
一种基于区块链和梯度压缩的去中心化联邦学习模型
2024-08-13 00:00:00刘炜马杰夏玉洁唐琮轲郭海伟田钊
郑州大学学报(理学版) 2024年5期










摘要: 联邦学习可在保护数据隐私的前提下完成模型的训练,但实际应用中存在的安全问题阻碍了联邦学习的发展。提出一种基于区块链和梯度压缩的去中心化联邦学习模型。首先,利用区块链存储训练数据,训练参与方通过全局模型本地更新的方式取代中心服务器并使用智能合约实现对链上数据的访问控制。其次,提出一种梯度压缩方法,对模型参数进行压缩以减少参与方与区块链之间的数据传输量且有效防止了梯度隐私泄露。最后,为减弱梯度压缩对全局模型收敛速度的影响,使用热身训练的方式提升全局模型的收敛速度以缩短整体训练时间。实验结果表明,该模型在减少传输数据量的情况下对全局模型准确率有较小影响且提升了联邦学习训练效率。
关键词: 区块链; 联邦学习; 智能合约; 梯度压缩; 隐私保护
中图分类号: TP302
文献标志码: A
文章编号: 1671-6841(2024)05-0047-08
DOI: 10.13705/j.issn.1671-6841.2023013
A Decentralized Federated Learning Model Based on Blockchain and
Gradient Compression
LIU Wei1,2,3, MA Jie1,2, XIA Yujie1,2, TANG Congke1,2, GUO Haiwei4, TIAN Zhao1,2
(1.School of Cyber Science and Engineering, Zhengzhou University, Zhengzhou 450002,China;
2.Zhengzhou Key Laboratory of Blockchain and Data Intelligence, Zhengzhou 450002,China;
3.Henan Collaborative Innovation Center of Internet Medical and Health Services, Zhengzhou University,
Zhengzhou 450052, China; 4.Information Management Center, Zhongyuan Oilfield Branch of
Sinopec, Puyang 457001,China)
Abstract: Federated learning could complete the training of models while protecting data privacy, but security issues in practical applications hindered the development of federated learning. A decentralized federation learning model based on blockchain and gradient compression was proposed. Firstly, a blockchain was used to store training data, and the training participants replaced the central server by local updates of the global model and used smart contracts to achieve access control to the data on the chain. Secondly, a gradient compression method was proposed to compress