
基于因果推断的两阶段长尾分类研究
2024-08-13 00:00:00曹小敏刘进锋
郑州大学学报(理学版) 2024年5期


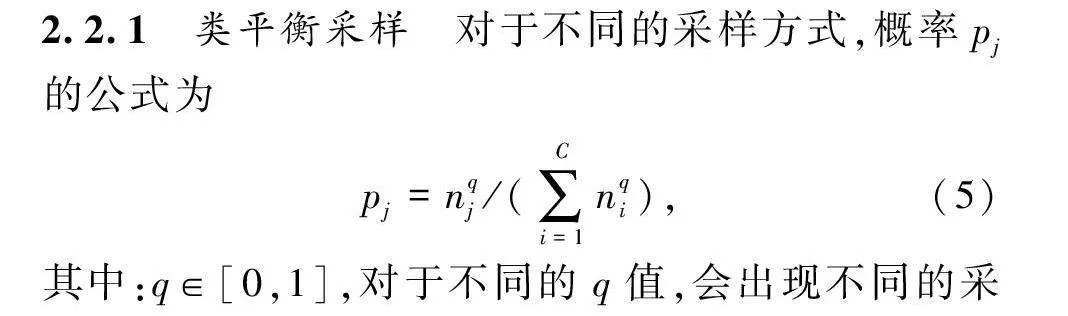







摘要: 为了解决数据的长尾分布容易造成网络模型识别准确度下降的问题,提出了一种基于因果推断的两阶段长尾分类模型。首先采用重加权的方法去除特征和标签之间可能存在的虚假关联;其次通过平衡微调进一步提升模型在少样本尾部类别识别的准确率。模型可分为两个阶段:第一阶段设计了具有迭代优化效果的去相关样本重加权算法以去除虚假相关,达到稳定预测的效果;第二阶段设计了基于CAM的类平衡采样算法进行平衡微调训练,使来自不平衡数据集的学习特征在所有类别之间转移和重新平衡,以提高模型在尾部类别的分类性能。实验结果证明了模型具有较优的性能,同时,无论从理论层面还是数据层面都具有较好的可解释性。
关键词: 长尾分布; 因果推断; 去相关; 类平衡采样; 可解释性
中图分类号: TP391
文献标志码: A
文章编号: 1671-6841(2024)05-0031-08
DOI: 10.13705/j.issn.1671-6841.2023122
A Study of Two-stage Long-tail Classification Based on Causal Inference
CAO Xiaomin, LIU Jinfeng
(College of Information Engineering, Ningxia University, Yinchuan 750021,China)
Abstract: In order to solve the problem caused by long-tail distribution of data, which might decrease network model recognition accuracy to decrease, a two-stage long-tail classification model based on causal inference was proposed. Firstly, a re-weighting approach in the model was used to remove possible spurious associations between features and labels, and secondly the recognition accuracy of the model in tail categories with fewer samples was improved by balancing fine-tuning. The model was divided into two stages. In the first stage, a de-correlated sample reweighting algorithm with iterative optimization effect was designed to remove spurious correlation and achieve stable prediction; in the second stage, a CAM-based class