
融合多粒度注意力特征的小样本分类模型
2024-08-17 00:00:00韩岩奇苟光磊李小菲朱东华
计算机应用研究 2024年7期


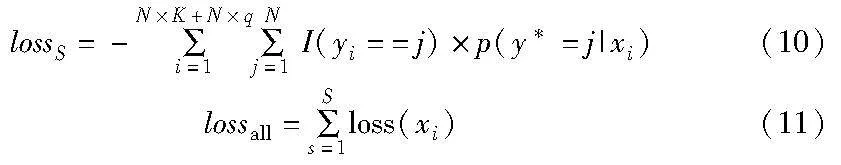




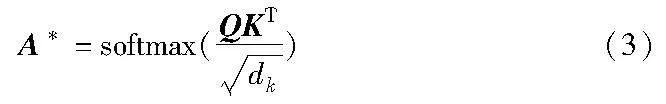



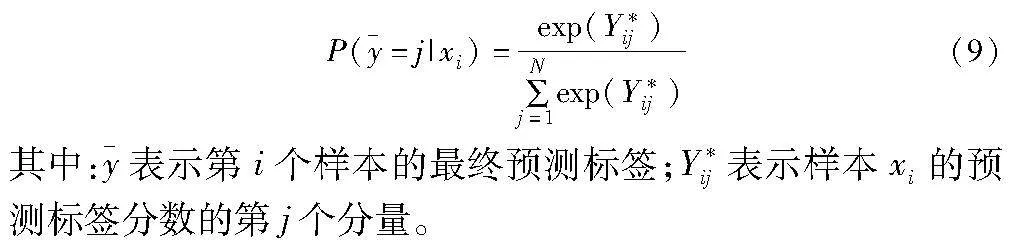

摘 要:在小样本分类任务中,现有的CNN模型存在特征提取不足、特征单一和小样本数据集类间差异化较弱的问题,导致分类精度较低。针对以上问题,提出一种融合多粒度注意力特征(fusion multi-granular attention feature,FMAF)的小样本分类模型。首先,该方法借鉴多粒度思想,重新设计CNN特征提取网络的架构来增强特征多样性;其次,在多粒度特征提取网络后添加自注意力层,提取多粒度图像特征中的关键特征,在多粒度注意力特征的基础上,借助特征融合方法融合多粒度注意力特征信息,突出关键特征,提高特征的表征力;最后,在两个经典的小样本数据集miniImageNet和tieredImageNet上进行了评估。实验结果表明,FMAF方法能有效提升分类的准确度和效率。
关键词:小样本学习;多粒度特征融合;自注意力机制;标签传播
中图分类号:TP393 文献标志码:A 文章编号:1001-3695(2024)07-045-2235-06
doi: 10.19734/j.issn.1001-3695.2023.09.0513
Few-shot classification model incorporating multi-granular attention features
Abstract: In the few-shot classification tasks, existing CNN models suffer from insufficient feature extraction, limited feature diversity and weak differentiation between classes in few-shot datasets, leading to low classification accuracy. To address these issues, this paper proposed a few-shot classification model called FMAF. Firstly, this method incorporated multi-granularity thought into the architecture of CNN feature extraction network to enhance feature diversity. Secondly, after the multi-granular feature extraction network, FMAF added a self-attention layer to extract key features from the multi-granular image features, based on the multi-granular attention features, FMAF employed a feature fusion method to combine the information from multiple-granularity attention features, highlighted the crucial features and improved feature representativeness. Finally, this paper utilized two classical few-shot datasets for experimental verification on miniImageNet and tieredImageNet. Experimental results show that FMAF method can effectively improve the accuracy and efficiency of classification.
