
基于双向时间卷积网络的半监督日志异常检测
2024-08-17 00:00:00尹春勇孔娴
计算机应用研究 2024年7期
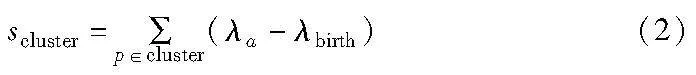

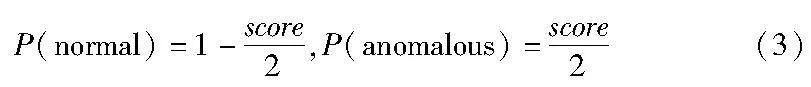

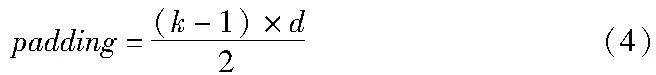




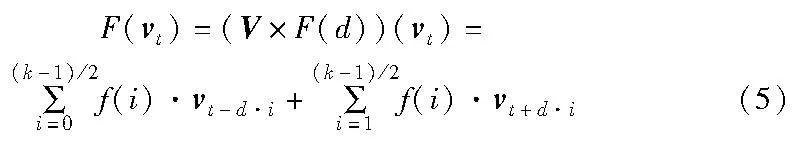
摘 要:由于日志解析准确率不高以及标记样本不足降低了异常检测的准确率,所以提出了一种新的基于日志的半监督异常检测方法。首先,通过改进字典的日志解析方法,保留了日志事件中的部分参数信息,从而提高日志信息的利用率和日志解析的准确率;然后,使用BERT对模板中的语义信息进行编码,获得日志的语义向量;接着采用聚类的方法进行标签估计,缓解了数据标注不足的问题,有效提高了模型对不稳定数据的检测;最后,使用带有残差块的双向时间卷积网络(Bi-TCN)从两个方向捕获上下文信息,提高了异常检测的精度和效率。为了评估该方法的性能,在两个数据集上进行了评估,最终实验结果表明,该方法与最新的三个基准模型LogBERT、PLELog和LogEncoder相比,F1值平均提高了7%、14.1%和8.04%,能够高效精准地进行日志解析和日志异常检测。
关键词:日志解析; 异常检测; 半监督学习; 双向时间卷积网络; 上下文相关性
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2024)07-026-2110-08
doi:10.19734/j.issn.1001-3695.2023.10.0507
Semi-supervised log anomaly detection based onbidirectional temporal convolution network
Abstract:Because the accuracy of log parsing is not high and the lack of tag samples reduces the accuracy of anomaly detection, this paper proposed a new semi-supervised anomaly detection method based on logs. Firstly, the method enhanced the log parsing method of the dictionary to retain parameter information in log events, improving the utilization and accuracy of log resolution. Next, the method utilized BERT to encode semantic information in the template, obtaining the semantic vector of the log. Then, the method employed the clustering method to estimate the tag, which effectively alleviated the problem of insufficient data labeling and enhanced the model’s ability of detecting unstable data. Finally, the method captured context information from two directions based on the bidirectional temporal convolution network(Bi-TCN) with residual blocks, which enhanced the accuracy and efficiency of anomaly detection. To evaluate the method’s performance, it conducted extensive experiments on two datasets. The results demonstrate that the proposed method achieves an average improvement of 7%,14.1% and 8.04% in F1 value compared to the latest three benchmark models, LogBERT,PLELog and LogEncoder, enabling efficient and accurate log parsing and log anomaly detection.
Key words:log parsing; anomaly detection; semi-supervised learning; bidirectional temporal convolution network; contextual correlation
0 引言
随着大型系统的规模和复杂性日益增加,一些外部故障或内部错误都可能引起系统崩溃,有必要及时并准确地检测出系统中的异常,以确保系统的可靠性和稳定性,从而减轻不必要的损失[1]。系统日志是指现代网络设备、系统及服务程序等在运行过程中产生的具有记载系统状态和事件信息的记录。通过对日志的分析,可以识别偏离预期行为或模式的日志序列,进行故障排除和问题诊断。因此,日志文件在监控网络情况、维护系统稳定、调试性能问题和保护软件安全等方面有重要的作用。
