
结合社交网络图的多模态虚假信息检测模型
2024-08-17 00:00:00叶舟波罗舜于娟
计算机应用研究 2024年7期




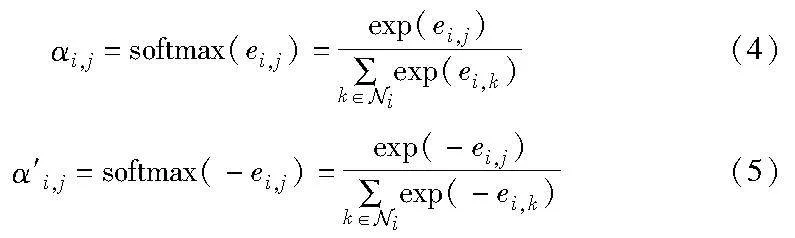





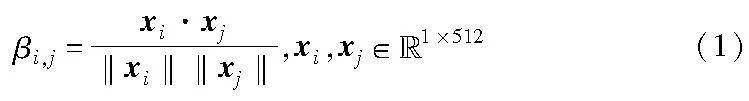

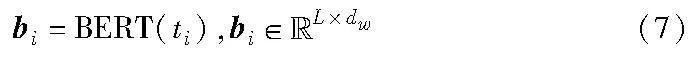

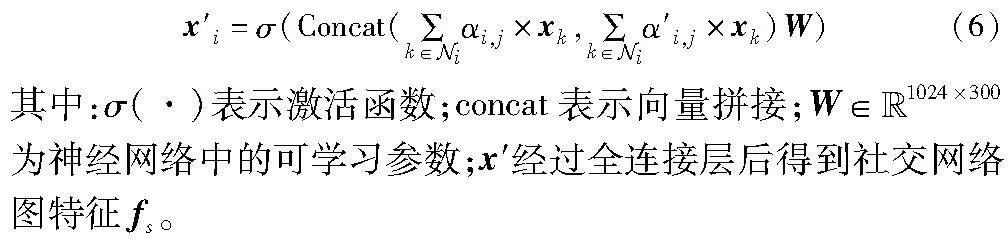

摘 要:针对现有虚假信息检测方法主要基于单模态数据分析,检测时忽视了信息之间相关性的问题,提出了结合社交网络图的多模态虚假信息检测模型。该模型使用预训练Transformer模型和图像描述模型分别从多角度提取各模态数据的语义,并通过融合信息传播过程中的社交网络图,在文本和图像模态中加入传播信息的特征,最后使用跨模态注意力机制分配各模态信息权重以进行虚假信息检测。在推特和微博两个真实数据集上进行对比实验,所提模型的虚假信息检测准确率稳定为约88%,高于EANN、PTCA等现有基线模型。实验结果表明所提模型能够有效融合多模态信息,从而提高虚假信息检测的准确率。
关键词:网络舆情; 虚假信息检测; 多模态融合; 跨模态注意力; 社交网络图
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)07-010-1992-07
doi:10.19734/j.issn.1001-3695.2023.11.0565
Multimodal misinformation detection model with social network graph
Abstract:To address the issues of existing misinformation detection approaches, which primarily focus on single-modal data analysis and ignore the correlation between information during detection, this paper proposed a multimodal misinformation detection model combined with the social network graph(MMD-SNG model). This model used the pre-trained Transformer model and the image caption model to extract the semantics of each modality from multiple perspectives. It incorporated the features of propagated information into the text and image data by fusing the social network graph of the information dissemination process. Finally, this model used a multimodal co-attention mechanism to allocate the weights of each modality for misinformation detection. This paper conducted comparative experiments on two real datasets including Twitter and Weibo, the proposed MMD-SNG model achieved a consistent detection accuracy of approximately 88%, which was higher than existing misinformation detection approaches such as EANN and PTCA. The experimental results demonstrate that the proposed model can fuse multimodal information effectively to improve the accuracy of misinformation detection.
