
面向联合收割机故障诊断领域知识图谱的构建技术及其问答应用
2024-06-17 03:42:20杨宁杨林楠陈健
中国农机化学报 2024年6期
杨宁 杨林楠 陈健
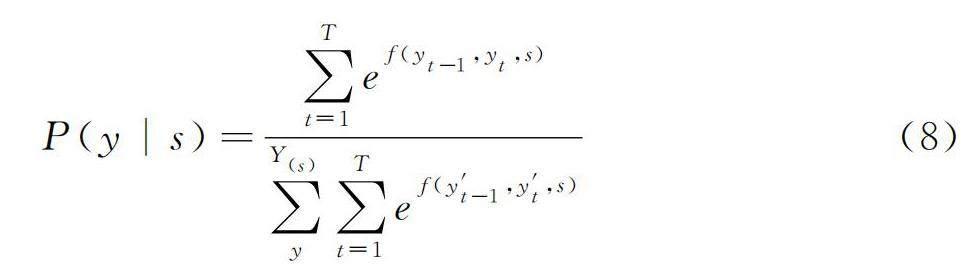
摘要:联合收割机作为一种有效的机械化收割设备,可以极大地提高农作物的收获效率。然而在进行收割作业时不可避免地会发生一些机械故障,由于驾驶员缺乏专门的维修经验,无法确定故障发生的原因以及出现故障后应该如何维修机器,导致严重影响农作物的收获,甚至还可能引发安全事故。由于知识图谱能够利用图数据库将专家知识等非结化数据进行规范化的存储,所以在故障诊断问答领域,知识图谱有着良好的应用前景,基于此提出一套面向联合收割机故障诊断领域知识图谱的构建方法。根据专家知识明确知识图谱中所需要的实体和实体关系类型,利用RoBERTa-wwm-ext预训练模型融合双向门控循环单元(BiGRU)和Transformer编码器的实体抽取模型对非结构化文本进行实体抽取;利用RoBERTa-wwm-ext预训练模型融合循环神经网络(RNN)模型对抽取的实体进行实体审核;在实体审核完成后使用RoBERTa-wwm-ext预训练模型融合双向门控循环单元(BiGRU)和注意力机制的关系抽取模型对头实体和尾实体之间存在的实体关系进行抽取;将抽取到的实体和实体关系组成三元组,利用三元组构建知识图谱,从而可以利用知识图谱实现智能问答。
关键词:联合收割机;知识图谱;预训练模型;故障诊断;双向门控循环单元
中图分类号:S225
文献标识码:A
文章编号:2095-5553 (2024) 06-0170-08
收稿日期:2022年11月27日
修回日期:2023年1月6日
*基金项目:国家重点研发计划(2021YFD1000205)
第一作者:杨宁,男,1997年生,山东滨州人,硕士研究生;研究方向为自然语言处理。E-mail: 804141529@qq.com
通讯作者:杨林楠,男,1964年生,云南保山人,博士,教授;研究方向为农业信息化。E-mail: lny5400@163.com
Construction techniques for knowledge graphs in the field of combine harvester fault
diagnosis and their question and answer applications
Yang Ning1, 2, 3, Yang Linnan1, 2, 3, Chen Jian1, 2, 3
(1. School of Big Data, Yunnan Agricultural University, Kunming, 650201, China; 2. Agricultural Big Data Engineering Research Center of Yunnan Province, Kunming, 650201, China; 3. Green Agricultural Product Big Data Intelligent Information Processing Engineering Research Center, Kunming, 650201, China)
Abstract: As an effective mechanized harvesting equipment, the combine harvester can greatly improve the harvesting efficiency of crops. However, it is inevitable that some mechanical failures will occur during harvesting operations. Since the driver lacks specialized maintenance experience, he does not know the cause of the failure and how to repair the machine when the failure occurs. This will seriously affect the harvest of crops, and even it may also cause safety accidents. Since knowledge graphs can use graph databases to store unstructured data such as expert knowledge in a standardized manner, knowledge graphs have good application prospects in the field of fault diagnosis question and answer. Based on this, a set of knowledge graphs for combine harvester fault diagnosis is proposed. Firstly, the entities and entity relationship types required in the knowledge graph are clarified based on expert knowledge, the entity extraction model of the Bidirectional Gated Recurrent Unit (BiGRU) and the Transformer encoder is combined with the RoBERTa-wwm-ext pre-training model to extract entities from unstructured text. Secondly, the RoBERTa-wwm-ext pre-training model is again used to fuse the recurrent neural network (RNN) model to conduct entity review of the extracted entities. Thirdly, after the entity review is completed, the RoBERTa-wwm-ext pre-training model is used to extract the entity relationships existing between the head entity and the tail entity, by combining the relationship between the Bidirectional Gated Recurrent Unit (BiGRU) and the attention mechanism. Finally, the extracted entities and entity relationships are formed into triples, and the triples are used to build a knowledge graph, so that the knowledge graph can be used to implement intelligent question and answer.
