
两阶段多标签分类探索中医证素辨证规律
2024-06-01 13:58:35蓝勇程春雷叶青胡杭乐沈友志
现代信息科技 2024年4期
蓝勇 程春雷 叶青 胡杭乐 沈友志

收稿日期:2023-05-10
基金項目:江西省自然科学基金资助项目(20224BAB206102);国家自然科学基金(82260988);江西省教育厅科学技术研究项目(GJJ2200923);江西省卫生和计划生育委员会-科技计划项目(202211404);江西中医药大学博士启动基金(2018WBZR021)
DOI:10.19850/j.cnki.2096-4706.2024.04.032
摘 要:探索证素辨证规律能更好地辅助临床决策和促进中医辨证理论的传承。中医文本句式结构复杂、表述标准不一,难以匹配符号规则,且神经网络黑盒特性又难以直接解释其辨证过程。为探索中医证素辨证规律,第一阶段使用神经网络模型对证素进行多标签分类,通过稀疏注意力捕获与证素相关的关键词及其权重生成证素表征;第二阶段使用随机森林对融入相关证素标签的证素表征进行分类训练,后对随机森林规则提取以探索辨证规律,提高证素辨证的可解释性。实验结果表明,该方法提升了证素辨识的准确率,同时F1保持较高水平,有利于探索证素辨证规律。
关键词:证素辨证规律;稀疏注意力;多标签分类;随机森林模型;可解释性
中图法分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)04-0153-10
Exploration of the Rules of Traditional Chinese Medicine Syndrome Elements Differentiation by Two-stage Multi-label Classification
LAN Yong1, CHENG Chunlei1,2, YE Qing1, HU Hangle1, SHEN Youzhi1
(1.College of Computer Science, Jiangxi University of Chinese Medicine, Nanchang 330004, China; 2.Key Laboratory of Artificial Intelligence in Chinese Medicine, Jiangxi University of Chinese Medicine, Nanchang 330004, China)
Abstract: Exploring the rules of syndrome element differentiation can better assist clinical decision-making and promote the inheritance of TCM syndrome differentiation theory. The sentence structure of TCM texts is complex, with varying expression standards, making it difficult to match symbol rules, and the black box characteristics of neural networks are difficult to directly explain their differentiation process. In order to explore the rules of syndrome element differentiation in TCM, it uses a neural network model to classify syndrome elements with multiple labels in the first stage, and generates syndrome element representation by capturing keywords and their weights related to syndrome elements through sparse attention. In the second stage, the random forest is used to conduct classified training on syndrome element representation incorporating relevant syndrome element labels, and then random forest rules are