
基于丝绸行业电商评论的属性级情感分析
2024-06-17 16:56:20尤良辉张华熊
软件工程 2024年6期
关键词:深度学习
尤良辉 张华熊


摘 要:
随着移动互联网时代的快速发展,电商平台迅速崛起成为推动网络消费增长的一股新兴且强大的力量。为了有效利用海量的商品评论数据,文章基于京东商城丝绸商品的评论数据,使用词频统计对评论数据进行分析处理,构建属性\|情感词词典,填充了评论中的隐性属性。利用Label Studio数据标注平台对评论数据进行属性\|观点\|情感的三元标注,经过标注后的数据集被应用于UIE(Unified Structure Generation for Universal Information Extraction)模型进行属性级情感抽取,并基于抽取的数据集对ERNIE(Enhanced Language Representation with Informative Entities)模型进行微调训练。实验结果表明,该方法在属性级情感分析中的准确率高达90%,填充隐性属性后,准确率提升至94%,表明该方法所得模型在属性级情感分析中有着不错的效果。
关键词:电商评论;深度学习;UIE;属性级情感分析
中图分类号:TP391.9 文献标志码:A
0 引言(Introduction)
随着互联网的快速发展,电子商务已经迅速成为人们进行购物和交易的主导方式。截至2023年6月,我国拥有约10.79亿网民,互联网普及率达到76.4%[1]。这一迅猛发展不仅催生了电子商务的繁荣,还带来了海量的电子商务数据,其中商品的用户评论数据相对容易获取且不涉及敏感信息,因此对这些海量的商品评论数据进行深入分析和挖掘,以提取有价值的消费者见解和市场趋势,成为当前自然语言处理研究领域的热点之一[2]。同时,我国纺织服装企业的生产模式普遍仍以传统的加工制造为主,智能化、协同化、信息化制造能力不强。随着近年来信息技术的快速发展,纺织服装行业也有借助现代信息技术转变模式、提升竞争力的愿望。
基于以上背景,本文旨在运用深度学习技术对纺织服装行业的电商评论数据进行属性级情感分析,希望能够揭示丝绸纺织行业中消费者的情感、观点和动态兴趣等行为要素,为商家提供决策和管理方面的指导和建议。
属性级情感分析[3]是一种文本分析技术,旨在从文本中提取出与特定属性相关的情感信息。相比于传统的整体情感分析,属性级情感分析的细粒度更细,可以帮助分析人员更准确地了解消费者对不同属性的情感倾向。
在丝绸纺织行业中,电商评论常常出现面料、颜色、价格等多个维度的评论,并且每个维度都有对应的情感。例如,“丝巾还是很漂亮的,面料也很舒服,就是价格太贵了”评论中的“面料”维度对应的观点词是“舒服”,情感倾向为正向,而“价格”维度对应的观点词是“贵”,情感倾向为负向。因此,对于类似的评论,分析人员不能简单地对整个句子进行情感分析,而是需要找到一种方法更加深入地挖掘信息,这种方法便是属性级情感分析。
在属性级情感分析中,需要识别出评论中涉及的不同维度,针对每个维度找到与之相关的观点词和情感倾向,通过属性级情感的提取,分析人员可以了解每个维度上的用户观点和情感倾向,从而获得更丰富的情感分析结果。
2 [JP5]相关深度学习模型(Relevant deep learning models)
2.1 UIE模型
UIE(Unified Structure Generation for Universal Information Extraction)[4]模型是一个面向信息抽取的统一文本到结构生成框架,它可以统一建模不同的信息抽取任务,如实体、关系、事件和情感等,并自适应地生成目标结构。该模型设计了一种结构提取语言(Structure Extraction Language,SEL),该语言可以有效地将不同的信息抽取(Information Extraction,IE)结构编码为统一的表示,从而可以在相同的文本到结构生成框架中对各种IE任务进行通用建模。为了自适应地为不同的IE任务生成目标结构,百度在线网络技术(北京)有限公司提出了结构模式指导器(Structural Schema Instructor,SSI),这是一种基于模式的提示机制,用于控制UIE中要发现的内容、要关联的内容及要生成的内容。
