
基于深度学习的法人和其他组织国民经济行业分类标准化流程研究
2024-06-03 10:39:14袁辉赵捷侯博李晟飞韩雪
中国标准化 2024年5期
关键词:深度学习
袁辉 赵捷 侯博 李晟飞 韩雪
摘 要:针对当前法人和其他组织在国民经济行业分类中存在效率及准确性不高的问题,提出一套基于BERT-LSTM-CNN国民经济行业数据自动分类标准化流程。首先,通过对统一代码数据进行质量评估和调整,确保输入数据的准确性。其次,使用训练完善的BERT-LSTM-CNN混合模型实现特征抽取,并应用自注意力机制与迁移学习策略,有效地处理了行业分类的问题。这一标准化流程不仅为各行业用户提供了准确、及时、全面的国民经济行业分类信息,同时还为决策制定过程提供了坚实的数据支撑。
关键词:法人和其他组织,国民经济行业分类,标准化流程,深度学习
DOI编码:10.3969/j.issn.1002-5944.2024.05.008
0 引 言
国民经济行业分类提供了一个结构化的框架用于管理和组织经济活动,其科学性和系统性有利于更全面、客观地了解和把握经济活动的宏观走向与微观运作。其次,行业分类可以作为数据分析的基础,为决策者提供了一个可靠的数据资源,帮助他们进行可靠的数据分析并基于此制定政策。除此之外,行业分类也可保障利益相关者的权益,规范企业行为,提升行业整体质量和服务水平,从而大大提升社会经济效益。因此,法人和其他组织的行业分类在国民经济中发挥着不可或缺的角色。
本文旨在基于深度学习的文本分类技术,研发建立对法人和其他组织进行国民经济行业分类的标准化流程,实现对目标分类调整的快速响应机制,以有效、持续地提升统一代码经济行业字段的完整率和准确性,最终形成全国所有机构的国民经济行业动态分布数据资源,更好地服务于统一代码应用部门和社会公众。
1 文本分类技术
文本分类是自然语言处理的一项重要任务,它的目标是根據语义信息将文本归入预先定义的类别之一。在实际应用中,文本分类被广泛应用于情感分析[1]、新闻分类[2]、医疗安全[3]等方面。本文旨在研究使用文本分类技术提升统一代码经济行业字段的完整率和准确性,满足各应用部门和社会公众的需求。当前的文本分类技术一般可以分为传统的文本分类模型和基于深度学习的文本分类模型两种。
1.1 传统的文本分类模型
传统的文本分类方法主要依赖于基于统计的模型,结合人工提取的特征进行分类。传统的文本分类方法包括朴素贝叶斯[4]、支持向量机(SupportVector Machine,SVM)[5]、K最近邻[6]和随机森林(Random Forest,RF)[7]等模型。朴素贝叶斯是一种基于贝叶斯定理的简单概率分类器,它假设特征之间相互独立。在处理大量文本数据时,朴素贝叶斯具有快速、易于理解和实现的优点。然而,其独立性假设在现实应用中往往不成立,因此对于某些复杂的问题,朴素贝叶斯的效果可能有所限制。SVM是一种二元线性分类器,它试图找到一个超平面将不同类别的数据分开。SVM具有强大的理论保证,但是在处理大量高维特征时,计算复杂度可能会上升。逻辑回归、决策树和RF等模型也被广泛应用于文本分类。这些模型在处理特定类型的问题,如二元分类问题或包含缺失值的问题上,具有优异的效果。
然而,传统的文本分类方法依赖于人工特征提取,这些特征可能无法充分捕获文本的全部信息,特别是复杂的语义和句法关系。此外,对于大规模的文本数据,例如国民经济行业数据,手工特征提取的方法效率低下,无法满足大数据的需求。
1.2 基于深度学习的文本分类
在自然语言处理领域,基于深度学习的文本分类模型已经成为主流,可以有效处理包括国民经济行业分类在内的多种文本分类问题。这些模型通过自动学习和提取文本特征,克服了传统文本分类方法依赖手动提取特征的局限性。
在深度学习模型中,用于文本分类的TextCNN[8]被广泛引用,也是首个将卷积神经网络(Convolutional Neural Network,CNN)[9]引入文本分类的模型,可以自动提取文本序列的局部相关特征,是早期深度学习文本分类的主要模型之一。然而,TextCNN主要关注词语层面的信息,较为有限的上下文考虑使得它在捕获长距离依赖与复杂语义关系方面存在一定困难。循环神经网络(RecurrentNeural Network,RNN)[10]在处理长序列文本信息的领域中显示出独特优势。尤其是长短期记忆网络(Long Short-Term Memory network,LSTM)[11]的成功应用,通过引入门机制解决了传统RNN模型中的长期依赖问题,显著提升了文本分类效果。
