
基于信誉机制的改进PBFT共识算法
2024-07-31 00:00李俊吉张佳琦
计算机应用研究 2024年6期






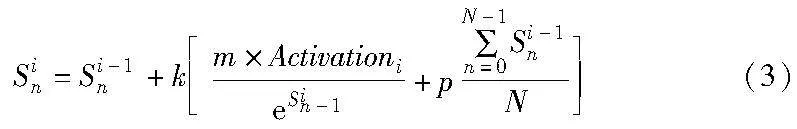

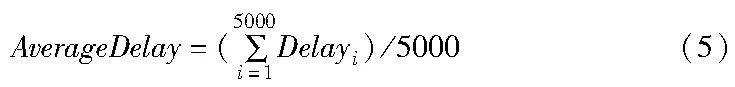


摘 要:针对实用拜占庭容错共识算法(practical Byzantine fault tolerant,PBFT)通信开销大和缺乏奖惩机制的问题,提出一种基于信誉机制的改进PBFT共识算法RPBFT(reputed practical Byzantine fault tolerance)。首先,引入信誉机制对节点评分,将参与共识的节点分为收集器节点和普通共识节点,并对恶意节点进行惩罚。其次,收集器节点负责收集普通共识节点的投票消息,避免普通共识节点之间的通信,从而降低通信开销。最后,当普通共识节点中的拜占庭节点均无恶意行为时,通过增加收集所需的投票数量,减少一次投票收集过程,实现快速共识。实验结果表明,RPBFT能够有效地发现恶意节点并对其作出惩罚,同时具有更低的通信开销、平均共识时延以及更高的共识吞吐量。当节点总数为37时,与SBFT相比,RPBFT将平均共识时延降低25.2%以上,并将共识吞吐量提高39%以上。
关键词:共识算法;信誉机制;实用拜占庭容错
中图分类号:TP311.1 文献标志码:A文章编号:1001-3695(2024)06-004-1628-07
doi: 10.19734/j.issn.1001-3695.2023.11.0517
Improved PBFT consensus algorithm based on reputation mechanism
Abstract:Aiming at the problem that PBFT had high communication overhead and lacks reward and punishment mechanism, this paper proposed a reputed PBFT consensus algorithm (RPBFT) based on reputation mechanism. Firstly, the algorithm introduced a reputation mechanism to score nodes, dividing the nodes participating in the consensus into collector nodes and ordinary consensus nodes, and punishing malicious nodes. Secondly, the collector node was responsible for collecting the voting messages of ordinary consensus nodes to avoid communication between ordinary consensus nodes, thus reducing communication overhead. Finally, when the Byzantine nodes in the ordinary consensus nodes had no malicious behavior, the algorithm achieved a fast consensus by increasing the number of votes required for collection and reducing the process of collecting votes once. The experimental results show that RPBFT can effectively detect and punish malicious nodes, while having lower communication overhead, average consensus latency, and higher consensus throughput. When the total number of nodes is 37, RPBFT reduced the average consensus latency by more than 25.2% and increased consensus throughput by more than 39% compared to SBFT.
Key words:consensus algorithm; reputation mechanism; practical Byzantine fault tolerant(PBFT)
0 引言
近年来,以比特币、以太坊、联盟链等应用为代表的区块链技术成功吸引了众多研究者的关注。区块链本质上是一个去中心化的分布式账本,融合了密码学、P2P网络及共识算法[1~5]等技术。共识算法是区块链去中心化账本和加密货币技术的重要组成部分,保证了区块链的完整性和一致性。
