
基于深度学习的图像拼接算法研究综述
2024-08-17 00:00:00杨利春田彬党建武
计算机应用研究 2024年7期












摘 要:图像拼接是计算机视觉和计算机图形学中的一个重要分支,在三维成像等方面具有广泛的应用。相较于传统基于特征点检测的图像拼接框架,基于深度学习的图像拼接框架具有更强的场景泛化表现。目前虽然关于基于深度学习的图像拼接研究成果众多,但仍缺少相应研究的全面分析和总结。为了便于该领域后续工作的开展,梳理了该领域近10年的代表性成果。在对传统拼接方法与基于深度学习的图像拼接方法对比的基础上,从图像拼接研究领域中的单应性估计、图像拼接和图像矩形化三个子问题出发,进行了学习策略及模型架构设计、经典模型回顾、数据集等方面的整理与分析。总结了基于深度学习的图像拼接研究方法的一些特点和当前该领域的研究现状,并对未来研究前景进行了展望。
关键词:单应性估计; 图像拼接; 图像矩形化; 深度学习
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)07-002-1930-10
doi:10.19734/j.issn.1001-3695.2023.10.0528
Survey on image stitching algorithm based on deep learning
Abstract:Image stitching is an important branch in computer vision and computer graphics, and has a wide range of applications in 3D imaging and other aspects. Compared with the traditional image stitching framework based on feature point detection, the image stitching framework based on deep learning has stronger scene generalization performance. Although there are many research results on image stitching based on deep learning, there is still a lack of comprehensive analysis and summary of the corresponding research. In order to facilitate the subsequent work in this field,this paper sorted out the representative results in this field in the past 10 years. Based on the comparison between traditional stitching methods and deep learning-based image stitching methods,it collated and analysed the learning strategy and model architecture design, classical model review, and dataset from the three sub-problems of homography estimation, image stitching, and image rectangling in the research field of image stitching. It summarized some features of deep learning-based image stitching research methods and summarized the current research status in the field,and prospected the future research prospects.
Key words:homography estimation; image stitching; image rectangling; deep learning
0 引言
图像拼接是一项关键且具有挑战性的计算机视觉任务,在过去的几十年里已经得到了很好的研究,其目的是将从不同观看位置捕获的不同图像构建成具有更宽视场(field-of-view,FOV)的全景。图像拼接被广泛应用于医疗[1]、监控视频[2]、自动驾驶[3]、虚拟现实[4]等领域。
传统的图像拼接技术可以分为自适应扭曲和接缝切割[5]两个步骤。传统算法往往依赖于越来越复杂的几何特征(点、线、边缘等特征)来实现更好的内容对齐和形状保存。在计算了扭曲之后,通常采用接缝切割去除视差伪影。为了探索不可见的接缝,使用边[6]、显著映射[7]等设计了各种能量函数。传统方法要求场景特征在图像中密集且均匀分布,鲁棒性差。同时,随着几何结构增大,计算成本急剧飞跃,因此图像拼接仍然具有挑战性。
近年来,随着深度学习技术的快速发展,基于深度学习的图像拼接模型得到了积极的探索,并在各种复杂场景上取得了良好的性能。受到光流估计、双目立体匹配等视觉研究的启发,目前基于深度学习的图像拼接研究主要围绕借助相关深度学习方法,构建更高效的模型架构设计、特定拼接场景设计及模型训练策略等方面展开。从早期的基于卷积神经网络(convolutional neural networks,CNN)的方法(如SRCNN[8])到最近有前景的基于注意力机制的方法(如swin Transformer[9]),各种深度学习方法已经被应用于处理图像拼接任务,解决了不少传统图像拼接方案难以解决的问题(如低纹理场景对齐、大视差拼接等)。目前,已经提出了各种基于深度学习(deep lear-ning,DL)图像拼接的相关研究工作,包括有监督、无监督、CNN、Transformer、GNN、级联式、非级联式等方法。
