
基于SLIC与APMMD结合的图像分割算法研究
2024-08-31 00:00:00傅江
机械制造与自动化 2024年3期
关键词:聚类


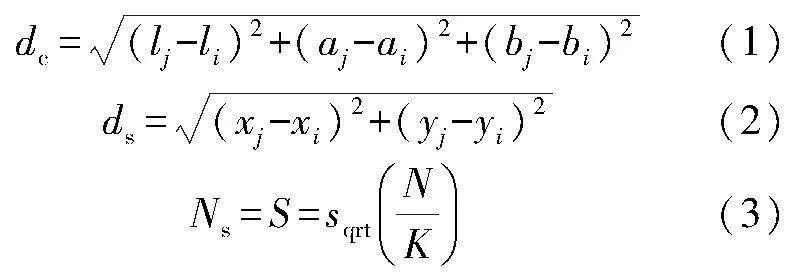

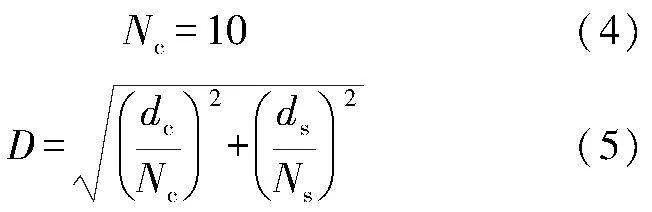
摘 要:超像素是由一系列特征相似且位置相邻的像素点组成的小区域。采用超像素分割既能降低图像分割的复杂度,又能更好地保留局部信息及边缘信息。针对管壁污渍识别和零件盒零件分类的要求,将SLIC与基于近邻传播最大-最小距离算法(APMMD)结合使用来达到更好的图像分割效果。该方法根据传统SLIC算法的步骤,在颜色空间转换时通过数据类型转换来优化内存;在均匀分配初始种子点之前,增加APMMD算法来解决初始聚类中心不合理导致聚类结果局部最优的问题,可在一定范围内防止种子点落在梯度较大的轮廓边界上。通过边界召回率和欠分割错误率验证了所提算法,发现其颜色空间转换时内存减少1.5 M,聚类时准确率提高了8.1%。
关键词:超像素;聚类;SLIC;APMMD
中图分类号:TP181文献标志码:A文章编号:1671-5276(2024)03-0141-05
Research on Image Segmentation Algorithm Based on Combination of SLIC and APMMD
Abstract:A superpixel is a small region consisting of a series of pixel points with similar features and adjacent positions. The use of superpixel segmentation can both reduce the complexity of image segmentation and better preserve local information and edge information. For the requirements of tube wall stain recognition and parts box part classification, SLIC is used in combination with the nearest neighbor propagation based maximum minimum distance algorithm (APMMD) to achieve better image segmentation results. The method optimizes memory by data type conversion during color space conversion according to the steps of traditional SLIC algorithm. Before uniform assignment of initial seed points, the APMMD algorithm is added to solve the problem of unreasonable initial clustering centers leading to locally optimal clustering results, which can prevent seed points from falling on contour boundaries with large gradients within a certain range. The proposed algorithm is verified by the boundary recall rate and under-segmentation error rate, and it is found that its memory is reduced by 1.5 M during color space conversion, and the accuracy rate is improved by 8.1 percentage points during clustering.
