
基于GA-TD3算法的交叉路口决策模型
2024-08-17 00:00:00江安旎杜煜原颖张昊赵世昕
计算机应用研究 2024年7期
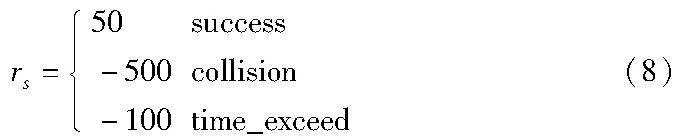

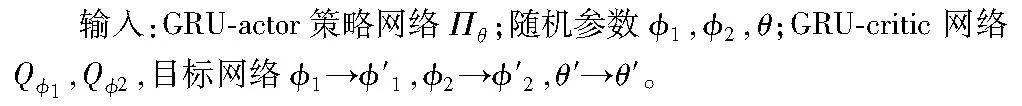


摘 要:为了解决交叉路口场景下无人驾驶决策模型成功率低、模型不稳定、车辆通行效率低的问题,从两个方面对TD3算法作出改进,提出了基于GA-TD3算法的交叉路口决策模型。首先引入记忆模块,使用GRU神经网络来提升决策模型的成功率;其次在状态空间引入社会注意力机制,更加关注与社会车辆的交互行为,保证模型稳定性的同时提升车辆的通行效率。采用CARLA仿真器进行20 000回合的模型训练后,TD3算法通过路口的成功率为92.4%,GA-TD3算法的成功率为97.6%,且车辆的通行时间缩短了3.36 s。GA-TD3算法模型在学习效率和通行效率上均有所提升,可用于缓解城市中的交通压力,提高驾驶效率。
关键词:深度强化学习; 无人驾驶决策; 交叉路口; 循环神经网络; 注意力机制
中图分类号:TP399 文献标志码:A 文章编号:1001-3695(2024)07-006-1965-06
doi:10.19734/j.issn.1001-3695.2023.10.0570
Intersection decision model based on GA-TD3 algorithm
Abstract:Addressing problems such as low success rates, instability, and inefficient traffic flow in autonomous decision-making models at intersections, this paper proposed an intersection decision model based on the GA-TD3(GRU attention twin delayed deep deterministic policy gradient)algorithm by improving TD3 algorithm from two aspects. Firstly,it introduced a memory module which using GRU neural network to improve the success rate of the decision model. Secondly, it introduced a social attention mechanism in the state space to focus on interactions with social vehicles,which ensured the stability of the model while improving the traffic efficiency of vehicles. After 20 000 rounds of training in the CARLA simulator, the TD3 algorithm achieves a success rate of 92.4%, while the success rate of the GA-TD3 algorithm is 97.6%. Additionally, the vehicle’s travel time is shortened by 3.36 s. GA-TD3 algorithm improves both learning efficiency and traffic efficiency, which can alleviate traffic pressure in urban scenes and improve driving efficiency.