共识算法的研究始于20世纪80年代初,Pease和Lamport等人[6,7]定义了拜占庭将军问题,并提出了两种拜占庭容错共识算法(Byzantine fault tolerance,BFT)。然而,这两种算法的通信复杂度均为指数级,高昂的复杂度使其一直停留在理论研究中。1999年,Castro等人[8]提出实用拜占庭容错共识算法(practical Byzantine fault tolerance,PBFT),解决了原始BFT效率不高的问题,将通信复杂度降低到多项式级,使得BFT在实际系统中应用变得可行。
然而,PBFT仍然存在一些不足。PBFT通信复杂度达到O(N2),其中N表示共识节点总数。这意味着当共识节点总数增加时,通信开销会显著增大,从而降低共识效率。此外,当拜占庭节点出现作恶行为时,PBFT不能提供有效的惩罚措施。
近年来,尽管许多PBFT改进算法[9~13]在一定程度上提高了性能,但它们主要是通过减少共识节点的数量来实现。这种方法虽然提高了效率,但也导致一些节点无法参与共识过程,从而降低了系统的去中心化程度。
因此,本文提出一种基于信誉机制[14]的改进PBFT共识算法RPBFT(reputed practical Byzantine fault tolerance,RPBFT)。首先对RPBFT的节点类型进行说明,并给出信誉机制的设计方案,接着介绍RPBFT的共识过程。最后,进行实验分析,并将RPBFT与其他学者改进的PBFT共识算法进行对比。相较于传统信誉机制改进的PBFT共识算法,RPBFT具有线性的通信复杂度。这意味着,随着节点总数的增加,RPBFT的通信开销相较于同类算法更少。本文的主要贡献如下:
a)RPBFT引入收集器节点的概念,并采用信誉机制来管理共识节点。根据节点的信誉分数选取收集器节点和普通共识节点。
b)收集器节点被用来收集普通共识节点的投票消息,使得普通共识节点之间无须进行通信,从而降低通信开销。
c)在普通共识节点中的所有拜占庭节点均无作恶行为的情况下,通过增加达成共识所需的投票数量,减少一次投票收集过程,实现快速共识。
1 相关工作
PBFT中的每个节点在prepare和commit阶段都需要大量的通信,这导致节点较多时通信量成倍增加。因此,现阶段的许多解决方案旨在通过减少参与共识的节点数量来提高PBFT的效率。Li等人[9]提出了一种可扩展的共识算法,该算法通过可验证随机函数选取部分节点参加共识,减少参与共识的节点数量,通过降低通信量来提高性能。然而,该算法中所有节点被选取的概率均相同,恶意节点仍然有机会参与共识。
针对这个问题,一些研究者对节点进行信誉评估,拒绝分数较低的节点参与共识。Lao等人[10]提出了一种基于位置的可扩展共识算法,该算法使用地理位置信息唯一标识物联网节点。节点的可信度是根据其在同一位置的工作时间来衡量的。可信度越高,被选为背书节点的概率就越大。该方法优化了共识委员会的选取,并防止了女巫节点参与共识。Tang等人[11]提出了一种基于信任的实用拜占庭算法,该算法引入信用分数来评估节点可信度,选取一部分信用分数较高的节点参与共识过程,提高了通信开销、共识效率等方面的性能。Tong等人[12]提出了Trust-PBFT算法,设计了一个三链模型来简化存储结构,并通过节点信任值选择节点执行共识,降低了通信开销,提高了性能。涂园超等人[13]提出一种基于信誉投票的改进方案,对每个节点进行评分,并根据评分分配不同的角色(普通节点、投票节点、候选节点和备选主节点),以便每次可以尽可能多地选择非拜占庭节点。
在以上缩小共识委员会的方法中,如果选取较多的节点,通信量仍然很高;如果只选取少数节点参与共识,系统就会出现中心化趋势。与此同时,一些研究者[15~21]使用分层或分组的方法来缩小单个共识委员会的规模,降低通信开销,并允许更多的节点参与共识,但他们都没有对共识流程进行改进。陈苏明等人[22]提出一种基于节点分组信誉模型的改进PBFT共识算法。该算法根据节点的信誉分数将节点进行分组,并对commit阶段进行优化,以减少该阶段的通信开销。然而,prepare阶段的通信开销并未发生改变,因此该算法的总体通信复杂度仍为O(N2)。
引入密码学技术来设计共识算法是一个有益的改进思路,可以减少通信开销。Yin等人[23]提出一种三阶段投票的BFT类共识算法HotStuff,该算法在投票过程中引入了基于门限签名[24,25]的收集器,以实现O(N)的消息验证复杂度。然而,该算法使用主节点承担收集器职责,增加了主节点的开销。Gueta等人[26]提出了一种可扩展的实用拜占庭容错共识算法SBFT,使从节点亦可承担收集器职责,有效地解决了主节点开销大的问题;同时,他们还设计了一种快速共识路径来提高系统性能。
然而,门限签名增加了时间开销并影响效率。Liu等人[27]引入密钥分享技术来实现收集器,但密钥分享技术在密钥收集过程中短暂复现私钥,增加了安全风险。本文提出的改进共识算法RPBFT基于信誉分数选取收集器节点,旨在减少门限签名带来的时间开销,从而提高性能,并对恶意行为进行惩罚。
2 RPBFT共识算法
2.1 节点分类
为了更好地管理和协调节点,将RPBFT中的节点分为共识节点和备选节点两类[14]。其中,共识节点包括收集器节点和普通共识节点。
2.1.1 收集器节点