Keywords:superpixel;clustering;SLIC;APMMD
0 引言
2003年,REN等[1]在研究中第一次提出了超像素的概念。简单的线性迭代聚类算法SLIC采用k均值方法高效地生成超像素。k均值方法采用距离作为相似性指标,将数据分为k组,随机选取k个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心的距离,把每个对象独立地分配给距离它最近的聚类中心[2]。此时,聚类中心和它的对象就是一个聚类。但是该方法使用聚类中所有点的均值作为新的中心点,如果簇中存在异常点将导致均值偏差较为严重,并且可能只能收敛到局部最优[3]。分析上述两种缺点,发现传统的k均值聚类算法对管壁污渍识别和零件盒零件分类并不能实现很好的分割效果。
近年来,在图像分割、目标检测识别方面的超像素分割方法得到了快速发展,特别是在工业视觉方面。本文采用王美琪等[4]提出的近邻传播最大-最小距离算法来代替SLIC的Kmeans聚类方法。该算法考虑了近邻传播算法,具有更高的鲁棒性及能够保证收敛到全局最优的特点,用其来获取K1个候选中心点;然后再从K1个候选中心点中通过最大-最小距离算法选取K个点作为初始聚类中心,很好地避免了随机性,对更复杂的聚类形状适应性好。通过实验发现将该方法用于SLIC算法较传统SLIC算法有着更好的分割结果,迭代次数减少,边缘分割更为明显且分割效果更好;缺点是会在单个物体内部产生一些无关边界,主要是由于连通性较差引起的,但该边界对分割结果的准确率不会产生太大影响。
1 传统SLIC算法
2010年,ACHANTA等[5]提出了局部聚类算法SLIC,该算法基于Lab颜色距离dc和空间距离ds,能很好地保留下一步的有效信息,并且对图像的边界信息保留很好。SLIC的三大要素分别是:RGB图像空间转换至Lab颜色空间、初始化种子点选取及调整、颜色距离和空间距离的计算。SLIC分割的效果主要受这三大要素的影响,特别是种子点的选取和调整。
1.1 颜色空间转换
Lab相对于RGB空间来说有着更宽阔的色域和丰富的色彩,弥补了RGB模型从蓝色到绿色之间的过渡色彩过多和从绿色到红色之间缺少黄色及其他色彩的缺点。
1.2 种子点选取和调整
种子点是SLIC聚类的起点。现有的种子点选取是基于半自动的,可人为设定图像分割时所需的聚类中心个数,然后根据图像的大小均匀分配种子点。假设图片高h、宽w,人为设定种子点个数k,则超像素的尺寸为h×w/k,两相邻种子点距离为sqrt(h×w/k)。该半自动方式虽然适用范围广,但是对经验知识要求高,容易局部收敛。
种子点的调整与聚类的准确性息息相关。初始化种子点时,存在种子点落于轮廓边界的可能性;当该可能性发生时,聚类的效果和准确性将直线下降,故需对种子点进行调整。调整方式一般是将图片均分为多个3×3区域,然后计算每个3×3区域内的像素点的梯度值,找到梯度最小的位置,将种子点移动到该位置进行更新。
1.3 计算颜色距离和空间距离
颜色距离和空间距离主要用来判断该像素点属于哪个种子点,将其规划到距离最近的种子点,即:
式中:dc代表颜色距离;ds代表空间距离;Ns是类内最大空间距离;Nc表示最大颜色距离;D则为计算出来的最终聚类度量。
2 本文算法
本文算法的主要是从颜色空间转换时保存的数据类型和种子点的初始化选取两个方面考虑。主要方法是用APMMD算法来代替Kmeans算法的随机选取。