Key words:deep reinforcement learning; autonomous driving decision; intersection scenario; recurrent neural network; attention mechanism
0 引言
在城市道路场景中,交叉路口场景的随机性较高,复杂度高于其他道路场景,因此交叉路口的事故发生率远高于其他场景,从而引发交通拥堵,路口通行效率也受到了极大的影响。无人驾驶技术的引入在一定程度上可以缓解交通拥堵,但想要实现高级别的无人驾驶,对交叉路口等复杂场景的研究是十分重要的。
无人驾驶传统决策模型大致分为基于规则的决策模型[1~3]、基于博弈论的决策模型[4]、基于启发式探索的决策模型[5]以及基于协同合作的方法[6,7]。传统的无人驾驶决策方法更多应用在简单场景中,无法与环境进行实时交互,在随机性强的场景中处理能力较差。
强化学习算法则弥补了缺陷,可以根据环境的反馈来学习并调整相应的决策策略,具有较强的自适应能力,例如Q-learning[8]、sarsa[9]。传统强化学习决策模型只能解决少量离散的动作值,因此得到的决策模型根据简单的状态空间给出的决策动作较为粗糙。
深度学习在处理大批量的数据方面具有较高的准确性,因此与强化学习结合得到的深度强化学习算法在处理连续高维的环境状态空间具有较好的表现能力,在连续控制任务[10]、棋盘游戏[11]以及实施策略游戏[12]上达到了超人级别的性能。此外无人驾驶领域也有着较为不错的成果[13~15],深度强化学习模型在匝道汇入[16]换道场景[17]都有着一定的研究,采用深度强化学习的方法解决交叉路口问题也是现阶段研究的热点之一[18~20]。文献[21]采用一种基于DDPG(deep deterministic policy gradien)算法的匝道汇入车流决策模型,将汇入车流问题转换为序列决策问题的方式进行求解。针对文献[21]实验模型不具备记忆功能的问题,吴思凡等人[22]提出基于LSTM-A3C(long short-term memory-asynchronous advantage actor-critic)算法的智能车汇入模型。实验结果表明结合长短期记忆神经网络可有效地解决模型训练时间长和模型收敛慢的问题,但DDPG算法本身存在局部最优、Q估计错误等问题,导致模型成功率低。双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient,TD3)算法改善了DDPG的问题[23]。文献[24]对TD3算法中的actor网络进行改进,为目标动作添加OU(Ornstein-Uhlenbeck) 噪声,对改进后的TD3算法进行无人驾驶车辆在无信号交叉口下的右转驾驶决策研究,发现其不仅能够探索更多可能,而且通行决策表现更加突出。由于驾驶环境的不确定性,导致大多数基于规则的模型决策精度差,文献[25]改进了TD3算法的结构,使用长短期记忆(LSTM)来选择基于时间信息的动作,该算法在SUMO仿真模拟器进行验证,在不确定交通场景下具有较好的泛化效果。
由于十字交叉路口场景的动态性和未知性较大,导致决策模型收敛速度慢、成功率低、训练过程模型波动较大以及交通效率低等问题,提出基于GA-TD3(GRU attention-twin delayed deep deterministic policy gradient)无人驾驶决策模型。该模型是在TD3算法的基础上,加入GRU(gate recurrent unit)神经网络,通过优化网络结构来提升决策模型的成功率;引入社会注意力机制,更加关注与社会车辆的交互行为来提升无人驾驶车辆通行效率。基于CARLA仿真平台,本文算法分别与主流的深度强化学习算法TD3、SAC(soft actor critic)算法进行实验对比,实验结果表明改进后的模型达到了预期效果。
