外,本文提出了一种新型的PE矩阵Mesh结构,使用该方法可以在不增加后端实现复杂度的情况下显著减少带宽消耗,且进一步提升在大算力下的可实现性。
1" 设计背景及相关工作研究
1.1" 设计背景
矩阵运算的本质是乘加运算,合理的对乘加运算进行调度是更好地实现矩阵运算的关键。对于维度为[X]×[Y]的矩阵[A]乘以维度为[Y]×[Z]的矩阵[B],其将得到维度为[X]×[Z]的结果矩阵[C]。
[a0,0…a0,Y-1⋮⋱⋮aX-1,0…aX-1,Y-1⋅b0,0…b0,Z-1⋮⋱⋮bY-1,0…bY-1,Z-1=c0,0…c0,Z-1⋮⋱⋮cX-1,0…cX-1,Z-1] (1)
式中结果矩阵[C]中的每个元素[ci,j=m=0Y-1ai,m⋅bm,j],[0≤i≤X-1],[0≤j≤Z-1]。
在多种应用领域下常需要对大规模矩阵运算进行加速,即需要实现对上述公式的加速。因此,有必要设计一款专门的矩阵运算单元来高效地实现上述矩阵运算。
1.2" 相关工作研究
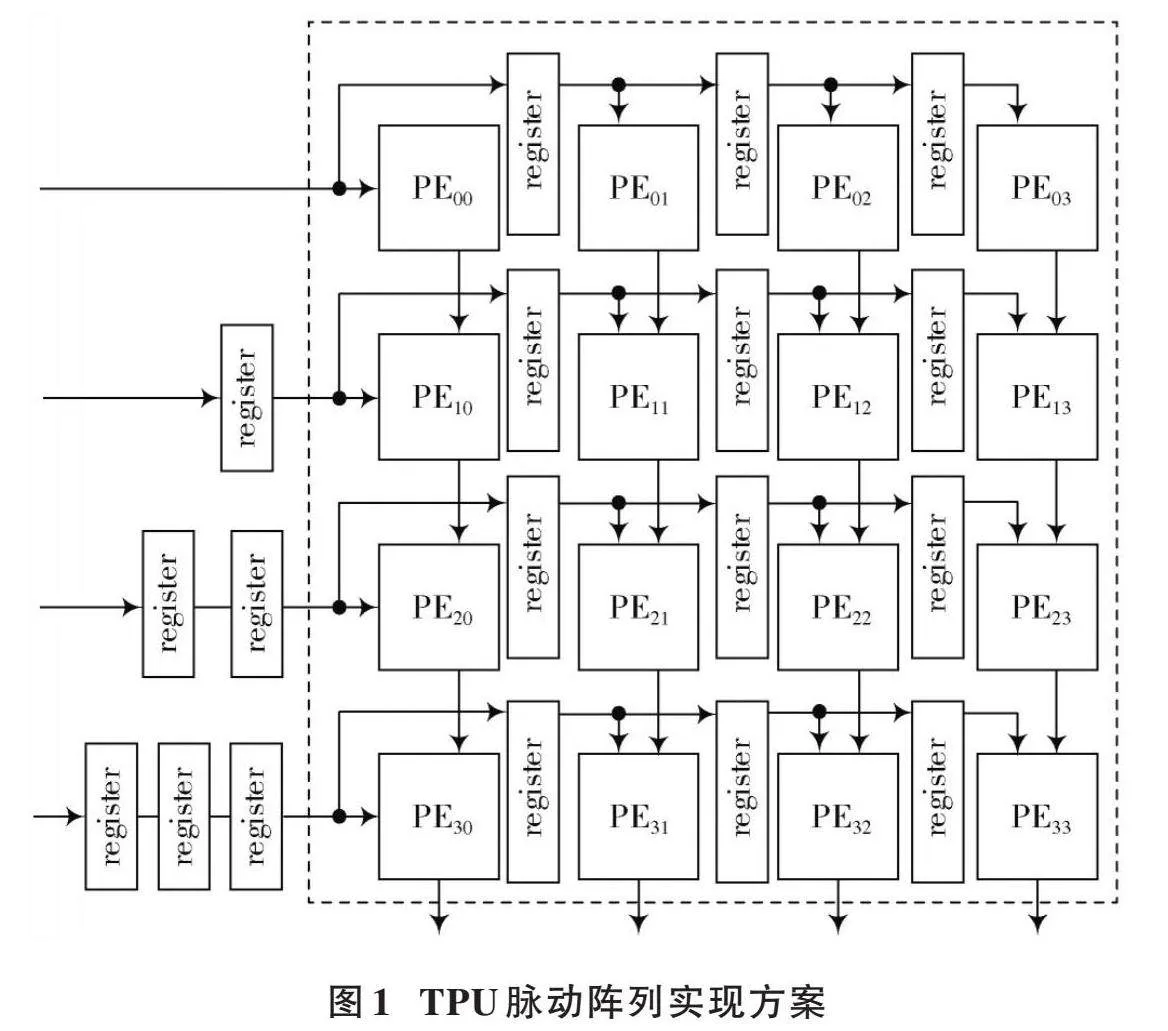
为了实现上述矩阵运算,谷歌公司专门设计了一款TPU来实现对矩阵运算的加速。TPU采用脉动阵列的方式实现矩阵运算,其核心是一个[N]×[N]的脉动阵列。图1以大小为4×4的脉动阵列为例进行说明。其权重被提前装载到脉动阵列中,权重系数可认为上述公式(1)中矩阵运算的矩阵[A],矩阵[A]中的每个元素[aj,i]被提前装载到脉动阵列的[PEi,j]中,这里[0≤i≤3],[0≤j≤3]。矩阵[B]作为输入特征图,从左到右水平地输入到脉动阵列当中。部分和从上到下垂直移动,脉动阵列最后一行的PE单元输出矩阵运算的结果。
在TPU脉动阵列中,每个[PEi,j]单元的硬件电路如图2所示。图2中上方的寄存器(reg)用于预先装载[A]矩阵中元素[aj,i];乘法器用于实现[B]矩阵的元素[bi,k]与[aj,i]的乘积,[0≤k≤3];图2中下方的寄存器用于存储部分和,同时输出当前PE单元的部分和给其下方的PE单元。对于脉动阵列最后一行的PE单元,其输出矩阵运算的最终结果。加法器用于实现乘法器输出与部分和结果的累加,这里输入给加法器的部分和结果来自于当前PE单元上方PE单元的运算结果。
谷歌公司的脉动阵列在实现矩阵运算时需要将矩阵[A]中的各个元素提前存储到脉动阵列中,当矩阵[A]发生变化时,每次都需要预先加载矩阵[A]的数据到脉动阵列中。当每次矩阵运算的矩阵[A]都不相同时,预先装载矩阵[A]到脉动阵列中会使矩阵运算的运算时间受到影响。
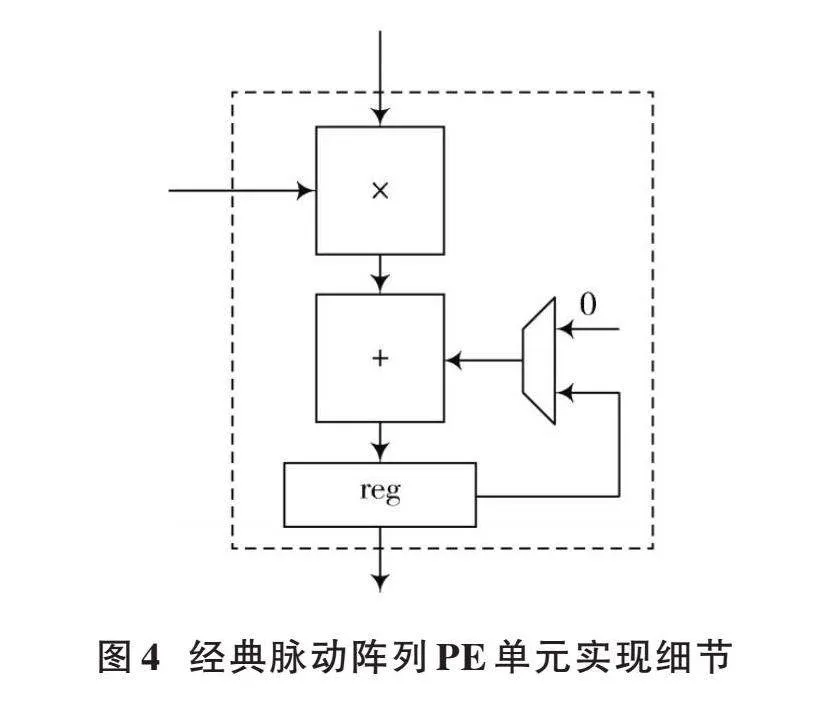
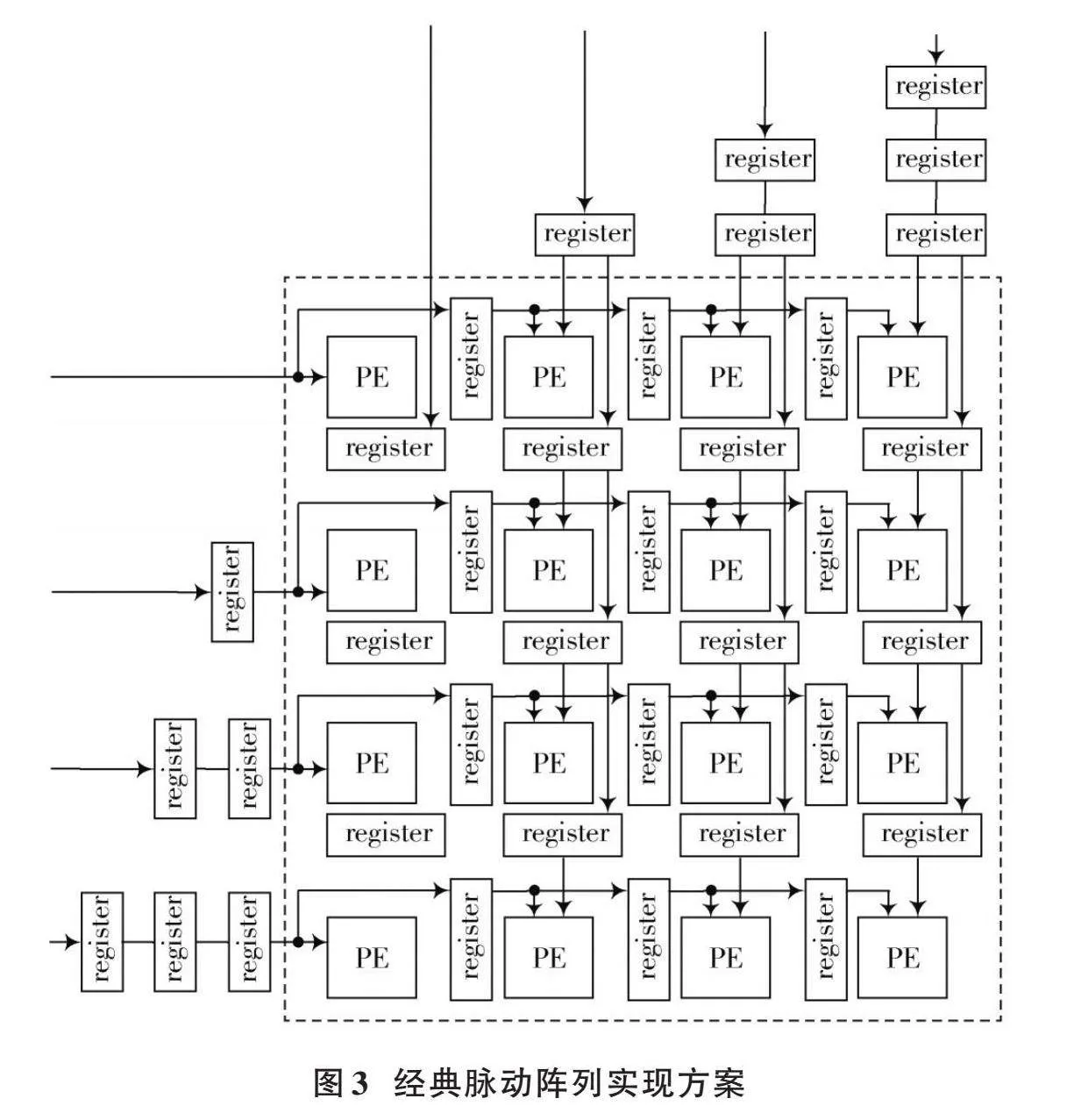