Key words:FSL; multi-granular feature fusion; self-attention mechanism; label propagation
0 引言
近年来,深度学习在计算机各个领域都有较大突破,尤其是在计算机视觉、语音识别以及文本分类等领域,但对于某些特定领域,例如医学上罕见疾病的诊断[1]、生物学上濒危动物的保护研究[2]等难以获取到真实有效的数据集,即使拥有充足的数据,但对数据进行标注亦费时费力。受到人类快速学习能力的启发,更多的研究者开始转向研究如何在少量样本的情况下进行图像分类,即小样本图像分类(few-shot image classification, FSIC)[3]。由于小样本本身数据不足以及数据集中存在类别高度相近的种类,如何从少量图像样本中挖掘丰富的特征信息以及提高类内和类间的判别性,成为FSIC研究的难点。现有FSIC方法[4]可以分为基于度量学习和基于元学习两大类。
基于度量学习的FSIC方法借助了度量函数建模支持集(support sets)样本与查询集(query sets)样本之间的相似关系[5]。该方法通过特征提取将支持集与查询集样本映射到公共特征空间,通过不同的度量函数,如余弦距离、欧氏距离等,计算查询集样本与支持集样本特征向量的相似度,以完成分类。起初,研究者着重把小样本学习的研究中心放在特征提取网络模型的设计上,相继提出了孪生神经网络(S-Net)[6]、匹配网络(M-Net)[7]、原型网络(P-Net)[8]等。以上研究所设计的网络在最终的距离度量上均使用了固定的度量方式,所有学习的过程均发生在样本的embedding阶段。基于对度量方式在分类中重要性的考量,Sung等人[9]提出关系网络(R-Net),通过浅层神经网络学习非线性距离度量,打破单一且固定的距离度量方式。Li等人[10]提出协方差度量网络(CovaMNet),通过提高支持样本类的精确表示,合理度量支持样本与查询样本的相似度。通过分析文献[6~10]不难发现,基于度量的方法更倾向于对样本对间的距离进行建模,未解决小样本实际存在的“类间类内差异性小”的情况。
基于元学习的FSIC方法,采用元任务机制进行知识迁移,辅助模型在新任务中更快、更准确地获取分类结果。早期,Santoro等人[11]提出记忆增强的神经网络,主要用于解决单样本学习问题。随后,Finn等人[12]和Ravi等人[13]将长短期记忆网络(LSTM)作为优化器,学习较好的初始化参数,使模型能在新的小样本数据上快速收敛。早期研究停留在基本优化算法及浅层特征的层面,未涉及如何提取更有效的特征。随后,Li等人[14]提出深度最近邻神经网络(DN4),着重关注最优深度局部信息。Xue等人[15]提出区域比较网络(RCN),通过学习注意权重的方法模拟人的视觉系统对图片的感知能力,开始关注图片中关键局部信息。李晓旭等人[16]提出注意力全关系网络(ATRNet)。王晓茹等人[17]提出先空间后通道注意力网络(AMGC)。文献[14~17]设计的网络模型开始关注局部特征信息及图像中关键部位的特征信息,使小样本低数据造成的特征信息不足的问题有所缓解。受到小样本目标分割领域中多尺度思想的影响,Chen等人[18]提出多尺度自适应网络(MATANet),Yu等人[19]提出回溯网络(LB-Net),汪航等人[20]提出多尺度特征生成网络(MSLPN),通过多尺度特征信息进行关系度量学习,对特征提取器输出层信息进行多尺度划分,在少量样本中提取更丰富的特征,增强了模型的分类性能。
