
基于改进YOLOv5的田间复杂环境障碍物检测
2024-06-17 10:38:20杨昊霖王其欢李华彪耿端阳武继达姚艳春
中国农机化学报 2024年6期
杨昊霖 王其欢 李华彪 耿端阳 武继达 姚艳春
摘要:为实现田间复杂环境下农业机器人自主导航作业过程中障碍物快速检测,提出一种基于改进YOLOv5的田间复杂环境下障碍物检测方法。建立包含农业机械、人、羊三类目标障碍物共计6 766张图片的农田障碍物数据集;通过k-means聚类算法生成最佳先验锚框尺寸;引入CBAM卷积块注意力模块,抑制目标障碍物周围复杂环境的干扰,增强目标显著度;增加一个检测头,跨层级连接主干特征,增强多尺度特征表达能力,缓解标注对象尺度方差带来的负面影响;使用Ghost卷积替换Neck层中普通卷积,减少模型参数,降低模型复杂度。改进后的模型比YOLOv5s基准模型检测精度提高2.3%,召回率提高3.1%,精确率提高1.9%,参数量降低7%左右,为无人农业机械自主作业过程中导航避障的研究提供技术参考。
关键词:农业机器人;农田障碍物检测;改进YOLOv5;图像处理;机器视觉
中图分类号:S220; TP391.4
文献标识码:A
文章编号:2095-5553 (2024) 06-0216-08
收稿日期:2022年9月13日
修回日期:2023年3月21日
*基金项目:国家重点研发计划(2021YFD2000502);山东省现代农业产业技术体系岗位专家项目(SDAIT—02—12)
第一作者:杨昊霖,男,1997年生,山东潍坊人,硕士;研究方向为智能农机装备。E-mail: 942740554@qq.com
通讯作者:耿端阳,男,1969年生,陕西澄城人,博士,教授,博导;研究方向为新型农业机械装备。E-mail: dygxt@sdut.edu.cn
Obstacle detection in complex farmland environment based on improved YOLOv5
Yang Haolin, Wang Qihuan, Li Huabiao, Geng Duanyang, Wu Jida, Yao Yanchuan
(College of Agricultural Engineering and Food Science, Shandong University of Technology, Zibo, 255000, China)
Abstract: In order to realize the rapid detection of obstacles in the process of autonomous navigation of agricultural robots in complex field environments, an obstacle detection method based on improved YOLOv5 in complex field environments is proposed. The farmland obstacle data set containing a total of 6766 images of agricultural machinery, human and sheep objects are established. The optimal prior anchor box size is generated by the k-means clustering algorithm. The CBAM convolution block attention module is introduced to suppress the interference of the complex environment around the target obstacle and enhance the target saliency. A detection head is added to connect the backbone features across levels, enhance the ability to express multi-scale features, and alleviate the negative impact of the variance of the scale of the labeled objects. The Ghost convolution is used to replace the ordinary convolution in the Neck layer to reduce the model parameters and decrease the model complexity. Compared with the YOLOv5s benchmark model, the improved model has increased the detection accuracy by 2.3%, the recall rate by 3.1%, the accuracy rate by 1.9%, and has decreased the reference number by about 7%. It provides technical reference for the research of navigation and obstacle avoidance during autonomous operation of unmanned agricultural machinery.
