
基于反向延长增强的对抗生成网络推荐算法
2024-08-17 00:00:00张文龙孙福振吴相帅李鹏程王绍卿
计算机应用研究 2024年7期



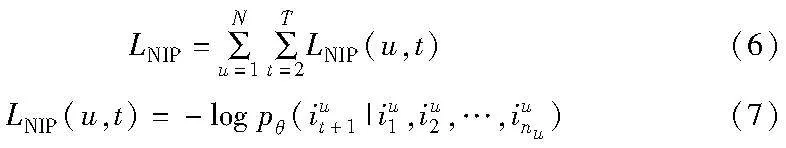


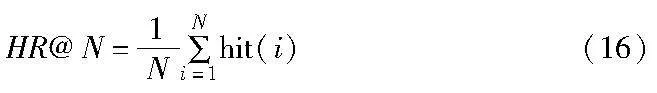


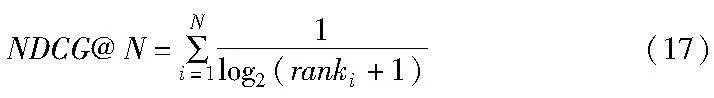








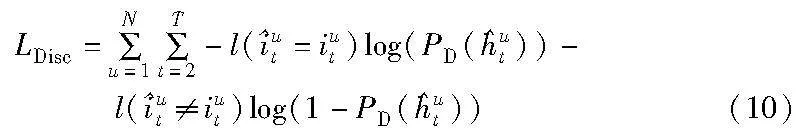
摘 要:针对现有序列推荐模型因数据稀疏性严重难以达到最优性能的问题,提出了一种基于反向延长增强的生成对抗网络推荐算法。该方法通过对交互序列进行延长增强来获取高质量的训练数据,以缓解数据稀疏性带来的模型训练不充分的问题。首先,使用伪先验项将项目序列进行反向延长,深化项目序列特征;其次,延长增强的对象由短序列更改为所有用户序列,充分挖掘长序列中富含的上下文信息,缓解了增广序列中伪先验项占比过大而带来的噪声问题;最后,使用共享项目嵌入的生成对抗网络,通过判别器与生成器联合训练以提高模型推荐性能。在三个公开数据集上的实验结果表明,所提模型的命中率(HR@N)和归一化折损累计增益(NDCG@N)相较于最优基线ELECRec平均提升30%,验证了反向延长增强对挖掘序列特征和缓解数据稀疏性的有效性。
关键词:推荐系统; 反向延长增强; 生成对抗网络; 序列推荐; 自注意力网络
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)07-016-2033-06
doi:10.19734/j.issn.1001-3695.2023.11.0548
Generative adversarial network recommendation based onreverse extension enhancement
Abstract:Addressing the challenge of suboptimal performance in existing sequential recommendation models due to severe data sparsity, this paper proposed a generative adversarial network recommendation algorithm based on reverse extension enhancement. The approach extended and enhanced interaction sequences to obtain high-quality training data, mitigating the issue of insufficient model training caused by data sparsity. Firstly, it extended the project sequences backwardly using pseudo-prior terms to deepen the features of the project sequences. Secondly, it shifted the target of extension enhancement from short sequences to all user sequences, thoroughly exploring contextual information embedded in long sequences and alleviating noise issues arising from an excessively large proportion of pseudo-prior terms in augmented sequences. Finally, it employed a generative adversa-rial network with shared project embeddings, and jointly trained the discriminator and generator to enhance the model’s recommendation performance. Experimental results on three public datasets demonstrate an average improvement of 30% in hit rate(HR@N) and normalized discounted cumulative gain(NDCG@N) compared to the optimal baseline ELECRec, confirming the effectiveness of reverse extension enhancement in mining sequence features and alleviating data sparsity.
