
基于深度学习的教育政策用户评论细粒度情感分析研究
2024-08-12 00:00:00吴运明张琳胡凡刚
中国电化教育 2024年7期
摘要:智媒时代微博、抖音等网络社交媒体平台成为政府与公众之间传递信息的重要渠道之一,公众在平台上对教育政策的评论影响着教育政策的实施进程、效果及后续政策的出台。融合主题模型LDA和深度学习模型LSTM,以“双减”政策为例,挖掘面向教育政策的网络社交媒体用户评论,并对其进行细粒度情感分析,剖析用户对教育政策的多维主观情感,为提升教育政策实施效果提供参考。研究发现,网络社交媒体用户对“双减”政策的舆论焦点主要集中在四个主题下的16个评论对象上,其中在素质教育、艺术活动、学历3个方面用户情感偏向于正向;在校外培训、课后服务、教育公平、贫富差距、就业等其余13个方面用户情感偏向于负向。
关键词:LSTM模型;LDA模型;情感分析;教育政策
中图分类号:G434 文献标识码:A
一、引言
近年来随着微博、抖音等网络社交媒体的飞速发展,国家的各种教育政策一经颁布迅速引起社会广泛网络舆情关注,诸如《关于进一步减轻义务教育阶段学生作业负担和校外培训负担的意见》《校外培训行政处罚暂行办法》等。教育政策是由政府及其机构和官员制定的、调整教育领域社会问题和社会关系的公共政策[1],对实现教育公平,进而实现社会公平有很大助益,可以为每个人提供平等的机会,使得每个人都能够获得优质的教育资源,帮助他们更好地适应社会和就业市场。然而,教育政策在积极推动构建良好教育体系的同时,也引发一些现实问题,让人们对教育政策的制定及实施产生负面舆论,这些舆论导致教育政策执行和决策的变化[2],给教育改革带来了新的问题。因此,挖掘网络社交媒体用户针对教育政策的评论文本,从用户所谈及的各方面对相关评论文本做细粒度情感分析,并及时针对用户舆论调整教育政策的决策和实施,对全面推进教育改革具有重要的价值和意义。
用户评论细粒度情感分析是通过对用户评论主题抽取、情感分析,实现更加精准的情感分类。目前针对教育政策产生的舆论进行情感分析的研究较少,已有研究大多关注一般领域的舆论情感分析。部分学者尝试将主题抽取模型与情感分析模型相结合对文本内容的情感分析。如彭云等[3]构建了一种名为SWS-LDA的主题模型,以期提高对特征词、情感词和它们之间关系的识别能力,进而提高该主题模型的情感极性分类准确性。苏莹等[4]结合了朴素贝叶斯模型和隐含狄利克雷分布模型,能够在不需要篇章和句子级别的标注信息的条件下,只需使用适当的情感词典就可以分析网络评论的情感倾向。另有部分学者利用基于机器学习的情感分析方法,包括深度神经网络、卷积神经网络、递归神经网络等[5],通过在原基础上不断改进算法以实现对评论的细粒度情感分类。如王义等[6]提出了一种细粒度多通道卷积神经网络模型,以词性向量和细粒度字向量为辅助输入,使用原始词向量来捕获句子间的语义信息,从而实现更加准确的文本情感分析。李慧等[7]、蔡庆平等[8]分别基于CNN构建了不同的面向产品评论的细粒度情感分析模型,从而能够比较全面地获得产品评论中有关多方面产品特征的情感倾向。针对教育政策用户评论情感分析的研究,偏重于改良或融合已有的理论或技术进行情感分类。例如,李沅静等[9]利用朴素贝叶斯、支持向量机等四种模型对“双减”短文本评论进行情感分析。辛明远等[10]将LDA模型中得到的主题向量与BERT词向量模型相结合,并融入CNN卷积层处理,对“双减”政策的舆论进行分类和提取主题词。已有相关研究中,部分与主题抽取相结合进行情感分析,另一部分侧重于从模型入手改进具体算法,仍以传统的情感强度值为依据划分情感,从而得到细粒度情感分析结果。上述情感分析方法虽然从整体上细化了用户对某一教育政策的态度,但无法全面地呈现用户在特定方面的不同情感。因此,本研究拟将深度学习模型中的LSTM(Long ShortTerm Memory,长短期记忆)模型与LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)主题模型相结合,挖掘网络社交媒体用户对某一教育政策的用户评论,实现在各舆论主题下多个方面的细粒度情感分类,以期助力政策制定者更深入地了解公众的需求和关注点,为后续政策的全面落实提供参考依据,并通过情感分析获得的数据调整政策宣传和推广的方式,切实增强公众对教育政策的认同感和满意度。
