
基于机器学习的口咽癌死亡预测模型构建与研究
2024-06-03 09:11:36潘逸菲
现代信息科技 2024年6期
收稿日期:2023-07-28
DOI:10.19850/j.cnki.2096-4706.2024.06.019
摘 要:采用机器学习对口咽癌患者一年生存情况构建预测模型,通过比较找到最优模型,以期为相关疾病预后提供可靠的参考指标。选取SEER数据库中2020年的口咽癌患者2 636例,数据经过SMOTE算法优化后,运用八种机器学习方法建立预测分类模型比较分析。基于随机森林、决策树算法的模型相对来说预测性能更佳。机器学习算法建立的预测模型能够较好地辅助口咽癌临床诊疗及预后相关行为。
关键词:口咽癌;机器学习;预测模型;SEER数据库;SMOTE算法
中图分类号:TP39;TP301.6;R780.1 文献标识码:A 文章编号:2096-4706(2024)06-0082-05
Construction and Research on Oropharyngeal Cancer Death Prediction Model
Based on Machine Learning
PAN Yifei
(Stomatological College of Nanjing Medical University, Nanjing 210003, China)
Abstract: Machine Learning is used to construct a prediction model for the annual survival situation of oropharyngeal cancer patients. In order to provide a reliable reference index for the prognosis of related diseases, the optimal model is found through comparison. And 2 636 patients with oropharyngeal cancer in 2020 from the SEER database are selected. After the data are optimized by SMOTE algorithm, eight Machine Learning methods are used to establish a predictive classification model for comparative analysis. The Models based on Random Forest and Decision Tree algorithm have better predictive