Key words:recommendation system; reverse extension enhancement; generative adversarial networks; sequential recommendation; self-attention networks
0 引言
在人工智能时代背景下,出现了很多信息过载[1]的问题,推荐系统[2]是减轻用户信息过载的重要工具。推荐系统的核心任务之一是序列推荐[3],其通过用户项目序列来挖掘用户表示,由于序列推荐实用价值高且使用场景广泛,近年来受到了研究者的广泛关注。
早期的序列推荐研究中,学者大多使用了马尔可夫链[4],只考虑近期的用户行为,无法整体建模用户的偏好。在循环神经网络(recurrent neural network,RNN)[5]被提出之后,其因能够建模项目之间的关系的特点逐渐流行,特别是在提出GRU4Rec(gated recurrent unit for recommendation)[6]之后,RNN模型更是成为了推荐算法的主流模型。随着深度学习的发展,Tang等人[7]提出了基于卷积神经网络的算法Caser(convolutional sequence embedding recommendation model),其使用滤波器建模序列特征,并将用户的长期和短期偏好[8]进行简单融合。
最近的研究中,在序列推荐领域涌现了两个主要研究方向。一方面,研究强大的模型来实现更好的推荐性能。有学者证明Transformer[9]可以有效地对项目相关性进行建模,Wang等人[10]对Transformer在序列推荐中的应用做出了开创性工作,他们提出了SASRec(self-attentive sequential recommendation)算法,使用点积自我注意力机制来学习序列中不同位置的项目对聚合特征的影响力。BERT4Rec[11](sequential recommendation with bidirectional encoder representations from transformer)在从左到右和从右到左两个方向对项目转换相关性进行建模。生成对抗网络[12]在最开始是用来模拟给定样本的生成,IRGAN [13](generative adversarial network for information retrieval)首先将生成对抗网络应用于信息检索中,采用简单的矩阵分解[14]构造了生成器和判别器。ELECRec(training sequential recommenders as discriminators)联合训练生成器和判别器,将判别器作为最终的推荐模型。然而,序列推荐模型对项目相关性[15]有效动态建模的能力受限于用户项目序列长度过短,因此强大模型也会受到数据稀疏性的影响。
另一方面,对模型的实验数据进行数据增强以获得更有效的训练数据集。其中PCRec[16](enhancing top-N item recommendations by peer collaboration)使用两个结构相同、参数不同的网络共同训练,并且对每一层的无效参数进行激活,达到相互合作的目的。S3-Rec(self-supervised learning for sequential recommendation)[17]和CL4SRec[18](contrastive learning for sequential recommendation)提出通过随机的reorder、mask和crop序列来增强用户的项目序列,丰富训练集。