二、基于深度学习模型的教育政策用户评论细粒度情感分析研究设计
(一)理论基础
深度学习LSTM模型由Sepp Hochreiter和Jurgen Schmidhuber提出[11],后被Alex Graves、Haim Sak等人逐步改进并予以应用,是RNN(Recursive Neural Network,循环神经网络)的一种特殊类型,具有记忆长短期信息能力的神经网络。相较于RNN,LSTM解决了长期依赖问题,可以学习长期依赖信息。LSTM模型的核心是由一个记忆单元和三个门组成的重复模块[12],通过门对记忆单元状态进行删除或添加信息。记忆单元能够使LSTM模型存储、读取、重置和更新长距离历史信息,输入门控制信息是否流入记忆单元中,遗忘门控制上一时刻记忆单元中的信息是否需要积累到当前时刻的记忆单元中,输出门则决定当前时刻记忆单元中的信息是否应该流入当前隐藏状态中。这些机制协同工作,使LSTM具有更好的处理长时间序列数据的能力,其结构如图1所示。

其中,Bt-1是单元状态,表示长期记忆,可以控制信息传递给下一时刻;ht-1是上一次的状态,表示短期记忆;xt指本次输入;ft、it、ot分别为遗忘门、输入门和输出门。
(二)研究设计
本研究构建了一个融合深度学习LSTM模型和主题抽取LDA模型的教育政策用户评论细粒度情感分析框架,包括用户评论采集、评论文本预处理、基于LDA模型主题抽取、基于主题词的评论文本分类、基于LSTM模型情感分类5个模块,具体如图2所示。
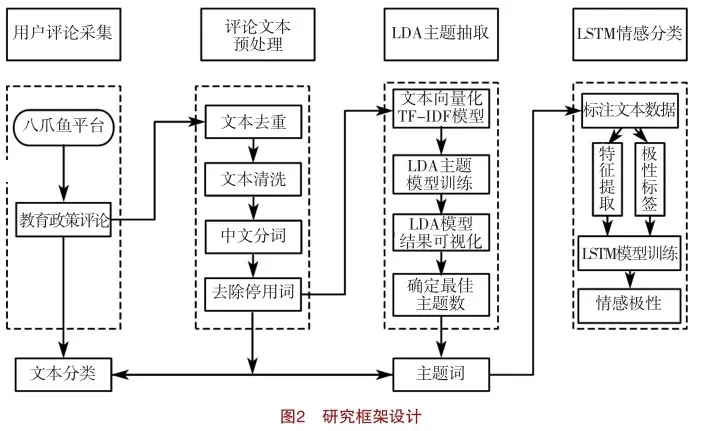
1.教育政策用户评论数据采集与预处理
数据收集与预处理主要包括数据采集、清洗和预处理三阶段,其中数据预处理分为中文分词和去停用词两个步骤,从而形成可进行情感分析和挖掘文本主题的语料库。首先,利用文本采集工具抓取微博、抖音、哔哩哔哩、知乎等网络社交媒体中用户有关某一教育政策的生成内容;然后,对数据做如下处理:(1)去重文本数据。由于抓取的评论数据会存在重复值,需要将重复的评论数据剔除,确保数据的唯一性。此外,对于评论中存在连续重复的词汇表达时,如“支持支持支持支持支持”,将其压缩为“支持”。(2)清洗文本数据。部分评论可能无法采集完整,即为缺失评论;再者,部分评论文不对题,或者仅使用特殊符号、颜文字、表情包等,此视为无效评论;另有部分评论内容极为简短,使用无意义的词汇,如“哈哈”“无语”等,无法识别出其具体表意,本研究也将其视为无效评论。清洗数据即删除信息缺失、无效的评论。(3)中文分词。利用Python中的Jieba分词包对用户评论数据进行分词。(4)去停用词。停用词是指在不同文本内容中出现频率较高的,但不具备实质性意义的词语或符号,例如“只是”“如果”“可以”等词,以及各种标点符号、数字等,通常在进行文本处理任务如分类、聚类、情感分析等前,需要对文本进行去停用词处理,减少冗余信息,提高分析的精度和效度。使用基于词表的去除法,将分词后的词语与停用词表进行比较,如果在分词结果中有存在于停用词表中的词语,则将其删除。
2.基于LDA模型的教育政策用户评论主题抽取
LDA模型是一种文档主题生成模型,属于无监督学习模型,包含词项、主题和文档三层结构,可以用来识别大规模文档集或语料库中潜藏的主题信息。它采用了词袋方法,将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。将每篇文档看作各种隐含主题的混合,而每个主题则表现为与该主题相关的词项的概率分布[13]。在实际分析过程中,先通过现有的文章训练出LDA模型,提取出相应的主题,再用模型预测新的文章所属主题分类。
基于LDA模型进行主题聚类的主要目的是通过对网络社交媒体用户评论的主题挖掘,得到聚类后的主题及每个主题下的主要关键词,从中得知网络社交媒体用户在谈及某一教育政策时所关注的各个方面,为后续进行细粒度情感分析划分多层次维度提供依据。(1)LDA模型参数及最佳主题数选择。Dirichlet先验α和β常按照经验值进行设置,而主题个数的取值对于模型性能和主题挖掘效果有着重要影响。目前相关研究在确定主题数时通常基于先验知识对文档包含的主题数进行初步估计,再结合困惑度、一致性以及主题间相似度等质量评价方法做出选择[14]。困惑度的大小与模型性能成反比,一致性的大小与模型性能成正比。本研究先根据经验判断主题个数,进而训练LDA模型,计算一致性数值,然后使用pyLDAvis包对模型进行可视化,根据呈现的主题气泡分布情况,确定最终主题个数。(2)LDA模型构建。使用TF-IDF算法在文本预处理后的语料中提取关键词,生成词频矩阵;通过LdaModel函数构建LDA模型,设定合适的主题数、迭代次数等参数;为了使聚类结果更加直观,利用pyLDAvis包对结果进行可视化,呈现各个主题在模型空间中的相互关系和重要性;为提高模型质量,可多次调整参数迭代训练,完成LDA主题聚类。