Key words:online public opinion; misinformation detection; multimodal fusion; multimodal co-attention; social network graph
0 引言
随着我国数字经济的发展与通信基础设施的日益完善,我国网民规模已达到10.67亿,互联网在城乡居民生活中得到了越来越广泛的普及与应用[1]。以微博、推特、微信朋友圈等为主的在线社交媒体平台逐步取代传统纸质与电视媒体,成为人们获取信息、分享观点、交换意见的主要场所。在线社交媒体平台正在促进文本、图片等多模态形式的信息在互联网上快速传播,而这些海量的多模态信息对我国网民和社会舆情有着广泛且深远的影响。虽然在线社交媒体平台拥有许多优秀内容,但由于其用户规模庞大且内容来源难以检测,其同样易被用来传播各种形式的虚假信息,如图1所示。不实信息借助在线社交媒体平台进行快速传播,往往会误导用户甚至引发严重的网络舆情管理问题[2]。因此,作为及时阻止虚假信息传播的基础环节,准确检测社交平台中的虚假信息就显得至关重要。
模态是指信息的来源或者信息表示形式。文本、图像、视频、声音和种类繁多的传感器信号都可以称为一种模态[3]。其中,文本和图像是当前在线社交媒体的主要内容形式。不同模态表示的信息往往存在交叉或互补,融合具有交叉或互补内容的多模态数据能够为管理决策提供更多且更准确的信息,提高决策准确率。因此如何处理利用所获取的多模态信息是提高决策总体准确率的关键[4]。
传统的虚假信息检测方法,主要从单一图像模态或单一文本模态入手进行检测,或是对两种模态进行简单的融合,一方面从文本方面对在线社交媒体平台内容制定文本规则或关键词屏蔽,另一方面从图片方面进行图片特征检测[5]。这类方法的主要问题有:a)虚假信息检测过程中大多是对各条信息独立检测,忽视了信息之间的相关性;b)简单的模态融合易丢失图像模态与文本模态之间的交互信息,影响了检测的准确率。
多模态信息的融合处理主要包括模态表示、模态转换、模态对齐与融合等步骤。为了利用在线社交媒体平台中各信息之间丰富的关联来检测虚假信息,本文将社交网络图融入多模态转换、对齐、融合的过程,提出结合社交网络图的多模态虚假信息检测(multimodal misinformation detection model with the social network graph,MMD-SNG)模型。该模型将在线社交媒体平台上的用户与内容连接起来,在信息检测过程中共享各信息中的知识,协助彼此之间的检测;同时通过改进模型损失函数,在模态融合之前进行信息与社交网络图的对齐;最后使用跨模态注意力机制动态分配图像模态、文本模态、图像描述模态、社交网络特征的权重,将结果输入至多层全连接层,进行虚假/非虚假信息分类,生成检测结果。
本文主要贡献如下:
a)将社交网络图结合进虚假信息检测模型中,通过社交网络图连接原本独立进行检测的信息,使各信息之间能够进行知识共享,从而提高虚假信息的检测准确率。
b)将现有图像描述模型和跨模态注意力机制引入虚假信息检测,并改进模型损失函数,对多模态信息进行转换、对齐与融合,提高对信息中各模态相关性的利用率,减少信息冗余,提高检测效率。
1 相关研究
虚假信息(misinformation)是指凭空捏造或被有意扭曲的消息,不能真实反映客观事物的本来面貌。近些年,国内外学者针对虚假信息的各类属性与传播特征,提出了很多虚假信息检测方法,包括制定文本规则、文本可信度评估等文本模态信息检测方法以及融合多模态信息的深度学习方法等。
1.1 单模态虚假信息检测
虚假信息检测方法的早期研究主要基于人工制定的特征规则,从文本内容、用户信息以及传播链的角度检测信息。例如,Castillo等人[6]通过制定规则,对Twitter传播的信息文本和传播用户进行主题发现与可信度评估,以发现社交媒体中的虚假信息。这类方法起到了一定的检测效果,但手工制定规则的成本较高且无法及时适应实时更新的信息检测。
近年来随着计算机算力的不断提升与深度学习技术的日益完善,机器学习和深度学习模型被应用于获取虚假信息检测的有效特征并进行分类[7]。Ma等人[8]基于递归神经网络(recurrent neural network,RNN)学习微博文本的连续表示,通过学习微博帖子的上下文信息以及文本随时间变化的特征来识别虚假信息。Nasir等人[9]提出了一种混合深度学习模型,结合卷积神经网络(convolutional neural network,CNN)和递归神经网络来进行虚假信息分类。Di Sotto等人[10]通过将所提取错误信息的关键特征与深度学习方法进行融合以检测虚假的健康信息。这类方法通过自动提取信息中各模态的特征以检测虚假信息,但因其仅提取单一模态信息而无法提取多模态信息完整语义,所以准确率不够令人满意。