performance, relatively. The prediction model established by the Machine Learning algorithm can effectively assist the clinical diagnosis and treatment of oropharyngeal cancer and prognostic behaviors.
Keywords: oropharyngeal cancer; Machine Learning; prediction model; SEER database; SMOTE algorithm
0 引 言
口咽癌指發生在舌根部、扁桃体、软腭及咽后壁黏膜的癌性病变,与口腔癌并称为世界第六大最常见的癌症[1]。在过去十年内,伴随着人乳头瘤病毒因素比例的上升,口咽癌在头颈部鳞癌中的占比正稳步提高[2],因此迫切需要采取相关措施来预测并降低口腔和口咽癌的发病率及死亡率。
近年来,随着人工智能的迅速发展,越来越多的领域开始在机器学习的基础上构建预测模型,在分析大规模数据等方面替代传统方法,表现出良好的准确率和稳定性。如医疗领域中,面对复杂高维度的医疗数据,机器学习技术可通过建模训练,学习数据中的内在统计模式和结构,达到预测疾病预后、寻找疾病诊断指标等可辅助临床诊疗的目的。
因此国内外许多研究在对疾病的诊疗探索中已将机器学习作为重要的辅助手段。如Sajjadian等发现机器学习可以较为准确地预测重度抑郁症的药物疗效,从而辅助抑郁症的个性化治疗[3]。Dong等建立的机器学习模型可为儿科重症监护急性肾损伤(Acute Kidney Injury, AKI)的诊疗提供早期预警并采取防治措施[4]。张博超等利用慢性阻塞性肺疾病中急性加重期患者的随机森林预测模型识别患者肺功能等级[5]。
口腔医学领域也是如此,Howard等建立的机器学习模型可以较好地预测能从头颈部恶性肿瘤放化疗中获益的中度风险患者,从而更好地进行治疗[6]。吴宇佳等利用基于机器学习构建了可摘局部义齿基牙选择模型,并对其选择结果进行合理性评价的方法[7]。此外,机器学习在预测疾病死亡率、3D重建、三维形态计量学、自动化治疗计划和制定个性化手术方案等方面均有广阔的发展前景。
基于机器学习的广泛应用和有效性,本研究将采用逻辑回归(Logistic Regression, LR)、决策树(Decision Tree, DT)、随机森林(Random Forest, RF)、朴素贝叶斯(Naive Bayes, NB)、支持向量机(Support Vector