借鉴基于门限签名实现收集器[23,26]的传统方案,引入收集器节点的概念。收集器节点主要负责收集来自共识节点的签名消息,并构建决议证书(quorum certificate,QC),QC的构建如算法1所示。在收集到2f+1个来自收集器节点和c+1个来自普通共识节点的正确投票后,收集器节点会记录投票消息并进行签名,生成QC。其中,f表示收集器节点中最多能够容忍的拜占庭节点数量,c表示普通共识节点中最多能够容忍的拜占庭节点数量。一旦QC构建成功,它将在整个网络广播,完成一次投票收集过程。
收集器节点类型与PBFT类似,分为主节点和从节点。收集器主节点接收来自客户端的请求,对其进行签名验证。验证成功后,它向所有节点广播PRE-PREPARE消息。在接收到正确的PRE-PREPARE消息后,收集器节点进入prepare阶段,并在收集器节点中广播PREPARE消息。
算法1 构建QC
2.1.2 普通共识节点
普通共识节点负责对收集器节点提出的提案进行投票。普通共识节点收到超过2f个来自不同收集器节点的相同提案,即可为该提案投票。
2.1.3 备选节点
新加入的节点默认设置为备选节点,暂不参与共识过程。备选节点按照到达顺序进行排名。当共识节点中的恶意节点被剔除后,排名最靠前的备选节点将转变为普通共识节点,并赋予初始信誉分数。
2.2 信誉机制
由于PBFT中缺乏奖惩机制,RPBFT引入了信誉机制,对诚实节点进行奖励,对作恶节点进行惩罚。在RPBFT中,收集器节点和普通共识节点共同维护节点的信誉分数信息。每一轮共识结束后,根据各个节点的信誉分数,选择信誉分数最高的3f+1个节点作为收集器节点,剩余的2c+1个节点则作为普通共识节点。在系统初始时,所有共识节点的信誉分数都被设为0,并随机选取3f+1个节点作为初始收集器节点。
在每一轮共识过程中,所有共识节点都将参与两次投票。收集器节点根据这些投票信息计算每个节点的信誉分数。收集器节点只有接收到2f个来自其他收集器节点的正确投票和c+1个来自普通共识节点的正确投票时,才会开始构建QC。由于QC中只保存了部分先达的投票信息,所以信誉分数是基于前c+1个来自普通共识节点的正确投票和前2f+1个来自收集器节点的正确投票来计算的。
收集器节点完成信誉分数的计算后,将包含投票节点编号的QC广播给所有节点,随后普通共识节点会根据接收到的QC验证收集器节点的信誉分数计算是否正确。如果验证失败,普通共识节点会认为该收集器节点作恶,向所有的收集器节点报告该作恶行为,当有超过2f+1的收集器节点和超过c+1以上的普通共识节点认为该节点作恶,该收集器节点将被剔除,随后根据信誉机制重新选取收集器节点和普通共识节点。由于QC中携带有收集器节点不可伪造的签名信息,所以该QC可以作为收集器节点作恶的证据。
信誉机制引入节点活跃度,以表示一段时间内节点参与投票的积极性,其公式为
其中:i表示节点编号5b0359b02b9ff924c393f77e56d5e623ea6464dd007422bf749316175508084a;b表示该时间段内总的投票次数;a表示节点i在b轮投票期间的投票数。RPBFT将b设置为50。
当节点出现异常行为但原因不明时,将对该节点采取惩罚措施,并观察其后续表现。异常的原因可能是系统中的网络问题导致的超时。由于该行为并非是由节点自身的作恶行为引起的,所以不能直接将其视为恶意节点。为此,信誉机制设计了惩罚因子。首次出现恶意行为不进行惩罚,以减少对诚实节点的误判。同时减缓对多次作恶的恶意节点的信誉分数的恢复速度。其公式为
其中:m表示惩罚因子;x表示异常行为的次数。当没有出现过异常行为时,m的值为1,信誉分数增长率为正常值。当出现一次异常行为时,考虑到可能不是由于节点自身的问题而发生的,m仍设置为1,此时增长率是正常的。但当异常行为次数超过1时,就会对其施以惩罚,减小信誉分数的增长率。如果异常行为的次数达到阈值(RPBFT设置为5),则将该节点认定为恶意节点,并将其剔除。同时,将从备选节点中选取最早进入的节点加入普通共识节点,参与共识。
为了防止收集器节点的信誉分数持续增加并确保其不会长期担任收集器节点,信誉机制引入信誉调节因子p。当节点i为收集器节点时,p=-0.15,否则p=0。使得收集器节点在完成共识后会适当减去一些信誉分数,避免连续担任收集器节点。节点的信誉分数Sin的计算如式(3)所示。
其中:n表示节点编号;i表示投票轮次;N表示节点总数;Si-1n为节点n上一次投票后的信誉分数;m为惩罚因子;Activationi为节点活跃度;p为信誉调节因子。当该节点参与投票时,k的值为1,否则为0。收集器节点一定参与投票,因为它包含自己的一票,若不包含,则认为收集器节点作恶。一旦发现收集器节点存在异常行为时,将其信誉分数减少所有节点平均信誉分数的一半,从而使其信誉分数更快地降低。初始信誉分数设为0,即S0n=0。
RPBFT中收集器节点有多个,每个收集器节点计算得到的信誉分数均不相同,这是因为每个收集器节点收到的投票节点各不相同。RPBFT将所有收集器节点的信誉分数进行综合,取平均值作为节点的最终信誉分数,并选取3f+1个分数最高的节点作为收集器节点。为应对恶意收集器节点对信誉分数的影响,本文在选取新一任收集器节点时,会去除f个最大值以及f个最小值,最终信誉分数计算如算法2所示。