balancing sampling algorithm was designed for balancing fine-tuning training, so that the learned features from unbalanced datasets were transferred and rebalanced among all classes to improve the classification performance of the model in the tail category. The experiments proved that the model had superior performance. Meanwhile, compared with other model, this model had better interpretability from the theoretical level as well as the data level.
Key words: long-tail distribution; causal inference; removal related; class balance sampling; interpretable
0 引言
近年来,随着大规模图像数据集在深度神经网络(deeps neural networks,DNN)上的广泛应用,使得计算机在识别、监控和跟踪目标方面超越人类成为可能[1]。在计算机视觉研究中,通常假设数据集的分布是均衡的,例如ImageNet-2012[2]、MS COCO[3]和Places Dataset[4]。而在实际应用中,数据集通常呈长尾分布,即少数类别(又称头类)包含大量样本,而大多数类别(又称尾类)只有非常少量的样本。许多标准高效的DNN在这种分布下训练时,呈现在头类中表现良好,而在尾类中表现不佳,从而导致整体识别精度显著下降。缓解此类问题的主要方法为非平衡学习策略,主要包含数据级策略和算法级策略两类。数据级策略主要包括各种类型的重采样方法;算法级策略着重调整各个类别的权重,引导网络对尾类给予更多的关注。除此之外,将头类数据中学习到的知识转移到尾类中也是一种行之有效的方法。
因果推断是用于解释分析的强大建模工具,可以帮助恢复数据中的因果关联,实现可解释的稳定预测,且因果关系也能为模型提供较强的可解释性。因此,本文结合因果推断理论缓解长尾分布数据分类问题。因果推断中的去相关样本重加权方法能够去除样本标签和特征之间的虚假相关,使模型更注重样本标签与特征之间的真正联系,避免混杂因素对模型的影响,这样不仅提升了模型的识别准确率,加强模型预测时的稳定性,同时具有较好的可解释性。
本文提出了一种基于因果推断的两阶段长尾分类模型,该模型第一阶段采用改进后的去相关样本加权的方法进行不平衡训练,以去除样本标签和特征之间的虚假相关;第二阶段针对第一阶段不平衡训练在尾类上识别精度较差的缺点,采用重采样方法进行平衡微调训练。
1 相关工作
1.1 传统方法