2.1 具体优化方向
1)颜色空间数据类型优化
Lab是由两个颜色通道(a代表绿色到红色的分量,b代表蓝色到黄色的分量)和一个亮度通道L组成的,是基于人类的视觉来设计的。相对于RGB空间来说,Lab有着更精确的颜色平衡,人眼对其感知也更加均匀[6]。在原始SLIC论文中,颜色空间转换时是采用double类型来保存转换结果,最后强制转换成整型,导致内存空间占用是直接用整型类型来存储的8倍。因此是RGB到Lab颜色空间的数据优化。本文采用直接将公式系数放大来避免double类型的方法,共分为两步:
a)RGB转XYZ空间,理论转换公式如下:
X=0.412 453×R+0.357 580×G+0.180 423×B(6)
Y=0.212 671×R+0.715 16×G+0.072 169×B(7)
Z=0.019 334×R+0.119 193×G+0.950 227×B(8)
上述公式中,由于原始X、Z分量的转换系数和分别是0.950 456和1.088 754,两者都不为1,因此需对其进行归一化处理来修正系数,修正后X的转换系数为0.433 953、0.376 219、0.189 828;Z的转换系数为0.017 758、0.109 477、0.872 765。由于公式里面存在大量小数系数,固X、Y、Z理论上都应该是浮点数,此时通过类型强制转换成整型可能会导致内存暴增并且效率十分低下。本文采用放大系数然后将结果右移的方法,很好地避免了类型强制转换和效率较低的缺点。值得注意的是,放大后的系数在保证不超过Int的最大范围时取值越大越好。最后,本文采用的转换公式为:
X=(455 033×R+394 494×G+199 049×B+524 288)20(9)
Y=(223 002×R+749 900×G+75 675×B+524 288)20(10)
Z=(18 621×R+114 795×G+915 161×B+524 288)20(11)
b)XYZ转Lab空间。由于前文通过公式求出XYZ分量的取值范围为[0,255],并且f(t)中的变量t的取值范围是[0,1],因此需将其归一化映射到[0,1]范围。最后XYZ到Lab的转换公式为:
Xn=Yn=Zn=1(12)
f(t)=t1/3, tgt;(6/29)3(13)
f(t)=1/3×(29/6)2×t+4/29, t≤(6/29)3(14)
L=116f Y/Yn-16(15)
a=500f X/Xn-f Y/Yn(16)
b=200f Y/Yn-f Z/Zn(17)
式中:Xn、Yn、Zn为参考白点的XYZ三色刺激值;f(t)为计算颜色空间转换的函数,将其分为两段是为了避免在t=0处出现无限斜率。
根据上述的理论分析,将本文方法与原始论文中采用的转换方法对比,对一幅480 px×640 px的图片进行RGB转Lab,从表1可以看出,通过python运行其速度和内存都有很大的进步。
2)初始化种子点优化
