
基于改进DeepLabv3+的道路分割算法
2024-06-01 11:14:29葛振强
现代信息科技 2024年4期
收稿日期:2023-08-07
DOI:10.19850/j.cnki.2096-4706.2024.04.028
摘 要:基于深度学习的遥感影像图像分割技术使用越来越广泛,针对现有算法存在参数量较大、细节部分提取结果差等问题,提出一种基于改进DeepLabv3+的道路图像分割方法。将轻量型网络MobileNetV2引入改进后的池化金字塔模型用以提取中阶特征图,增强了不同感受野之间的相关性;并采用多尺度拼接融合方法生成高阶特征图,同时引入注意力机制来进一步加强对图像特征的提取效果。实验结果表明,所提方法相比于DeepLabv3+模型mIoU提高了5%,有效提升了遥感图像的分割精度。
关键词:语义分割;遥感影像;道路提取;注意力机制;DeepLabv3+
中图分类号:TP18;TP751 文献标识码:A 文章编号:2096-4706(2024)04-0132-05
Road Segmentation Algorithm Based on Improved DeepLabv3+
GE Zhenqiang
(Taiyuan Normal University, Jinzhong 030619, China)
Abstract: The use of Deep Learning-based remote sensing image segmentation technology is becoming increasingly widespread. In response to the problems of large parameter quantities and poor results in extracting details in existing algorithms, a road image segmentation method based on improved DeepLabv3+ is proposed. Introducing the lightweight network MobileNetV2 into an improved pooling pyramid model to extract mid-order feature maps, which enhance the correlation between different receptive fields. A multi-scale concatenation fusion method