解决长尾分布数据的传统方法主要有重采样和重加权两类。重采样即重新采样数据集以实现更均衡的数据分布,这类方法包括对少数类进行过采样[5](通过添加数据副本)、对多数类进行欠采样[6](通过移除数据),以及基于每类样本数量的类平衡抽样[7-8]。有学者对重采样的方法进行改进或与其他方法相结合,获得了优于单一重采样方法的性能,比如Zhou等[9]提出了一个统一的双边分支网络(bilateral branch network, BBN),该网络同时负责表征学习(此分支利用原始数据学习)和分类学习(此分支利用重采样学习),以全面提高长尾任务的识别性能。Kang等[10]将实例平衡采样与分类器相结合,发现使用最简单的实例平衡采样学习到的表示,可以通过调整分类器来实现较强的长尾识别能力。
重加权方法的主要思想是给不同类别分配不同的权重,引导网络对少数类别给予更多的关注,实际上是调整了每个类别的损失在总损失中的占比,缓解了因长尾分布导致的梯度占比失衡。Gui等[11]设计了一个重新加权方案,其利用每个类别的有效样本数来重新平衡损失,从而产生类别平衡损失。Cao等[12]设计了一种两步训练方法,第一步只用基于理论原则的标签分布感知边际损失(label-distribution-aware margin loss, LDAM)进行训练,取代训练过程中标准的交叉熵损失;第二步加上了传统重加权操作。这种方法将重新加权置于初始阶段之后,允许模型学习初始表示,同时避免与重新加权、重新抽样相关的一些并发问题。
传统方法有较优的分类性能,但其可解释性较差,这限制了深度学习方法的应用领域。
1.2 因果推断方法
因果推断是研究如何更加科学地识别变量之间的因果关系。因果推断要求原因先于结果,原因与结果同时变化或者相关,结果不存在其他可能的解释,强调原因的唯一性。Pearl等[13]提出了“因果之梯”的概念,自下而上将问题划分为关联、干预和反事实,分别对应于观察、行动和想象。对于这三个层次,因果推断的方法主要包括重加权方法、分层方法、基于匹配方法、基于树方法、基于表示方法、基于多任务学习方法以及元学习方法[14]。
在平衡分布数据分类任务中,基于因果推断的方法展示了其优势。Kuang等[15]提出了一种去相关加权回归DWR算法,该算法联合了优化变量去相关正则化模型和加权回归模型。Shen等[16]提出了一种新的因果正则化逻辑回归CRLR算法,全局混杂因子平衡有助于识别因果特征,在不同域之间,这些因果特征对结果的影响具有稳定性,然后对这些因果特征进行逻辑回归,构建一个针对不可知性的鲁棒预测模型,其可解释性可以通过特征可视化得到充分描述。Li等[17]将因果分类用于一组个性化决策问题,并将其与分类进行区分,讨论了通过增强型因果异质性建模方法解决因果分类的条件,同时还提出了一个因果分类的一般框架,使用现有的监督方法进行灵活运用。
虽然在平衡分布数据分类任务中,因果推断方法优势明显,但将其应用于长尾分布数据分类任务中会存在尾部类别分类精度较差的问题,从而影响整体分类精度。
2 基于因果推断的两阶段长尾分类模型
2.1 去相关样本重加权算法及改进
在实际应用中,不能保证未知测试数据与训练数据具有相同的分布。如果利用训练数据中存在的特征之间的偏差关系来改进预测,就会导致参数估计的不准确性以及与不同分布数据集之间预测的不稳定性。因此导致模型精度下降的主要原因是不相关特征和类别标签之间的虚假相关。去相关样本重加权方法[15]的目标是去除特征之间的虚假相关,本质是通过对样本进行全局加权,直接对每个输入样本的所有特征进行去相关以解决分布偏移问题,去相关样本加权方法首先利用卷积神经网络(convolutional neural network,CNN)进行特征提取,然后开始去相关的样本重加权,以此来消除特征之间的线性、非线性依赖关系,再利用最终损失对分类网络进行优化并进行图片分类。所用公式为