ASReP[19](augmenting sequential recommendation with pseudo-prior items)提出了延长增强,通过反向训练Transformer模型来获得伪先验项,用于延长增强。上述数据增强方法在提高序列数量的同时,却面临因序列语义不完整而增加噪声和上下文信息不能有效融合的问题。为此,本文提出了一种反向延长的显式数据增强方法,通过使用伪先验项延长序列长度以保证序列的语义完整性,并将延长增强的方法扩展到长短序列,深度挖掘长序列中的上下文信息来弥补短序列信息不足的问题,提升模型的推荐性能。此外,方法还利用共享项目嵌入的生成对抗网络来精准把握用户长短期偏好。本文的主要工作包括:
a)提出了一种基于反向延长增强的生成对抗网络推荐算法(generative adversarial network recommendation based on reverse extension enhancement,REEGAN)。通过生成伪先验项来深度挖掘项目序列特征,并提出改进的延长增强方式,缓解伪先验项序列过长带来的噪声问题,优化了模型的训练。
b)引入了共享项目嵌入的生成对抗网络,通过共享项目嵌入信息,使模型能够更好地理解和利用项目之间的关联性,从而提高推荐的准确性和个性化程度。
c)经实验结果证明,所提算法较当前最优基线有明显提升,充分展示了其有效性和延长增强在序列推荐中的优势。在冷启动数据集上的实验证明了所提模型在缓解用户冷启动问题上也具有良好的效果。
1 问题定义
设数据集中用户集为U={u1,u2,…,um},其中m为用户集中用户个数,项目集合V={i1,i2,…,ik},其中k为项目集中项目的个数,则用户u按交互时间排序的项目序列Iu表示为
本文相关符号定义如表1所示。
2 基于反向延长增强的生成对抗网络推荐算法
2.1 模型框架
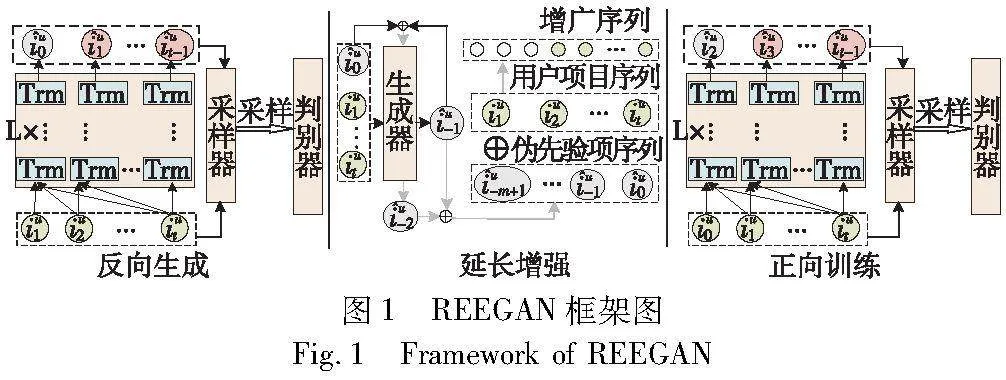
为了充分挖掘项目序列中丰富的上下文信息,本文设计了一种延长增强的数据增强方式,并使用生成对抗网络来实现该算法。本文算法总体框架如图1所示,自上到下划分为三个核心模块,分别为反向生成、延长增强、正向训练。REEGAN算法三个核心模块的处理过程如下:
b)延长增强模块:模型通过延长增强模块将伪先验项序列I^u和项目序列Iu拼接为增广序列Iaug,该模块将模型对交互序列的逆向理解与原始项目序列的上下文信息有机地融合,创造了更为丰富的增广序列。
2.1.1 反向生成模块
为了生成包含更多上下文信息的伪先验项序列,本文设计了反向生成模块以生成伪先验项序列。生成的伪先验项既需要保持项目序列的相关性,还需要体现用户兴趣转变,因而,本文对模型进行反向训练,以保证模型能够学习到丰富的反向知识,使得生成的伪先验项保持原有序列的项目相关性;同时反向语义中蕴涵用户兴趣的转变,模型可以更好地捕捉用户偏好。在实现的过程中将用户项目序列Iu作为输入数据,并据此预测用户u的项目交互序列Iu的前一项,即伪先验项u0:
2.1.2 延长增强模块
为了解决上述问题,本文采用了对所有项目序列进行延长增强的方法。相比仅针对短序列的延长增强,长序列中蕴涵更丰富的信息,因此模型只需要使用少量的伪先验项就能够达到最优推荐性能。这一改进不仅减少了伪先验项序列带来的噪声,还简化了模型的训练过程。
2.1.3 正向训练模块
本模块旨在利用增广序列中丰富的上下文信息进行序列推荐任务的训练,使用增广序列作为训练数据,且模型训练的方向与常规模型方向相同,在序列推荐任务中,用户的历史行为通常按时间顺序排列,因此从左到右的训练方向更符合时序性的学习需求。这种一致性有助于模型更好地捕捉用户行为的演变趋势,提高对时序性特征的学习能力。具体来说,将增广序列Iuaug作为输入数据,并据此预测用户u在t+1步的交互项目:
p(iut+1=i|Iuaug)(4)
其中:iut+1为模型即将推荐给用户u的项目;Iuaug则为用户u经过延长增强后的增广项目序列。
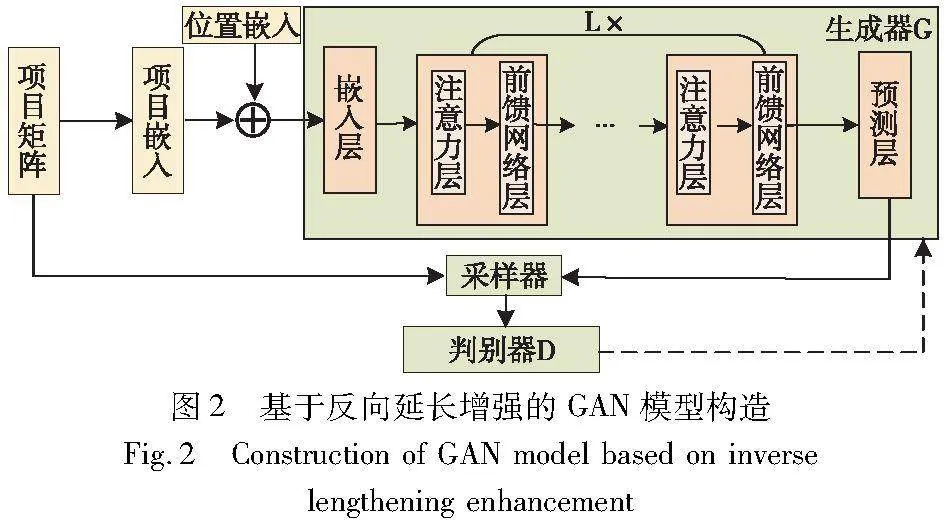
2.2 基于反向延长增强的GAN模型构造
为使得伪先验项更加符合项目序列特征和增加推荐效果,本文使用生成对抗网络来构造REEGAN,其通过生成器和判别器之间的相互对抗,能够使得生成器生成的项目更加准确。REEGAN中的生成器和判别器均由Transformer模型构造,其网络表示为fG和fD。图2展示了基于反向延长增强的GAN模型的具体构造。生成器的任务为模拟真实数据的分布情况来生成虚假样本,以骗过判别器的判断,从而鼓励判别器提高其判别项目的能力。判别器的任务则为判断给定输入的项目是真实样本还是虚假样本,督促生成器产生更加高质量的样本,这两者的任务目标是相反的,其互相对抗以获得更加真实的数据。其中真实样本为用户项目序列,虚假样本为生成器生成的项目。
2.2.1 生成器
为实现生成器根据用户历史交互数据的特征来生成伪先验项和推荐项目的目标,本文采用生成性任务训练生成器。对每个时间步t,用户u对项目i的偏好使用softmax层来表示:
在训练过程中,截断用户项目序列前n-1项[20],将此作为生成器的训练数据,训练目标为恢复第n个项目,此训练目标促使生成器更加专注于从已观察到的历史信息中提取序列特征,并用这些特征来生成下一个项目,这对于生成器在真实场景中准确生成用户可能感兴趣的项目是至关重要的。其训练损失为
其中:θ为神经网络fθ,其编码序列潜在空间表示为hut=fθ({iuj}tj=1),以此来衡量编码序列hut与潜在空间表示中下一个项目iuj+1之间的相似性。
2.2.2 采样器
采样器通过参数α控制着在生成序列时采用已有序列信息和生成器模型输出之间的相对权重。这种相对权重可以在一定程度上保留原始序列的语义完整性,同时引入模型的创造性和泛化能力。采样器的采样步骤为:首先对序列中百分之α
2.2.3 判别器
对于判别器,使用二元交叉熵损失来进行训练,如下所示。
2.2.4 生成器和判别器组件
项目嵌入层是将项目映射为潜在空间的关键部分,本文中这一层由生成器和判别器共享。通过这种共享机制,梯度可以通过嵌入层传播,使得生成器和判别器能够相互影响。这种共享机制促使两个模块在训练中共同学习更具代表性的项目嵌入,有助于提高整体模型的一致性和性能。模型中嵌入层的表示为项目嵌入和位置嵌入的和:
h0t=it+pt(11)
其中:pt∈P是位置索引t的位置嵌入,并且使用可学习的位置嵌入,这样可以获得更好的性能。对模型可处理的最大长度n进行了限制,当序列长度大于n时,取序列右侧的n项,序列长度不足n时,则在序列右侧增加填充项。
单个自注意力模块由自注意力层和位置前馈网络构成。其中注意力机制被定义为
Fi=FFN(hit)=ReLU(hitW(1)+b(1))W(2)+b(2)(13)
其中:W(1)和W(2)是一个d维的参数矩阵;b(1)和b(2)是d维的偏置向量。为了学习更复杂的特征转换,选择堆叠自注意力模块,在每个自注意力层和位置前馈网络增加残差连接、层归一化和dropout:
g(x)=x+dropout(g(LayerNorm(x)))(14)
其中:g(x)代表自注意力层或者位置前馈网络,即对输入的x进行层归一化之后放入网络中,并对其输出进行dropout处理,最后将x添加到输出中。
2.3 损失函数
在模型训练阶段进行联合训练,最小化以下损失:
L=LNIP(I,G)+λLDisc(,D)(15)
其中:LNIP为生成器损失;LDisc为判别器损失;λ是一个用来控制判别强度的超参数。
2.4 算法伪代码
算法1 REEGAN算法