Keywords: agricultural robot; farmland obstacle detection; improved YOLOv5; image processing; machine vision
0 引言
近年来,随着自动驾驶和智能化作业的广泛应用,在农业生产领域,利用无人农业机械,自主完成枯燥繁琐的田间作业,已经成为当前解决农村劳动力短缺和用工成本上升的主要技术手段,而在自主作业过程中所面临的环境感知、决策与逻辑判断等技术,是无人农机必须面对的问题。在环境感知方面,当无人农机作业时,在作业路径上,会不可避免地出现多种障碍物,如树木、房屋、电线杆、动物和其他农机等[1]。传统的无人农机,只对周围的障碍物进行定位,而不对障碍物进行识别检测分类,这不利于对不同类别障碍物危险等级的划分、避障决策的制定和执行,如在面对活体障碍物时,很难准确预测其行动轨迹,需要立即停车,避免造成危险[2];而在面对树木、电线杆等静止物体时,基本不要高危险等级的制动方案,只需选择更加有效的避障策略即可。因此,开展基于机器视觉的障碍物检测和识别对农业机器人或者无人农机开发具有重要的意义[3]。
针对农田障碍物,传统的基于手工特征进行的目标检测存在检测精度低、易受环境干扰和泛化能力不强等缺点[4]。而基于深度学习的目标检测则有效地解决了这些问题,成为当前计算机视觉领域的重要研究方向。基于深度学习的目标检测算法分为两类:一类是两阶段(two-stage)目标检测算法,包括R-CNN、Fast R-CNN、Faster R-CNN等[5-7]。薛金林等[1]通过改进Faster R-CNN目标检测算法来识别农田中的障碍物,有效提高了农田障碍物的识别速度,减少了误检和漏检,满足拖拉机低速作业的实时检测需求。夏成楷[8]设计了一种改进的Faster R-CNN检测模型,通过对特征提取网络和RPN (Region Proposal Network)进行改进,提高了农田障碍物检测的准确率和检测速度。另一类是单阶段(one-stage)目标检测算法,包括SSD、Retina Net、YOLO系列等[9-13],该类算法具有结构简单、计算高效、实时性好等优点[14, 15]。刘慧等[16]通过对SSD进行改进,解决了果园复杂环境障碍物信息难以准确检测出的问题。魏建胜等[17]在YOLOv3的基础上,使用Darknet53作为特征提取网络,加入残差模块解决梯度问题,实现了农田中障碍物准确检测。李文涛等[18]在YOLOv3-tiny检测框架上混合使用注意力机制,通过强化检测目标提高了障碍物识别过程的抗背景干扰能力,且在占用内存和检测速度方面较SSD、YOLOv3等算法具有明显优势。YOLOv5作为YOLO系列算法的代表,相较于YOLOv3、YOLOv4来说,在检测精度和实时性方面都有了较大的提升[19]。
针对非结构农田环境下检测目标障碍物存在作物遮挡、光线影响、自然背景干扰[20]以及障碍物与周围作物相似造成传统算法检测准确率有待提高的问题,本文提出一种改进YOLOv5田间障碍物检测方法,即建立农田障碍物目标检测数据集,通过k-means聚类算法[21]匹配最佳先验锚框尺寸;针对目标障碍物在复杂背景下难以检测的问题,在YOLOv5检测模型的基础上引入卷积块注意模块(Convolutional Block Attention Module,CBAM)[22],加强对检测目标的关注度,增强目标障碍物在复杂环境中的显著度,进而提高网络的检测精度;增加一个检测头,跨层级融合多尺度特征;引入Ghost卷积[23],替换Neck层中的卷积操作,减少增加检测头以及引入注意力机制后对检测速度的影响,降低模型复杂度,提高网络的检测速度。