the model parameters to reduce the amount of data transmission between the participants and the blockchain and effectively to prevent the gradient privacy leakage. Finally, to reduce the impact of gradient compression on the convergence speed of the global model, a warm-up training method was used to improve the convergence speed of the global model to shorten the overall training time. The experimental results showed that the model had a small impact on the global model accuracy and improved the federal learning training efficiency with the reduced amount of transmitted data.
Key words: blockchain; federal learning; smart contract; gradient compression; privacy protection
0 引言
联邦学习(federated learning,FL)[1]作为一种隐私计算解决方案,其目的是在保护数据隐私的前提下完成模型训练的相关任务,与传统的集中式机器学习相比,联邦学习可以在数据不出本地的情况下完成模型训练,可有效打破“数据孤岛”。联邦学习的快速发展,使其在实际应用过程中也产生了一系列安全问题。
1) 中心化服务器[2]。中心化联邦学习对全局模型的更新依赖中心服务器,这种服务器常由不可信第三方进行提供,当第三方不可信或中心服务器因遭受攻击而宕机时,全局模型无法更新,导致联邦学习过程被迫中止并造成全局模型的泄露。
2) 梯度隐私泄露[3]。全局模型的更新需要聚合局部模型,局部模型中的数据包含参与方的数据隐私,恶意攻击者可以利用DLG[4]方法或iDLG[5]方法从局部模型中推断出参与方所持有的数据和标签,造成参与方的数据泄露。
3) 网络传输负担[6]。联邦学习中心服务器在每轮全局更新开始阶段与结束阶段需要与参与方进行数据交互,模型参数在数据交互中占比很大。随着深度学习的发展,一个复杂的深度学习网络包含的模型参数数据量高达数百兆[7]。当训练参与方数量较多时,与中心服务器进行数据交互会产生通信瓶颈,影响联邦学习的训练效率。
区块链是将密码学、P2P、智能合约、共识机制结合起来形成的一个分布式共享账本[8],具有去中心化、不可篡改、可追溯等特性。将区块链和联邦学习相结合可以解决联邦学习的部分安全问题:利用区块链去中心化的特点代替联邦学习的中心服务器完成模型全局更新过程;利用区块链不可篡改的特性记录联邦学习中参与方的局部模型以及全局模型,在遭受攻击时或需要溯源时参与方节点进行追责。
虽然区块链和联邦学习相结合提升了训练过程的安全性和可追溯性,但大批量数据的上链操作会严重影响区块链的效率,拖慢整体训练速度,因此需要减少传输数据量,以加快整体训练速度。
综上所述,为提高参与方与区块链网络间的通信效率并增强隐私保护,本文构建了一种基于区块链和梯度压缩的去中心化联邦学习模型。首先,利用区块链存储训练数据,训练参与方通过全局模型本地更新的方式取代中心服务器并使用智能合约实现对链上数据的访问控制。其次,为提升区块链网络效率,提出一种梯度压缩方法,通过对模型参数进行压缩以减少参与方与区块链之间的数据传输量且有效防止了梯度隐私泄露。最后,为减弱梯度压缩对全局模型收敛速度的影响,使用热身训练的方式提升全局模型的收敛速度以缩短整体训练时间。