综合以上文献分析得出,现有小样本学习中存在以下几点不足:a)现有特征提取网络仅仅使用深层次细粒度特征信息,忽视了浅层次粗粒度特征中的细节、位置信息对分类的作用;b)FSIC方法在提取多尺度特征信息后采用简单拼接融合的方式,忽略了各层次特征对分类结果贡献程度之间存在的差异性;c)FSIC数据集中含有多个类别高度相似的样本,以往研究对类间和类内的可区分性未进行有效处理,导致样本被错误分类,从而降低准确率。
基于以上小样本学习中的问题,本文贡献如下:a)针对现有特征网络提取特征不足、特征单一的问题,设计一种多粒度注意力特征提取网络,提取图像的粗粒度和细粒度特征信息,同时借助注意力机制提高图像关键特征的表征力;b)针对现有特征融合方式的局限性,设计一种加权融合机制,根据不同粒度层中特征对结果的贡献,设置最优权值融合浅层粗粒度特征与深层细粒度特征;c)小样本数据集本身存在类间差异小的情况,为此引入标签传播算法,加强类内样本的相似性,拉大类间样本的差异性,提高模型的分类准确度。
1 融合多粒度注意力特征的小样本分类算法
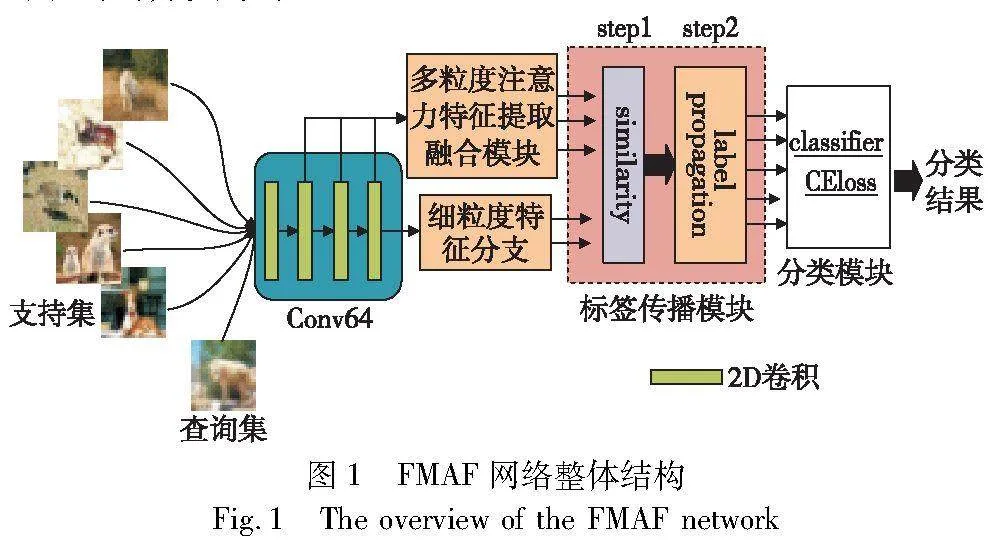
FMAF小样本分类模型架构如图1所示。该网络由多粒度注意力特征融合模块、细粒度特征分支、标签传播模块、分类策略模块组成。其核心在于:多粒度注意力特征提取融合模块,借助多粒度注意力融合模块提取多组多粒度的关键特征,每组特征均可以单独表示其提取图像的特征;细粒度特征分支的设计保留了图像最细粒度的信息,同时弥补分类结果严重依靠多粒度特征,平衡最终的分类结果;标签传播模块借助相似性度量函数计算每组特征中所提取的支持集与查询集样本特征之间的相似性,随后使用标签传播算法完成对未知样本的预测任务;最后通过分类模块将所有组的分类结果进行融合,得到最终的分类结果。
1.1 小样本问题定义
现有小样本学习中,所有数据集均划分为训练集、验证集、测试集,且三个数据集中所含类别不交叉。小样本学习主要按照N-way K-shot的范式进行学习。在训练阶段,N-way K-shot表示随机从训练集中选取N个类别数据,每类中抽取K个样本作为支持集,共有N×K个标注样本;然后从N个类别剩余样本中选取q个样本作为查询集,共有q×N个样本,1个支持集S加1个查询集Q构成一个元任务T。同样地,验证集和测试集数据同样按照该标准划分,借助N×K个支持集样本对所有查询集样本进行分类,这便是小样本学习问题。其中,支持集S、查询集Q及任务T定义如式(1)所示。
S={xjn,yin)|i=1,2,…,K;n=1,2,…,N}
Q={(xjn)|j=1,2,…,q;n=1,2,…,N}
T={S,Q}(1)
其中:x和y表示图像和图像标签。
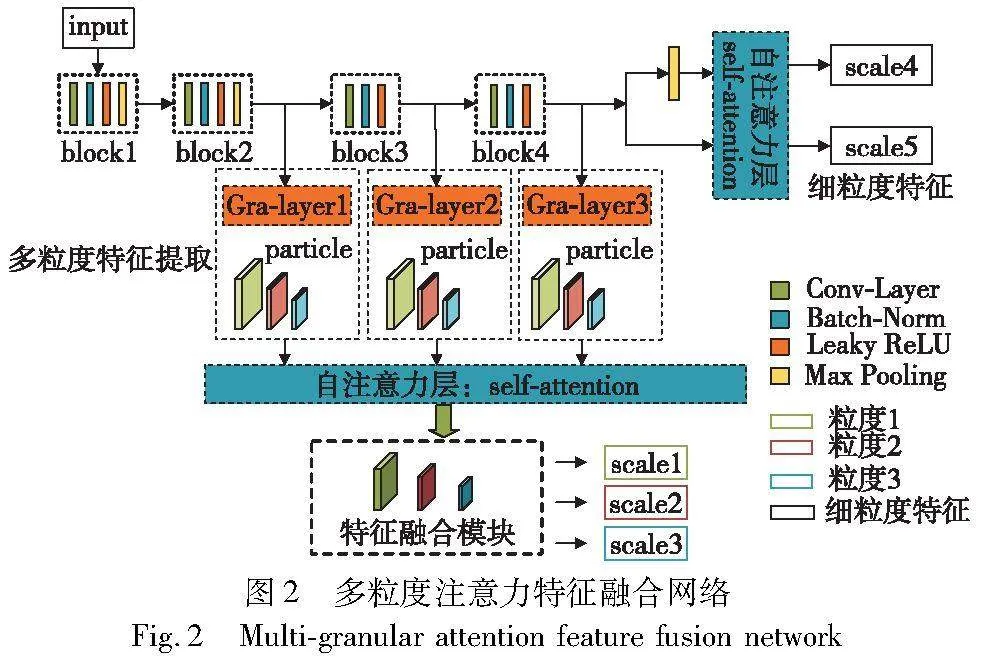
1.2 多粒度注意力特征提取融合网络
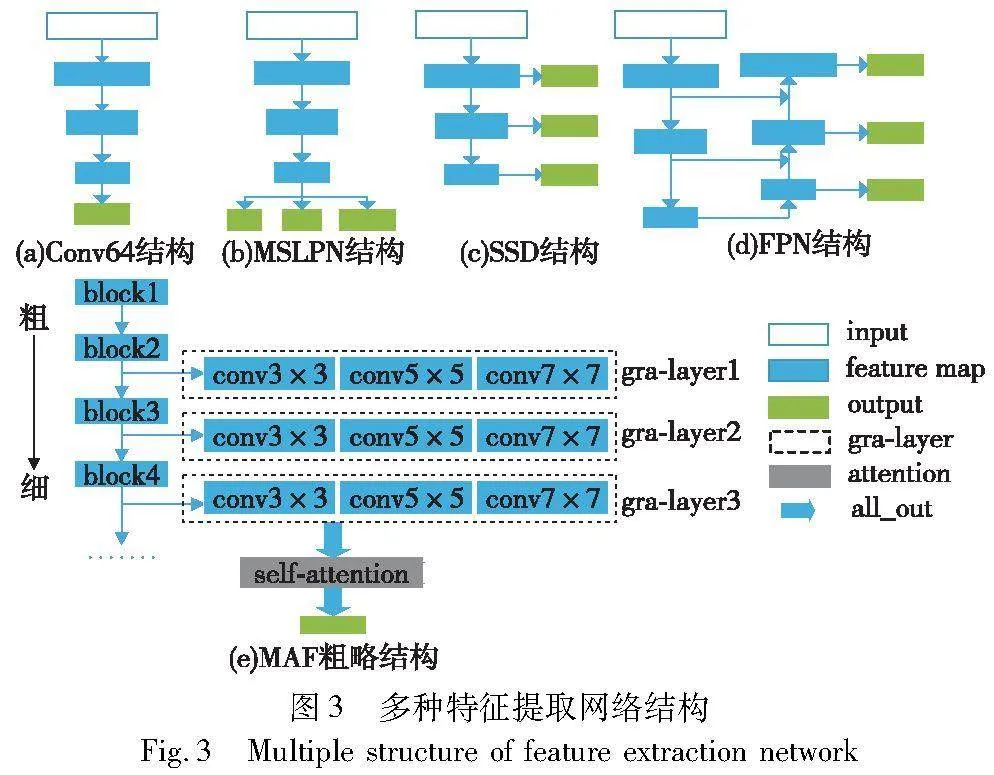
现有FSIC模型使用的特征提取网络大多为Conv64、ResNet12[21]和MSLPN,均只用特征提取网络的最后一层输出作为最终分类的依据,忽略了浅层特征对分类结果的影响,从而导致网络特征提取不足、特征单一的问题。为了获取小样本图像中丰富的特征信息,提高图像分类的准确率,本文重新设计一种多粒度注意力特征融合网络,与CNN其他变体网络不同,该网络不仅考虑网络深层次与浅层次信息,
同时抽取每层中不同粒度的图像特征,网络详细结构如图2所示。该网络的实现由两个阶段组成,第一阶段为多粒度注意力特征提取(multi-granular attention features,MAF),第二阶段为特征融合。