为此,一些设计采用经典脉动阵列[13⁃16]的方式实现矩阵运算,图3展示了其中一种经典脉动阵列的实现方式。此时[A]矩阵从左到右输入到脉动阵列,[B]矩阵从上到下输入到脉动阵列。不同于TPU中的脉动阵列只在最后一行的PE单元输出最终运算结果,该方法下脉动阵列中的每个PE单元都会输出矩阵运算的最终结果。
图3所示脉动阵列中每个PE单元的运算结构如图4所示,其乘法器用于接收矩阵[A]和矩阵[B]的元素实现乘法运算,加法器用于实现累加运算,寄存器用于存储部分和以及最终的运算结果。当寄存器输出最终运算结果时,多路选择器选择将数据0输入到加法器的其中一个输入端口。
为了实现上述矩阵运算,英伟达公司在其最新的几款GPU产品中专门加入了Tensor Core(张量核心)来实现对矩阵运算的加速。其具体实现细节并没有在其白皮书中完整的说明。
AMD没有在其GPU中设计专门的用于计算矩阵运算的单元,其通过将矩阵运算转换成并行的乘加运算,利用其CU(Compute Unit)内部SIMD(Single Instruction Multiple Data)下的多个乘加单元的并行运算来实现对矩阵运算的加速。在相同算力的情况下,由于输入输出数据不停地和存储媒介进行交互,其加速能力不如专门的矩阵运算加速单元。
2" 本文架构实现方案
对于上述现有方案,其每个PE单元只能计算[a*b+c]。为了实现[a*b+c],每个PE单元有1个乘法器、1个加法器和1个用于存储运算结果的寄存器。为了提高算力,需要增加脉动阵列中PE单元的个数,因此脉动阵列中加法器和乘法器的个数也成倍增加。同时,为了实现脉动阵列,在PE矩阵的数据输入端口需要额外的寄存器来缓存输入数据,以实现时序匹配,此时所需的寄存器数量也随之增加。脉动阵列规模越大,需要的乘法器、加法器以及寄存器的数量就会成倍增加。
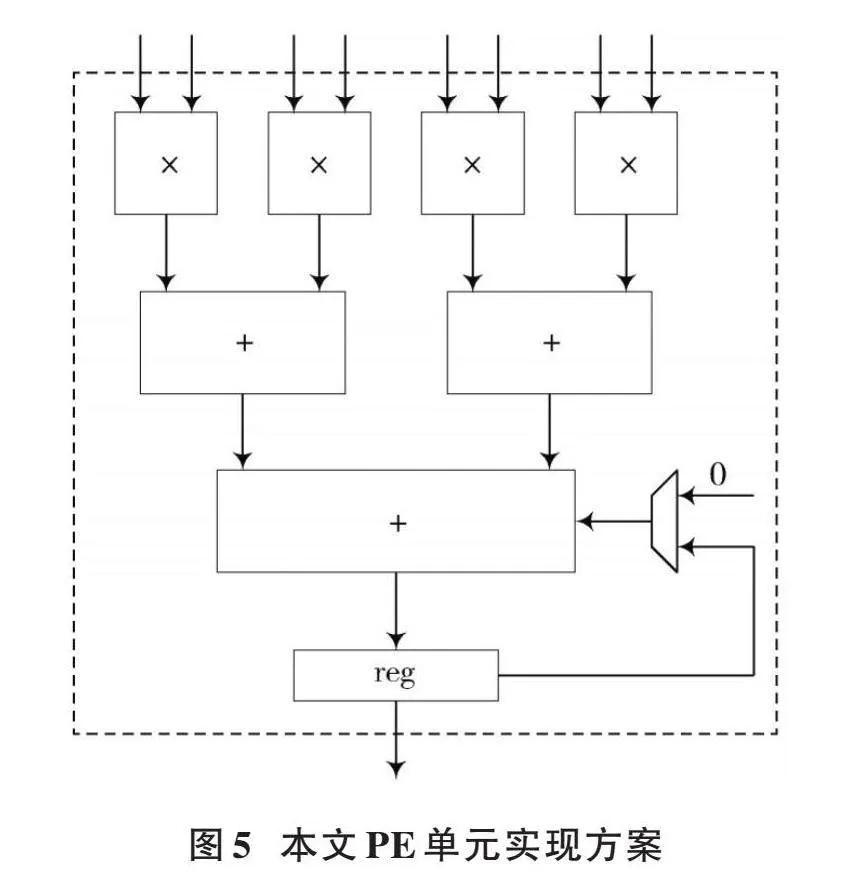
通过对PE单元进行改进,本文提出了一种在相同算力情况下减少加法器和寄存器使用数量的方案。在本设计中,每个周期矩阵[A]中同一行的相邻多个元素同时输入到PE矩阵对应行的每个PE单元中,矩阵[B]中同一列的相邻多个元素同时输入到PE矩阵对应列的每个PE单元中,即每个PE单元每个周期可以实现[a1*b1+a2*b2+…+an*bn]的运算,即将传统的PE单元执行标量运算改进为每个PE单元都可执行向量运算,这里[n]为每个PE单元中乘法器的个数。以[n]等于4为例,其PE单元的结构如图5所示。
图5中每个PE单元的乘法器个数为4,其对应的加法器数量为3,寄存器的数量为1,其每次可以实现4对输入元素的向量乘累加运算。采用这种方案,虽然乘法器的数量提高了4倍,但加法器和寄存器数量并没有与传统架构一样提升4倍,其加法器的数量为3,寄存器的数量只为1,可见采用该方法可有效地减少资源消耗。
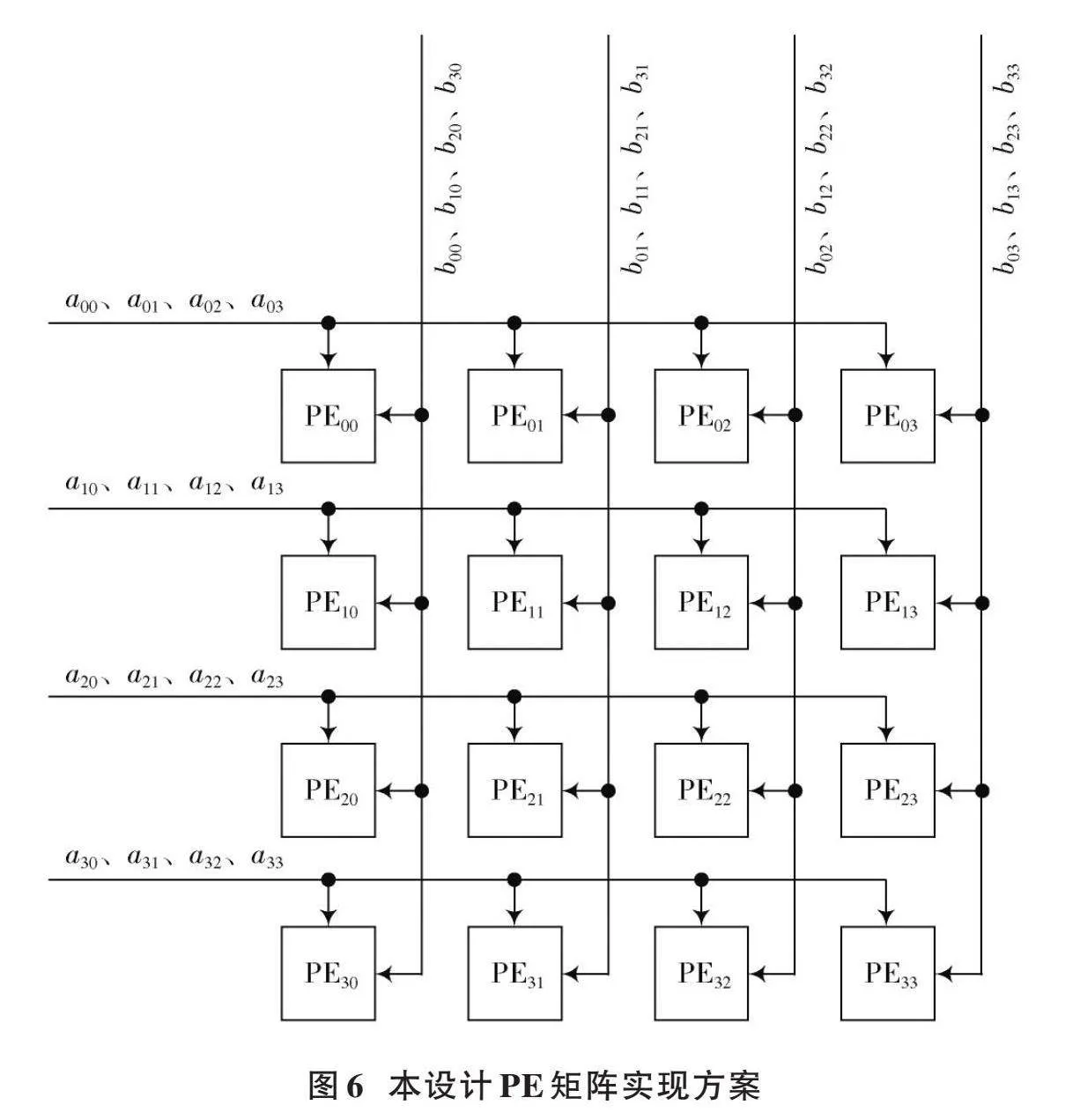