wb=argminw∑pj=1‖E[XTj∑wX-j]-E[XTjw]E[XT-jw]‖22,(1)
其中:w为样本权重;wb表示最终学习到的样本权重;∑w=diag(w1,w2,…,wn)和∑ni=1wi=n是权重对应的对角矩阵,n表示样本量;X表示变量集合(为n维行矩阵),X-j=X\{Xj}表示通过删除变量集合X中第j个变量所得到的所有剩余变量;p表示变量的位数。
通过样本重加权使X中的变量互不相干,从而减少训练环境中协变量之间的相关性,从而提高参数估计的准确性。当∑ni=1wi=n时,公式(1)中的损失可以表示为
Loss=∑pj=1‖XTj∑wX-j/n-(XTjw/n)·(XT-jw/n)‖22,(2)
其中w为wi。
由于在重加权过程中会产生大量的额外空间,为解决这一问题,本文在上述方法的尾端采用了迭代优化机制,只保存最优权重参数。对于每个批次,用于优化样本权重的特征生成为
ZO=Concat(ZG1,ZG2,…,ZGk,ZL),
wO=Concat(wG1,wG2,…,wGk,wL)。(3)
其中:ZO和wO分别表示优化样本特征和权重;ZG1,ZG2,…,ZGk,wG1,wG2,…,wGk表示整个训练集的全局信息,在每个批次结束时更新;ZL和wL是当前批次中的特征和权重。例如批量大小为x时,ZO是大小为((k+1)x)×mZ的矩阵,wO是(k+1)x维向量。通过这种方式将储存成本从O(N)降到了O(kx)。在对每一批进行训练时,保持wGi不变,只有wL在本批次进行特征学习,在每次训练迭代结束时,将全局信息(ZGi,wGi)和局部信息(ZL,wL)融合,所用公式为
Z′Gi=αiZ+(1-αi)ZL,
w′Gi=αiwGi+(1-αi)wL。(4)
对于每组全局信息(ZGi,wGi),使用k个不同的平滑参数αi来约束全局信息的长期记忆(αi较大)和短期记忆(αi较小),最后将(ZGi,wGi)替换为(Z′Gi,w′Gi)。
在训练过程中,引入Mixup[18]数据增强方法可进一步提高模型性能。Mixup数据增强方法简单来说就是构造虚拟训练样本执行数据增强,并且在数据处理过程中引入较少的参数量来节约计算资源。
本阶段网络模型采用Resnet_34作为主干网络,并将输出的特征图谱进行去相关的样本重加权操作,并利用最终损失对分类网络进行迭代优化,从而实现图片分类任务,其主要流程如图1所示。
2.2 基于CAM的类平衡采样
第一阶段模型在不均衡数据集上训练,能够学习到好的特征表示,但是尾部类别中识别准确率较差。为了得到更均衡的数据分布,第二阶段用重采样方法进行平衡微调,使获取的不平衡数据集特征值在所有类别之间实现特征共享与特征重平衡。最终本文选择基于类激活映射(class activation mapping,CAM)[19]的类平衡采样方法作为平衡微调实验的模型。
2.2.1 类平衡采样
对于不同的采样方式,概率pj的公式为
pj=nqj/(∑Ci=1nqi),(5)
其中:q∈[0,1],对于不同的q值,会出现不同的采样策略;C是类的数量。
本文所用的采样方法为类平衡采样[10],每个类被选中的样本概率相等。q=0时,概率pCBj公式为
pCBj=1/C。(6)
2.2.2 类激活映射(CAM)
