
基于数据中台的建筑业数据清洗算法研究
2024-06-03 03:28:24曾莎洁陶兴张承雄
信息系统工程 2024年5期
曾莎洁?陶兴?张承雄
摘要:数据清洗是对脏数据进行检测和修复的过程,是进行数据分析应用的前提。对数据缺失、数据重复、数据错误这三种数据噪声的检测技术进行详细阐述,按照数据清洗方式对数据修复技术进行分类概述,包括基于规则的数据清洗算法、基于统计的数据清洗算法和人工智能技术的数据清洗算法,并提出了基于数据中台的数据获取、清洗、服务架构,结合建筑领域数据特征进行了算法适应性分析,可为建筑领域的数据治理和应用提供重要参考。
关键词:数据中台;数据清洗;机器学习;ETL;建筑业
一、前言
在建筑业,随着BIM等数字化技术的发展,工作模式已逐渐向标准化和结构化推进,并依托模型数据实现精细化管理。通过物联网技术实现多元数据采集和传输,极大拓展BIM信息来源,确保数据实时、准确[1]。通过云计算技术实现数据的分布式存储,使项目不同参与方、不同业务领域、建筑不同阶段之间的数据能够共享与管理,提高BIM的协作能力,为共享、使用BIM数据奠定基础[2]。数据挖掘技术则可以对海量数据进行高效、深度挖掘,从而充分发挥BIM的作用[3]。比如在识别建筑典型能耗模式、建立鲁棒能耗预测模型方面,数据挖掘技术相比传统方法在诊断制冷空调系统运行状况方面表现更优异,在处理复杂庞大的建筑运行数据上具有很高的价值。大数据技术正带领中国建筑行业向管理数字化、建造工业化转型,而标准化、高质量的可靠数据是这一切的重要基础。因此,提高数据质量,特别是在建筑行业中,成为提升整个行业数字化水平的关键步骤。
二、研究背景
数据分析的基础是数据清洗。大数据的特点是数据体量大、数据类型多,数据质量参差不齐,将这些脏数据有效转化成高质量的干净数据是体现数据价值、发挥数据服务作用的保障。数据清洗可以识别和修复异常数据,将异常对数据的影响降至最低,提高数据的质量。数据清洗算法的研究最早出现在美国,异常数据的类型主要包括数据缺失不完整、数据有重复冗余、数据错误或数据之间相互冲突。数据错误类型也随着大数据技术的发展、数据编码方式的变化、数据传输方式的改变而增加。同时,数据清洗技术也面临新的挑战,尤其是数据量的指数级增加对数据清洗效率提出了更高要求,传统的数据清洗算法无法胜任大数据时代的挑战,寻找高效、精准的数据清洗算法一直是困扰行业多年的难题。
人工智能技术的发展为数据清洗算法的研究提供了新思路。利用机器学习中的非监督学习算法来发现数据清洗决策的隐含规律,可以极大降低人工标注数据的工作量。同时,数据中台的发展为数据的采集、清洗、运用提供了平台基础。基于数据中台的建筑业数据清洗算法研究被提出,将平台、数据、算法、行业有机聚合在一起,为建筑业数据质量的提升和运用提供新路径。
三、数据中台治理现状