is adopted to generate high-order feature maps, while introducing attention mechanisms to further enhance the extraction effect of image features. The experimental results show that the proposed method improves mIoU by 5% compared to the DeepLabv3+ model, effectively enhancing the segmentation accuracy of remote sensing images.
Keywords: semantic segmentation; remote sensing image; road extraction; Attention Mechanism; DeepLabv3+
0 引 言
图像语义分割是在像素级别上的分类,即对图像进行识别和理解,针对图像所含有的语义信息对图像中每个像素进行分类标注[1]。语义分割技术在医疗[2,3]、交通、遥感影像[4-6]分割等领域有广泛的应用。在交通领域中,道路是交通的主要组成部分,对城市规划和交通管理有着非常重要的意义。高分辨率遥感图像中的道路提取任务就是针对这个问题进行的。传统的人工提取方法耗时费力,难以处理大规模数据。而语义分割技术可以通过深度学习模型自动提取道路的轮廓和边界,大大提高了提取效率和准确性,有着非常广泛的应用前景。语义分割技术被广泛用于图像处理领域,能够自动提取目标区域的轮廓和边界,SegNet[7]、UNet[8]等算法在各个领域有着准确性高、效率高的特点。但是语义分割在道路方面的使用还不是很多,因其存在一些处理特征时忽略了像素间关系或者空间分辨率减小的情况。近几年,由谷歌设计的Deeplab系列图像分割算法获得了广大科技研究者的广泛关注,该网络提出了空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP),扩大了分割网络的感受野,提高了分割网络的准确性。DeepLabV3+算法[9]使用了Encoder-Decoder结构,通过融合低阶特征和高阶特征,使分割网络获取更多的特征信息,提高了分割的准确性。有学者不断对该模型进行改进[10-13]以期达到分割更加精确的目的。尽管DeepLabV3+图像分割网络在一些公开数据集上有着不错的效果,但是对于道路提取这一对细节要求更多的任务,DeepLabV3+的表现就有些不尽人意了。同时DeepLabV3+使用Xception网络作为特征提取网络造成该模型参数量比较大,所以需要更多的时间来进行计算。还因为道路环境中背景复杂,存在很多干扰因素,也容易出现细节部分提取效果较差的问题。