3.基于主题词的教育政策用户评论文本细粒度划分
根据得到的最佳主题数对已抽取的主题词进行筛选,并据此对预处理后的用户评论进行归类,实现评论文本的细粒度划分,为后续采用LSTM对面向教育政策的用户评论进行细粒度情感分析做准备。(1)主题词筛选。通过LDA主题模型算法确定最佳的主题数,抽取出与之相关的主题词,去除重复、无关、低频主题词,构建更具意义的主题类别。(2)将评论切分成短句。对于每条用户评论,根据标点符号将其拆分成若干个短句,以达到更细粒度的文本表示,提高后续细粒度情感分析的精确度。在拆分时需注意,同一句话内部出现多次标点符号,需要基于语法规则进行修正,并去除短句中的空格、制表符和回车符等不必要的空白字符。(3)短句文本分类。将切分后的评论短句按照主题词进行归类,将包含该类别主题词的所有短句视为同一个类别。
4.基于深度学习模型LSTM的教育政策用户文本情感分析
为获取网络社交媒体用户对教育政策多层面的情感态度,本研究采用深度学习模型中的LSTM模型对各主题下的网络社交媒体用户评论文本进行正向、负向情感极性分析。首先,需要将原评论文本按主题分类,部分评论可能出现在不同的主题下;然后,按照上述预处理步骤再次对文本内容进行分词和去停用词;最后,构建LSTM模型,分别判断不同主题下各类文本的情感倾向,数值趋近0为负向,趋近1为正向。
LSTM模型构建过程:
(1)使用词向量训练模型Word2Vec训练语料以获得词向量。Word2Vec能够将由文本转化为的稀疏矩阵的向量维数进行缩减,从而得到每个词所对应的低维向量,即词嵌入过程,这种低维向量更适合深度学习模型的训练。
(2)导入torch库构建深度学习模型。LSTM模型的参数中有三个是必须设置的:一是输入特征维度input_size,如果将一个句子作为输入,每个词都被转换为一个向量,则该值为每个词向量的维度;二是隐藏层状态的维度hidden_size,即每个时间步长LSTM单元输出的状态向量的维度,通常会根据数据集的大小和模型的复杂度来设置该参数;三是LSTM堆叠的层数num_layers,该值越大,模型的复杂度越高,但同时也会增加训练时间和计算资源的消耗。需要注意的是,LSTM还有其他可供设置的参数,如序列长度、Dropout率等,这些参数的设置要根据具体任务需求和数据情况进行调整。
(3)定义BCELoss损失函数和Adam优化器。nn.BCELoss()是二分类交叉熵损失函数,模型只能输出两种可能的结果,如正面情绪和负面情绪、垃圾邮件和非垃圾邮件等,将数据标签定义为0和1,其中0代表第一种输出,1代表第二种输出。torch.optim.Adam()是Adam优化算法的实现,用于更新模型的权重和偏置等参数,在使用torch.optim.Adam()时,需要将模型的参数传入,同时可以设置学习率、权重衰减因子、动量参数等超参数。
(4)迭代训练LSTM模型,在每个epoch循环中,先将数据输入模型进行前向计算,然后根据预测结果和真实标签计算损失,并进行反向传播更新模型参数。同时训练过程中会输出测验后的loss、accuracy等信息,可根据这些信息重新定义参数,再次训练模型。
5.结果评价
将上述研究框架应用于具体教育政策进行细粒度情感分析,并采用各类指标对分析结果进行评价,包括对LDA主题抽取结果和LSTM情感分析结果的评价。