1 YOLOv5目标检测算法原理
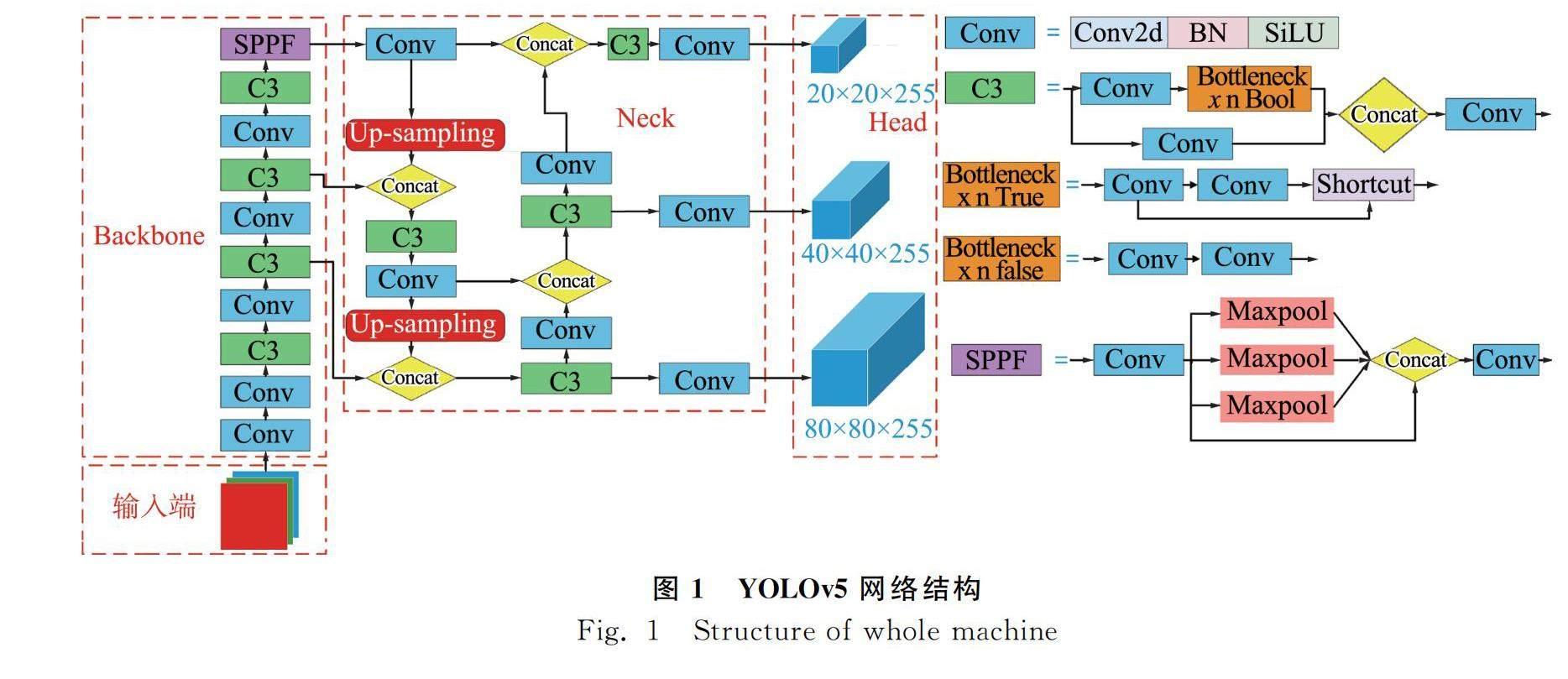
YOLOv5是YOLO系列中最新算法,属于单阶段目标检测模型,是直接对网络进行端到端的训练,主要包含四部分:输入端、Backbone、Neck、Head。其中输入端是图像预处理阶段,主要由Mosaic数据增强、自适应锚框计算和自适应图片缩放三部分组成,最终将输入样本图片调整为640×640;Backbone层中,最新v6.0版本将Conv标准卷积层替换v5.x中的Focus模块,减少模型参数量,提升速度和精度,便于导出其他框架,还包含跨阶段局部网络(Cross Stage Partial Network, CSP)和快速空间金字塔池化(Spatial Pyramid Pooling-Fast, SPPF)三部分;Neck层采用了FPN+PAN特征金字塔结构,其中FPN用来增强语义信息,PAN用来增强定位信息,两者互补,加强网络特征的融合能力;在Head层中采用GIOU_Loss(Generalized Intersection over Union Loss)做Bounding box的损失函数,用来估算检测目标矩形框的识别损失。网络结构如图1所示。
2 改进YOLOv5的农田障碍物检测方法
本研究的YOLOv5改进算法框架如图2所示。从图2可以看出首先将样本划分为训练集和测试集,并对训练集样本进行数据增强,然后将所得到训练集样本输入到算法检测模型进行训练,以得到检测算法的训练权重,最后使用得到的训练权重在测试集上进行测试验证。
2.1 k-means聚类
YOLOv5算法是基于锚框的目标检测算法,原算法中先验锚框参数是对COCO数据集使用k-means算法聚类生成,如果基于原始设定anchor参数进行训练,会对识别精度和定位精度产生影响。
k-means算法是在数据集所有的边界框中挑选k个样本作为簇的中心,针对数据集中的每个样本计算它到k个簇中心的距离并将样本划分到它最近的簇中,然后对每个簇中所有样本的均值作为簇的中心,然后求的新的簇心,循环该过程到簇心不发生变化或样本数不发生变化为止,最终筛选出k个簇中心。在YOLOv5中使用的k-means算法,是基于欧氏距离(Euclidean Distance)作为样本与样本之间的距离进行聚类。然而欧氏距离只考虑了样本距离,不考虑长宽比和覆盖面积,容易导致适应度(Fitness)变差,所以,本文将在标准k-means算法的基础上,使用d(bboxes,anchors)作为样本之间的距离进行聚类,d(bboxes,anchors)的计算公式如式(1)所示。
d(bboxes,anchors)=1-IoU(bboxes,anchors)(1)
式中:d(bboxes,anchors)——当前锚框到聚类簇中心框的距离;
IoU(bboxes,anchors)——当前锚框和聚类簇中心框的交并比。
IoU的取值范围为0~1,两个bboxes重合程度越高,IoU值就越大,1-IoU就越趋近于0,d(bboxes,anchors)越小,表示两个样本之间的距离越近。通过试验对比欧氏距离与d(bboxes,anchors)在本文数据集聚类差异,试验结果如表1所示。