为了产生鉴别性的信息,本文受类激活映射的启发,将CAM与类平衡采样相结合构成第二阶段实验,使模型从数据层面具有可解释性。
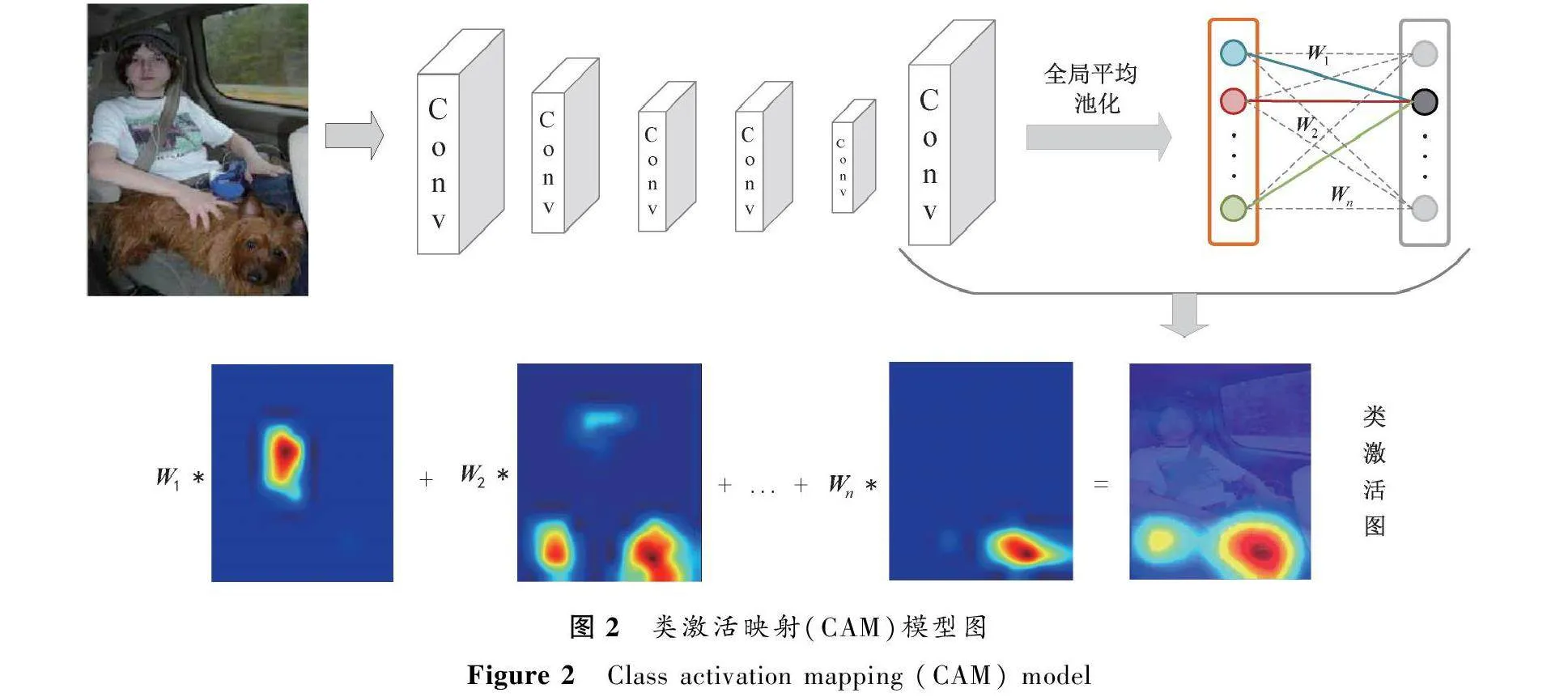
类激活映射(CAM)[19]是将输出层的权重投射回卷积特征图,以识别图像关注区域的重要性技术。通过全局平均池化输出卷积层中每个单元特征图的空间平均值,这些值的加权和生成最终输出。类似地,通过计算最后一个卷积层的特征图的加权和获得类激活图,生成类激活图的过程如图2所示。
对于给定的图像,设fk(x,y)表示在空间位置(x,y)处最后卷积层中单元k的激活。然后对单元k执行全局平均池化,Fk=∑x,yfk(x,y),因此,对于给定的c类,softmax的输入是Sc,Sc=∑kwckFk,其中wck是对应单元k的c类的权重。最后,c类softmax输出为公式(7),通过将Fk=∑x,yfk(x,y)代入到Sc中,得到公式(8)。
Pc=exp(Sc)∑cexp(Sc),(7)
Sc=∑kwck∑x,yfk(x,y)=∑x,y∑kwckfk(x,y)。(8)
Mc被定义为c类的类激活映射,其中每个元素空间的公式为
Mc(x,y)=∑kwckfk(x,y),(9)
因此,Sc=∑x,yMc(x,y),Mc直接指示了网络空间(x,y)处激活的重要性,从而图像分类为c类。
2.2.3 基于CAM的类平衡采样
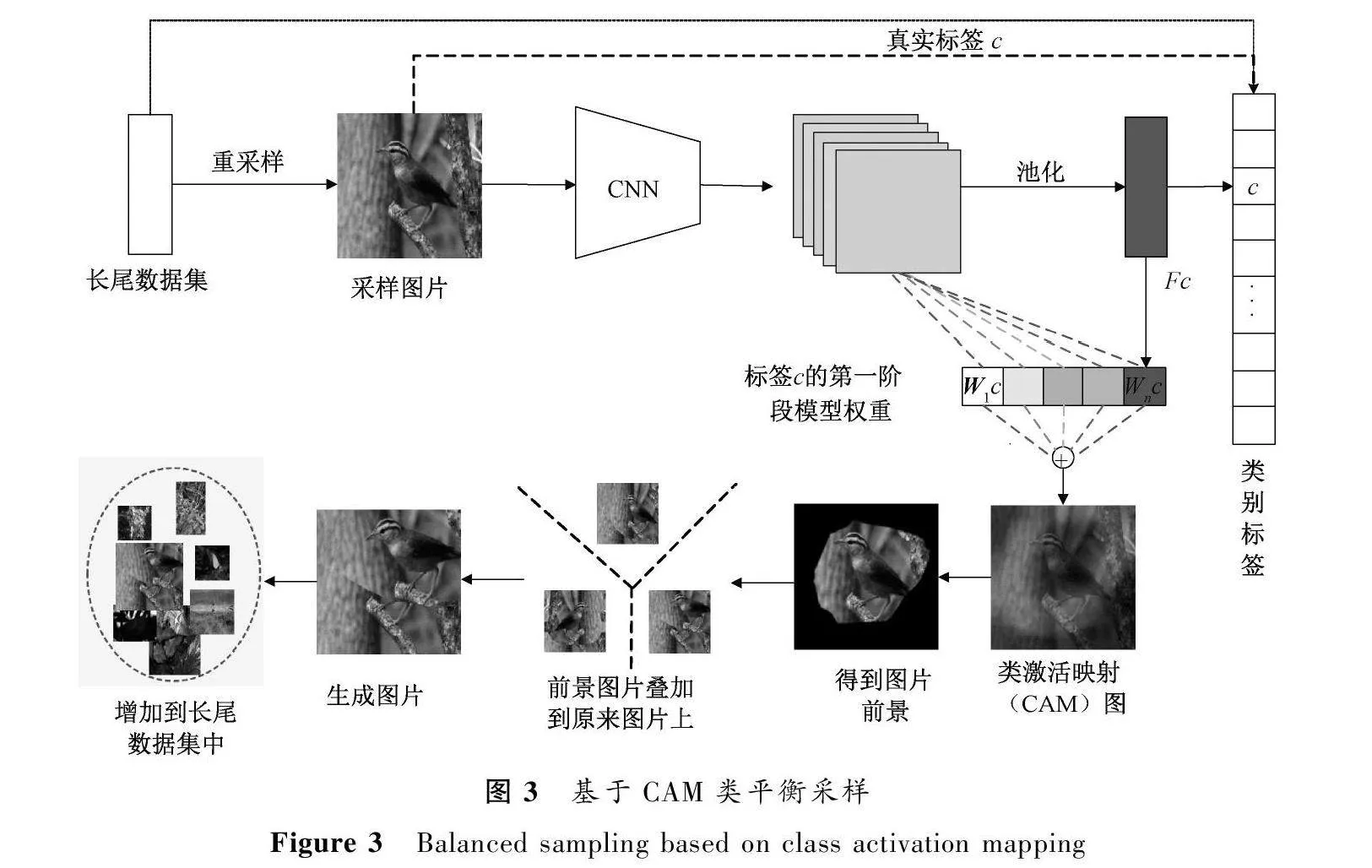
第二阶段微调过程如图3所示,首先应用重新采样来获得平衡的采样图像,通过第一训练阶段的参数化模型得到特征图,再通过全连接层得到图像的类别标签。对于每个采样的图像,基于标签c的特征图和第一阶段训练得到的权重生成CAM。前景和背景根据CAM的平均值分开,其中前景包含大于平均值的像素,背景包含其余的像素。最后,在背景保持不变的情况下对前景进行预处理,包括水平翻转、缩放、旋转和平移变换,对每张图片随机选择一个变换,最终生成有信息的采样数据,并将生成的采样数据增加到数据集,使用第一训练阶段的参数化模型进行训练。
2.3 去相关样本重加权算法和CAM的可解释
2.3.1 去相关样本重加权算法的可解释
虽然许多深度学习模型在其目标任务上能够取得良好的性能,但深度学习模型一直以来都被认为是“黑箱”模型。近年来,有学者尝试使用因果推断的方法去探究深度学习网络的可解释性。Pearl等[13]阐述了因果关系阶梯中不同层级的可解释性,因果关系阶梯大致可以分为以下三层。
1) 统计相关的解释,该层级旨在利用相关性来解释人类是如何进行判断的。
2) 因果干预的解释,该层级旨在对相关行动进行人为干预,从而得到干预后的结果,并通过这些结果进行解释。
3) 基于反事实的解释,该层级是三个层级中最高的,旨在利用一些反事实来进行想象,并基于这些想象进行解释。
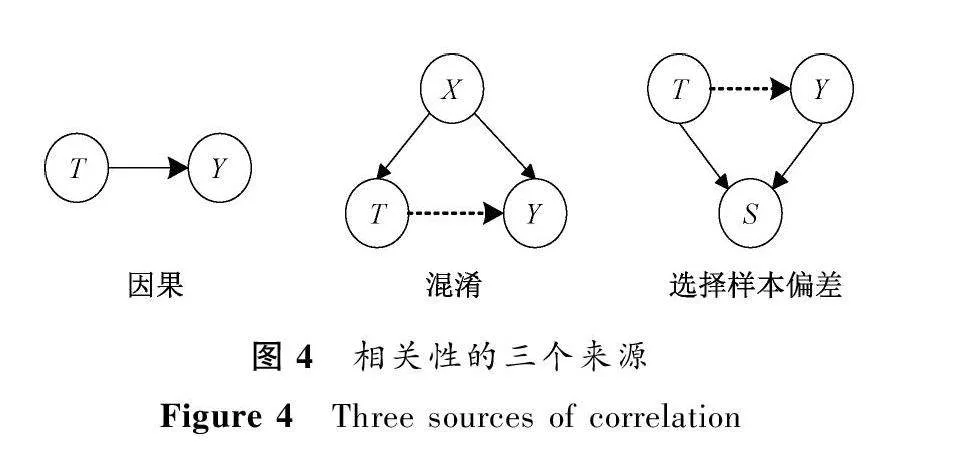
当前的机器学习主要利用数据中的统计相关性进行建模,相关性的来源主要有因果、混淆以及样本选择偏差三种,分别对应图4中的三种结构。图4中T表示原因,Y表示结果,X表示混淆变量,S表示选择偏差,实心箭头表示因果关系,虚线箭头表示假性相关关系。混淆是指存在一个变量X,该变量构成了T和Y的共同原因,如果忽略了X的影响,那么T和Y之间存在假性相关关系,即T并非产生Y的直接原因。样本选择偏差也会产生相关性,当两个相互独立的变量T和Y产生了一个共同结果S,引入S则为T和Y之间打开了一条通路,从而误以为T和Y之间存在关联关系。上述两种相关通常被称为虚假相关,只有由因果产生的相关是一种稳定的机制,不会受非标签特征影响,也只有这种稳定的结构是可解释的。