算法2 计算最终信誉分数
2.3 共识过程
为了降低通信开销,RPBFT优化共识过程,尽可能减少投票阶段的通信次数。RPBFT共识节点的总数|R|=3f+2c+2,其中,f表示收集器节点中最多存在f个拜占庭节点,c表示普通共识节点中最多存在c个拜占庭节点。在RPBFT中,收集器节点数量为N1=3f+1,普通共识节点数量为N2=2c+1。收集器节点和普通共识节点通过信誉机制进行划分。RPBFT共识流程如图1所示,其中,C为客户端节点,0~3为收集器节点,4~6为普通共识节点。
RPBFT由七个阶段组成,分别是request阶段、pre-prepare阶段、prepare阶段、prepare-ack阶段、commit阶段、commit-ack阶段和reply阶段。
2.3.1 request阶段
在request阶段,客户端会向收集器主节点发送REQUEST消息,该消息中包含客户端对该消息的签名。本文基于一个假设,即没有签名方的私钥,任何人都无法伪造签名。因此,在不公开客户端私钥的情况下,任何人都不能冒充该客户端发送虚假请求。
2.3.2 pre-prepare阶段
在pre-prepare阶段,收集器主节点会等待来自客户端的请求,验证其签名是否有效并满足应用层的要求。如果验证通过,将创建PRE-PREPARE消息并将其广播到所有节点。
2.3.3 prepare阶段
在prepare阶段,所有节点等待来自收集器主节点的PRE-PREPARE消息,对其进行验证。验证通过后,开始第一轮投票。每个节点向所有的收集器节点发送投票消息,等待收集器节点整合投票消息。
2.3.4 prepare-ack阶段
在prepare-ack阶段,收集器节点负责收集有效投票消息。当收集到c+1个来自普通共识节点的投票消息以及2f+1(包括自己)个来自收集器节点的投票消息,且这些消息均通过正确性验证,则投票收集完成。节点的信誉分数计算如算法3所示。随后,根据投票消息创建QC。为便于普通共识节点对收集器节点计算信誉值分数进行监督,QC中包括参与投票的节点编号以及收集器节点对QC的签名。接着,创建PREPARE-ACK消息,并将其与QC一并发送至所有的普通共识节点。鉴于收集器节点在下一个阶段并无任务,RPBFT要求收集器节点在本阶段提前开始第二轮投票,发送COMMIT投票消息给所有的收集器节点。
算法3 计算信誉分数
2.3.5 commit阶段
在commit阶段,普通共识节点等待接收收集器节点的PREPARE-ACK消息。收到该消息后,进行验证,并通过携带的QC验证收集器节点计算的信誉分数是否正确,普通共识节点验证信誉分数的过程如算法4所示。验证通过后,保存信誉分数,并进入下一阶段投票。将投票消息发送给所有的收集器节点。由于收集器节点在prepare-ack阶段已经发送过了投票消息,所以该阶段不再进行投票。
算法4 普通共识节点验证信誉分数
2.3.6 commit-ack阶段
在commit-ack阶段,收集器节点与prepare-ack阶段类似,收集各节点的投票消息,对其进行验证,并计算信誉分数,根据投票信息生成QC。随后,向普通共识节点发送COMMIT-ACK消息,并携带QC以供普通共识节点验证收集器节点计算的信誉分数。同时,向客户端发送REPLY消息,告知其共识成功达成。
2.3.7 reply阶段
在reply阶段,客户端等待接收来自收集器节点的REPLY消息,并对其验证。当收到f+1个正确的REPLY消息且内容一致时,认为客户端的请求操作已达成共识。
在此阶段,普通共识节点会收到来自收集器节点的COMMIT-ACK消息及相应的QC,并对它们进行验证。随后根据QC验证收集器节点计算的信誉分数是否正确。若分数不正确,则认为该收集器节点存在恶意行为,将其标记为恶意节点,同时将排名最高的备选节点晋升为普通共识节点,并重新选取收集器节点。若分数正确,则需要确定下一任的收集器节点。
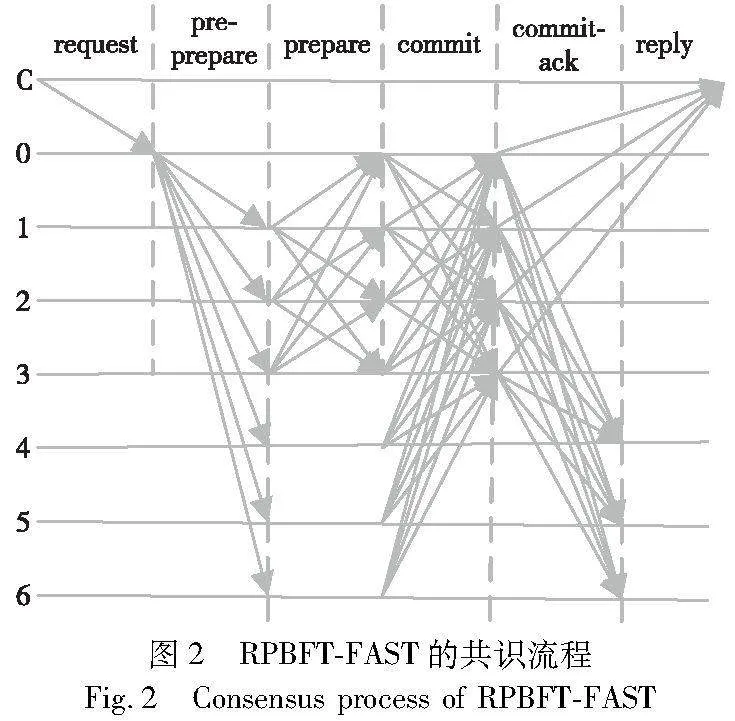
2.4 快速共识
由于引入了信誉机制,拜占庭节点的数量会不断减少,剩余的拜占庭节点也会尽可能地减少作恶行为以增加自己的信誉分数。在这种情况下,RPBFT进一步优化共识过程,实现快速共识。与Zyzzyva[28]类似,当普通共识节点中的拜占庭节点均无作恶行为时,增加commit阶段中创建QC所需投票数,并精简普通共识节点的prepare和prepare-ack阶段,实现快速共识,称为RPBFT-FAST。RPBFT-FAST的共识流程如图2所示。
与RPBFT的共识流程类似,C表示客户端节点,0~3为收集器节点,4~6为普通共识节点。在request阶段,客户端C向收集器主节点发送请求操作。随后,收集器主节点验证请求,验证成功后以PRE-PREPARE消息的形式转发给所有节点。收集器节点在收到正确的PRE-PREPARE消息后进入prepare阶段,而普通共识节点则直接进入到commit阶段。在prepare阶段,收集器节点内部广播PREPARE消息,每个收集器节点在收到2f+1个正确的PREPARE消息(包括自己)后进入commit阶段。在commit阶段,所有节点均向收集器节点发送COMMIT消息。收集器节点收到2c+1个来自普通共识节点(所有的普通共识节点)以及2f+1个来自收集器节点的正确COMMIT消息后向普通共识节点发送COMMIT-ACK消息,作为对COMMIT消息的响应。同时,收集器节点向客户端发送REPLY消息,表明本轮共识已完成,并将区块持久化到存储中。如果客户端收到f+1个正确的REPLY消息,则认为其发送的请求操作已经完成。当一个普通共识节点接收到2f+1个COMMIT-ACK消息时,认为本轮共识已完成,将区块持久化到存储中,准备进行下一轮共识。