extracted to explore the syndrome differentiation rules and improve the interpretability of syndrome element differentiation. The experimental results show that this method improves the accuracy of syndrome element identification, while maintaining a high level of F1, which is conductive to exploring the rules of syndrome element differentiation.
Keywords: rules of syndrome element differentiation; sparse attention; multi-label classification; random forest model; interpretability
0 引 言
辨证是中医认识疾病的基本原则,也是中医临床立法、处方、用药的基础和前提,正确辨证有助于提高临床诊断的准确性和治疗效果[1]。在中医辨证中,临床专家收集四诊信息,并依据中医辨证理论对患者的证候归属进行诊断,从而实现对患者病情的准确诊断和治疗安排。然而,中医证候缺乏统一标准规范,具有稀疏、组合繁杂等特点,证素为证候的要素,是中医辨证诊断的最小单元[2],将证候转换为证素表示,规范了标签分布,减小了标签空间的复杂度,且一定程度上改变了中医证候及中医辨证方法繁杂、证型诊断结果各异的局面,也为中医学与深度模型交叉融合提供良好范式。证素辨证通过计算症状对病位、病性证素的诊断贡献度,准确辨识现阶段证素分布规律[3]。另一方面,中医辨证研究较多但临床应用却十分有限,关键原因之一是辨证的可解释性不足,由于不理解模型决策的原理,医生和患者难以认可模型的辨证结果。
为增强模型的可解释性,本文在辨证的同时探索证素辨证规律。分两个阶段进行,第一阶段使用融合稀疏注意力机制的神经网络模型对证素进行多标签分类,通过稀疏注意力捕获与证素相关的关键词及其权重生成证素表征,稀疏注意力对不同证素生成不同的文本表示,去除了无关特征,最大程度上关注了证素的关键辨证依据。但大量辨证依据独立分布且含有特异点,需从诸多样本的辨证依据中进一步分析其辨证规律。第二阶段基于第一阶段的证素表征,加入证素标签特征,期望学习标签之间相关性,后输入随机森林对证素进行分类,对训练好的随机森林模型规则提取以探索证素辨证规律,提高证素辨证的可解释性。本文的研究贡献主要如下:
1)第一阶段基于融合稀疏注意力机制的多标签分类模型生成证素的辨证依据:证素多标签分类的过程即证素辨证的过程,不过由于神经网络的黑盒特性,辨证过程难以解释,而稀疏注意力聚焦于关键辨证依据,去除无关特征,提升了证素辨证的可解释性,并为第二阶段做前提准备。
2)第二阶段对训练好的随机森林规则提取探索证素辨证规律:使用随机森林对融入证素标签特征的证素表征进行分类训练,考虑标签之间的相关性,由于随机森林中决策树路径具有天然的可解释性,可利用规则提取方法获取证素辨证规律,进一步提升了证素辨证的可解释性。
3)稀疏注意力机制成为神经网络模型与随机森林模型之间协作的桥梁:中医文本篇幅较长,统一编码高维且稀疏,使用随机森林直接对其训练将会大幅提升决策树的复杂度,且为得到更为精确的结果耗费大量时间资源生成大量的决策树,不利于事后可解释性分析,而神经网络融入稀疏注意力后能针对具体任务端到端地聚焦于关键特征,缩减样本的特征空间,有利于随机森林的训练。
4)形成了一个可解释的良好范式:首先由稀疏注意力生成关键辨证依据,缩减特征空间,然后使用随机森林对其进行分类训练,最后对训练好的随机森林规则提取生成证素辨证规律,进行事后可解释性分析,此方法在保持较好辨证效果的同时具有较强的可解释性。
1 相关工作
基于中医“辨证论治”的特点,中医辨证智能化的研究也日益增多[4]。基于传统的机器学习方法,严冬等[5]收集了78例多发性硬化患者308例次病例资料,对其进行主成分分析与聚类分析研究发性硬化患者的中医证候特点及其分布规律。庞稳泰等[6]提取2019冠状病毒中医诊疗方案中的病期、证型、方剂等信息,采用频数统计和相关分析,探讨组方及临床证候规律。赵若含等[6,7]收集160例原发性肺癌患者数据,采用Logistic回归模型进行多因素回归分析以确定独立影响因素,使用χ2检验分析抑郁轻重程度与中医证候之间的关系。杨玉培等[8]收集97例多囊卵巢综合征不孕症患者中医四诊信息,运用频数分析以及聚类分析等统计方法来探索治疗前后中医病性、病位的分布规律。传统的机器学习方法对数据集的质量有着较高的要求,需要中医领域专家对特征进行提取与整理,且此类方法不能很好地表征文本语义特征。