此外,本文方案还对PE矩阵的实现进行了优化,如图6所示,本文方案并没有采用脉动阵列的方式实现PE矩阵,而是将输入矩阵[A]的各行数据广播到PE矩阵对应行的各个PE单元中,将输入矩阵[B]的各列数据广播到PE矩阵对应列的各个PE单元中。此种方法可进一步减少采用脉动阵列时输入端所需要的寄存器数目,同时,其不需要额外的延时即可将输入数据同时传递给各个PE单元。
图6以在4×4大小的PE矩阵中实现4×4大小的[A]矩阵乘以4×4大小的[B]矩阵为例,说明矩阵运算在本文方案PE矩阵中的运算流程。
在一个周期内,将矩阵[A]第一行的四个数据[a00~a03]同时广播到PE矩阵第一行的4个PE单元PE00~PE03;将矩阵[A]第二行的四个数据[a10~a13]同时广播到PE矩阵第二行的4个PE单元PE10~PE13;将矩阵[A]第三行的四个数据[a20~a23]同时广播到PE矩阵第三行的4个PE单元PE20~PE23;将矩阵[A]第四行的四个数据[a30~a33]同时广播到PE矩阵第四行的4个PE单元PE30~PE33。
在该周期内,将矩阵[B]第一列的四个数据[b00~b30]同时广播到PE矩阵第一列的4个PE单元PE00~PE30;将矩阵[B]第二列的四个数据[b01~b31]同时广播到PE矩阵第二列的4个PE单元PE01~PE31;将矩阵[B]第三列的4个数据[b02~b32]同时广播到PE矩阵第三列的4个PE单元PE02~PE32;将矩阵[B]第四列的四个数据[b03~b33]同时广播到PE矩阵第四列的4个PE单元PE03~PE33。
此时PE矩阵的各个PE单元只需一个周期即可同时计算出结果矩阵的16个运算结果[c00~c03]、[c10~c13]、[c20~c23]、[c30~c33]。PE矩阵中的每个PE单元计算出结果矩阵的一个元素。例如,PE单元PE00执行[c00=a00*b00+a01*b10+a02*b20+a03*b30]这4对输入数据的乘加运算;PE单元PE01执行[c01=a00*b01+a01*b11+a02*b21+a03*b31]这4对输入数据的乘加运算;依此类推,其余PE单元同时完成各自的运算。由于单周期内同时输出4×4大小的矩阵输出结果,使得输出结果的存储控制逻辑也会相应简化。
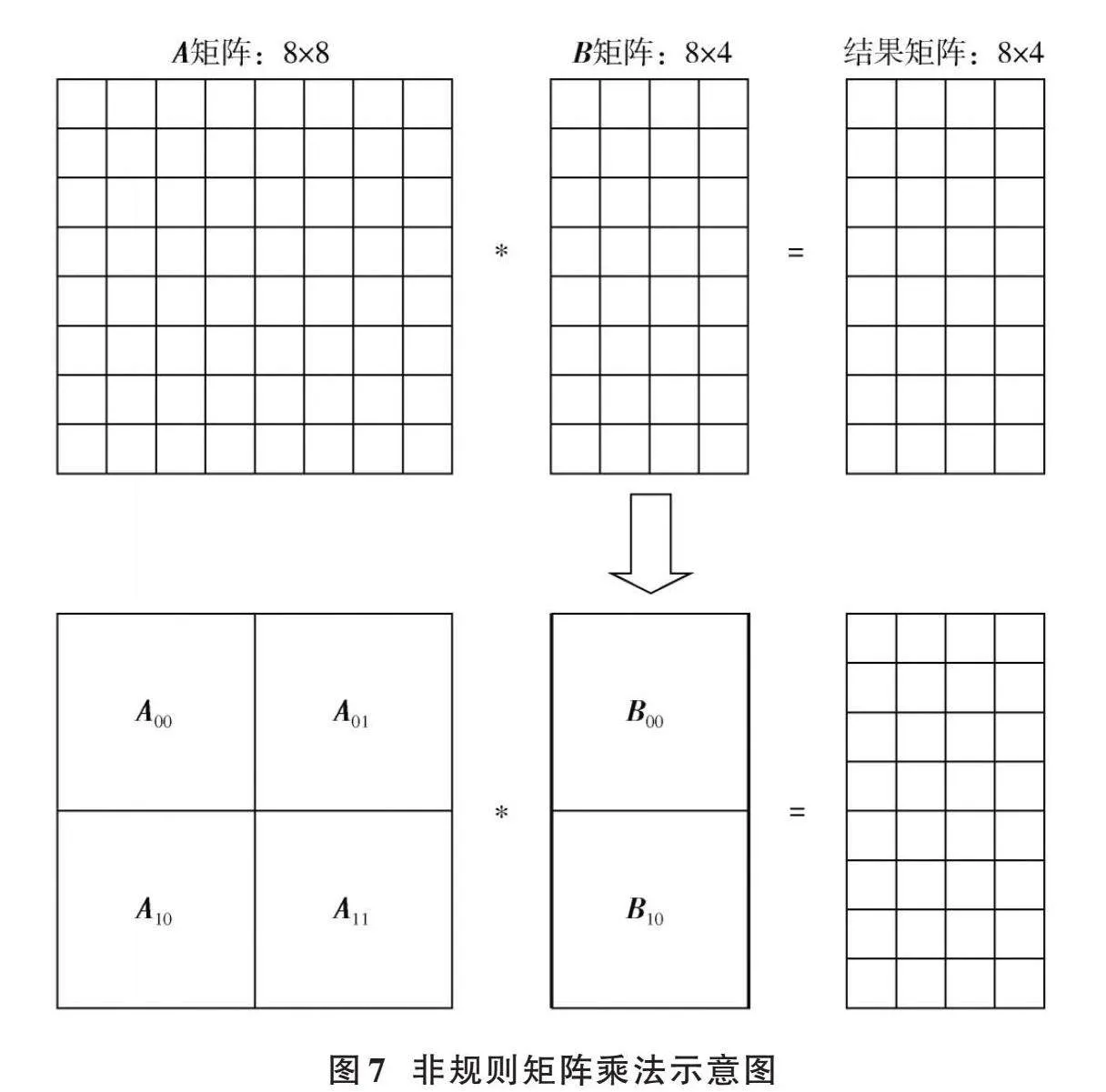
当其他形状的矩阵[A]和矩阵[B]相乘时,需要结合与PE矩阵交互的存储器的读写控制逻辑,反复利用PE矩阵来完成各种形状的矩阵乘法运算。以大小为8×8的矩阵[A]和大小为8×4的矩阵[B]相乘为例,其可以拆解为多个4×4的矩阵乘法运算以及相应的累加运算,其运算流程如图7所示。
8×8矩阵乘以8×4的矩阵可以等效为式(2):
[A00A01A10A11B00B10=C00C10] (2)
式中:[A00]、[A01]、[A10]、[A11]、[B00]和[B10]都为4×4矩阵;结果矩阵[C00]和[C10]也都为4×4矩阵。