Keywords: combine harvester; knowledge graph; pre-training model; fault diagnosis; bidirectional gated recurrent unit
0 引言
知识图谱其本质是将结构化的知识存入知识库,用来对物理世界中的相互关系及其概念进行描述。“实体—关系—实体”的三元组类型,以及相关“属性—值对”是构成知识图谱的基本组成单位,实体之间通过关系相互联结,构成了网状的知识结构[1]。
知识图谱自诞生以来在问答领域[2]就得到了广泛的应用。王寅秋等[3]利用专业的医疗知识图谱,让公众能够在医疗社区中更便利、更准确地获取有价值的信息。曹明宇等[4]针对成人中常见的原发性肝癌,从知识库中抽取知识三元组构建了原发性肝癌的知识图谱,在此基础上实现了能够有效回答原发性肝癌相关的药物、疾病及表征等问题。
借鉴知识图谱在问答领域的成功应用,国内外也已经有相关文献将知识图谱引入到故障诊断问答领域。薛莲等[5]提出了一种磁悬浮轴承故障领域知识图谱构建方法,对磁悬浮故障领域的故障诊断具有一定的指导意义。吴闯等[6]提出了一套面向航空发动机润滑系统的故障知识图谱构建方法,实现了润滑系统故障知识智能问答和故障归因分析应用。然而针对联合收割机故障诊断的知识图谱构建方法及其问答应用还尚未有研究。
联合收割机在出厂的时候,从事研发和测试的相关人员会根据研发和测试的数据编写大量有关联合收割机故障诊断的文本数据,可以利用这些非结构化的文本数据结合知识图谱构建技术从中抽取实体以及实体之间的关系组成三元组来构建知识图谱。因此,提出一套面向联合收割机故障诊断知识图谱的构建及应用流程。
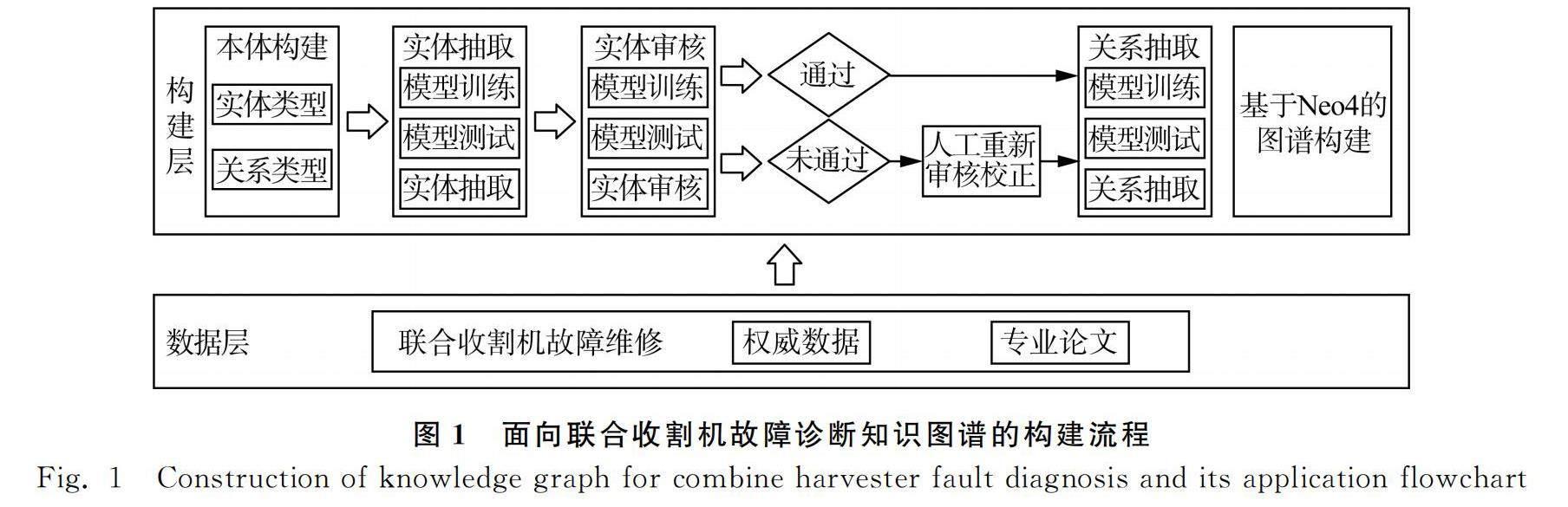
1 联合收割机故障诊断领域知识图谱总体构建流程
如图1所示,面向联合收割机故障诊断知识图谱的构建主要分为两层。第一层为数据层,主要以权威的故障诊断书籍以及专业的论文作为数据来源构建起原始语料库。第二层为构建层,构建知识图谱主要分为两种,一种是自底向上的构建方法在构建通用知识图谱时比较合适,另一种是自顶向下的构建方法在构建垂直行业知识图谱时较为适用[7]。由于在故障诊断领域是较为专业的垂直领域,所以本文采用自顶向下的构建方法。为了减小实体抽取误差对实体关系抽取的影响,相较于传统自顶向下构建知识图谱方法,本文在实体抽取和关系抽取之间加入实体审核任务,用来规避一些不规范的实体。
2 本体构建
本体是一个数据模型,表示一组概念以及一个域中这些概念之间的关系[8]。在构建对某一专业领域的图谱时,应根据专家知识先行构建该图谱的本体,为后续的实体抽取和关系抽取提供规范。本体构建主要包括规定实体类型、规定实体关系类型、确定头实体和尾实体。
对联合收割机故障诊断知识图谱规定的实体类型为故障部位、故障名称、故障原因以及故障维修。关系类型及其头、尾实体如表1所示。构建完成的本体可视化结构如图2所示。
3 实体抽取
3.1 实体抽取模型
在知识图谱中每个节点都是由实体构成,因此在构建知识图谱时需要利用实体抽取模型参照构建的实体类型对相关领域的非结构化文本进行实体抽取。在深度学习技术出现之前,像隐马尔可夫(HMM)、最大熵隐马尔可夫(EMHMM)大部分都是基于线性统计模型来实现的实体抽取的。随着近几年深度学习的不断发展,基于端到端的实体抽取模型不断地被提出,其中最为经典的是由Huang等[9]提出的BiLSTM+CRF模型,并在实体抽取中取得了不错的成绩。后来又有研究人员将以BERT为代表的预训练模型加入BiLSTM+CRF中,使得实体抽取的效果得到了进一步的提升,也使得BERT+BiLSTM+CRF成为目前主流的实体抽取模型。