随着人工智能的不断发展,神经网络广泛应用于中医辨证任务中。丁亮等[9]使用深度神经网络建立原发性肝癌证型诊断分类模型,以挖掘临床数据和证型之间的非线性关系,并利用关联规则验证结果的准确性。张异卓等[10]构建基于BERT候选项选择结构的中医证候归类模型。Huang等[11]对病历数据进行结构化处理,将智能辩证视为高维稀疏向量分类任务,通过卷积神经网络模型生成的交叉特征进行辩证分类。此外,知识图谱的兴起为中医药领域知识的整合、关联以及分析提供了理想的技术方法,知识图谱可以有效地改进中医辨证方法的分析方式,帮助使用者理解和掌握中医学中的复杂信息。如石英杰[12]构建胸痹知识图谱探索胸痹的证治规律。刘凡[13]基于多源异构数据构建名老中医经验传承知识图谱,为慢性胃炎辨证论治方案提供可视化分析。另外,可将知识图谱与深度学习结合运用,以提高深度学习模型的性能,叶青等[14]以及Yang等[15]将知识图谱嵌入向量融入神经网络表征从而构建中医辨证模型。基于深度学习的中医辨证模型大都面向特定疾病或特定问题且解释性不足,中医辨证方法从理论走向临床应用还需进一步研究。
近年来,可解释性已成为人工智能领域的研究热点,旨在解释深度学习模型预测结果的原理,为此,越来越多的解释方法和模型被提出[16-22]。在医疗领域,Poplin等[23]构建了一个可解释的心血管疾病诊断系统,该系统使用注意力机制来关注影响诊断结果的重要因素,并自动生成注意力热力图,以视网膜图像作为参考,用于预测及评估与心血管疾病相关的风险。Kermany等[24]构建了可解释性的肺炎医疗诊断系统,能够精确诊断致盲视网膜疾病,并能在30秒内判断患者是否需要治疗且准确率较高。王雨虹[25]提出了一种基于实体关系抽取技术的中文影像报告肿瘤信息提取方法,该方法针对TNM分期的需求,自动从报告中提取与分期相关的文字表示,随后利用规则对文字表示进行分析,进而用于分期决策,其中提取的信息以报告文字为证据支撐,具有一定的解释性。
在中医领域,一些工作也研究了深度学习模型的可解释性。骆明楠[26]对舌诊病性进行诊断,通过引入注意力机制,增强了深度模型对图像的建模效果,进而提高了智能舌诊的病性诊断效果,并增加了诊断的可解释性。Pang等[27]在中医辨证过程中采用了注意力机制,为不同症状表现分配不同的权重,从而突出关键症状表现,提高了病情诊断的准确性和可解释性。郑毅[28]构建了药症知识图谱,使用深度模型建立处方推荐模型,采用最短路径生成法和注意力机制法对模型进行可解释性分析。尽管注意力机制有一定的可解释性,但对中医辩证思维的解释不够充分,难以完全呈现出真实的中医辨证过程。于是向兴华等[29]构建多棵去相关决策树,再使用规则提取方法探索中医辨证规则,具有一定的临床可解释性。
本文使用稀疏注意力端到端地捕获证与症之间的对应关系,具有一定的可解释性,后对训练好的随机森林规则提取生成证素辨证规律,可呈现中医辨证过程,进一步增强了证素辨证的可解释性。
2 模型方法
本文模型方法整体框架如图1所示,主要由融合了稀疏注意力机制的多标签分类注意力模型(Sparse At-tention Multi-label Classification, SAML)与随机森林(Random Forest, RF)组成。
方法包含两个阶段,第一阶段使用SAML模型抽取每个样本证素标签所关联的关键词及其稀疏注意力权重生成证素表征,其表现形式如图1中第一阶段右侧所示,其中,kni表示第n个证素所关注的第i个关键词,α表示其对应的注意力权重;第二阶段对证素表征融入相关标签特征,期望学习证素标签之间的相关性,后使用随机森林进行分类训练,对训练后的随机森林规则提取生成证素辨证规律,模型框架如图1中第二阶段所示,其中,Li表示第i个证素标签,使用独热编码。
2.1 SAML生成证素表征
第一阶段模型方法SAML基于极端多标签分类注意力模型(AttentionXML)做了改进,AttentionXML提出了多标签注意机制,该机制能够捕捉与每个标签最相关的部分,对不同的标签生成不同的文本表示,稀疏注意力在此基础上去除一些无关特征,聚焦于关键特征,保持较好辨证效果的同时提升模型的可解释性,另一方面,损失函数改为焦点损失,增强尾部标签的预测能力。
SAML模型由四部分组成:词汇表示层、Bi-LSTM层、稀疏注意力层、全连接层和输出层。图1中第一阶段左侧为SAML模型框架图。
1)词汇表示层。SAML的输入是长度为n的原始标记文本。每个词汇由一个深层语义嵌入向量表示,使用预训练的300维嵌入向量作为初始词汇表示,词库中未索引到的词使用随机向量表示。