日志数据通常是由源代码中日志语句打印的半结构化的文本字符串组成,详细记录了操作信息,包含应用状态、程序执行逻辑、事件信息等。随着系统的发展,日志事件和日志序列的更迭导致日志语句不断演化。不同类型的设备包含多样的数据元素和不同的日志语法,因此日志具有多样性和非结构化的特点。通常在日志数据的采集、检索和预处理过程中,不可避免地会在原始日志数据中引入一定程度的噪声,导致日志数据具有不稳定性[2]。除此之外,分布式软件系统会产生大量具有复杂依赖关系的日志信息。因此日志数据的非结构性、不稳定性以及庞大的数据量都会给异常日志检测带来巨大的挑战。
早期,系统日志的异常检测依赖于运维人员的个人知识、技术及经验,人工检查分析大量日志信息,难以得出有效的分析和检测。随着人工智能技术的不断发展,越来越多基于机器学习的数据挖掘与异常检测方法应运而生,这些方法能够自动地从运维数据中学习日志事件之间的内在关系并总结规则,实现了日志异常检测的自动化,增加了异常检测的效率和准确率。
现有采用深度学习技术的异常检测方法分为监督学习、无监督学习和半监督学习三大类。监督学习方法SwissLog[3,4]、LightLog[5]依赖于大量已标注的训练数据,可以有效学习历史日志信息,但基于日志数据异构、大量且不稳定的特性,需要大量人工标记工作的监督学习方法并不实用。无监督异常检测方法如DeepLog[6]、LogAnomaly[7],基于训练数据大部分是正常日志的先验条件,对噪声敏感,在实际中遇到看不见的日志事件或序列有效性会降低。而半监督学习使用部分标记数据和大量未标记的数据进行模式识别工作,尽可能减少人工标记成本,同时又能带来比较高的准确性。
日志数据集作为时序数据的一种,大多深度学习的异常检测方法DeepLog、LogRobust、SwissLog等使用循环神经网络(recurrent neural network,RNN) 以及相关变体进行日志序列特征学习。然而RNN每两个相邻神经元是相互连接的,计算当前的隐藏状态需要计算之前的隐藏状态,因此不支持并行计算,训练时间开销大,且处理长序列时可能出现梯度消失或爆炸的问题,虽然长短期记忆网络(long short-term memory,LSTM)和门控循环单元网络(gate recurrent unit,GRU)可以减缓但也不能完全杜绝。此外,RNN在从日志序列获取信息时,由于每个隐藏状态仅记住部分信息,会随着时间的增长被遗忘,所以稳定性不佳。时间卷积网络(temporal convolution network,TCN)[8]不仅可以通过一些层的堆叠来捕捉序列数据的时间属性,而且可以并行化处理,解决了建模远程关系时的梯度爆炸和消失问题,在内存消耗和处理速度方面具有显著优势,能够更快地获得稳定的模型。
与此同时,基于深度学习的日志异常检测方法性能对日志解析的正确性依赖较高,然而现有的日志解析方法无法应对频繁变化的日志语句,普遍需要经过预先调参,存在过度解析丢失日志事件中价值信息的问题。基于频繁项挖掘的方法FT-tree[9]、基于最长公共子序列的方法Spell[10]、基于启发式方法Drain[11]是日志异常检测使用最频繁的几种解析方法。FT-tree方法在时间、空间上开销大;Spell仅基于最长公共子序列的策略会导致分区不足,且没有限制其前缀树的深度,直接计算两条日志事件之间的最长公共子序列,比较耗时;Drain在准确性、健壮性和效率性方面具有优势,但其将日志过度解析为可变部分,会丢失重要信息,容易导致误报。在SwissLog中提出了一种基于字典且无须参数调整的日志解析方法,可以保留日志语义含义,并可以高效地正确解析日志。
本文提出了一种新的基于日志的半监督异常检测方法,命名为BTCNLog(log anomaly detection based on Bi-TCN)。首先,通过改进的基于字典的日志解析方法进行日志解析;然后,使用BERT[12]对日志模板进行编码,充分表示日志语义信息;接着,受PLELog[13]方法的启发,采用层次聚类方法初步估计未标记的日志序列的标签并赋予标签概率,可以学习历史异常日志信息;最后,采用带有残差块的双向时间卷积网络从两个方向捕获上下文信息,对日志数据进行有效异常检测。
本文的主要贡献有:a)提出了一种新的基于日志的半监督异常检测方法BTCNLog,引入带有残差块的双向时间卷积网络从两个方向捕获上下文信息,从而更好地捕获日志序列的特征,提高了异常检测的精度和效率;b)结合日志数据的特性改进了日志解析方法,保留了部分参数语义信息,提高了日志信息的利用率和日志解析的准确率;c)为了缓解数据标注不足问题,采用聚类的方法进行标签估计,学习历史异常日志信息;d)通过三个公共数据集上对模型进行对比实验和消融实验,证明了本文方法的有效性。
1 相关工作
1.1 日志解析
日志解析是一个将非结构化数据转为结构化数据的过程,具体而言,通过技术将已知日志事件中日志关键字和参数拆分并统一模板的过程。目前,日志解析是许多日志异常检测方法的基本步骤,现有方法可以分为以下几类:
a)基于聚类的方法。主要假设是同类的日志事件或签名之间具有相似性,通过计算它们之间的距离,根据相似性进行聚类,在每个聚类中提取日志模板,代表方法有LKE[14]和LogMine[15]。
b)基于频繁模式挖掘的方法。通过挖掘日志事件中项的频率,提取日志中频繁出现的一组常量项形成日志模板,代表方法有LFA[16]和FT-tree。
