
基于Swing 的HTML解析器的实现与应用
2024-08-31 00:00:00宋宇
科技资讯 2024年14期


摘要:HTML页面解析是一切工作的基础,通过分析HTML解析器感兴趣的标签以及超链接的分类,在Java的Swing包的基础上实现了一个HTML解析器,用来提取HTML文档的超链接和锚文本;然后把HTML解析器应用到多媒体信息检索系统的搜索器Spider的开发中,通过设定若干个种子网站,选择合适的搜索算法,从中筛选出包含音频、视频和Flash动画的web页面,并将其存放在数据库中。
关键词:解析器HTMLSwing超文本链接链接文本
中图分类号:G250
ImplementationandApplicationofHTMLParserBasedonSwing
SONGYu
LibraryofNanjingUniversityofChineseMedicine,Nanjing,JiangsuProvince,210023China
Abstract:HTMLpageparsingisthefoundationofallwork.ByanalyzingthetagsandclassificationofhyperlinksthatHTMLparsersareinterestedin,anHTMLparserhasbeenimplementedbasedonJava'sSwingpackagetoextracthyperlinksandanchortextfromHTMLdocuments; Then,theHTMLparserisappliedtothedevelopmentofthesearchengineSpiderformultimediainformationretrievalsystems.Bysettingseveralseedwebsitesandselectingappropriatesearchalgorithms,webpagescontainingaudio,video,andFlashanimationsarefilteredoutandstoredinadatabase.
KeyWords:Parser;HTML;Swing;Hyperlink;Linktext
HTML是一种标记语言,其目的在于运用标记(tag)使文件达到预期的显示效果;由于其简单易学的特点,就算在各种Web设计语言竞争发展的今天,它在Web设计中仍然具有无法被取代的地位,受到众多Web设计人员的青睐;很多情况下,只需要HTML文档中的部分信息,基于这种需求,HTML的解析技术受到许多人的关注;尽管现在有好多现成类似的例子程序,但它们提取的信息未必适合需求,因此仍然需要编制符合要求的HTML解析器。
本文在Java的Swing包的基础上,对解析Web页面遇到的困难给以分析并提出相应的解决办法,对其中的关键技术给出详细说明,实现了一个用于提取超链接的HTML解析器;并把该解析器用用到多媒体信息检索系统的搜索器Spider[1-3]的开发中。
1HTML解析器的实现
Java中Swing[4]包的HTML解析器类Parser是HTMLEditorKit类的内部类,本文主要就是利用Parser类实现对HTML解析器的构建。
1.1解析器感兴趣的标签
HTML文档标签[5]大致分为两类:一类是传输数据的标签,如paragraph、table等,它们显示web站点包含的信息;第二类是基础结构标签(infrastructuretags),这类标签指示浏览器如何从当前页面跳转到其他页面,常见的有<A>、<Area>和<Form>,这类标签需要提取。由于最终要提取出包含音频、视频和Flash动画的页面,因此还需要提取包含这些多媒体数据的标签。在web页面中,这些多媒体数据可以以链接的形式出现,也可以嵌入Web页面中,以链接形式出现的多媒体数据包含在标签<A>中,嵌入Web页面中的多媒体数据包含在标签<object>和<embed>中。<embed>标签是Netscape的私有标签,用于Windows和Macintosh平台下的NetscapeNavigator浏览器以及Macintosh平台下的IE浏览器,这个标签应用虽然广泛,但并未被w3c收录,因此使用此标签的Web页面将通不过w3c校验。<object>标签w3c推荐使用,用于Windows平台的IE浏览器,但这个标签在IE5-IE6/Win上必须下载完才能正常显示。为了中和这两者之间的矛盾,几乎所有的Web设计者在嵌入多媒体数据时,同时使用这两个标签即把<embed>标签嵌套放在<object>标签内;因为这两者包含的多媒体文件是同一个,因此在实际提取过程中,只提取一个即可;由于<embed>标签未被w3c收录,所以在Swing包中并不支持这个标签,因此只通过<object>标签来提取(其实多媒体文件的路径是包含在这个标签的<param>标签中);除此之外,还要提取标签<Base>和<Frame>,各标签的作用如表1所示。