其中,适应度为每个真实框与聚类得到的12个锚框满足阈值条件下宽高比的平均值,最大可能召回为满足条件的宽高比概率。从表1可知,使用d(bboxes,anchors)作为样本与样本之间的距离进行聚类适应度(Fitness)比使用欧氏距离的方法提升2.12%,最大可能召回率(Best Possible Recall, BPR)提升了0.88%,最终得到适用本文数据集的12个聚类中心,并确定先验锚框的尺寸,如表2所示。
2.2 注意力机制
由于农田环境的复杂性,周围农作物对目标障碍物的影响,光照等自然因素的作用,可能存在对目标障碍物漏检的现象。因此,在原模型Neck层C3模块后,引入串联通道注意力机制和空间注意力机制的CBAM卷积块注意模块,自适应的细化中间的特征映射,增加其表征能力,其结构如图3所示。
使用最大池化(Max Pooling)和平均池化(Average Pooling)对特征图特征进行空间信息汇总,得到两个1×1×C的通道描述,然后将这两个描述输入共享多层感知机内,共享多层感知机是由一个多层感知机和一个隐藏层组成,再将得到的两个特征元素相加,经过一个sigmoid函数激活得到通道注意力Mc(F),其计算方法如式(2)所示。
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))
=σ(W1(W0(Fcavg))+W1(W0(Fcmax)))(2)
式中:F——输入特征;
σ(·)——sigmoid激活函数;
MLP——多层感知机;
Fcavg——平均池化后的特征;
Fcmax——最大池化后的特征;
W1、W0——MLP的两个对输入共享的权重参数。
利用特征图的空间关系生成空间注意力模块,在加强图像空间位置信息的同时,也弥补了通道注意力模块所造成的一些位置信息的损失。其计算方法如式(3)所示。
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
=σ(f7×7([Fsavg;Fsmax]))(3)
输入特征F首先沿着通道轴应用平均池化和最大池化操作,得到Fsavg和Fsmax,并将它们拼接起来得到一个特征描述符,再经过一个7×7的卷积层和sigmoid函数激活得到空间注意力Ms。
CBAM注意力模块加入前后对比结果如图4所示。图4中高显著度区域用红色表示,颜色越深表示显著度越高。
从图4可以看出,加入CBAM注意力模块后,抑制了周围无用的环境信息,增强了待测目标的显著度,解决原网络无注意力偏好的问题,使网络能够更多地关注有意义的信息,为后续障碍物的精确检测奠定了基础。
2.3 Ghost卷积
深度卷积神经网络包含大量的卷积操作,而在实际应用中需要将模型部署在嵌入式终端,但是当具有大量参数的复杂模型加在性能较差的终端上时,会导致即使训练后模型精度高,但在使用过程中因为计算工作量问题导致实时性较低、精度下降。因为普通卷积生成的特征图会出现大量相似的特征,针对这一问题,引入Ghost卷积模块,将普通卷积生成特征图的过程分解为两部分,首先Ghost卷积将原始图像先通过少量卷积生成一小部分特征,然后利用廉价的线性操作生成剩下相似的特征,Ghost卷积模块如图5所示。
假设输入为X,经过任意卷积层可生成n个特征映射,在Ghost卷积模块中,输入X首先使用普通卷积生成m个固有特征映射Y′,然后对每个固有特征映射Y′进行s次廉价的线性变换,根据式(4)得到s个Ghost特征。
yij=Φi,j(yi′) i=1,…,m,j=1,…,s(4)
式中:y′i——Y′第i个固有特征;