LDA主题抽取的目的是将文本数据划分为多个主题,并进一步了解这些主题的内容和特征。评价LDA主题抽取结果的方法和标准具体取决于分析的目的,以下为常用于评价LDA主题抽取结果的指标[15]:(1)主题的数量:主题的数量影响到了LDA模型的复杂度和解释性,如果主题数量过多,可能会使得主题之间的界限变得模糊不清,难以解释;反之,如果主题数量过少,则可能无法涵盖所有关键信息。(2)单词分布:主题中所包含单词的分布也是一个重要的指标,主题内部单词的分布应该尽量集中在某些关键词上,而非分布均匀、散落不定。(3)主题一致性和可解释性:在各个主题之间应该确保连贯性,即每个主题所包含的单词都应该与整个主题相关联,对于每个主题来说,需要检查其包含的单词是否能够解释该主题所代表的内容,如果主题中包含的单词没有明显的共性,可能会造成解释上的困难。
LSTM情感分类的目的是对文本数据进行情感判断,并将其归类为积极、消极或中性等不同类别。评价LSTM情感分类结果需要根据具体需求选取适合的评价指标进行综合考虑,以确保分类结果的准确性和可靠性,以下是一些常见的指标[16]:(1)准确率:通过准确率可以很好地反映出模型的整体分类效果,但可能会受到数据集分布不均等问题的影响,因此需要结合其他评价指标进行综合分析。(2)精确率和召回率:用于评估二元分类模型性能的两个重要指标,这两个指标结合使用可以更全面地评估分类器表现,需要根据具体情况权衡取舍。(3)F1值:F1值是精确率和召回率的调和平均值,可以对分类器的性能进行综合评估。
三、用户评论细粒度情感分析——以“双减”政策为例
(一)数据采集与预处理
使用八爪鱼采集器抓取来自微博、知乎、抖音、哔哩哔哩等网络社交媒体有关“双减”政策的评论,具体包括的字段有:评论内容、用户名、发表时间、开课阶段、点赞数,采集完成后将数据导出。共抓取了22876条评论数据,经过数据去重和清洗后获得有效数据18189条,部分采集数据如表1所示。
使用jieba库进行分词处理。为使分词结果更加确切有效,在词典中添加“双减政策”“素质教育”“培训机构”等自定义词汇;调用jieba.cut函数,设置分词模式为精准模式进行分词;由于单字词包含信息量较少,需将单字词过滤掉;在分词处理后,选用百度停用词表,剔除分词结果中的特殊符号等无实质性意义词汇,得到最终的分词结果。部分评论分词结果如图3所示。

(二)用户评论主题抽取
利用Python拟合LDA模型。首先根据文本内容主题分布情况粗略设定主题数为10,遍历语料库的次数为100,列出在线评论集合中最重要的10个主题及每个主题的若干关键词,进而进行可视化处理。由于聚类出的主题交叠现象较为严重,为选取最佳主题数,通过计算一致性数值,并绘制主题-coherence曲线,选择最佳主题数为4。最终抽取4类主题。
根据主题聚类结果,得到表2所示的四个主题及每个主题下最重要的10个主题特征词。

(三)用户评论文本分类
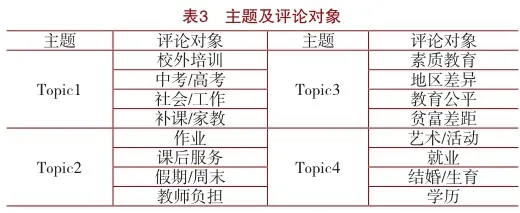
对上述抽取出的主题词进行筛选,去除无研究意义的词汇,将表意重复的多个主题词聚类为一个词语作为所要进行情感分析的层面之一,最终聚合为每个主题下的4个评论对象,如表3所示。
将评论文本切分成短句,对切分后的句子进行修正,并去除短句中的空格、制表符和回车符等不必要的空白字符,同时设定短句长度最小值为5,删除无具体意义的过短语句,从而使每个短句语义完整且仅涉及对“双减”政策一个方面的意见。具体切分实例如表4所示。

根据评论对象对切分后的评论文本进行筛选,包含同一评论对象的短句作为一个类别,从而完成用户针对“双减”政策舆论的细粒度划分。
(四)主题文本情感分析
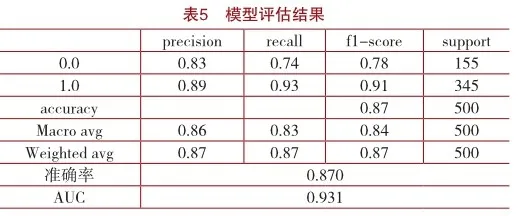
将数据集分为训练集和测试集,占比为9:1。导入必要的torch、gensim等库,加载数据,预训练得到Word2Vec词向量。在定义LSTM模型类时,传入以下参数:learning_rate=5e-4;input_size=768;num_ epoches=5;batch_size=100;embed_size=64;hidden_ size=64;num_layers=2,迭代训练神经网络,并在测试集进行效果检验。本研究采用准确率(Precision)、召回率(Recall)和F1值(f1-score)评估分类模型性能,模型评估结果如表5所示。从表5可以看出负向情感和正项情感分别训练模型结果在准确率上分别为0.83和0.89,总体的F1值也达到了0.87,达到良好的效果。每个主题下的准确率(Precision)、召回率(Recall)和F1值的Macro Average(宏平均)值均在0.8以上,达到良好的水平。Weighted Average(加权平均)是指对每个主题类别分别计算指标,然后取这些指标的加权平均值。从加权平均值计算结果也可以看出均为0.87,达到了良好的效果。AUC用于衡量分类器对于区分两个类(正类和负类)的能力,介于0和1之间,其值越高表示模型的分类性能越好。从表5的计算结果看出AUC值为0.931,说明模型在进行正负类分类时,效果非常好。综上所述,本研究构建的主题情感细粒度分类模型具有良好的分类效果。