1 基于GA-TD3算法的决策模型
本文提出的交叉路口决策模型采用TD3算法模型作为基准进行改进。TD3是由DDPG算法改进而来,引入双层critic网络解决DPPG算法Q值高估的问题,actor网络延迟更新,以及增加动作噪声提升算法的性能。此外,DDPG和TD3主要用于处理连续的状态空间和动作空间,在无人驾驶决策领域有着不错的表现。
由于无人驾驶车辆的动作是连续的,为了保证动作的连贯性,在动作探索的过程中采用OU噪声取代了高斯噪声,以此提高模型的准确率[24]。此外还有学者通过修改经验回放池,对过往经验进行合理采样,以提升模型的成功概率。但针对动态变化的场景,以上改进依旧存在学习效率低、模型不稳定的问题。
面对交叉路口场景,agent车辆在训练过程中普遍存在对前后状态信息关联性较少的问题,同样TD3模型也会因场景中的车辆布局动态变化导致模型的成功率降低,车辆通行路口的效率也随之降低。无人驾驶场景的状态空间和动作空间以连续数据为主,在处理大量具有序列特征的数据,RNN(recurrent neural network)神经网络能够很好地挖掘到数据中的时态及语义,在无人驾驶场景中可以较好地处理状态空间中的有序数据并获取有意义的状态关系[26]。但RNN不具备长期记忆信息能力,在模型训练过程中容易产生梯度消失的问题。LSTM具有长期记忆的功能,可以有效解决RNN面临的梯度问题,该神经网络在记忆有意义信息的同时也会忘记无意义的信息。文献[25]同样采用LSTM与TD3算法进行结合,使用长短期记忆来选择基于时间信息的动作,使agent车辆的动作更可靠,从而提升模型的成功率。将LSTM与TD3模型结合在一定程度上增加了模型的维度,在处理前期较为简单的场景会增加动作选择的范围,导致模型的在前期训练出现不稳定、收敛慢的问题。
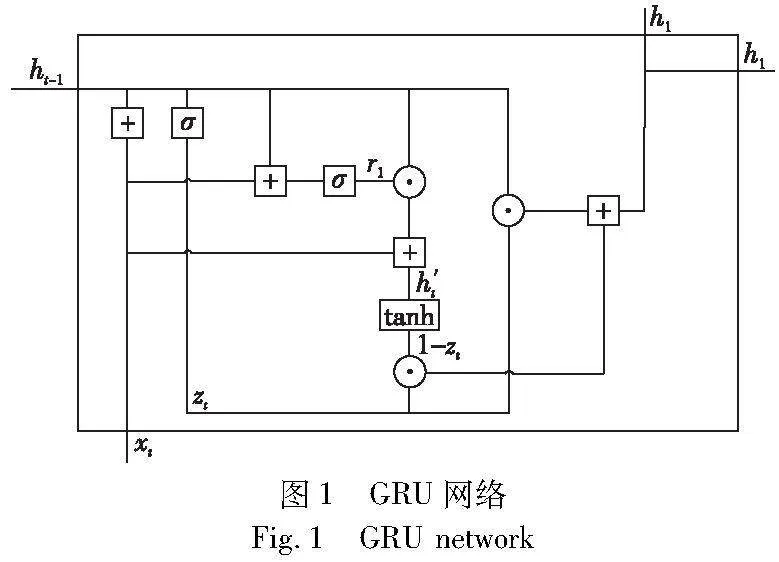
GRU是LSTM的变体,如图1所示,其框架结构更加简洁,仅由两个门构成(update门和reset门),因此可以直接将隐藏状态传递给下一个单元,参数也相对更少,面对一般规模的数据集,GRU比LSTM更容易训练,模型的收敛速度更快,却具有相近的性能[27]。
GRU有update门和reset门两个重要的门,分别如式(1)(2)所示。
zt=σ(Wz·[ht-1,xt])(1)
rt=σ(Wr·[ht-1,xt])(2)
其中:xt为第t个时步的输入向量;经过线性变换后,ht-1表示上一时步的信息并再次进行线性变换。
reset门与update门同理,新的记忆信息将通过reset门存储的过去信息进行计算,公式为
h′t=tanh(W·[rtht-1,xt])(3)
update门用来决定当前记忆内容h′t与ht-1中需要存储哪些信息,ht用来存储当前单元的信息并传递到下一个单元中。具体公式为
ht=(1-zt)*h(t-1)+zt*h′t(4)
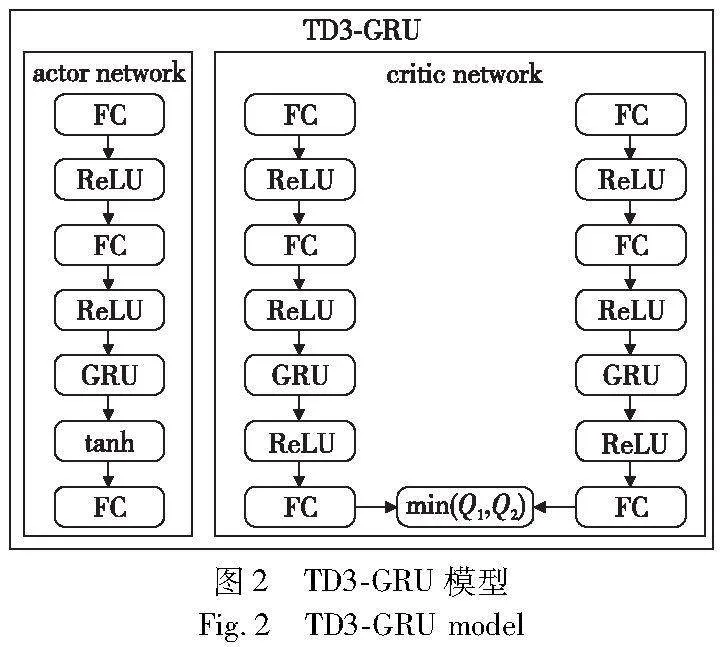
门控循环单元会记忆每一个循环过程中有用的信息并传递到下一个循环单元,保留有意义的历史信息,将GRU神经网络与TD3的actor-critic网络相结合,为TD3算法模型提供记忆功能详细结构,如图2所示。actor-critic网络均采用全连接网络结构,状态数据处理过程融入GRU网络,通过GRU网络保留上一时刻有意义的历史状态信息与当前输入的状态进行计算,保留有需要记忆的状态ht传递给actor-critic网络最后一层进行处理,actor-critic网络中对状态数据处理建立连接,以此改善了深度强化学习模型在面对复杂场景收敛速度慢、成功率低的问题。