1.2超链接解析与分类
该解析器重点解析的信息是超链接,超链接包括链接地址URL和链接文本,其中链接地址URL包括两类:绝对URL和相对URL。绝对URL是包含首页域名的完整的网址,带有http和www的链接,唯一确定一个页面,而相对URL是不完整的,它依赖于它所在的页面,要想解析相对URL,必须将它转换为绝对URL。
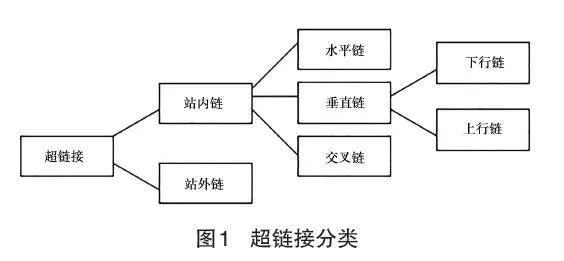
页面中的超链接反映的是页面相互之间的逻辑关系,按照不同的标准和目的,可以区分为不同的类别。本文根据需要,把超链接分为站内链接和站外链接。对于站内链接又分为四类:(1)下行链,目标页面是当前页面的下级页面;(2)上行链,目标页面是当前页面的上级页面;这两种类型是定义在Web站点逻辑层次结构的垂直方向上的,统称为垂直链;(3)水平链,目标页面和当前页面处于同一目录;(4)交叉链,目标页面和当前页面不在同一路径上。从以上描述可以看出,这种分类方法是根据页面的物理结构来区分的。超链接分类如图1所示。
2.3实现过程
(1)建立TCP连接:首先通过DNS解析获取改页面对应的IP地址,然后通过URLConnection建立与TCP连接,这个过程包括3次握手,以确保连接的可靠性。
(2)发起HTTP请求:向服务器发送HTTP请求,请求中包含请求行、请求头和请求正文。请求行描述了客户端的请求方式、请求的资源名称以及使用的HTTP协议版本号。
(3)服务端进行HTTP响应:服务器接收到请求后,返回一个HTTP响应,该响应由状态码、响应头和实体内容组成。状态码用于表示服务器对请求的处理结果,如2xx表示请求成功,4xx表示客户端发生错误等。如果成功,将网页HTML代码通过输入流读入阅读器Reader中。
(4)调用解析器HTMLEditorKit.Parser对象的parse()方法,对HTML文档进行实际地解析。
(5)当遇到<A>、<Area>、<Map>等包含链接地址的标签,则提取出该标签的属性HREF值。
(6)同时提取该链接的锚文本,以作为该链接的内容描述,并确保链接URL值与锚文本之间的一一对应关系。
(7)将所有提取出来的链接URL和锚文本一并存入数据库中。
2HTML解析器的系统应用
将第二部分设计的HTML解析器应用到多媒体信息检索系统的搜索器Spider的开发中。首先给定若干种子网站,然后利用本文第二部分构造的HTML解析器、按照宽度优先的爬行策略遍历每个种子网站,提取出种子网站里所有包含音频、视频、Flash动画的网页。由于该搜索器刚开始做,所以目前只是在功能上的实现,效率不是太高,爬行策略会在接下来的研究中继续优化。该系统大体包括5个模块:种子链接初始化模块、HTML解析模块、爬行模块、目标网页提取模块、存储模块。
在该系统中,HTML解析模块在本文的第二部分有详细的说明,在此就不在展开叙述,该部分重点对该系统的其他4个模块的作用与实现进行阐述。
2.1种子链接初始化模块
种子链接的提供一般有3种方法。第一种是手工寻找,这种方法由于有了人的判断与筛选,选择出的种子链接的质量比较高,它一般包含较多的目标页面;其缺点也是显而易见,这种方法耗时耗力。第二种方法是通过元搜索引擎来提供,这种方法与第一种方法相反,虽然省去了人工的找寻阶段,但其提供的种子链接的质量没有保证。第三种方法是允许用户把他们自己的网站提交,经确认后加入种子链接列表,这种方法一般作为一种辅助手段,来配合前两种方法进行。由于目前这个系统还在试验阶段,并为投入运行,因此手工选择了20个包含音频、视频、Flash动画较多的网站进行测试,在以后会加入其他两种方法来进行种子链接的初始化。
2.2爬行模块