Machine, SVM)、K近邻(K-Nearest Neighbors, KNN)、梯度提升(Gradient Boosting, GB)、极限梯度提升(Extreme Gradient Boosting, XGBoost)八种机器学习算法建立预测分类模型,通过对比分析,寻找更适合构建口咽癌死亡预测模型的方法,为口咽癌诊疗预后提供依据。
1 算法和处理
1.1 SMOTE算法
SMOTE(Synthetic Minority Oversampling Technique)算法指合成少数类过采样技术。它是在随机过采样算法基础上分析并根据原有少数类样本人工合成新样本,从而使训练集数据分布更均衡[8]。
1.2 逻辑回归算法
LR属于广义线性回归模型,可以测量关联、预测结果和控制混杂变量效应[9]。本研究中,该过程大概为先建立代价函数去代入初步的回归分类模型,再迭代优化,求解出最优的模型参数,测试验证模型的好坏。
1.3 决策树算法
DT指通过建立可视化的结构图将每一个决策与对应的结果连接起来,利用一系列的决策节点及其分支条件判断最后所属的类别[10]。具体过程为:处理、利用和训练数据,基于损失函数最小化的原则归纳算法,并建立可读的规则和决策模型,然后使用决策树模型对新数据进行预测分析。
1.4 随机森林算法
RF是基于分类回归树的集成算法。利用自助法重采样技术,在原始训练集中,有放回地重复随机抽取k个样本生成新的训练样本集,再根据自助样本集生成k个分类树组成随机森林。即通过随机抽样和在分裂变量中加入随机性,使树之间的独立性增强[11]。
1.5 朴素贝叶斯算法
NB是以贝叶斯定理为基础、基于特征条件独立假设的分类模型。先假设特征词之间独立,通过给定的训练数据集来学习从输入到输出过程的联合概率分布。然后基于学习到的模型,输入给定的x值,求出使得后验的概率最大的输出值Y [12]。
1.6 支持向量机
SVM的基本模型是定义为特征空间上的间隔最大的线性分类器,其形式为一个凸二次规划的求解问题。它的目的是在两个类别之间创建决策边界,从而能够从一个或多个特征向量进行预测[13]。
1.7 K近邻算法
KNN指的是给定一个训练集,输入新的实例特征向量,算法识别训练数据集中具有预定义度量的与该实例最近邻的k个实例,并从其类别中通过多数表决进行预测及分类[14]。
1.8 梯度提升算法
GB是提升树的优化算法,它的基本原理是利用模型损失函数的负梯度信息,得出提升算法中残差近似值,把新加入的弱分类器训练后累加拟合到现有的模型中[15],成為新的回归树。
1.9 极限梯度提升算法
XGBoost是一种机器学习算法,它是基于梯度提升算法的若干扩展和改进。它的核心思想是在梯度提升树算法中引入强化学习技术,通过对目标函数的最优化来提高模型的精度和泛化能力。极限梯度提升原理将多个弱学习器进行串行或并行集成,从而构建强大的集成模型。
2 资料与方法
2.1 一般资料