RPBFT默认采用快速共识。然而,普通共识节点中存在恶意节点或故障节点时,由于无法收集到足够的(2c+1条)正确的COMMIT消息,快速共识无法达成。此时,将未投票的节点视为恶意节点,扣除其信誉分数,以减少快速共识失败的次数。随后RPBFT-FAST切换到RPBFT重新开始共识。此时,保存收集到的COMMIT消息用于commit阶段,即在收集器节点收集到足够的PREPARE消息后,检查收集器节点在快速共识期间收集的COMMIT消息是否足够。如果足够,则认为已经完成commit阶段,并发送COMMIT-ACK和reply消息来完成共识。如果不足,则发送PREPARE-ACK消息请求重新完成commit阶段。以此减少重复消息的发送,降低通信开销。
2.5 安全性分析
假设收集器节点中最多存在f个拜占庭节点,普通共识节点中最多存在c个拜占庭节点,诚实节点不会同时对两个不同的提案进行投票。如果所有非拜占庭节点本地提交的相同序号的区块都一致,则算法安全。
定义1 安全性。如果以下条件成立,则算法是安全的:当收集器节点中最多存在f个拜占庭节点,普通共识节点中最多存在c个拜占庭节点时,如果在某个序号n1上已有一个诚实节点提交了区块,则将不会在该序号上提交其他区块。
结论1 在序号为n1时,如果一个诚实的收集器节点收到2f+1条(包括自己)来自收集器节点的对提案p1的投票,则不可能收到2f+1条(包括自己)来自收集器节点的对提案p2的投票,其中p1≠p2。
证明 当收集器主节点是诚实节点时,最多f个收集器节点可以对提案p2投票。当收集器主节点是拜占庭节点时,收集器节点中最多存在f-1个从节点为拜占庭节点。如果收集器节点可以收到2f+1条(包括自己)来自收集器节点的对提案p2的投票,则有一个正常节点对两个提案都进行了投票,这是不可能的。综上所述,结论1成立。
结论2 当序号为n1时,收集器将只通过一个提案。
证明 当收集器中主节点是诚实节点时,所有节点均可接收到正确的提案。2f+1个收集器节点和c+1个普通共识节点将会为该提案进行投票。由于只有拜占庭节点对其他提案投票,无法达到投票阈值,恶意提案无法通过。当主节点是拜占庭节点时,从结论1可得出结论,在收集器节点的投票过程中,只有一个提案p可以被通过。尽管普通共识节点可以产生多个恶意提案,但由于这些恶意提案与p不同,系统最终认为主节点存在作恶行为,并剔除作恶节点重新开始共识。综上所述,结论2成立。
结论1和2证明了RPBFT具有安全性。
3 实验及分析
考虑到SBFT有收集器节点和快速共识的思想,且RPBFT是PBFT的改进算法,本实验选择了SBFT和PBFT以及Kumar等人[29]提出的基于信誉的PBFT共识算法(reputed PBFT,R-PBFT)作为对比算法。实验基于Java t-io框架,实现了多线程、多节点的PBFT、SBFT、R-PBFT以及RPBFT共识算法,对RPBFT的性能进行实验分析,并与PBFT[8]和SBFT[26]、R-PBFT[29]进行对比。在实验中,RPBFT的收集器节点数量为3f+1。为了使收集器节点更少以获得更高的性能,实验将收集器节点总数设置为4。此外,实验设置诚实节点不会出现故障等问题。实验过程中,客户端发送并发交易5 000条,每100条交易打包成一个区块。实验重复50次,取平均值作为最终的实验结果。实验软硬件配置信息如表1所示。
3.1 容错性分析
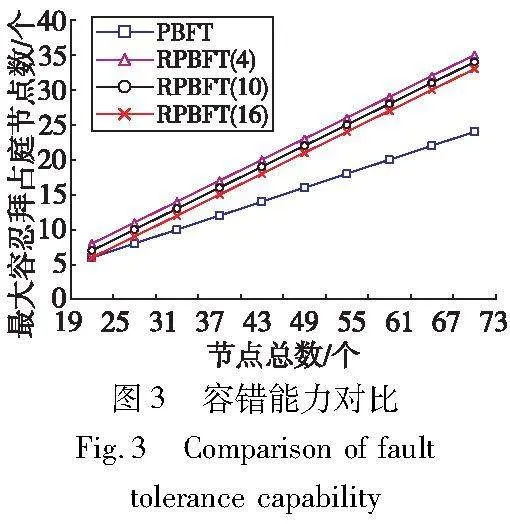
RPBFT收集器节点能够容忍的最大拜占庭节点数为f,普通共识节点能够容忍的最大拜占庭节点数为c。容错能力对比如图3所示,SBFT、R-PBFT容错能力与PBFT相同,这里不再赘述。RPBFT(x)表示收集器节点数为x时,RPBFT可以容忍的最大拜占庭节点数。从图3中可以看出,RPBFT的容错性能优于PBFT。当收集器节点数量越少时,容错性能会提高。这是因为收集器节点可以容忍1/3的拜占庭节点,而普通共识节点中可以容忍1/2的拜占庭节点。这意味着,普通共识节点的数量增加时,可以容忍的拜占庭节点数量也会增加。因此,RPBFT容错性能优于PBFT,且收集器节点数量越少,容错性能越好。
3.2 信誉机制分析
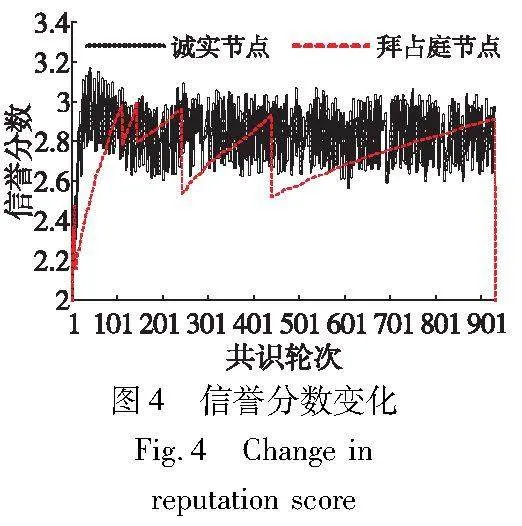
将收集器节点的数量设置为4,普通共识节点的数量设置为41,其中初始收集器中存在1个拜占庭节点,普通共识节点中存在20个拜占庭节点。设置拜占庭节点作恶的概率为50%,其作恶行为表现为不发送消息。初始收集器节点为编号最小的4个节点,剩余41个节点为普通共识节点。实验持续进行到第一个作恶的拜占庭节点被剔除,选择该节点作为拜占庭节点代表,并任意选择一个诚实节点作为诚实节点代表,记录这段时间中诚实节点和拜占庭节点的信誉分数变化如图4所示。