[C00=A00*B00+A01*B10] (3)
[C10=A10*B00+A11*B10] (4)
根据式(2)~式(4),通过反复调用4×4矩阵运算单元并执行相应的累加运算,可以实现任意大规模的矩阵运算。
为了进一步提高PE矩阵的运算能力,通常采用增加PE矩阵尺寸的方法,例如将本文所示的PE矩阵大小从4×4增加到8×8甚至16×16。但随着PE矩阵尺寸的增加,后端实现的难度也会随之增加。为了提高后端的可实现性,同时实现更高的算力,通常采用分tile的方式来实现,即用多个小尺寸的PE矩阵同时工作来完成更大规模的矩阵运算。比如4个16×16的PE矩阵并行工作即可达到尺寸为32×32的PE矩阵的算力。
本文展示了4个4×4大小的PE矩阵同时工作可实现更大算力的例子。其中每个PE矩阵在工作时都需要相应的带宽资源来向PE矩阵输入矩阵[A]数据以及矩阵[B]数据。为了达到应有的算力,多个PE矩阵同时工作时,相应的带宽资源将成倍增加。
本文提出一种新型的PE矩阵互联方案,使得输入到PE矩阵的数据被共享,进而减少了多个PE矩阵同时工作时所需的总带宽资源。
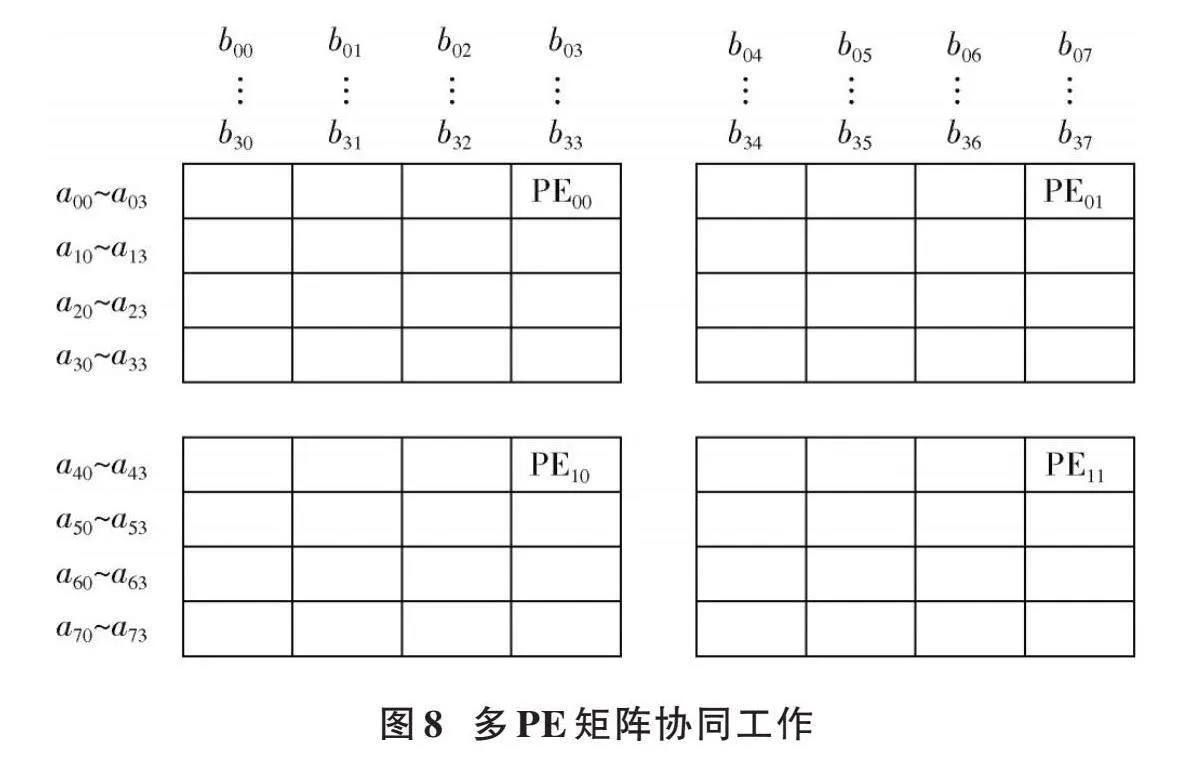
对于8×4大小的[A]矩阵乘以4×8大小的[B]矩阵,每个PE矩阵执行的操作如图8所示。
图8中:PE00、PE01、PE10以及PE11都表示大小为4×4的PE矩阵。其中PE矩阵PE00用于计算[A]矩阵的前4行和[B]矩阵的前4列;PE矩阵PE01用于计算[A]矩阵的前4行和[B]矩阵的后4列;PE矩阵PE10用于计算[A]矩阵的后4行和[B]矩阵的前4列;PE矩阵PE11用于计算[A]矩阵的后4行和[B]矩阵的后4列。
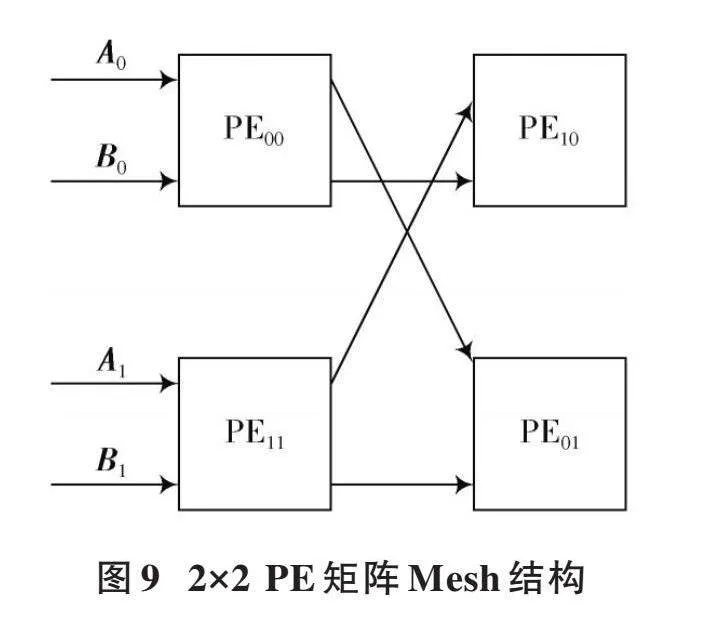
通过对PE矩阵进行重新互联,并改动每个PE矩阵在PE矩阵Mesh中的位置,利用数据共享可以达到减少带宽资源的效果。与图8对应的PE矩阵Mesh结构如图9所示。
在图9中,利用Mesh结构对矩阵数据进行共享,并改动PE矩阵在Mesh中的相对位置,使得4个PE矩阵整体的输入带宽资源减少一半。在图9中,PE矩阵PE00和PE01共享数据[A0];PE矩阵PE00和PE10共享数据[B0];PE矩阵PE11和PE10共享数据[A1];PE矩阵PE11和PE01共享数据[B1]。可以看到,图9中每个PE矩阵在PE矩阵Mesh中的位置也有相应的调整。在图9中,输入数据仅输入给最左侧一列PE矩阵,为了实现数据共享,也对PE矩阵的位置进行了调整。将图8所示的常规位置变为如图9所示的位置。当PE矩阵Mesh规模进一步增大时,也仅有最左侧一列PE矩阵接收输入数据,此时输入带宽资源会更显著减少。而常规排列方法会使最左侧一列和最上边一行都有与外部数据的交互,增加了后端可实现的难度。