c)基于日志结构启发式方法。利用日志结构中不同的属性,使用机器学习等启发式方法提取通用模板,代表方法有Drain、IPLoM[17],其中Drain是一种基于固定深度树的在线日志解析方法,能够以流的方式准确、高效地从原始日志事件中自动提取日志模板。
d)基于字典的方法。通过现有日志模板来构造字典,再用于日志解析的方法。Logparse[18]将模板生成问题转换为词分类问题,并学习模板词和变量词的特征。Logram[19]是利用n-gram字典实现自动日志解析方法。
e)其他方法。Spell使用最长公共序列算法在线搜索日志组解析流中的日志。NuLog[20]是一种基于掩码语言建模分析上下文中出现的标记来学习日志数据的一般语义表示。
1.2 日志异常检测
异常检测过程是使用机器学习等方法对特征向量进行学习,从而生成异常检测的模型,该模型可用于对新的日志进行检测[21]。现有日志异常检测方法可以分为数据挖掘和深度学习方法。
数据挖掘的方法有逻辑回归(logistic regression,LR)[22],其将日志序列构造成事件计数向量,利用计数向量和标签训练逻辑回归模型,计算测试用例的异常可能性并设置阈值区分出异常日志。支持向量机[23]同样将日志序列表示为事件计数向量,如果测试用例位于超平面之上则其为异常日志。基于聚类的无监督学习方法LogCluster[24]通过事件计数向量表示日志序列,对日志序列进行聚类,每个簇的质心为代表性向量。通过计算新日志序列向量与所有现有集群代表向量之间的距离来检测异常。此类基于数据挖掘的日志异常检测方法通常将日志表示为日志事件计数向量,无法捕获日志事件的语义信息,异常检测效果不稳定。
基于深度学习的日志异常检测方法可以更好地学习日志序列中日志事件之间的内在关系,对异常日志的检测有较高的精确率和鲁棒性。监督方法中,LogRobust采用Drain方法进行日志解析,通过预处理、词向量化并结合词频-逆文档频率(term frequency-inverse document frequency,TF-IDF) [25]将日志事件转变为语义向量,使用基于注意力的双向长短期记忆神经网络(bidirectional long-short term memory,Bi-LSTM)学习不同日志事件的重要性,可以处理不稳定的日志序列。SwissLog利用基于字典无须参数调整的日志解析方法进行解析,并使用BERT编码器对模板中的语义信息进行编码,最后基于注意力的BJ2Jx2DeswPIXWzW+DPWXqOdr3yrevS785yZfbAbjUVM=i-LSTM模型进行日志异常检测。LightLog方法基于word2vec[26]和后处理算法获得低维语义向量,通过轻量级时间卷积网络实现在边缘设备上的日志异常检测。上述监督学习方法需要人工对大量日志进行标注,十分耗时。无监督方法中,Logsy[27]方法使用辅助数据集的正常日志序列增强数据表示,将注意力机制与Transformer编码器相结合来进行异常检测。OC4Seq[28]将一类分类器与GRU网络相结合,在日志序列上分别进行全局和局部的异常检测。此类无监督学习的方法只关注历史正常日志序列的信息,忽略了历史异常日志序列的信息。
2 BTCNLog模型总体框架
现有基于日志异常检测的方法通常都包含日志收集与预处理、日志解析、特征提取和异常检测四个步骤。本文BTCNLog日志异常检测模型总体框架如图1所示。在训练阶段,首先对原始日志条目进行预处理、日志解析提取模板,并将模板进行向量化提取日志语义向量。然后,将日志条目分组成日志序列,对训练日志序列数据进行聚类标签估计,得到伪标签。最后将带有伪标签的日志序列语义向量输入Bi-TCN,进行异常检测模型训练。在测试阶段,同样对新的原始日志进行处理获得日志序列及对应的日志序列语义向量,输入训练好的模型进行异常检测。
2.1 日志解析和向量化
日志解析是将原始日志经过预处理,提取日志模板的过程。日志的向量化是指将日志提取的模板语句嵌入语义向量,得到可以进行模型训练的日志数据,最后结合日志分组得到日志序列及对应的日志序列向量。
2.1.1 预处理
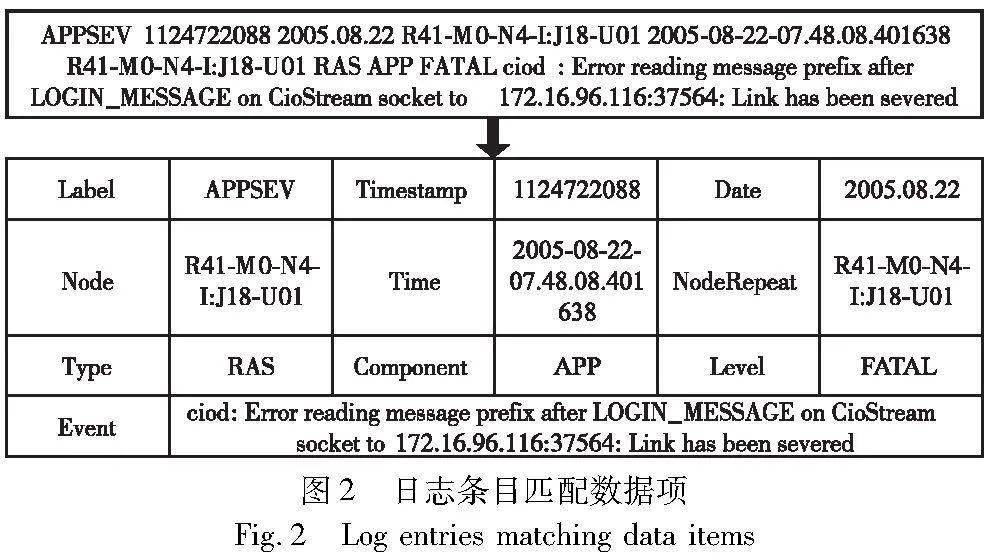
预处理日志数据是日志处理的第一步。不同系统日志条目会包含时间戳、日志消息等级和日志事件等不同的日志数据项,因此需要根据日志数据集的框架,使用正则表达式匹配各个数据项,如图2所示。
其中显示了一条BGL数据集日志条目,当标签Label为“-”时表示正常日志,否则为异常日志。日志类型level可以粗略区分日志的等级,但不足以将异常日志和正常日志完全区分,而日志事件event是描述事件具体发生的非结构化文本,蕴涵丰富的日志信息,因此是进行日志分析和异常检测的主要数据来源。如果将原始日志事件直接向量化,则会出现词汇量过多、无效词过多的问题,给日志异常检测带来许多噪声,影响训练效果。因此将事件中的日志公共变量,例如IP地址、八进制数、日期等,利用正则表达式分别替换成对应标记,而不是被统一的变量通配符替换,这样不仅可以保留部分变量的语义信息,还可以通过正则表达式筛选出不符合规则的变量。接下来对日志事件进行日志解析,将描述系统事件的日志关键字部分和日志参数部分进行分离。
2.1.2 日志解析
传统日志解析方法例如使用最频繁的Spell和Drain方法都需要对不同日志分别进行预训练调参才能达到最佳解析结果。此外,还会因正常日志和异常日志存在过多相同内容而导致日志关键字部分被过度解析成参数部分。目前日志事件大多都是基于英文单词组成具有一定可读性的语句,因此基于字典的日志解析方法,可以保留有效词的语义信息,缓解过度解析的问题。其中SwissLog使用了此类日志解析方法。