数据中台是集数据采集、清洗、共享、数据建模、数据管理和数据服务应用于一体的应用平台。当数据中台中的多个数据库汇聚的时候,表示相同实体的记录具有不同的表示格式有可能会产生重复或冲突,进而产生重复元组检测和清除问题。数据清洗是识别并解决元组重复和冲突问题的方法。数据挖掘前需要实现数据的检查、缺失值和异常数据检测和校正,因此,数据清洗也是进一步进行数据分析或数据挖掘的基础。数据中台面向不同服务均有数据清洗的需求,但是,目前在中台的数据清洗算法没有进行有效分离和整合,也没有建立數据清洗算法库。
四、异常数据来源分析
建筑领域数据质量问题产生的原因可能在数据生成、传输、存储的任何一个环节。错误值包括输入错误和错误数据。输入错误是由原始数据录入人员疏忽而造成的。错误数据大多是由一些客观原因引起的,例如,建筑工地人员的变动等[4]。异常数据是指所有记录中一个或几个字段间绝大部分遵循某种模式,其他不遵循该模式的记录,例如,建筑工地噪音监测数据超过历史最高纪录等。此外,由于建筑行业的特点,项目人员的流动性、设计变更、返工、设备故障造成数据的不一致情况,以及计量单位的不一致、建筑地址更新等其他情况也会导致数据质量问题。
五、基于数据中台的数据清洗架构
(一)总体架构
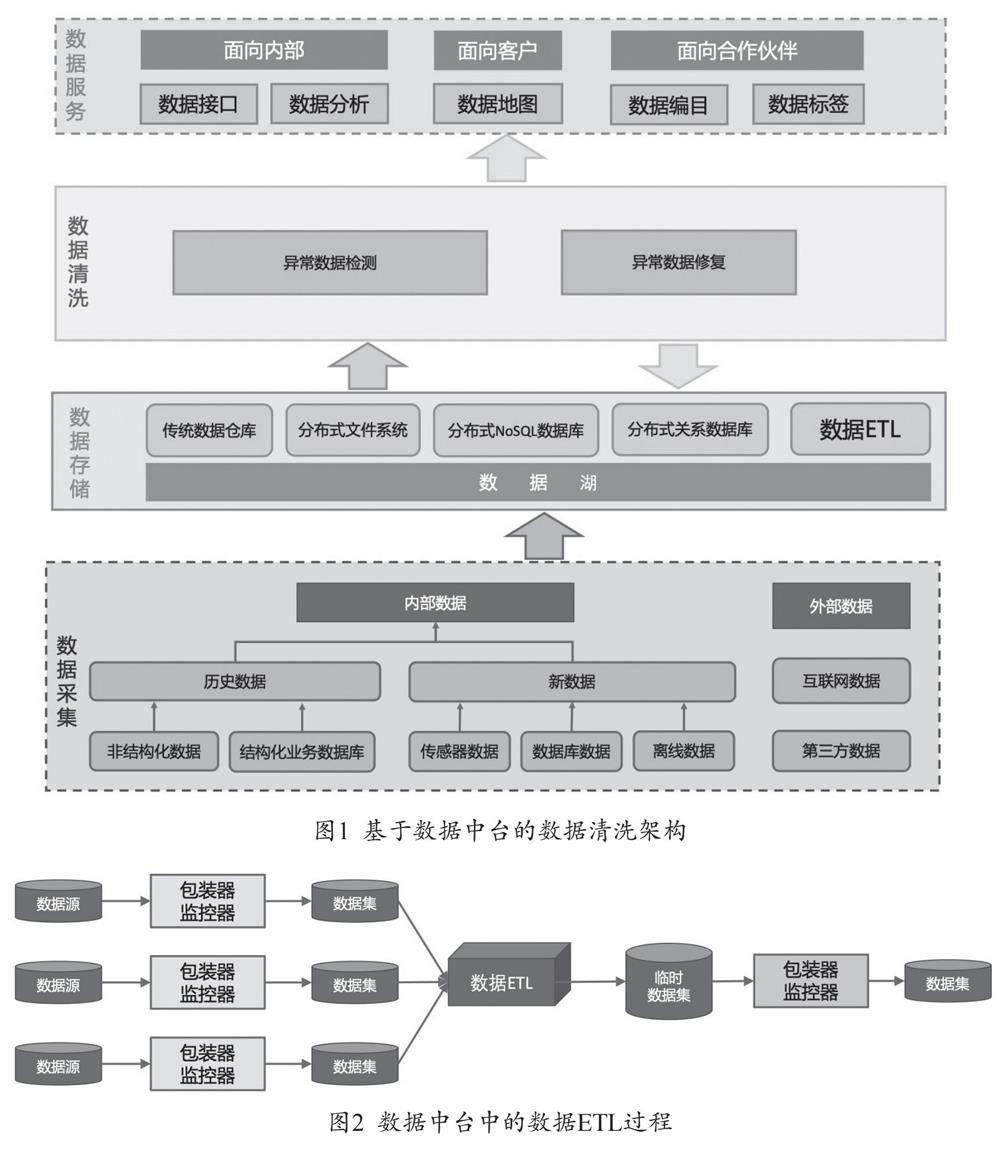
基于数据中台的数据清洗架构由四部分组成,包括数据采集、数据存储、数据清洗、数据服务,其总体架构如图1所示。
(二)数据ETL
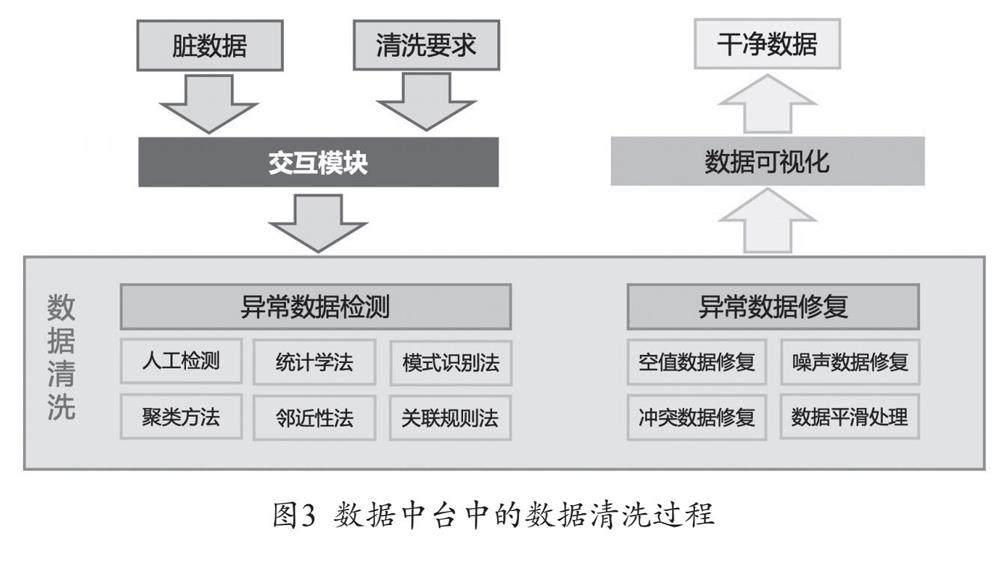
在数据中台中,数据ETL是对包装器和监视器提取的数据进行汇聚、转换,然后形成聚合数据,供后续的数据清洗使用。数据源的数据通过包装器和监视器抽取到数据仓库中进行预处理,其过程如图2所示。监视器监控数据源的变化,包装器进行数据源数据的抽取。
(三)数据清洗
数据中台中的数据清洗过程如图3所示。清洗过程包括四大步骤,数据交互、异常数据检测、异常数据修复和数据可视化。交互模块实现与数据湖的数据获取以及清洗规则的载入。异常数据检测模块实现基于检测算法的噪声数据检测。异常数据修复模块实现基于数据修复算法的数据修复。可视化模块实现数据清洗结构的可视化展示、与数据仓库的交互,并最终通过数据中台提供数据服务。
六、数据清洗算法
(一)异常值检测与修复
1.异常值检测
在建筑领域,异常值检测是数据预处理的一个重要步骤,异常值检测的方法包括统计方法Z-Score、IQR,以及机器学习方法DBSCAN和Isolation Forest共四种。
Z-Score方法基于统计学原理通过计算数据点与平均值的差除以标准差来判断数据点是否为异常值。Z-Score适用于符合或近似正态分布的数据集,对于非正态分布的数据,效果会下降。
IQR方法通过计算数据的第一、四分位数(Q1)和第三、四分位数(Q3)之间的距离来识别异常值。在智慧城市的交通流量监测中,IQR可以用来识别异常的交通流量数据。例如,由于事故或特殊事件导致的流量突增或突减,从而帮助城市管理者优化交通流和减少拥堵。