3" 性能分析
对于单个矩阵乘法运算单元,考虑到频率要求和后端的可实现性,本文设计采用的PE矩阵中的单个PE单元一般实现对4、8以及16对输入数据的乘加运算。当输入数据对数大于16时后端实现难度巨大,小于4时算力又显不足。对于单个PE单元,输入数据对数越大,PE单元能达到的最高频率越低,同时后端实现该PE矩阵的难度越大。在具体选择PE矩阵大小时,需根据算力、频率的要求以及后端实现方案的难度,从上述三种情况中选择一种实现。如果单个PE单元实现4对输入数据的乘累加运算,则相应的PE矩阵大小为4×4,其乘法器个数为4×4×4;如果单个PE单元实现8对输入数据的乘累加运算,则相应的PE矩阵大小为8×8,其乘法器个数为8×8×8;如果单个PE单元实现16对输入数据的乘累加运算,则相应的PE矩阵大小为16×16,其乘法器个数为16×16×16。可见当进一步增加规模时,乘法器数将以指数增加,后端实现难度也将呈指数级增加。
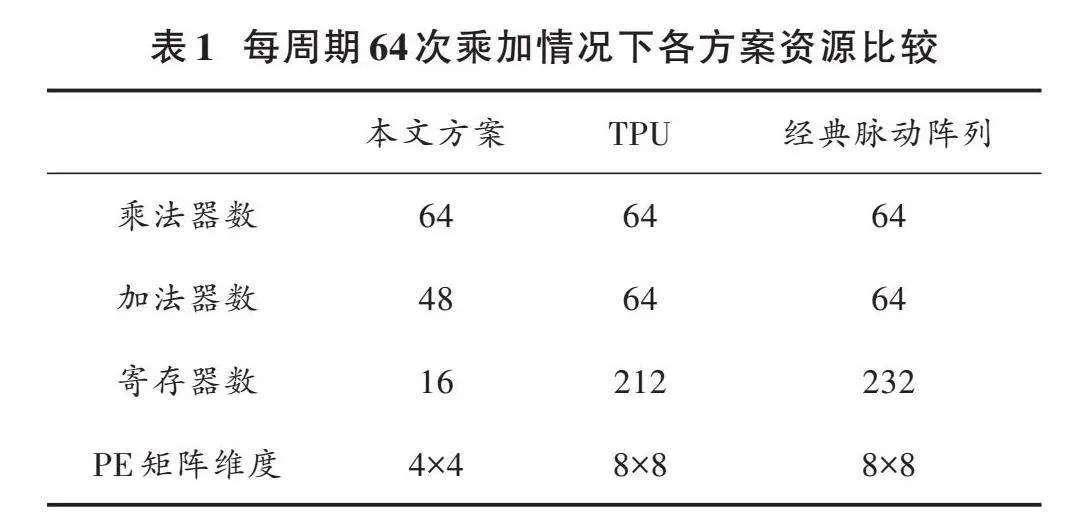
对于每个PE单元实现4对乘加运算的情况,其相应的PE矩阵大小为4×4,此种情况下,PE矩阵乘法器个数为64,加法器的个数为48,寄存器的个数为16。在相同算力下,采用TPU的矩阵乘法实现方案,需要的乘法器个数为64,加法器个数为64,寄存器的个数为212。在相同算力下,采用经典脉动阵列实现矩阵乘法的方案,需要的乘法器个数为64,加法器个数为64,寄存器个数为232。表1展示了各种方案下矩阵乘法单元的资源消耗情况。
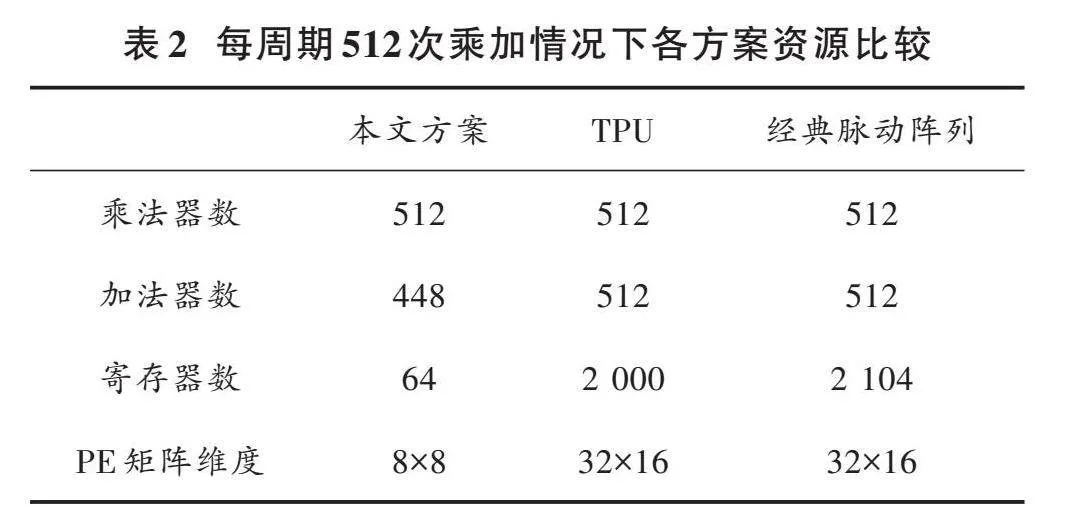
对于每个PE单元实现8对乘加运算的情况,其相应的PE矩阵大小为8×8,此种情况下,PE矩阵乘法器个数为512,加法器的个数为448,寄存器的个数为64。在相同算力下,采用TPU的矩阵乘法实现方案,需要的乘法器个数为512,加法器个数为512,寄存器的个数为2 000。在相同算力下,采用经典脉动阵列实现矩阵乘法的方案,需要的乘法器个数为512,加法器个数为512,寄存器个数为2 104。表2展示了各种方案下矩阵乘法单元的资源消耗情况。
对于每个PE单元实现16对乘加运算的情况,其相应的PE矩阵大小为16×16,此种情况下,PE矩阵乘法器个数为4 096,加法器的个数为3 840,寄存器的个数为256。在相同算力下,采用TPU的矩阵乘法实现方案,需要的乘法器个数为4 096,加法器个数为4 096,寄存器的个数为14 240。在相同算力下,采用经典脉动阵列实现矩阵乘法的方案,需要的乘法器个数为4 096,加法器个数为4 096,寄存器个数为16 192。表3展示了各种方案下矩阵乘法单元的资源消耗情况。