首先,对每个日志事件进行分隔并形成一组单词标记。由于日志事件中包含许多特殊符号,所以采用空格及日志中常用的特殊分隔符来分割日志事件字符串。根据引入的字典,将所有的单词标记进行字典化,有效单词放入单词集中。然后,将日志事件根据单词集进行集群,具有相同单词集并且每个单词词频相同的日志事件被归为同一集群,每个集群使用最长公共序列提取维护一个模板。接下来,将所有不同集群获得的粗略模板按照顺序生成前缀树,用来整合最终的模板。
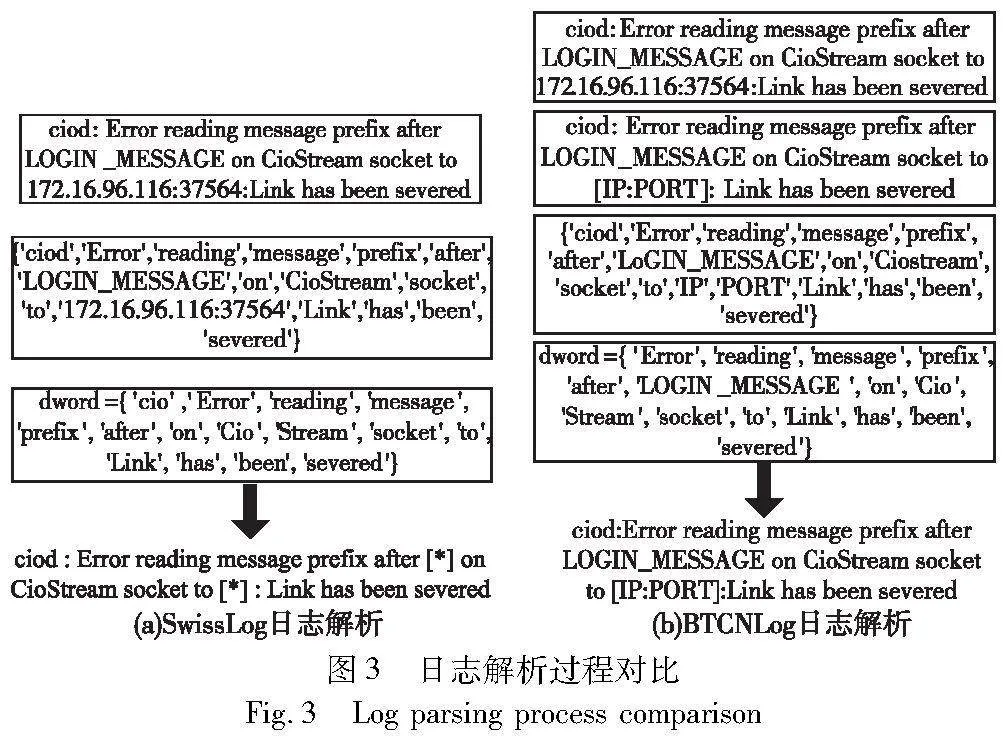
然而SwissLog在依据有效词的单词集进行集群时,当日志事件中无有效词或有效词单一较少时,有被解析为0模板或其他模板的可能性,导致大量0模板或模板解析错误,影响日志序列上下文依赖性的提取。因此本文在选择日志事件单词集时,额外加入了由下画线或其他连字符组成的有效单词,并将其存入分词缓存字典。此外,针对分词器wordninja会产生错误拆分单词的问题,本文对其拆分后的单词作进一步筛选,确保拆分的正确性,可以大大减少解析为0模板和其他模板的可能性。图3(a)是SwissLog日志解析处理过程,其将单词“ciod”错误拆分为“cio”和“d”,并且将“LOGIN_MESSAGE”视为无效词,而该单词在一定程度上蕴涵语义。图3(b)是BTCNLog日志解析处理过程,可以看出本文的日志解析方法,结合日志事件中单词的特性,保留了日志事件中的部分参数信息,从而减少了传统日志解析中,因解析不准确降低日志异常检测方法的性能。
2.1.3 BERT语义向量化
下面对每个日志事件转换的日志模板进行向量化。传统上,日志事件的单词通过使用word2vec或GloVe[29]方法进一步转换为向量,然后根据单词向量计算每个句子的表示向量。但是,此类方法生成的向量不包含上下语义信息,不能解决同义词问题。为了更好地捕捉单词的上下语义信息和词性差异,BTCNLog使用BERT作为词嵌入的方法。BERT词嵌入模型的核心是Transformer编码器,使用双向自注意力机制能够学习到单词上下文的相关性,能够根据周围的单词动态地产生单词表示形式。
在本模型中,利用预先训练好的BERT模型来获取日志事件的语义信息,该模型在维基百科语料库和图书语料库上进行了训练,包含12层Transformer的编码器,其中每个Transformer有768个隐藏单元。
2.1.4 日志分组
本文使用了滚动窗口和会话窗口结合的分组策略对日志序列进行分组,可以减少同一个事务的日志数据被分到不同日志序列中的情况,从而提高本模型的日志序列上下文依赖性的提取性能。
常规的日志分组方法包括滚动窗口、滑动窗口和会话窗口。 滚动窗口是基于日志时间戳数据取相同窗口大小的日志,互不重叠。滑动窗口也是基于日志时间戳数据,依据窗口大小和步长划分,其前后窗口会重叠。会话窗口是基于日志的会话标识符进行分组。然而系统会多个任务并发执行,导致日志的执行顺序可能会交错,因此基于日志时间戳分组的滚动窗口和滑动窗口会导致同一个事务的日志数据被分到不同日志序列中,影响日志序列上下文依赖性的提取。会话窗口会导致日志序列长度有较大差别。
本文采取基于日志时间戳结合日志条目中某个特定数据项将日志重排并固定窗口大小w进行日志分组。此日志分组方法基于数据项可以粗略划分日志事务的前提来选取数据项,例如node或user。可以一定程度上保证相同日志事务被划分到相同日志序列,并且不会产生日志序列长度相差太大的情况。若日志序列包含异常日志事件,则该日志序列为异常日志序列,否则为正常日志序列。
2.2 聚类估计标签
在已知部分正常日志序列的基础上,基于语义相似的日志序列更有可能共享相同标签的性质,通过聚类,进一步估计训练集中未标记日志序列的标签,从而融合监督方法的优点,可以学习到历史异常日志的信息。
基于密度群集的HDBSCAN[30]聚类算法可以处理密度不同的聚类问题,无须预定义聚类数量且参数量少。因此采用HDBSCAN算法将训练集中的所有日志序列聚类到不同的簇,使每个簇更可能包含语义相似的日志序列。由于日志序列语义向量维度较大影响聚类效率,所以采用了FastICA[31]算法降低日志语义向量的维度,保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
本文的日志序列聚类过程如下:首先,将日志序列中每条日志语句语义向量求和作为图的顶点,日志序列之间的相互可达度量距离作为顶点之前边的权重,构建了一个带权连通无向图。 日志序列之前相互可达度量距离如式(1)所示。
dmreach-m(a,b)=max{corem(a),corem(b),d(a,b)}(1)
其中:dmreach-m(a,b)表示日志序列样本a和b的相互可达度量距离;corem(a)表示日志序列样本a与第m个最近邻样本点的核心距离;d(a,b)是两个日志序列样本点a和b之间的直接距离。
其次,将该带权图通过Prim算法构建其最小生成树。根据最小生成树,通过按距离升序排列树的边,并为每条边创建一个新的合并簇进行迭代,将其转换为连接组件的层次结构。然后,根据设置的最小簇数值,将大而复杂的簇层次结构缩小成一个较小的树。最后,根据每个簇的稳定性值,从压缩树中提取出稳定的簇。簇的稳定性scluster公式如式(2)所示。
其中:λ=1/distance;λbirth表示当节点被分裂成两个子节点时,对应断开边的长度的倒数;λa表示日志序列样本点a因为分裂离开该节点时,对应断开边长度的倒数。