Φi,j——生成第j个ghost特征线性运算。
最终得到n=m×s特征图Y=[y11,y12,…,yms],作为Ghost卷积模块的输出。
本文利用Ghost卷积构建GhostC3模块,替换原模型特征融合层中Conv和C3模块,在保证模型精度的基础上,大幅降低模型复杂度,减少模型参数,利于低性能设备上的部署。
2.4 Neck层改进
原YOLOv5模型中采用的是FPN+PAN的特征金字塔结构,FPN自顶向下传达强语义特征,PAN则自底向上传达强定位特征。通过对本文所构建数据集进行分析,发现所检测物体尺度跨度过大。针对这一问题,在YOLOv5的基础上增加一个预测头来应对多尺度物体的检测,结合其他三个预测头,四个检测头输出结构可以缓解标注对象尺度方差带来的负面影响,有效提高多尺度目标识别的精度。同时因为神经网络层数不断加深,特征信息会不可避免地有所损失,并在Neck层特征融合过程中,跨层级连接主干网络提取的特征,使预测特征层既拥有顶层的语义信息又拥有底层的位置信息,实现更高层次的特征融合,如图2中Neck层所示。
3 试验结果与分析
3.1 试验环境
本试验使用的操作系统为Ubuntu18.04,显卡型号为NVIDIA RTX2060 6G,CPU为i7-1165G7,运行内存大小为16 G,基于Pytorch深度学习框架,编程语言为Python,使用CUDA11.3和CUDNN8.2.4对GPU进行加速, Learning_rate设为0.01,Weight_decay为0.000 5,Momentum为0.937,训练100个Epochs。
3.2 数据集介绍
数据集可视化分析如图6所示。
试验中所用数据集为从多种渠道搜集、具有典型农业生产信息的图片6 766张,包含以田间劳作农民为主的人,农业机械和羊三类目标障碍物,并通过LabelImg标注软件对数据进行标注,按照9∶1的比例将数据集随机划分为训练集和测试集,最终得到的数据集包含6 766张标注图片,其中训练集6 089张图片,测试集677张图片。
3.3 评价指标
为准确评价本文改进模型的性能,使用mAP@0.5、召回率(Recall, R)、精确率(Precision, P)、模型参数量作为本文模型的评价指标。其中mAP@0.5为IoU阈值为0.5时所有类别平均精度(Average Precision,AP)的平均值,召回率表示所有障碍物被识别出来的比率,精确率表示障碍物在所识别目标中所占比率,计算如式(5)~式(7)所示。
AP=∫10P(R)dR(5)
P=TPTP+FP(6)
R=TPTP+FN(7)
式中:TP——实际为正样本,检测为正样本的数量;
FP——实际为负样本,检测为正样本的数量;
FN——实际为正样本,检测为负样本的数量。
3.4 结果分析
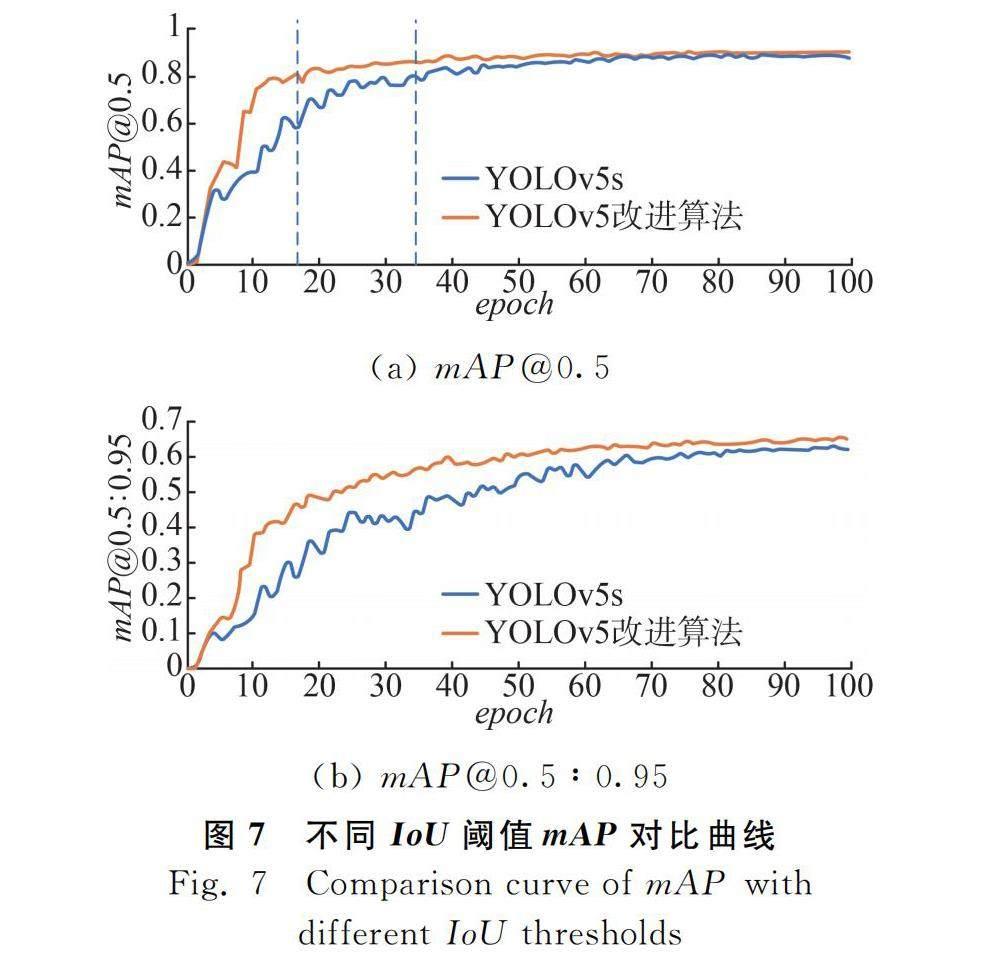
改进后的网络模型与YOLOv5s训练平均精度(mean Average Precision, mAP)对比结果如图7所示。
从图7(a)可以看出,两种算法都具有较高的精度,其中YOLOv5改进算法mAP@0.5在迭代到第16轮时就达到0.8,最终逐渐稳定到0.9左右,而YOLOv5s算法迭代到第34轮mAP@0.5才达到0.8,最终稳定在0.87左右,YOLOv5改进算法较改进前提升了3个百分点;图7(b)表示是在0.5~0.95区间内不同IoU阈值上的平均mAP。
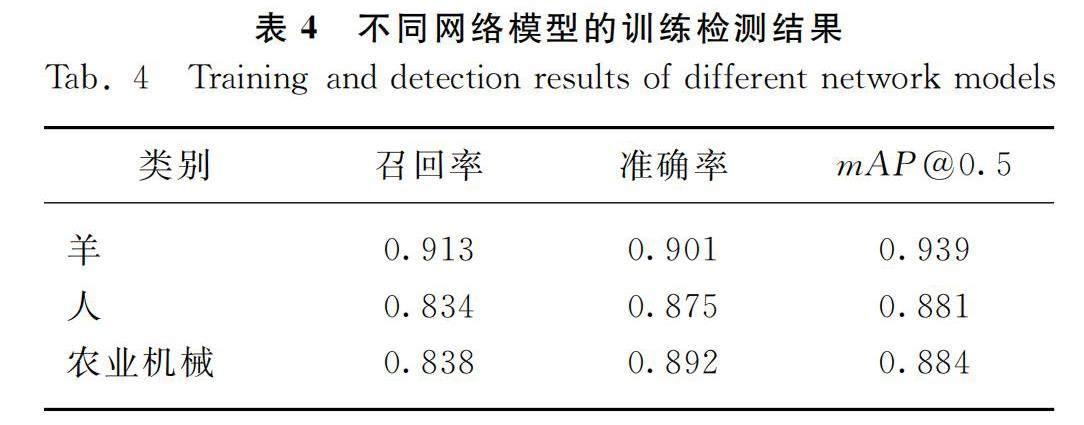