之前的综述研究,如文献[10],虽然给出了图像拼接算法的全面调查,但是主要针对传统方法进行全面总结,而文献[11~13]只关注图像拼接中,特定任务方法。文献[11]专注于对基于特征方法的技术研究;Lyu等人[12]提供了用传统解决方案解决图像/视频拼接问题的详细综述,主要针对基于像素的方法与基于特征的方法进行总结;虽然Liao等人[13]讨论了基于DL学习图像配准方法,但只考虑了图像校准中的各种技术,缺乏对整个图像拼接过程的详细概述。此外,由于基于DL学习的图像拼接综述数量很少,读者很难了解图像拼接的发展趋势。为了便于后续的研究工作,在此本文从模型架构设计、学习策略设计、拼接方式设计等方面出发,针对图像拼接的三个子任务,即单应性估计、图像拼接和图像矩形化,进行了分类整理及概述,并对当前的算法进行了对比及总结。不同于现有的图像拼接相关综述,本文主要围绕DL方法在图像拼接领域的研究方法、数据集等进行了归纳分析。就当前基于DL的图像拼接研究存在的问题及未来研究前景进行了总结与展望。
本文主要贡献有三个方面:
a)对比分析了传统图像拼接算法与基于深度学习的图像拼接技术各自的优缺点,为该领域后续工作的开展提供了指导。
b)对基于DL的图像拼接技术进行了全面的综述,包括基准数据集、学习策略及模型设计出发点等多个角度,回顾了各个子领域的一些基于DL的经典模型,梳理了其模型亮点与不足,为后续相关工作的跟进指引了方向。
c)讨论了基于DL的图像拼接领域研究所面临的问题与挑战,整理了基于DL的图像拼接领域研究的一些模型代码和数据集,为同类研究工作的开展提供了有力的支撑。
1 传统拼接与基于DL拼接技术对比
本章从不同的角度回顾了传统图像拼接与基于DL的图像拼接技术,包括传统的单应性估计方法和基于DL的单应性估计方法,传统图像拼接方法与基于DL图像拼接,传统矩形化与基于DL矩形化。
1.1 单应性估计方法对比
单应性是指3D平面里两幅图像或者围绕相机投影中心旋转拍摄的两幅图像之间的变换关系。单应是两个空间之间的映射,通常用来表示同一场景的两个图像之间对应关系的3×3矩阵,包含8个自由度。换句话说,单应性是两个图像中的点之间的非奇异线性关系。
1.1.1 传统的单应性估计
传统的单应性估计是基于特征点匹配的方法,特征是要匹配的两个输入图像中的元素,它们是在图像块的内部,图像块是图像中的像素组,特征通常包括点、线、边缘等。传统方法为了给图像对提供更好的特征匹配,通常采用角点匹配。角点是很好的匹配特性,在视点变化时,角点特征是稳定的;此外,角点的邻域具有强度突变。角点检测算法有Harris角点检测算法、SIFT特征点检测算法、FAST算法角点检测算法等。
1.1.2 基于DL的单应性估计
基于DL的单应性估计方法通过深度单应性估计模型,利用图像物体重叠部分的特征关系,通过图论等方法,无须人工干预即可实现全自动单应性估计,虽然存在较强的场景泛化能力,但严重依赖数据集。针对此问题,为了便于该领域后续工作的开展,整理两者的优缺点如表1所示。
1.2 图像拼接方法对比
1.2.1 传统的图像拼接
传统的图像拼接方法可以分为基于像素的拼接与基于特征的拼接。基于像素的方法将图像的所有像素强度相互比较,对于场景移动问题健壮性差,速度也相比于基于特征的方法更慢。基于特征的方法虽然自动发现无序图像集之间的重叠关系,但是严重依赖于特征等信息,并且其特征检测器的选择取决于问题本身,不同的特征器在不同场景下存在的问题也不同,比如特征计算时间长、性能差等问题。
1.2.2 基于DL的方法
为了解决传统方法中的不足,提出了基于DL的图像拼接技术。相较于传统算法,基于DL的图像拼接算法可以为图像处理提供更高效、精准的解决方案。如表2所示,整理了关于传统图像拼接与DL图像拼接的优缺点,为后续研究提供了参考。
1.3 图像矩形化方法对比
图像拼接技术在获得大视场的同时,也因为视角投影带来了不规则的边界问题。研究发现,艺术家与普通用户通常更喜欢矩形边界[14]。
1.3.1 传统的矩形化方法
为了获得矩形边界,传统矩形化通常采用裁剪与图像补全的方法,但这种方法丢失了更多的原始内容信息。图像补全[15,16]可以根据图像中完整区域的信息对缺失区域进行填充,当缺失区域较小或纹理结构简单时,这种方法的效果较好,但当缺失区域较大或纹理结构高度复杂时,得到的填充区域会存在严重的内容失真。此外,通过图像补全技术获得的矩形图像可能会增加一些看似合理但不现实的信息,这在实际应用中非常危险。
1.3.2 基于DL的矩形化方法
与传统方法不同,基于DL图像矩形化技术不引入任何额外的虚假内容信息,只是在原始内容信息的基础上通过网格畸变将拼接后的图像扭曲成矩形图像,并获得了令人满意的效果。表3整理了关于传统图像矩形化与DL图像矩形化的优缺点,为了后续研究提供参考。
2 基于DL的单应性估计
单应是两个空间之间的映射,通常用来表示同一场景的两个图像之间的对应关系,是两个图像中点之间的非奇异线性关系。DL为单应性估计带来了新的灵感,无须人工干预即可实现全自动单应性估计。首先,在基于学习的图像校准中总结了几种广泛使用的学习策略,即基于有监督的单应性估计和无监督的单应性估计;接着,回顾了一些最新使用的网络架构以及经典模型。
2.1 学习策略
2.1.1 有监督
Detone等人[20]在2016年首次提出了一种有监督DL卷积神经网络(HomographyNet)来估计一对图像之间的相对单应性,输入两张图,它直接产生两幅图像之间的同形关系。Le等人[21]填补了在动态场景下单应性研究的不足,提出了一个多尺度神经网络。Nowruzi等人[22]提出了一个双卷积回归网络的层次来估计一对图像之间的单应性,通过简单模型的分层排列,实现了更高性能。Wang等人[23]使用卷积神经网络提高给定图像对的单应性估计的准确性。通过采用受立体匹配工作启发的空间金字塔池化模块[24],利用图像的上下文信息,提高卷积部分的特征提取性能力。Nie等人[25]提出了一个大基线DL单应性模型,用于估计不同特征尺度下参考图像和目标图像之间的精确投影变换,其中大基线[26]是中小基线的相对概念,但由于合成图像中缺乏真实的场景视差,其泛化能力受到限制。最近的一些工作[27~31]使用真实世界的场景建立了训练数据集,并用手动注释标记捕获的图像,从而促进了这一研究领域的发展。