1 相关工作
针对运用区块链技术解决联邦学习中存在的相关问题,众多学者提出了相关方案。Hu等[9]提出了一个基于区块链和边缘计算的高效去中心化联邦学习框架,同时将CKKS方案应用于模型聚合和远程评估,为模型构建提供了一种通用方法。Sun等[10]提出了一种基于Hyperledger Fabric框架的联邦学习系统,通过区块链记录每个全局模型的更新过程并追踪本地更新过程,使用同态加密来保护本地模型更新,在本地模型聚合之前添加差分隐私来保护隐私。Peng等[11]提出一个名为VFChain的基于区块链系统的可验证和可审计的联邦学习框架,通过区块链选择一个委员会来聚合模型并在区块链中记录,并提出了一种新的区块链认证数据结构以提高可验证证明的搜索效率。Li等[12]设计了一个区块链辅助分散联邦学习框架BLADE-FL,每个参与方将其经过训练的模型广播给其他参与方,将自己的模型与接收的模型聚合,然后在下一轮本地训练之前竞争生成区块,同时为广播前的模型添加噪声来防止隐私泄露。Liu等[13]提出一个名为FedAC的联邦学习方法,利用区块链网络取代中央服务器来聚合全局模型,避免了异常本地设备训练失败、专用攻击等问题。Shlezinger等[14]提出了名为UVeQFed的联邦学习通用矢量量化方法,通过此方法可以产生一个分散的训练系统,其中训练模型的压缩仅引起最小准确率损失。Cui等[15]提出了一种名为BCFL的联邦学习方法,其将联邦学习和区块链相结合,并使用一种梯度压缩方法减小上传的模型数据量。Desai等[16]提出了一个基于混合区块链的联邦学习框架,该框架使用智能合约自动检测,并通过罚款惩罚恶意攻击者,使用二进制压缩方法对模型进行压缩,提升了框架效率。
上述研究主要是利用区块链结构的不可篡改性记录联邦学习过程中的模型及聚合过程,利用加密算法对模型进行加密,利用广播的形式聚合全局模型取代中心服务器,在解决联邦学习通信瓶颈时通过减少模型参数量进行优化。本文提出的基于区块链和梯度压缩的去中心化联邦学习模型,利用区块链存储训练数据,参与方从区块链上获取训练数据后采用全局模型本地更新的方式取代中心服务器,利用梯度压缩方法减少链上传输数据量,利用热身训练方式减弱梯度压缩对训练速度的影响。
2 模型设计
2.1 系统模型
本文构建了一个基于区块链和梯度压缩的去中心化联邦学习模型。该模型主要由区块链网络、联邦学习参与方和智能合约构成。基于区块链和梯度压缩的去中心化联邦学习模型如图1所示。
1) 区块链网络。利用区块链网络存储训练数据,主要包括模型信息、身份信息、验证信息和评价信息等数据。
2) 联邦学习参与方。联邦学习参与方又分为任务发布方与训练参与方。任务发布方向训练参与方发布训练任务并授予身份信息;训练参与方利用本地数据进行训练并参与模型共识过程。
3) 智能合约。智能合约为联邦学习参与方与区块链之间提供安全的数据接口,在共识阶段通过调用智能合约对模型进行验证及评价。
在本文设计的模型中,任务发布方首先向训练参与方发布训练任务及身份信息,并向区块链网络传输初始全局模型,训练参与方获取训练任务及身份信息后调用数据交互合约从区块链中获取初始全局模型,利用本地数据完成模型训练后获得局部模型,对局部模型梯度压缩后调用数据交互合约传输训练数据。其余参与方检测到区块长度增加后,调用模型验证合约对该局部模型进行验证,在验证结束后调用模型评价合约对该局部模型进行评价记录。训练参与方上传局部模型后等待其余训练参与方完成训练并上传局部模型,当产生的局部模型数量达到更新阈值时,从区块链上获取其余参与方的局部模型后在本地生成新的全局模型并开展新一轮的模型训练,直至训练结束。
2.2 智能合约
2.2.1 智能合约设计
本模型设计了四个智能合约来记录和验证模型数据,分别为身份验证合约、数据交互合约、模型验证合约和模型评价合约。