为了进一步提高PE矩阵的算力,同时不增加后端实现的难度并减少带宽消耗,本文提出了一种PE矩阵之间的互联方案。表4给出了在不同PE矩阵Mesh规模下,带宽资源节省的倍数。由于任意地增加PE矩阵Mesh的规模同样会增加后端的实现难度,表4仅给出大小为2×2、4×4以及8×8情况下带宽资源节省的倍数。可见,采用本文所示的PE矩阵互联方案可以有效减少带宽资源的消耗。
为了方便验证,图10展示了2×2大小的PE矩阵波形图,PE矩阵中每个PE单元包含2个乘法器,即每个PE单元的计算并行度为2。其中[a00]、[a01]、[a10]以及[a11]为矩阵[a]的输入数据,[b00]、[b01]、[b10]以及[b11]为矩阵[b]的数据,[c00]、[c01]、[c10]以及[c11]为PE矩阵的输出结果。由图10可见,每个周期2×2大小的矩阵结果同时输出。
综上所述,相比于业内流行的两种矩阵运算实现方案,在实现相同算力的情况下,使用本文方案可使硬件资源消耗更少。同时,相比于TPU在每次进行矩阵运算时,对于不同的矩阵[A],TPU都需要将[A]矩阵的元素预先加载到脉动阵列中,本文设计不需要额外的矩阵加载过程,因此相比于TPU来说进一步地减少了处理时间。此外,相比于业内流行的两种矩阵运算实现方案,本文方案在PE矩阵的输入端口并没有用于匹配时序的寄存器,其可以进一步减少矩阵运算的latency。同时,采用本文提出的PE矩阵互联方案可以在节省带宽资源且不增加后端实现复杂度的情况下进一步提升算力,以实现算力的扩展。因此,本文方案可以作为实现矩阵运算的有效实现方案。
4" 结" 语
本文介绍了实现矩阵运算加速的硬件微架构方案,分析了业界实现矩阵运算的通用方法,并对谷歌的TPU和通用脉动阵列进行了详细的分析。为了进一步减少硬件资源消耗,本文设计了一种改进型PE矩阵,该PE矩阵将数据广播到多个PE单元,减少了通用方法中对输入端寄存器的使用。本文方案使用可同时进行多对输入数据乘加运算的PE单元,进一步减少了对加法器和寄存器的使用,达到了减少硬件资源消耗的目的。同时,采用本文提出的PE矩阵互联方案可进一步提升算力,其可以在不增加后端实现复杂度的情况下减少带宽资源。经过分析表明,在具有相同算力的情况下,使用本文方案可以在使用更少硬件资源以及带宽的情况下达到更少的运算延迟,因此是实现矩阵运算加速的一种有效方案。
注:本文通讯作者为田映辉。
参考文献
[1] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2016: 770⁃778.
[2] ZHANG X Y, ZHOU X Y, LIN M X, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2018: 6848⁃6856.