3 实验与结果分析
3.1 数据集
本文对从亚马逊评论收集的具有不同数据分布的三个数据集进行了实验研究,其分别为sports、beauty和toys。为了获得有意义的训练集数据,本文与其他模型的处理方式相同 [21],删除了所有相关交互少于5次的用户和项目,将数据集分为训练集、验证集和测试集,项目序列的最后一个项目用于测试,倒数第二个项目用于验证,其余项目用于训练,数据集统计信息如表2所示。
3.2 评价指标
为给予推荐效果定量的评价,使用命中率(hit rate,HR)和归一化折损累计增益(normalized discounted cumulative gain,NDCG)来评估模型推荐性能,采用了HR@5、HR@10、NDCG@5、NDCG@10四个常用的top-N评价指标。
1)命中率 HR@N衡量真实项目是否排在前N个推荐项目中:
其中:hit()函数代表是否命中,即真实交互项目是否在推荐列表中,存在则hit()为1,反之为0。
2)归一化折损累计增益 NDCG@N则会给予N个项目中前排真实项目更大的分数,充分考虑了位置因素:
其中:rank为命中项目在推荐列表中的位置。
3.3 基线方法
本文采用了两种类型的基线模型来进行对比实验,一种为依靠模型能力进行推荐的算法SASRec、BERT4Rec、S3-Rec、Seq2Seq;另一种为基于数据增强的推荐算法CL4Srec、DuoRec、EMKD。为保证基线模型发挥最优效果,对比实验使用基线模型的默认参数。对比模型的简要介绍如下:
SASRec[10]:使用Transformer代替RNN捕捉用户的特征。
BERT4Rec[11]:使用双向注意力机制建模用户的特征,具有较好的推荐性能。
S3-Rec[18]:使用自注意力网络的自监督学习方法。
Seq2Seq[22]:一种新的Seq2Seq训练策略,通过研究用户更长期的未来行为来提供额外的监督信号。
ELECRec[23]:一种生成对抗网络方法,在训练完成后将生成器丢弃,将判别器作为最终的推荐模型。
CL4SRec[18]: 提出了三种不同的数据增强方法来构建不同视角的用户交互序列,并将其用于对比学习来捕捉不同视角之间的相似性。
DuoRec[24]:利用对比学习来重建序列表征,并构建模型级增强来更好地保留语义信息。
EMKD[25]:采用多个并行网络,并使用对比知识蒸馏来促进网络间的知识转移。
3.4 实现细节
本文基于PyTorch设计实现了REEGAN模型,选择Adam作为优化器,验证集上NDCG@10连续20轮次,不再提升时停止训练,最优超参数组合根据模型在验证集上的表现确定,在测试集上验证模型效果。本文对应的超参数设置为:批量大小设置为256,自注意力模块层数和头数设置为2,并将嵌入维度和最大序列长度分别设置为64和50。
3.5 实验结果分析
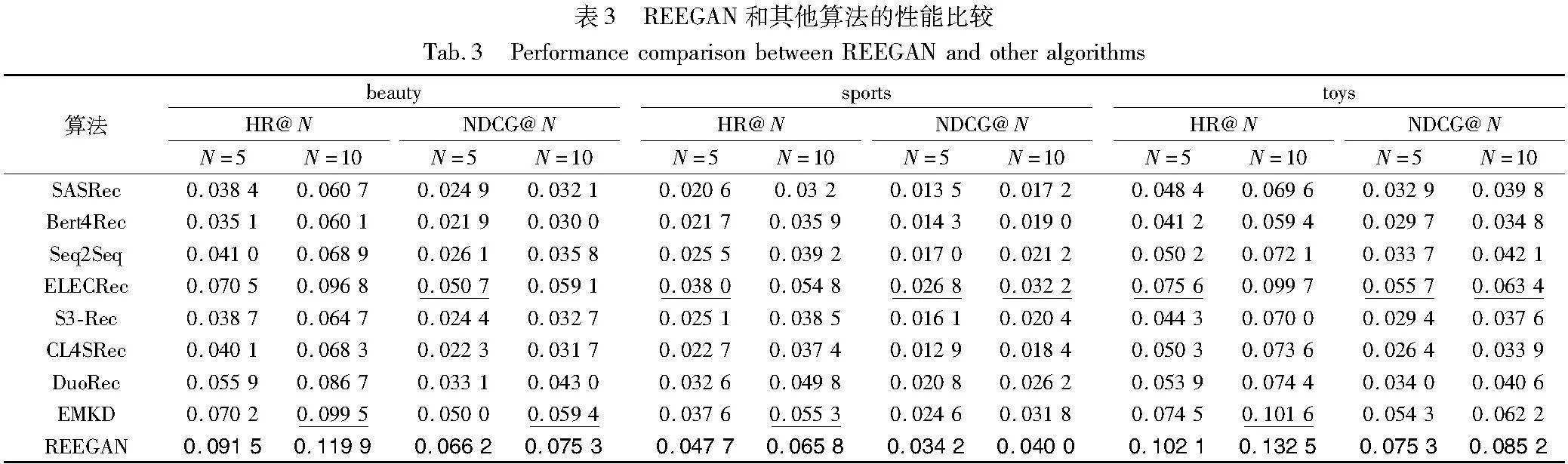
为评估所提模型的推荐性能,本文在beauty、sports和toys数据集上进行了对比实验,REEGAN与基线模型的性能比较如表3所示。
实验结果表明:
a)REEGAN与基线模型相比有明显提升,与次优基线相比,在评价指标HR和NDCG中平均提升了30%,在beauty数据集中,模型在评价指标HR@10上提升了23.8%,标准差为0.001 59,验证了延长增强和生成对抗网络的有效性。
b)REEGAN优于DuoRec等数据增强的方法,表明了延长增强在增强交互序列特征方面的有效性,避免了“裁剪”“遮蔽”等随机数据增强方法对用户特征的损害。然而,基于数据增强的方法优于SASRec等仅基于模型能力的算法,这表明对数据进行数据增强是有必要的,有助于解决现有模型存在的数据稀疏性问题。