DBSCAN是一种基于密度的聚类算法,能够识别出高密度区域中的核心样本、边界样本和噪声点(异常值)。DBSCAN特别适合处理具有复杂形状和大小的数据集。
Isolation Forest是一种基于树的异常值检测算法,适用于高维数据的异常值检测。该方法通过随机选择特征和随机选择切分值来孤立观察值,异常值的孤立程度通常比正常点要高。在安全监控和环境监测项目中,Isolation Forest可以有效识别异常的监控图像或环境指标读数。例如,不寻常的温度变化或空气质量突变,可能预示着火灾、污染事件或设备故障。
2.异常值修复
异常值的修复算法可根据数据的应用场景灵活选择,以下是常用的异常值修复算法,适用于建筑领域不同的应用场景。
(1)中位数填充
使用中位数进行填充是将一组数据从小到大进行排列,取其中间位置的数进行填充。若数据量为偶数个,则取中间位置的2个数的算术平均值。
在建筑成本估算或城市规划项目中,中位数填充适用于处理由于缺乏完整记录或数据收集不一致而产生的缺失数据。例如,若某个区域的建筑材料价格存在缺失值,鉴于价格数据可能因为极端市场波动而出现波动,使用中位数填充可以避免极端值导致的偏差,从而提供一个稳定的价格估算基础。
(2)众数填充
用一组数据中出现次数最多的数值进行填充。众数填充特别适合于处理建筑和智慧城市项目中的分类数据(如建筑类型、设施用途等)缺失。在城市交通流量研究中,如果部分交通节点的类型数据(如车站、十字路口等)缺失,使用众数填充可以确保数据的完整性,同时保持对城市交通模式分析的准确性。
(3)最近邻插值填充
最近邻插值(K-最近邻,KNN)填充是一种基于相似度的数据填充方法,其基本思想是找到缺失值点最近的K个“邻居”,然后用这些“邻居”的数据通过某种方式(如算术平均、加权平均等)来填充异常值。
最近邻插值可以应用于城市规划和建筑设计中的空间数据处理。例如,在处理城市热岛效应研究中的温度数据缺失时,可以利用地理上相近区域的温度数据进行插值。
(4)前向/后向填充
使用缺失数据的上一条数据或下一条数据进行处理。前向填充和后向填充适合处理建筑工程项目中的时间序列数据,如施工进度报告、材料供应记录等。在处理这类数据时,如果某一天的记录缺失,可以假设短期内施工进度或材料需求变化不大,因此使用前一天或后一天的数据进行填充是一种实用的方法。
(5)回归法填充
根据已有数据和与其有关的其他变量的数据建立拟合模型来预测异常的数值,根据数据建立一个回归模型,然后使用这个模型来预测缺失数据的值。这种方法特别适合于数据之间存在明显线性或非线性关系的情况。
回归法填充适用于数据分析类情况,特别是当数据之间存在明显的相关性时。例如,在分析城市能耗模式时,如果某些建筑的能耗数据缺失,可以基于建筑面积、使用人数、建筑类型等其他变量建立回归模型来预测缺失的能耗数据。这种方法可以帮助城市规划者和建筑设计师更准确地理解能耗分布,进而制定更有效的能源管理策略。