1.2 多模态虚假信息检测
随着在线社交媒体平台信息从基于文本的帖子发展为带有图片或视频的多媒体推文,学者们开始研究包含文本模态和图像模态的多模态虚假信息检测方法。Wang等人[11]提出基于生成对抗网络(generative adversarial networks,GAN)的EANN模型,将多模态数据进行简单融合后输入GAN判别器中判定事件类别,利用学习到的每个事件的共享特征与独有特征强化虚假信息分类器。Khattar等人[12]提出基于双模态变分自编码器和二元神经网络分类器的MVAE模型,通过优化观测数据的边际似然值的边界,来学习概率潜在变量模型。张国标等人[13]通过对图片与文本进行语义一致性计算,构建虚假新闻检测模型。Zhou等人[14]基于多模态特征联合和跨模态相似性来学习社交媒体信息表示的SAFE模型,并通过计算相似度与损失函数相结合来改进分类模型。
在融合图像模态与文本模态进行虚假信息检测的同时,为了提高检测准确率,学者们提出基于社交网络图的虚假信息检测方法。Yang等人[15]提出基于图卷积网络与对抗训练的CGAT模型,通过训练鉴别器以区分在社交媒体中伪装身份的虚假信息发布者。Wei等人[16]提出基于贝叶斯方法的考虑信息传播过程中潜在关系的EBGCN模型,该方法能够自适应地确定传播图中边的权重值以处理传播结构中的不确定性。Zheng等人[17]在社交网络中考虑隐藏链接预测并且通过损失函数对齐来提升模态融合效果。韩雪明等人[18]在传播树结构上利用Transformer架构学习帖子的语义关系,提出了一种基于传播树的节点及路径双注意力虚假信息检测模型DAN-tree,进一步对传播结构上的深层结构和语义信息进行融合。这类虚假信息检测方法多是对文本模态、图片模态与社交网络进行两两组合,尚未充分利用数据中的所有信息。
综上,当前虚假信息检测少有对多个模态信息进行融合、转换、对齐的虚假信息检测研究,尚未充分利用数据语义信息提高检测准确率。因此,在过去研究的基础上,本文结合社交网络图特征,融合文本模态与图像模态以提高虚假信息检测的准确率。
2 多模态虚假信息检测模型MMD-SNG
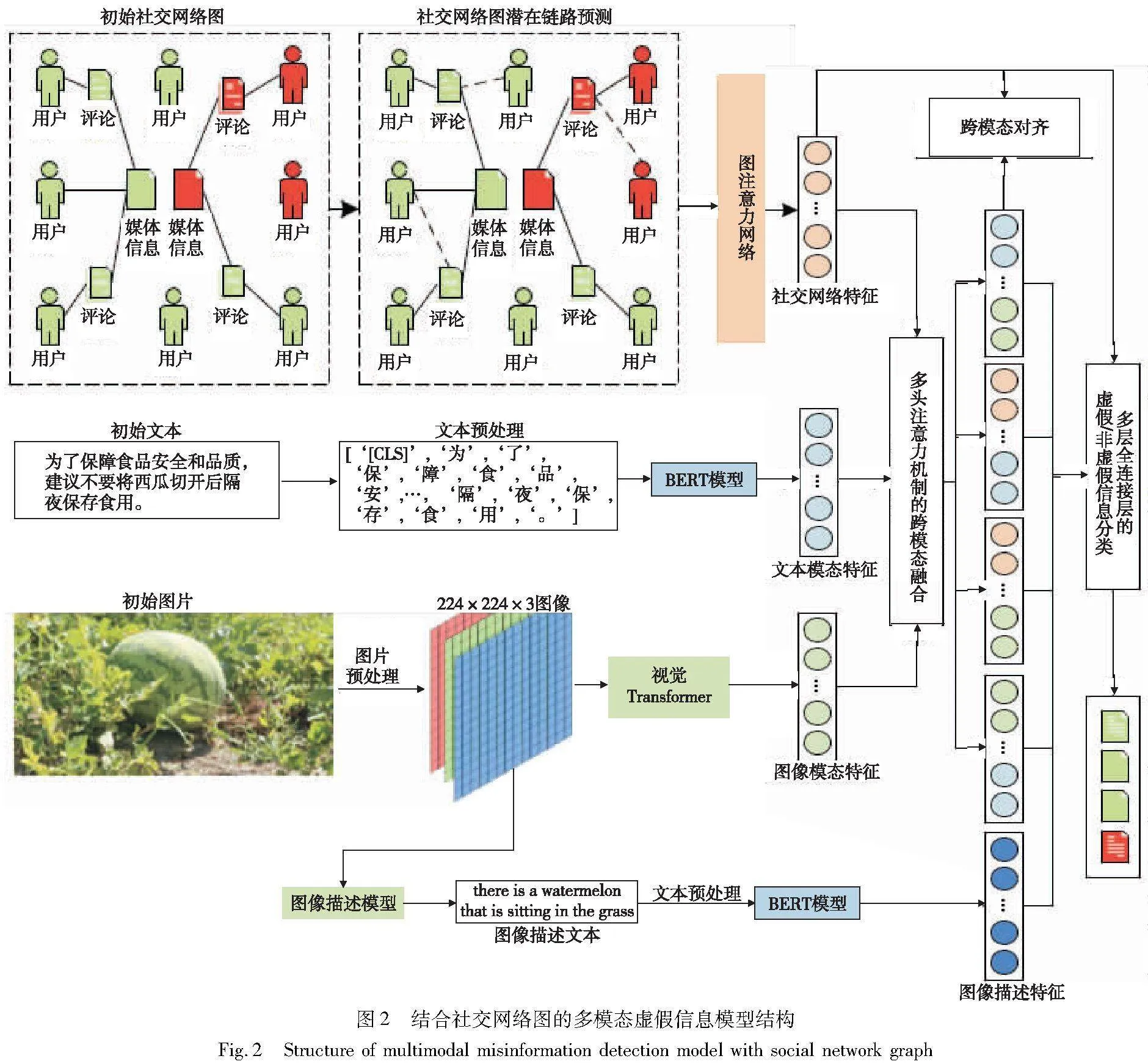
结合社交网络图的多模态虚假信息检测模型(MMD-SNG模型)主要由社交网络图以及多模态表示、转换、对齐、融合模块组成,其结构如图2所示。
MMD-SNG模型将输入待检测的多模态信息转换为集合Info={info1,info2,…,infon}。在其中,每条多模态信息infoi∈Info,infoi={ti,pi,ui,ci},ti表示该信息所包含的文本,pi表示该信息所包含的图片,ui表示在社交平台发布该信息的用户,ci表示该信息所获得的评论集合。一条多模态信息可以包含多条来自不同用户的评论,即ci={c1i,c2i,…,cji}。
根据输入数据集建立初始社交网络图G={N,A},其中N表示社交网络图中的节点,本文将社交平台中的信息、用户、评论作为社交网络图的节点,N的个数表示为k;社交网络图中的邻接矩阵表示为A∈{0,1}k×k,当aij=1时表示节点nodei与nodej之间存在一条无向边。
2.1 社交网络图特征
将社交平台中的信息、用户、评论作为社交网络图的节点。对于信息与评论节点的初始化,选用下文提取其中文本信息的句向量作为节点初始化特征;而对于用户节点,则选用其所发布的所有信息与评论的句向量平均值作为节点初始化特征。为了缓解社交网络图中链接稀疏的问题,本文通过计算节点间的余弦相似度对社交网络图进行潜在链路预测,如式(1)所示。
其中:xi,xj为对应节点nodei、nodej的初始化特征向量;βi,j为两节点的余弦相似度。
本文认为余弦相似度大于一定阈值的节点间可能存在潜在链路,因此在预测后邻接矩阵A′中将余弦相似度大于所设阈值θ的两节点连接设置为1,如式(2)所示。
使用图注意力网络[19]提取社交网络图特征,能够对不同的邻接节点赋予不同的权重,更有利于关键信息的汇聚。对于节点nodei,逐个计算其与邻接节点nodej的注意力权重,如式(3)所示。
ei,j=LeakyReLU(Concat(xiW,xjW)×a)(3)