在MAF阶段,本文选取Conv64作为多粒度注意力特征提取阶段的骨干网络,对比ResNet12和MSLPN而言,Conv64更轻量,更适合少量样本的分类学习,其网络结构如图3(a)所示,MSLPN结构如图3(b)所示。在目标检测领域,Liu等人[22]设计了一种SSD网络结构,从网络不同层提取多尺度特征信息,如图3(c)所示。Hu等人[23]和华杰等人[24]提出特征金字塔网络(FPN),通过自上而下和跳跃连接的方法提取目标中多层级中强语义信息,有效提升检测精度,其结构如图3(d)所示。受小样本目标检测任务中特征提取网络的设计方法及粒计算研究中粒度[25]思想的启发,重新设计Conv64特征提取网络,所设计的多粒度注意力特征提取网络如图3(e)所示。其中,根据粒度的划分标准,将Gra-layer1、Gra-layer2、Gra-layer3分别定义为粗粒度层、中间过渡层、细粒度层,将Conv3×3、Conv5×5、Conv7×7三种不同尺寸的卷积核定义粒子粒化的比例。比如:Conv3×3代表针对当前粒度层进行一次粒化比例为3×3的卷积操作。从粗粒度层到细粒度层、从大粒子到小粒子,逐层、逐粒地进行特征提取,让模型能够充分学习到图像不同粒度层之间的信息,以及每个粒度层下不同大小粒子的像素信息,减少卷积过程中有效特征信息的丢失。为获取图像中的关键特征信息,减少冗余信息干扰的同时保留多样化的图像特征信息,本文在多粒度特征提取后添加一层自注意力机制。
其次,计算query和key两者间相似性得到A=QKT。对结果进行归一化处理得到注意力矩阵:
最后,根据权重系数矩阵A*,对value进行加权求和,得到自注意力模块输出的特征图,计算过程为
attention(Q,K,V)=A*V(4)
在特征融合阶段,将不同的特征组合在一起,可以弥补其他特征的不足,实现优缺互补,提升模型的性能和泛化能力。但传统的特征融合方法大多使用concatenate实现特征的简单拼接融合,容易使关键信息缺失、冗余特征信息过多,导致模型分类效果不佳。文献[26,27]在此基础上进行改进,采用特征级加权融合为每层设置相同的权重,用于融合浅层粗力度特征和深层细粒度特征,但未对不同层次特征信息的重要性进行理论分析,导致分类效果不佳。综合上述思想的优缺点,为确保每层特征能够匹配到合适的权重,本文对层次信息的重要性进行分析,根据不同粒度层特征对分类的贡献度为每层设置不同的权值,并不断进行调整,选择出最优权值进行不同粒度层次之间多组信息的融合。
特征加权融合阶段的具体实现流程如下:首先将多粒度注意力特征提取模块的输出记为attij,其中i表示第几个粒度层,j表示粒化操作;其次采用特征点乘的方式融合多粒度注意力特征提取网络的输出结果,并为前2层多粒度注意力的输出设置权重参数α和β,且满足α+β=1。融合计算过程为
scaleU50+1Y95yWwAUIj7f8SxKg==13=αatt13·βatt23·att33
scale25=αatt15·βatt25·att35
scale37=αatt17·βatt27·att37
(5)
该多粒度注意力特征融合算法的具体伪代码描述如算法1所示。
算法1 多粒度注意力特征融合算法
1.3 标签传播及分类模块
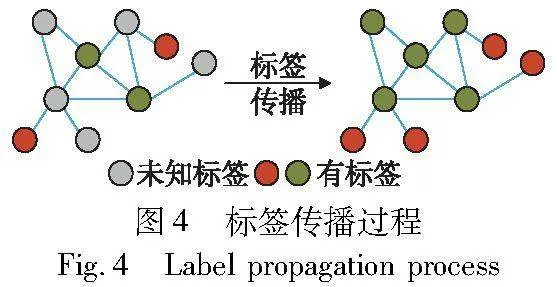
小样本数据集本身存在类间差异小、类别高度相似的问题,如何拉大类间距离、缩小类内的距离,有效提高分类准确率成为小样本分类任务中不可忽视的挑战。借鉴文献[28]中提出的标签传播方法,在特征充分提取后,对特征向量进行相似性度量,根据度量函数构建的样本之间的相似度进行标签传播,标签传播算法过程如图4所示。
标签传播算法流程:首先,采用高斯核函数度量5个特征分支中支持集样本和查询集样本间的相似度,如式(6)所示。
其中:s代表不同特征分支;Wij表示样本xi和xj的相似度;|θi|s为分支s下的分支参数,可通过网络学习获取。