传统的可解释技术多数会依赖于特征和结果之间的相关性,有可能会检测出一些相反甚至病态的解释关系。同时,这些技术难以回答“如果某个干预改变了,模型的决策或判断是什么?”这样的反事实相关的问题。而属于可解释性技术的因果推断技术是专门研究干预结果效应的方法。因果关系与其他关系相比受到的干扰较少,由因果产生的相关是一种稳定的机制,不会受非标签特征所影响。
当进行因果推断时,需要考虑可能存在的混淆因素,这些因素可能导致因果关系被低估或高估。为了得出准确的因果推断结果,可采用去相关样本重加权的方法消除混淆因素。
去相关样本重加权方法通过重新加权样本来减少某些特征对研究结果的影响,从而更准确地确定因果关系。
2.3.2 CAM的可解释
CAM是一种用于深度学习模型可视化和解释的方法,可以帮助我们理解模型对不同类别的判断基于哪些特征。CAM通过对CNN模型的最后一层卷积层进行修改,使其能够输出给定输入图像在特定类别上的激活热力图。CAM将CNN最后一层卷积层的特征图和全局平均池化层的特征权重相乘,得到每个类别的特征映射,这些特征映射会被送入一个可视化工具中,并将它们转换为彩色的热力图,这些热力图可以让人们更直观地理解模型的判断过程,识别出模型可能出现的错误,还可以用于优化模型的训练和设计,通过观察热力图发现哪些区域对于分类有用,进而调整模型参数,以提高模型的准确性和可解释性。
3 实验结果与分析
3.1 数据集设置
本文使用的CIFAR-10/100_LT[11]是CIFAR-10/100的长尾版本。CIFAR-10和CIFAR-100都包含60 000张图像,50 000张用于训练,10 000张用于验证,类别分别为10和100。
本次实验根据数据不平衡率设计了CIFAR-10/100的长尾版本,数据不平衡率控制了训练集的分布。不平衡率被广泛用作长尾性的度量,也是本文主要使用的长尾性度量标准。Cui等[11]将数据集的不平衡率μ定义为最大类中的训练样本数除以最小样本数,其中N是每个类别中的样本数量,则
μ=Nmax/Nmin。(10)
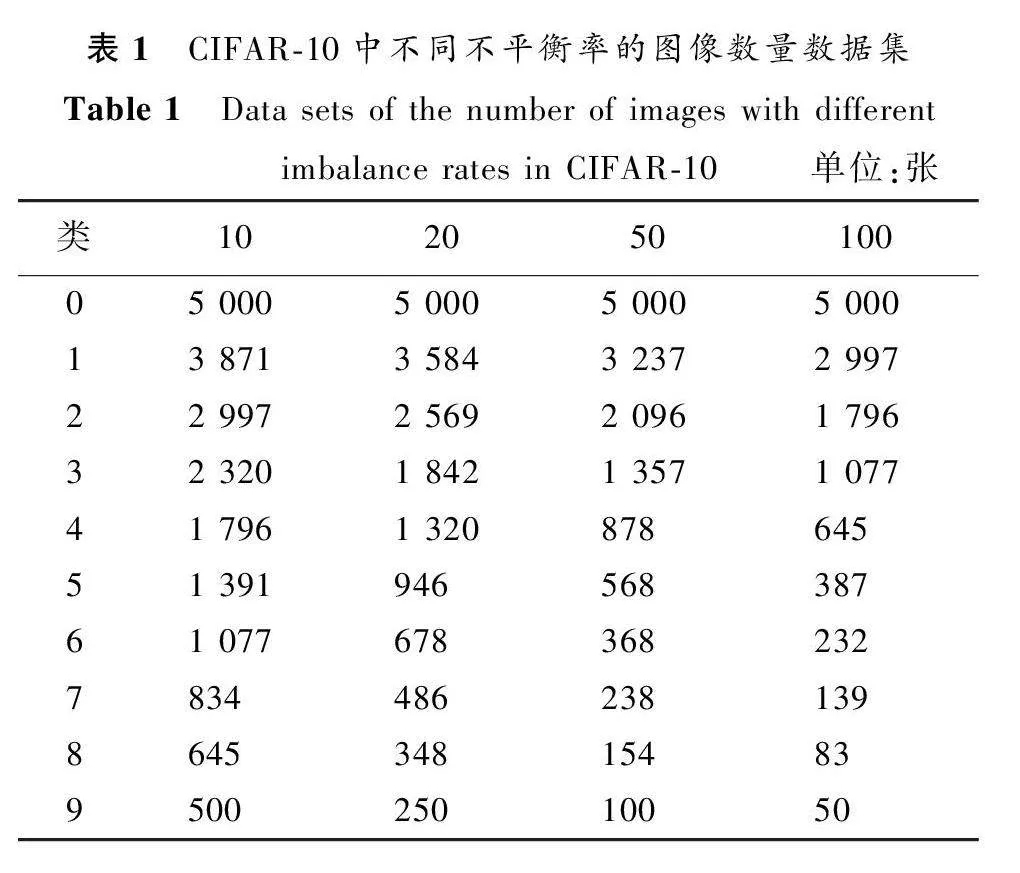
对于长尾CIFAR-10数据集,不平衡率分别设置为10、20、50、100时图像数量如表1所示。同时,也对CIFAR-100数据集做了类似的处理。
3.2 实验设置
本文模型的特征提取器选用Resnet_34,第二阶段的实验采用了第一阶段不平衡训练得到的最优参数化模型。其中第一阶段实验参数设置如下:次数epoch=200;学习率lr=0.01;动量momentum=0.9;
批量大小batch_size=128;权重衰减wd=1e-4。第二阶段的实验参数除epoch设置为40以外,其他与第一阶段实验参数设置相同。在进行采样方式的对比实验以及消融实验时,参数设置均与上述参数设置相同。
本文所涉及的实验均在Windows 11操作系统以及NVIDIA GeForce RTX 3050 4 GB GPU上实现,本文采用的深度学习的开源框架为Pytorchcuda 1.13.0。
3.3 实验结果