(6)几何平均值填充
几何平均值是所有数值乘积的n次方根,用于不同数量级的数值的平均,如增长率。几何平均值填充适用于处理成倍增长或减少的数值数据,特别是当数据分布偏斜或需要计算平均增长率时。例如,在分析一系列建筑材料成本的年增长率时,如果部分年份的数据缺失,使用几何平均值填充可以更准确地估计长期趋势,因为它能够充分考虑到数据的乘性增长特性。
(7)调和平均值填充
调和平均值是一组数值倒数的算术平均值的倒数,适用于计算平均速率。调和平均值填充适合于处理速率或比例相关的数据缺失,特别是当数值不能简单通过算术平均来代表整体时。在交通流量分析中,如果某个时间段内的车辆平均速度数据缺失,使用调和平均值填充可以更准确地反映车流的平均速度,尤其是在交通状况复杂、速度变化大的情况下。
(8)加权平均值填充
加权平均值是每个数值乘以一个权重,然后加总的结果除以权重的总和,适用于不同数值有不同重要性的场合。加权平均值填充考虑了不同数据点的重要性或可靠性差异,适用于数据点具有不同权重的场景。在建筑能耗分析中,如果缺失某些时段的能耗数据,可以根据不同时段(如白天和夜间)的能耗特性和重要性,使用加权平均值进行填充。这种方法特别适合于需要区分数据贡献度或重要性的复杂分析场景。
(二)缺失值检测与修复
缺失值检测的目标是识别数据集中的缺失值,可以使用python中的isnull()和notnull()函数,或者Java中自定义if (value == null)代码实现缺失值的检测。缺失值的修复算法与异常值的修复算法相同。
(三)重复数据检测与修复
重复数据可能由于数据录入错误、数据集成过程中的重叠产生。重复数据处理方法包括基于规则的重复检测和基于相似度的方法。
1.基于规则的重复检测
基于规则的方法通过定义一组规则来识别重复记录。这些规则通常基于关键字段的匹配。例如,姓名、地址或其他唯一标识符。此方法的关键在于精确地定义哪些字段组合能够唯一标识一个记录,并据此检查数据集中的重复项。
基于规则的重复检测应用场景,比如供应链管理,建筑项目通常涉及大量的材料供应商和子承包商。通过定义明确的规则(如供應商名称、合同编号)来识别和合并供应链数据库中的重复记录,可以确保材料采购和供应链管理的准确性,避免重复下单或支付。
2.基于相似度的方法
基于相似度的方法更加灵活,能够识别在表面上不完全相同但本质上重复的记录。该方法通常使用文本相似度算法来计算记录间的相似度得分,并根据这个得分来判定记录是否重复,包括Jaccard相似度、余弦相似度、Levenshtein距离。
七、结语
数据中台的建设为数据的获取、数据汇聚、数据服务打通了数据链路,数据清洗算法为数据质量提升、数据挖掘、数据应用提供了根本保障,基于数据中台的数据清洗算法研究成果为建筑业数字化转型提供了重要参考和理论技术支撑。鉴于数据总量的持续增长,以及数据质量问题的多元化,未来的研究将不断探索更高效的数据清洗算法,以应对日益复杂的数据质量问题,数据清洗算法的研究将会是持续发展和深化的过程。