其次,为防止模型过拟合,提升模型的泛化能力,取矩阵Ws中每一行前k个最大值(k=20),构建K最近邻图并借助拉普拉斯正则化对K进行处理,得到泛化能力较好的相似度矩阵Ls=D-1/2WsD-1/2,借助标签传播的方法得到5个分支下查询集的预测标签分数。具体标签传播公式为
Ys=(I-αLs)-1Y0(7)
其中:Y0为初始化标签矩阵;α∈(0,1)控制传播的信息量,本文设置α为0.99;I表示单位矩阵;Y表示预测的标签分数。
然后,利用式(7)进行标签传播,输入相似度矩阵Ls获得每个分支下的预测标签分数Ys,通过最简单的分数加权获得最终的预测分数Y*,加权方式为
通过激活函数softmax得到最终的5个特征分支的分类结果,如式(9)所示。
最终通过交叉熵损失计算每个分支下的损失,加权融合后作为5个分支的总损失,如式(10)(11)所示。
其中:I(*)为推断函数;yi为样本真实标签值,当yi==j为真时,I=1,当yi==j为假时,I=0。所有参数以端到端的方式进行更新。
2 实验
2.1 数据集
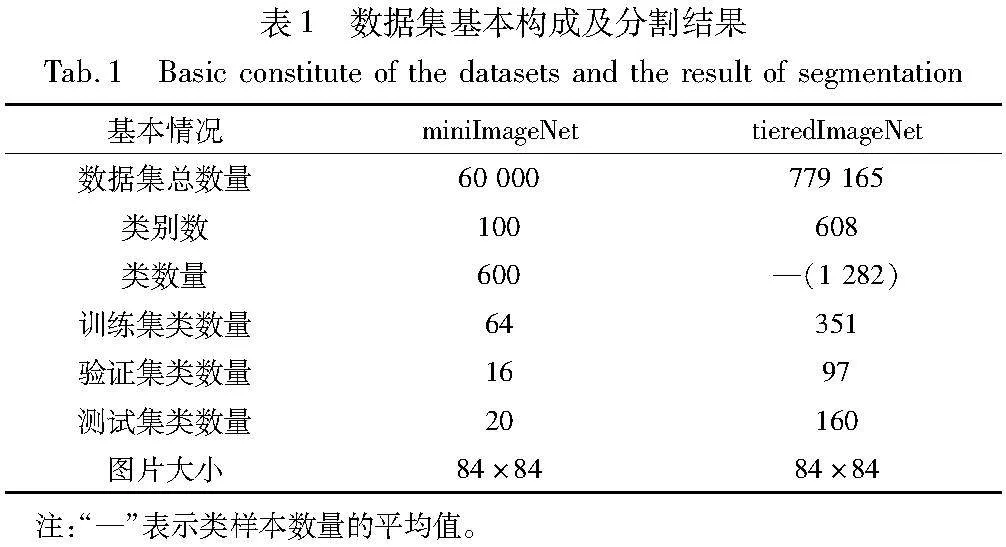
本文使用两个经典的小样本公开数据集miniImageNet和tieredImageNet对FMAF方法进行评估。两个数据集的图像包含各种各样的物体、动物及植物等,具有较高的复杂性和多样性。本文使用这两个数据集做FSIC任务时,需将数据集分割为训练集、验证集以及测试集且互不相交,具体数据集基本构成及分割结果如表1所示。
2.2 实验设置
1)学习策略设置 在训练、验证和测试阶段遵循小样本学习方式,两个小样本数据集miniImageNet和tieredImageNet均按照N-way K-shot的范式进行训练。训练和验证时,随机采取210 000个元任务,按100个元任务进行划分,每100个为一个epoch,共有2 100个epoch。在5-way 1-shot任务中,5个类别分别选取1张图像,共计5张图像作为支持集;从每个类剩余图像中选取15张图像,共计75张图像作为查询集。测试时,随机选取1 000个元任务进行测试,共计10个epoch,并取10个epoch的平均准确率作为最终结果,置信区间为95%。
2)实验环境 本文所有实验均在Ubuntu18.04系统,NVIDIA Tesla V100(32GB) GPU,PyTorch(1.7.1)深度学习框架环境下运行。
3)参数设置 训练集、验证集和测试集均采用一样的参数设置,即初始学习率为0.001,每训练25 000个任务后,学习率减半,动量为0.99,优化器使用Adam,其余参数采用默认值。
2.3 实验结果与分析
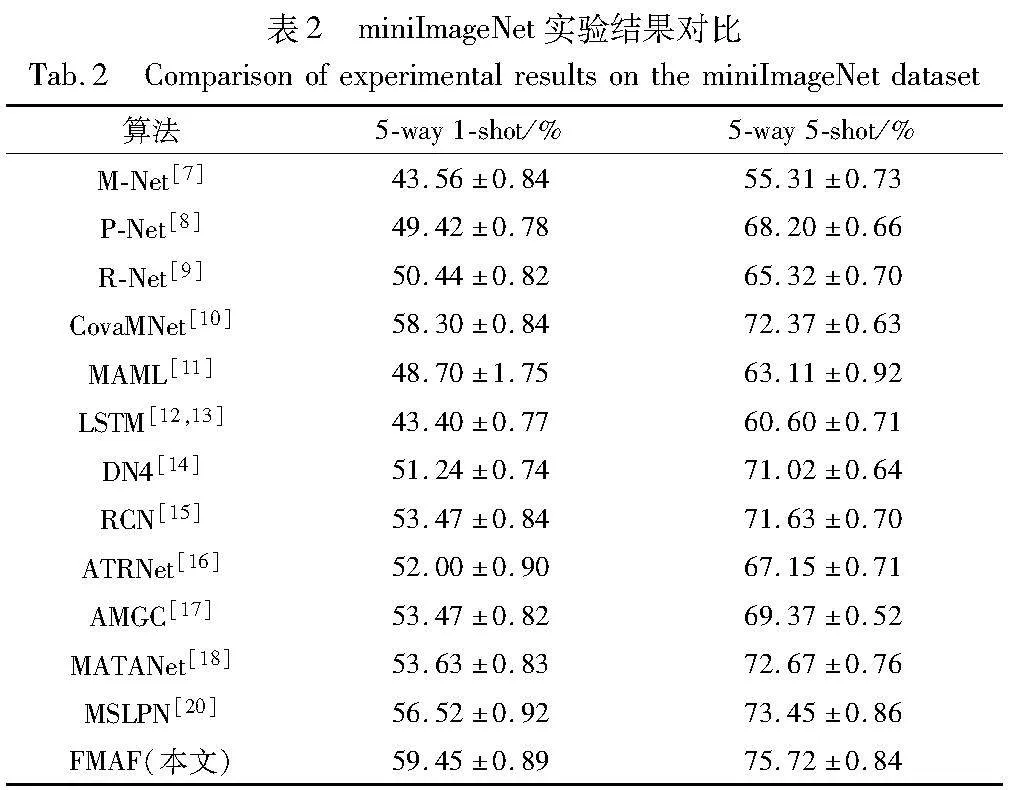
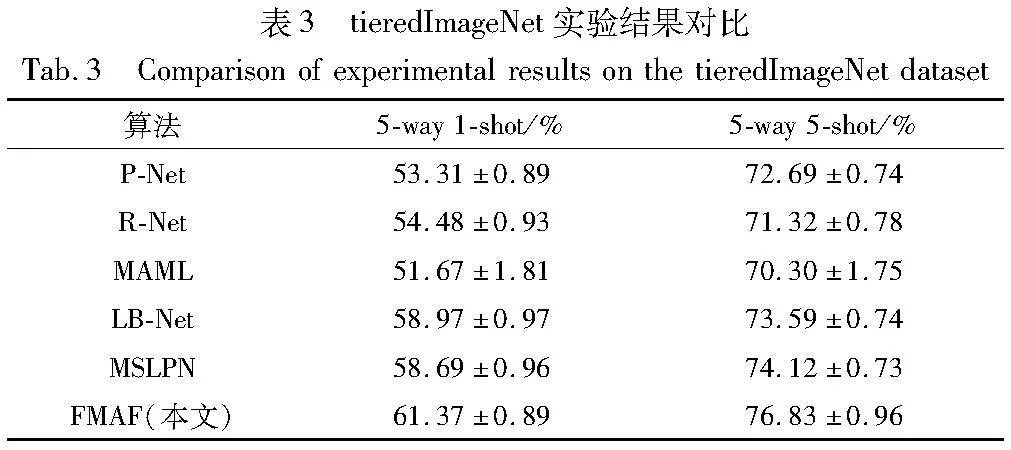
为了验证FMAF算法的有效性,分别与多种小样本学习方法进行对比实验,如M-Net、P-Net、R-Net、CovaMNet、MAML、LSTM、DN4、RCN、ATRNet、AMGC、MATANet、LB-Net、MSLPN等模型,对比方法在特征提取部分均使用Conv4-64(4层卷积,64维输出),FMAF方法实验结果如表2、3所示。
表2和3中的实验结果表明,FMAF方法在miniImageNet数据集上,其准确率相较于MSLPN,在小样本学习的5-way 1-shot和5-way 5-shot任务下分别提升了2.93百分点和2.27百分点;在tieredImageNet数据集上,本文方法在5-way 5-shot和5-way 1-shot 设置下分别提升了2.68百分点和2.71百分点。以上实验结果表明,FMAF方法在小样本图像分类上的精度高于其他方法。
2.4 特征可视化实验分析