深度强化学习算法的网络结构是由各个全连接层组合而成,获取到的状态信息输入模型中,并依次输入到各全连接层进行处理,全连接层将处理后的结果输入到下一层,最终得到相关的策略。这些策略在训练过程中较容易得到,但难以给出做出当前动作的理由。如何让决策变得更加合理成为了学术界的一大难题。对于无人驾驶决策动作而言,agent车辆能够集中关注到交汇过程中有价值的信息是十分重要的[28,29]。
注意力机制被广泛运用于深度学习模型的多个领域,比如图像检测、语音识别、以及自然语言处理等。近年来,注意力机制开始与深度强化学习相结合,主要应用于深度强化学习决策序列等方向,无人驾驶车辆可以根据输入的状态序列找到需要关注且有价值的状态。
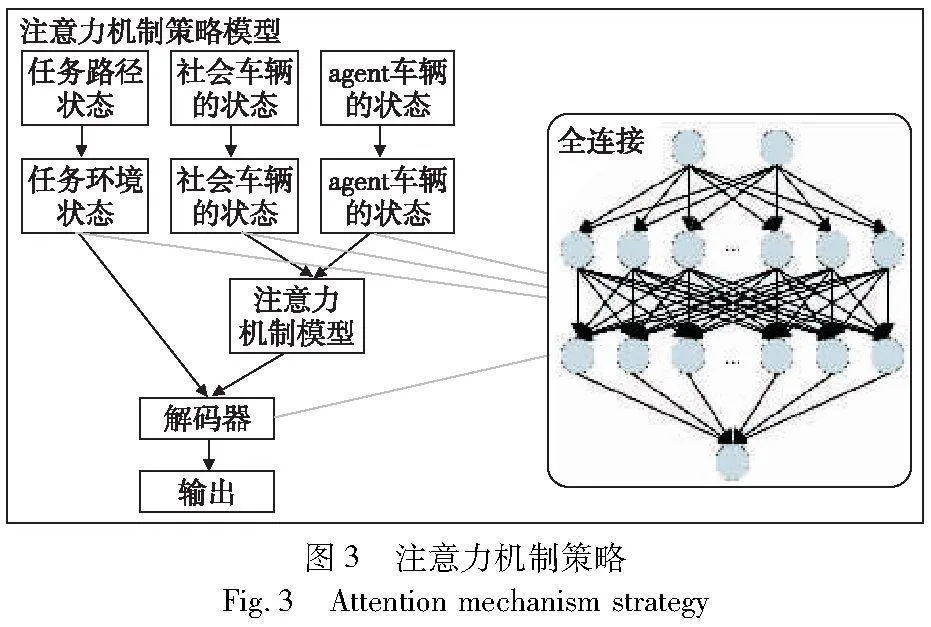
采用这种技术的主要目的是使深度强化学习模型自动捕获自我车辆和社会车辆之间的依赖关系,以获取更好的性能并具备较好的可解释性。如图3所示,将注意力机制应用于actor网络,模型中的编码器和解码器由全连接层组成,由此构成注意力机制策略结构。产生注意力张量的过程可以描述如下:首先,需要将所有车辆的状态表示分解为自我车辆状态和社会车辆状态两个部分,分别对它们各自的状态进行编码,给出所有车的嵌入结果,然后将嵌入结果传递给深度强化学习网络进行学习。注意力机制聚焦状态信息之间的依赖关系,使自我车辆在动作选择上也更加准确,保证模型的稳定性。
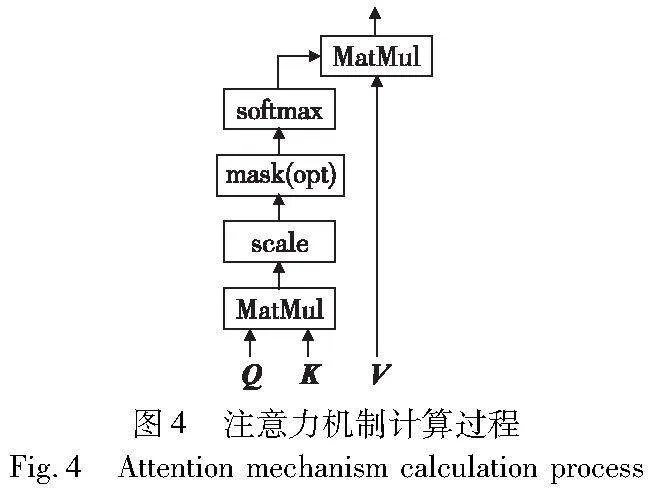
GA-TD3模型中的注意力机制的查询向量定义为QA=[qe],代表计算当前agent车辆与其他需要集中关注的社会车辆状态的关系度和关联性。键向量定义为K=[ke,k1,…,kn],主要与查询向量搭配使用,代表社会车辆和agent车辆之间产生交互的状态关键信息。值向量定义为V=[ve,v1,…,vn],代表当前状态空间对agent车辆交互过程中动作选择的重要状态信息,也代表着状态空间需要集中关注的重要信息。深度强化学习模型根据获取到的注意力信息进行策略选择,增加了策略选择的可解释性。计算过程如图4所示。
1.1 状态空间
状态空间是无人驾驶车辆从环境中获取的所有车辆的状态数据,这些数据反映了当前环境下车辆作出决策后所发生的一些情况。在复杂场景下无人驾驶车辆的状态空间主要包括自我车辆的速度ve、位置pe,以及自我车辆与交互的社会车辆的相对速度vrel,相对位置prel和相对航向角rrel。因此,状态空间定义为
st=(ve,pe,vrel,prel,rrel)(6)
1.2 动作空间
在深度强化学习决策模型中,无人驾驶车辆的动作空间包含自我车辆要执行的动作指令。在实验环境中自我车辆在通过十字路口时的动作分为加速动作和减速动作,因此动作空间离散为加速Aup、减速Adown两个向量,表示为
A={Aup,Adown}(7)
1.3 奖励函数
在深度强化学习模型中,奖励函数主要体现在自我车辆和社会车辆交互过程中,自我车辆可以获得最大期望的决策,奖励函数的设定对于无人驾驶作出的期望决策动作至关重要。因此,决策模型算法的函数设定选择围绕车辆是否能成功通过十字路口来进行设计,在通过路口的过程中,自我车辆与社会车辆不发生碰撞并且通过的时间不能过长。根据以上条件,奖励函数可以分为两个部分组成,即r=rt+rs。
rs代表自我车辆根据当前状态设定奖励函数,为了保证能够获得较大的成功率,当车辆发生碰撞时深度强化学习模型将给出最大惩罚。同时,为了避免自我车辆通过十字路口等待最佳的通行间隙,导致车辆进入盲目等待状态,将对等待超过30 s的车辆给予超时惩罚。edbf83cc4248e99b276b3e0c4b5eed94fcf25fa4722714f7e9ba68aa2472c03e在每个回合中,车辆到达设定的终点再给予奖励。
以上是当前回合结束后对车辆当前状态设定奖励函数,这样车辆获得的奖励实时性较低。为了能够获得实时奖励,在自我车辆行驶过程中每走一步都给予及时奖励rt=rt+rstep,其中rstep=-0.2为每个时间步长设定的小惩罚,以此来提高车辆的通行时间。