本研究在SEER(Surveillance, Epidemiology, and End Results)数据库2023年4月发布的“Incidence-SEER Research Data, 17 Registries, Nov 2022 Sub(2000—2020)”中筛选出诊断年份为2020年的患者数据,排除部分信息不全及模糊的数据,最终纳入2 636例患者的诊疗数据。
2.2 实验方法
2.2.1 数据采集及预处理
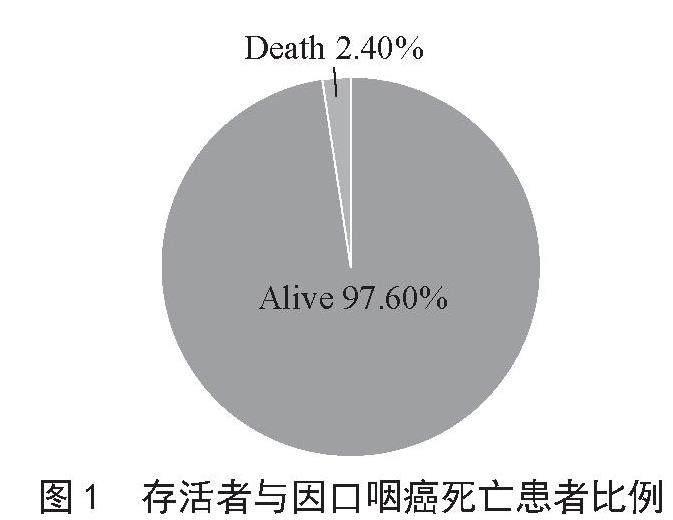
选取SEER数据库中2020年就诊的2 636例患者信息,进行分析和预处理。在数据处理的过程中,发现生存者和因口咽癌死亡患者分布差别明显,具体情况如图1所示。
图1 存活者与因口咽癌死亡患者比例
从图1可知,本研究数据集存在数据不平衡问题,为了保证实验的合理性和可行性,本文采用SMOTE算法对数据集进行处理。
2.2.2 特征选择
本研究考虑到临床特征的有效性和合理性,选取了与口咽癌预后相关性较大的指标,从流行病学、临床分期、诊疗计划等方面出发,建立了多维度口咽癌死亡预测模型。共选取年龄、性别、种族、原发部位、偏侧、TNM分期、淋巴清扫、放化疗选择等22个输入指征。
2.2.3 模型构建
用SMOTE算法对数据作不平衡预处理后,先将预处理后的数据以7:3的比例随机划分为训练集及测试集。利用训练集创建预测死亡预后的模型,然后利用测试集评估模型效果。在Windows 10平台Python3.8环境下构建LR、DT、NB、RF、SVM、KNN、GB、XGBoost分类预测模型。
2.2.4 模型评估
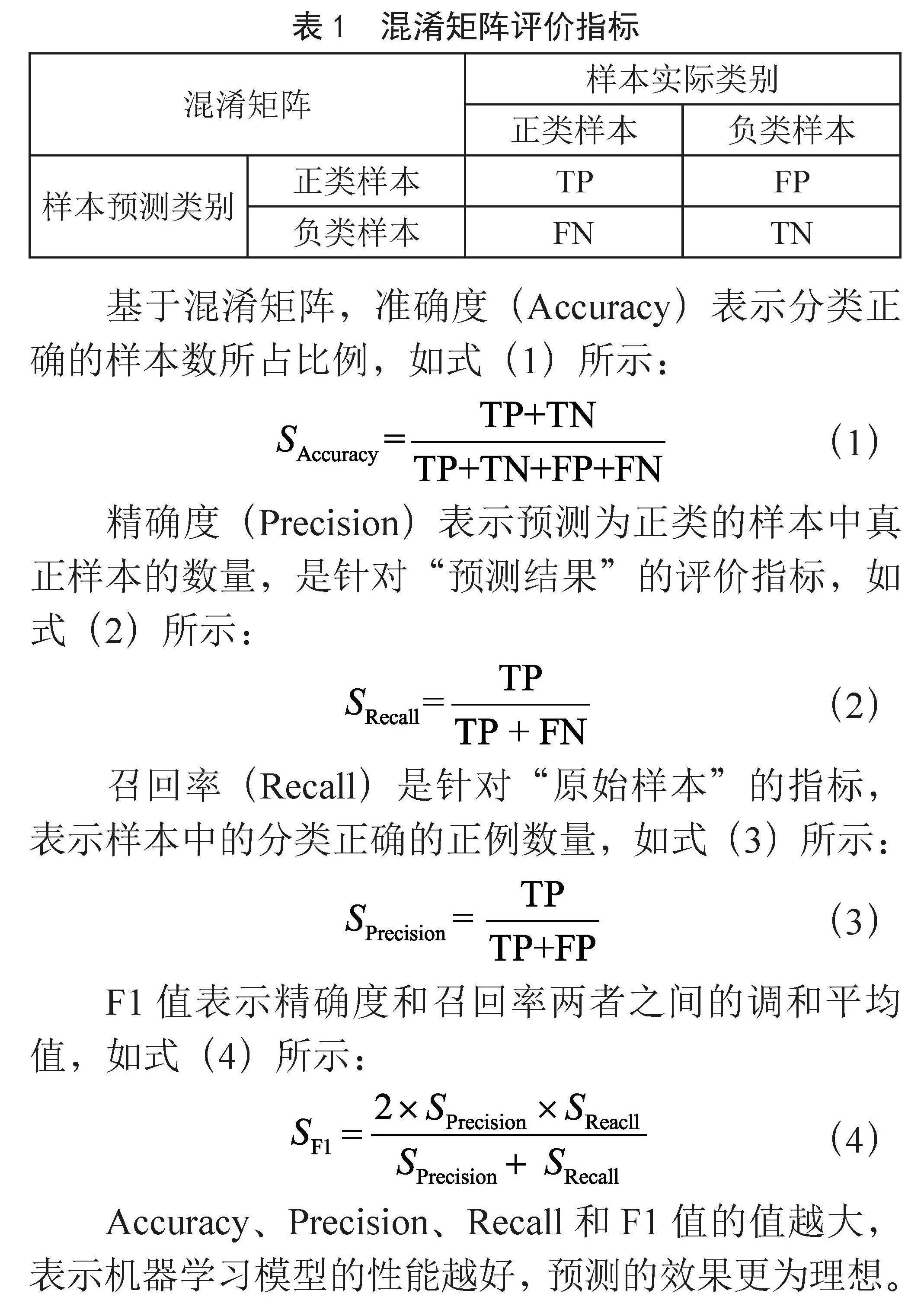
在用训练集构建模型以后,将使用测试集对上述模型的预测进行客观评价。本研究选取混淆矩阵、准确度、精确度、召回率、ROC曲线面积等多个指标对预测模型作出评价,混淆矩阵如表1所示。
表1 混淆矩阵评价指标
混淆矩阵 样本实际类别
正类样本 负类样本
样本预测类别 正类样本 TP FP
负类样本 FN TN
基于混淆矩阵,准确度(Accuracy)表示分类正确的样本数所占比例,如式(1)所示:
(1)
精确度(Precision)表示预测为正类的样本中真正样本的数量,是针对“预测结果”的评价指标,如式(2)所示:
(2)
召回率(Recall)是针对“原始样本”的指标,表示样本中的分类正确的正例数量,如式(3)所示:
(3)
F1值表示精确度和召回率两者之间的调和平均值,如式(4)所示:
(4)
Accuracy、Precision、Recall和F1值的值越大,表示机器学习模型的性能越好,预测的效果更为理想。