2.1.2 无监督
由于合成图像中缺乏真实的场景视差,其泛化能力受到限制。为了解决这个问题,Nguyen等人[32]第一个提出了一种无监督解决方案,最大限度地减少了真实图像对上的光度损失。该模型估计了没有投影标签的配对图像的单应性矩阵,通过减少无须地面实况数据的逐像素强度误差,使UDHN[32]优于以前的监督学习技术。所提无监督算法在保证精度和对光照波动的鲁棒性的同时,还可以实现更快的推理。受这项工作的启发,越来越多的方法利用无监督学习策略来估计单应性,如CA-UDHN[26]、RISNet[33]、BaseHomo[34]、HomoGAN[35]和文献[36]。
2.2 网络架构
2.2.1 基于CNN
大多数基于DL的单应性估计方法使用基于CNN的网络架构作为主干网络,从最早的基于DL的单应性估计[20],使用VGGNet[37]作为骨干,到最先进的方法[22,25,30],与传统的基于特征的方法相比具有更强的鲁棒性。在学习范式方面,无论使用有监督学习还是无监督学习,CNN强大的特征提取能力都是促进基于DL的单应性估计领域进步的原因。
2.2.2 基于CNN+Transformer
注意力是为了模仿人类感知的机制而建立的,主要集中在关注突出部分[28,29]。由于现有的单应性估计方法没有明确考虑跨分辨率问题,忽略了输入图像与特征之间对应关系的显式表述。为了解决此问题,Shao等人[38]提出了一种用于交叉分辨率单应性估计的监督Transformer。针对不同的任务,提出了一种具有局部注意力的Transformer。
2.2.3 基于GAN+Transformer
由于现有的单应性估计方法没有明确考虑平面诱导视差的问题,这将使预测的单应性在多个平面上被破坏。为了解决此问题,Hong等人[35]提出了一种专注于主导平面的基于无监督学习的单应性估计模型。针对不同的任务,提出了一种具有局部注意力的Transformer。
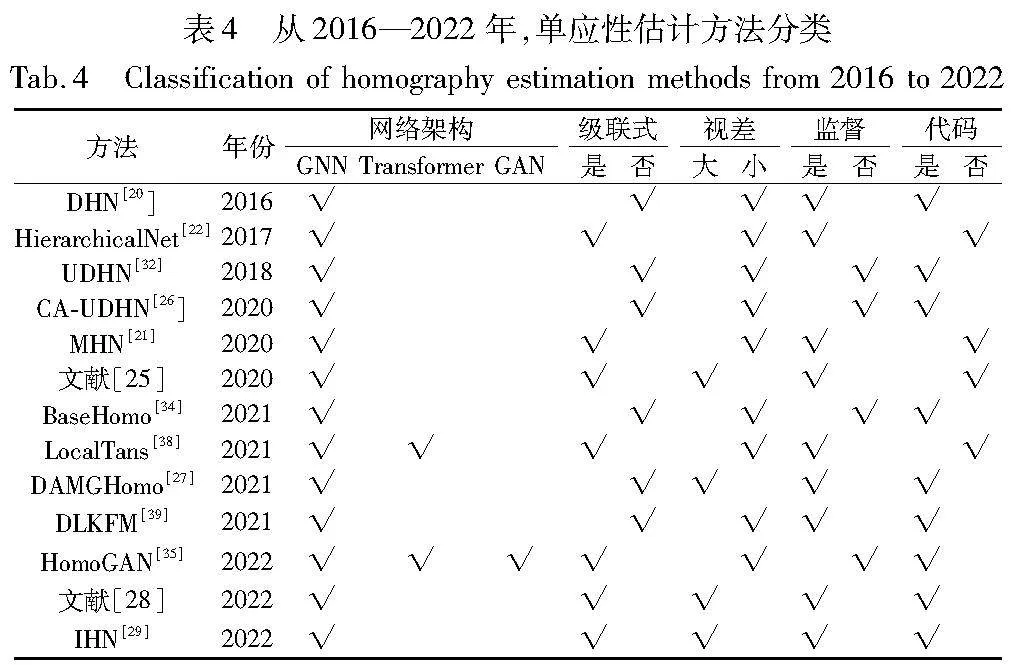
表4整理了2016—2022年DL单应性估计方法,根据有无真实标签可分为有监督和无监督两类,根据网络架构可分为基于CNN、基于Transformer与基于GAN的方法,还可根据网络架构是否级联与视图场景视差大小进行分类。
从经典方法[20,22]到先进的方法[29,35],大多数单应性估计方法都倾向于使用监督学习策略来训练其网络,但是人工注释很容易出错,导致注释质量不一致或包含受污染的数据,增加了构建数据集的复杂性和成本,而增加训练数据集以提高性能可能具有挑战性,并且合成图像中缺乏真实的场景视差,其泛化能力也受到限制,因此无监督方法逐渐被重视。
从表4可知,大部分网络都采用了基于CNN的方法在特征域上进行单应性估计,但是基于CNN的网络结构对于处理复杂问题适应性不是很强,没有明确考虑平面诱导视差问题,这将使预测的单应性在多个平面上受到影响。于是,逐渐引入了注意力机制与GAN来处理复杂问题。比如,HomoGAN提出了一种新的方法来引导无监督单应性估计集中在优势面上,设计了一个多尺度Transformer网络,以粗到精的方式从输入图像的特征金字塔中预测单应性。
2.3 经典单应性估计模型
2.3.1 首个有监督DL单应性网络
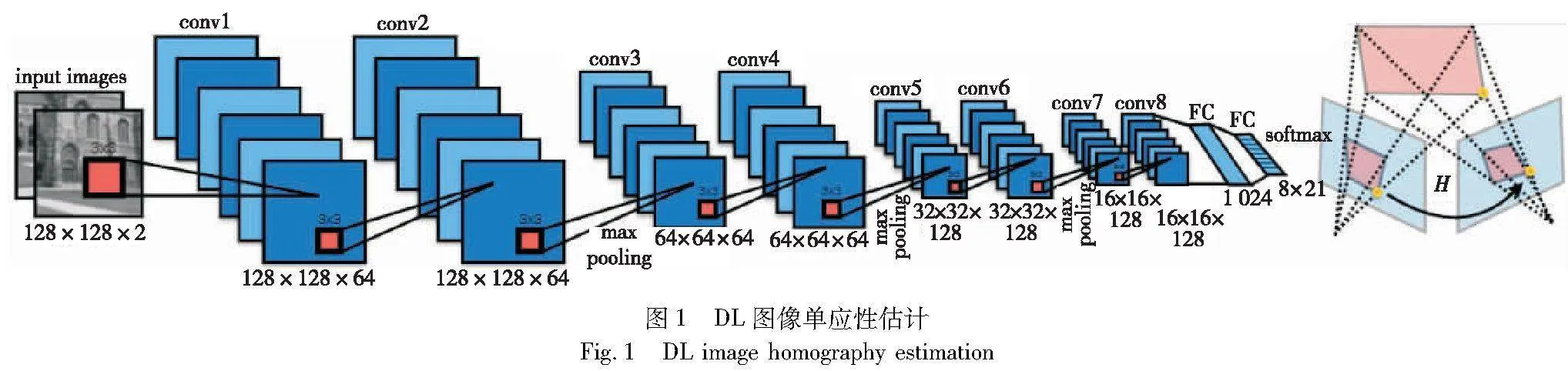
图1[20]是第一个有监督DL图像单应性估计结构。
该网络采用VGG作为主干网络,以两张堆叠的灰度图像作为输入,输出4点偏移量用于单应性矩阵求解,可用于将像素从第一张图像映射到第二张图像。该方法存在以下优点:a)无须单独的局部特征检测和转换估计RNNz2lO8Xror7iwsSFV/a+oU5Hqp4MlyxTJegSCtmsU=阶段;b)采用端到端的方式,缩减了人工预处理和后续处理,使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度;c)设计并实现了回归单应性网络与分类单应性网络。
该方法存在以下缺点:网络通过多层的卷积的叠加,整体架构比较简单,只能处理简单的一个平面到一个平面的单应性估计问题,因此算法适应性不强。
2.3.2 首个大基线深度单应性网络
如图2[25]所示,为了以灵活的学习方式拼接任意视图和输入大小的图像,Nie等人[25]提出了基于大基线DL单应性的边缘保留图像拼接学习方法,在一定程度上解决了固定视图和输入大小限制对单应性估计的影响。该方法存在以下优点:a)针对单应性估计算法适应性不强的问题,采用级联式网络,以更快的速度预测图像的单应性,具有更为复杂的网络结构,在复杂场景下具有更好的单应性估计效果;b)所提学习框架可以缝合任意视图和输入大小的图像,从而有助于在其他真实图像中表现出出色的泛化能力。该方法存在以下缺点:a)在图像拼接任务上的性能可能受到输入图像的特征点密度和分布的影响;b)在图像拼接的过程中,可能会出现边缘不连续的问题,需要进一步优化方法以解决上述问题。
2.3.3 跨分辨率DL单应性估计网络
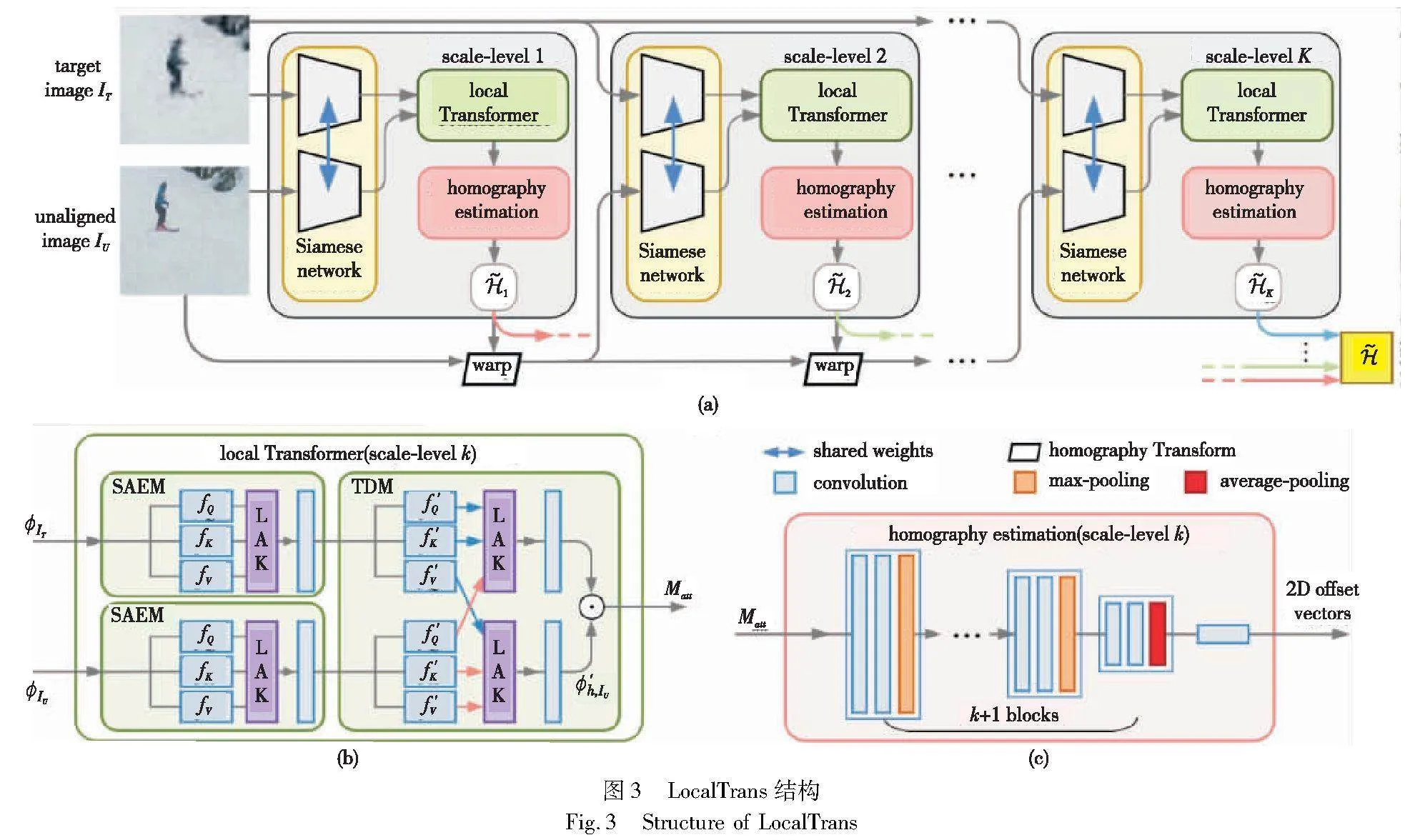
单应性估计可以输入包括不同分辨率的图像,如图3[38]所示。LocalTrans[38]在分辨率差距高达10倍的跨分辨率情况仍然下实现了卓越的性能。该方法将交叉分辨率单应性估计视为一个多模态问题,并提出了一个嵌入在多尺度结构中的局部变压器网络来显式学习多模态输入之间的对应关系。该方法存在以下优点:a)提了一种新颖的多尺度局部变换网络,为解决差分分辨率问题在同分辨率图像对齐中提供了有效的方法;b)通过将局部注意力核心(LAK)嵌入到多尺度结构中,从而能够在长短距离范围内捕捉对齐关系。该方法存在以下缺点:在真实场景的数据集上处理复杂场景时,其性能还待进一步探究。
3 基于DL的图像拼接