本文针对联合收割故障诊断领域的实体抽取对BERT+BiLSTM+CRF模型进行了改进,提出了RoBERTa-wwm-ext+BiGRU+Multi-Head-Self-Attention+CRF模型。模型图如图3所示,该模型主要利用的是RoBERTa-wwm-ext预训练模型作为词嵌入层,将Transformer的编码器层融合双向门控循环单元(BiGRU)作为的上下文编码器,最后利用条件随机场(CRF)作为解码器进行实体的输出。
3.2 词嵌入层
RoBERTa预训练模型是Liu等[10]沿着BERT预训练模型的训练思路,针对BERT在训练中存在的不足之处进行了改进从而提出的一种新的预训练模型,通过使用动态掩码策略、调整优化器参数和使用更大的字符编码等方法使得RoBERTa预训练模型的性能要比BERT预训练模型更加优秀。RoBERTa-wwm-ext是根据Cui等[11]提出的全词遮蔽(WWM)策略使用中文数据集重新训练RoBERTa所得到的一种新的预训练模型。全词遮蔽策略是对词语作遮蔽语言训练,因为中文的词语由多个字符组成,直接遮蔽单个字符可能会导致语义信息的丢失。通过使用全词遮蔽策略,能够更好地捕捉中文词语的完整语义,从而提高模型在中文自然语言处理任务中的表现。
3.3 位置编码器
在自然语言中,每一句话都是由单词构成,单词在句子中出现的位置不同代表的语义信息也就不同。Transformer不同于时序类的神经网络,其通过自注意力机制来获取句子中词与词之间的关系,但是自注意力机制无法获取词在句子中位置信息,故需要在词向量进入Transformer编码器前加入位置编码器,这样就可以将词汇在不同位置产生语义信息添加到词嵌入的张量中去,弥补了信息的缺失。位置编码器主要使用的绝对位置编码,是由sin函数和cos函数的线性变换来提供给模型位置信息,计算如式(1)、式(2)所示。其中,pos代表当前字符在序列中位置,从1到序列长度的范围内取值;i代表嵌入向量的维度的索引;dmodel代表嵌入向量的维度,即每个元素在嵌入空间中的表示维度;PE(pos,2i)代表绝对位置编码中的正弦函数部分,在位置pos和维度2i上的正弦值;PE(pos,2i+1)代表绝对位置编码中的余弦函数部分,表示在位置pos和维度2i+1上的余弦值。这些变量在绝对位置编码的公式中通过正弦和余弦的运算,为序列中的每个位置pos的每个维度i提供了一个独特的编码值,以便模型能够理解输入序列中不同位置的元素。
PE(pos,2i)=sinpos10 0002idmodel(1)
PE(pos,2i+1)=cospos10 0002idmodel(2)
3.4 上下文编码层
上下文编码层主要是由Transformer的编码器层和双向门控循环单元(BiGRU)组成。Transformer编码器对于句子语义信息能够进行很好的挖掘,融合双向循环门控单元对目标词的上下文进行区分,两者相互融合使得获取的词向量更加符合语义信息。