ROC(Receiver Operating Characteristic Curve)指接受者特征曲线,是反应敏感性及特异性连续变量的一项综合指标,描述的是分类模型性能随着其阈值变化而变化的过程。ROC曲线的面积用AUC值表示,是一个重要的评估值。面积值为0.5表示识别能力为0,为随机分类;面积值越接近于1表示识别能力越强。
3 评价与分析
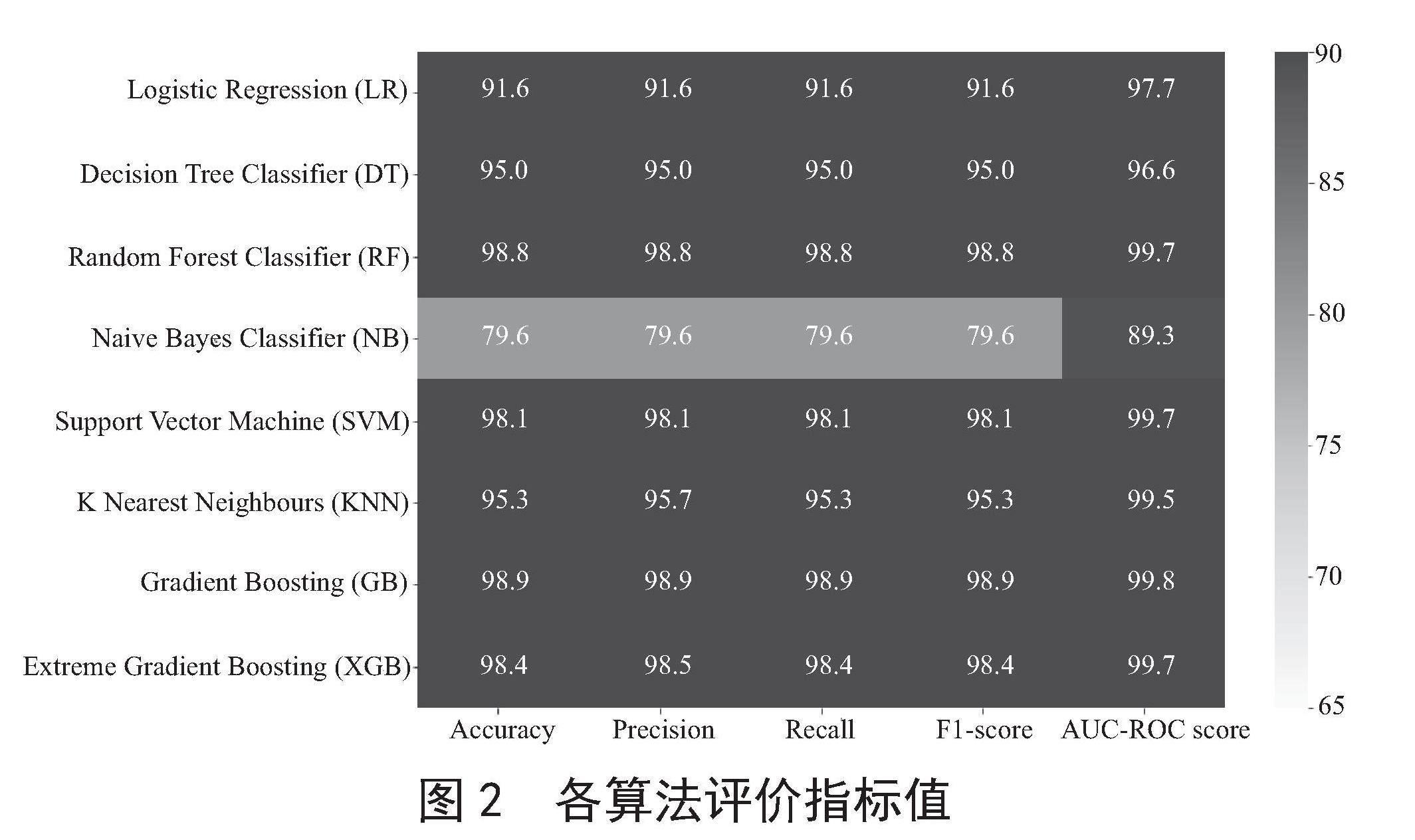
对SMOTE算法处理后的数据模型采用Accuracy、Precision、Recall、F1值和AUC进行性能评价后,得到的各项指标值如图2所示。
图2 各算法评价指标值
从图2结果可以看出,随机森林、决策树、梯度提升、极限梯度提升算法在准确度、精确度、召回率、F1值指数方面都优于其他机器学习算法,其中随机森林和梯度提升算法的优势更为明显,分别为98.8%和98.9%,说明这两种算法预测效果比较准确。
如图3所示,随机森林、决策树、梯度提升、极限梯度提升算法的ROC曲线面积最为理想,其中梯度提升算法最佳。这些算法建立的预测模型可以更好地拟合数据,从而通过部分临床特征预测口咽癌预后和死亡类型。然而,贝叶斯算法建立的预测模型虽然相对来说AUC值也比较理想,但是,相对于其他算法模型显得较低,不建议采用。
(a)逻辑回归算法
(b)决策树算法
(c)随机森林算法
(d)朴素贝叶斯算法
(e)支持向量机算法
(f)K近邻算法
(g)梯度提升算法
(h)极限梯度提升算法
图3 各算法ROC曲线
综上,随机森林算法和梯度提升算法在多个评价指标上都优于其他机器学习算法,可能是由于两种算法均属于集成分类算法,可以较好地适应数据集并减小误差,具有更优良的性能,从而更好地辅助口咽癌的临床诊疗。
本研究讨论了多种机器学习方法在口咽癌死亡预测方面的应用和评价,并且从结论可以得出这些机器学习方法均具有较好的统计学意义,但其中不足之处是,机器学习的预测模型缺乏与临床相关的推理解释,与临床特征的诊疗推断尚不能达到理论上的融会贯通,还需要进一步的探索。
4 结 论
随着经济社会的发展和致病因素的流行,口咽癌在头颈部鳞癌中的占比正稳步提高,因此口咽癌的临床诊疗需要得到进一步的优化。本研究通过8种机器学习方法建立口咽癌死亡预测分类模型,SMOTE算法优化后比较分析,发现基于随机森林、决策树、梯度提升、极限梯度提升的机器学习模型的性能指标较高,能够较好地辅助口咽癌临床诊疗及预后。其中,随机森林算法和梯度提升算法在多个评价指标上综合优于其他机器学习算法,可以在口咽癌死亡和预后的诊疗中作为良好的辅助诊断工具,为口咽癌的早期诊断和治疗提供科学依据,从而为口咽癌患者提供更理想且个性化的治疗方案。
参考文献:
[1] PSYRRI A,PREZAS L,BURTNESS B. Oropharyngeal Cancer [J].Clinical Advances in Hematology & Oncology,2008,6(8):604-612.