从图4中可以看出,诚实节点的信誉分数在3附近振荡。这是因为诚实节点在成功担任收集器节点后会降低其信誉分数,以避免继续担任收集器节点。然而,拜占庭节点的信誉分数振荡次数较少,且其间隔越来越大。这是因为拜占庭节点存在作恶行为,收集器节点有时无法收集到来自它的投票,导致信誉分数上升速度不如诚实节点快。此外,当拜占庭节点的作恶行为被发现后,惩罚因子导致它的增长速度进一步减慢。因此,需要更多的共识轮次信誉分数才能恢复到平均水平。在第932轮时,因为拜占庭节点作恶次数已经达到5次,此时该节点被标记为恶意节点并踢出系统。综合来看,该信誉机制可以有效地发现作恶节点并对其作出惩罚,同时防止信誉分数无限增长。
3.3 共识通信量
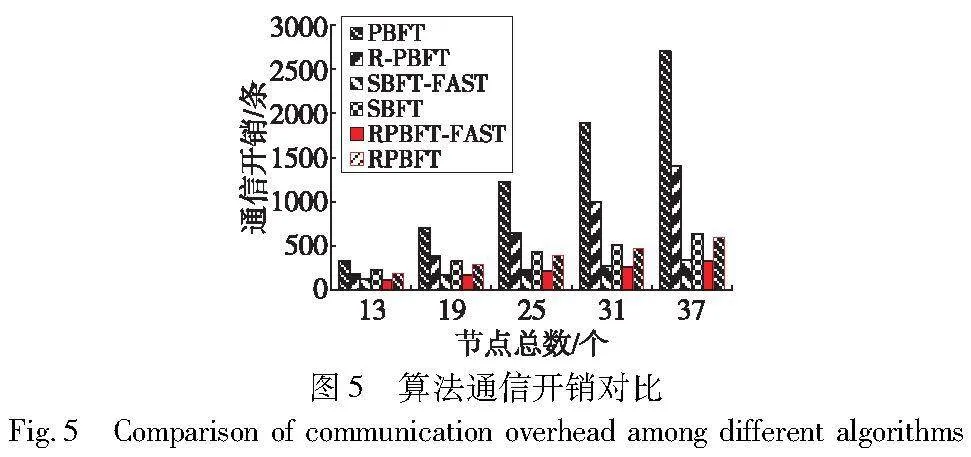
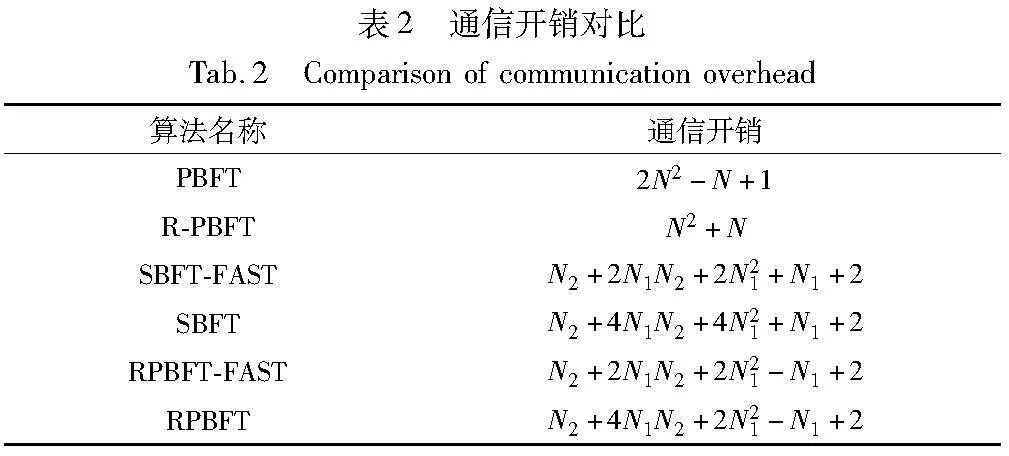
设RPBFT和SBFT中收集器节点总数为N1,普通共识节点总数为N2,PBFT和R-PBFT节点总数为N。同时,RPBFT-FAST、SBFT-FAST表示两者在拜占庭节点无作恶行为时的通信开销,RPBFT、SBFT表示两者在存在拜占庭节点作恶时的通信开销。PBFT和R-PBFT在两种情况下的通信开销相同,不再分开讨论。计算三种算法从request阶段到reply阶段的通信次数,通信开销对比如表2所示。当收集器节点总数N1为常数时,RPBFT的通信复杂度为O(N2)。当收集器节点总数为4时,得到各算法通信开销对比如图5所示。
从图5中可以看出,无论拜占庭节点是否存在作恶行为,RPBFT通信开销均低于PBFT与R-PBFT。当拜占庭节点存在作恶行为时,RPBFT的通信开销略低于SBFT,而在拜占庭节点不存在作恶行为时,两者通信开销几乎相同。总体来说,RPBFT与SBFT的通信开销相差不大,但低于PBFT与R-PBFT。
3.4 平均共识时延
共识时延是指客户端发送交易请求到整个共识过程完成所需要的时间,即
Delayi=Tfinish-Treq(4)
其中:Delayi表示交易i的共识时延;Tfinish表示交易所在区块完成确认的时间;Treq表示客户端发送请求的时间。
实验中,平均共识时延是对5 000次并发交易的共识时延取平均值,即
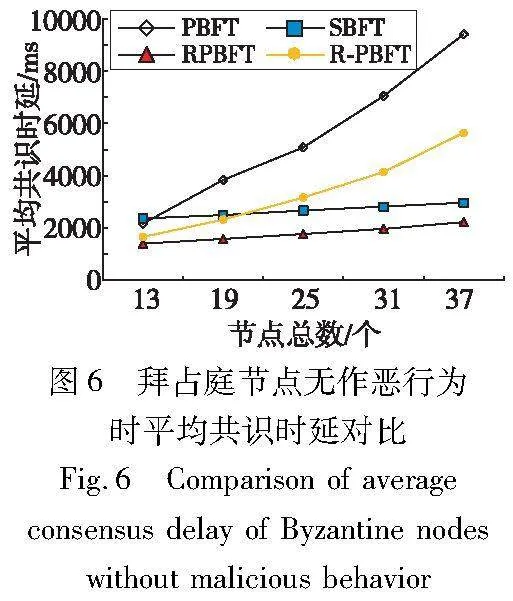
RPBFT与PBFT、R-PBFT和SBFT在节点数量相同的情况下进行对比实验,实验将节点总数设置为13、19、25、31、37,并保持收集器节点总数为4。确保四种算法的节点总数一致,比较算法的平均共识时延。RPBFT和SBFT在拜占庭节点无作恶行为的情况下,使用快速共识完成共识。拜占庭节点无作恶行为时,平均共识时延对比如图6所示。
从图6中可以看出,当拜占庭节点无作恶行为时,RPBFT的平均共识时延整体上高于PBFT、R-PBFT与SBFT。随着节点数量的增加,RPBFT与SBFT的平均共识时延呈现出相对稳定的增长趋势,而PBFT和R-PBFT的平均共识时延急剧上升。结果表明,当拜占庭节点无作恶行为且节点总数为37时,RPBFT的平均共识时延相较于SBFT减少了约25.2%,相较于PBFT降低了约76.4%,相较于R-PBFT下降了约60.5%。
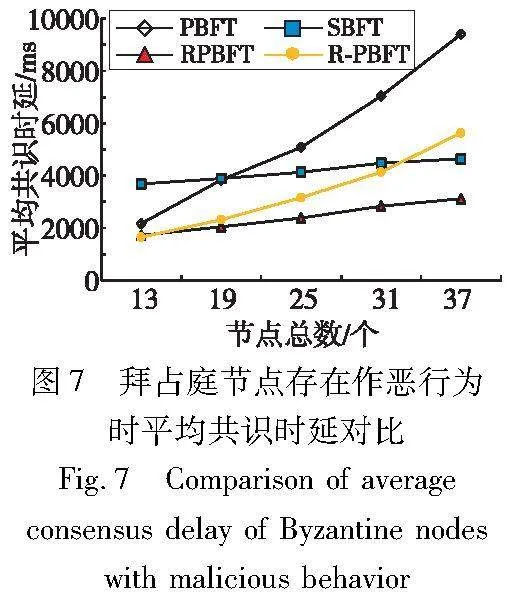
当拜占庭节点存在作恶行为时,由于无法收集到足够的投票,快速共识无法完成,拜占庭节点存在作恶行为时平均共识时延对比如图7所示。整体上,RPBFT的平均共识时延低于SBFT、PBFT以及R-PBFT。当节点总数为13时,RPBFT的平均共识时延与PBFT和R-PBFT差距很小,此时R-PBFT的平均共识时延甚至低于SBFT,这表明R-PBFT在节点较少时具有较低的平均共识时延。然而,随着节点总数的增加,PBFT和R-PBFT的平均共识时延迅速上升,并且整体上高于其他两种算法。结果表明,在拜占庭节点存在作恶行为的情况下且节点总数为37时,RPBFT的平均共识时延与SBFT相比减少了约32.8%,与PBFT相比降低了约66.8%,与R-PBFT相比下降了约44.6%。
在节点总数较少的情况下,无论拜占庭节点是否存在作恶行为,RPBFT的平均共识时延与R-PBFT非常接近,并且小于SBFT。随着节点数量的增加,RPBFT和SBFT的平均共识时延整体上低于PBFT和R-PBFT,并且RPBFT和SBFT的平均共识时延增长相对缓慢。由于RPBFT省去了门限签名的开销,与SBFT相比,RPBFT具有更低的平均共识时延。而PBFT和R-PBFT具有较高的通信复杂度,随着节点数量的增加,两者的平均共识时延迅速增加,远远超过RPBFT的平均共识时延。综合来看,RPBFT在平均共识时延方面具有良好的性能。
3.5 共识吞吐量
共识吞吐量是指系统每秒内可以完成多少交易请求的共识,即
TPS=Countreq/Ttotal(6)
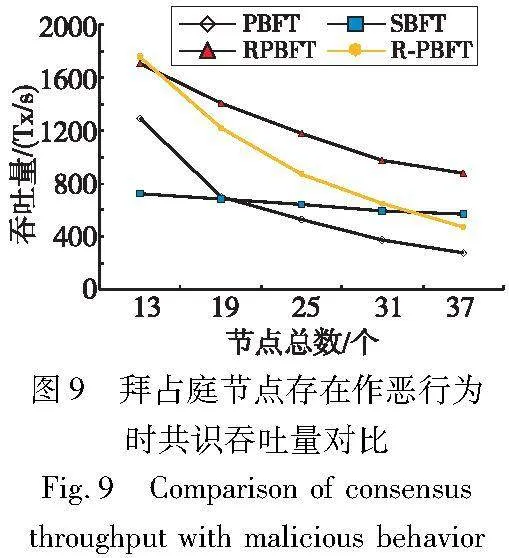