在Transformer编码器中主要是利用多头自注意力来获取单词在句子中的语义信息。多头自注意力的计算规则是一个词的词向量Xt={x1,x2,x3,x4,…},其中xi是输入序列的第i个元素,根据规定的头数平均分割,每一个分割下来的向量进行三个线性变换乘以三个不同的权重矩阵Wq、Wk、Wv得到三个形状相同但数值不同的向量Qi(query)、Ki(key)、Vi(value),将Qi与所有的键Kj的转置做点积运算,然后除以一个缩放系数dk,dk是键Kj的维度。再使用softmax处理,这里的softmax函数将计算每个注意力分数的指数,然后对它们进行归一化,使它们的和等于1,最后与Vj做张量乘法,这里的Vj值向量序列的第j个元素,最后将每个分割下来的向量再重新拼接,拼接后的向量就是经过多头注意力计算后的词向量。在这里需要注意当Q、K、V的来源相同时才是自注意力机制。计算图如图4所示。计算公式如式(3)所示。
Attention(Q,K,V)=softmaxQi·KTjdk·Vj(3)
在深度学习网络中往往会出现退化和训练困难的问题,因此Transformer编码器加入了残差网络和层归一化,优化了在训练过程存在的梯度消失和训练困难的问题。
由于传统的循环神经网络(RNN)在时间方向进行反向传播更新梯度参数时会流经tanh节点和矩阵乘机节点。y=tanh(x)的导数为dydx=1-y2,根据其导数可知,当导数的值小于1时,随着x的值在正数方向不断增加,导数的值是越来越接近于0的,这就意味着如果梯度经过tanh节点过多的话,导数的值就会慢慢趋近于0,从而出现梯度消失的现象,一旦出现梯度消失,权重参数将无法进行更新,这也是传统循环神经网络无法学习到长时序依赖的主要原因之一。当梯度经过矩阵乘机节点时梯度会随着时间步的增加呈现出指数级别的增长,当梯度过于庞大时就会出现非数值,导致神经网络无法进行学习,从而引发梯度爆炸。长短时记忆网络(LSTM)通过引进输入门、遗忘门和输出门在一定程度缓解了传统循环神经网络所带来的问题[12]。门控循环单元(GRU)作为LSTM的改进版本,不仅具有LSTM的优势而且还减少了计算成本和参数。GRU计算图如图5所示,由于没有记忆单元,只有一个隐藏状态h参与门控循环单元在时间上的传播,所以门控循环单元只设置了重置门r和更新门z,降低了计算成本。重置门是决定在多大程度上“忽略”过去的隐藏信息,更新门则是对新增的信息进行加权。门控循环单元计算如式(4)~式(7)所示,其中h~是新的隐藏状态。由于单向的门控循环单元只能学习到上文的信息,而没有办法学习到下文的信息,然而利用双向的门控循环单元不仅可以学习到上文的信息也可以学习到下文的信息,提高了模型对实体的抽取精度。
z=σ(xtW(z)x+ht-1W(z)h+b(z))(4)
r=σ(xtW(r)x+ht-1W(r)h+b(r))(5)
h~=tanh(xtWx+(r⊙ht-1)Wh+b)(6)
ht=(1-z)⊙ht-1+z⊙h~(7)
式中:xt——输入矩阵;
ht——隐藏状态矩阵;
ht-1——前一个隐藏状态矩阵;
Wx——输入状态权重矩阵;
Wh——隐藏状态权重矩阵;
b——输出偏置项。
3.5 解码层