单应性估计是一个完整拼接算法里面的第一步,通过单应性估计[26,35,40]扭曲后得到配准后的图像,还需要将对齐后的图像进行拼接。由于这些扭曲中的大多数使用单应性正则化将扭曲平滑地外推到非重叠区域,所以不可避免地受到投影失真的影响而出现重影。为了消除拼接图像中的重影,已经提出了许多方法。根据是否进行接缝预测,将其分为非接缝缝合和接缝驱动缝合;根据学习策略可将其分为有监督方法与无监督方法。
3.1 拼接方式
3.1.1 非接缝缝合
融合重影是由单应矩阵不能完美地对齐两幅图像这一事实引起的,通过尽可能地将目标图像与参考图像对齐来消除重影。APAP[36]在图像中放置一个网格,并为每个网格估计局部单应变换模型。由于其优异的性能,该技术已被广泛应用于图像对齐。为了实现更好的对齐,Robust ELA[41] 结合了基于网格的模型和直接变形策略。为在低纹理环境保持良好的效果,Li等人[42]开发了一种双特征扭曲模型用于图像对齐,同时使用稀疏特征匹配和线对应。以上这些方法将图像划分为不同的区域,并计算每个不同区域的单应性矩阵。通过在这些区域上施加空间变化的扭曲,重叠区域被很好地对齐,重影显著减少。但是,非接缝拼接方法在小视差图像中表现良好,却很难处理大视差图像,这种方法会导致拼接图像不佳。
3.1.2 接缝缝合
接缝缝合通过研究缝合扭曲图像的最佳接缝来隐藏伪影。通过优化与接缝相关的成本,可以沿着接缝将重叠划分为两个互补区域,然后根据两个区域形成缝合图像来改善重影问题。接缝预测是接缝驱动拼接方法的基础,Cheng等人[43]提出了第一个基于DL的接缝预测方法,结合了接缝形状约束和接缝质量约束的选择性一致性损失来监督网络学习,将接缝预测转换为掩模预测。为了进一步保持宽视差条件下的图像结构,LPC[44]提出了一种利用线点一致性度量的接缝匹配策略。Liao等人[45]提出了一种新的迭代接缝估计方法,使用混合质量评价方法来评价接缝沿线的像素,接缝与之前的接缝相比发生了可以忽略不计的变化时,迭代完成,但在大视差时可能会失败。Gao等人[5]提出选择具有最高感知质量的接缝来评估单应性逆变换。Zhang等人[46] 提出了一种处理视差的局部拼接方法,仅从大致对齐的图像中估计合理的接缝。ACIS[47]提出了一种四元数秩1对齐(QR1A)模型,同时学习最优接缝线和局部对齐。Lin等人[48]提出了一种接缝引导的局部对齐方法,该方法根据与当前接缝的距离自适应特征加权迭代地改进扭曲。Nie等人[7]提出了基于DL的接缝拼接,通过无监督学习无缝合成拼接图像,但是存在边界不清晰、生成的掩码不连续等问题。
3.2 学习策略
3.2.1 有监督
随着DL的快速发展,以大数BXWNAfbmen2HnTuLPaRYfg==据驱动的有监督学习在众多计算机视觉课题中得到了广泛研究,然而,DL图像拼接技术仍处于发展阶段。Nie等人[30]提出了一种基于全局单应性的视角自由的图像拼接网络,其首次在完整的DL框架中成功拼接了任意视图的图像,能够处理从任意视图捕获的图像,并且它可以尽可能地消除重影效应,但存在输入规模固定、泛化能力弱的局限性。
3.2.2 无监督
在实际场景中,每个图像域都有可能包含多个不同的深度层次,这与单应性的平面场景假设相矛盾。由于单一的单应性不能解释不同深度级别的所有对齐,所以在缝合结果中经常存在重影效应。为了解决此问题,Nie等人[7]首次提出了无监督DL图像拼接,重建图像拼接特征,并认为重建拼接特征比重建像素级拼接图更容易,随后拼接特征被用来重建出拼接图。2023年Nie等人[6]在之前的研究基础上提出了用于无监督视差DL拼接的薄板样条线运动学习来无缝合成图像,该算法通过对齐和失真的联合优化,实现了重叠区域的精确对齐和非重叠区域的形状保持。
考虑到现有基于DL的拼接算法研究较少,本文在表5中总结了2013—2023年一些经典的图像拼接方法(包括传统图像拼接方法与基于DL的图像拼接方法),根据有无真实标签可分为有监督和无监督两类,根据网络架构可分为基于CNN、基于图卷积网络(GCN)与基于其他的方法 ,并根据拼接方式、与视图场景视图大小进行分类。由表5可知,流行的图像拼接方法[6~7,30,43]主要在于解决图像重影问题。这些方法的最终目的都是通过一系列变化,使图像更好地对齐,以缓解重影问题。
3.3 经典图像拼接模型
3.3.1 首个无监督像素级重建拼接网络
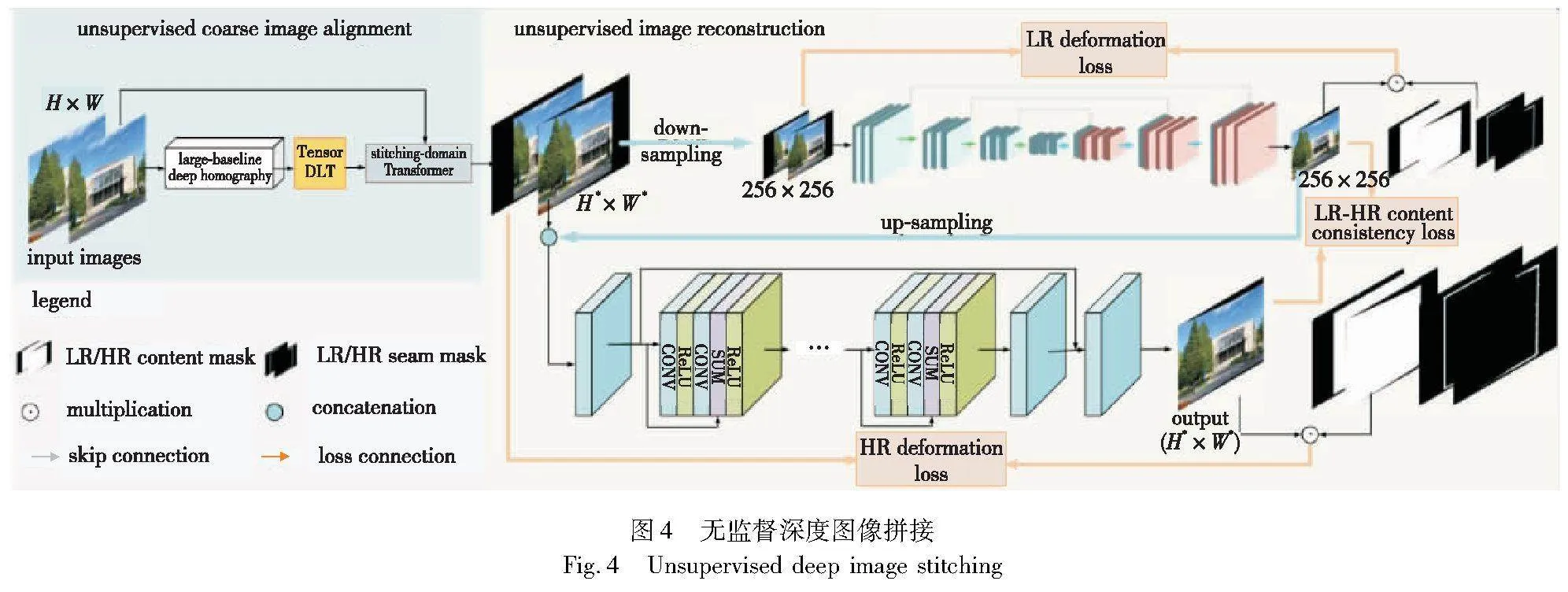
Nie等人[7]发现,重建拼接特征比重建像素级拼接图更容易,因此提出了一个无监督深度图像拼接的方法,通过设计一个无监督图像重建网络,来消除从特征到像素的伪影,如图4[7]所示。
方法存在以下优点:a)通过特征域融合的方式,一定程度上消除了由于单应性估计不完全对齐导致的拼接后的图像存在的重影问题;b)使用无监督的方式,在首个真实场景下的图像拼接数据集上进行单应性估计与图像拼接任务,并取得了很好的效果。该方法存在以下缺点:a)在图像拼接过程中,对于低分辨率变形分支中,使用的编码器与解码器过于简单,如果使用更复杂的网络结构或许能增强图像拼接的效率与效果;b)对于高分辨率精细分支,网络始终处理高分辨率图像,严重影响了处理速度,为了提高性能,可以对模型进行改进,比如先卷积缩放后的图片,或者更换效果更好的网络;c)在极大偏斜的场景中,因为重建能力有限,重建网络可能会失败。
3.3.2 基于DL的无监督接缝拼接网络
传统的拼接算法通常使用基于网格的多单应性方案[36],但它不能有效地并行加速,这意味着它不能用于DL框架[11]。为了克服这个问题,如图5[6]所示,Nie等人[6]利用TPS变换[53]来实现有效的局部变形。该算法通过对齐和失真的联合优化,实现了重叠区域的精确对齐和非重叠区域的形状保持。如图5所示,该方法存在以下优点:a)通过无监督学习对接缝驱动的合成掩模进行无缝合成,完全消除了由于单应性估计不完全对齐导致的拼接后的图像存在的重影问题;b)引入了TPS策略进行扭曲点控制,替代了传统的效率低下的多重单应性扭曲方式,同时保证了全局线性变换与局部非线性变形,实现了图像与视差对齐。
该方法存在以下缺点:a)在图像拼接过程中,缺少基于DL接缝的评价指标及定义;b)只是采用了简单的U-Net进行接缝掩码生成,缺乏对更为精细化的网络对结果影响的探讨;c)缺乏对最优接缝定义的探讨;d)缺乏对非二值掩码接缝质量评价的探讨。