c)基于生成对抗网络的推荐算法优于其他算法,这表明了基于GAN的推荐算法在捕捉用户偏好方面具有出色的性能。尤其值得注意的是,与数据增强方法(如DuoRec)相比,基于GAN的算法(例如ELECRec)在推荐性能上略有优势。其原因可能为ELECRec采用判别器作为推荐模型,而判别性任务对于训练数据的要求相对较低。这种设计允许ELECRec更好地适应数据稀疏性,同时保持了高性能。与此相反,这些随机数据增强的方法可能损害序列的语义特征,甚至带来了大量噪声,因而推荐性能不佳。
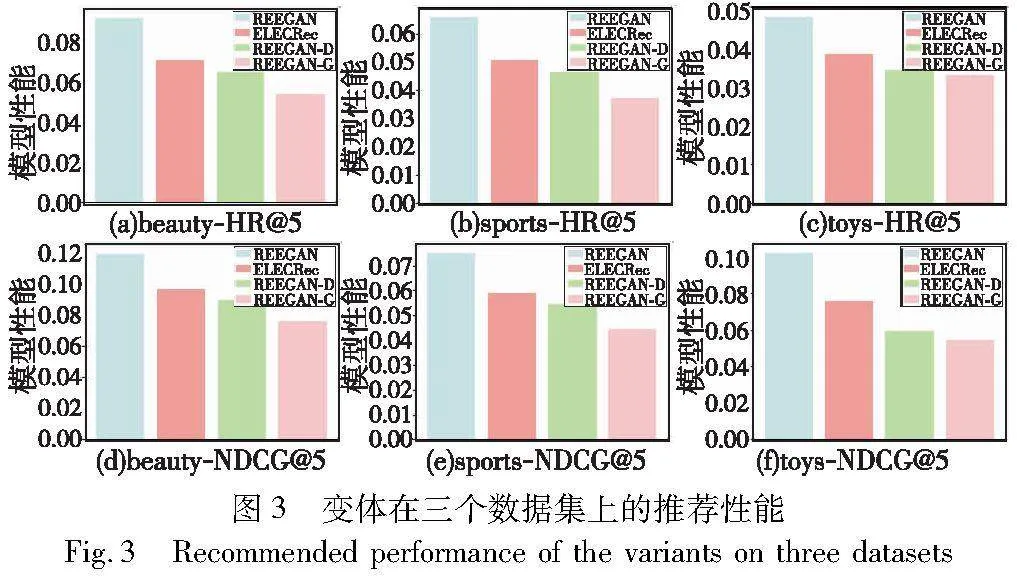
3.6 消融实验分析
为了验证最终推荐模型的类别和延长增强分别对推荐性能的影响,在三个数据集上进行了两个消融实验,实验结果如图3所示。变体模型如下:REEGAN-D,使用判别器作为最终生成伪先验项和推荐项目的模型;REEGAN-G,此变体去除了延长增强,仅使用生成对抗网络来捕捉用户偏好,最终将生成器用于推荐。
由图3可以看出,REEGAN在所有情况下均优于其他变体。其中,两个变体的性能低于基线ELECRec,表明延长增强和以生成器为推荐模型两个结合才能够发挥效果,单独无法发挥正向作用。
REEGAN-D的推荐性能较差的原因为模型需要与交互序列相关性较强的伪先验项来延长序列,判别器生成的伪先验项仅考虑个体,生成的伪先验项关联性不强,反而给模型带来大量噪声。
REEGAN-G则因数据稀疏性表现最差,ELECRec的性能优于REEGAN-G的原因为判别性任务对数据的要求较低,从而能够达到较好的推荐性能,REEGAN则因高质量的延长增强后的训练数据,而训练出充分发挥功能的生成器用于推荐。
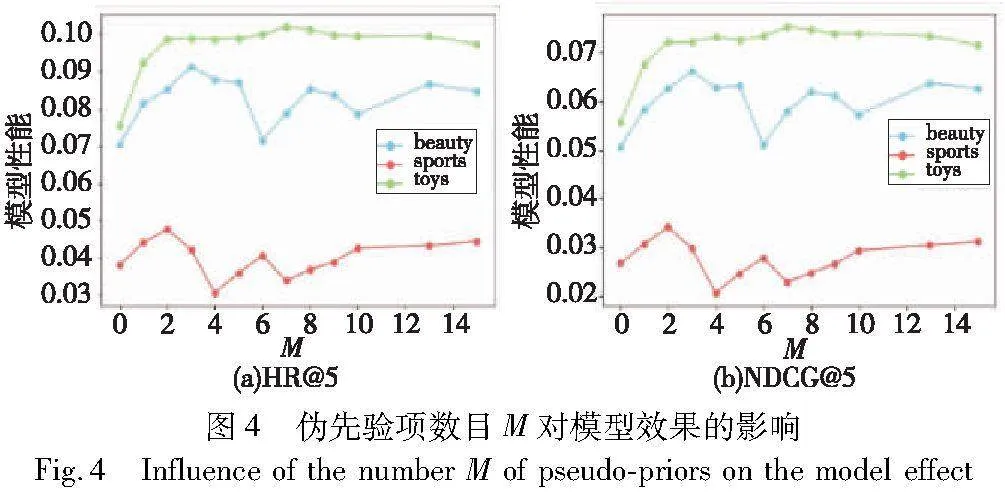
3.7 增广序列参数分析
增广序列由伪先验项序列和交互序列组成,为了研究增广序列中参数对推荐性能的影响,本文针对伪先验项数目M在三个不同的数据集进行了一系列实验。如图4所示,本文在三个数据集上测试了不同超参数M对评价指标HR@5和NDCG@5的影响。
实验结果表明以下几点:
a)在三个数据集中,当伪先验项数目M设定为3时,模型达到了最佳性能水平。这进一步验证了所提算法的有效性,因为它缩短了伪先验项序列的长度,从而减轻了因伪先验项数目过多而引入的大量噪声问题。
b)当伪先验项数目M为0时,模型性能较差,验证了在短序列情况下模型学习能力有限。适度增加伪先验数目M后,模型性能显著提升,验证了延长增强的有效性。然而,进一步增加伪先验数目并不会显著提升性能,而可能引入更多噪声。
3.8 案例分析
为了更加深入地理解所提模型,以用户u的交互数据[i1,i2,…,i4]为例,展示了REEGAN的推荐过程,如图5所示。
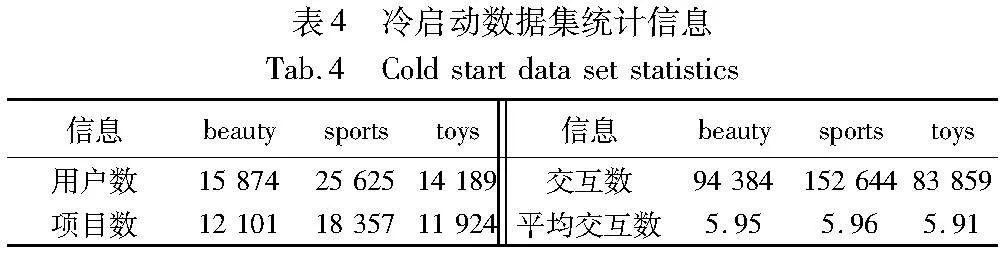
3.9 冷启动分析
反向延长增强通过扩展交互序列的长度来缓解数据稀疏的问题。为了深入研究在数据极度稀疏的情况下模型的推荐表现,构建了一组冷启动数据集,数据集的统计信息如表4所示,其去除了长度大于7的交互数据,将序列长度限制在5~7。可以发现在三个数据集中,交互数据占原数据集的70%左右,即用户交互长度大多较短。实验结果如图6所示。
从图6中可以看到,所提模型在三个稀疏数据集上表现出色,与最佳基线模型ELECRec相比,实现了最佳的推荐性能。这一结果验证了所提模型在处理冷启动问题上的有效性,并间接证明了反向延长增强对推荐性能的贡献。
4 结束语