为说明多粒度注意力特征提取结构所提取的图像特征的有效性,本文借助Grad-CAM[29]方法分别对Conv64、MSLPN及MAF网络所提取的特征进行可视化操作,热力图分别如图5(b)~(d)所示。通过对比可视化结果可以看出,Conv64与MSLPN网络所提取到的特征布局较为分散,对可区分的判别性特征不敏感,该模型进行分类时,由于提取的特征不充分,分类精度相对不高,尤其是面对小样本数据集中类别相近的任务时,容易分类错误。反观MAF网络结果下的热图可以看出,融合多种粒度层次下的图像信息得到了更具判别性和全面的提取,提取的特征可以更精确地表示图像。
2.5 网络复杂度分析
为了证明FMAF网络的轻量性、应用性,本文借助网络结构可视化工具torchsummary计算网络模型的参数数量及网络结构的计算量。所谓的计算量指的是输入单个样本(一张图像),模型完成一次前向传播所发生的浮点运算次数,即模型的时间复杂度,单位是FLOPs。
将FMAF网络与现有小样本主流特征提取主干网络Conv64、ResNet12、ResNet18相比较,结果如表4所示。
实验结果表明:FMAF网络的复杂度及参数量远远低于ResNet12、ResNet18,有效改进了模型运用中的实时性及运算速度;虽然相较于Conv64而言,复杂度及参数量都相差不大,但是分类的精度远高于Conv64。
2.6 消融实验
为了验证多粒度注意力机制融合网络设计的合理性,分别对该网络中粒度层数的取舍、加权融合权重的设置及有无注意力机制三个方面,在miniImageNet数据集上进行消融实验,实验结果如表5~7所示。
为了选取最合适的粒度层,本文进行了四组实验,分别对Conv64网络的第2、第3以及第4层输出的特征进行多粒度特征提取的有效性进行验证。实验结果表明:当选取Conv64网络最后3层的输出作为多粒度层的输入,分类效果最优。原因在于,单一粒度层获取的信息过于片面,无法更精确地表示图像。当选择Gra-layer2、Gra-layer3两层特征时,效果有所提升;当选取Gra-layer1、Gra-layer2、Gra-layer3三层特征进行分类时,准确率提升较为显著,说明充分利用浅层粗粒度特征并结合深层细粒度特征能有效提升分类的精度。在miniImageNet数据集上的5-way 1-shot和5-way 5-shot两种设置下,准确率分别达到58.06%±0.70%和74.08%±0.96%。
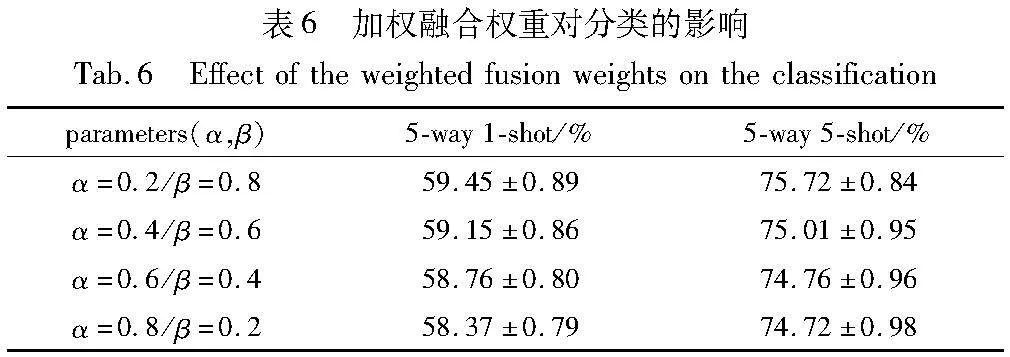
表5中的实验设置采用每个粒度层等权重的融合,未考虑不同粒度层所获取的图像特征信息对分类的贡献度问题。为此,针对Gra-layer1、Gra-layer2两个粒度层特征对分类精度的重要性进行消融实验,结果如表6所示。
由表6实验结果可知,当α=0.2,β=0.8时,模型达到了最优的性能。当α取值越来越大时,模型性能随之降低;当β取值越来越小时,模型性能同样也有所降低。实验表明,粗粒度信息对分类结果同样具有影响,给予粗粒度信息合适的权值,可以提高模型的分类性能。
表5和6在验证融合多粒度注意力特征时,已经考虑了自注意力机制对筛选重要特征的有效性。为了验证自注意力机制对模型性能是否有效果,本文设计了自注意力消融实验。实验结果如表7所示。
由表7可知,使用自注意力的结果要优于未使用自注意力的结果,这说明自注意力可以显著提高模型对图像中重要特征的捕获能力。
2.7 其他实验细节
根据上述实验结果与分析来看,FMAF模型中引入的自注意力机制对分类是有效果的。相较于其他常用的通道注意力(SE、CAM)[30]、空间注意力(SAM)[31]和通道空间双注意力机制(CBAM)[32]而言,自注意力机制[33]更擅长捕捉特征图中某一像素与全局像素之间的长期依赖关系,能够使得模型注意到整个输入中不同部分之间的相关性,而常见注意力机制局限于局部相邻像素之间的关系。
为了充分证明自注意力机制在模型中的有效性,本文在miniImageNet数据集进行常见注意力机制对比实验,结果如表8所示。
3 结束语