2)Bi-LSTM层。Bi-LSTM是一种能够有效捕捉长距离双向语义依赖关系的神经网络,适用于序列文本数据的建模,使用Bi-LSTM捕获上下文特征,于每个时间步通过串联正向输出和反向输出作为下一层网络的输入。
3)稀疏注意力层。将注意力层改为稀疏注意力层,AttentionXML通过注意力机制加权计算每个标签上下文向量的线性组合,而Softmax归一化可能会导致密集的注意力权重,非零权重可能会为无关特征分配权重,且会缩减权重高的特征,本文采用稀疏注意力(α-entmax[30])关注关键特征,去除无关特征,如式(1)所示:
(1)
其中,当α = 1时表示Softmax函数,α = 2时表示Sparsemax函数。,将Rd+1中向量映射到Δd函数用于将权重向量转换为概率分布表示。α-entmax(z)避免采用指数函数对注意力权重z做平滑变换,该机制将z的欧氏投影返回到概率单纯形上,由于单纯形的限制,该投影点通常会落在单纯形的边界上[31],从而实现稀疏化效果。为保留更多的特征信息,α超参数设为1.5。
4)全连接层和输出层。SAML有一个全连接层和一个输出层。全连接层和输出层共享参数,以突出标签之间注意力的差异。此外,在标签之间共享全连接层的参数值可减少参数数量,以避免过度拟合,并保持模型比例较小。
5)焦点损失。AttentionXML使用交叉熵损失函数,将其改为焦点损失(Focal Loss, FL),随着预测输出概率的增加,正样本的损失逐渐降低;反之,对于负样本,预测输出概率越小则损失越小。焦点损失函数如式(2)所示:
(2)
其中,焦点损失在交叉熵基础上引入了一个可调节因子γ,当γ>0时有针对性地减少易分类样本的损失,使模型更加关注于困难和错误分类的样本,后引入平衡因子α,以此平衡标签样本的不均衡。
第一阶段使用SAML模型对证素进行多标签分类,稀疏注意力能够得出每个样本证素标签的关键辨证依据,但由大量样本生成的辨证依据繁杂多样且含有特异样本,为探索证素辨证普遍规律,从稀疏注意力层分别抽取每个证素所关联的关键词作为属性,其稀疏注意力权重作为特征进行编码生成证素表征,如圖1中第一阶段右侧所示,如此生成的证素表征不再是神经网络中不明具体含义的机器数字,一定程度上提升了证素辨证的可解释性,为第二阶段生成辨证规律做前提准备。
2.2 RF分类及规则提取
随机森林(RF)以决策树为基本单元,通过集成多棵决策树投票得出结果。RF构建单棵决策树过程为:假设数据集T中样本量为M,每次有放回随机选择M次样本,单个样本没有被抽取到的概率为(1-1/M)M,如此便选择了部分样本用作决策树训练。然后,训练样本同样采取随机抽样方法选择特征子集,特征抽取数量为 ,n为数据集特征总数,从 个特征中采用基尼指数选择一个最优特征作划分决策树节点,之后每个节点如此反复迭代,直至节点不能分裂为止。按照上述步骤构建大量的决策树,即构成随机森林,每棵决策树产生一个投票结果,最终投票结果最多的类别,即为模型最终预测结果。由于RF中决策树的特性,针对各分类结果存在多条路径规则,对RF进行规则提取可生成证素辨证规律。
2.2.1 证素表征预处理后训练
由于证素标签较多,为全部标签训练一个随机森林难以拟合数据集且规则路径错综复杂,为生成更为清晰的证素辨证规律,将多分类任务转换成二分类任务,对每个证素独立训练一个二分类随机森林,通过建立多个独立的随机森林来进行多标签分类,样本存在该证素标签即为正样本,无该证素标签即为负样本。首先,对第一阶段的证素表征进行归一化处理,后在此基础上融入相关证素标签,如图1第二阶段左侧所示,即将该样本的其他证素标签进行独热编码拼接于证素表征之后,期望在训练过程中能够捕捉标签之间的相关性,提升模型性能,最后将特征丰富后的证素表征输入RF中进行分类训练。
2.2.2 RF迭代测试方法
由于RF训练数据集中含有真实标签特征,而在测试时标签是未知的,为验证各证素RF的性能,采取一种迭代的方式进行测试,如图2所示。
测试集证素表征由第一阶段模型抽取得出,由于测试集标签未知,初次迭代将所有相关标签编码为0,而RF对缺省值也能获得较好结果,经过一次迭代后将所有RF分类预测结果进行独热编码,更新相关证素标签特征,然后再作为RF输入继续分类预测,如此反复迭代,当分类结果与真实标签的F1值不再变化时终止迭代。
2.2.3 RF规则提取生成证素辨证规律
对训练后的RF进行规则提取,以便解释模型的辨证结果。RF规则提取的基本思路是将决策树的结构转化为一组规则,每个规则对应决策树中的一条路径。以下是随机森林规则提取的流程:
1)遍历递归随机森林中的每棵决策树的节点,将其转化为一组规则。规则由条件和结论组成,其中条件由一系列特征和阈值组成,结论则是分类标签。
2)计算每个规则的频率和误差。频率为满足某一规则中规则条件的样本比例,误差为规则确定的错误分类样本数与满足规则样本数的比率,这两个指标有助于评估规则的有效性。
3)根据频率和误差指标,选择一组最具代表性和可解释性的规则,其规则可用于解释模型的结果或预测新的样本标签。为提高可解释性,可对规则进行合并和简化,如合并相同特征的规则,删除无关特征的条件等。
3 实验结果与分析
3.1 实验数据
对本文所提出的方法进行评估,实验数据为江西中医药大学岐黄国医书院提供的真实电子病历,共有10万余个病历。
首先对数据证候进行预处理,为规范标签分布,减少标签空间的复杂度,以中医证素表为标准通过前后向最大匹配法将证候标签转换成证素表示。中医证素表基于朱文锋教授总结的证素概念,再由中医专家对部分证素进行细化扩展得出,共有病性病位共200余种,部分证素如表1所示。通过中医证素表对电子病历证候进行预处理,表2为证候到证素转换示例。
表1 中医证素表
病位 病性 病位 病性
心 风 肺 湿
肝 寒 … …
肾 暑 咽 风阳上扰
表2 证候到证素转换示例
证候 证素
病位 病性
肝肾两经 湿浊 湿重 湿热
湿重于热 肾 肝 湿 热
太阳少阴风寒湿 营瘀 水饮浊 少阴 太阳 营 风 浊 水饮
寒湿
气滞 三焦 湿热生痰 湿热
痰阻气滞 三焦 气滞 痰 湿 热
将证候转换成证素表示之后,抽取电子病历中四诊信息作为模型的输入,最终实验数据集表现形式如表3所示。
表3 实验数据集表现形式
文本 标签
问诊;望诊;闻诊;脉诊 证素
模型输入为一串文本,由问诊、望诊、闻诊、脉诊四诊表述拼接而来,标签为证素。为使模型效果更优,对四诊数据进行一些处理。首先去除文本中的停用词与特殊字符,后为使模型更拟合于数据集,去除一些特殊的离群文本,仅保留文本长度为400个字及以下的文本,最后基于中医术语词表使用结巴分词对文本进行分词。此中医术语词表为中医专业人员整理,共包含27 468个词汇。
对数据进行删除和过滤等处理后,为有针对性地探索某位医生或某个病种的辨证规律,分别根据医生、病种(中医诊断)整理出4个数据集,训练集以及测试集分别随机选取了总样本的80%和20%,数据集样本量和标签数目情况如表4所示。
表4 数据集样本量和标签数目情况表
数据集 训练集 测试集 总计 证素标签
医生 医生A 16 258 4 065 20 323 141
医生B 12 710 3 178 15 888 183
病种 咳嗽 10 894 2 723 13 617 160
痹癥 3 518 879 4 397 135
3.2 实验参数与评价指标
本文实验模型的参数设置如下,词向量的维度为300维,使用Word2Vec词向量初始化,Word2Vec词库中未索引到的词由随机向量表示。Bi-LSTM的隐藏层维度为256,学习率为1×10-2,使用optim内置方法lr_scheduler调整学习率,最小为1×10-4;稀疏注意力机制α超参数设为1.5;使用Adam算法优化模型参数,使用批处理方法对模型参数进行更新,批处理大小batch-size设为100,迭代次数epoch为100,每20个batch设置一个检查点,以保存最优模型,当30次检查点不再更新最优模型时终止训练。以热启动方式不断生成多棵决策树,发现RF决策树棵数为200时模型趋于稳定,其他参数优先使用默认值。SAML模型损失函数为焦点损失,RF模型以基尼系数(gini)为损失函数。
两阶段多标签分类模型性能越好才能生成更为准确的证素辨证规律。为评价模型性能,两阶段实验均以汉明损失(Hamming-Loss, HL)、正确率(Precision)、召回率(Recall)和 micro-F1作为评价指标。
汉明损失衡量预测错误标签的比例,汉明损失值越低,表示模型性能越好。具体计算如式(3)所示:
(3)
其中,N表示样本总数,L表示标签数目,y表示第i个样本的真实标签,y′表示第i个样本的预测标签,XOR表示异或运算。
P值、R值和micro-F1计算公式如式(4)(5)(6)所示,其中m表示第m类标签,TPm、FPm、FNm分别表示真阳性、假阳性、假阴性。
(4)
(5)
(6)
3.3 实验结果及分析
为验证本文模型方法的有效性,与一些经典基线模型进行对比。基线模型为:CNN[32]、DPCNN[33]、BiLSTM-Att[34]、SGM[35]、AttentionXML[36]。表5为根据医生整理的数据集实验结果,表6为根據病种整理的数据集实验结果。