为缓解数据稀疏性的问题,本文提出了一种基于反向延长增强的生成对抗网络推荐方法REEGAN,通过反向训练模型生成伪先验项序列的方式来增加用户项目序列长度,使其携带更多的上下文信息,延长增强的对象不再为自定义长度的短序列,降低了伪先验项序列长度过长带来的噪声。在三个真实数据集上的实验结果表明,所提算法性能相较最新的基线算法更优,消融实验也证明了反向延长增强的有效性。最后,模型在冷启动数据集上的表现进一步验证了其在缓解数据稀疏性方面的能力。在未来的工作中,将继续探究根据序列长度的分布与关系,实现自适应延长,并考虑使用增广序列作为对比学习的新视图,以提高模型的推荐性能。
参考文献:
[1]Fan Ziwei, Liu Zhiwei, Wang Yu, et al. Sequential recommendation via stochastic self-attention[C]//Proc of ACM Web Conference. New York:ACM Press, 2022: 2036-2047.
[2]Xie Ruobing, Zhang Shaoliang, Wang Rui, et al. A peep into the future: adversarial future encoding in recommendation[C]//Proc of the 15th ACM International Conference on Web Search and Data Mining. New York:ACM Press, 2022: 1177-1185.
[3]欧道源, 梁京章, 吴丽娟. 基于高斯分布建模的序列推荐算法[J]. 计算机应用研究, 2023, 40(4):1108-1112. (Ou Daoyuan, Liang Jingzhang, Wu Lijuan. Algorithm of sequential recommendation based on Gaussian distribution modeling[J]. Application Research of Computers, 2023,40(4) :1108-1112.
[4]Li Kaiyuan, Wang Pengfei, Li Chenliang. Multi-agent RL-based information selection model for sequential recommendation[C]//Proc of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2022:1622-1631.
[5]Han Jiadi, Tao Qian, Tang Yufei, et al. DH-HGCN: dual homogeneity hypergraph convolutional network for multiple social recommendations[C]//Proc of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2022: 2190-2194.
[6]Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[EB/OL]. (2016-03-29). https://arxiv.org/abs/1511.06939.
[7]Tang Jiaxi, Wang Ke. Personalized top-n sequential recommendation via convolutional sequence embedding[C]//Proc of the 11th ACM International Conference on Web Search and Data Mining. New York:ACM Press,2018: 565-573.