参考文献
[1] BARACHO R M A, PEREIRA M L, ALMEIDA M B. Ontology, internet of things, and building information modeling (BIM): an exploratory study and the interrelations between technologies [C]//Proceedings of the IX Seminar on Ontology Research in Brazil and I Doctoral and Masters Consortium on Ontologies. Brazil: Universidade Federal do Rio Grande do Sul, 2017: 141-146.
[2] DING L, XU X. Application of cloud storage on BIM life-cycle management [J]. International Journal of Advanced Robotic Systems, 2014, 11(1): 1-10 .
[3] BILAL M, OYEDELE L O, QADIR J, et al. Big data in the construction industry: a review of present status, opportunities, and future trends [J]. Advanced Engineering Informatics, 2016, 30(3): 500-521.
[4]张承雄.一种基于层次分析法的建筑领域大数据质量评价指标体系及评价模型研究[J].建筑科技,2023,7(02):73-78.
基金项目:上海市社会发展科技攻关项目“面向新城建设运营的数字协同与综合决策关键技术及示范”(项目编号:22dz1201500)
作者單位:曾莎洁、张承雄,上海市建筑科学研究院有限公司、上海市工程结构安全重点实验室;陶兴,中国建筑土木建设有限公司
责任编辑:张津平、尚丹
猜你喜欢
居业(2022年2期)2022-03-25 03:05:02
小哥白尼(野生动物)(2021年5期)2021-08-30 06:16:48
建材发展导向(2021年12期)2021-07-22 08:06:28
海峡姐妹(2020年6期)2020-07-25 01:26:06
经济技术协作信息(2018年5期)2019-01-19 08:39:14
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