2.2 ERNIE模型
ERNIE[5](Enhanced Language Representation with Informative Entities)模型采用Transformer Encoder的方式作为基本的编码器,模型大小是12 encoder layer、178 hidden units、12 attention heads。ERNIE模型与BERT[6](Bidirectional Encoder Representations from Transformers)模型十分相似,但ERNIE改进了两种masking策略,一种是基于短语的masking策略,另一种是基于名词(如人名、位置、组织、产品)的masking策略。在ERNIE中,将由多个字组成的短语或者名词当成一个统一单元,相比于BERT基于字的mask,这个单元当中的所有字在训练的时候,统一被mask。对比直接将知识类的query映射成向量后直接相加,ERNIE通过统一mask的方式,可以潜在地学习到知识的依赖及更长的语义依赖,进而让模型更具泛化性。
3.1 在线评论数据采集
(1)采集来源
网络化时代的到来产生了大量的消费者生成内容,消费者不仅可以在消费前在互联网中获得产品的基本信息,也可以获知其他已购买该产品的消费者对产品的使用体验。这些信息在互联网不同的平台上不停地更新,例如京东、淘宝等第三方购物平台,以及官方的论坛、社区、社交平台账号等。由于丝绸纺织行业的用户评论内容丰富,用户的需求多样,这就要求采集的用户评论数量足够多、内容真实且篇幅不能过短。官方的论坛、社区、社交平台账号的评论数量较少,不满足采集需求,并且有可能是商家花钱买推广的评论。相比于官方的论坛、社区、社交平台账号,第三方在线平台具有评论真实、属性全面、质量更高的优势。首先,随着互联网购物方式的普及和物流行业的快速发展,越来越多的消费者选择线上购买产品,因此第三方购物网站的每款热销丝绸商品的评论都达到数万条,这些评论可以真实地反映大多数消费者的心声。其次,用户在评论商品时,可以选择不同的属性标签,这为细粒度的需求分析提供了相对完善的评论信息。最后,得益于平台的评论监测过滤机制,大大减少了其中掺杂的垃圾评论,提高了评论的质量。因此,本文选择各个电商平台的评论作为在线评论数据来源。
(2)采集过程
基于用户评价的数据挖掘需要大量的用户评论语料,显然依靠人力收集在线用户评论的工作量相当大,因此必须借助现有的爬虫技术从电商平台快速获取用户评论。网络爬虫[7]其实就是一个程序或者脚本,它向目标链接发起Http请求并按照开发者设定的规则对返回数据进行过滤解析,实现自动从互联网上抓取所需的信息。为我们熟知的搜索引擎如谷歌和百度都是大型的爬虫系统,基于用户输入的关键字在全网进行爬虫搜索,并将相关的网页呈现给用户。
现有的网络爬虫工具有“八爪鱼”、HTTrack、Scraper、OutWit Hub等。“八爪鱼”是一款免费且功能强大的网站爬虫,用于从网站上帮助使用者提取需要的几乎所有类型的数据。用户可以使用其内置的正则表达式工具从复杂的网站布局中提取许多棘手网站的数据,并使用XPath配置工具精确定位Web元素。
利用网络爬虫工具“八爪鱼”对京东商城的丝绸类商品评论进行爬取,主要爬取评论、用户名、评价星级、店铺名称、货号、商品材质等内容(表1)。
3.2 数据预处理
虽然在线商城的用户评论数量庞大,但是由于用户表达随意,其中掺杂了许多无效评论,若在后续分析阶段不对其进行处理,则这些无效评论将带来较大的干扰。因此,需要对评论进行预处理,去除无效评论。需要删除的评论可分为3种情况。
一是重复的评论。爬取的评论难免会出现重复内容,原因可能是用户进行了复制粘贴,或是在分批爬取时,网页更新了评论动态等。为此,需要删除重复的评论。
二是过短的评论。一些评论可能只包含一两个字,这类过短的评论所包含的信息非常有限,因此真正有效的评论至少需要包含3个字以上,例如“速度快”,因此需要删除少于3个字的评论。
三是无意义的评论。某些消费者为了积分而随意评论,他们会随意打字凑字数,这种评论毫无挖掘价值,同样需要删除。
经过上述筛选步骤,共得到了16 900条有效的评论数据。