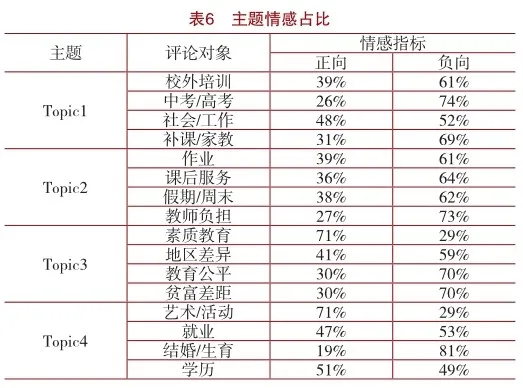
利用已训练完成的LSTM模型,输入各类别下的文本内容,判断用户评论的情感倾向,统计四类主题下相关评价对象正向、负向情感的评论比例。如表6所示,得到具体主题词的情感量化值,例如用户在“素质教育”的话题评论中明显的偏向于正向,而在 “升学考试”话题中的评论情感则偏向于负向。因此,出于用户对“双减”政策的情感需求,相关机构在促进政策落实时,需要重点关注该政策对中考高考的消极影响,并在下一步执行计划中实施改进措施。
(五)结果讨论与分析
1.用户对主题1下“校外培训”“中考高考”“社会工作”“补课家教”四个方面舆论的评价情感倾向均偏向于负向
首先,“双减”政策明确规定了义务教育阶段教育质量保障机制,将禁止校外培训机构开展与义务教育阶段内容和形式相关的培训业务,这意味着校外培训机构无法再在中小学教育领域大肆招生,可能会导致一些校外培训机构生存压力增加或者面临关闭,增加一批失业人员。“双减”政策实施后,不仅校外培训机构会受到冲击,普通中学升学考试科目和升学政策也可能会有所调整,这些变化都会影响到中考和高考的录取标准和招生政策[17]。对校外培训有较强依赖性的学生将会面临更大的学业困难,许多学生家长想通过让孩子参加校外培训提高学习成绩的计划被阻塞,这引起了众多家长和学生的不满,这也间接导致一批学生放弃升学,被迫早早地进入社会谋求工作,尤其是家境普通的学生。对于家境殷实的家庭,家长可能会采取较为隐蔽的方式,花较高的价钱聘请学历高、能力强的一对一家教,这在某种程度上加剧了教育资源分配不均衡的现象[18],造成优势学生与劣势学生之间的差距进一步拉大。特别是在当下,学历已然成为职业岗位的敲门砖,那些放弃升学的人也会面临巨大的就业压力。
2.用户对主题2下“作业”“课后服务”“假期周末”“教师负担”四个方面的舆论均偏向于负向情感
据现有调查研究显示,该政策实施后中小学生作业量明显减少。这在一定程度上缓解了学生焦虑情绪[19]。但研究结果显示,61%的家长和学生表示政策实施后在作业减负方面并没有起到一定的效果。有许多学校将超负的部分作业转化为各种形式发布给学生,从表面看学生的书面作业确实减少了,但学生的作业压力并没有减少。在“课后服务”方面,根据孟晶等[20]对小学教师课后服务认同现状的调查,存在教师对学校课后服务的执行方式认同偏低、学校课后服务的执行主体单一、学校课后服务的内容脱离教师实践等一系列问题。部分人认为课后服务是形存实亡,例如,学校利用课后服务时间并不是在帮助学生巩固复习、辅导作业,而是强制要求学生参加以便于老师讲解新课,而且有很多学生抱怨课后服务的时间过长。张妍等[21]也认为义务教育学校课后服务仍面临课后服务制度规范亟待完善、课后服务人员权责有待厘清、课后服务保障体系有待健全等现实难题。若不抓紧解决这些问题,不仅不会减压,反而会增加学生的学业压力。不仅如此,“双减”政策在某些方面也加重了教师的负担,教师在完成日常的教学任务之后,会以监督学生完成作业的方式参与课后服务工作,这种延时工作难免会让教师感到时间紧张,难以合理分配精力。在“假期周末”方面,部分人表示由于早已习惯了在假期、周末补课,在取消校外培训后自己在放假期间无所事事;部分人表示原本计划在周末的补课被迫调整到了学周中,或者有的直接没有做任何调整,仍然利用周末假期进行补课,并没有达到减负的效果。
3.用户对主题3下的舆论在“地区差异”“教育公平”“贫富差距”方面为负向情感,在“素质教育”方面偏向于正向情感
用户舆论在“地区差异”“教育公平”“贫富差距”方面的情感偏向于负面,反映了现有教育资源不均衡、教育不公平等缺陷,引起该现象产生的因素即为地区差异、贫富差距,而这两个因素同时也是导致用户负面情感出现的具体原因。