1) 身份验证合约。为阻止未经允许的参与方向区块链网络中上传恶意信息,以及对局部模型的溯源操作,该合约对调用合约参与方进行身份验证以控制链上数据访问。
2) 数据交互合约。提供参与方与区块链之间数据接口,并记录参与方的访问时间与访问次数,参与方通过该合约上传或下载全局轮次、模型类型、模型参数、全局模型哈希、模型准确率等信息。
3) 模型验证合约。在联邦学习中,恶意参与方会发起投毒攻击以干扰联邦学习训练,或是参与方不参与全局模型的更新,仍使用旧模型或其他模型进行训练而导致模型质量下降。模型验证合约对上传的模型进行验证。首先,验证本轮次训练的全局模型,即验证全局模型哈希是否正确。其次,利用本地数据计算该局部模型准确率,判断该模型是否为投毒攻击。最后,对此模型投票,获得半数以上票数则接受该模型,否则拒绝该局部模型。
4) 模型评价合约。当一个参与方所上传的局部模型被多次拒绝,则有理由认为该参与方可能为恶意参与方或该参与方所拥有的本地数据不符合联邦学习训练要求。模型评价合约记录各参与方所上传的局部模型遭受拒绝次数,当某个参与方遭受拒绝次数达到拒绝阈值时,则移除该参与方的身份信息,拒绝参与此次联邦学习训练。
2.2.2 智能合约调用过程
联邦学习训练参与方调用智能合约过程如图2所示。当某个训练参与方完成联邦学习局部模型的训练后,首先调用数据交互合约获取数据接口,数据交互合约会调用身份验证合约来验证参与方的身份信息,以保证区块链上数据访问的安全性,身份验证无误后将数据模型上传至区块链网络。
共识小组由除该局部模型拥有者之外的其余训练参与方构成。共识小组监听区块链网络长度变化,当发现新的局部模型被上传至区块链网络后,调用模型验证合约对局部模型进行验证。模型验证合约将调用数据交互合约从区块链网络获取新的局部模型,之后共识小组利用本地数据对该局部模型进行验证并投票,并将该局部模型的验证结果上传至区块链网络。若该局部模型被拒绝,则调用模型评价合约对该局部模型拥有者进行记录,并将评价信息上传至区块链网络。
2.3 梯度压缩
为减少训练参与方与区块链网络的数据传输量,本文使用梯度压缩算法对模型进行压缩,使用梯度解压算法对模型进行还原,并使用热身训练算法减弱梯度压缩对模型收敛速度造成的影响。
2.3.1 梯度压缩算法
在该模型下的联邦学习中,训练参与方要与区块链网络之间传输大量的训练数据,此过程不仅需要耗费时间和网络带宽,也降低了区块链网络的效率,此外在全局模型的本地聚合过程中下载其余参与方的局部模型也需要耗费大量的资源。在分布式架构的深度学习模型中,99%的梯度交互通信是冗余的[17]。这些冗余的梯度耗费了大量的资源。本文提出一种梯度压缩算法来降低训练参与方和区块链网络之间的通信数据量,该方法可以提升训练效率并防止梯度隐私泄露。
梯度压缩算法如算法1所示。本算法使用本轮本地模型与上轮全局模型的差值作为梯度(grad),逐层对梯度中的参数进行采样,根据压缩率p和采样后的梯度参数确定选择阈值(t),只选取梯度绝对值大于t的梯度进行传输。压缩率p定义为
p=size(select(Gw))/size(Gw),(1)
其中:select(Gw)是选择大于t进行传输的梯度参数;size(Gw)是计算梯度参数的数量。
使用top-k算法确定t时,若不使用分层采样方式,需要对每层梯度的所有参数进行top-k运算,算法复杂度为O(n),n为梯度参数数量,此过程耗费大量的时间进行计算。因此在算法开始阶段首先对每层梯度进行采样,对采样结果进行top-k运算可减少t的确定时间。
采样过程首先由式(2)确定每层梯度的采样数量(sample),
sample=q×size(Gw)。(2)
由于每层梯度Gw的参数数量不同,为保证采样质量,根据式(3)设置最小采样数量min_sample。采样数量小于min_sample时对Gw进行全部采样,
min_sample=1/p。(3)