近年来,自注意力机制的提出,尤其是BERT(Bidirectional Encoder Representation fromTransformers)[12]预训练模型的成功,对自然语言处理领域产生了深远影响。这些模型通过对全局上下文信息进行动态权重分配,显著提高了文本理解的精度和效率。相较于传统的深度学习模型,BERT和Transformer等模型在处理如国民经济行业分类等更为复杂、多类别的文本分类任务时,展现出显著的性能优势。
1.3 法人和其他组织国民经济行业分类的挑战
法人和其他组织的国民经济行业分类,旨在根据特定的工作内容、经营性质等信息对企业进行准确归类。在实施过程中,企业将根据国家标准被归入适合的行业类别。然而,实际操作过程中存在许多挑战。
(1)数据质量与可用性:为准确进行行业分类,需要依赖于大量准确、全面且高质量的标准数据。然而,实际环境中的数据可能存在噪声、缺失信息或分类错误,这些问题都可能影响到模型的训练效果,从而降低分类的准确度。
(2)特征选择与表示:行业分类需要从丰富的数据中提取有效的特征以区分不同行业。在某些情况下,特定行业之间可能存在交叉或模糊的边界,这使得识别和选择有效的特征变得尤为困难。
(3)多义性和模糊性的挑战:在实现行业分类时,经常会遇到同一个企业在不同的上下文(经营范围描述的信息)或发展阶段(如经营范围变更等)可能归属于不同的行业类别的情况。这种多义性和模糊性可能会导致分类模型的性能下降,甚至产生错误的分类结果。如何设计和实施一种能有效处理这种多元性的模型,是行业分类面临的一个重要挑战。
为了更好地应对这些挑战,本文提出了一种基于深度学习的法人和其他组织的国民经济行业分类标准化流程,为法人和其他组织的国民经济行业分类提供了一种全新有效的解决方案,让行业分类更加精准,更具可行性。
2 基于深度学习的法人和其他组织国民经济行业分类标准化流程
在构建基于深度学习的法人和其他组织国民经济行业分类模型时,可以考虑下述的标准化操作流程,包括数据质量评估与调整、特征抽取策略、模型设计优化、系统应用。
2.1 数据质量评估与调整
在现阶段,国民经济行业数据是一个十分宝贵的资源,是理解和分析经济趋势、制定经济政策的重要依据。然而,这类数据的质量和可用性往往会受到一系列问题的影响,比如数据噪声、信息缺失和错误分类等。为了更准确地进行行业分类,必须充分重视并处理这些数据问题。首先,数据噪声不仅会干扰对真实状况的理解,还可能对模型的训练产生负面影响,降低预测的准确性。因此,本文优先实施了数据清洗和降噪操作,通过科学有效的方法,如异常值检测和滤波技术,将干扰信息剔除,提升数据的质量和可用性。其次,补充缺失信息也是十分重要的环节。在真实情况中,数据源的复杂性和多样性往往使得数据收集不尽完整,这就需要通过合适的插补方法,如对缺失值进行估计或利用相关信息进行填充,尽可能将缺失信息进行补充,增强数据集的完整性,进一步提高模型的學习效果和分类准确度。最后,纠正错误分类是确保国民经济行业分类准确性的重要手段。由于行业分类涉及的领域广泛,专业性强,附带的复杂性和多样性可能引发错误分类。本文引入专家知识库和重分类手段,结合深度学习模型自我调修特性,校正错误信息,以保证原始数据的正确性。
2.2 特征抽取策略
目前,国民经济行业分类面临的第二大挑战是如何从大量且复杂的数据中提取有效的特征,以及如何识别出那些能有效区分不同行业的关键特征,这在一些行业间存在较大交叉或模糊边界的情况下更具挑战性。运用深度学习技术有望在国民经济行业数据的特征提取与选择过程中实现显著优化,不仅能有效地提取出具有区分力的特征信息,而且可以进一步增强行业数据的表述能力,从而更精准地刻画各个行业的细微差别。深度学习的核心特点之一就是自动特征学习,它可以自动从大量原始数据中挖掘出有区分能力的特征,从而解决人工特征提取的局限性。