首先,在一些较为发达的一线城市,如北京、上海等地作为政策试点地区,“双减”政策相对落实到位,相关部门对政策实施过程进行全面监管,同时创新各种举措,不断探索政策落地途径。而在其他不同的地区,政策的落实情况及面对的难题也各有不同,例如根据江西省教研室的调查显示,97.8%的学生学习及整体状况呈现出良好的态势,但65.31%的教师表示工作负担加重,也要求学校整体改进教育教学制度[22];据昆明市相关部门的调研,虽然有超过95%的学生和家长对昆明市“双减”工作满意,但仅有29.59%的学生认为没有作业负担,47.28%的学生不参加校外培训[23]。同时,由于城乡教育发展的不均衡以及农村优质教学资源的短缺,使得“双减”政策在农村与城市的实施无法一概而论[24],“双减”工作在乡镇学校的推进仍存在问题。陆芳等对比城市和乡镇教师就“双减”政策落实情况的评估,采用卡方检验获得的结果表明,城市学校实施课后服务的比例显著高于乡镇,而更多的乡镇教师认为“双减”实施后“基本没有变化”[25]。由此可知,“双减”工作的开展情况存在一定的城乡差异。
此外,贫富差距影响着教育资源的获得。自“双减”政策发布以来,我国对校外培训机构进行了大力压缩,有证机构积极转型调整,而无证机构则完全停止了培训行为,扭转了校外培训过多过滥的局面,学科类培训机构大幅压减[26]。这就导致大部分平价且小有成效的校外教育机构要接受改制调整,同时引起家长焦虑,在这种局面的刺激下较为富裕的家庭争先招聘学历高、能力强的私人家教,而一对一辅导所要花费的金额远远超过之前的大班授课,大部分普通家庭难以承担这笔支出,因此会在一定程度上拉大贫富两类家庭孩子的教育水平,引发了新的教育公平问题。
在“素质教育”方面用户评论的情感倾向偏向于正向,虽然“双减”政策会对素质教育的发展带来挑战,但大部分群众都认为“双减”政策对于推进素质教育具有积极的促进作用,例如,学校能够通过优化课程设置、增加运动场地和基础设施等方式,开展多元化的课外活动、设计并组织各种形式的文体娱乐项目以及提供丰富的实践机会等,以充分发掘学生的个性和特长,培养学生的创新精神和实践能力,从而促进学生的全面发展。“双减”政策还会协调家校社共同推进素质教育发展。不少学校为落实好“双减”政策进行教育教学改革的实践探索。让“学校回归教育主阵地”是家校社协同育人的根本前提,因此该政策能够密切家校社合作关系,实现家校社协同育人功能[27]。此外,也有利于转变教育观念、改进教学模式,最重要的是遏制了私立教育的无限发展,缩小了教育差距。由此看来“双减”政策在义务教育阶段的中小学取得了一定的成效。正基于此,大众也寄望将该政策推广到高中阶段。
4.用户对主题4中 “艺术体育”“学历”方面舆论偏向于正向情感,对“就业”“结婚生育”方面偏向于负向情感
“双减”政策的一个重要目标是减轻学生校外培训的负担,为此,该政策规定在一年内有效减轻中小学生的课外负担,并关闭不合规的校外学科类培训机构,同时规范和完善校内教育体系。一方面,这有利于优化教育体系结构、促进教育改革、全面开展素质教育,有助于减少青少年儿童的学业负担,释放他们活泼好动的天性,保护他们健康成长,这也是部分大众支持该政策的原因。另一方面,许多人持反对意见,在家长层面,“让孩子赢在起跑线上”这句话深入人心,激发了家长之间的竞争心,又由于各个家庭的收入水平不同,管制校外辅导机构对他们来说自然不是一件值得欢喜的事情;在社会层面,管制校外辅导机构导致一大批从业者失业[28],其中师范类专业毕业者居多,对即将毕业的大学生来说失去了一条就业之路,在教师编制门槛十分难过的现状下,唯有选择考研是一个延缓就业的最佳道路,然近年考研人数急剧增长、考研难度升级,使得这些人群对“双减”持有负面情绪。另外,该政策引起了家长甚至一个家庭内部的焦虑。一方面,由于家长对升学率高度关注和家长间的不断竞争,加之人们历来对职业学校的不重视,而在就业时招聘公司又格外注重应聘人员的学历,因此人们对该政策产生了抱怨情绪,认为国家推行“双减”政策的目的是补给社会劳动力,让部分大学生甚至是中学生直接选择就业,而非升学。然而就业市场竞争激烈,许多年轻人需要更长的时间来找到稳定的工作,这可能迫使他们推迟结婚和生育的计划。随着“双减”政策的推进,义务教育质量得到提升,家长更注重子女教育,因此一些家长希望在子女教育上投入更多的时间和精力,这也可能导致他们在较晚的时候才考虑结婚和生育的问题,以保证能够承担高额的教育花费。