[8]刘树栋, 张可, 陈旭. 基于多维度兴趣注意力和用户长短期偏好的新闻推荐[J]. 中文信息学报, 2022, 36(9): 102-111. (Liu Shudong, Zhang Ke, Chen Xu. Multi-dimensional interest-attention-based news recommendation with long and short-term user preferences[J]. Journal of Chinese Information Processing, 2022, 36(9): 102-111.)
[9]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010.
[10]Wang Chengkang, McAuley J. Self-attentive sequential recommendation[C]//Proc of IEEE International Conference on Data Mining. Piscataway, NJ: IEEE Press, 2018: 197-206.
[11]Sun Fei, Liu Jun, Wu Jian, et al. BERT4Rec: sequential recommendation with bidirectional encoder representations from Transformer[C]//Proc of the 28th ACM International Conference on Information and Knowledge Management. New York:ACM Press, 2019: 1441-1450.
[12]陈继伟, 汪海涛, 姜瑛, 等. 基于生成对抗模型的序列推荐算法[J]. 中文信息学报, 2022,36(7): 143-153. (Chen Jiwei, Wang Haitao, Jiang Ying, et al. Sequential recommendation with generative adversarial networks[J]. Journal of Chinese Information Processing, 2022, 36(7): 143-153.)
[13]Wang Jun, Yu Lantao, Zhang Weinan, et al. IRGAN: a minimax game for unifying generative and discriminative information retrieval models[C]//Proc of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2017: 515-524.
[14]周璐鑫, 李曼, 蒋明阳,等. 融合交互强度的优化社交推荐算法[J]. 计算机应用研究, 2024,41(1):65-71. (Zhou Luxin, Li Man, Jiang Mingyang, et al. Improving social recommendation algorithm via embracing interaction strength[J]. Application Research of Computers, 2024,41(1):65-71.)
[15]石美惠, 申德荣, 寇月, 等. 融合全局和局部特征的下一个兴趣点推荐方法[J]. 软件学报, 2023,34(2): 786-801. (Shi Meihui, Shen Derong, Kou Yue, et al. Next point-of-interest recommendation approach with global and local feature fusion[J]. Journal of Software, 2023,34(2): 786-801.)
[16]Zhai Mengjia, Gu Fei, Wang Jin, et al. PCRec: a private coding computation scheme based on edge computing for recommendation system[C]//Proc of IEEE International Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking. Piscataway, NJ: IEEE Press, 2020: 183-191.
[17]Zhou Kun, Wang Hui, Zhao W X, et al. S3-Rec: self-supervised learning for sequential recommendation with mutual information maximization[C]//Proc of the 29th ACM International Conference on Information & Knowledge Management. New York:ACM Press, 2020: 1893-1902.
[18]Xie Xu, Sun Fei, Liu Zhaoyang, et al. Contrastive learning for sequential recommendation[C]//Proc of the 38th IEEE International Conference on Data Engineering. Piscataway, NJ: IEEE Press, 2022: 1259-1273.
[19]Liu Zhiwei,Fan Ziwei,Wang Yu,et al. Augmenting sequential recommendation with pseudo-prior items via reversely pre-training transformer[C]//Proc of the 44th International ACM SIGIR Conference on Research And Development in Information Retrieval. New York:ACM Press, 2021: 1608-1612.
[20]钱忠胜, 杨家秀, 李端明, 等. 结合用户长短期兴趣与事件影响力的事件推荐策略[J]. 计算机研究与发展, 2022,59(12): 2803-2815. (Qian Zhongsheng, Yang Jiaxiu, Li Duanming, et al. Event recommendation strategy combining user long-short term interest and vent influence[J]. Journal of Computer Research and Development, 2022,59(12): 2803-2815.)
[21]Fan Ziwei, Liu Zhiwei, Zhang Jiawei, et al. Continuous-time sequential recommendation with temporal graph collaborative transformer[C]//Proc of the 30th ACM International ConferenceIenME5s4s3Djsc6dpCZSAAePdWT2n9VppW6KSQAmPC0= on Information & Knowledge Management. New York:ACM Press, 2021: 433-442.
[22]Ma Jianxin, Zhou Chang, Yang Hongxia, et al. Disentangled self-supervision in sequential recommenders[C]//Proc of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York:ACM Press, 2020: 483-491.
[23]Chen Yongjun, Li Jia, Xiong Caiming. ELECRec: training sequential recommenders as discriminators[C]//Proc of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2022: 2550-2554.
[24]Qiu Ruihong, Huang Zi, Yin Hongzhi, et al. Contrastive learning for representation degeneration problem in sequential recommendation[C]//Proc of the 15th ACM International Conference on Web Search and Data Mining. New York:ACM Press, 2022: 813-823.
[25]Du Hanwen, Yuan Huanhuan, Zhao Pengpeng, et al. Ensemble mo-deling with contrastive knowledge distillation for sequential recommendation[C]//Proc of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2023:58-67.