得到节点nodei与其邻接节点的注意力权重ei,j后,使用softm1514f2a2c35a2d7c1aedde2108066c396fde03bf3bb13b163bc3c5d9b41ee656ax进行注意力权重归一化。在社交媒体中,一条评论可以对一条信息提出同意观点或反对观点,由注意力机制会相应得到正注意力权重与负注意力权重。在softmax函数中,会将负注意力权重值赋予相对较小的注意力分数,导致反对观点所获得的注意力较少[20]。因此,在计算注意力分数的同时,计算取负注意力权重时的注意力分数,得到节点nodei与其邻接节点的正注意力分数αi,j与负注意力分数α′i,j,如式(4)(5)所示。
将正负注意力分数与邻接节点特征进行加权求和后进行拼接,拼接后的向量经过一层全连接层即可得到经过图注意力网络汇聚后的社交网络图特征x′i,如式(6)所示。
2.2 文本模态特征
利用预训练模型提取文本模态特征。此处使用BERT模型[21],该模型利用自注意力机制对文本进行全局上下文理解,能够更好地捕捉文本的语义信息。对于多模态社交媒体信息数据集Info中的文本T={t1,t2,…,tn},首先进行去除停用词与分词等预处理,并在文本前添加标识分类。对于每一条文本ti,利用基于无监督预训练的BERT模型对其进行向量表示,即B={b1,b2,…,bn},如式(7)所示。
其中:L表示句子长度;dw表示词向量维度,本文设置为512;每条bi第一行的词向量bi[CLS]对应该文本的分类标识,将分类标识所对应的词向量作为该文本的句向量。句向量经全连接层降维后作为跨模态注意力中文本模态的输入ft。
2.3 图像模态特征
对于图像模态的表征,CNN使用卷积核来获取图像信息,但不擅长融合其他模态的信息,而Transformer的输入不需要保持二维图像,通常可以直接对像素进行操作得到初始嵌入向量,更适合多模态信息融合,因此本文使用Transformer提取多模态社交媒体信息中的图像模态特征。此处使用CLIP模型[22]中预训练的ViT[23]模型。
对于多模态社交媒体信息数据集中的图像P={p1,p2,…,pn},首先进行图像变换与图像切块等预处理,并添加标识分类以及每个图像块的位置编码。对于每一张图片pi,利用基于对比学习预训练的ViT模型抽取其特征,即V={v1,v2,…,vn},如式(8)所示。
其中:每条vi第一行的向量vi[CLS]对应该图片的分类标识。本文将分类标识所对应的向量作为该图片的全局特征向量,经全连接层降维后作为跨模态注意力中图像模态的输入fp。
2.4 多头注意力机制的跨模态融合
在已有多模态虚假信息检测研究中,多采用直接相加融合或点乘融合,在模态融合时未进行权重动态分配,无法对各模态之间相关联语义进行针对性融合。为此,本文引入多头跨模态注意力机制,以使模型更好地捕捉不同模态之间的关联性,在更好地学习不同模态之间共性的同时减少信息冗余。多头注意力机制的跨模态融合计算方法如式(9)~(11)所示。
如图2所示,分别将所获取的文本模态特征ft、图像模态特征fp、社交网络图特征fs作为注意力机制中的Q、K、V,从而获得文本-图像融合特征ftp、图像-文本融合特征fpt、社交网络图-文本融合特征fst、社交网络图-图像融合特征fsp。
通常从社交媒体上获取的图像-文本对是弱相关的,即文本包含与图像无关的文字或图像包含文本中没有描述的实体[25]。因此跨模态注意力机制对于图像模态和文本模态映射仍停留在其各自的空间,难以学习到跨模态信息之间的交互。为了改善在噪声数据中的学习问题,引入均方差损失Euclid Math OneLApalign,以对齐社交网络图、图像模态、文本模态三者之间的信息,如式(12)所示。
2.5 虚假信息检测分类
通过前述的多模态特征提取和跨模态对齐,获得输入多层全连接层的所有输入,且所有特征均通过全连接层降至同一维度。将这些特征向量拼接后输入多层全连接层,得到最终虚假信息检测分类结果,如式(13)(14)所示。
3 实验及结果分析
3.1 实验数据
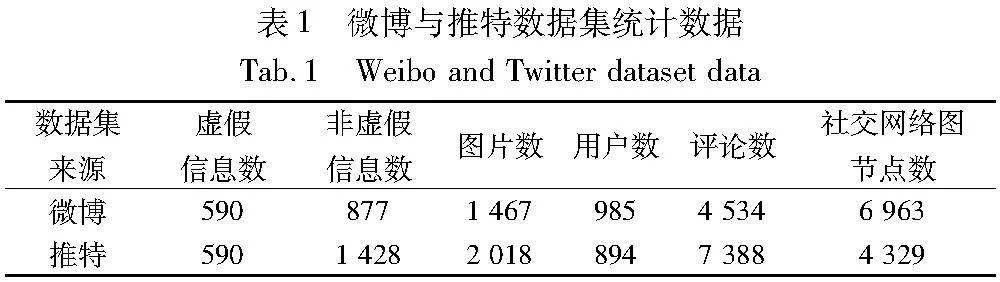
采用微博[26]与推特[27]两个真实社交媒体虚假信息检测数据集进行实验,分析本文方法的性能。微博与推特均为目前主流的社交媒体平台,其数据具有代表性。两个数据集均包含文本、图像、评论以及标注。其中,微博数据集中的文本内容为中文,推特数据集中的文本内容为英文。