综上,网络社交媒体用户对“双减”政策的舆论焦点主要集中在4个主题、16个评论对象上,在“素质教育”“艺术活动”“学历”3个方面用户情感偏向于正向;在“校外培训”“课后服务”“补课家教”“作业”“假期周末”“教师负担”“中考高考”“社会工作”“地区差异”“教育公平”“贫富差距”13个方面用户情感偏向于负向。
四、结语
针对教育政策用户评论文本的情感分析,本研究提出了融合LSTM深度学习情感分析与 LDA主题挖掘的细粒度情感分析框架,对从微博、知乎以及抖音等平台抓取的教育政策用户评论文本数据进行情感分析。借助LDA模型对用户评论文本进行主题分类,为下一步细粒度情感分析划分层面提供依据,进而利用LSTM模型分析各层面用户评论的情感态度。LSTM模型需要在人工标注相关数据的前提下进行构建才能细粒度地识别用户评论中的情感倾向,未来将对深度学习模型进行优化,利用半监督和无监督学习方法,进一步提高情感分类的速度和准确度。
目前,我国正在大力推动“双减”政策的落实,本研究有助于指明进一步推动“双减”政策实施的方向、有针对性的强化政策操作与执行力度。根据上述分析,笔者提出以下几点建议:
(1)关注公众舆论方向,及时调整教育政策实施重点和方向。政府机构应当密切关注社会各界对于教育政策执行效果和社会影响的反馈意见和舆情动态,及时收集、分析和应对各种声音和反馈,以更好地倾听民意,保障教育政策实施的公正性和透明度。同时,根据实际情况和社会反馈及时调整和优化教育政策的执行重点和方向。在教育政策实施过程中不断完善政策措施,加强督导检查,并能够灵活地进行调整,避免产生不利影响,确保教育政策目标的顺利实现。
(2)加强教育政策执行监管、督导力度,保证不同地区以及同一地区的城乡学校齐头并进。政府机构应当建立科学有效的管理制度和监管体系,从制定、实施到评估各个环节都要健全规范,落实责任制,加强数据统计与分析,确保教育政策执行的科学性、公正性和可行性。增强信息公开和沟通机制,加强与社会各界的沟通,提高透明度,及时发布教育政策信息和执行情况,并注重对“双减”政策和后续政策的宣传和普及,为公众了解政策目标、内容和效果提供便利,树立政府公信力和形象。有关部门也应该加大对“双减”政策的解读和宣传力度,提高社会各界对政策的认知度和支持度。其次,学校之间的资源配置应按照实际需求和情况进行调整,确保各个地区、各个学校的教育资源均衡配置。政府要给予学校更多的自主权和管理权限,让学校自主管理,依法依规治理,详细制定必要的工作计划和标准,以规范化、科学化的方式推进教育政策的实施。
(3)发展社会经济,缩小贫富差距,促进教育资源合理分配。实施“双减”政策需要配合发展社会经济,通过发展经济来缩小贫富差距,进而促进教育资源合理分配。政府应该制定明确的政策措施,通过财政补贴、资源配置等方式,加强教育资源的公平性,确保资源的合理分配,让每个学生都能够享受到公平的教育机会,同时加大对于贫困地区的教育投入,提升贫困地区的教育资源质量,让贫困地区的学生也能够享受到优质的教育资源。
参考文献:
[1] 刘复兴.教育政策的边界与价值向度[J].清华大学教育研究,2002,(1):70-77.
[2] 蒋建华,崔彦琨,王鐘.舆论、教育政策与教育治理现代化[J].教育研究,2021,42(11):132-137.
[3] 彭云,万红新,钟林辉.一种语义弱监督LDA的商品评论细粒度情感分析算法[J].小型微型计算机系统,2018,39(5):978-985.
[4] 苏莹,张勇等.基于朴素贝叶斯与潜在狄利克雷分布相结合的情感分析[J].计算机应用,2016,36(6):1613-1618.
[5] 谭翠萍.文本细粒度情感分析研究综述[J].大学图书馆学报,2022,40(4):85-99+119.
[6] 王义,沈洋,戴月明.基于细粒度多通道卷积神经网络的文本情感分析[J].计算机工程,2020,46(5):102-108.
[7] 李慧,柴亚青.基于卷积神经网络的细粒度情感分析方法[J].数据分析与知识发现,2019,3(1):95-103.
[8] 蔡庆平,马海群.基于Word2Vec和CNN的产品评论细粒度情感分析模型[J].图书情报工作,2020,64(6):49-58.