Kmeans算法是一种十分典型的基于距离的算法,它认为两个点之间距离越小就越有可能属于同一个样本[7]。本文为了去除Kmeans随机性而导致的局部收敛,在SLIC的种子点均匀选取之前增加近邻传播最大-最小距离算法。该方法首先通过AP算法获得K1个具有代表性的候选中心点;该候选点是从全局寻找的最优点,它对数据的初始样本是不敏感的,并且不会存在远离聚类的异常点。然后再通过最大-最小距离算法从K1中选出K个初始种子点。选取原则为:①选取距离最远的两个候选点作为前两个聚类中心Z1、Z2;②计算其余所有点分别与Z1、Z2的距离Di1、Di2,比较Di1、Di2,选择其中较小的一个;③将上一步获取的所有值进行比较,选择最大值对应的点作为第三个聚类中心Z3;4)若Z3存在,则计算剩余的点分别与Z1、Z2、Z3的距离Di1、Di2、Di3,重复②、③,选择出第四个聚类中心;⑤以此类推,直到聚类中心数量满足要求为止。最后,将获得的初始聚类中心采用Kmeans的迭代方法更新聚类中心点,直至聚类收敛。
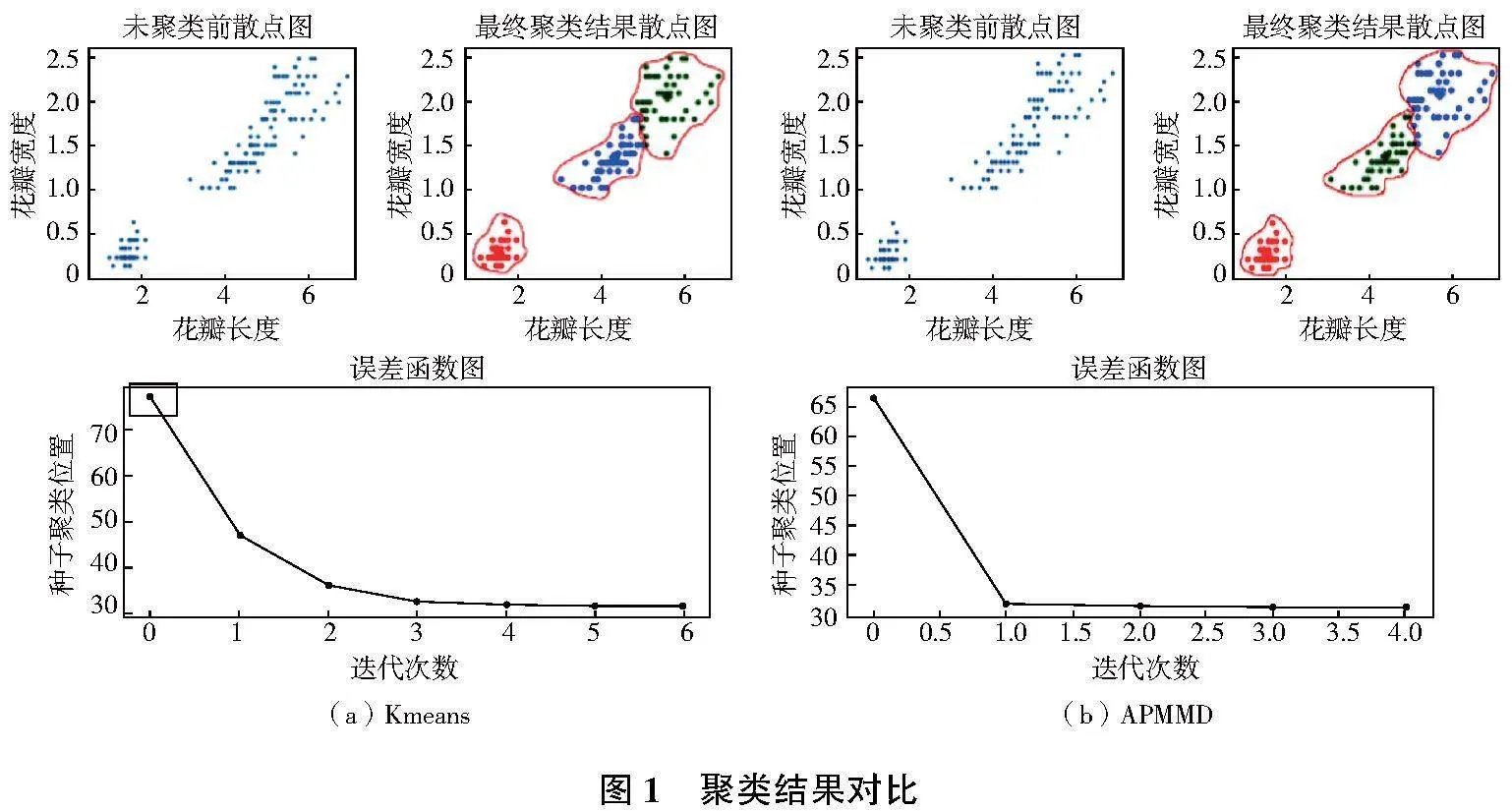
对Iris数据集采用Kmeans聚类算法和近邻传播最大-最小距离算法。从图 1可以看出,Kmeans聚类算法由于初始聚类中心是随机选择的,初始误差较大,导致其后续迭代次数增加,而迭代次数增加必定导致时间消耗和内存占用增加,聚类中心更改的范围较大;而近邻传播最大-最小距离算法获得的初始聚类中心对Iris数据集是基本适用的,并且该适用性也增加了每次迭代收敛的速度,APMMD获得的初始聚类中心与最终聚类中心也较为接近。最后对两种算法的准确率ACC进行比较:ACC,Kmeans=0.892,ACC,APMMD=0.973。
2.2 算法流程图
综上所述,算法流程图如图 2所示。
3 图像分割验证实验
3.1 实验结果图分析
图像分割是指按照一定的相似性准则将图像划分成具有特殊语义的不同区域[8];具体可分为3类:基于图论的方法、基于梯度下降的聚类方法和基于深度语义的方法。而SLIC就是基于梯度下降的聚类方法中的一种,除此之外还有分水岭方法和Mean-shift方法[9]。
本文采用基于LY公司数字化装配项目实拍的零件盒及其内零件的数据集来验证SLIC与APMMD算法结合的图像分割结果。如图 3所示,本文算法的效果明显优于原始SLIC算法。譬如在超像素平均尺寸为20时,第1行图像中零件盒里第1列中第2个零件和第3个零件的轮廓在本文算法中清晰完整地呈现出来了;而在SLIC算法中,第2个零件和第3个零件的轮廓就没能完全分割出来。第2行图像中也是本文算法轮廓分割较好;但其中也显示了两个算法都具备的一个缺点:连通性较差,易将两个像素差距较小的零件分配给同一超像素。第3行图像用来证明该结合方法的适用性,从图中可以看出,SLIC会将天鹅翅膀的羽毛棱角分配给湖面的超像素,而天鹅翅膀轮廓在本文算法中清晰可见。如图 4所示,发现当超像素平均尺寸减少时,本文结合算法和原始SLIC算法分割效果都有一定的改善;但是不宜过小,会导致超像素块变成为像素点,其无关边界会增加,失去了超像素更好的特征表达能力。因此,建议超像素平均尺寸的大小控制在20左右,这样不会产生较多的过分割轮廓,分割效果也符合期望值。
3.2 评价指标
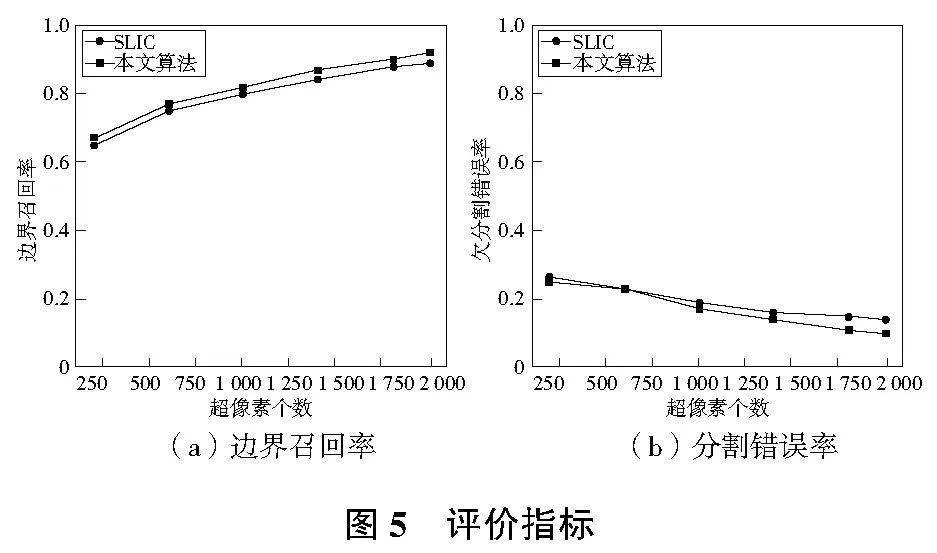
对结果图像的分析,可以从视觉方面发现两者的优劣,但缺少有效性方面的证明。因此,通过计算两者的边界召回率和欠分割错误率来对有效性进行证明(图5)。边界召回率指的是正确预测为边界的值占所有边界的比重;欠分割错误率指的是前景目标误识别为背景的部分占前景目标整体的比重。
由图 5可以明显看出,采用APMMD初始聚类中心的方法分割效果明显优于Kmenas的随机选取方法。
4 结语