为了对比分析多模态虚假信息检测方法,在数据集的预处理阶段,本文专注于检测具有多模态特征的虚假信息,因此删除了数据集中仅含文本或图片的数据以及重复数据,同时为了保证数据质量,删除了经word piece分词后token序列长度小于5的数据或图片单边分辨率低于112的数据。设置句子token序列长度为80,对于超长的句子,截去超出部分;对于长度不足80的句子则用标识符补齐。同时,将图片大小调整为224×224×3,以方便模型输入。经过预处理后的数据集如表1所示。
3.2 实验设置及评价指标
本文实验均基于单张NVIDIA RTX3090 24 GB GPU训练,使用的CUDA版本为11.3。本文通过基于Python的深度学习框架PyTorch实现MMD-SNG模型,所使用的预训练模型权重来自HuggingFace,将预处理完的数据输入进模型进行训练。
将数据集按7∶1∶2随机划分训练集、验证集与测试集,所有实验均在相同的训练集、测试集上完成。在训练过程中,本文使用AdamW作为目标函数的优化器,学习率设置为0.001,权重衰减系数设置为0.01,全连接层激活函数为GELU,训练批次大小设置为96,训练轮数设置为80。本文在训练中采用早停策略,如损失函数在10轮训练中未下降则停止训练。
由于本文选用数据集中的两类数据数量不同,所以本文选用准确率(accuracy)、加权平均精确率(weighed-precision)、加权平均召回率(weighed-recall)、加权平均F1分数(weighed-F1-score)作为评价指标,上述评价指标在后续表中分别简称为A、P、R、F1。
3.3 基线模型
本文选择了几种在公开数据集中表现出优异性能的虚假信息检测模型,将其与本文模型作对比,具体如下:
a)EANN(event adversarial neural network)[11]:该模型采用Text-CNN模型提取文本模态特征,采用VGG-19模型提取图像模态特征,两者通过连接融合后进行虚假信息检测。该模型提出采用生成对抗网络学习各事件的独立性,有利于模型学习各事件的独立特征。b)GLAN(global-local attention network)[28]:该模型基于社交网络图,将相关转发的语义信息与注意力机制进行融合,为每条信息生成包含社交语义的局部特征表示,同时构建一个全局异质图捕获丰富的结构信息用于虚假信息检测。
c)SAFE(similarity-aware fake news detection)[14]:该模型通过引入一个额外的全连接层的扩展Text-CNN来提取文本模态特征与图像特征,并在损失函数中引入文本模态与图像模态的微调余弦相似性以进行虚假信息检测。
d)EBGCN(edge-enhanced Bayesian graph convolutional network)[16]:该模型采用贝叶斯方法,自适应地重新考虑了社交网络图中的潜在关系,结合了文本嵌入层与图卷积神经网络共同提取社交网络图特征,然后通过节点更新模块与边推理模块捕获图结构特征,将两者拼接以进行虚假信息检测。
e)PTCA(pre-trained Transformer and cross attention)[29]:该模型采用预训练的Transformer分别提取文本和图像特征,同时使用Text-CNN多角度提取语义特征,通过交叉注意力机制获取两个模态的融合特征后进行虚假信息检测。
其中EANN、SAFE、PTCA同时提取了文本模态与图像模态特征进行虚假信息检测,GLAN、EBGCN在提取社交媒体信息文本模态特征的基础上融合了社交网络图进行虚假信息检测。
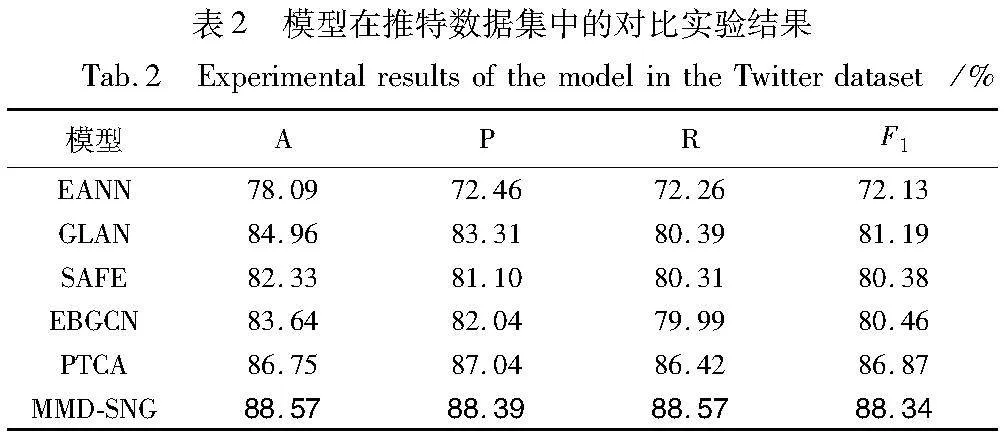
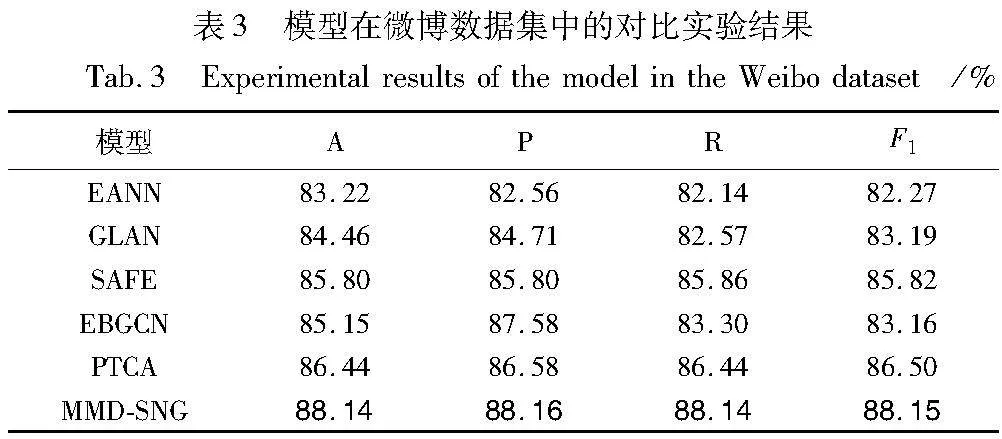
3.4 对比实验本文提出的结合社交网络图的多模态虚假信息检测模型MMD-SNG与其他模型在推特数据集上的实验对比结果如表2所示,在微博数据集上的实验对比结果如表3所示,粗体表示在该指标下取得的最优结果。
由表2和3所示,MMD-SNG模型在两个真实虚假信息检测数据集中评价指标上优于当前先进的基线模型,相关结果分析如下:
a)在与EANN模型的对比中,MMD-SNG在两个数据集的检测准确率平均高出了7.1%。EANN在融合阶段仅采用了高维的拼接融合,表明MMD-SNG中采用跨模态注意力融合机制能够有效减少模态融合过程中各个模态所包含的噪声信息,动态计算的注意力分数能够将权重赋予各模态中的有效信息,从而提高模态融合效率。