本文提出了一种融合多粒度注意力特征(FMAF)的小样本分类模型。该方法借助多粒度注意力特征融合网络,丰富了图像特征,解决了小样本低数据问题;同时借助标签传播算法,使相同的类尽可能地靠近,不同的类尽可能地拉远,最后完成分类。在两个数据集上的对比实验以及消融实验表明,FMAF方法有效提升了小样本图像分类的精度。未来FSIC研究可以从以下两方面进行:
a)利用卷积神经网络设计更高效的多粒度特征生成算法,丰富图像特征。
b)在特征提取过程中,可以借助三支决策理论,通过对网络每层特征进行决策,去除干扰信息,保留有效特征。
参考文献:
[1]Isabel S B,David C P,Sara G A. Exploring deep learning methods for recognizing rare diseases and their clinical manifestations from texts [J]. BMC Bioinformatics,2022,23(1): 263.
[2]Wu J,Chantiry X E,Gimpel T,et al. AI-based classification to facilitate preservation of British Columbia endangered birds species [C]// Proc of IEEE Canadian Conference on Electrical and Computer Engineering. Piscataway,NJ: IEEE Press, 2022: 85-88.
[3]葛轶洲,刘恒,王言,等. 小样本困境下的深度学习图像识别综述 [J]. 软件学报,2022,33(1): 193-210.(Ge Yizhou,Liu Heng,Wang Yan,et al. Summary of deep learning image recognition under the few-shot sample dilemma [J]. Journal of Software,2022,33(1): 193-210.)
[4]刘颖,雷研博,范九伦,等. 基于小样本学习的图像分类技术综述 [J]. 自动化学报,2021,47(2): 297-315.(Liu Ying,Lei Yanbo,Fan Jiulun,et al. Summary of image classification techniques based on few-shot learning [J]. Acta Automatica Sinica,2021,47(2): 297-315.)
[5]Zeng Zhiyong,Li Dawei,Yang Xiujuan. Deep domain adaptation using cascaded learning networks and metric learning [J]. IEEE Access,2023,11: 3564-3572.
[6]Koch G,Zemel R,Salakhutdinov R. Siamese neural networks for one-shot image recognition [C]// Proc of the 32nd International Confe-rence on Machine Learning. [S.l.]:JMLR,2015.
[7]Vinyals O,Blundell C,Lillicrap T,et al. Matching networks for one-shot learning [C]// Proc of the 30th Annual Conference on Neural Information Processing Systems. Cambridge,MA: MIT Press,2016: 3630-3638.