1.4 交叉路口决策模型
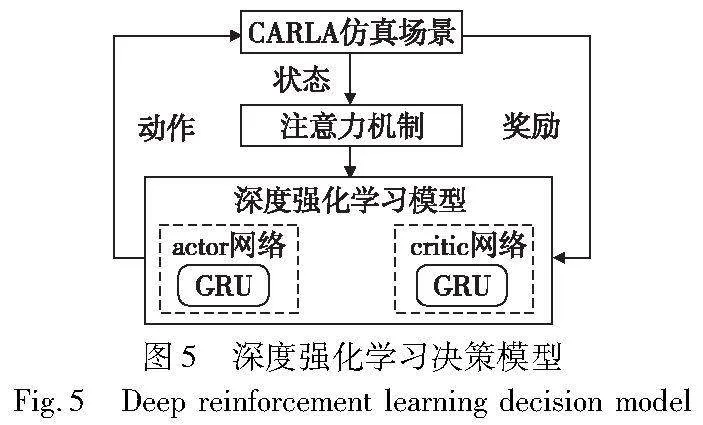
基于GA-TD3算法的完整决策模型如图5所示。CARLA仿真场景提供当前时刻环境状态st,首先使用注意力机制模型处理状态信息,输出的注意力张量AttentionTensor输入到actor网络。在actor-critic网络中,GRU处理得到的ht传递给网络的最后一层全连接层,最终actor网络输出相应的动作。自我车辆则根据模型的动作输出结果,在仿真场景中不断地探索,与社会车辆进行交互,在环境交互的过程中,模型车辆自我回报奖励,critic网络根据得到的动作奖励对动作进行评估得到Qmin(s,a)。模型采用延迟更新策略,对网络参数进行更新,以此探索得到最优的交叉路口决策模型。
详细的算法流程如算法1所示,首先初始化GRU-actor和GRU-critic网络参数,并初始化相关的目标网络参数。从CARLA仿真模拟器获取的状态空间进行解析,将状态空间输入到注意力机制模型中,注意力机制实时关注agent车辆与社会车辆交互的重要信息,将得到的注意力张量输入到模型中进行训练,模型根据获取到的状态信息进行动作选择,从而得到合理的策略。actor和critic网络根据延迟更新的频率依次更新,并更新相关的目标网络。深度强化学习不断地迭代循环直至训练结束,从而获取到模型的最优策略。
算法1 GRU-Attention-TD3
2 仿真实验
2.1 仿真环境
实验设备配置为:Ubuntu 20.04系统,Intel Xeon Gold 6326 CPU @ 2.90 GHz,128 GB运行内存,显卡Tesla V100-PCIE-32 GB。 实验开发语言以Python语言为主,神经网络框架选择TensorFlow框架,采用CARLA仿真模拟器,选择了Town03地图搭建仿真场景。实验场景搭建参考文献[24]。根据实验需求重新设定实验场景数据。
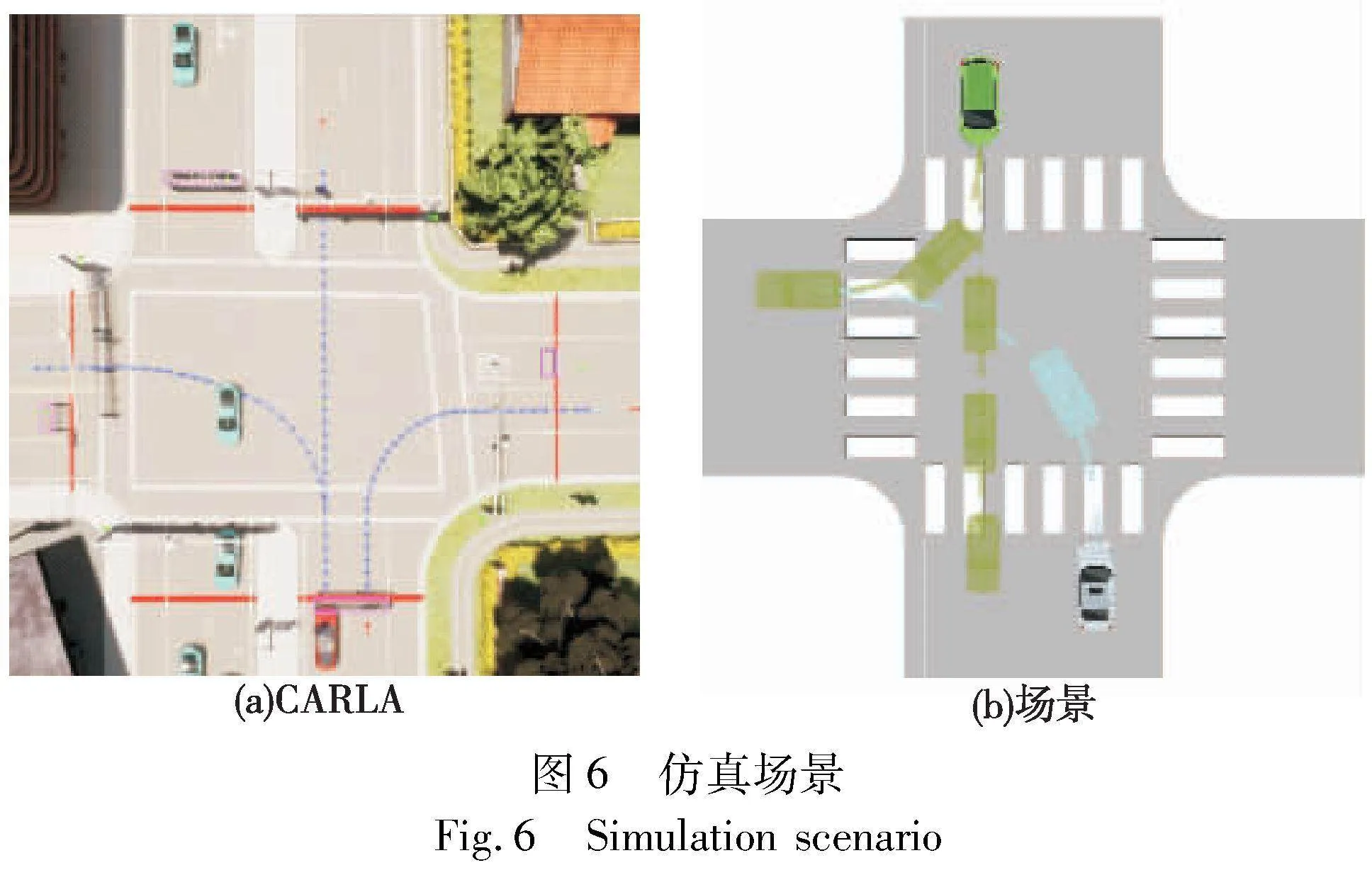
自我车辆及社会车辆的路线,仿真场景如图6(a)所示。交通流中社会车辆分直行通过十字路口和右转同自我车辆共同汇入目的道路两种路径,如图6(b)所示。右转和直行的社会车辆随机生成,社会车辆的跟车距离保持在5 m,在7~12 s随机时间里生成社会车辆。当右转车辆和直行车辆数量达到6辆以上开始生成自我车辆,进行训练。为了加快训练的时间,实验场景关闭了红绿灯的轮转时间,始终保持自我车辆在结束新一轮训练后能够立刻生成。
实验中的自我车辆根据设定的路线完成左转行驶任务。场景以带有交通信号灯的十字路口、交通流以垂直方向直行与左转车辆同时存在的情景为主,当社会车辆数量达到5辆时,交通流初始化完毕,开始生成自我车辆。生成自我车辆有两个限定条件,分别是交通流初始完毕和当前通行方向交通信号灯为绿灯。同时满足这两个条件,CARLA场景开始新的回合生成自我车辆,左转通过当前路口。自我车辆的纵向控制由算法输出的目标速度决定,限定了车辆的目标速度为50 km/h。社会车辆的初始速度为10 km/h,最终的目标速度为50 km/h。
2.2 深度强化学习参数设定
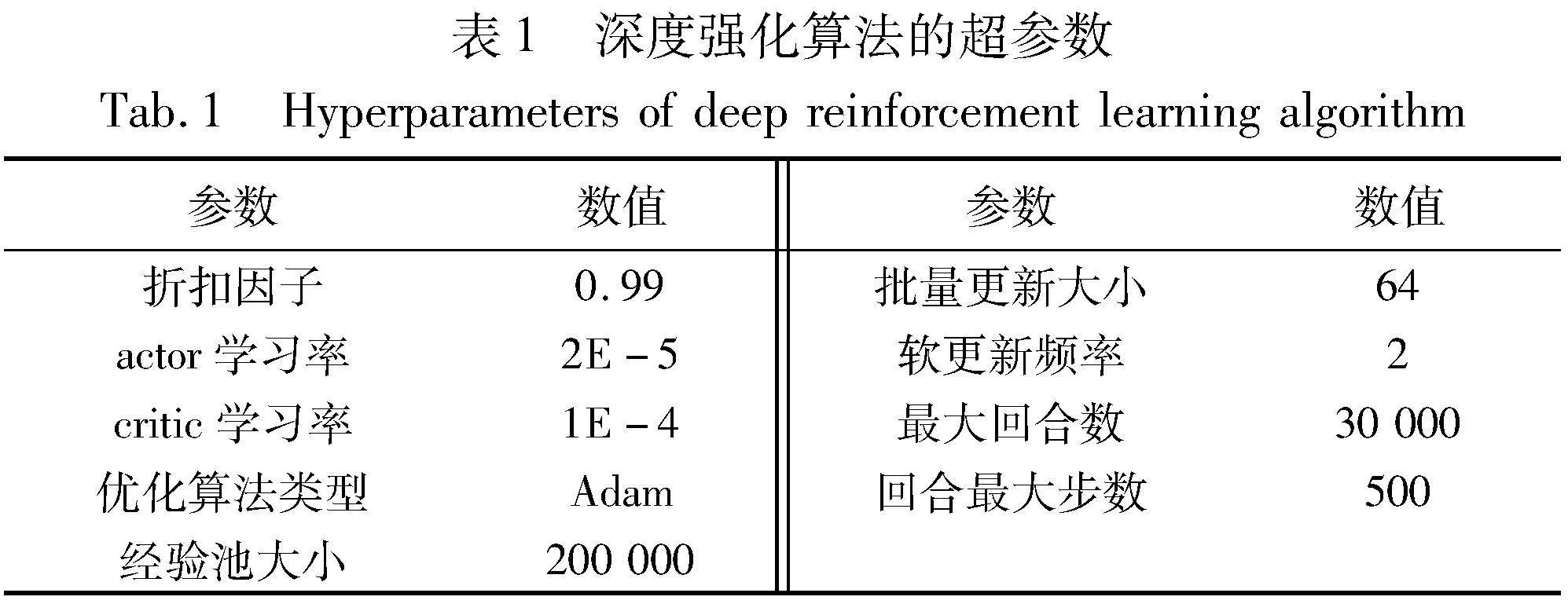
本文实验训练回合为20 000轮,带有噪声的回合数为1 000轮,模型训练的详细超参数如表1所示。
3 实验结果分析
实验采用不同的决策算法输出的动作结果控制自我车辆根据周围车流环境的变化顺利左转通过十字路口驶入主路,通过对比不同模型的成功率、超时率、奖励值,以及车辆通过路口的时间来衡量深度强化学习模型的好坏。
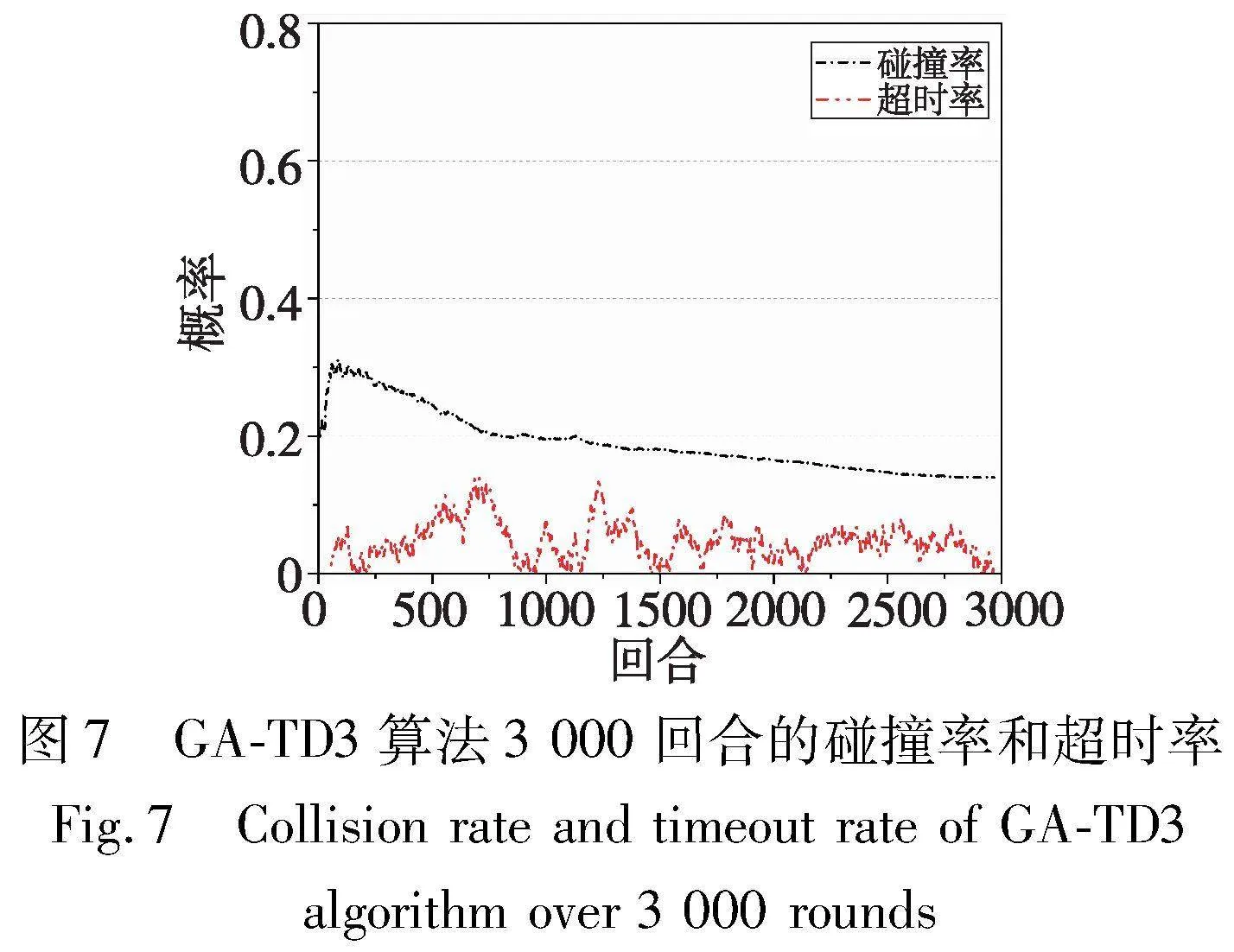