表4为各子类在改进算法上的检测结果。可以看出三类目标物的检测精度都在90%左右。召回率和准确率都在80%以上。
为验证改进后算法的优势,选取主流的单阶段及两阶段目标检测模型进行比较,对比结果如表5所示。
由表5可知,YOLOv5改进算法较原来YOLOv5s算法检测精度提高了2.3%,召回率提高3.1%,精确率提高了1.9%,时间提高3%,说明YOLOv5改进算法更适应于农田检测环境,减少因为遮挡等而造成的漏检问题,提高了算法的鲁棒性。Faster R-CNN作为两阶段目标检测算法的代表,精度和召回率都高于YOLO算法及SSD算法,但是精确率较低,检测速度要远慢于其他算法,实时性方面较差,硬件需求较高。而YOLOv5改进算法经过轻量化的改进,训练后的网络权重从14.4 MB减少到14.0 MB,检测速度也得到了提升,远快于其他目标检测算法。通过对比试验可以看出,YOLOv5改进算法在农田障碍物检测方面有较高的精度和检测速度,可以更有效地进行障碍物的识别,同时拥有更好的检测性能。
为验证YOLOv5改进算法各部分作用,进行消融试验验证,其结果如表6所示。
通过表6可以看出,在原YOLOv5s模型基础上,通过使用k-means聚类算法修改先验框尺寸,mAP提高了0.7%,召回率提高了0.4%,准确率提高了0.4%。说明修改后的先验框尺寸比原始尺寸更加合理;在Neck层增加跨层级特征融合并增加一个检测头,虽然参数量有所增加,但是mAP提高了1.2%,召回率提高了1.3%,精确率提高了1.7%,缓解了数据集标注尺度方差大的问题,提高了检测精度;针对由于检测物体周围环境影响造成的漏检问题,在Neck层增加CBAM注意力模块,mAP提高了0.9%,召回率提高了2.4%,降低漏检风险;对改进后的模型进行轻量化的改进,将Neck层中所有的普通卷积替换为Ghost卷积,mAP虽稍有下降,但仍然比原YOLOv5s模型检测精度提高了2.3%,召回率提高了3.1%,精确率提高了1.9%,参数量降低了7%左右,缓解了由于方法改进所造成参数量增加的问题,更有利于嵌入式设备的部署。总之,YOLOv5s改进算法在农田障碍物检测上,具有更高的准确率、召回率和更少的模型参数量,更适用于农田障碍物检测。
为进一步验证YOLOv5改进算法的有效性,选取相似环境干扰、沙尘、逆光、遮挡等几种典型情况进行验证测试,测试结果如图8所示。
从图8可以看出,YOLOv5改进算法比YOLOv5s算法检测出目标的置信度都有明显的提升;其中YOLOv5s算法在逆光、遮挡和相似环境影响的情况下都出现漏检问题,漏检目标在图8(a)中用蓝色框标出,而YOLOv5改进算法在这些环境因素影响下,仍然检测出目标,说明YOLOv5改进算法经过改进后减少了因为遮挡而造成的目标特征表达能力不足的问题,通过加入注意力模块,增强了特定目标区域的表征能力,弱化背景环境的影响,有效解决了检测过程中的漏检问题。
4 结论
1) 提出一种基于YOLOv5的田间复杂环境障碍物检测的改进型算法,即应用基于使用d(bboxes,anchors)作为样本之间的距离的k-means聚类算法得到先验锚框的最佳匹配结果,提高目标障碍物的识别精度和定位精度;引入CBAM注意力模块,缓解由于环境影响导致目标显著度弱造成的漏检;通过增加检测头,跨层级连接主干特征,增强多尺度特征表达能力,提高检测精度;将Neck层中的普通卷积替换为Ghost卷积,减少模型参数,提高检测速度,有效提高了嵌入式设备部署的适应性。