其中:Countreq为交易的总数;Ttotal是完成交易所花费的时间。吞吐量的单位为Tx/s,其中Tx表示交易的数量,s表示时间单位秒,Tx/s表示每秒完成的交易数。共识节点的总数分别设置为13、19、25、31、37。通过调整节点数量,比较四种共识算法的共识吞吐量。当拜占庭节点无作恶行为时,共识吞吐量对比如图8所示。可以看出,RPBFT的共识吞吐量始终高于SBFT、R-PBFT和PBFT。当节点总数为37时,与SBFT相比提高了约39.9%,与R-PBFT相比上升了约171.5%,与PBFT相比增加了约356.8%。
当拜占庭节点中存在作恶行为时,共识吞吐量对比如图9所示。当节点总数为13时,RPBFT的共识吞吐量与R-PBFT相差不大,而SBFT的共识吞吐量低于其他三种算法。这是因为节点较少时,SBFT的通信开销与其他算法接近,但由于存在额外的门限签名开销,其共识吞吐量低于其他算法。随着节点总数的增加,PBFT和R-PBFT的通信开销急剧上升,它们的共识吞吐量快速下降,随后低于SBFT的共识吞吐量。相比之下,RPBFT通信量较低且没有门限签名开销,因此其共识吞吐量始终高于PBFT、R-PBFT和SBFT。当节点总数为37时,RPBFT的共识吞吐量与SBFT相比提高了约54%,与R-PBFT相比上升了约86.7%,与PBFT相比增加了约214.1%。
RPBFT算法在两种情况下具有较高的共识吞吐量。值得注意的是,当节点数量较少时,RPBFT的共识吞吐量与R-PBFT接近,但随着节点数量的增加,R-PBFT的共识吞吐量迅速下降,而SBFT与RPBFT的下降速度则较为缓慢。整体上来看,RPBFT具有较高的共识吞吐量。
综上所述,当节点数量较少时,RPBFT的平均共识时延和共识吞吐量与R-PBFT接近。随着节点数量的增加,RPBFT在平均共识时延和共识吞吐量方面的表现优于其他算法。总体来看,RPBFT可以有效地降低恶意节点担任收集器节点的概率,并在容错性、共识通信量、平均共识时延和共识吞吐量方面展现出优异的性能。
4 结束语
针对PBFT通信开销大及缺乏奖惩机制的问题,本文提出了一种基于信誉机制的RPBFT共识算法。RPBFT采用信誉机制对共识节点进行信誉评分,并选取信誉分数最高的3f+1个节点作为收集器节点,剩余2c+1个节点作为普通共识节点。新加入的备选节点不参与共识,等待共识节点作恶被踢出后,就可以转变为普通共识节点参与共识。收集器节点负责收集普通共识节点的投票,以减少普通共识节点之间的通信,降低通信开销。当普通共识节点中的拜占庭节点无作恶行为时,增加收集器节点需要接收投票的数量以减少一次投票收集过程,从而实现快速共识。实验表明,RPBFT具有较低的通信开销,并显著提高了其在平均共识时延和吞吐量的性能,同时能够对恶意节点进行有效惩罚。但RPBFT仍有不足之处,后续工作将进一步提高算法的可扩展性。
参考文献:
[1]夏清,窦文生,郭凯文,等. 区块链共识协议综述 [J]. 软件学报,2021,32(2): 277-299. (Xia Qing,Dou Wensheng,Guo Kaiwen,et al. Survey on blockchain consensus protocol [J]. Journal of Software,2021,32(2): 277-299.)
[2]Wang Xin,Duan Sisi,Clavin J,et al. BFT in blockchains: from protocols to use cases [J]. ACM Computing Surveys,2022,54(10): 1-37.
[3]冯了了,丁滟,刘坤林,等. 区块链BFT共识算法研究进展 [J]. 计算机科学,2022,49(4): 329-339. (Feng Liaoliao,Ding Yan,Liu Kunlin,et al. Research advance on BFT consensus algorithms [J]. Computer Science,2022,49(4): 329-339.)
[4]刘懿中,刘建伟,张宗洋,等. 区块链共识机制研究综述 [J]. 密码学报,2019,6(4): 395-432. (Liu Yizhong,Liu Jianwei,Zhang Zongyang,et al. Overview on blockchain consensus mechanisms [J]. Journal of Cryptologic Research,2019,6(4): 395-432.)
[5]袁勇,倪晓春,曾帅,等. 区块链共识算法的发展现状与展望 [J]. 自动化学报,2018,44(11): 2011-2022. (Yuan Yong,Ni Xiaochun,Zeng Shuai,et al. Blockchain consensus algorithms: the state of the art and future trends [J]. Acta Automatica Sinica,2018,44(11): 2011-2022.)
[6]Pease M,Shostak R,Lamport L. Reaching agreement in the presence of faults [J]. Journal of the ACM,1980,27(2): 228-234.