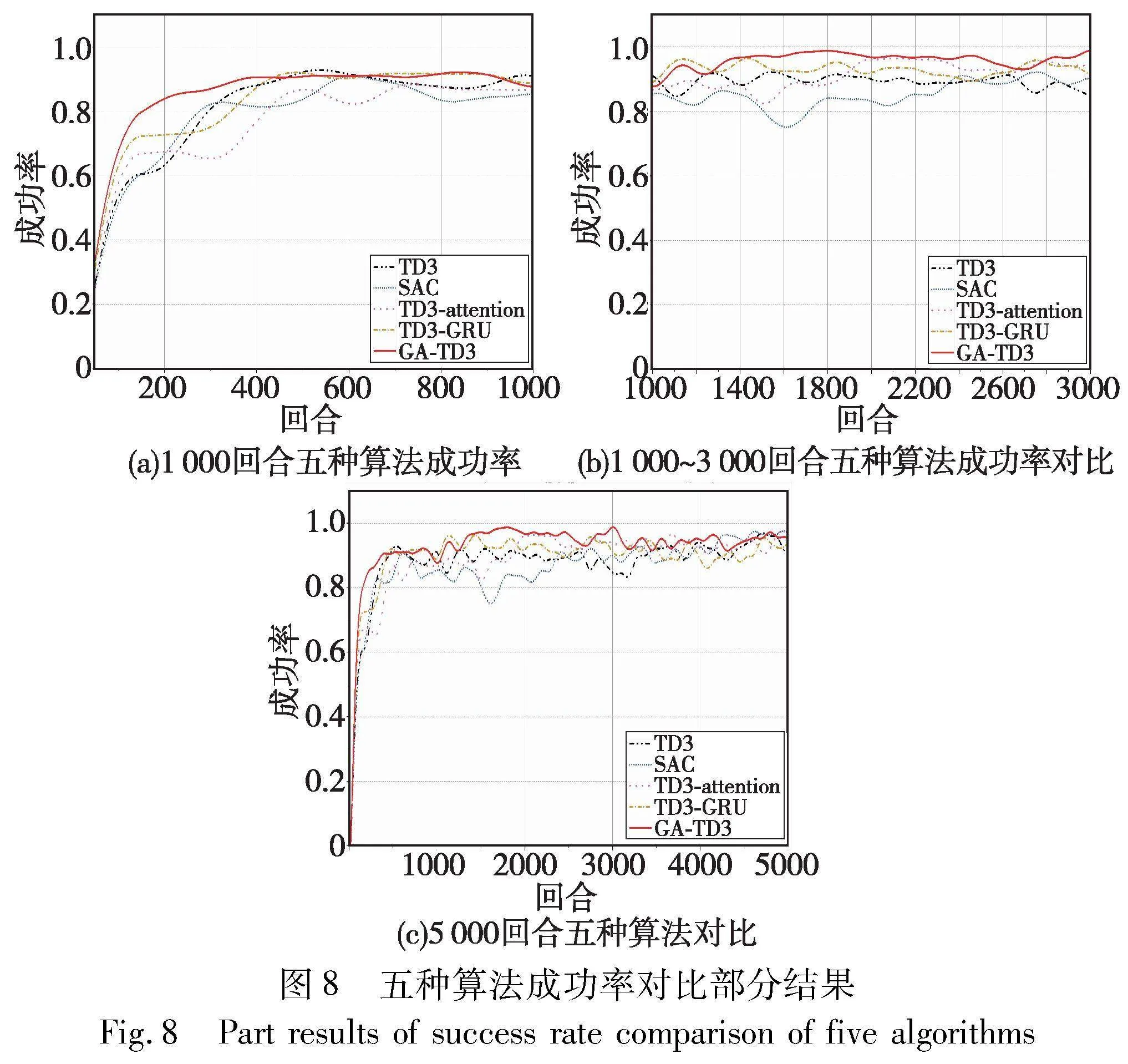
将本文改进后的算法与TD3[24]、SAC[30]、TD3-GRU[31]、TD3-Attention[15]进行实验对比,详细结果如图7~10所示。如图7所示,GA-TD3模型在训练初期,自我车辆为了通过路口不停在探索动作,因此决策模型的碰撞率较高,在150回合左右达到峰值后模型学习到了一部分经验样本,探索动作相对保守,碰撞率开始下降。由于刚开始训练的模型处于不停探索的状态,所以刚开始超时率为0。在训练了一段时间后,为了保证安全通行,自主车辆等待通行的最佳间隙,在此过程中车辆容易出现等待超时的现象。模型学习到车辆出现盲等状态,为了增加通行效率,模型增加动作探索。在后续的训练过程中,模型通过来回的探索等待以此寻找最佳动作,在2 000回合后模型的超时率在一定区间内稳定波动,且模型的碰撞率持续下降,由此可见模型在2 000回合后趋于收敛。
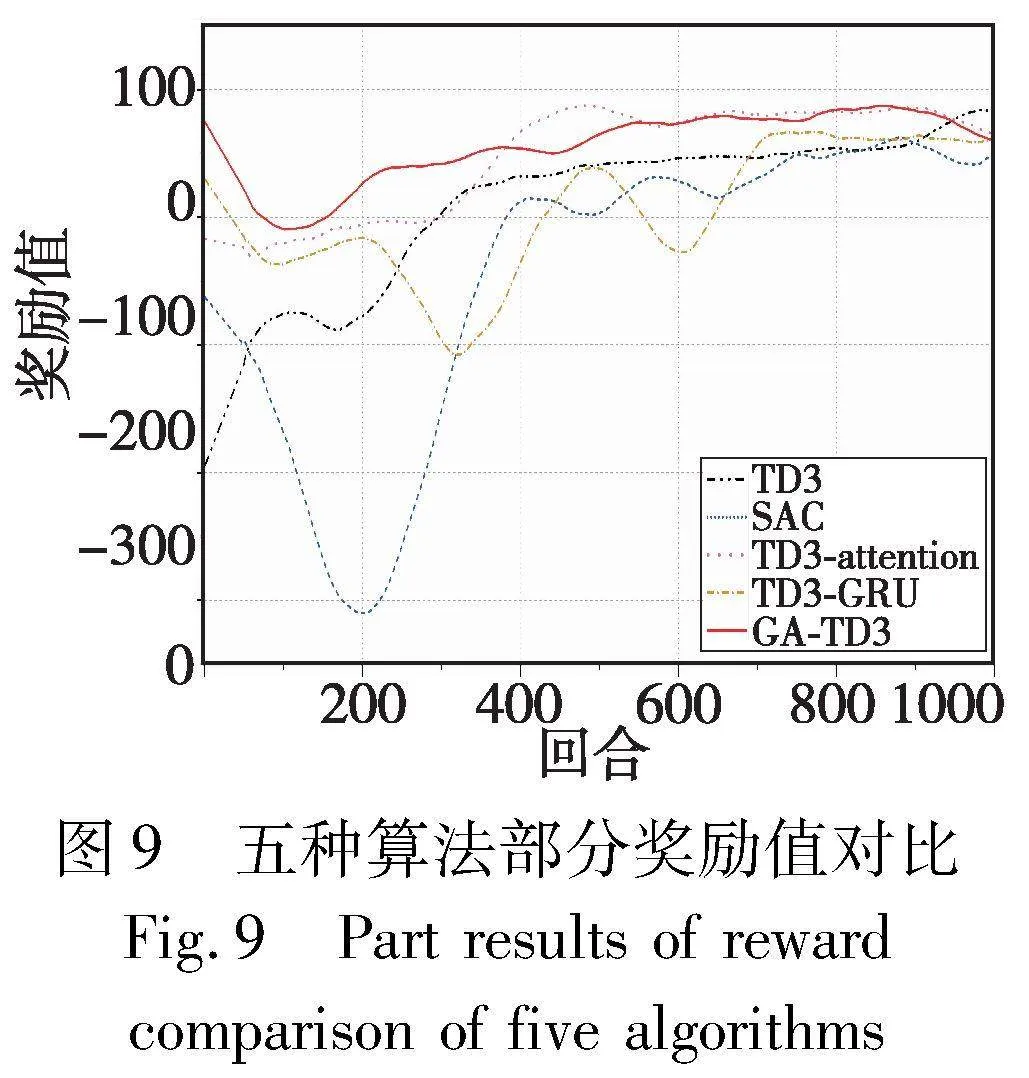
图8为GA-TD3算法与其他算法的对比局部图。从图中可以看出,GRU网络的记忆功能对模型uNmUZMh3Od9SQl7eaRAOJA==的训练速度上有一定提升。TD3-GRU与GA-TD3模型训练前期,相较于TD3模型,引入GRU的模型收敛速度较快,200回合模型已经具有收敛趋势。GA-TD3在300回合已经处于一个较为平稳的状态,在训练了1 000回合后,成功率基本保持在0.92以上,当模型训练至5 000回合,模型的成功率已经可以达到0.95。TD3-GRU模型的收敛效果与GA-TD3模型较为接近,当模型训练至2 000回合,模型的成功率在0.9~0.95。TD3-attention模型收敛速度相对于TD3-GRU较慢,在2 000回合后模型的成功率维持在0.9左右。TD3模型的收敛速度与SAC较为接近,相较于引入GRU的TD3模型收敛速度较慢,且成功率相对较低,前5 000回合成功率基本维持在0.9以下。与TD3同一时间段提出的SAC算法相比,SAC在前期的训练结果最低,由于SAC是随机探索的策略,前期训练当作探索的不确定性较大,导致模型收敛相对较慢。综上,提出模型在收敛速度上优于TD3与SAC两个模型。
由于GRU网络与TD3网络结合得到的TD3-GRU模型结构相较于TD3模型更为复杂,模型在训练过程中,环境的随机性会导致模型在训练期间出现波动。基于注意力机制的深度强化学习决策模型,能够帮助agent车辆在与社会车辆交互的过程中,查询筛选出有效的状态数据,减少了模型对无效动作的探索,提升模型的学习效率和稳定性。奖励函数设定每次发生碰撞赋予-500的回报,在前期探索过程中,可以看出引入注意力机制的模型奖励回报平均总值维持在0以上。TD3为确定性策略,在动作探索过程中,对于环境的变换适应性较差,导致奖励值较长时间处于负值状态。SAC为随机探索策略,在探索过程中相较于TD3模型更能适应变换的场景。
如图10所示,TD3和TD3-GRU模型在模型的稳定性上较差,这是因为环境中的社会车辆始终都是随机生成的,在模型训练后期容易出现成功率下降的情况。因此随机场景中,传统深度强化学习算法想要在长期训练过程中维持一个相对稳定的成功率,具有一定的难度。提出基于attention模型的深度强化学习算法会更加关注状态空间中agent车辆与社会车辆的交互行为,使其关注到更有价值的状态信息。从奖励值结果图中也可以看出,TD3-attention模型和GA-TD3模型在随机场景下模型的稳定性较优。奖励值维持在正值,证明agent车辆出现碰撞的概率较低。
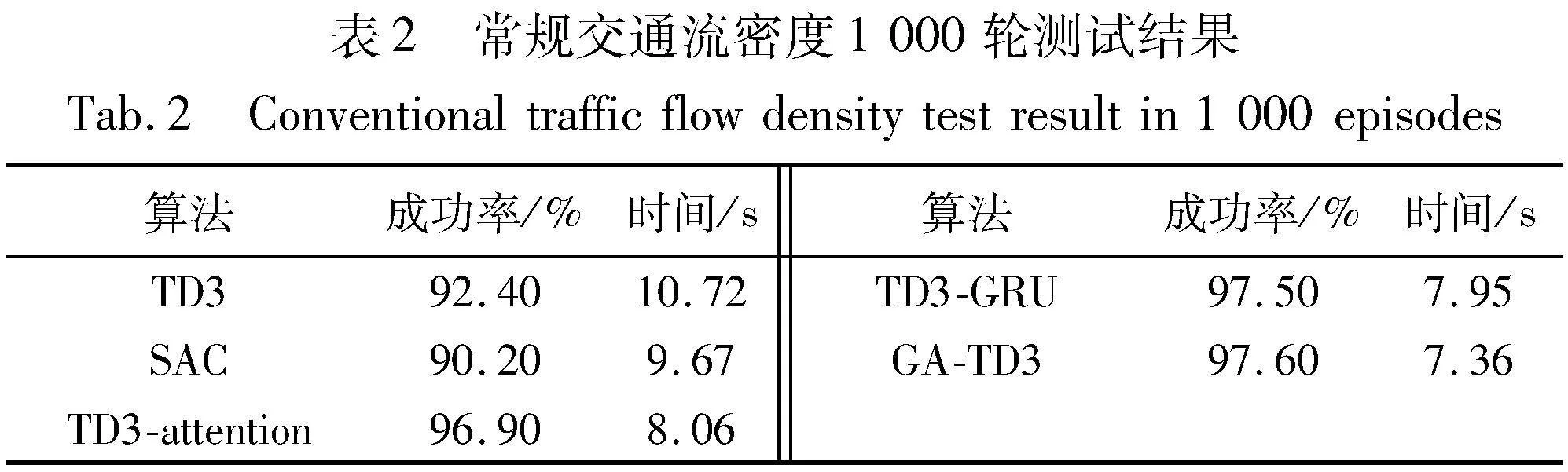