在特征抽取阶段,本文采用了BERT、LSTM和CNN的组合模式。使用BERT来提取词义和上下文信息,并将其转换为数值向量;将LSTM用于处理文本长序列数据,捕捉长距离依赖信息;而CNN可以从局部特征提取出行业数据的关键信息。这种组合使得特征的抽取既能考虑到全局信息又不缺失局部的关键特征。在处理行业间复杂、模糊边界的问题上,模型能更好地鉴别出行业的特性。
2.3 模型优化设计
在现代经济体系中,一个企业可能在不同的时间,甚至在相同的时间内,都存在属于多个不同行业的情况。这种现象反映了企业行业分类的固有多义性和模糊性,同时也为行业分类带来了重大的挑战,尤其是在构建具有泛化能力的深度学习模型的过程中。
为了应对这一挑战,本文提出了利用自注意力机制和迁移学习的方案。自注意力机制可以使模型自动确定输入特征之间的相互关系,从而有助于捕捉到行业分类中的多元性和模糊性。通过运用自注意力机制,模型能够学习到如何根据不同的上下文调整对企业的行业归类。
接下来,利用迁移学习来处理企业在不同行业之间的流动性。迁移学习使得从一个任务(如某一特定行业的分类)中学习到的知识能够被应用到另一任务(如另一行业的分类),这对于企业在不同行业之间的流动性的处理尤其重要。
为了实现这一策略,构建的数据集中应涵盖各类企业在不同的上下文和发展阶段的数据,包括但不限于企业的企业名称、经营范围等。然后利用这些数据来训练深度学习模型。
2.4 系统应用
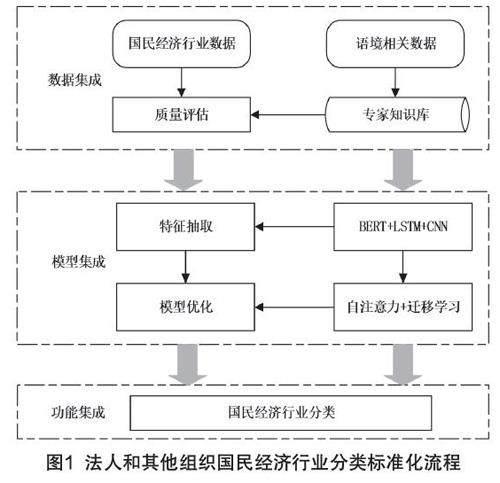
国民经济行业数据是理解和分析经济趋势、制定相应政策的重要依据。由于数据的多样性和复杂性,传统的分类方法往往无法准确进行分类。因此本文基于BERT-LSTM-CNN深度学习模型,实现了一个国民经济行业数据的自动分类标准化流程,主要由数据集成、模型集成和功能模块集成构成,如图1所示。
在数据集成阶段,对统一代码数据做了全面收集和精准预处理,还进一步整合了企业基本信息、经营范围、财务报告等多源数据,形成完整的企业画像,完成数据预处理和质量评估的工作。
模型集成阶段,将训练好的模型加载到数据平台,并与API接口交互。本文利用BERT、LSTM和CNN的混合模式对这些数据进行特征抽取,并应用自注意力机制与迁移学习策略,使模型在处理行业分类的多义性和模糊性上以及应对企业跨行业的问题上具有更高的准确度。
功能模块集成阶段包括对企业的统一代码数据进行行业分类,基于分类结果进行数据分析,如行业分布、发展趋势、风险预警等,最后通过收集用户反馈和审核结果对模型进行持续优化和调整,进一步增强模型的泛化和应用能力。
总结来说,通过上述标准化流程,可以实现深度学习模型与统一代码数据的有效结合,为各行业用户提供准确、及时、全面的国民经济行业分类信息,助力决策制定和业务发展。同时,通过持续的数据更新和模型优化,平台能够适应经济环境的变化和行业分类标准的调整,保持其服务的准确性和时效性,为国民经济行业数据的自动分类提供了一种精准、高效且可持续优化的解决方案。
3 结 语
国民经济行业分类是行业分析、决策制定和经济增长策略改进中的重要环节。本文将深度学习模型与统一代码数据有效结合,构建基于BERTLSTM-CNN国民经济行业数据的标准化流程,为各行业用户提供了准确、及时、全面的国民经济行业分类信息,进一步为决策制定和业务发展提供助力。法人和其他组织国民经济行业分类标准化流程工作需要不断深化,以推动其在决策制定等关键领域中发挥出更大的价值。
参考文献
[1]陶全桧, 安俊秀, 陈宏松. 基于跨模态融合E R N I E的多模态情感分析研究[ J ] .成都信息工程大学学报,2022,37(5):501-507.
[2]杨森淇,段旭良,肖展,等.基于ERNIE+DPCNN+BiGRU的農业新闻文本分类[J].计算机应用,2023,43(5):1461-1466.
[3]许浪,李代伟,张海清,等.基于神经网络的医疗文本分类研究[J].计算机工程与科学,2023,45(6):1116-1122.