本文使用固定间隔对每层梯度Gw中的参数进行抽取,使用式(4)确定采样步长(step),若进行全部采样则设置step为1。将固定间隔设置为step,对Gw进行采样得到Gsample,
step=1/q。(4)
对采样结果Gsample的绝对值执行top-k运算,k值由式(5)确定,选取运算结果中的最小值即为t,
k=p×size(Gsample)。(5)
在确定t后,根据Gw生成相同形状的掩码矩阵Mask,存储梯度参数位置。若Gw中的参数绝对值≥t,则将Mask的对应位置设置为1,否则设置为0。然后将Gw与Mask进行点乘运算得到传输梯度G′w。将G′w和Mask转为不含0的一维梯度值(values)与梯度坐标(indices)后,作为梯度Gw进行输出。
算法1 梯度压缩算法
输入: 梯度压缩前集合grad={G1,…,Gn},压缩率p,采样率s。
输出: grad。
1. for w←1 to W
2. 采样Gsample←s of Gw
3. 确定选择阈值t←p of Gsample
4. Mask←Gw>t
5. G′w←Gw⊙Mask
6. indices←将Mask转为不含0的一维张量
7. values←将G′w转为不含0的一维张量
8. Gw←indices,values
9. end for
2.3.2 梯度解压算法
从区块链下载得到压缩后的局部模型,所含梯度的维度与参数量都与压缩前的梯度不同,无法直接使用,需要使用梯度解压算法将梯度还原成压缩前的维度与所含参数量。
梯度解压算法如算法2所示。参与方将接收的局部模型中的梯度拆分为梯度坐标(indices)与梯度值(values),因在联邦学习过程中只改变模型相关参数而不改变模型形状,故只读取初始模型每层的初始形状(shape)即可完成梯度解压过程,而无须额外的参数传输。首先,按照每层shape转为一维的形状生成一维全0张量Gzero。然后,根据indices与values向全0张量Gzero相应位置插入数据,其余位置插入0。最后,将插入数据的张量转为层梯度shape,从而完成整个梯度解压的全过程,将梯度恢复至G′w。
算法2 梯度解压算法
输入: 梯度压缩后集合grad={G1,…,Gn},初始模型M0。
输出: grad。
1. for w←1 to W
2. indices,values←Gw
3. shape←读取M0中Gw层的维度形状
4. Gzero←生成一维全0张量
5. for i,v in indices,values
6. Gzero[i]=v
7. end for
8. G′w←将Gzero转为Gw维度形状shape
9. end for
2.3.3 热身训练算法 在联邦学习全局轮次开始迭代初期,初始模型M0变化迅速,梯度变化幅度明显且多样化。梯度压缩因其压缩率的影响限制了模型的变化范围,从而延长了模型急剧变化的周期,降低了模型的收敛速度。为了减弱梯度压缩对前期模型快速变化周期的影响,本文采用热身训练方法来帮助提升模型的收敛速度。热身训练算法如算法3所示。
在全局轮次g开始迭代初期,设置若干个周期为热身轮次e,将压缩率设置为热身压缩率wp,在这些周期内增加传输的梯度参数量来减弱梯度压缩对模型变化的影响,热身轮次结束后仍按照基础压缩率bp进行梯度压缩。通过这种方式使模型在热身训练周期内快速变化,加快模型的收敛速度。
算法3 热身训练算法
输入: 全局迭代次数g,热身轮次e,热身压缩率wp,基础压缩率bp。
输出: 压缩率p。
1. for i←1 to g
2. if 热身训练
3. ;if i<e
4. p←wp[e]
5. 梯度压缩 compression(grad,p,s)
6. end if
7. end if
8. 梯度压缩 compression(grad,bp,s)
9. end for
3 实验分析
3.1 实验设置