b)GLAN将原信息、转发信息与用户信息之间的结构关系建模为社交网络异质图,但在建模过程中只考虑社交媒体中的文本模态信息,忽略了图像模态信息,在与GLAN模型的对比中,表明图像模态的加入有助于丰富社交媒体信息的特征表示,多模态融合后的特征具有更加丰富的语义信息,能够增强虚假信息检测效果。
c)SAFE在文本与图像模态融合阶段,通过计算相似度的方式将两种模态间的特征进行融合,其实验结果表明在模态融合阶段考虑各模态间的相似度以对齐模态,有助于提高模态融合性能。
d)与GLAN相似,EBGCN采用贝叶斯方法,在社交网络图中考虑了节点间的潜在关系可靠性,但同样仅抽取文本模态特征,表明了在虚假信息检测中考虑社交网络图的潜在链路预测能够提升检测性能。
e)PTCA使用了两个经预训练的Transformer模型(BERT和ViT)分别提取文本和图像特征,一定程度上克服了样本数量不足的局限性,该模型还采用Text-CNN模型多角度提取文本语义信息,最后通过交叉注意力机制进行特征融合。同时,由于基于Transformer模型中的自注意力机制带来了二次方计算复杂度,与本文相同,模型在表现出优异性能的同时,其计算时间与算力消耗方面与上述模型相比较大。
3.5 交叉验证实验
为避免偶然性,更全面评估模型表现,本节将两个数据集中虚假信息与非虚假信息两类数据平均分成五份进行分层五折交叉验证。交叉验证实验其余设置与对比实验相同,五次实验结果取平均值,结果如表4所示。
由表4可以看出,MMD-SNG模型在两个真实数据集上的交叉验证实验表现与对比实验中的结果相近,证明了该模型的可靠性。
3.6 消融实验
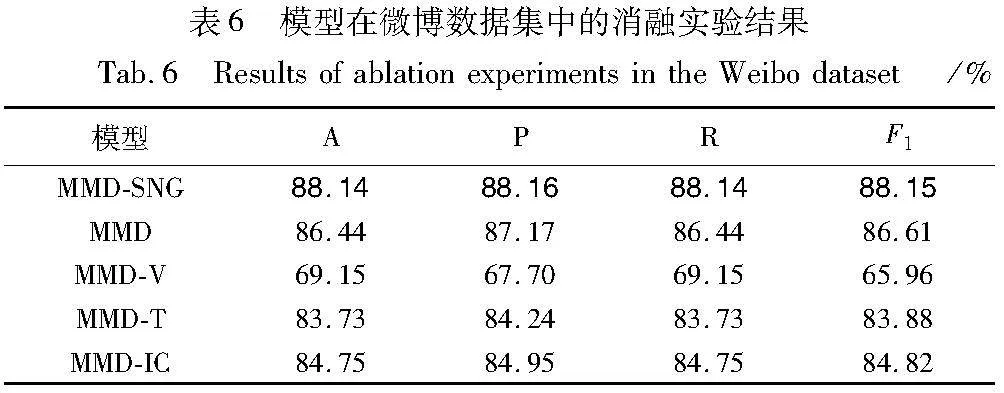
为验证本文模型中各部分模块功能,通过对本文模型去除对应模块进行消融实验。在两个数据集上的消融实验结果如表5和6所示,粗体表示在该指标下取得的最优结果。MMD-SNG为本文模型,MMD表示在本文模型的基础上去除社交网络特征与模态对齐,MMD-V表示在本文模型的基础上去除视觉模态特征、图像描述特征与模态对齐,MMD-T表示在本文模型的基础上去除文本模态特征与模态对齐,MMD-IC表示在本文模型的基础上去除图像描述特征。
由表5、6数据,对消融实验结果分析如下:
a)与去除了社交网络图的MMD相比,MMD-SNG中社交网络图特征的加入将各条独立的信息通过图结构连接起来,使得在模型检测时能够同时考虑多条信息语义,能够提高多模态虚假信息检测模型性能。
b)MMD-IC的性能下降表明,图像描述模态的加入对原有信息作了数据增强,能够利用信息中的全部语义,以提升模型各项性能。
c)MMD-V与MMD-T的性能结果表明,多模态虚假信息检测相比于单一模态检测,能够从多角度提取信息特征,使检测性能得到显著提高;且在不同数据集中,文本模态与图片模态所表现出的信息量不同,同时利用多种模态数据能够有效提升虚假信息检测模型的鲁棒性。
3.7 参数敏感性实验
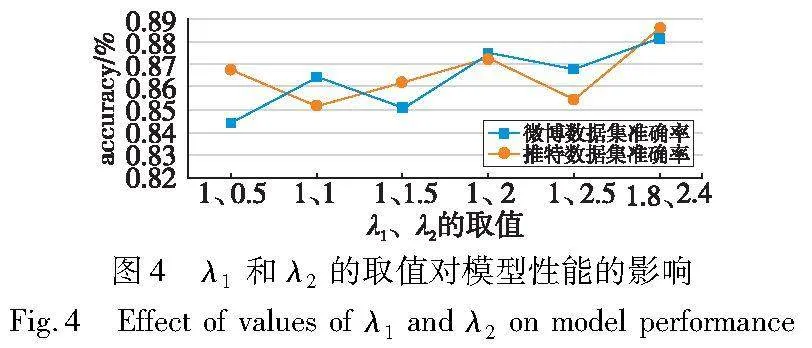
在本文2.1节潜在链路预测式(2)与2.5节的模型损失函数式(16)中,潜在链路预测阈值θ与分类损失函数与对齐损失函数前的系数λ1和λ2是本文模型中的重要超参数,因此,本节对不同参数的取值导致模型性能的影响进行评估。
参数敏感性实验结果分别如图3和4所示。从图3中可以看出,当其他参数固定时,改变θ的值能对模型在不同数据集上的性能均产生较大影响,当节点相似度阈值设为0.5时进行潜在链路预测,能够使模型性能取得最优。
从图4可以看出,当固定θ为0.5时,在一定范围内,模型性能总体趋势为随着λ1和λ2的增加而增加,说明模态对齐能够使得模态间数据具有一致性,对齐损失函数与分类损失函数的结合能够有效提升模型性能。经多次实验结果表明,当λ1的取值为1.8,λ2的取值为2.4时,模型的性能取得最优。
3.8 样例分析
为了更加直观证明本文模型的有效性,将本文模型的结果与现有基线模型进行比较,结果如图5所示。图5为在两个数据集中被MMD-SNG正确检测的社交媒体信息,其中绿框中的为真实信息,红框中的为虚假信息。从图5中可以看出,多模态虚假信息主要涉及图像窜改、夸大文本内容、图像与文本描述不符等情况。图5(a)(b)为常识类与谚语类文本信息,比较模型(如EANN、GLAN)对其进行了错误分类,本文模型由于采用经过预训练的语言模型提取文本特征,能够正确检测该类信息。图5(c)为图片信息中含有地图的信息,比较模型(如EANN、PTCA)对其进行了错误分类,本文模型由于具有图像描述模块,对于识别图片中的文字以及地图类图片时,能够准确识别到图片中的文字信息并提高检测正确率。