条件随机场(CRF)是一种给定输入随机变量X,求解条件概率P(y|x)的概率无向图模型。因为隐马尔可夫模型(HMM)存在观察独立假设和隐马尔可夫链,所以对于序列标注问题不是很合理。最大熵模型(EM)在进行序列标注的时候会出现标签偏离的情况。条件随机场是在这两个模型的基础上提出的一种判别生成模型,不仅打破了隐马尔可夫模型的两个假设而且还对最大熵模型存在标签偏差的问题进行了修正,使模型在序列标注问题上可以做到全局的归一化,对标签进行更好的预测。建模公式如式(8)所示,给定一个序列s=[s1,s2,…,sT]其对应标签序列为y=[y1,y2,…,yT],Y(s)代表所有有效标签的序列,y的概率是由式(8)计算得出的。在式(8)中f(yt-1,yt,s)是计算yt-1到yt的转化分数,来最大化P(y|s),使用维特比算法找到最优的标签路径输出,e代表指数函数。
P(y|s)=∑Tt=1ef(yt-1,yt,s)∑Y(s)y∑Tt=1ef(y′t-1,y′t,s)(8)
3.6 试验与分析
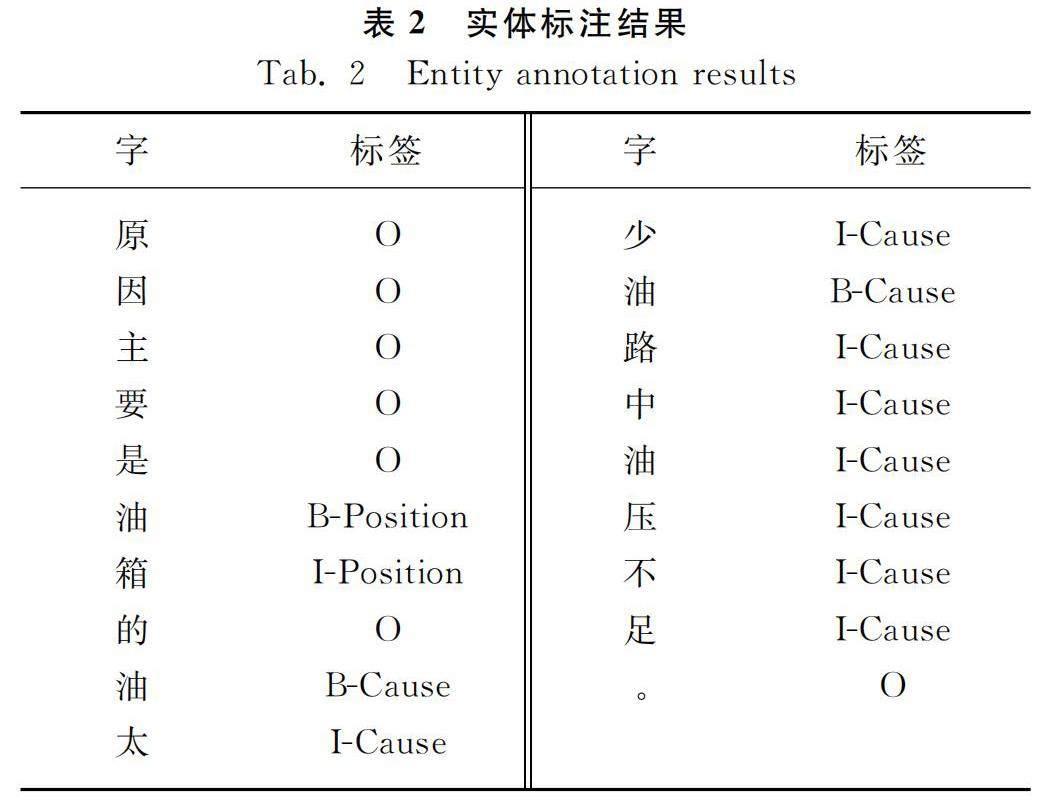
根据构建的联合收割机故障诊断语料库,采用BIO标记,利用YEEDA[13]实体标记工具共标记实体8 159个,“故障部位”4 147个实体、“故障原因”1 514个实体,“故障维修”1 014个实体、“故障名称”1 484个实体。实体标注结果如表2所示。实体抽取模型中超参数的参数配置如表3所示。
将实体抽取数据集按照8∶2的比例来划分训练集和测试集,参照混淆矩阵用精确率P(Precision),召回率R(Recall)和F1值(F1-measure)作为评价指标。其计算如式(9)~式(11)所示。
P=TPTP+FP(9)
R=TPTP+FN(10)
F1=2×P×RP+R(11)
式中:TP——模型预测为正类的正样本;
FP——模型预测为正类的负样本;
FN——模型预测为负类的正样本。
为了验证RoBERTa-wwm-ext+BiGRU+Multi-Head-Self-Attention+CRF模型优于传统的BERT+BiLSTM+CRF模型,所以本文进行了模型对比试验,模型对比结果如表4所示。从模型对比结果可知,RoBERTa-wwm-ext+BiGRU+Multi-Head-Self-Attention+CRF的准确率、召回率和F1值均优于传统的BERT+BiLSTM+CRF模型。
4 实体审核
4.1 实体审核模型
因为实体关系抽取任务会用到实体抽取的结果,所以实体抽取结果的好坏会影响实体关系抽取结果的好坏,因为实体抽取模型抽取实体的准确度并不能达到100%所以会存在一些实体抽取的误差,所以我们在实体抽取任务和实体关系抽取任务之间加入实体审核任务,目的就是为了减小这个误差对实体关系抽取的影响。在审核的过程中模型主要是根据字符本身的组合方式来进行判别,实际上,这是一种不需要获取长时序关系的文本分类任务。再加上RNN循环神经网络模型的参数较少,计算比较简单,对于获取短时序本文关系的效果和性能都能达到很好的均衡,所以选用RNN循环神经网络来解决短文本分类任务。实体审核模型架构如图6所示,该模型主要包含词嵌入层和循环神经网络层。
每条文本在经过实体抽取后会将抽取出来的实体保存为文本类型的文件,用于实体审核模型的输入。例如一段文本‘通常作物产量愈高前进速度就愈慢否则易发生堵塞或超负荷现象。当实体抽取模型能够准确地抽取出文本中所存在的故障名称实体为“堵塞”和“超负荷”时,就会通过实体审核进入下一个环节,反之将由人工根据本文重新进行提取后进入下一个环节。
4.2 实体审核数据集与数据分析
实体审核数据集样例如表5所示,实体审核数据集样本分析如表6所示。根据表6可知,实体审核数据样本的平均长度是5.11,长度中位数是4.0,因此实体审核数据集属于短文本,使用RNN循环神经网络就可以达到很好的分类效果。