对五组算法模型进行确定性验证实验,结果如表2所示。在保证五组模型的社会车辆生成概率和红绿灯场景保持一致的情况下,对TD3、SAC、TD3-attention、TD3-GRU、以及GA-TD3模型行分别进行1 000回合的验证性实验。实验结果表明GA-TD3无人驾驶决策模型的成功率达到了97.6%,TD3模型的成功率为92.4%,成功率提升了5.2%,车辆通过十字路口的时间缩短了3.36 s;与SAC模型相比,成功率提升了7.4%,通行时间缩短了2.31 s。整体模型的成功率和车辆的通行效率均有提升。
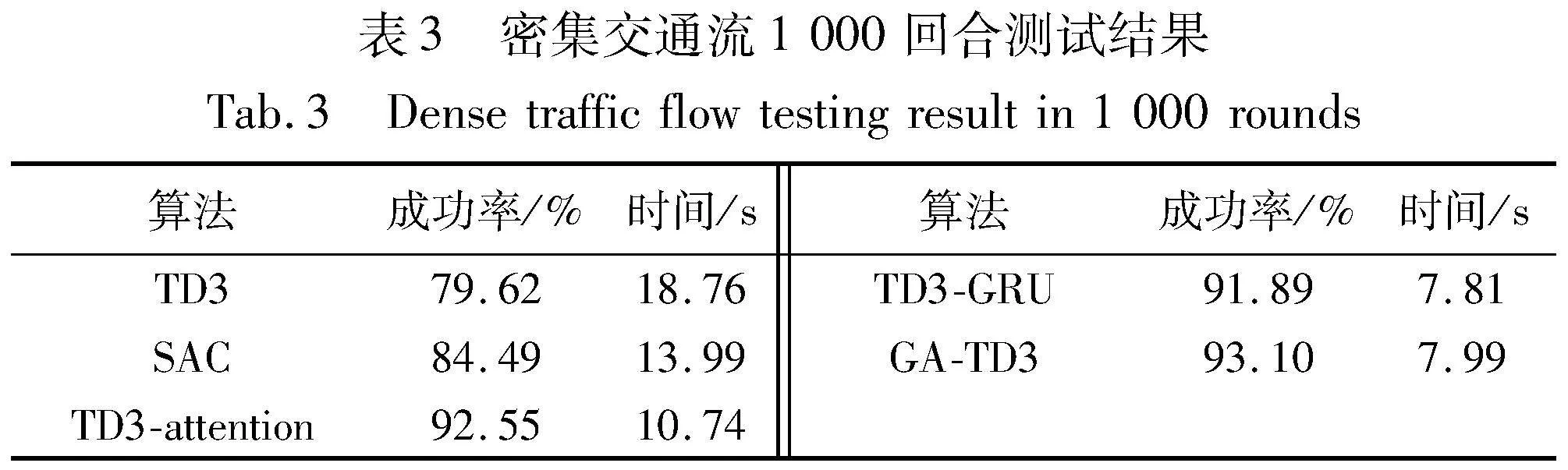
此外,对五组算法还进行了密集交通流的测试。重新设定测试场景,修改社会车辆的生成时间间隔在4~8 s,社会车辆的跟车距离最小保持在3 m。当社会车辆的数量达到8辆的时候,开始生成自我车辆进行验证测试,五组算法依次进行1 000轮验证测试,验证结果如表3所示。从表中可以看出,改进后的模型较为稳定,成功率保持在90%以上,TD3和SAC模型的成功率都有所降低,且同行时间更长,在测试过程中出现了自我车辆等待超时的现象,导致模型的成功率有所降低。注意力机制的模型在密集交通流的场景更加关注社会车辆与自我车辆之间的交互,等待选择最佳通行间隙,因此通行时间相对于表2的交通流场景等待时间较长。引入GRU的模型由于车流密度的增加,场景的动态性增加,模型更加关注的是车辆到达终点的结果,所以在测试过程前期碰撞率有所增加,导致模型在测试过程中适应性相对不足,成功率有小幅降低,但在通行时间上没有太大的变化。从整体上看,提出的GA-TD3模型在成功率远高于TD3模型,通行时间上相对于表2的交通流场景增加了0.63 s,和密集交通流下的TD3-GRU模型的通行时间相对接近,且成功率优于TD3-GRU的模型。
从实验整体上对比可以看出,提出模型在稳定性和成功率均有所提升。针对交叉路口而言,本文模型下的agent车辆通过交叉路口过程中产生碰撞概率以及agent车辆在路口不通行进入长期等待的概率都会大幅降低,从而提高了车辆通过交叉路口的效率。该方法在城市交叉场景中可以极大提高车辆的通行效率、缓解交通压力,并增加车辆的安全率,减少交通事故的发生。
4 结束语
本文围绕复杂场景下的深度强化学习决策模型进行研究,主要针对十字路口无人驾驶车辆左转汇入目的车道的场景,提出了基于TD3的改进算法GA-TD3。左转车辆需要与不同路径的社会车辆在交汇点进行交互,无人驾驶车辆如何在交互过程中作出合理安全的决策行为十分重要。本文算法引入注意力机制使自我车辆和社会车辆进行交互,查询最有价值的交互车辆,提升模型的成功率以及模型的稳定性。其次将GRU神经网络融入到TD3的网络结构中,使模型具备记忆功能,更好地处理有序的数据,加快了模型的收敛速度,增加了模型的成功率。实验采用CARLA仿真模拟器进行模拟实验。通过实验验证,基于GA-TD3无人驾驶决策模型在训练至500回合后开始收敛,验证集的成功率达到了97.6%,相较于TD3算法成功率提升了5.2%,减少了agent车辆与社会车辆碰撞,提升了无人驾驶的安全性能。此外,车辆的通行时间也缩短了3.36 s,大大增加了路口车辆的通行效率,缓解了城市复杂场景下交通压力。GA-TD3无人驾驶决策模型在成功率和通行效率上都得到了验证。但该模型在面对车流量更密集的场景还有待改进,下一步将对此问题提出进一步研究。
参考文献:
[1]Bai Zhengwei, Hao Peng, Shangguan Wei, et al. Hybrid reinforcement learning-basN7eBPA15xr9ZiVgiEYSpxQ==ed ECO-driving strategy for connected and automated vehicles at signalized intersections[J]. IEEE Trans on Intelligent Transportation Systems, 2022, 23(9): 15850-15863.