为了评估本文所提方法的性能,基于CIFAR-10数据集进行实验,该数据集包含50 000张训练图像和10 000张测试图像,每个样本是一个32×32×3的彩色图像,共10种分类。resnet网络作为深度学习领域中具有代表性的网络,其在分类任务与目标检测任务中都有较好的性能表现,实验分别训练测试resnet18、resnet50这两种DNN模型的图片分类性能。两种模型都采用SGD优化器更新策略,小批量尺寸为32,学习率0.01,动量0.01。在联邦学习模型中设置10个训练参与方,本地迭代3轮。本实验运行环境为Intel(R) Xeon(R) E5-2620 2.10 GHz CPU, 32 GB RAM,和两个NVIDIA Tesla T4 GPU的硬件系统。
3.2 更新阈值选取实验
为确定不同更新阈值对联邦学习全局模型准确率造成的影响,分别使用3、5、7作为更新阈值,使用resnet18、resnet50模型分别进行训练,并根据模型对数据集中的训练结果计算准确率,以确定训练参与方从区块链网络下载其余参与方的局部模型的更新阈值。其结果如图3所示。
从实验结果中可知,使用不同更新阈值的两种模型,前50轮的全局模型准确率随着更新阈值的增长提升。resnet18模型三种更新阈值其第50轮准确率分别为83.49%、85.2%、85.7%。resnet50模型三种更新阈值其第50轮准确率分别为87.48%、88.28%、89.05%。k=3时的模型准确率与k=5或7时的模型准确率相比有较大差别。而k=5时与k=7时准确率接近。k值的增加虽然会提升全局模型准确率,但也会拖慢联邦学习模型的效率。综合考虑,本文使用k=5进行后续实验。
3.3 梯度压缩实验
为测试不同压缩率压缩模型后的效果,本文使用不同压缩率在两种模型上分别进行了多次实验。
实验首先将模型参数输出至文件中计算模型的初始大小,然后分别使用0.1~0.5压缩率对模型进行压缩并输出至相同格式的文件中,通过统计文件实际大小以得到压缩后的模型尺寸。resnet18、resnet50模型压缩前及不同压缩率压缩后的结果如表1所示。
从压缩结果来看,随着压缩率的不断降低,压缩 后的模型大小在不断减小。模型实际压缩率(ACR)由式(6)计算得到,
ACR=CMS/MS,(6)
其中:CMS为压缩后的模型大小;MS为压缩前的模型大小。
根据2.3.1节的梯度压缩算法可知,压缩后的模型由大于阈值的梯度和梯度的坐标构成,故压缩后的模型体积大于由压缩率计算得出的模型体积。压缩率为0.5时测得实际压缩率为0.74,压缩差值为0.24。模型压缩率为0.1时测得实际压缩率为0.14,超过的部分是由于需要将梯度坐标保存在压缩后的数据中而产生的数据,压缩率越低,实际压缩率也越接近压缩率。对比两模型的结果可知,在相同的压缩率下,不同模型的实际压缩率基本相同,故该梯度压缩方法可适用于不同的深度学习模型。
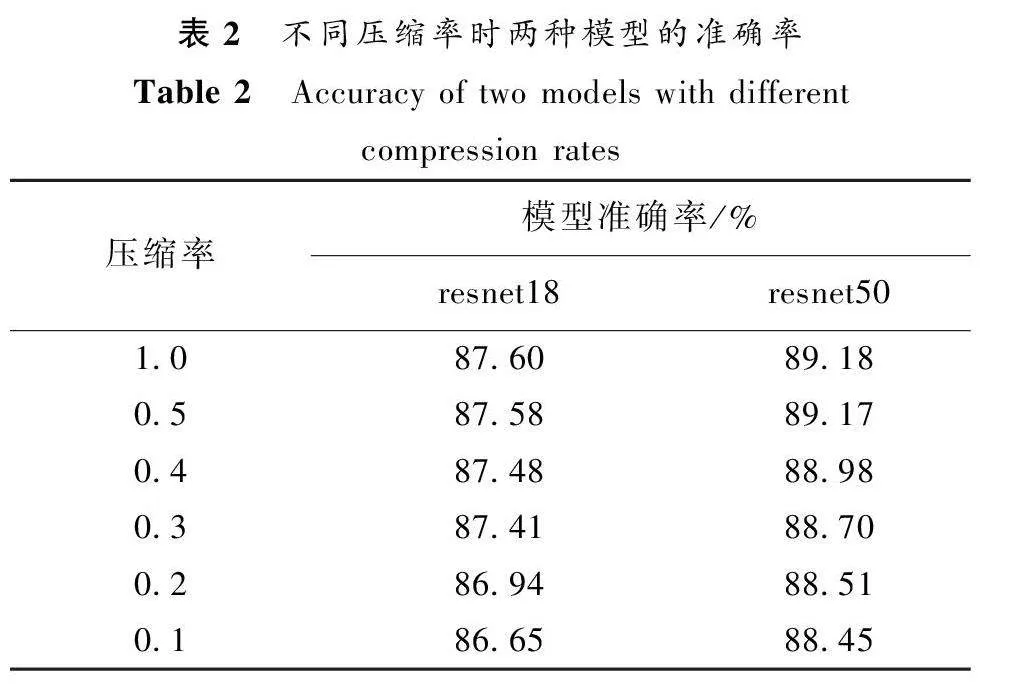
为确定压缩率对准确率造成的影响,实验测试在0.1~0.5压缩率下的resnet18和resnet50模型准确率的变化情况,对不同压缩率下的同一模型执行相同次数的局部与全局迭代,统计模型多次训练后的准确率再进行平均,得到的两种模型在不同压缩率下的准确率如表2所示。
从不同压缩率下准确率的结果来看,随着压缩率的不断减小,参与方传输的数据量在不断减少,所获取的全局模型准确率也有所降低。使用压缩率为0.5时两种模型的准确率几乎没有变化。使用压缩率为0.1时,resnet18模型的准确率仅降低了0.95%,resnet50模型准确率仅降低了0.73%。整体上看,使用较低压缩率对模型准确率影响较小,因此本文提出的模型是有效且可行的。
3.4 热身训练实验
在使用梯度压缩进行实验的过程中观察到使用较低的梯度压缩率会减慢模型的收敛速度,虽经过长时间的全局迭代后也能让全局模型收敛并获得较高的准确率,但不能为了追求压缩效率而减弱了联邦学习整体效率。实验首先统计了resnet18模型使用不同压缩率前20轮准确率变化情况,其结果如图4所示。