4.3 RNN循环神经网络
存在一个环路是循环神经网络(RNN)最主要的特征,通过这个环路数据就可以不断地得到循环,正是循环神经网络存在这样的特征,才使得循环神经网络在记住过去数据信息的同时还可以更新数据。如图7所示,通过展开RNN层的循环,将其转化成了从左向右延伸的长神经网络,每个时刻的RNN层前面是输入后面是输出,据此可以计算出当前时刻的输出,计算如式(12)所示。在式(12)中,首先执行矩阵的乘积运算,然后使用tanh函数变换它们的和,其结果就是时刻t的输出ht,这个ht有两个不同的流向,向上输出到下一个计算层,向右输出到下一个循环神经网络层。现在的出处ht是由前一个输出ht-1计算出来的,这就说明RNN的状态h是通过式(12)来更新的。
ht=tanh(ht-1Wh+xtWx+b)(12)
4.4 试验与分析
将3 000条实体审核数据按照8∶2的比例来划分训练集和测试集,训练的损失值和准确值如图8、图9所示。从图8可以看出,基于RoBERTa-wwm-ext预训练模型融合循环神经网络的实体审核模型的准确率可以达到98.20%,具有很好的实体审核效果。
5 实体关系抽取
5.1 实体关系抽取模型
实体关系抽取是在已完成实体识别的基础上,检索实体间所存在的关系,目前主流的抽取方法主要是基于规则和监督学习的方法[14]。基于规则的抽取方法虽然抽取的准确度较高但是存在覆盖率低和移植困难等问题。基于监督学习方法旨在通过标注部分相关数据集去训练一个关系抽取模型。本文模型架构如图10所示。
本文所使用的是基于监督学习的方法,通过改进模型来提高实体关系抽取的准确度。基于注意力机制的双向长短期记忆网络(BiLSTM)关系抽取算法是由Zhou等[15]在2016年自然语言处理处理(Natural Language Processing,NLP)领域的国际顶级会议Association for Computational Linguistics(ACL)上提出的。本文在此模型的基础上加入了预训练模型,将双向长短期记忆网络换成了双向门控循环单元,不仅极大地提高了实体关系的抽取准确率,而且计算成本更低。
5.2 注意力机制
当人们去观察新事物的时候,大脑会把焦点聚焦在事物中比较重要的地方,不需要从头到尾观察一遍事物后,才能有判断结果,注意力机制的提出正是基于这样的理论。注意力机制最早是由Mnih等[16]在计算机视觉领域提出,Bahdanau等[17]首次将注意力机制应用在自然语言处理领域,使机器翻译的效果得到了提升。2017年,文献[18]在机器翻译任务中使用了注意力机制取得良好的效果。注意力机制的计算规则是词向量H={h1,h2,h3,…,hn}经过tanh激活函数计算以后乘以权重矩阵W得到相似值,利用softmax函数将相似值归一化,词向量H再和归一化后的相似值相乘得到经过注意力计算后的词向量。计算公式如式(13)~式(16)所示。
M=tanh(H)(13)
S=M·W(14)
a=softmax(S)(15)
Fatt=H·aT(16)
5.3 试验与分析
将构建好的500条关系抽取数据集按照8∶2的比例划分出训练集、测试集,实体关系抽取数据集样例如表7所示,模型超参数配置如表8所示。