由表5和表6四个数据集实验结果显示,第一阶段模型SAML相比于基线模型在HL和F1评价指标上均取得了最好的性能。SAML相比于AttentionXML模型性能有所提高,说明采用焦点损失使模型关注于更少、更难分类的标签,增强了尾部标签的预测能力,且稀疏注意力关注证素辨证的关键依据,消除了无关特征的影响。SGM模型将多标签分类任务视为序列生成任务,其具有较强的顺序敏感性,不同的标签排列顺序会对预测结果产生较大影响。CNN模型分类依赖局部明显特征,而数据集中长尾标签较多,个别标签样本量较少,分类结果更加偏向于样本量多的标签,从召回率较低可以看出此特点。相比于BiLSTM-Att模型,SAML模型引入了稀疏注意力机制,能够针对不同标签捕捉最相关的文本表示,从而更为准确地生成证素标签的语义表示。
表5 医生数据集实验结果
模型 医生A 医生B
HL P R F1 HL P R F1
CNN 0.016 0.872 0.827 0.849 0.041 0.646 0.604 0.625
DPCNN 0.016 0.881 0.821 0.850 0.040 0.634 0.617 0.625
BiLSTM-Att 0.015 0.882 0.839 0.860 0.040 0.635 0.615 0.625
SGM 0.017 0.834 0.847 0.841 0.043 0.622 0.620 0.621
AttentionXML 0.015 0.873 0.852 0.862 0.041 0.634 0.608 0.621
SAML 0.014 0.887 0.857 0.872 0.040 0.634 0.620 0.626
SAML-RF 0.013 0.912 0.833 0.871 0.037 0.725 0.474 0.573
表6 病种数据集实验结果
模型 咳嗽 痹症
HL P R F1 HL P R F1
CNN 0.035 0.654 0.638 0.646 0.026 0.777 0.714 0.744
DPCNN 0.037 0.654 0.616 0.634 0.032 0.724 0.639 0.679
BiLSTM-Att 0.036 0.643 0.633 0.638 0.026 0.777 0.705 0.739
SGM 0.035 0.638 0.634 0.642 0.032 0.697 0.681 0.689
AttentionXML 0.035 0.655 0.638 0.646 0.025 0.799 0.701 0.747
SAML 0.033 0.660 0.656 0.658 0.024 0.795 0.723 0.757
SAML-RF 0.030 0.738 0.595 0.659 0.024 0.817 0.695 0.751
第二阶段模型SAML-RF在第一阶段模型SAML基础上进行实验,由表5和表6实验结果可以看出,第二阶段相比于第一阶段在HL和P值评价指标上达到了最优性能,并保持着较高的F1值。由于数据集标签样本不均衡,虽焦点损失有一定改善,但部分长尾标签仍然难以预测,导致第一阶段的召回率较低,生成的证素表征大多为样本量多的证素标签,而样本较少的证素标签正样本较少负样本较多,由第二阶段P值与R值对比可以看出此特点,RF预测的证素标签准确率远大于召回率,许多尾部标签难以预测。虽然第二阶段相比于第一阶段在F1性能上基本没有提升,甚至在医生B数据集上有所降低,但其使用RF对证素进行分类,RF中决策树天然的可解释性有利于事后进行可解释性分析。另一方面,第二阶段准确率高也具有一定优势,其证素分类准确率越高代表着RF决策树中正确的决策路径越多,有利于生成证素辨证规律。
由表5和表6实验结果可以看出,在医生A数据集和痹症数据集上模型效果最好,其F1值分别达到了0.871和0.755;而医生B数据集和咳嗽数据集效果较差,其F1值分别达到了0.573和0.659。究其原因,中医辨证理论有一特点,不同医生对不同病种的辨证风格不一,医生A数据集是根据医生A整理的数据集,其样本量较多,据统计其病种大多为感冒、哮喘以及发热,其他病种虽然存在但样本较少,故在医生A数据集上模型效果较优;而医生B数据集共含有48种类型的病种,各病种类型样本过于分散,且其证素标签有180个,在类型如此多的病种中对某一证素进行分类难度较高。咳嗽病种由于诱发因素较多,且多含其他并发症,不同医生辨证方式复杂多样,在此数据集上模型效果较差;而痹症由于其症状表现具有强烈的鲜明性,辨证风格较为统一,在少量样本的情况下也能有较好的效果。由于四个数据集的分布构成不同,在各数据集上的模型行性能也较为符合客观规律。
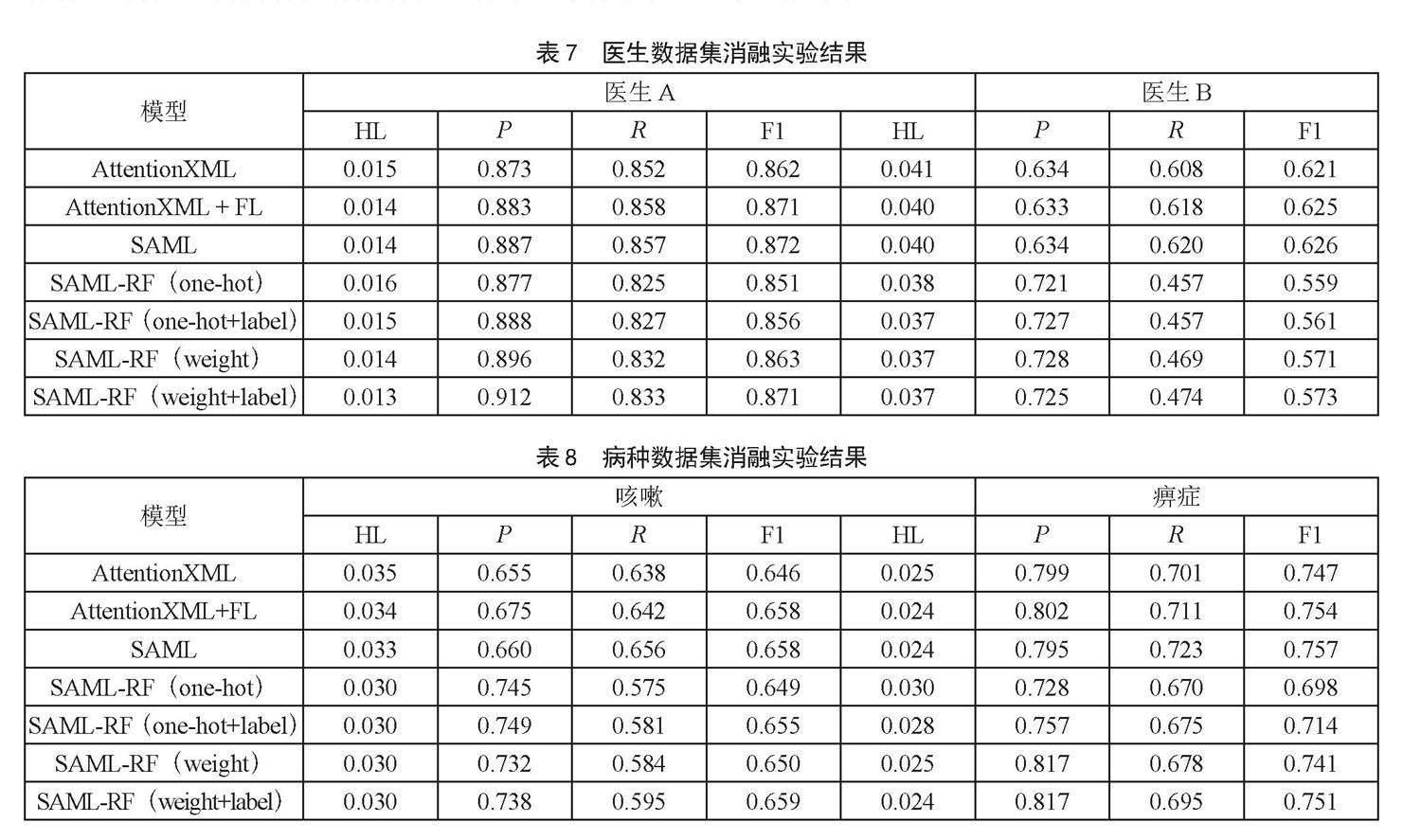