2) 通过构建农田障碍物数据集,完成YOLOv5改进算法的测试验证。结果表明:YOLOv5改进算法在田间复杂环境下,对目标障碍物的平均检测精度达90.1%,较YOLOv5s检测算法提升了2.3个百分点,并且降低了模型的复杂度,单张图片的检测速度减少到0.009 s。
参 考 文 献
[1]薛金林, 李雨晴, 曹梓建. 基于深度学习的模糊农田图像中的障碍物检测技术[J]. 农业机械学报, 2022, 53(3): 234-242.
Xue Jinlin, Li Yuqing, Cao Zijian. Obstacle detection based on deep learning for blurred farmland images [J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(3): 234-242.
[2]Mwalupaso G E, Wang S, Rahman S, et al. Agricultural informatization and technical efficiency in maize production in Zambia [J]. Sustainability, 2019, 11(8): 2451.
[3]何勇, 蒋浩, 方慧, 等. 车辆智能障碍物检测方法及其农业应用研究进展[J]. 农业工程学报, 2018, 34(9): 21-32.
He Yong, Jiang Hao, Fang Hui, et al. Research progress of intelligent obstacle detection methods of vehicles and their application on agriculture [J]. Transactions of the Chinese Society of Agricultural Engineering, 2018, 34(9): 21-32.
[4]郝帅, 杨磊, 马旭, 等. 基于注意力机制与跨尺度特征融合的YOLOv5输电线路故障检测[J]. 中国电机工程学报, 2023(6): 2319-2330.
Hao Shuai, Yang Lei, Ma Xu, et al. YOLOv5 transmission line fault detection based on attention mechanism and cross-scale feature fusion [J]. Proceedings of the CSEE, 2023(6): 2319-2330.
[5]Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[6]Girshick R. Fast R-CNN [C]. Proceedings of the IEEE International Conference on Computer Vision, 2015: 1440-1448.
[7]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks [J]. Advances in Neural Information Processing Systems, 2015, 28.
[8]夏成楷. 基于深度学习的农田障碍物的识别和无人农业车辆避障策略研究[D]. 南京: 南京农业大学, 2020.