从图4可以看出压缩率(p)为0.3~0.5的收敛速度较为相似且较接近于压缩率为1.0的收敛速度,而使用压缩率为0.2的模型在第12轮左右也与使用压缩率为0.3~0.5的模型准确率较为接近,准确率上升最慢的是压缩率为0.1的模型,直至第20轮也未能完成模型的快速收敛过程并达到准确率缓慢上升的阶段。若在联邦学习中直接使用较低压缩率压缩后的模型参与全局模型更新会影响联邦学习的效率。在第20轮时,使用压缩率为0.1的模型其准确率仅为76.35%,而压缩率为1.0的模型在第6轮准确率就达到了76.65%,且在前5轮次中压缩率为1.0的模型准确率快速上升并处于快速收敛阶段。因此在训练前期使用对模型收敛速度影响较小的压缩率将提升联邦学习的效率。
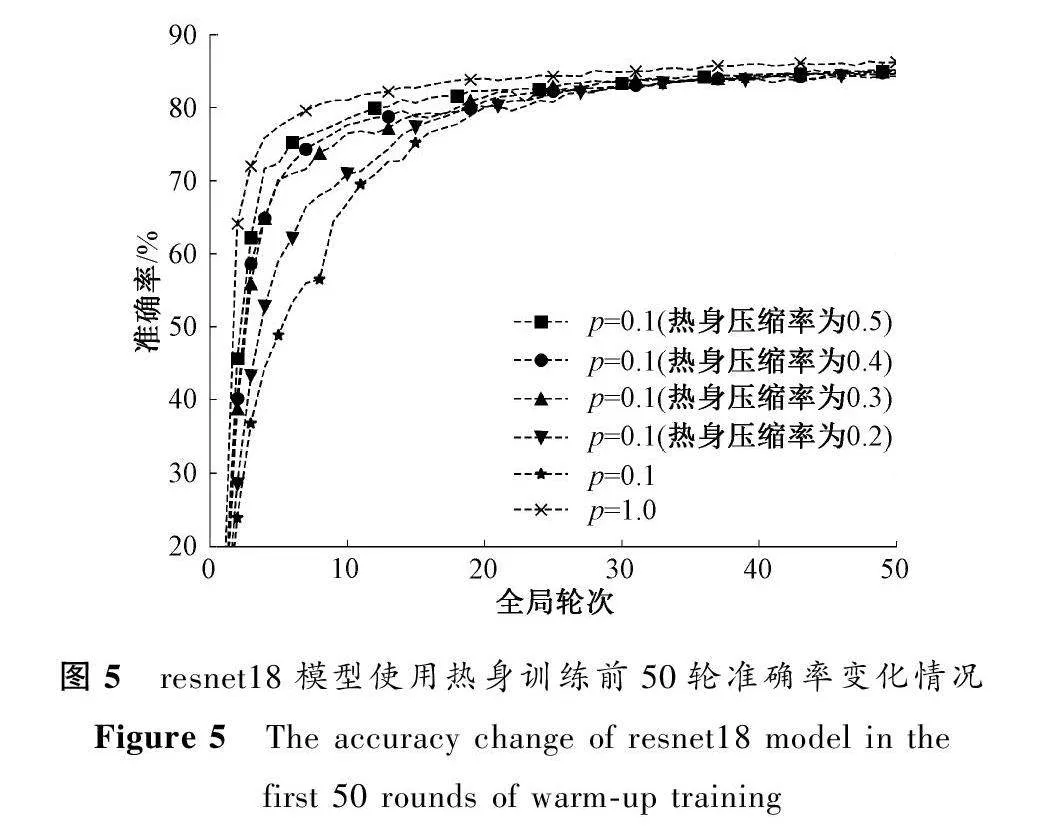
根据这一观察结果,在实验中将全局迭代前5轮设置为热身轮次,在此轮次里分别使用0.2~0.5作为热身压缩率,结束热身训练轮次后压缩率仍使用0.1进行压缩,同时设置压缩率为1.0与压缩率为0.1且不使用热身训练为对照,resnet18模型使用热身训练前50轮准确率变化情况如图5所示。
从实验结果中可以看到,使用热身训练方法的模型其收敛速度比不使用热身训练方法的模型收敛速度快。同时在热身轮次中,使用较高压缩率的模型其收敛速度快于低压缩率的模型。在第20轮左右用热身压缩率为0.5的模型准确率开始缓慢上升。在训练结束的第50轮时,使用热身压缩率为0.5的模型其准确率较不使用热身训练的模型提升了0.35%。虽然在热身轮次中使用较高压缩率增加了数据传输量,但同时提升了模型准确率,因此在热身轮次使用对传输参数数量影响较小的压缩率可有效提升模型收敛速度,缩短联邦学习的训练时间。针对联邦学习的复杂情况,热身训练方法可适用于短时间低数据传输的联邦学习场景中。
3.5 梯度隐私泄露实验
为验证梯度压缩对梯度隐私泄露的保护作用,分别使用不同压缩率验证在DLG和iDLG两种梯度隐私攻击方法中的隐私保护效果,实验结果如图6、图7所示。
从实验结果可以看出,梯度压缩对梯度隐私泄露有保护作用。随着压缩率的降低,使用DLG和iDLG两种梯度隐私攻击方法对图片的还原效果逐渐降低。在压缩率为1.0时,使用两种梯度隐私攻击方法可以完全还原图片,使用梯度压缩后,当压缩率为0.9时仍可判断图片;压缩率为0.8时对比原始图片隐约可看到图片轮廓;使用更低的压缩率后无法判断还原出的图片。从实验结果可知,使用0.8以下的压缩率可有效预防DLG和iDLG两种梯度隐私攻击方法。
4 结论
本文提出一种基于区块链和梯度压缩的去中心化联邦学习模型。首先,利用区块链存储训练数据,并采用全局模型本地更新的方式代替传统中心服务器。其次,因区块链网络传输数据效率较低且局部模型中存在大量冗余数据,提出梯度压缩算法,在确保模型准确率的前提下减少各训练参与方的传输数据量,并有效保护了梯度隐私。最后,为减弱梯度压缩对全局模型收敛速度的影响,采用热身训练的方式加快模型收敛。经实验证明,本文所提出的联邦学习模型在保证准确率的情况下减少了数据传输且提升了联邦学习训练效率。
然而,基于区块链和梯度压缩的联邦学习模型仍存在一些不足,在全局模型更新时,等待其余参与方上传局部模型的过程中可能需要耗费大量时间,此过程也会减慢联邦学习的效率。在接下来的工作中将采用激励机制和异步更新的方法进行研究,以提高模型的效率。
参考文献:
[1] MCMAHAN H B, MOORE E, RAMAGE D, et al. Federated learning of deep networks using model averaging[EB/OL]. (2016-02-17)[2022-09-20]. https:∥arxiv.org/abs/1602.05629.