3.3.3 多光谱图像拼接网络
如图6[52]所示,该方法实现了多视图场景的多谱图像之间的拼接,提出了一种基于空间图推理的多光谱图像拼接方法,首次将图卷积网络引入多光谱交叉视图对齐和集成的关系建模中。该方法存在以下优点:a)通过空间图推理方法有效地整合多光谱图像,生成宽视场图像;b)通过探讨多光谱关系并利用图卷积网络,提高了多视角对齐和整合的性能;c)通过引入长距离纵横一致性来提高空间和通道维度上的上下文感知,有助于多视角场景的整合和多光谱图像的融合。
该方法存在以下缺点:a)由于在图像重构过程中考虑到多光谱图像信息,生成的宽视场图像可能会呈现较低的鲜艳度;b)与可见光图像相比,红外图像的引入可能导致生成的结果中的噪声降低。
4 基于DL的图像矩形化
图像矩形化是图像拼接的后处理任务,图像拼接后难以避免地会存在边界不规则、边界缺失等情况,图像矩形化技术则是在不引入任何额外的虚假内容信息,只是在原始内容信息的基础上通过网格畸变将拼接后的图像扭曲成矩形图像。在矩形化过程中,采用网格局部扭曲的方法,通过对网格形变实现矩形化效果。根据扭曲的方式不同,此过程可以分为一阶段扭曲与两阶段扭曲。
4.1 扭曲方式
4.1.1 两阶段
He等人[19]提出两阶段优化保线网格变形。然而,所提出的能量函数只能保留线性结构。考虑到直线可能在全景图(ERP格式)中弯曲,Li等人[18]将保线能量项改进为保测地线能量项,但是这种改进限制了它在全景图中的应用,并且测地线不能直接从拼接图像中检测到。Zhang等人[17]在统一优化中桥接了图像矩形化和图像拼接,但为了减少最终矩形结果的失真,他们对矩形形状作出了妥协,转而采用分段矩形边界约束。
4.1.2 一阶段
Nie等人[14]提出了一个简单但有效的一阶段学习基线,通过DL的方法来解决图像在非线性对象的肖像和风景上存在明显的失真问题,相较于两阶段,性能明显提升。Liao等人[54]提出了一种方法来约束矩形图像的非线性和非刚性变换,在内容与边界上实现了鱼眼图像矩形化,但其边界存在模糊现象。图9(a)展示了传统的基于两阶段扭曲的图像矩形化基线[19],图9(b)展示了基于DL的一阶段扭曲图像矩形化基线[11]。
考虑到现有基于DL的图像矩形化研究刚刚起步,因此在表6中总结了2013—2022年来一些经典的图像矩形化方法(包括传统方法图像矩形化方法与基于DL的图像矩形化方法),根据有无真实标签可分为有监督和无监督两类,并根据矩形化方式、扭曲阶段进行分类。
4.2 经典图像矩形化模型
4.2.1 首个有监督图像矩形化网络
目前的图像矩形化研究均为有监督学习的,尚无基于无监督学习的图像矩形化研究。图7[11]所示为首个有监督DL矩形化体系结构,通过一阶段多扭曲的方式对网格进行扭曲,从而保证内容的完整性以及边界的规则化。此方法存在以下优点:a)该方法通过扭曲的方式进行矩形化,因此不会引入与图片信息不符合的内容;b)提出了一种由边界项、网格项和内容项组成的综合目标函数,保证在非线性场景中也具有良好的性能。此方法存在以下缺点:使用残差渐进回归策略在一定程度上会增加模型学习的负担。
4.2.2 鱼眼矩形化网络
图8[54]展示了在广角镜头下的矩形校正网络(RecRecNet)架构,将拼接后的广角不规则图像通过一系列变形方式,扭曲为规则的矩形化图片。该方法存在以下优点:a)通过使用基于8-DoF(8-自由度)的课程来学习逐渐变形规则,在最终的矩形任务上提供快速收敛;b)通过一个薄板样条(TPS)模块来制定矩形图像的非线性和非刚性变换,在非线性场景下也实现了良好的效果,具有良好的场景泛化能力。该方法存在以下缺点:a)在训练过程中,RecRecNet可能需要大量的数据来学习复杂的结构逼近任务;b)DoF-based(基于自由度)课程学习可能在其他领域的应用中需要对课程结构进行调整以适应新的任务需求;c)在某些情况下,RecRecNet 可能需要更多的训练时间来学习更复杂的变形规则。
4.2.3 首个端到端矩形化集成网络
RDISNet方法不同于以往的图像矩形化方法,而是通过端到端的方式,在学习颜色一致性和保持内容真实性的同时,直接将两幅图像拼接成一个标准的矩形图像,如图9[55]所示。该方法存在以下优点:a)设计了一个扩大RDISNet接收场景的扩展的BN-RCU模块,以维护拼接图像中大物体的结构特征;b)RDISNet是首次将图像拼接和矩形处理整合成一个端到端的过程,同时学习图像对的颜色一致性。该方法存在以下缺点:a)可能无法完全涵盖自然图像中的丰富内容信息;b)由于该算法是在合成数据集上进行的实验,所以在真实数据集上可能会出现一定程度的失真;c)在处理大偏斜角度的图像时,可能无法完全保留图像的内容和真实性;d)在处理具有不同光照条件的图像时,可能会出现白边,从而影响模型的性能。
5 数据集汇总
由于应用场景的不同,图像拼接数据集的构建方式也各异。有的需要人工标注(如在有监督单应性估计训练中标注配对图像之间的相对位置关系),有的需要剔除不满足要求的图像(如在图像矩形化中标签的标注需要剔除严重形变图像)。为了便于学者的研究,本文整理了近些年来在基于DL的图像拼接领域研究中的相关数据集(单应性估计、图像拼接、图像矩形化常用的数据集),如表7所示。
6 结束语
1)研究总结
本文梳理了图像拼接研究领域的三个重要分支(单应性估计、图像拼接/融合、图像矩形化)的相关研究进展。在对比分析各个分支研究中传统算法与基于DL算法各自的优劣情况后,就基于DL的图像拼接研究进行了进一步细化整理。探究了其在单应性估计、图像拼接、图像矩形化三个分支研究中的方法分类、经典网络回顾以及当前所存在的问题。最后,本文还整理了相关的数据集,以便为该领域的研究提供指导。具体来说,本文的研究总结如下:
a)本文对比分析了图像拼接中多个研究分支中传统算法与基于DL的算法之间的各自优缺点,发现基于DL的算法在低纹理、低光照等场景具有更好的性能表现。此外,在运行速度等方面也具有一定的优势,具有较好的研究前景。
b)本文整理分析了各个研究分支中的模型设计出发点(如是否使用监督学习、网络架构设计、适用场景等)及一些经典网络的优缺点,为图像拼接领域后续研究工作的进一步开展提供了参考。