[9] 李沅静.基于二阶隐马尔可夫模型的文本情感分析及其在“双减”政策中的应用[D].安庆:安庆师范大学,2023.
[10] 辛明远,刘继山.基于BERTCNN-LDA模型的舆情检测方法——以双减政策为例[J].信息与电脑(理论版),2022,34(2):59-6m9uRuPBbEDk6W9AbU1UUUQ==3.
[11] Sepp H.Jurgen S.Long Short-Term Memory.Neural Computation,1997,9 (8):1735-1780.
[12] 朱光,刘蕾,李凤景.基于LDA和LSTM模型的研究主题关联与预测研究——以隐私研究为例[J].现代情报,2020,40(8):38-50.
[13] Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation [J].Journal of Machine Learning Research,2003,3:993-1022.
[14] 张东鑫,张敏.图情领域LDA主题模型应用研究进展述评[J].图书情报知识,2022,39(6):143-157.
[15] 关鹏,王曰芬,傅柱.不同语料下基于LDA主题模型的科学文献主题抽取效果分析[J].图书情报工作,2016,60(2):112-121.
[16] 冯兴杰,张志伟,史金钏.基于卷积神经网络和注意力模型的文本情感分析[J].计算机应用研究,2018,35(5):1434-1436.
[17] 贾伟,屈宸羽,蔡其勇.“双减”背景下家长作业焦虑问题还存在吗——基于扎根理论对C市9区1648名家长的实证研究[J].中国电化教育,2023,(5):95-104.
[18] 朱新卓,骆婧雅.“双减”背景下初中生家长教育焦虑的现状、特征及纾解之道——基于我国8省市初中生家庭教育状况的实证调查[J].中国电化教育,2023,(4):49-56.
[19] 宁本涛,杨柳.中小学生“作业减负”政策实施成效及协同机制分析——基于全国30个省(市、区)137个地级市的调查[J].中国电化教育,2022,(1):9-16+23.
[20] 孟晶,杨宝忠.小学教师对课后服务的认同困境与路径[J].教育理论与实践,2023,43(11):28-32.
[21] 张妍,曲铁华.义务教育学校课后服务:功能议题、现实审思与未来进路[J].当代教育科学,2023,(2):73-80.
[22] 徐承芸,林通.“双减”政策实施后师生现实状况审思——基于对江西省部分小学师生的调研分析[J].基础教育课程,2022,(7):14-20.
[23] 杜仲莹.学生和家长对“双减”工作满意度超95%[N].昆明日报,2022-04-17(01).
[24] 薛海平,师欢欢.起跑线竞争:我国中小学生首次参与课外补习时间分析——支持“双减”政策落实的一项实证研究[J].华东师范大学学报(教育科学版),2022,40(2):71-89.
[25] 陆芳,张莉等.中小学校“双减”实施情况、存在问题及对策——基于江苏省的实证分析[J].天津师范大学学报(基础教育版),2022,23(4):25-30.
[26] 梁凯丽,辛涛等.落实“双减”与校外培训机构治理[J].中国远程教育,2022,(4):27-35.
[27] 陈晓慧.“双减”时代智能技术的可为与能为——基于“家—校—社”协同育人视角[J].中国电化教育,2022,(4):40-47.
[28] 薛二勇,李健,刘畅.“双减”政策执行的舆情监测、关键问题与路径调适[J].中国电化教育,2022,(4):16-25.
作者简介:
吴运明:副教授,在读博士,研究方向为教育数据挖掘与应用。
张琳:在读硕士,研究方向为教育数据挖掘与应用。
胡凡刚:教授,博士后,博士生导师,副校长,研究方向为教育虚拟社区理论与实践、教育大数据应用。
Fine-Grained Sentiment Analysis of User Comments on Educational Policies Based on Deep Learning
Wu Yunming1,2, Zhang Lin3, Hu Fangang2
1.School of Education, Qufu Normal University, Qufu 273165, Shandong 2.School of Communication, Qufu Normal University, Rizhao 276826, Shandong 3.School of Information Science and Technology, Northeast Normal University, Changchun 130117, Jilin
Abstract: In the era of smart media, online social media platforms such as Weibo and Tiktok have become one of the most important channels to transmit information between the government and the public, and the public’s comments on education policies on these platforms influence the implementation process, effect and subsequent policies. By integrating the LDA model and the LSTM model, and taking the“double reduction” policy as an example, the study mines the users’ comments on education policies on online social medias and finegrainedly analyzes the users’ multidimensional subjective emotions towards education policies, so as to provide a reference for improving the implementation effect of education policies. It is found that the focus of online social media users’ opinions on the “double reduction” policy is mainly concentrated on 16 comment objects under four themes, among which the users’ emotions are positive in three aspects, including quality education, art activities, and academic qualifications; and the remaining 13 aspects are negative, such as out-of-school training, afterschool service, education fairness, rich-poor gap, and employment.
Keywords: LSTM model; LDA model; sentiment analysis; educational policy
责任编辑:李雅瑄