本文通过对经典SLIC算法的实现步骤进行分析,从RGB转Lab颜色空间和采用APMMD算法初始化种子点两方面对其进行优化,进行了实验验证,证明了颜色空间转换时速度和内存都有进步;种子点聚类时,聚类准确率提高、迭代次数下降。
实验中也发现:本文算法存在过分割的可能性,且容易生成无关边界,特别是对亮度高的物品生成的无关边界更多。因此,下一步的研究方向可以从增强连通性、去除无关边界两方面考虑。
参考文献:
[1] REN X F , MALIK J. Learning a classification model for segmentation[C]//Proceedings Ninth IEEE International Conference on Computer Vision. Nice,France:IEEE,2008:10-17.
[2] 周丽娟,王慧,王文伯,等. 面向海量数据的并行Kmeans算法[J]. 华中科技大学学报(自然科学版),2012,40(增刊1):150-152.
[3] 程艳云,周鹏. 动态分配聚类中心的改进K均值聚类算法[J]. 计算机技术与发展,2017,27(2):33-36.
[4] 王美琪,李建. 一种改进K-means聚类的近邻传播最大最小距离算法[J]. 计算机应用与软件,2021,38(7):240-245.
[5] ACHANTA R,SHAJI A,SMITH K,et al. SLIC superpixels compared to state-of-the-art superpixel methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2274-2282.
[6] DONG L L , ZHANG W D , XU W H. Underwater image enhancement via integrated RGB and LAB color models[J]. Signal Processing:Image Communication,2022,104:116684.
[7] 刘江华. 一种基于kmeans聚类算法和LDA主题模型的文本检索方法及有效性验证[J]. 情报科学,2017,35(2):16-21,26.
[8] 宋熙煜,周利莉,李中国,等. 图像分割中的超像素方法研究综述[J]. 中国图象图形学报,2015,20(5):599-608.
[9] 王春瑶,陈俊周,李炜. 超像素分割算法研究综述[J]. 计算机应用研究,2014,31(1):6-12.
猜你喜欢
铁道通信信号(2019年6期)2019-10-08 09:02:40
电子测试(2017年15期)2017-12-18 07:19:27
雷达学报(2017年6期)2017-03-26 07:53:02
光学精密工程(2016年5期)2016-11-07 09:05:53
互联网天地(2016年1期)2016-05-04 04:03:17
自动化学报(2016年8期)2016-04-16 03:38:58
现代计算机(2016年17期)2016-02-28 18:35:32
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
河南科技(2014年23期)2014-02-27 14:19:14