[3] VASWANI A, SHAZZER N, PARMAR N, et al. Attention is all you need [C]// 2017 Conference and Workshop on Neural Information Processing Systems (NIPS). [S.l.: s.n.], 2017: 1⁃11.
[4] HUANG G, LIU Z, WEINBERGER K Q. Densely connected convolutional networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2017: 4700⁃4708.
[5] BENJUMEA A, TEETI I, CUZZOLIN F, et al. YOLO⁃Z: Impro⁃ving small object detection in YOLOv5 for autonomous vehicles [C]// IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2021: 1⁃11.
[6] GOPAL R, ANTON B, NARENDRA D, et al. Data multiplexed and hardware reused architecture for deep neural network acce⁃lerator [J]. Neurocomputing, 2022, 486: 147⁃159.
[7] PRATAP S R, SHREYAM K, JUGAL G, et al. A time domain 2D OaA⁃based convolutional neural networks accelerator [J]. Memories: Materials, devices, circuits and systems, 2023, 4: 100041.
[8] CHEN Y R, XIE Y, SONG L H, et al. A survey of accelerator architectures for deep neural networks [J]. Engineering, 2020, 6: 264⁃274.
[9] LI T, SHEN L. A sparse matrix vector multiplication accelerator based on high⁃bandwidth memory [J]. Computers and electrical engineering, 2023, 105: 108488.
[10] HAMEED K F, ADEEL P M, SHAHID M. Toward designing a hardware accelerator for 3D convolutional neural networks [J]. Computers and electrical engineering, 2023, 105: 108489.