图5(d)中所示的图片与现实具有差距,可能是一张伪造的图片、图5(e)中文字与图片相比具有夸大成分、而图5(f)中则是图片内容与文本不符。以上三个例子均具有上述虚假信息主要特征,本文模型均正确将其检测为虚假信息,而比较模型(如PTCA、EBGCN等)将其分类为非虚假信息。上述结果表明,本文模型能够有效地提取多模态社交媒体信息中的文本信息和图像信息,与社交网络图的结合以及利用图像描述进行数据增强能够更全面地检测社交媒体信息的真实性,证明其在多模态虚假信息检测任务中的有效性。
4 结束语
针对当前在线社交媒体平台虚假信息检测方法中存在的忽略信息间相关性和多模态融合不充分问题,本文提出结合社交网络图的多模态虚假信息检测模型。该模型采用社交网络图连接通常独立进行检测的信息,将图信息以节点特征的形式融合进虚假信息检测模型;同时,提出基于图像描述模型的多模态数据增强方法,将经过模态转换后的图像描述文本融合进最终的决策模型中;最后,经过模态对齐与跨模态注意力机制,将社交网络特征、文本模态特征、图像模态特征、图像描述特征进行融合以作虚假信息检测。在推特和微博上的实验结果表明,其相比已有模型取得了更好的准确率。
本研究的不足之处在于,构建社交网络图时仅考虑了文本模态信息,无法全面捕获多媒体信息中的关联性;并且,本文所使用的图像描述模型仅可产生英文文本描述,在中文数据集上会与现有的中文文本模态产生特征间隔,从而造成信息冗余。未来研究可在MMD-SNG模型的基础上,完善社交网络图的构建以及探索使用中文图像描述模型,进一步优化多模态虚假信息检测模型的计算效果。
参考文献:
[1]中国互联网网络信息中心. 第51次中国互联网络发展状况统计报告 [R/OL]. (2023-03-02) [2023-05-31]. https://www. cnnic. net. cn/n4/2023/0303/c88-10757. html. (China Internet Network Information Center. The 51st statistical report on the development of China’s Internet [R/OL]. (2023-03-02) [2023-05-31]. https://www. cnnic. net. cn/n4/2023/0303/c88-10757. html.)
[2]王晰巍, 邱程程, 李玥琪. 突发公共事件下社交网络谣言辟谣效果评价及实证研究[J]. 情报理论与实践, 2022, 45(12): 14-21. (Wang Xiwei, Qiu Chengcheng, Li Yueqi. Evaluation and empirical research on the effect of social network rumors refutation under public emergencies[J]. Information Studies: Theory & Application, 2022, 45(12): 14-21.)
[3]Bengio Y, Courville A, Vincent P. Representation learning: a review and new perspectives[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013,35(8): 1798-1828.
[4]Baltruaitis T, Ahuja C, Morency L P. Multimodal machine learning: a survey and taxonomy[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2018,41(2): 423-443.
[5]Guo Haoming, Huang Tianyi, Huang Huixuan, et al. A systematic review of multimodal approaches to online misinformation detection[C]//Proc of the 5th IEEE International Conference on Multimedia Information Processing and Retrieval. Piscataway, NJ: IEEE Press, 2022: 312-317.