这样,将训练集中的日志序列分成若干簇,语义相似的日志序列划分到同一簇中,同簇的日志序列共享相同的标签。因此,如果一个簇包含已知的正常日志序列,则该簇中的其余未标签的日志序列更有可能也是正常日志序列,否则有可能是异常的。通过测量未标记日志序列属于每个标签的概率来为每个未标记日志序列指定概率标签,以减少噪声的影响。具体而言,HDBSCAN聚类结果会给每个日志序列样本分配一个0~1的分数score,用于表示每个日志序列属于该簇的不确定性,score越小说明该日志序列越接近该簇的中心。因此,可以将该分数划为属于正常或异常的概率,若预测为正常日志序列,则伪标签如式(3)所示。
2.3 异常检测
在日志异常检测阶段中,使用了残差块的双向时间卷积网络从两个方向捕获上下文信息,从而提高捕获日志数据的特征性能。首先通过日志序列S={e1,e2,…,en}得到日志序列语义向量表示为V={v1,v2,…,vn},其中n为该日志序列长度,et(1≤t≤n)是第t个日志事件,将其中每个日志事件et都对应地表示为语义向量vt,从而将其放入到Bi-TCN中。
Bi-TCN是由TCN扩展而来的。TCN是一种基于CNN的新型神经网络模型,旨在处理时间序列预测任务,其遵循一维全卷积网络的架构,具有相同的输入和输出长度。与普通卷积不同的是,TCN使用因果卷积来确保只捕获过去的信息,利用膨胀卷积在卷积核中增加空洞来增加感受野,因此具有更灵活的感受野,有利于捕捉序列数据的短期和长期时间依赖性。与RNN相比,其易于并行化处理,解决了建模远程关系时的梯度爆炸和消失问题,在内存消耗和处理速度方面具有显著优势。
然而原始的TCN只关注当前日志序列的局部特征与其上文信息之间的相关性,完全忽略了日志序列与其下文信息之间的相关性。因此,将TCN扩展为双向网络即Bi-TCN,它可以从日志序列上下文的信息中捕获每个日志的长期上下文依赖关系,从而有效地增强上下文表示。在TCN中,因果卷积操作保证只有当前时间戳之前的输入数据被用来进行学习,因此将因果卷积改为一维卷积以实现双向的信息学习。
将V输入Bi-TCN,进一步提取长日志上下文的相关性。给定序列V={v1,v2,…,vn},Bi-TCN输出一个相同长度的输出结果Y={y1,y2,…,yn}。其中,每个yt(1≤t≤n)不仅依赖于该时刻之前的输入值,而且与未来的输入值有关,从而提取了日志序列的上下文相关性。Bi-TCN残差块如图4(a)所示,一个残差块包含两层膨胀卷积,以使模型可以获得更大的感受野,在每层之后加入了WeightNorm层,并使用dropout层来防止模型过拟合。通过残差块可以实现跨层连接的恒等映射,解决了深层网络的训练问题可以大大增加网络的层数。卷积过程如图4(b)所示,Bi-TCN使用一维全卷积,并在每层加入0-padding实现输入和输出长度相等,填充公式如式(4)所示,膨胀卷积计算公式如式(5)所示。
其中:d表示膨胀率,以2的指数增长(d=1,2,…,2n);k表示卷积核的大小;f表示滤波器;t-d·i表示过去的时间方向;t+d·i表示未来的时间方向。
提取特征后,使用全局平均池化代替全连接层来平均最后一个卷积层的输出特征,进一步减少全连接层中的参数,从而实现紧凑和高效的特征表示。最后,经过全连接层和softmax分类器判定异常。
算法1 BTCNLog算法
3 实验及分析
3.1 数据集
日志解析实验部分采用了Loghub[32]提供的真实世界日志数据集,其中包含从分布式系统、超级计算机、操作系统、移动系统、服务应用程序收集的16个数据集,每个数据集包含2 000个日志条目。
日志异常检测实验部分选择了三个公共日志数据集(BGL、Thunderbird和Spirit)用于验证实验的有效性。BGL是从BlueGene/L超级计算机收集的日志数据集,部署在劳伦斯利弗莫尔国家实验室,时间跨度251 d,包含4 747 963条日志记录,其中348 460条是异常的。Thunderbird和Spirit都是在美国新墨西哥州阿尔伯克基的桑迪亚国家实验室的两台真实世界的超级计算机系统收集的大型日志数据集。选取Thunderbird原始数据集中前5 000 000条连续日志数据和Spirit数据集的1 GB日志数据进行实验。这三个数据集中的每条日志消息都被手动标记为异常或正常。
3.2 评估指标
大部分日志异常检测的研究只使用精确率(precision)、召回率(recall)和F1值作为评估指标。由于日志数据集正负样例不均衡的特性,使用特异性(specificity)即被正确识别为正常的日志序列在所有真实正常序列中的百分比,可以衡量误报的概率,更全面地评估日志异常检测模型。日志解析实验的度量标准是解析准确率(parsing accuracy),正确解析的日志事件与日志事件总数之比,其中日志模板的部分匹配情况也被认定为不正确。
TP表示模型正确检测出的异常日志序列数量;FP表示被模型错误识别为异常的正常日志序列的数量;FN表示被模型判别为正常的异常日志序列数量,即未被检测到的异常日志序列的数量;TN表示模型正确识别的正常日志序列数量。
3.3 基准模型
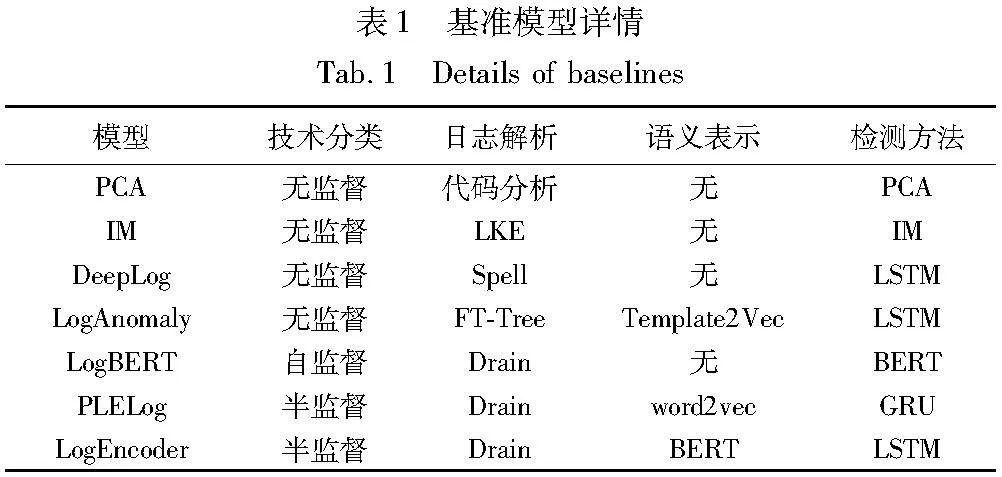
日志解析实验部分将改进的日志解析方法与使用频率最高的两个日志解析方法Spell和Drain以及SwissLog日志解析方法进行比较。同时,日志异常检测实验部分将BTCNLog与七个基准方法作比较,其中包括两个基于数据挖掘的日志异常检测方法,以及五种基于深度学习的日志异常检测方法,详情如表1所示。