[11] JOUPPI N P, YOUNG C, PATIL N, et al. In⁃datacenter performance analysis of a tensor processing unit [C]// 2017 ACM/IEEE Annual International Symposium on Computer Architecture (ISCA). New York: IEEE, 2017: 1⁃12.
[12] NVIDIA Corporation. NVIDIA A100 tensor core GPU architecture [M]. USA: NVIDIA Corporation, 2022.
[13] 王阳,陶华敏,肖山竹,等.基于脉动阵列的矩阵乘法器硬件加速技术研究[J].微电子学与计算机,2015,32(11):120⁃124.
[14] 刘勤让,刘崇阳,周俊,等.基于线性脉动阵列的卷积神经网络计算优化与性能分析[J].网络与信息安全学报,2018,4(12):16⁃24.
[15] XU R, MA S, WANG Y H, et al. Heterogeneous systolic array architecture for compact CNNs hardware accelerators [J]. IEEE transactions on parallel and distributed systems, 2022, 33(11): 2860⁃2871.
[16] INAYAT K, CHUNG J. Hybrid accumulator factored systolic array for machine learning acceleration [J]. IEEE transactions on very large scale integration systems, 2022, 30(7): 881⁃892.
猜你喜欢
西安航空学院学报(2022年2期)2022-07-04 07:45:42
汽车零部件(2020年3期)2020-03-27 05:30:20
表面工程与再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技术(2018年9期)2018-11-02 05:31:34
IT经理世界(2018年20期)2018-10-24 02:38:24
通信电源技术(2018年3期)2018-06-26 06:33:30
军营文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
学与玩(2017年12期)2017-02-16 06:51:12