[2] MARUR S,D'SOUZA G,WESTRA W H,et al. HPV-associated Head and Neck Cancer: A Virus-related Cancer Epidemic [J].the Lancet Oncology,2010,11(8):781-789.
[3] SAJJADIAN M,LAM R W,MILEV R,et al. Machine Learning in the Prediction of Depression Treatment Outcomes: A Systematic Review and Meta-analysis [J].Psychological Medicine,2021,51(16):2742-2751.
[4] DONG J Z,FENG T,THAPA-CHHETRY B,et al. Machine Learning Model for Early Prediction of Acute Kidney Injury (AKI) in Pediatric Critical Care [J].Crit Care,2021,25(1):288.
[5] 張博超,杨朝,郭立泉,等.基于机器学习的慢性阻塞性肺疾病急性加重预测模型的研究 [J].中国康复理论与实践,2022,28(6):678-683.
[6] HOWARD F M,KOCHANNY S,KOSHY M,et al. Machine Learning-Guided Adjuvant Treatment of Head and Neck Cancer [J].Journal of Clinical Oncology,2020,3(11):6567.
[7] 吴宇佳,周崇阳,徐子能,等.基于机器学习的可摘局部义齿基牙选择模型的合理性评价 [J].中国实用口腔科杂志,2023,16(3):333-338.
[8] DABLAIN D,KRAWCZYK B,CHAWLA N V. DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data [J].IEEE Transactions on Neural Networks and Learning Systems,2023,34(9):6390-6404.
[9] STOLTZFUS J C. Logistic Regression: A Brief Primer [J].Academic Emergency Medicine,2011,18(10):1099-104.
[10] 申泉,罗旭飞,石安娅,等.基于临床实践指南决策树的设计与思考 [J].协和医学杂志,2022,13(6):1081-1087.
[11] 曹桃云.基于随机森林的变量重要性研究 [J].统计与决策,2022,38(4):60-63.
[12] 马刚.朴素贝叶斯算法的改进与应用 [D].合肥:安徽大学,2018.
[13] HUANG S J,CAI N G,PACHECO P P,et al. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics [J].Cancer Genomics Proteomics,2018,15(1):41-51.
[14] GWEON H,SCHONLAU M,STEINER S H. The K Conditional Nearest Neighbor Algorithm for Classification and Class Probability Estimation [J].PeerJ Computer Science,2019,5:e194.
[15] 吕佳.梯度提升回归树算法研究及改进 [D].上海:上海交通大学,2017.
作者简介:潘逸菲(2001—),女,汉族,江苏淮安人,本科在读,研究方向:颌面部肿瘤研究与生物信息学结合。
猜你喜欢
东方教育(2016年9期)2017-01-17 21:04:14
中国经贸(2016年21期)2017-01-10 12:21:20
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
商情(2016年43期)2016-12-23 14:23:13
经济师(2016年10期)2016-12-03 22:27:54
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
商业经济研究(2016年14期)2016-09-14 08:25:44