3.3.1 对比实验
将本文所提出的模型与CIFAR10/100_LT数据集上的其他方法进行评估,不平衡率分别设置为10、20、50及100。同时为了去除不同实验环境带来的数据差异,采用的所有对比方法均在本文模型相同的实验环境下进行。分类精度结果如表2所示,其中黑体数据为最优结果。
CIFAR10_LT数据集:当不平衡率分别设置为10、20、50及100时,相比于其他方法,本文模型取得了最优分类精度,分别为91.22%、86.01%、82.76%和79.28%。
CIFAR100_LT数据集:当不平衡率设置为10和20时,本文模型取得了最优精度,分别为62.41%和55.44%。当不平衡率设置为50和100时,最优分类精度为BKD模型的47.25%和44.21%,本文模型的分类精度为47.43%和43.39%。
本文模型在CIFAR10_LT数据集上有最优的表现,在CIFAR100_LT数据集相关实验中与最优模型BKD表现基本持平,精度相差不足1%。
不相关特征和类别标签之间的虚假相关是导致模型预测准确率下降的主要原因,同时会导致模型预测的不稳定性。本文模型通过去除变量之间的虚假相关,提高模型的预测稳定性以及准确率。其次,通过增加平衡微调实验,解决了不平衡数据导致模型在样本数量较少的尾部类别中识别精度较差的问题,进一步提高了模型性能。
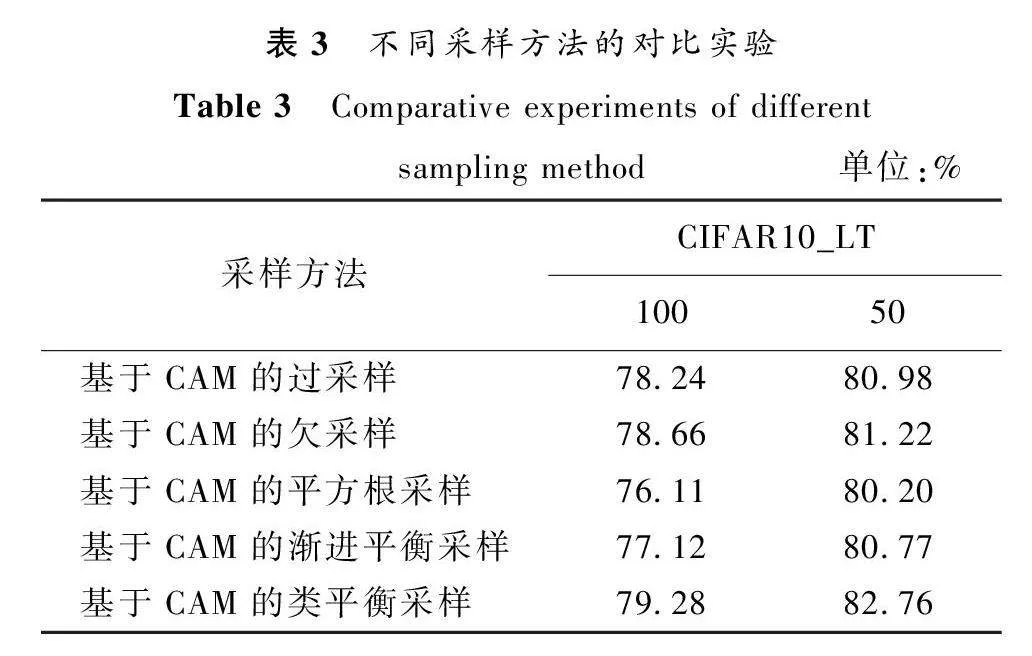
为了证明选择类平衡采样方法的优越性,对不同采样进行了对比实验,不平衡率取100和50,分类精度结果如表3所示。
从表3中可以看出,基于CAM的类平衡采样方法优于其他基于CAM的采样方法。
3.3.2 消融实验
为了判断各方法的有效性,本文进行了消融实验来评价本文所提出两阶段模型的性能。消融实验只在不平衡率为100的CIFAR10_LT上进行,其主干网络均采用Resnet_34。具体实验结果如表4所示。
在Resnet_34网络的基础上增加去相关重加权方法之后,分类精度增长8.69%,以此可以证明因果推断原理在长尾分类任务中的有效性。在②的基础上,增加Mixup数据增强方法之后,分类精度提升1.88%。添加第二阶段微调实验(类平衡采样)之后,分类精度比③增长2.69%,但将类平衡采样更改为基于CAM的类平衡采样方法之后,分类精度比③提升6.34%。可见使用了CAM的方法进行类平衡采样,不仅能够提升模型性能,还能够使模型从数据层面具有可解释性。
4 结束语
本文的主要贡献如下:1) 本文提出的基于因果推断的两阶段长尾分类模型在CIFAR10/100_LT数据集上取得了不错的分类效果,并且通过对比实验以及消融实验,证明了该方法的有效性;2) 本文所提出的方法不仅在整体模型上具有可解释性,并且在微调训练阶段采用了基于CAM的类平衡采样方法,CAM方法能够显示出特征的具体位置,使模型在数据层面也具有可解释性;3) 本文将因果推断理论应用于长尾分类任务中,再次证明因果推断理论在长尾分类任务中的有效性。
解决长尾分布问题在计算机视觉领域不仅非常重要,而且也是一项巨大的挑战。我们认为因果推断是一个很好的发展方向,在未来的研究中,将深入研究因果推断理论在长尾分类任务中的应用。
参考文献:
[1] 王阳, 袁国武, 瞿睿, 等. 基于改进YOLOv3的机场停机坪目标检测方法[J]. 郑州大学学报(理学版), 2022, 54(5): 22-28.