[2]Schmidt G K, Posch B. A two-layer control scheme for merging of automated vehicles[C]//Proc of the 22nd IEEE Conference on Decision and Control. Piscataway, NJ: IEEE Press, 1983: 495-500.
[3]Rios-Torres J, Malikopoulos A A. Automated and cooperative vehicle merging at highway on-ramps[J]. IEEE Trans on Intelligent Transportation Systems, 2016,18(4): 780-789.
[4]Qu Dayi, Zhang Kekun, Song Hui, et al. Analysis and modeling of lane-changing game strategy for autonomous driving vehicles[J]. IEEE Access, 2022, 10: 69531-69542.
[5]Cheng Wei, Fei Hui, Yang Zijiang, et al. Fine-grained highway autono-mous vehicle lane-changing trajectory prediction based on a heuristic attention-aided encoder-decoder model[J]. Transportation Research Part C: Emerging Technologies, 2022, 140: 103706.
[6]Pei Huaxin, Zhang Jiawei, Zhang Yi, et al. Fault-tolerant cooperative driving at signal-free intersections[J]. IEEE Trans on Intelligent Vehicles, 2022, 8(1): 121-134.
[7]Pei Huaxin, Zhang Jiawei, Zhang Yi, et al. Optimal cooperative dri-ving at signal-free intersections with polynomial-time complexity[J]. IEEE Trans on Intelligent Transportation Systems, 2021, 23(8): 12908-12920.
[8]Yan Qi,Wang Hongfeng. Double-layer Q-learning-based joint decision-making of dual resource-constrained aircraft assembly scheduling and flexible preventive maintenance[J]. IEEE Trans on Aerospace and Electronic Systems, 2022, 58(6): 4938-4952.
[9]Rais M S, Boudour R, Zouaidia K, et al. Decision making for auto-nomous vehicles in highway scenarios using Harmonic SK deep SARSA[J]. Applied Intelligence, 2023, 53(3): 2488-2505.
[10]Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning [EB/OL]. (2019-07-05). https://arxiv.org/abs/1509.02971.
[11]Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
[12]Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster level in StarCraft Ⅱ using multi-agent reinforcement learning[J]. Nature, 2019, 575(7782): 350-354.
[13]Kiran B R, Sobh I, Talpaert V, et al. Deep reinforcement learning for autonomous driving: a survey[J]. IEEE Trans on Intelligent Transportation Systems, 2021,23(6): 4909-4926.
[14]Wu Jingda, Huang Zhiyu, Lyu Chen. Uncertainty-aware model-based reinforcement learning: methodology and application in autonomous driving[J]. IEEE Trans on Intelligent Vehicles, 2022, 8(1): 194-203.
[15]Chen Jianyu, Li S E, Tomizuka M. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning[J]. IEEE Trans on Intelligent Transportation Systems, 2021,23(6): 5068-5078.
[16]Wang Huanjie,Gao Hongbo,Yuan Shihua,et al. Interpretable decision-making for autonomous vehicles at highway on-ramps with latent space reinforcement learning[J]. IEEE Trans on Vehicular Technology, 2021, 70(9): 8707-8719.
[17]Li Guofa, Yang Yifan, Li Shen, et al. Decision making of autonomous vehicles in lane change scenarios: deep reinforcement learning approaches with risk awareness[J]. Transportation Research Part C: Emerging Technologies, 2022, 134: 103452.
[18]Zhou Mofan, Yu Yang, Qu Xiaobo. Development of an efficient dri-ving strategy for connected and automated vehicles at signalized intersections: a reinforcement learning approach[J]. IEEE Trans on Intelligent Transportation Systems, 2019, 21(1): 433-443.
[19]Wei Lianzhen, Li Zirui, Gong Jianwei, et al. Autonomous driving strategies at intersections: scenarios, state-of-the-art, and future outlooks[C]//Proc of IEEE International Intelligent Transportation Systems Conference. Piscataway, NJ: IEEE Press, 2021: 44-51.
[20]Shu Hong, Liu Teng, Mu Xingyu, et al. Driving tasks transfer using deep reinforcement learning for decision-making of autonomous vehicles in unsignalized intersection[J]. IEEE Trans on Vehicular Technology, 2021, 71(1): 41-52.
[21]吴思凡, 杜煜, 徐世杰, 等. 基于深度确定性策略梯度的智能车汇流模型[J]. 计算机工程, 2020, 46(1): 87-92. (Wu Sifan, Du Yu, Xu Shijie, et al. Traffic merging model for intelligent vehicle based on deep deterministic policy gradient[J]. Computer Engineering, 2020, 46(1): 87-92.)
[22]吴思凡, 杜煜, 徐世杰, 等. 基于长短期记忆-异步优势动作评判的智能车汇入模型[J]. 汽车技术, 2019, 529(10): 42-47. (Wu Sifan, Du Yu, Xu Shijie, et al. Intelligent vehicle merging model based on long short-term memory and asynchronous advantage actor critic algorithm[J]. Automobile Technology, 2019, 529(10): 42-47.)
[23]Liu Yuqi, Zhang Qichao, Zhao Dongbin. A reinforcement learning benchmark for autonomous driving in intersection scenarios[C]//Proc of IEEE Symposium Series on Computational Intelligence. Pisca-taway, NJ: IEEE Press, 2021: 1-8.
[24]王曙燕, 万顷田. 自动驾驶车辆在无信号交叉口右转驾驶决策技术研究[J]. 计算机应用研究, 2023,40(5): 1468-1472. (Wang Shuyan, Wan Qintian. Right-turn driving decisions of autonomous vehicles at signal-free intersections[J]. Application Research of Computers, 2023,40(5): 1468-1472.)
[25]Wu Sifan, Tian Daxin, Zhou Jianshan, et al. Autonomous on-ramp merge strategy using deep reinforcement learning in uncertain highway environment[C]//Proc of IEEE International Conference on Unmanned Systems. Piscataway, NJ: IEEE Press, 2022: 658-663.
[26]Liu Shuijing, Chang Peixin, Liang Weihang, et al. Decentralized structural-RNN for robot crowd navigation with deep reinforcement learning[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway, NJ: IEEE Press, 2021: 3517-3524.
[27]Ni Tianwei, Eysenbach B, Salakhutdinov R. Recurrent model-free RL can be a strong baseline for many POMDPs[EB/OL]. (2022-06-05). https://arxiv.org/abs/2110.05038.
[28]Mott A, Zoran D, Chrzanowski M, et al. Towards interpretable reinforcement learning using attention augmented agents[EB/OL]. (2019-06-06). https://arxiv.org/abs/1906.02500.
[29]Iqbal S, Sha Fei. Actor-attention-critic for multi-agent reinforcement learning[C]//Proc of International Conference on Machine Learning. [S.l.]: PMLR, 2019: 2961-2970.
[30]Tang Xiaoling, Huang Bing, Liu Teng, et al. Highway decision-making and motion planning for autonomous driving via soft actor-critic[J]. IEEE Trans on Vehicular Technology, 2022, 71(5): 4706-4717.
[31]Ye Junliang, Gharavi H. Deep reinforcement learning assisted beam tracking and data transmission for 5G V2X networks[J]. IEEE Trans on Intelligent Transportation Systems, 2023, 24(9): 9613-9626.