c)本文整理了各项算法的代码开源情况,数据集使用情况等相关信息,为该领域的研究提供了指导方向。
d)单应性估计研究主要采用4点偏移量预测的方法进行网络设计;单应性估计网络主要以级联网络的方式进行设计,可以实现4点偏移量的逐步回归,取得了较好的性能表现,但是存在响应效率问题;掩码模块的设计可解决含有运动物体的场景对齐;局部网格扭曲具有较好的对齐表现,但是存在一定的形变失真问题。
e)图像拼接/融合研究主要可分为特征级融合重构和接缝掩码拼接两种方式。像素级融合可一定程度消除在单应性估计中带来的重影错位问题,但会造成一定的模糊现象且不能完全解决该问题;接缝掩码拼接的方式取得了较好的视觉感知表现,但是最优接缝的度量仍有所缺陷。
f)图像矩形化研究可解决图像拼接带来的边界不规则问题。目前基于DL的研究刚刚起步,仅存在有监督学习方式的矩形化网络,无监督网络仍有待探索。此外,矩形化结果仍存在少许的局部断线等问题有待被解决。
2)未来挑战
作为计算机视觉的一项至关重要的任务,图像拼接在过去的几十年中得到了广泛的研究。将DL技术引入图像拼接领域,带来了图像拼接相关研究的再一次繁荣,但是同时它也带来了一些新的挑战。具体如下:
a)多模态图像拼接以及在交叉任务上应用图像拼接技术的研究刚刚兴起,仍有待进一步更近,以便更好地挖掘图像拼接的潜在价值。
b)在单应性估计过程中,级联式网络的设计具有逐步回归的好处,但是当级联层数达到一定阈值后,网络性能将变得不稳定,其内在原理仍不明朗。
c)现有基于DL的图像拼接技术主要采用了全局单应性和规则网格的局部单应性进行图像配准工作,但是由于图像存在景深的差异,在配准过程中往往难以实现重叠区域的全部像素对齐。此外,规则网络并不能充分地在不同景深进行对齐。探索超像素分割的不同景深对齐方法仍有待开展。
d)当前的图像拼接研究主要集中于成对图像之间的拼接研究工作,对于多幅图像之间的拼接仍主要采用逐步堆叠的方式,这不可避免会带来累积误差的问题。因此,探索多幅图像之间的全局最佳对齐位置的配准研究仍有待跟进。
e)当前的图像拼接研究主要侧重于单一视觉任务,如大视差、运动图像配准等研究,目前尚无统一框架的出现。探索图像拼接的通用框架的研究仍有待开展。
f)一个实用拼接算法不仅应考虑其配准及拼接性能表现,还应从算法的可移植性、运行速率、资源占用量以及轻量化的移动端表现等方面进行综合度量。因此,在后续研究中可从多个方面进行整体度量。
g)图像矩形化任务主要以内容保真的形式拉伸图像以得到规则的图形边界,可以解决扭曲失真并避免生成网络所带来的伪信息,其潜在价值及更多的应用场景仍有待进一步探究。
h)能够一步实现图像拼接三个子任务的端到端的网络仍有待被进一步探究,以解决现有网络参数量庞大、运行效率低等问题。
参考文献:
[1]Li Desheng, He Qian, Liu Chunli, et al. Medical image stitching using parallel sift detection and transformation fitting by particle swarm optimization[J]. Journal of Medical Imaging and Health Informatics, 2017,7(6): 1139-1148.
[2]Li Jia, Zhao Yifan, Ye Weihua, et al. Attentive deep stitching and quality assessment for 360°omnidirectional images[J]. IEEE Journal of Selected Topics in Signal Processing, 2019,14(1): 209-221.
[3]Wang Lang, Yu Wen, Li Bao. Multi-scenes image stitching based on autonomous driving[C]//Proc of the 4th IEEE Information Technology, Networking, Electronic and Automation Control Conference. Piscataway, NJ: IEEE Press, 2020: 694-698.
[4]Anderson R, Gallup D, Barron J T, et al. Jump: virtual reality video[J]. ACM Trans on Graphics, 2016,35(6): 1-13.
[5]Gao Junhong, Li Yu, Chin T J, et al. Seam-driven image stitching[EB/OL]. (2013). https://api.semanticscholar.org/CorpusID:18578917.
[6]Nie Lang, Lin Chunyu, Liao Kang, et al. Parallax-tolerant unsupervised deep image stitching[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2023: 7365-7374.
[7]Nie Lang, Lin Chunyu, Liao Kang, et al. Unsupervised deep image stitching: reconstructing stitched features to images[J]. IEEE Trans on Image Processing, 2021,30: 6184-6197.
[8]Dong Chao, Loy C C, He Kaiming, et al. Learning a deep convolutional network for image super-resolution[C]//Proc of the 13th European Conference on Computer Vision. Cham: Springer, 2014: 184-199.