Xia Chengkai. Research on farmland obstacle recognition based on deep learning and obstacle avoidance strategies for unmanned agricultural vehicles [D]. Nanjing: Nanjing Agricultural University, 2020.
[9]Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector [C]. Computer Vision-ECCV, 2016: 14th European Conference, 2016: 21-37.
[10]Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection [C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 2980-2988.
[11]Redmon J, Farhadi A. YOLO9000: Better, faster, stronger [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 7263-7271.
[12]Redmon J, Farhadi A. Yolov3: An incremental improvement [J]. ArXiv preprint ArXiv: 1804.02767, 2018.
[13]Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection [J]. arXiv preprint arXiv: 2004.10934, 2020.
[14]刘俊明, 孟卫华. 基于深度学习的单阶段目标检测算法研究综述[J]. 航空兵器, 2020, 27(3): 44-53.
Liu Junming, Meng Weihua. Review on single-stage object detection algorithm based on deep learning [J]. Aero Weaponry, 2020, 27(3): 44-53.
[15]赵奇慧, 刘艳洋, 项炎平. 基于深度学习的单阶段车辆检测算法综述[J]. 计算机应用, 2020, 40(S2): 30-36.
Zhao Qihui, Liu Yanyang, Xiang Yanping. Review of one-stage vehicle detection algorithms based on deep learning [J]. Journal of Computer Applications, 2020, 40(S2): 30-36.
[16]刘慧, 张礼帅, 沈跃, 等. 基于改进SSD的果园行人实时检测方法[J]. 农业机械学报, 2019, 50(4): 29-35, 101.
Liu Hui, Zhang Lishuai, Shen Yue, et al. Real-time pedestrian detection in orchard based on improved SSD [J]. Transactions of the Chinese Society for Agricultural Machinery, 2019, 50(4): 29-35, 101.
[17]魏建胜, 潘树国, 田光兆, 等. 农业车辆双目视觉障碍物感知系统设计与试验[J]. 农业工程学报, 2021, 37(9): 55-63.
Wei Jiansheng, Pan Shuguo, Tian Guangzhao, et al. Design and experiments of the binocular visual obstacle perception system for agricultural vehicles [J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37(9): 55-63.
[18]李文涛, 张岩, 莫锦秋, 等. 基于改进YOLOv3-tiny的田间行人与农机障碍物检测[J]. 农业机械学报, 2020, 51(S1): 1-8, 33.
Li Wentao, Zhang Yan, Mo Jinqiu, et al. Detection of pedestrian and agricultural vehicles in field based on improved YOLOv3-tiny [J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(S1): 1-8, 33.
[19]Wang J, Chen Y, Gao M, et al. Improved YOLOv5 network for real-time multi-scale traffic sign detection [J]. arXiv preprint arXiv: 2112.08782, 2021.
[20]杨娟娟, 高晓阳, 李红岭, 等. 基于机器视觉的无人机避障系统研究[J]. 中国农机化学报, 2020, 41(2): 155-160.
Yang Juanjuan, Gao Xiaoyang, Li Hongling, et al. Research on UAV obstacle avoidance system based on machine vision [J]. Journal of Chinese Agricultural Mechanization, 2020, 41(2): 155-160.
[21]刘路, 潘艳娟, 陈志健, 等. 高遮挡环境下玉米植保机器人作物行间导航研究[J]. 农业机械学报, 2020, 51(10): 11-17.
Liu Lu, Pan Yanjuan, Chen Zhijian, et al. Inter-rows navigation method for corn crop protection vehicles under high occlusion environment [J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(10): 11-17.
[22]Woo S, Park J, Lee J Y, et al. CBAM: Convolutional block attention module [C]. Proceedings of the European Conference on Computer Vision (ECCV), 2018: 3-19.
[23]Han K, Wang Y, Tian Q, et al. GhostNet: More features from cheap operations [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1580-1589.
猜你喜欢
制造技术与机床(2018年12期)2018-12-23 02:40:52
电子制作(2018年18期)2018-11-14 01:48:20
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
电脑知识与技术(2016年28期)2016-12-21 12:13:14
科技视界(2016年26期)2016-12-17 17:31:58
科教导刊(2016年25期)2016-11-15 17:53:37
软件工程(2016年8期)2016-10-25 15:55:22
科技视界(2016年20期)2016-09-29 11:11:40
企业导报(2016年10期)2016-06-04 11:37:43