a)主成分分析(PCA)[33]。将日志序列矢量化为事件计数向量,利用PCA构建对事件计数向量的正常空间和异常空间,若测试用例远离正常空间则为异常日志。
b)不变量挖掘(invariant mining,IM)[34]。从日志计数向量中挖掘日志事件之间的不变量,不满足这些不变量的日志序列被视为异常。
c)DeepLog。将系统日志表示为日志模板的索引,通过LSTM网络学习正常日志序列并预测下一个日志事件来判定异常。
d)LogAnomaly。在template2vec的支持下提取隐藏在日志模板中的语义信息,使用LSTM网络从正常日志序列中提取顺序和定量特征并通过预测判定异常。
e)LogBERT[35]。使用BERT来捕获整个日志序列的信息,并通过屏蔽日志键预测和超球体最小化体积两个新的自监督训练任务学习正常日志序列。训练后,利用模型预测结果推导出日志序列的异常分数用于区分出异常日志。
f)PLELog。通过概率标签估计结合历史异常日志信息,并使用word2vec语义嵌入处理不稳定的数据,最后使用基于注意力的GRU进行异常检测。
g)LogEncoder[36]。一种半监督异常检测的日志序列编码框架,利用预先训练的模型来获得每个日志事件的模型,并将单类和对比目标学习方法结合,使用基于注意力的模型来捕获日志事件的信息。
3.4 实验坏境和配置
在配备Intel CoreTM i5-10400F 2.90 GHz CPU、128 GB内存、具有6 GB GPU内存的GTX1660Ti和Windows操作系统的服务器上,使用了Python 3.8.3、PyTorch 1.5.1等进行日志解析、日志异常检测和消融实验。
本文设置日志序列窗口大小w为60,根据训练环境设置模型训练epochs为5,batch_size为100,测试batch_size为1 024。根据先验知识,FastICA组件数量设置为100,HDBSCAN中参数min_cluster_size设置为100,min_samples为100。根据调参结果,使用4层Bi-TCN模型,每层的卷积核大小k为3,dropout设置为0.2。使用Adam优化器和LambdaLR学习率调整方法,初始学习率设置为2E-3。根据以下比例拆分所有数据集:60%的数据用于训练,10%用于验证,30%用于测试。
3.5 结果和分析
3.5.1 日志解析实验
日志解析部分使用与SwissLog方法所提供的相同字典进行实验,除此之外,为了与解析结果相匹配,在预处理时将正则表达式替换的参数部分改为统一标记。表2显示了BTCNLog模型日志检测部分与其余三个基准方法在16个日志数据集上的实验结果以及平均准确率,其中加粗字体显示每个数据集最优结果。实验结果表明,在每个数据集上,BTCNLog模型都能取得优于Spell和Drain方法的结果,因为基于字典的解析方法不会将日志关键字过度解析为日志参数。较SwissLog而言,结合日志单词特点的改进使得日志解析准确率在Hadoop、Thunderbird、Mac、Linux、Android五个数据集上都提高了。值得一提的是,在SwissLog论文中提到Mac日志数据集上解析的效果较差,在经过改进后,Mac日志数据集中含有语义信息的合成词被保留,准确率提高了4.45%。
3.5.2 日志异常检测实验
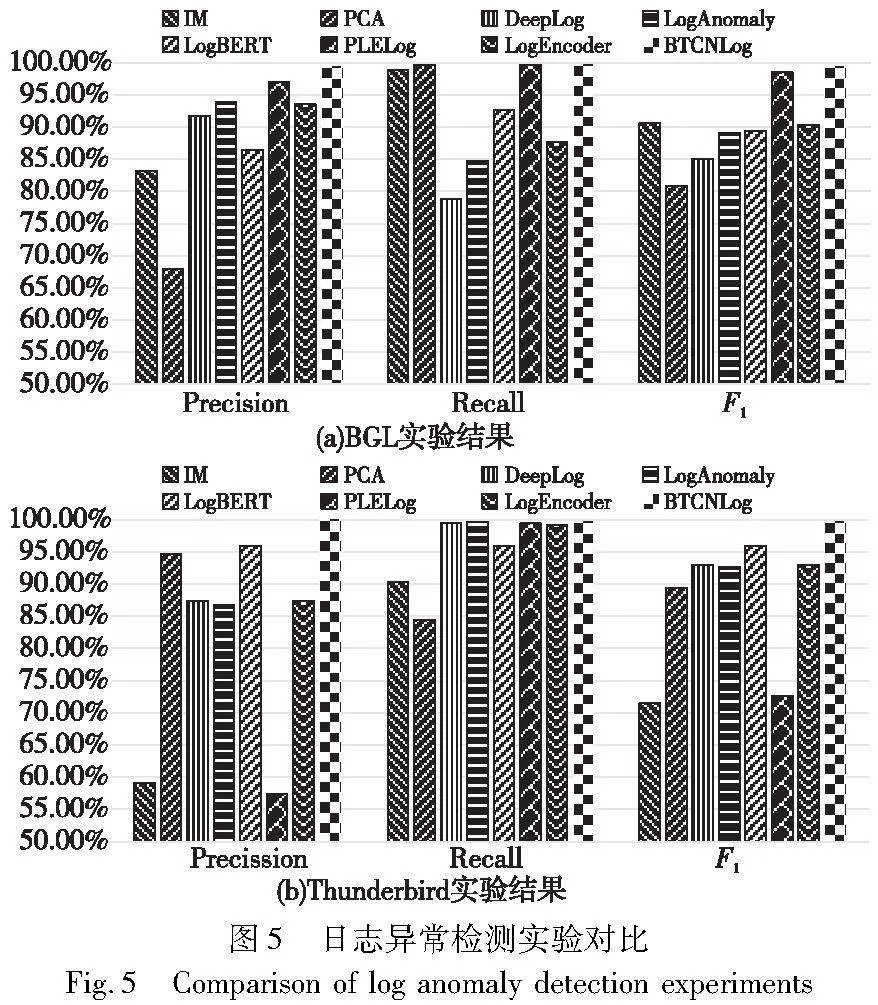
图5(a)(b)分别显示了BTCNLog与七个基准在BGL和Thunderbird日志数据集上的对比实验结果。由于很多基准实验未在Spirit日志数据集上进行,并且使用Drain解析Spirit数据集准确率低,所以只在消融实验中对该日志实验结果进行分析。
实验结果表明,基于数据挖掘的方法IM和PCA表现低于基于深度学习的方法,因为此类方法将日志序列表示为日志计数向量,即每个维度表示日志事件在日志序列中出现的次数,忽略了日志事件中的语义信息,无法应对不断演化的日志语句。基于正常日志进行训练的无监督方法DeepLog和LogAnomaly旨在预测日志序列中的下一个日志事件,所以它们只能预测其训练集中出现的日志事件,很容易将看不见的日志事件视为异常,降低了异常检测的准确率。此外,DeepLog基于日志模板索引进行异常检测,忽略了模板语义信息,效果不如LogAnomaly。至于方法LogBERT,虽在BGL数据集上表现一般,但其使用BERT可以有效捕获整个日志序列的信息,因此其有效性优于Deeplog和LogAnomaly。PLELog由于其语义嵌入和整合历史异常知识的能力,在BGL数据集上表现良好,但是在Thunderbird数据集上表现较差,与其采用的日志解析方法Drain解析效果不佳有关。半监督模型LogEncoder同样使用BERT提取模板中的语义信息,结合注意力机制和对比学习具有鲁棒性,在两个数据集上都能取得较好的检测结果。而BTCNLog在日志解析方法上进行了改进,结合BERT更能保留日志事件语义信息,使用Bi-TCN从日志序列上下文提取相关性,可以更好地捕获异常,因此在两个数据集上都取得了较高的F1分数,优于其他基准模型。
为了进一步评估不同日志序列窗口大小对日志异常检测有效性的影响,窗口大小w分别选取60、120、180、240进行实验,实验结果如图6所示。结果表明,实验窗口对异常检测有效性结果影响不大,各个评估指标都能达到较高水平。因此,使用BTCNLog模型可以有效学习不同长度日志序列中的依赖关系。
3.5.3 消融实验
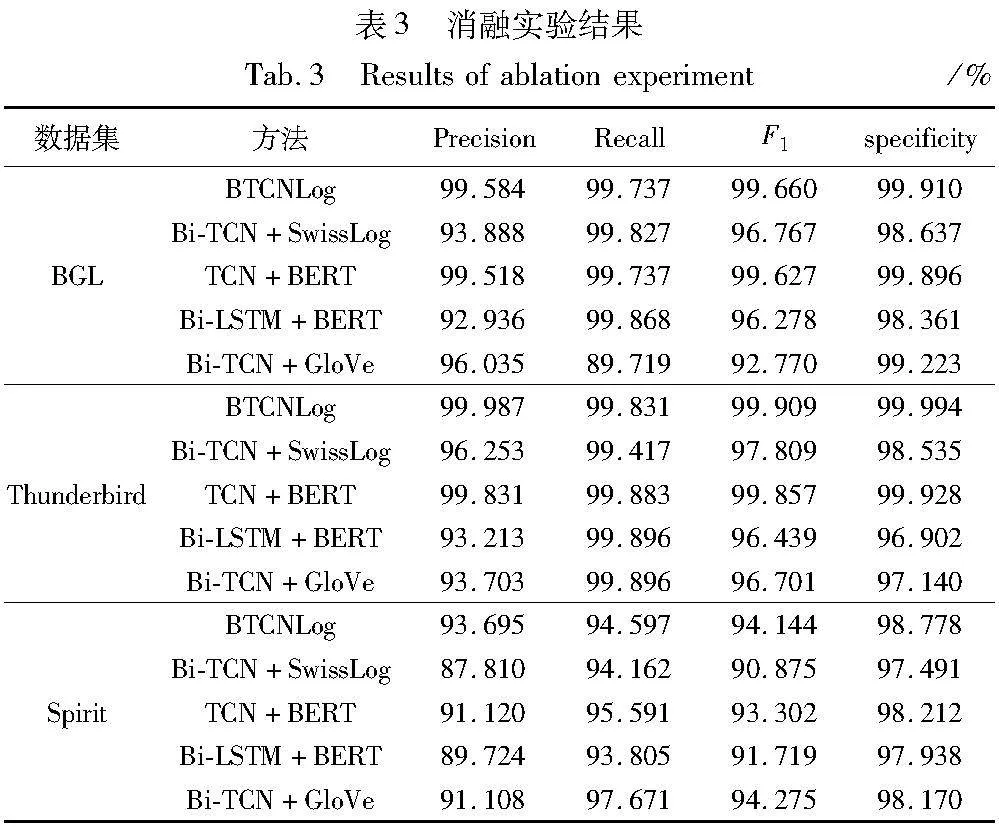