在这一模块,利用第二部分设计的HTML解析器,提取出页面的所有链接,通过对链接进行过滤,只保留与网页文本的链接,然后按照宽度优先的访问策略依次遍历所有链接。在此,为了尽量避免遍历到无关链接,对链接的访问进行控制,指访问其内部链接,而对外部链接暂时不考虑(但会在以后的研究中对其价值进行判断,据此来决定此链接的取舍)。其判断方法如下:将超链接的URL地址与源网页的URL地址进行比较,如果两地址只是在最后一个“/”间隔符后面的字符不同,则此链接为内部链接,称此链接与源链接有“亲族”关系,按照与源链接的远近,又将这种“亲族”关系细分为“父子”关系(指在物理存储上该链接位于源链接所在目录的一个子目录中)和“兄弟”关系(指在物理存储上该链接与源链接处在同一目录下),若该链接与源链接不是“亲族”关系,将其舍弃;通过这种处理后,每个种子链接将形成一棵“链接树”,通过这棵树对该网站的链接进行大体分类,每个类别下的网页存在某种程度的相关性,为将来寻找目标页面提供了便利;多个种子链接将形成多棵“链接树”,它们共同形成“超链接树林”;
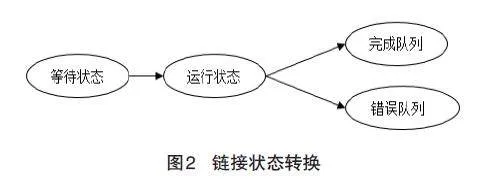
为了避免对链接的重复访问,为每个链接设置了访问状态,通过访问状态把所有的链接分为4个队列:(1)等待队列,处于该队列的链接表示等待被访问,访问状态为W;(2)运行队列,处于该队列的链接表示正在被访问,访问状态为R;(3)完成队列,处于该队列的链接表示已经被访问完毕,访问状态为C;(4)错误队列,处于该队列的链接表示在访问过程中发生错误,访问状态为E;在任一时刻,一个链接只能属于一个队列,称之为链接状态,一个链接的链接状态转换如图2所示。
2.3目标网页提取模块
这一模块的作用是在爬行模块形成的“超链接树林”中寻找包含音频、视频、Flash动画的页面,目前采用的方法比较简单:依次取出“超链接树林”中的每个链接进行访问,通过本文第二部分构造的HTML解析器获得每个链接页面中的所有链接,如果所有的这些链接中有以音频、视频、Flash动画的扩展名结尾的链接,将该链接对应的页面提取出来作为目标页面。这种方法简单易行,并且不会漏掉目标页面,即查全率比较高;但其缺点也很明显,因为这种方法要对每个链接都要判断一遍,所以效率太低,即查准率太低。下一步会对这一模块重点进行改进,对每一链接的价值根据页面内容和链接结构等提示性信息进行判断,根据链接的价值大小,决定是否访问此链接及访问的顺序。
2.4存储模块
在这一模块,采用Access数据库分五个表对数据进行存储,第一张表是SeedLink,这张表用来存放种子链接,其结构如图3所示。
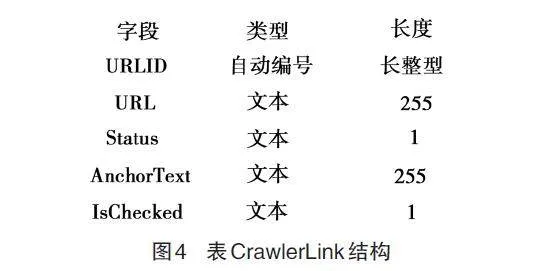
第二张表是CrawlerLink这张表用来存放中间链接,即从种子链接中得到的所有内部链接,也就是在爬行模块中提到的“超链接树林”中的所有链接,之所以也把中间链接也存储在数据库中而没有放到内存中,是因为随着链接的增多,在内存中存放链接时,其运行效率会逐渐下降,其结构如图4所示。
第三张表是Video,第四张表是Audio,第五章表是Flash,这3张表是用来存放包含视频、音频和动画的页面信息,其结构相似,表Video的结构如图5所示。
3结语
对HTML文档进行解析是好多与网页进行交互系统的基础,由于各个系统的目的不同,对网页元素的提取也各不相同,因此不存在一个通用的HTML解析器,因此本文构造了一个用来提取网页链接及链接文本的HTML解析器,并把此解析器应用到多媒体信息检索系统的搜索器Spider的开发中,目前该系统尚处在实验阶段,只是在功能上的实现,对爬行算法并未进行优化,在下一步的工作中,将在爬行算法上进一步研究。
参考文献
[1]刘晓旭.主题网络爬虫研究综述[J].电脑知识与技术,2024,20(8):97-99.
[2]郭婺,郭建,张劲松,等.基于Python的网络爬虫的设计与实现[J].信息记录材料,2023,24(4):159-162.
[3]古志敏,吴明珠.基于Python网络爬虫设计与实现[J].电脑编程技巧与维护,2023(9):163-166.
[4]王勇,洪进,杜兰兰,等.基于JavaSwing的找点软件设计与实现[J].现代计算机,2022,28(16):96-100.
[5]杨大为,王诗念,包立岩,等.基于文本及HTML标签密度的网页正文提取[J].沈阳理工大学学报,2022,41(4):14-19.