[BT5+*5]3.3 词频统计与分析
词频统计分析是文本分析中一种重要的方法。它通过计算词语在文本中的频率揭示文本的特征和模式。词频统计可用于识别文本的主题和关键词,把握评论中的核心内容和重点词汇,同时它能揭示词语之间的关联关系,帮助分析人员理解文本的内在结构和语义信息。此外,词频统计可用于情感分析,评估文本的情感倾向。在特定领域的文本分析中,词频统计也具有重要作用,它能帮助分析人员理解和解释领域内的文本内容。
3.3.1 Jieba分词
Jieba分词[8]是一种基于Python语言的中文分词工具,它采用了基于前缀词典实现的分词算法,能够将一段中文文本切割成一个一个的词语,并对每个词语进行词性标注。停用词是指在文本分析过程中需要过滤掉的一些常见词语,这些词语通常是出现频率较高,但对文本分析任务并没有实质性贡献的词语,比如“的”“是”“在”等。本文在使用Jieba分词工具对数据进行分词处理时,使用了公开的中文常用停用词表——哈工大的中文停用词表(哈尔滨工业大学自然语言处理实验室发布的一个停用词表)过滤掉停用词。
3.3.2 统计词频与分析词性
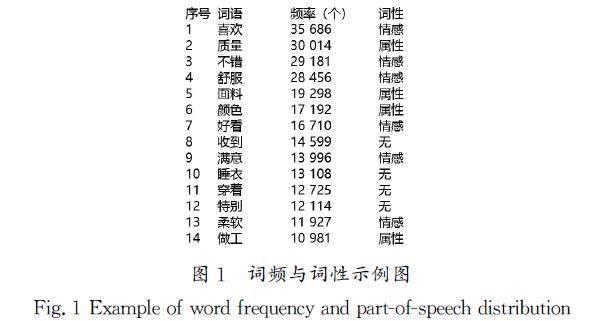
对每条评论的词语进行频率统计,提取所有出现频率超过1%的词语共104个,并对它们进行词性分析,词频与词性示例图如图1所示。
3.3.3 构建属性聚类表和属性\|情感词词典
统计得出与丝绸有关的属性,并根据相似性将其分为7个大类,创建属性聚类表(表2)。
3.4 属性级情感数据标注
数据标注平台:Label Studio是一个开源的数据标注平台,支持各种类型的数据标注任务,包括文本、图像、音频、视频等。它可以帮助数据科学家和研究人员快速地创建高质量的标注数据集,将其用于机器学习、深度学习等任务中。
根据属性聚类表(表2)和属性\|情感词词典(表3)进行标注,具体标注规则如下:将属性标注为评价维度(正向或负向),将其对应的情感词标注为观点词,二者之间以“观点词”相关联,属性级情感数据标注示例图如图2所示。
3.5 属性级情感数据提取
3.5.1 设计结构提取语言
根据属性级情感数据标注构建结构模式指导器(SSL),用于控制UIE中要发现的内容、要关联的内容及要生成的内容。在本研究中需要构建的结构模式指导器有4个,分别是“属性”“属性对应的观点词”“观点词”“情感倾向”。
通过UIE模型设计结果提取语言(SEL),完成属性级情感的信息抽取任务。在形式上,UIE将给定的结构模式指导器(S)和文本序列(X)作为输入,并生成线性化SEL(Y),其中包含基于模式S从X中提取的信息:
3.5.2 隐性属性提取
在中文语境中,常常会出现省略的情况,因此为了增加句子的表达能力和描述能力,本文采用属性\|情感词词典补全省略的属性。使用UIE模型构建结构提取语言(SEL)时,当句子中存在某个观点词没有相互对应的属性词时,会在属性\|情感词词典中进行检索,查看是否将属性词省略,若存在省略情况,则将省略的属性词添加到SEL中,实现隐性属性的提取。以评论“太贵了”为例,该句子中明显省略的属性词为“价格”。隐性属性SEL构建表如表5所示。
3.5.3 UIE模型提取结果
属性级标注数据共1 000余条,经过UIE模型构建后,可得到训练集13 000余条,验证集1 600余条,测试集1 600余条。
3.6 ERNIE模型训练
3.6.1 实验环境配置
本文模型基于Paddlepaddle框架,使用GPU进行训练,实验使用的GPU为NVIDIA GTX3060,Paddlepaddle\|gpu版本2.4.2,Paddlenlp版本2.5.2,Python版本3.9,CPU为R9\|6900HX,操作系统为Windows10家庭中文版。模型支持处理的最大序列长度为256,训练批次为8次,训练最大学习率设置为0.000 01。
3.6.2 评价指标
评价模型的指标[9]主要有精确率(Precision),召回率(Recall)和F1值,计算方法如公式(2)至公式(4)所示:
其中:TP为预测正确的正样本数量,FP为预测错误的正样本数量,FN为预测错误的负样本数量。
3.6.3 实验结果与分析