[9]Liu Ze, Lin Yutong, Cao Yue, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 9992-10002.
[10]Szeliski R. Image alignment and stitching: a tutorial[J]. Foundations and Trends in Computer Graphics and Vision, 2007, 2(1):1-104
[11]Adel E, Elmogy M, Elbakry H. Image stitching based on feature extraction techniques: a survey[J].International Journal of Compu-ter Applications, 2014,99(6): 1-8.
[12]Lyu Wei, Zhou Zhong, Lang Chen, et al. A survey on image and video stitching[J].Virtual Reality & Intelligent Hardware, 2019,1(1): 55-83.
[13]Liao Kang, Nie Lang, Huang Shujuan, et al. Deep le1dfd02c7be1e12f2501b56f79281697905e57853cc110e7756d7b12d24aff934arning for ca-mera calibration and beyond: a survey[EB/OL]. (2023-03-19). https://arxiv.org/abs/2303.10559.
[14]Nie Lang, Lin Chunyu, Liao Kang, et al. Deep rectangling for image stitching: a learning baseline[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5730-5738.
[15]Krishnan D, Teterwak P, Sarna A, et al. Boundless: generative adversarial networks for image extension[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 10520-10529.
[16]Suvorov R, Logacheva E, Mashikhin A, et al. Resolution-robust large mask inpainting with Fourier convolutions[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision.Pisca-taway, NJ: IEEE Press, 2022:3172-3182.
[17]Zhang Yun, Lai Y K, Zhang F L. Content-preserving image stitching with piecewise rectangular boundary constraints[J].IEEE Trans on Visualization and Computer Graphics, 2020,27(7): 3198-3212.
[18]Li Dongping, He Kaiming, Sun Jian, et al. A geodesic-preserving method for image warping[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2015: 213-221.
[19]He Kaiming, Chang Huiwen, Sun J. Rectangling panoramic images via warping[J].ACM Trans on Graphics, 2013,4(32):1-10.
[20]Detone D, Malisiewicz T, Rabinovich A. Deep image homography estimation[EB/OL]. (2016-06-13). https://arxiv.org/abs/1606.03798.
[21]Le H, Liu Feng, Zhang Shu, et al. Deep homography estimation for dynamic scenes[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 7649-7658.
[22]Nowruzi F E, Laganiere R, Japkowicz N. Homography estimation from image pairs with hierarchical convolutional networks[C]//Proc of IEEE International Conference on Computer Vision Workshops. Piscataway, NJ: IEEE Press, 2017: 904-911.
[23]Wang Xiang, Wang Chen, Bai Xiao , et al. Deep homography estimation with pairwise invertibility constraint[C]//Proc of Joint IAPR International Workshop on Structural, Syntactic, and Statistical Pattern Recognition. Cham: Springer, 2018: 204-214.