为了验证本文实体关系抽取模型的有效性和准确性,本文选取了传统的BERT+BiLSTM+Attention模型进行对比试验,如表9所示。结果表明本文的关系抽取模模型的准确率、召回率和F1值均优于传统的关系抽取模型。
6 图谱构建
将抽取到的实体和实体关系以三元组的形式存入到Neo4j图数据库中,构建起联合收割机故障诊断知识图谱。图谱的可视化数据如图11所示。
7 智能问答
7.1 意图分析
意图识别是进行知识问答的开始,也是机器人理解用户语义的前提,其主要任务是准确判断用户有什么样的需求,根据用户所提出的问题进行归类,本质上也是一项文本分类任务。意图槽不同所对应的意图也就不相同,意图分类的准确性也会直接影响到标签的识别和条件体、目标体的识别,因此一个好的意图识别方法对实现知识问答尤为重要。意图识别的方法主要包括基于监督学习的方法和基于规则词典的方法,由于缺乏相关的训练语料,本文将选择基于关键字和规则的问题方式来进行意图识别。
7.2 基于词典规则的意图分类
基于词典规则的意图识别方法需要构建规则模板以及类别信息来对用户的意图进行分类[19]。意图不同所匹配的领域字典也会不同,当接收到用户的意图后,会根据意图和词典的匹配程度或者重合程度来进行判断。虽然基于词典规则的意图识别方法会存在人力物力耗费大、难以维护和移植性较差等缺点,但是在小规模的数据集上构造相对容易,识别准确度高,对于缺乏训练语料的小样本数据来说效果很好。
7.3 应用
利用Python编程语言中内置的服务器访问模块,访问服务器。将对话接口接入到智能问答应用中,用户只需要下载相对应的手机应用输入想问的问题,如果数据库中存在能够回答相关问题的答案,机器人便会实现智能问答。
8 结论
1) 联合收割机在进行收割作业时容易发生机械故障,针对这个问题借鉴了知识图谱在故障诊断领域的成功经验,提出一套面向联合收割机故障诊断的知识图谱构建方法和流程。
2) 以专业的联合收割机维修书籍和论文为原始语料,构建起13万字的命名实体识别数据集,3 000条实体审核数据集,500条实体关系数据集,为后续的模型研究提供可靠的数据的支撑。
3) 未来还将进一步提高模型的抽取精度,建立更加可靠的农机故障诊断知识图谱,更好地服务于广大农机驾驶员朋友。
参 考 文 献
[1]刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.
Liu Qiao, Li Yang, Duan Hong, et al. Knowledge graph construction techniques [J]. Journal of Computer Research and Development, 2016, 53(3): 582-600.
[2]王智悦, 于清, 王楠, 等. 基于知识图谱的智能问答研究综述[J]. 计算机工程与应用, 2020, 56(23): 1-11.
Wang Zhiyue, Yu Qing, Wang Nan, et al. Survey of intelligent question answering research based on knowledge graph [J]. Computer Engineering and Applications, 2020, 56(23): 1-11.
[3]王寅秋, 虞为, 陈俊鹏. 融合知识图谱的中文医疗问答社区自动问答研究[J]. 数据分析与知识发现, 2023, 7(3): 97-109.