第一组实验是直接将ERNIE预训练模型对测试集进行多次验证后的平均评价指标;第二组实验是通过UIE属性提取后,对ERNIE模型进行小样本训练后的平均评价指标;第三组实验是采用隐性属性提取后,对ERNIE模型进行小样本训练后的平均评价指标。实验结果如表6所示。
从表6中的数据可以看出,通过属性聚类表和属性\|情感词词典设计的UIE提取规则对于预训练模型效果提升十分有效,特别是召回率有了大幅的提升,这是模型能够学习到更多丝绸纺织行业属性的表现;而隐性属性提取的方法使模型能够注意到评论中隐含的属性,使模型的评价指标F1值相较于未经过隐性属性提取的方法的相应指标值提升了4百分点。
4 结论(Conclusion)
在如何有效利用商品评论数据的问题上,本文针对丝绸纺织行业的商品评论数据,通过词频统计分析构建了属性聚类表和属性\|情感词词典,同时基于评论中隐性属性的提取并结合UIE模型和ERNIE模型,实现了对丝绸纺织行业电商评论的属性级情感提取。实验结果证明了本文所提方法的有效性,该方法能够帮助商家有效了解消费者的需求和市场发展趋势,从而有针对性地对产品进行改进。此外,该方法对于其他行业的评论数据挖掘也具有一定的参考价值。
参考文献(References)
[1] CNNIC. 第52次中国互联网络发展状况统计报告[EB/OL]. (2023\|08\|28)[2024\|02\|01]. https:∥www.cnnic.net.cn/n4/2023/0828/c88\|10829.html.
[2] 李铁. 面向大规模电商评论的情感分析与兴趣挖掘研究[D]. 成都:电子科技大学,2018.
[3] ZHANG L,WANG S,LIU B. Deep learning for sentiment analysis:a survey[J]. WIREs data mining and knowledge discovery,2018,8(4):e1253.
[4] LU Y J,LIU Q,DAI D,et al. Unified structure generation for universal information extraction[C]∥Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). Stroudsburg,PA,USA:Association for Computational Linguistics,2022:5755\|5772. [HJ2.5mm]
[5] ZHANG Z Y,HAN X,LIU Z Y,et al. ERNIE:enhanced language representation with informative entities[C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA,USA:Association for Computational Linguistics,2019:1441\|1451.
[6] 李可悦,陈轶,牛少彰. 基于BERT的社交电商文本分类算法[J]. 计算机科学,2021,48(2):87\|92.
[7] 陈国良,郭修豪. 基于商品评论信息的特征挖掘[J]. 福建电脑,2015,31(5):106\|107.
[8] 韦人予. 中文分词技术研究[J]. 信息与电脑(理论版),2020,32(10):26\|29.
[9] POWERS D M W. Evaluation:from precision,recall and F\|measure to ROC,informedness,markedness and correlation[DB/OL]. (2020\|10\|11)[2024\|02\|01]. https:∥arxiv.org/abs/2010.16061.
作者简介:
尤良辉(2000\|),男,硕士生。研究领域:深度学习。
张华熊(1971\|),男,博士,教授。研究领域:智能信息处理。本文通信作者。
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