[2] 刘炜, 唐琮轲, 马杰, 等. 区块链在隐私计算中的应用研究进展[J]. 郑州大学学报(理学版), 2022, 54(6): 12-23.
LIU W, TANG C K, MA J, et al. Application research and progress of blockchain in privacy computing[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(6): 12-23.
[3] 陈明鑫,张钧波,李天瑞.联邦学习攻防研究综述[J].计算机科学,2022: 49(7):310-323.
CHEN M X,ZHANG J B,LI T R.A review of research on attack and defense of federal learning [J].Computer science, 2022: 49(7):310-323.
[4] ZHU L,LIU Z,HAN S.Deep leakage from gradients [M].Federated Learning. Cham: Springer International Publishing, 2019.
[5] ZHAO B, MOPURI K R, BILEN H. iDLG: improved deep leakage from gradients[EB/OL]. (2020-01-08)[2022-09-20]. https:∥arxiv.org/abs/2001.02610.
[6] CHEN M Z, SHLEZINGER N, POOR H V, et al. Communication-efficient federated learning[J]. Proceedings of the national academy of sciences of the United States of America, 2021, 118(17): e2024789118.
[7] HE K M, ZHANG X, REN S Q, et al. Deep residual learning for image recognition supplementary materials[EB/OL]. (2015-12-10)[2022-09-20]. https:∥doi.org/10.48550/arXiv.1512.03385.
[8] MERMER G B, ZEYDAN E, ARSLAN S S. An overview of blockchain technologies: principles, opportunities and challenges[C]∥The 26th Signal Processing and Communications Applications Conference. Piscataway: IEEE Press, 2018: 1-4.
[9] HU S L, LI J F, ZHANG C X, et al. The blockchain-based edge computing framework for privacy-preserving federated learning[C]∥IEEE International Conference on Blockchain. Piscataway: IEEE Press, 2022: 566-571.
[10]SUN J, WU Y, WANG S P, et al. Permissioned blockchain frame for secure federated learning[J]. IEEE communications letters, 2022, 26(1): 13-17.
[11]PENG Z, XU J L, CHU X W, et al. VFChain: enabling verifiable and auditable federated learning via blockchain systems[J]. IEEE transactions on network science and engineering, 2022, 9(1): 173-186.
[12]LI J, SHAO Y M, WEI K, et al. Blockchain assisted decentralized federated learning (BLADE-FL): performance analysis and resource allocation[J]. IEEE transactions on parallel and distributed systems, 2022, 33(10): 2401-2415.
[13]LIU Y H, QU Y Y, XU C H, et al. Blockchain-enabled asynchronous federated learning in edge computing[J]. Sensors, 2021, 21(10): 3335.
[14]SHLEZINGER N, CHEN M Z, ELDAR Y C, et al. UVeQFed: universal vector quantization for federated learning[J]. IEEE transactions on signal processing, 2021, 69: 500-514.
[15]CUI L Z, SU X X, ZHOU Y P. A fast blockchain-based federated learning framework with compressed communications[J]. IEEE journal on selected areas in communications, 2022, 40(12): 3358-3372.
[16]DESAI H B, OZDAYI M S, KANTARCIOGLU M. BlockFLA: accountable federated learning via hybrid blockchain architecture[C]∥Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy. New York: ACM Press, 2021: 101-112.
[17]CHEN T Y, SUN Y J, YIN W T. Communication-adaptive stochastic gradient methods for distributed learning[J]. IEEE transactions on signal processing, 2021, 69: 4637-4651.