为了进一步验证模型各组件的有效性,本文在四个数据集上进行了三组消融实验,实验结果如表7和表8所示。
1)AttentionXML为基线模型,AttentionXML+FL在其基础上加入焦点损失,SAML再加入稀疏注意力机制。由表7和表8实验结果可以看出,加入焦点损失后的模型性能明显优于基线模型,表明焦点损失对模型是有利的,其增强了尾部标签的预测能力。加入稀疏注意力后模型性能略微提升,说明了稀疏注意力所关注到的关键词即辨证依据是切实有效的,在去除无关特征后,仅部分关键词就能得到较好的效果。
2)SAML-RF(one-hot)将关键词独热编码,SAML-RF(weight)将关键词特征设为稀疏注意力权重,SAML-RF(one-hot+label)以及SAML-RF(weight+label)将关键词编码后融入证素标签特征。表7和表8实验结果表明,其注意力权重特征对模型性能影响较小,单纯以抽取出的关键词进行独热编码也有较好的性能,进一步验证了稀疏注意力所关注到的关键词的有效性。
3)表7和表8实验结果显示,融入证素标签特征后模型性能有所提高,说明RF有捕捉到标签之间的相关性,关键词与证素标签相关联进一步提升模型的预测效果。
3.4 RF规则提取结果
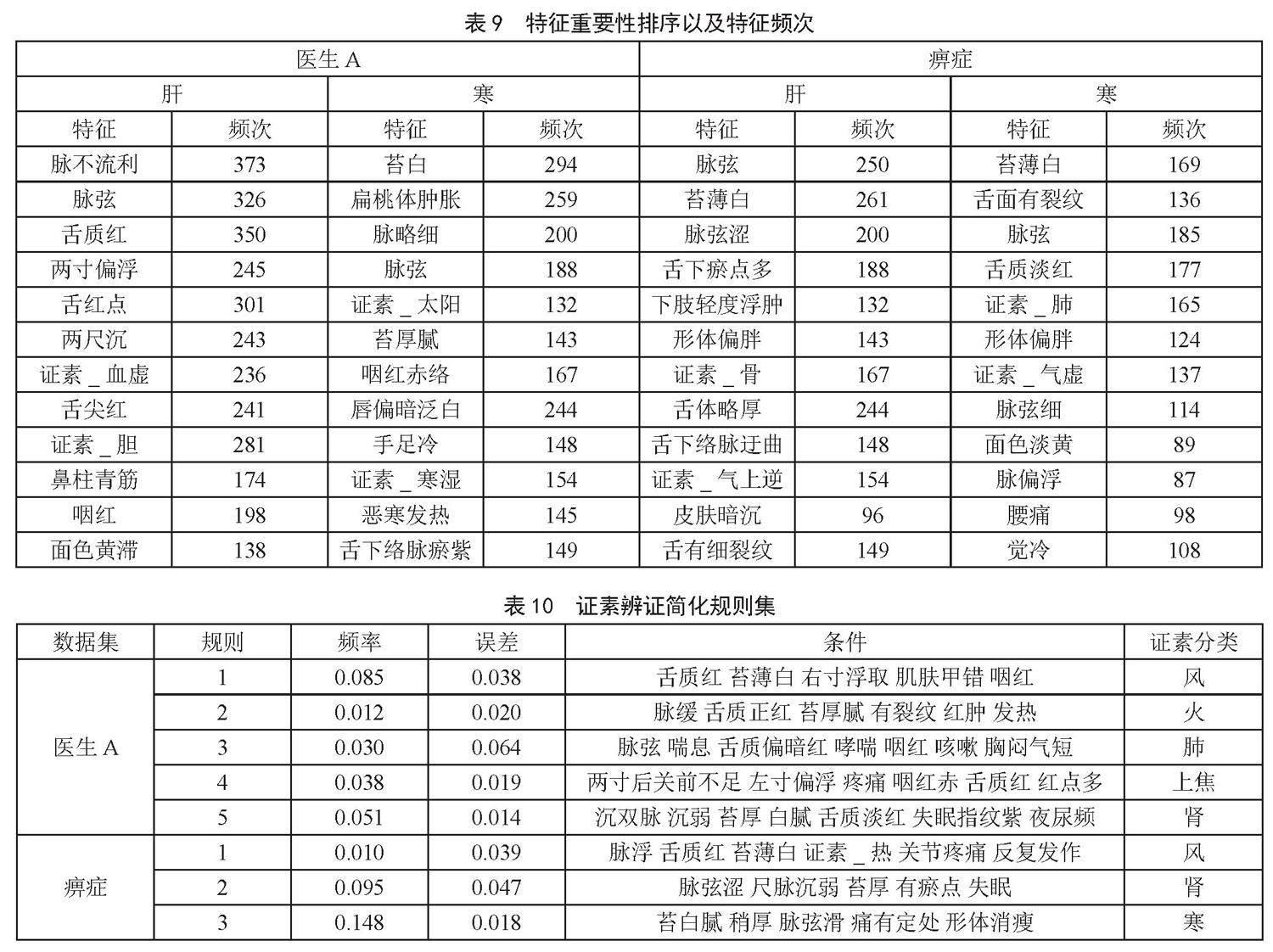
为能更直观地理解随机森林的辨证原理,忽略注意力权重的影响,将关键词和其他证素标签独热编码作为RF的训练数据,以性能较好的医生A和痹症数据集为例,随机森林部分特征重要性排序以及其为节点特征的频次如表9所示。表9中特征重要性从上到下逐渐减低,从表中可以看出,脉诊和舌诊特征的重要性较高,较为符合岐黄国医书院医师辨证风格。对训练好的RF进行规则提取,部分证素分类简化规则集如表10所示。
表10中频率为满足某一规则中规则条件的样本比例,误差为规则确定的错误分类样本数与满足规则样本数的比率,条件仅代表“有”此特征,其他“无”特征由于规则条件过长在此不打印输出。由表10可以看出,对RF进行规则提取确实能找到一些可解释的辨证规律,并且其误差也较低,可为医生或相关从业人员提供有效的指导,但部分规则还需中医专家进行分析评价。
4 结 论
本文使用融合了稀疏注意力的神经网络端到端地捕获证与症之间的对应关系,去除了其他无关特征,缩减特征空间,有利于随机森林的训练,后对训练好的随机森林进行规则提取生成证素辨证规律,可对辨证结果进行可解释性分析。实验结果表明,本文模型方法提升了证素辨识的准确率,同时F1保持较高水平,有利于探索证素辨证规律,增强了证素辨证的可解释性。
本文方法相比基线模型方法的辨证效果有所提高,但距离成为中医辨证辅助决策临床应用还有较大差距。需加强学习的深度,将知识图谱、深度学习等算法有机结合,加强模型的构造、训练和优化,且规则提取方法还需进一步深入研究。另外中医领域知识专业性非常强,其辨证理论复杂,本文虽能得到部分辨证规律,但大量规则还需和中医专家共同合作来分析评价,才能构建中医专家认可和理解的辨证规律。
参考文献:
[1] 冷玉琳,高泓,富晓旭,等.中医证候临床研究方法研究進展 [J].中华中医药杂志,2021,36(10):6002-6005.
[2] 朱文锋,甘慧娟.对古今有关证素概念的梳理 [J].湖南中医药导报,2004(11):1-3+5.
[3] 王章林,赖新梅.证素辨证理论体系与方法学研究述评 [J].福建中医药,2022,53(5):53-55+59.
[4] 李连新,杨璠,朱兆鑫,等.中医人工智能辨证研究现状与发展 [J].世界科学技术-中医药现代化,2021,23(11):4268-4276.
[5] 严冬,谢瑶,芮一峰,等.基于主成分分析与聚类分析的多发性硬化中医证候分类研究 [J].现代中医临床,2020,27(6):13-16+26.
[6] 庞稳泰,金鑫瑶,庞博,等.中医药防治新型冠状病毒肺炎方证规律分析 [J].中国中药杂志,2020,45(6):1242-1247.
[7] 赵若含,李慧杰,张洁,等.肺癌相关性抑郁的影响因素及中医证候分析 [J].现代中医临床,2022,29(5):13-18.
[8] 杨玉培,宋亚静,刘杨杰,等.基于聚类分析对体外受精与胚胎移植控制性超促排前后多囊卵巢综合征不孕症中医证候的研究 [J].世界中西医结合杂志,2022,17(10):2024-2028+2034.
[9] 丁亮,章新友,刘莉萍,等.基于深度神经网络的原发性肝癌证型诊断分类预测模型 [J].世界科学技术-中医药现代化,2020,22(12):4185-4192.
[10] 张异卓,周璐,孙月蒙,等.基于双向表示神经网络的中医证候归类模型的构建 [J].世界科学技术-中医药现代化,2022,24(10):4063-4072.