[4]GAO H, ZENG X, YAO C. Application of improved d i s t r i b u t e d n a i v e B a y e s i a n a l g o r i t h m s i n t e x t classification[J]. The Journal of Supercomputing, 2019, 75:5831-5847.
[5]LUO X. Efficient English text classification using selected machine learning techniques[J]. Alexandria Engineering Journal, 2021, 60(3): 3401-3409.
[6]ZHAO D, HU X, XIONG S, et al. K-means clustering and kNN classification based on negative databases[J]. Applied soft computing, 2021, 110: 107732.
[7]CHEN H, WU L, CHEN J, et al. A comparative study of automated legal text classification using random forests and deep learning[J]. Information Processing & Management,2022, 59(2): 102798.
[8]DENG J, CHENG L, WANG Z. Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification[J]. Computer Speech & Language, 2021,68: 101182.
[9]A L B AW I S , M O H A M M E D T A , A L - Z AW I S .Understanding of a convolutional neural network[C]//2017 international conference on engineering and technology(ICET). Ieee, 2017: 1-6.
[10]POUYANFAR S, SADIQ S, YAN Y, et al. A survey on deep learning: Algorithms, techniques, and applications[J].ACM Computing Surveys (CSUR), 2018, 51(5): 1-36.
[11]CHEN C, DAI J. Mitigating backdoor attacks in lstmbased text classification systems by backdoor keyword identification[J]. Neurocomputing, 2021, 452: 253-262.
[12]L EHE?K A J, ?VEC J, IRCING P, et al. Adjusting BERTs pooling layer for large-scale multi-label text classification[C]//International Conference on Text, Speech,and Dialogue. Cham: Springer International Publishing,2020: 214-221.
作者简介
袁辉,硕士,高级工程师,研究方向为大数据分析和信息技术标准化。
赵捷,硕士,高级工程师,研究方向为大数据治理和信息技术标准化。
侯博,本科,工程师,研究方向为网络安全和信息技术标准化。
李晟飞,本科,工程师,研究方向为网络安全与机器学习。
韩雪,硕士,高级工程师,研究方向为统一社会信用代码相关标准。
(责任编辑:袁文静)
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