[6]Castillo C, Mendoza M, Poblete B. Information credibility on Twitter[C]//Proc of the 20th International Conference on World Wide Web. New York: ACM Press, 2011: 675-684.
[7]Mishra S, Shukla P, Agarwal R. Analyzing machine learning enabled fake news detection techniques for diversified datasets[J]. Wireless Communications and Mobile Computing, 2022,2022(1): article ID 1575365.
[8]Ma Jing, Gao Wei, Mitra P, et al. Detecting rumors from microblogs with recurrent neural networks[C]//Proc of the 25th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 3818-3824.
[9]Nasir J A, Khan O S, Varlamis I. Fake news detection: a hybrid CNN-RNN based deep learning approach[J]. International Journal of Information Management Data Insights, 2021,1(1): 100007.
[10]Di Sotto S, Viviani M. Health misinformation detection in the social web: an overview and a data science approach[J]. International Journal of Environmental Research and Public Health, 2022,19(4): 2173.
[11]Wang Yaqing, Ma Fenglong, Jin Zhiwei, et al. EANN: event adversarial neural networks for multi-modal fake news detection[C]//Proc of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM Press, 2018: 849-857.
[12]Khattar D, Goud J S, Gupta M, et al. MVAE: multimodal variatio-nal autoencoder for fake news detection[C]//Proc of World Wide Web Conference. New York: ACM Press, 2019: 2915-2921.
[13]张国标, 李洁. 融合多模态内容语义一致性的社交媒体虚假新闻检测[J]. 数据分析与知识发现, 2021, 5(5): 21-29. (Zhang Guobiao, Li Jie. Detecting social media fake news with semantic consistency between multi-model contents[J]. Data Analysis and Knowledge Discovery, 2021, 5(5): 21-29.)
[14]Zhou Xinyi, Wu Jindi, Zafarani R. Safe: similarity-aware multi-modal fake news detection[C]//Proc of Pacific-Asia Conference on Know-ledge Discovery and Data Mining. Cham: Springer, 2020: 354-367.
[15]Yang Xiaoyu, Lyu Yuefei, Tian Tian, et al. Rumor detection on social media with graph structured adversarial learning[C]//Proc of the 29th International Conference on International Joint Conferences on Artificial Intelligence. 2021: 1417-1423.
[16]Wei Lingwei, Hu Dou, Zhou Wei, et al. Towards propagation uncertainty: edge-enhanced Bayesian graph convolutional networks for rumor detection[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL Press, 2021: 3845-3854.
[17]Zheng Jiaqi, Zhang Xi, Guo Sanchuan, et al. MFAN: multi-modal feature enhanced attention networks for rumor detection[C]//Proc of the 31st International Joint Conference on Artificial Intelligence. 2022: 2413-2419.
[18]韩雪明,贾彩燕,李轩涯,等. 传播树结构节点及路径双注意力谣言检测模型[J]. 计算机科学, 2023, 50(4): 22-31. (Han Xueming, Jia Caiyan, Li Xuanya, et al. Dual-attention network model on propagation tree structures for rumor detection[J]. Computer Science, 2023,50(4): 22-31.)
[19]Velicˇkovic' P, Cucurull G, Casanova A, et al. Graph attention networks[EB/OL]. (2018-02-04)[2023-05-31]. https://arxiv. org/pdf/1710.10903.pdf.
[20]Tian Tian, Liu Yudong, Yang Xiaoyu, et al. QSAN: a quantum-probability based signed attention network for explainable false information detection[C]//Proc of the 29th ACM International Conference on Information & Knowledge Management. New York: ACM Press, 2020: 1445-1454.
[21]Devlin J, Chang Mingwei, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24)[2023-05-31]. https://arxiv.org/pdf/1810.04805.pdf.
[22]Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//Proc of International Conference on Machine Learning. 2021: 8748-8763.
[23]Dosovitskiy A,Beyer L,Kolesnikov A,et al. An image is worth 16×16 words: transformers for image recognition at scale[EB/OL]. (2021-6-3)[2023-05-31]. https://arxiv.org/pdf/2010.11929.pdf.
[24]Li Junnan, Li Dongxu, Xiong Caiming, et al. Blip: bootstrapping language-image pre-training for unified vision-language understanding and generation[C]//Proc of the 39th International Conference on Machine Learning. 2022: 12888-12900.
[25]Li Junnan, Selvaraju R, Gotmare A, et al. Align before fuse: vision and language representation learning with momentum distillation[J]. Advances in Neural Information Processing Systems, 2021,34: 9694-9705.
[26]Song Changhe, Yang Cheng, Chen Huimin, et al. CED: credible early detection of social media rumors[J]. IEEE Trans on Know-ledge and Data Engineering, 2019, 33(8): 3035-3047.
[27]Zubiaga A, Liakata M, Procter R. Exploiting context for rumour detection in social media[C]//Proc of International Conference on Social Informatics. Cham: Springer, 2017: 109-123.
[28]Yuan Chunyuan, Ma Qianwen, Zhou Wei, et al. Jointly embedding the local and global relations of heterogeneous graph for rumor detection[C]//Proc of IEEE International Conference on Data Mining. Piscataway, NJ: IEEE Press, 2019: 796-805.
[29]蒋保洋, 但志平, 董方敏,等. 基于双预训练Transformer和交叉注意力的多模态谣言检测[J]. 国外电子测量技术, 2023, 42(4): 149-157. (Jiang Baoyang, Dan Zhiping, Dong Fangmin, et al. Multimodal rumor detection method based on dual pre-trained Transformer and cross attention mechanism[J]. Foreign Electronic Measurement Technology, 2023, 42(4): 149-157.)