消融实验可以验证模型各个部分的有效性,因此分别在BGL、Thunderbird和Spirit日志数据集上进行消融实验,验证日志解析、日志语义嵌入和日志异常检测模型的有效性。表3显示了在三个数据集上进行三项消融实验的实验结果。
1)日志解析的消融实验
将日志解析部分改为SwissLog原始解析方法,实验效果如表3的模型Bi-TCN+SwissLog所示,在三个数据集上的实验结果都略有下降。因为BTCNLog模型的解析部分结合了日志单词的特性,并保留了部分参数的语义信息,充分利用日志事件的语义信息。在Spirit数据集上,实验效果普遍较差,这与该数据集中包含较多专业领域缩写、可读性较差有关。
2)异常检测模型的消融实验
表3的模型TCN+BERT显示了将日志异常检测模型部分改为TCN的实验结果,结果显示,使用TCN进行异常检测仍然可以得到很好的效果,但与Bi-TCN相比,实验效果略微下降。此外,使用具有100层隐藏层的Bi-LSTM替换Bi-TCN,实验结果如表3的Bi-LSTM+BERT模型所示,虽召回率可以保持较好水平,但精确率有所下降,从而证实了Bi-TCN有效学习日志序列上下文信息,对日志异常检测有改进的效果。
3)语义向量的消融实验
在保持模型其余部分相同的情况下,将日志模板语义嵌入模块改为GloVe和TF-IDF进行实验,其中语义向量维度为300。实验结果如表3的Bi-TCN+GloVe模型所示,虽然在召回率上BTCNLog模型结果略低些,但在精确度、F1分数和特异性上比使用GloVe作为语义嵌入的效果好。这是因为使用GloVe方法会有很多OOV(out of vocabulary)问题,无法准确表示日志序列语义信息。因此结果证实了BERT语义嵌入的有效性,可以有效保留日志的语义信息。
4 结束语
本文提出了一种新的基于日志的半监督异常检测方法BTCNLog。首先通过改进的基于字典的日志解析方法进行日志解析,使用BERT对模板中的语义信息进行编码获得日志的语义向量;通过新的日志分组方式进行分组;然后通过聚类进行标签估计;最后,基于双向的时间卷积网络进行异常检测。该模型能够提高日志解析准确性,充分利用日志事件的语义信息,并高效提取日志序列上下文信息,提高了日志异常检测的效率和精度。同时,半监督学习方法减少人工标注,可以学习到历史异常日志的信息。
今后工作的主要目标在于在现实大型软件系统中部署,测试其在更多日志数据集上的表现。同时,将进一步改进模型,解决BTCNLog对于部分可读性较差的系统日志事件异常检测效果不佳的问题。
参考文献:
[1]贾统, 李影, 吴中海. 基于日志数据的分布式软件系统故障诊断综述[J]. 软件学报, 2020,31(7): 1997-2018. (Jia Tong, Li Ying, Wu Zhonghai. Review of fault diagnosis of distributed software system based on log data[J]. Journal of Software, 2020, 31(7): 1997-2018.)
[2]Zhang Xu, Xu Yong, Lin Qingwei, et al. Robust log-based anomaly detection on unstable log data[C]//Proc of the 27th ACM Joint Mee-ting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM Press, 2019: 807-817.
[3]Li Xiaoyun, Chen Pengfei, Jing Linxiao, et al. SwissLog: robust and unified deep learning based log anomaly detection for diverse faults[C]//Proc of the 31st International Symposium on Software Reliability Engineering. Piscataway,NJ: IEEE Press, 2020: 92-103.
[4]Li Xiaoyun, Chen Pengfei, Jing Linxiao, et al. SwissLog: robust anomaly detection and localization for interleaved unstructured logs[J]. IEEE Trans on Dependable and Secure Computing, 2023, 20(4): 2762-2780.
[5]Wang Zumin, Tian Jiyu, Fang Hui, et al. LightLog: a lightweight temporal convolutional network for log anomaly detection on the edge[J]. Computer Networks, 2022, 203: 108616.
[6]Du Min, Li Feifei, Zheng Guineng, et al. DeepLog: anomaly detection and diagnosis from system logs through deep learning[C]//Proc of ACM SIGSAC Conference on Computer and Communications Secu-rity. New York: ACM Press, 2017: 1285-1298.