Wang Yinqiu, Yu Wei, Chen Junpeng. Automatic question-answering in Chinese medical Q & A community with knowledge graph [J]. Data Analysis and Knowledge Discovery, 2023, 7(3): 97-109.
[4]曹明宇, 李青青, 杨志豪, 等. 基于知识图谱的原发性肝癌知识问答系统[J]. 中文信息学报, 2019, 33(6): 88-93.
Cao Mingyu, Li Qingqing, Yang Zhihao, et al. A question answering system for primary liver cancer based on knowledge graph [J]. Journal of Chinese Information Processing, 2019, 33(6): 88-93
[5]薛莲, 姚新文, 郑启明, 等. 高铁列控车载设备故障知识图谱构建方法研究[J]. 铁道科学与工程学报, 2023, 20(1): 34-43.
Xue Lian, Yao Xinwen, Zheng Qiming, et al. Research on construction method of fault knowledge graph of CTCS on-board equipment [J]. Journal of Railway Science and Engineering, 2023, 20(1): 34-43.
[6]吴闯, 张亮, 唐希浪, 等. 航空发动机润滑系统故障知识图谱构建及应用[J]. 北京航空航天大学学报, 2024(2): 1-14.
Wu Chuang, Zhang Liang, Tang Xilang, et al. Construction and application of fault knowledge graph for aero-engine lubrication system [J]. Journal of Beijing University of Aeronautics and Astronautics, 2024(2): 1-14.
[7]瞿智豪, 胡建鹏, 黄子麒, 等. 工业设备故障处置知识图谱构建与应用研究[J]. 计算机工程与应用, 2023, 59(24): 309-318.
Qu Zhihao, Hu Jianpeng, Huang Ziqi, et al. Research on construction and application of knowledge graph for industrial equipment fault disposal [J]. Computer Engineering and Applications, 2023, 59(24): 309-318.
[8]谭玲, 鄂海红, 匡泽民, 等. 医学知识图谱构建关键技术及研究进展[J]. 大数据, 2021, 7(4): 80-104.
Tan Ling, E Haihong, Kuang Zemin, et al. Key technologies and research progress of medical knowledge graph construction [J]. Big Data Research, 2021, 7(4): 80-104.
[9]Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging [J]. arXiv Preprint arXiv: 1508.01991, 2015.
[10]Liu Y, Ott M, Goyal N, et al. RoBERTa: A robustly optimized BERT pretraining approach [J]. arXiv Preprint arXiv: 1907.11692, 2019.
[11]Cui Y, Che W, Liu T, et al. Pre-training with whole word masking for Chinese bert [C]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29 (13): 3504.
[12]Hochreiter S, Schmidhuber J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780.
[13]Yang J, Zhang Y, Li L, et al. YEDDA: A lightweight collaborative text span annotation tool [J]. arXiv Preprint arXiv: 1711.03759, 2017.
[14]王传栋, 徐娇, 张永. 实体关系抽取综述[J]. 计算机工程与应用, 2020, 56(12): 25-36.
Wang Chuandong, Xu Jiao, Zhang Yong. Survey of entity relation extraction [J]. Computer Engineering and Applications, 2020, 56(12): 25-36.
[15]Zhou P, Shi W, Tian J, et al. Attention-based bidirectional long short-term memory networks for relation classification [C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (volume 2: Short papers), 2016: 207-212.
[16]Mnih V, Heess N, Graves A, et al. Recurrent models of visual attention [J]. Advances in Neural Information Processing Systems, 2014, 3.
[17]Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate [J]. arXiv Preprint arXiv: 1409.0473, 2014.
[18]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [J]. Advances in Neural Information Processing Systems, 2017, 30.
[19]罗承天, 叶霞. 基于知识图谱的推荐算法研究综述[J]. 计算机工程与应用, 2023, 59(1): 49-60.
Luo Chengtian, Ye Xia. Survey on knowledge graph-based recommendation methods [J]. Computer Engineering and Applications, 2023, 59(1): 49-60.
猜你喜欢
农机使用与维修(2017年1期)2017-02-07 22:46:34
农机使用与维修(2017年1期)2017-02-07 22:42:10
农机使用与维修(2017年1期)2017-02-07 22:39:08
新教育时代·教师版(2016年33期)2016-12-02 22:26:31
智富时代(2016年12期)2016-12-01 16:28:41
中国远程教育(2016年9期)2016-11-19 12:21:26
中国教育信息化·基础教育(2016年9期)2016-10-18 02:29:50
中国科技博览(2016年11期)2016-05-06 09:09:16
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