[7]Lamport L,Shostak R,Pease M. The Byzantine generals problem [J]. ACM Trans on Programming Languages and Systems,1982,4(3): 382-401.
[8]Castro M,Liskov B. Practical Byzantine fault tolerance [C]// Proc of the 3rd Symposium on Operating Systems Design and Implementation. New York: ACM Press,1999: 173-186.
[9]Li Yixin,Wang Zhen,Fan Jia,et al. An extensible consensus algorithm based on PBFT [C]// Proc of International Conference on Cyber-enabled Distributed Computing and Knowledge Discovery. Pis-cataway,NJ: IEEE Press,2019: 17-23.
[10]Lao L,Dai Xiaohai,Xiao Bin,et al. G-PBFT: a location-based and scalable consensus protocol for IoT-Blockchain applications [C]// Proc of IEEE International Parallel and Distributed Processing Symposium. Piscataway,NJ: IEEE Press,2020: 664-673.
[11]Tang Song,Wang Zhiqiang,Jiang Jian,et al. Improved PBFT algorithm for high-frequency trading scenarios of alliance blockchain [J]. Scientific Reports,2022,12(1): article No.4426.
[12]Tong Wei,Dong Xuewen,Zheng Jiawei. Trust-PBFT: a PeerTrust-based practical Byzantine consensus algorithm [C]// Proc of International Conference on Networking and Network Applications. Pisca-taway,NJ: IEEE Press,2019: 344-349.
[13]涂园超,陈玉玲,李涛,等. 基于信誉投票的PBFT改进方案 [J]. 应用科学学报,2021,39(1): 79-89. (Tu Yuanchao,Chen Yuling,Li Tao,et al. Improved PBFT scheme based on reputation voting [J]. Journal of Applied Sciences,2021,39(1): 79-89.)
[14]路宇轩,孔兰菊,张宝晨,等. MC-RHotStuff: 面向多链基于信誉的HotStuff共识机制 [J/OL]. 计算机研究与发展. (2023-08-14) [2023-10-24]. http://kns. cnki. net/kcms/detail/11. 1777. TP. 20230812. 1255. 002. html. (Lu Yuxuan,Kong Lanju,Zhang Baochen,et al. MC-RHotStuff: multi-chain oriented hotstuff consensus mechanism based on reputation [J/OL]. Journal of Computer Research and Development.(2023-08-14) [2023-10-24]. http://kns. cnki. net/kcms/detail/11.1777.TP.20230812.1255.002.html.)
[15]Feng Libo,Zhang Hui,Chen Yong,et al. Scalable dynamic multi-agent practical Byzantine fault-tolerant consensus in permissioned blockchain [J]. Applied Sciences,2018,8(10): 1919.
[16]Li Wenyu,Feng Chenglin,Zhang Lei,et al. A scalable multi-layer PBFT consensus for blockchain [J]. IEEE Trans on Parallel and Distributed Systems,2021,32(5): 1146-60.
[17]Miic' V B,Miic' J,Chang Xiaolin. The impact of vote counting policy on the performance of PBFT [C]// Proc of IEEE Canadian Confe-rence on Electrical and Computer Engineering. Piscataway,NJ: IEEE Press,2021: 1-6.
[18]Yu Ge,Wu Bin,Niu Xinxin. Improved blockchain consensus mechanism based on PBFT algorithm [C]// Proc of the 2nd International Conference on Advances in Computer Technology,Information Science and Communications. Piscataway,NJ: IEEE Press,2020: 14-21.
[19]胡荣磊,丁安邦,于秉琪. 一种基于门限签名的区块链共识算法 [J]. 计算机应用研究,2022,39(12): 3555-3561. (Hu Ronglei,Ding Anbang,Yu Bingqi. Blockchain consensus algorithm based on threshold signature [J]. Application Research of Computers,2022,39(12): 3555-3561.)
[20]刘陕南,张荣华,刘长征. 基于分组和信用分级的 PBFT共识算法改进方案 [J]. 计算机工程,2023,49(11): 143-149. (Liu Shannan,Zhang Ronghua,Liu Changzheng. Improvement of PBFT consensus algorithm based on grouping and credit rating [J]. Computer Engineering,2023,49(11): 143-149.)
[21]朱海,金瑜. DS-PBFT: 一种基于距离的面向区块链的共识算法 [J]. 小型微型计算机系统,2022,43(3): 506-513. (Zhu Hai,Jin Yu. DS-PBFT: a distance based consensus algorithm for blockchain [J]. Journal of Chinese Computer Systems,2022,43(3): 506-513.)
[22]陈苏明,王冰,陈玉全,等. 基于节点分组信誉模型的改进PBFT共识算法 [J]. 计算机应用研究,2023,40(10): 2916-2921. (Chen Suming,Wang Bing,Chen Yuquan,et al. Improved PBFT consensus algorithm based on node grouping reputation model [J]. Application Research of Computers,2023,40(10): 2916-2921.)
[23]Yin Maofan,Malkhi D,Reiter M K,et al. HotStuff: BFT consensus with linearity and responsiveness [C]// Proc of ACM SymposiumG+dV3c7yLNBrXYA8mEP26Fhu1wQuQW+LzaNF8qLtybI= on Principles of Distributed Computing. New York: ACM Press,2019: 347-356.
[24]Boldyreva A. Threshold signatures,multisignatures and blind signatures based on the gap-Diffie-Hellman-group signature scheme [C]// Proc of the 6th International Workshop on Theory and Practice in Public Key Cryptography. Berlin: Springer,2002: 31-46.
[25]Boneh D,Lynn B,Shacham H. Short signatures from the Weil pairing [J]. Journal of Cryptology,2004,17(4): 297-319.
[26]Gueta G G,Abraham I,Grossman S,et al. SBFT: a scalable and decentralized trust infrastructure [C]// Proc of the 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks. Piscataway,NJ: IEEE Press,2019: 568-580.
[27]Liu Jian,Li Wenting,Karame G O,et al. Scalable Byzantine consensus via hardware-assisted secret sharing [J]. IEEE Trans on Computers,2019,68(1): 139-51.
[28]Kotla R,Alvisi L,Dahlin M,et al. Zyzzyva: speculative Byzantine fault tolerance [J]. ACM Trans on Computer Systems,2010,27(4): 1-39.
[29]Kumar A,Vishwakarma L,Das D. R-PBFT: a secure and intelligent consensus algorithm for Internet of Vehicles [J]. Vehicular Communications,2023,41: 100609.