[24]Chang Jiaren, Chen Yongsheng. Pyramid stereo matching network[C]//Proc of IEEE Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press,2018: 5410-5418.
[25]Nie Lang, Lin Chunyu, Liao Kang, et al. Learning edge-preserved image stitching from large-baseline deep homography[EB/OL]. (2020-12-11). https://arxiv.org/abs/2012.06194.
[26]Zhang Jirong, Wang Chuan, Liu Shuaicheng, et al. Content-aware unsupervised deep homography estimation[EB/OL]. (2020-07-20). https://arxiv.org/abs/1909.05983.
[27]Nie Lang, Lin Chunyu, Liao Kang, et al. Depth-aware multi-grid deep homography estimation with contextual correlation[J]. IEEE Trans on Circuits and Systems for Video Technology, 2022, 32(7): 4460-4472.
[28]Jiang Hai, Li Haipeng, Lu Yuhang, et al. Semi-supervised deep large-baseline homography estimation with progressive equivalence constraint[C]//Proc of AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press, 2023: 1024-1032.
[29]Cao S Y, Hu Jianxin, Sheng Zehua, et al. Iterative deep homography estimation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 1869-1878.
[30]Nie Lang, Lin Chunyu, Liao Kang, et al. A view-free image stitching network based on global homography[J].Journal of Visual Communication and Image Representation, 2020,73: 102950.
[31]Zhao Yajie, Huang Zeng, Li Tianye, et al. Learning perspective undistortion of portraits[C]//Proc of IEEE/CVF International Confe-rence on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 7848-7858.
[32]Nguyen T, Chen S W, Shivakumar S S, et al. Unsupervised deep homography: a fast and robust homography estimation model[J].IEEE Robotics and Automation Letters, 2018,3(3): 2346-2353.
[33]朱永, 付慧, 唐世华, 等. RISNet: 无监督真实场景图像拼接网络[J]. 计算机应用研究, 2023, 40(9): 2856-2862. (Zhu Yong, Fu Hui, Tang Shihua, et al. RISNet: unsupervised real scene image stitching network[J]. Application Research of Computer, 2023,40(9): 2856-2862.)
[34]Ye Nianjin, Wang Chuan, Fan Haoqiang, et al. Motion basis lear-ning for unsupervised deep homography estimation with subspace projection[C]//Proc of IEEE/CVF International Conference on Compu-ter Vision. Piscataway, NJ: IEEE Press, 2021: 13097-13105.
[35]Hong Mingbo, Lu Yuhang, Ye Nianjin, et al. Unsupervised homo-graphy estimation with coplanarity-aware GAN[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2022: 17642-17651.
[36]Zaragoza J, Chin T J, Tran Q H, et al. As-projective-as-possible image stitching with moving DLT[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2014,36(7): 1285-1298.
[37]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10). https://arxiv.org/abs/1409.1556.
[38]Shao Ruizhi, Wu Gaochang, Zhou Yuemei, et al. LocalTrans: a multiscale local transformer network for cross-resolution homography estimation[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 14870-14879.
[39]Zhao Yiming, Huang Xinming, Zhang Ziming. Deep Lucas-Kanade homography for multimodal image alignment[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 15945-15954.
[40]Liu Shuaicheng, Ye Nianjin, Wang Chuan, et al. Content-aware unsupervised deep homography estimation and its extensions[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2022, 45(3): 2849-2863.
[41]Li Jing, Wang Zhengming, Lai Shiming, et al. Parallax-tolerant image stitching based on robust elastic warping[J]. IEEE Trans on Multimedia, 2018, 20(7): 1672-1687.
[42]Li Nan, Xu Yifang, Wang Chao. Quasi-homography warps in image stitching[J]. IEEE Trans on Multimedia, 2018, 20(6): 1365-1375.
[43]Cheng Senmao, Yang Fan, Chen Zhi, et al. Deep seam prediction for image stitching based on selection consistency loss[EB/OL]. (2023-06-26). https://arxiv.org/abs/2302.05027.
[44]Jia Qi, Li Zhengjun, Fan Xin, et al. Leveraging line-point consistence to preserve structures for wide parallax image stitching[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2021: 12181-12190.
[45]Liao Tianli, Chen Jing, Xu Yifang. Quality evaluation-based iterative seam estimation for image stitching[J].Signal, Image and Video Processing, 2019,13: 1199-1206.
[46]Zhang Fan, Liu Feng. Parallax-tolerant image stitching[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2014: 3262-3269.
[47]Li Jiaxue, Zhou Yicong. Automatic color image stitching using quaternion rank-1 alignment[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 19688-19697.
[48]Lin Kaimo, Jiang Nianjuan, Cheong L F,et al. SEAGULL:seam-guided local alignment for parallax-tolerant image stitching[C]//Proc of the 14th European Conference on Computer Vision. Cham:Springer, 2016: 370-385.
[49]Li Shiwei, Yuan Lu, Sun Jian, et al. Dual-feature warping-based motion model estimation[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2015: 4283-4291.
[50]Lin C C, Pankanti S U, Ramamurthy K N, et al. Adaptive as-natural as-possible image stitching[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2015: 1155-1163.
[51]Zhang Guofeng, He Yi, Chen Weifeng, et al. Multi-viewpoint panorama construction with wide-baseline images[J]. IEEE Trans on Image Processing, 2016, 25(7): 3099-3111.
[52]Jiang Zhiying, Zhang Zengxi, Liu Jinyuan, et al. Multi-spectral image stitching via spatial graph reasoning[C]//Proc of the 31st ACM International Conference on Multimedia. New York:ACM Press, 2023:472-480.
[53]Bookstein F L. Principal warps: thin-plate splines and the decomposition of deformations[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 1989,11(6): 567-585.
[54]Liao Kang, Nie Lang, Lin Chunyu, et al. RecRecNet: rectangling rectified wide-angle images by thin-plate spline model and DoF-based curriculum learning[EB/OL]. (2023-09-05). https://arxiv.org/abs/2301.01661.
[55]Zhou Hongfei, Zhu Yuhe, Lyu Xiaoqian, et al. Rectangular-output image stitching[C]//Proc of IEEE International Conference on Image Processing. Piscataway, NJ: IEEE Press, 2023: 2800-2804.
[56]Xiao Jianxiong, Ehinger K A, Oliva A, et al. Recognizing scene viewpoint using panoramic place representation[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2012: 2695-2702.
[57]Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: common objects in context[C]//Proc of the 13th European Conference on Computer Vision. Cham :Springer, 2014: 740-755.
[58]Huang P H, Matzen K, Kopf J, et al. DeepMVS: learning multi-view stereopsis[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 2821-2830.
[59]Weyand T, Araujo A, Cao Bingyi, et al. Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 2572-2581.
[60]Caesar H, Bankiti V, Lang A H, et al. nuScenes: a multimodal dataset for autonomous driving[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 11618-11628.