[8]Snell J,Swersky K,Zemel R. Prototypical networks for few-shot lear-ning [C]// Proc of the 31st Annual Conference on Neural Information Processing Systems. Cambridge,MA: MIT Press,2017: 4077-4087.
[9]Sung F,Yang Yongxin,Zhang Li,et al. Learning to compare: relation network for few-shot learning [C]// Proc of the 31st Meeting of the IEEE/CVF Conference Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 1199-1208.
[10]Li Wenbin, Xu Jinglin, Huo Jing,et al. Distribution consistency based covariance metric networks for few-shot learning [C]// Proc of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2019: 8642-8649.
[11]Santoro A,Bartunov S,Boyvinick M,et al. Meta-learning with memory augmented neural networks [C]// Proc of the 33rd International Conference on Machine Learning. New York: ACM Press,2016: 1842-1850.
[12]Finn C,Abbeeel P,Levine S. Model-agnostic meta-learning for fast adaptation of deep networks [C]// Proc of the 34th International Conference on Machine Learning. New York: ACM Press,2017: 1126-1135.
[13]Ravi S,Larochelle H. Optimization as a model for few-shot learning [C]// Proc of the 5th International Conference on Learning Representations. 2017.
[14]Li Wenbin,Wang Lei,Xu Jinglin,et al. Revisiting descriptor based image-to-class measure for few-shot learning [C]// Proc of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press, 2019: 7253-7260.
[15]Xue Zhiyu,Duan Lixin,Li Wen,et al. Region comparison network for interpretable few-shot image classification [EB/OL].(2020-09-08). https://arxiv.org/abs/2009.03558.
[16]李晓旭,刘忠源,武继杰,等. 小样本图像分类的注意力全关系网络 [J]. 计算机学报,2023,46(2): 371-384.(Li Xiaoxu,Liu Zhongyuan,Wu Jijie,et al. Total relation network with attention for few-shot image classification [J]. Journal of Computer Science,2023,46(2): 371-384.)
[17]王晓茹,张珩. 基于注意力机制和图卷积的小样本分类网络 [J]. 计算机工程与应用,2021,57(19): 164-170.(Wang Xiaoru,Zhang Hang. Relation network based on attention mechanism and graph convolution for few-shot learning [J]. Computer Engineering and Applications,2021,57(19): 164-170.)
[18]Chen Haoxing,Li Huaxiong,Li Yaohui,et al. Multi-scale adaptive task attention network for few-shot learning [C]// yD+cumv6c2rNFbHzlHO2Qg==Proc of the 26th International Conference on Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 4765-4771.
[19]Yu Z J,Sebastian R. Looking back to lower-level information in few-shot learning [J]. Information,2020,11(7): 345-358.
[20]汪航,田晟兆,唐青,等. 基于多尺度标签传播的小样本图像分类 [J]. 计算机研究与发展,2022,59(7): 1486-1495.(Wang Hang,Tian Shengzhao,Tang Qing,et al. Few-shot image classification based on multi-scale label propagation [J]. Journal of Computer Research and Development,2022,59(7): 1486-1495.)
[21]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 770-778.
[22]Liu Wei,Anguelov D,Erhan D,et al. SSD: single shot multibox detector [C]// Proc of the 14th European Conference on Computer Vision. Cham: Springer,2016: 21-37.
[23]Hu Miao,Li Yali,Wang Shengjin,et al. Attention aggregation based feature pyramid network for instance segmentation [C]// Proc of Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 15343-15352.
[24]华杰,刘学亮,赵烨. 基于特征融合的小样本目标检测 [J]. 计算机科学,2023,50(2): 209-213.(Hua Jie,Liu Xueliang,Zhao Ye. Few-shot object detection based on feature fusion [J]. Computer Science,2023,50(2): 209-213.)
[25]2022年中国粒计算与知识发现学术会议 [J]. 智能系统学报,2022,17(1): 219.(2022 China granular computing and knowledge discovery conference [J]. Trans on Intelligent Systems,2022,17(1): 219.)
[26]Wang Xiaoru,Ma Bing,Yu Zhihong,et al. Multi-scale decision network feature fusion and weighting for few-shot learning [J]. IEEE Access,2020,8: 92172-92181.
[27]Jin H Y,Dongsuk K,Jun W C. ScarfNet:multi-scale features with deeply fused and redistributed semantics for enhanced object detection [C]// Proc of the 25th International Conference on Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 4505-4512.
[28]Liu Yanbin,Lee J,Park M,et al. Learning to propagate labels: transductive propagation network for few-shot learning [C]// Proc of the 7th International Conference on Learning Representation. 2019.
[29]Chattopadhyay A,Sarkar A,Howlader P,et al. Grad-CAM+: genera-lized gradient-based visual explanations for deep convolutional networks [C]// Proc of IEEE Winter Conference on Applications of Computer Vision. 2018: 839-847.
[30]Hu Jie,Shen Li,Albanie S,et al. Squeeze-and-excitation networks [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2020,42(8): 2011-2023.
[31]Song Heda,Deng Bowen,Michael P,et al. A fusion spatial attention approach for few-shot learning [J]. Information Fusion,2022,81: 187-202.
[32]Sanghyun W,Jongchan P,Young L,et al. CBAM: convolutional block attention module [EB/OL].(2018-07-18). https://arxiv.org/abs/1807.06521.
[33]Jain R,Watanabe H. Self-attention based neural network for few shot classification [C]// Proc of the 9th IEEE Global Conference on Consumer Electronics. Piscataway,NJ: IEEE Press,2020: 429-430.