[7]Meng Weibin, Liu Ying, Zhu Yichen, et al. LogAnomaly: unsupervised detection of sequential and quantitative anomalies in unstructured logs[C]//Proc of the 28th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers, 2019: 4739-4745.
[8]Bai Shaojie, Kolter J Z, Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[EB/OL]. (2018-04-19). https://arxiv.org/abs/1803.01271.
[9]Zhang Shenglin, Meng Weibin, Bu Jiahao, et al. Syslog processing for switch failure diagnosis and prediction in datacenter networks[C]//Proc of the 25th International Symposium on Quality of Ser-vice. Piscataway,NJ: IEEE Press, 2017: 1-10.
[10]Du Min, Li Feifei. Spell: online streaming parsing of large unstructured system logs[J]. IEEE Trans on Knowledge and Data Engineering, 2018, 31(11): 2213-2227.
[11]He Pinjia, Zhu Jieming, Zheng Zibin, et al. Drain: an online log parsing approach with fixed depth tree[C]//Proc of the 24th IEEE International Conference on Web Services. Piscataway,NJ: IEEE Press, 2017: 33-40.
[12]Devlin J, Chang Mingwei, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24). https://arxiv.org/abs/1810.04805.
[13]Yang Lin, Chen Junjie, Wang Zan, et al. Semi-supervised log-based anomaly detection via probabilistic label estimation[C]//Proc of the 43rd International Conference on Software Engineering. Piscataway,NJ: IEEE Press, 2021: 1448-1460.
[14]Fu Qiang, Lou Jianguang, Wang Yi, et al. Execution anomaly detection in distributed systems through unstructured log analysis[C]//Proc of the 9th IEEE International Conference on Data Mining, Piscataway,NJ: IEEE Press, 2009: 149-158.
[15]Hossein H, Debnath B, Xu Jianwu, et al. LogMine: fast pattern re-cognition for log analytics[C]//Proc of the 25th ACM International on Conference on Information and Knowledge Management. New York: ACM Press, 2016: 1573-1582.
[16]Nagappan M, Vouk M. Abstracting log lines to log event types for mining software system logs[C]//Proc of the 7th IEEE Working Conference on Mining Software Repositories. Piscataway,NJ: IEEE Press, 2010: 114-117.
[17]Makanju A, Zincir-Heywood A N, Milios E. Clustering event logs using iterative partitioning[C]//Proc of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2009: 1255-1264.
[18]Meng Weibin, Liu Ying, Zaiter F, et al. Logparse: making log parsing adaptive through word classification[C]//Proc of the 29th International Conference on Computer Communications and Networks. Piscataway,NJ: IEEE Press, 2020: 1-9.
[19]Dai Hetong, Li Heng, Shang Weiyi, et al. Logram: efficient log parsing using n-gram dictionaries[J]. IEEE Trans on Software Engineering, 2022, 48(3): 879-892.
[20]Nedelkoski S, Bogatinovski J, Acker A, et al. Self-supervised log parsing[C]//Proc of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham: Springer, 2020: 122-138.
[21]张颖君, 刘尚奇, 杨牧, 等. 基于日志的异常检测技术综述[J]. 网络与信息安全学报, 2020,6(6): 1-12. (Zhang Yingjun, Liu Shangqi, Yang Mu, et al. Overview of log based anomaly detection technology[J]. Journal of Network and Information Security, 2020, 6(6): 1-12.)
[22]Bodík P, Goldszmidt M, Fox A, et al. Fingerprinting the datacenter: automated classification of performance crises[C]//Proc of the 5th European Conference on Computer Systems. New York: ACM Press, 2010: 111-124.
[23]Liang Yinglung, Zhang Yanyong, Xiong Hui, et al. Failure prediction in IBM BlueGene/L event logs[C]//Proc of the 7th IEEE International Conference on Data Mining Workshops. Piscataway,NJ: IEEE Press, 2007: 583-588.
[24]Zhu Jieming, He Pinjia, Fu Qiang, et al. Learning to log: helping developers make informed logging decisions[C]//Proc of the 37th IEEE International Conference on Software Engineering. Piscataway,NJ: IEEE Press, 2015: 415-425.
[25]Soucy P, Mineau G. Beyond TFIDF weighting for text categorization in the vector space model[C]//Proc of International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers, 2005: 1130-1135.
[26]Ling Wang, Dyer C, Black A, et al. Two/too simple adaptations of word2vec for syntax problems[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL Press, 2015: 1299-1304.
[27]Nedelkoski S, Bogatinovski J, Acker A, et al. Self-attentive classification-based anomaly detection in unstructured logs[C]//Proc of IEEE International Conference on Data Mining. Piscataway,NJ: IEEE Press, 2020: 1196-1201.
[28]Wang Zhiwei, Chen Zhengzhang, Ni Jingchao, et al. Multi-scale one-class recurrent neural networks for discrete event sequence ano-maly detection[C]//Proc of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. New York: ACM Press, 2021: 3726-3734.
[29]Pennington J, Socher R, Christopher D. Manning. GloVe: global vectors for word representation[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL Press, 2014: 1532-1543.
[30]McInnes L, Healy J, Astels S. HDBSCAN: hierarchical d+BbziV4l++hmVIQbFW5Dzg==ensity based clustering[J]. Journal of Open Source Software, 2017,2(11): 205.
[31]Oja E, Yuan Zhijian. The FastICA algorithm revisited: convergence analysis[J]. IEEE Trans on Neural Networks, 2006, 17(6): 1370-1381.
[32]Zhu Jieming, He Shilin, He Pinjia, et al. Loghub: a large collection of system log datasets for AI-driven log analytics[C]//Proc of the 34th International Symposium on Software Reliability Engineering. Piscataway,NJ: IEEE Press, 2023: 355-366.
[33]Xu Wei, Huang Ling, Fox A, et al. Detecting large-scale system problems by mining console logs[C]//Proc of the 22nd ACM SIGOPS Symposium on Operating Systems Principles. New York: ACM Press, 2009: 117-132.
[34]Lou Jianguang, Fu Qiang, Yang Shengqi, et al. Mining invariants from console logs for system problem detection[C]//Proc of USENIX Annual Technical Conference. Berkeley: USENIX Press,2010: 24.
[35]Guo Haixuan, Yuan Shuhan, Wu Xintao. LogBERT: log anomaly detection via BERT[C]//Proc of International Joint Conference on Neural Networks. Piscataway,NJ: IEEE Press, 2021: 1-8.
[36]Qi Jiaxing, Luan Zhongzhi, Huang Shaohan, et al. LogEncoder: log-based contrastive representation learning for anomaly detection[J]. IEEE Trans on Network and Service Management, 2023,20(2): 1378-1391.