WANG Y, YUAN G W, QU R, et al. Target detection method of airport apron based on improved YOLOv3[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(5): 22-28.
[2] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]∥2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2009: 248-255.
[3] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[M]. Cham: Springer International Publishing, 2014.
[4] ZHOU B L, LAPEDRIZA A, KHOSLA A, et al. Places: a 10 million image database for scene recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(6): 1452-1464.
[5] JUNSOMBOON N, PHIENTHRAKUL T. Combining over-sampling and under-sampling techniques for imbalance dataset[C]∥Proceedings of the 9th International Conference on Machine Learning and Computing. New York: ACM Press, 2017: 243-247.
[6] MOHAMMED R, RAWASHDEH J, ABDULLAH M. Machine learning with oversampling and undersampling techniques: overview study and experimental results[C]∥2020 11th International Conference on Information and Communication Systems. Piscataway:IEEE Press, 2020: 243-248.
[7] SHEN L, LIN Z C, HUANG Q M. Relay backpropagation for effective learning of deep convolutional neural networks[M]. Cham: Springer International Publishing, 2016.
[8] MAHAJAN D, GIRSHICK R, RAMANATHAN V, et al. Exploring the limits of weakly supervised pretraining[C]∥Computer Vision-ECCV 2018: 15th European Conference. New York: ACM Press, 2018: 185-201.
[9] ZHOU B Y, CUI Q, WEI X S, et al. BBN: bilateral-branch network with cumulative learning for long-tailed visual recognition[C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 9716-9725.
[10]KANG B Y, XIE S N, ROHRBACH M, et al. Decoupling representation and classifier for long-tailed recognition[EB/OL].(2019-10-21)[2023-02-21]. https:∥arxiv.org/abs/1910.09217.
[11]CUI Y, JIA M L, LIN T Y, et al. Class-balanced loss based on effective number of samples[C]∥2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 9260-9269.
[12]CAO K D, WEI C, GAIDON A, et al. Learning imbalanced datasets with label-distribution-aware margin loss[EB/OL]. (2019-07-18)[2023-02-21].https:∥arxiv.org/abs/1906.07413.
[13]PEARL J, MACKENZIE D. The book of why: the new science of cause and effect[M].New York: Basic Books Publishing, 2018.
[14]YAO L Y, CHU Z X, LI S, et al. A survey on causal inference[J]. ACM transactions on knowledge discovery from data, 2021, 15(5): 1-46.
[15]KUANG K, XIONG R X, CUI P, et al. Stable prediction with model misspecification and agnostic distribution shift[J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(4): 4485-4492.
[16]SHEN Z Y, CUI P, KUANG K, et al. Causally regularized learning with agnostic data selection bias[C]∥Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM Press, 2018: 411-419.
[17]LI J Y, ZHANG W J, LIU L, et al. A general framework for causal classification[J]. International journal of data science and analytics, 2021, 11(2): 127-139.
[18]ZHANG H Y, CISSE M, DAUPHIN Y N, et al. Mixup: beyond empirical risk minimization[EB/OL].(2017-10-25)[2023-02-21].https:∥arxiv.org/abs/1710.09412.
[19]ZHOU B L, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 2921-2929.
[20]YANG Y Z, XU Z. Rethinking the value of labels for improving class-imbalanced learning[EB/OL]. (2020-07-13)[2023-02-21]. https:∥arxiv.org/abs/2006.07529.
[21]CHOU H P, CHANG S C, PAN J Y, et al. Remix: rebalanced mixup[M]. Cham: Springer International Publishing, 2020.
[22]ZHANG S Y, CHEN C, HU X Y, et al. Balanced knowledge distillation for long-tailed learning[J]. Neurocomputing, 2023, 527: 36-46.