[11] HUANG Z,MIAO J,CHEN J,et al. A Traditional Chinese Medicine Syndrome Classification Model Based on Cross-Feature Generation by Convolution Neural Network: Model Development and Validation [J/OL].JMIR Medical Informatics,2022,10(4):e29290(2022-06-04).https://medinform.jmir.org/2022/4/e29290.
[12] 石英杰.基于病机模型的胸痹病中医智能辅助诊断方法研究 [D].北京:中国中医科学院,2021.
[13] 刘凡.基于知识图谱技术的名老中医慢性胃炎辨证论治方案研究 [D].北京:中国中医科学院,2020.
[14] 叶青,张素华,程春雷,等.融合知识图谱的多通道中医辨证模型 [J].科学技术与工程,2022,22(21):9190-9198.
[15] YANG R,YE Q,CHENG C,et al. Decision-making system for the diagnosis of syndrome based on traditional Chinese medicine knowledge graph [J/OL].Evidence-Based Complementary and Alternative Medicine,2022,2022:8693937(2022-02-10).https://pubmed.ncbi.nlm.nih.gov/35186106/.
[16] GUIDOTTI R,MONREALE A,RUGGIERI S,et al. A survey of methods for explaining black box models [J].ACM computing surveys (CSUR),2018,51(5):1-42.
[17] GUNNING D,AHA D. DARPA's explainable artificial intelligence (XAI) program [J].AI magazine,2019,40(2):44-58.
[18] SAMEK W,MONTAVON G,VEDALDI A,et al. Explainable AI: interpreting,explaining and visualizing deep learning [M].Cham:Springer,2019.
[19] LINARDATOS P,PAPASTEFANOPOULOS V,KOTSIANTIS S. Explainable ai: A review of machine learning interpretability methods [J/OL].Entropy,2020,23(1):18(2020-12-25).https://doi.org/10.3390/e23010018.
[20] TJOA E,GUAN C. A survey on explainable artificial intelligence (xai): Toward medical xai [J].IEEE transactions on neural networks and learning systems,2020,32(11):4793-4813.
[21] SCHOONDERWOERD T A J,JORRITSMA W,NEERINCX M A,et al. Human-centered XAI: Developing design patterns for explanations of clinical decision support systems [J/OL].International Journal of Human-Computer Studies,2021,154:102684(2021-07-28).https://doi.org/10.1016/j.ijhcs.2021.102684.
[22] ANTONIADI A M,DU Y,GUENDOUZ Y,et al. Current challenges and future opportunities for XAI in machine learning-based clinical decision support systems: a systematic review [J/OL].Applied Sciences,2021,11(11):5088(2021-05-31).https://www.mdpi.com/2076-3417/11/11/5088.
[23] POPLIN R,VARADARAJAN A V,BLUMER K,et al. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning [J].Nature biomedical engineering,2018,2(3):158-164.
[24] KERMANY D S,GOLDBAUM M,CAI W,et al. Identifying medical diagnoses and treatable diseases by image-based deep learning [J].cell,2018,172(5):1122-1131.
[25] 王雨虹.面向TNM分期的中文影像報告肿瘤信息提取研究 [D].杭州:浙江大学,2020.
[26] 骆明楠.面向智能舌诊的注意力卷积网络研究 [D].广州:华南理工大学,2020.
[27] PANG H,WEI S,ZHAO Y,et al. Effective attention-based network for syndrome differentiation of AIDS [J].BMC Medical Informatics and Decision Making,2020,20(1):1-10.
[28] 郑毅.融合知识图谱的可解释性处方推荐方法研究[D].北京:北京交通大学,2021.
[29] 向兴华,彭叶辉,杨伟,等.顽固性高血压发生主要不良心血管事件患者的中医四诊信息可解释性研究——基于随机森林规则提取方法 [J].中医杂志,2022,63(7):628-634.
[30] PETERS B,NICULAE V,MARTINS A F T. Sparse sequence-to-sequence models [EB/OL].(2019-05-14).https://arxiv.org/abs/1905.05702.
[31] MARTINS A,ASTUDILLO R. From softmax to sparsemax: A sparse model of attention and multi-label classification [C]//International conference on machine learning. New York:JMLR,2016:1614-1623.
[32] KIM Y. Convolutional Neural Networks for Sentence Classification [EB/OL].(2014-08-25).https://arxiv.org/abs/1408.5882v2.
[33] JOHNSON R,ZHANG T. Deep pyramid convolutional neural networks for text categorization [C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Vancouver:ACL,2017:562-570.
[34] ZHOU P,SHI W,TIAN J,et al. Attention-based bidirectional long short-term memory networks for relation classification [C]//Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2:Short papers).Berlin:ACL,2016:207-212.
[35] YANG P,SUN X,LI W,et al. SGM: sequence generation model for multi-label classification [EB/OL].(2018-06-13).https://arxiv.org/abs/1806.04822v3.
[36] YOU R,ZHANG Z,WANG Z,et al. Attentionxml: Label tree-based attention-aware deep model for high-performance extreme multi-label text classification [C]//Advances in Neural Information Processing Systems 32 (NeurIPS 2019).NIPS,2019:1-11.
作者簡介:蓝勇(1997—),男,汉族,江西宜春人,硕士研究生在读,研究方向:自然语言处理;通讯作者:程春雷(1976—),男,汉族,江西南昌人,副教授,硕导,博士,主要研究方向:机器学习、知识表示与学习、知识图谱;叶青(1967—),女,汉族,江西南昌人,教授,硕士,研究方向:计算机应用技术;胡杭乐(1998—),男,汉族,浙江杭州人,硕士研究生在读,研究方向:自然语言处理;沈友志(1997—),男,汉族,江西抚州人,硕士研究生在读,研究方向:自然语言处理。