针对上述道路分割所存在的问题,本文提出一种基于改进DeepLabV3+分割方法来进行遥感图像的道路分割,选择更加轻量化的特征提取网络,对原始的ASPP結构进行改进,添加注意力机制和进行多尺度融合。通过对比实验验证此方法可以使道路边缘分割更加清晰,提高了道路提取精度。
1 理论基础
1.1 DeepLabV3+基础模型
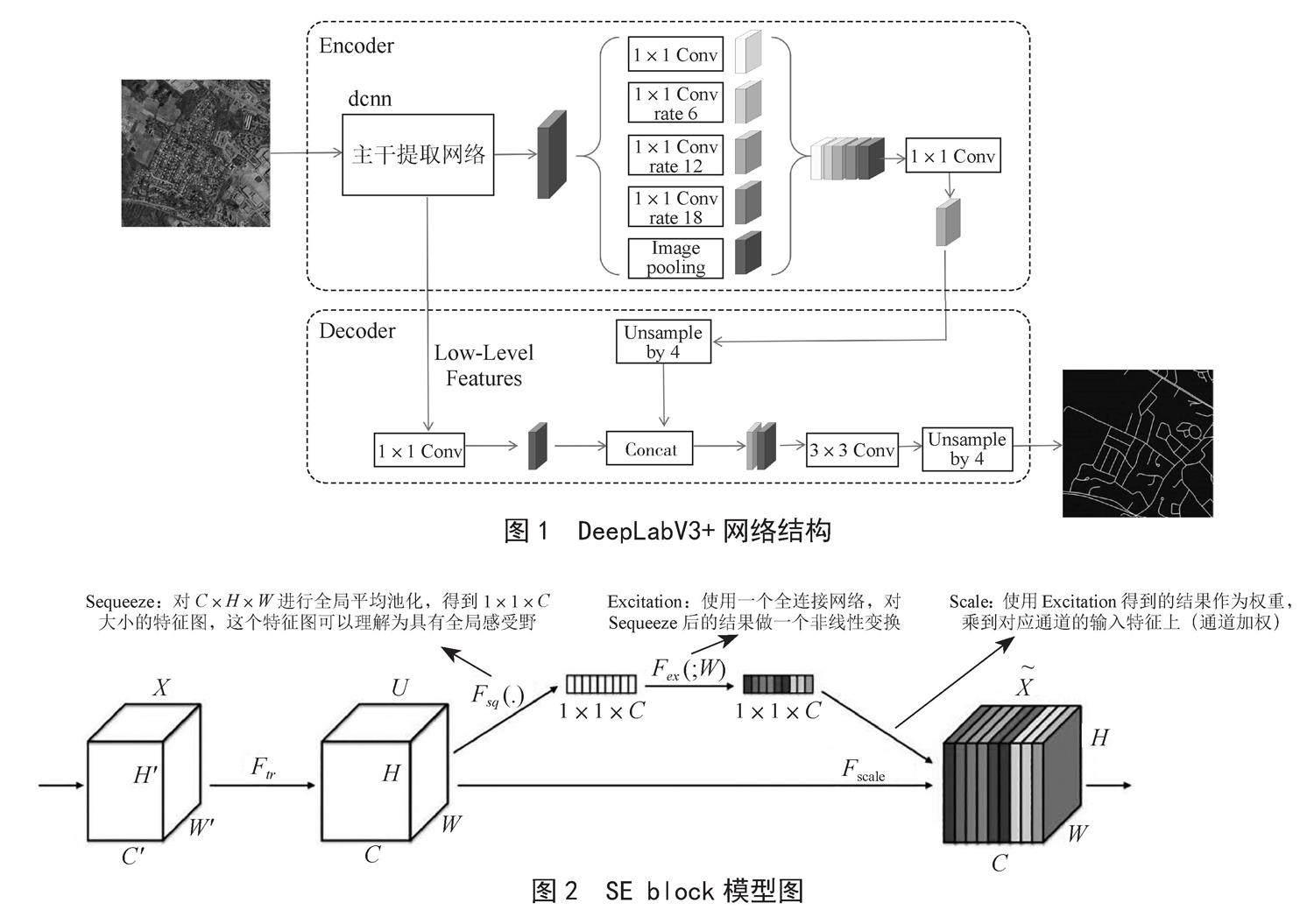
DeepLabV3+是在DeepLabV3基础上的改进,它们使用了相同的编码器模块,DeepLabV3+在DeepLabV3基础上添加了解码器模块,从而实现端到端的语义分割。deepLabV3+网络结构如图1所示。
1.2 SE通道注意力机制
为了更好地对通道信息有选择地进行关注,从而提高信息输出的效率和边缘细节分割准确性,在解码器4倍上采样后使用SENet(Squeeze and Excitation Networks)[14]通道注意力机制来加强通道信息获取。图2为该机制的结构图,图中C、H、W代表特征图的通道数、长和宽。该结构主要分为以下3个方面:1)将特征图进行Squeeze(压缩),该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合。2)Excitation操作,该步骤使用两个全连接层,通过全连接层之间的非线性特征增加模型的复杂度,以确定不同通道之间的权重。3)将Reshape过后的权重值与原有的特征图做乘法运算(该步骤采用Python的广播机制),得到不同权重下的特征图。
2 改进的DeepLabV3+网络
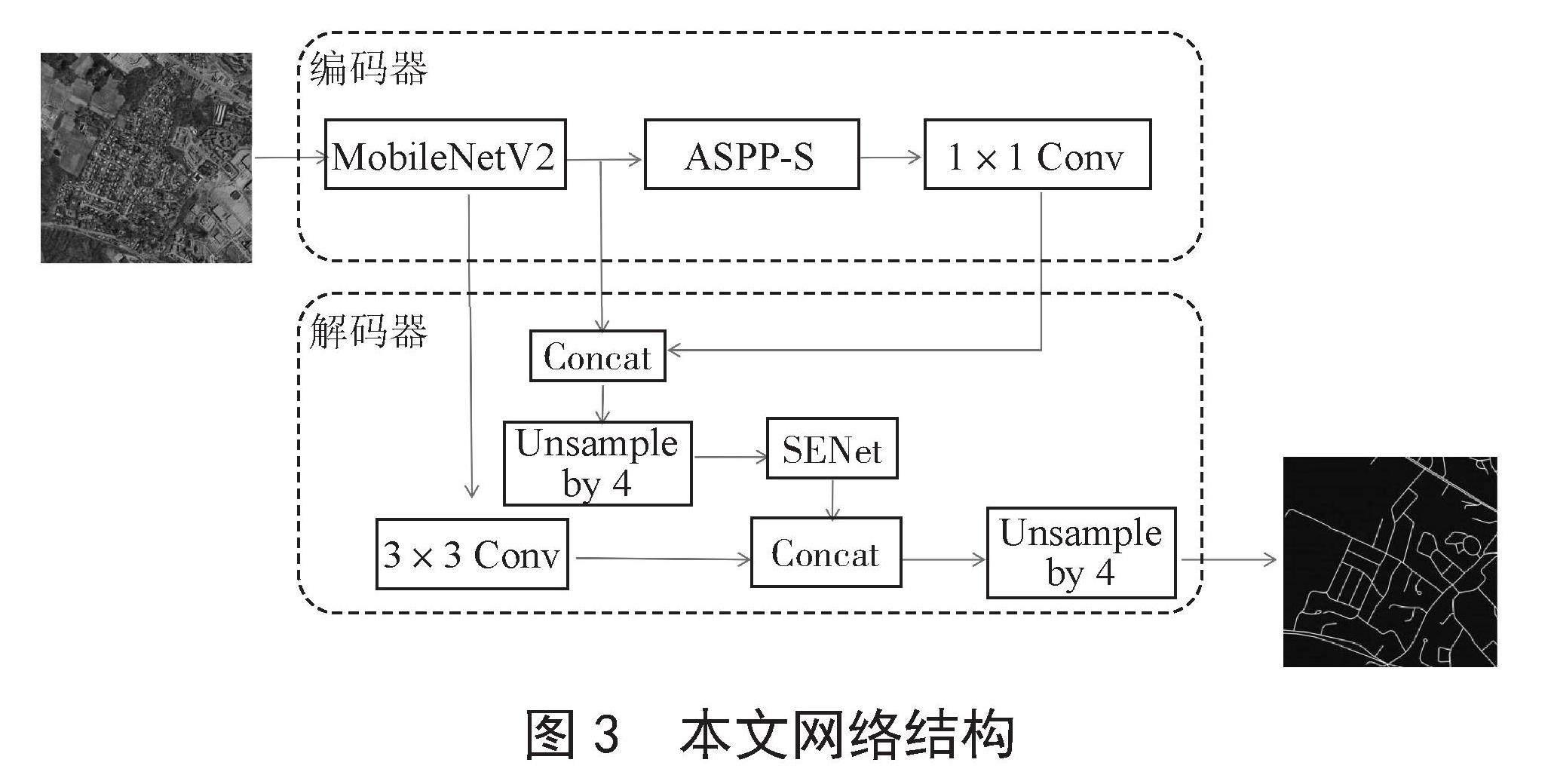
在遥感图像中,道路信息所占据的像素比例通常相对较小,而且容易受到背景环境因素的干扰,如建筑物、树木等。因此,对于道路信息的准确提取,算法的细节提取能力非常重要。为解决DeepLabv3+模型参数量大,且对道路易产生漏分割和不连续问题,本文对DeepLabV3+模型的主干特征提取网络进行轻量化改进,再对ASPP模块进行改进,最后在改进的ASPP模块中进行特征融合时加入SENet注意力机制,使分割速度和分割精度得到有效提升。改进后的DeepLabV3+算法网络结构如图3所示。
图3 本文网络结构
2.1 轻量化特征提取网络
在原先的DeepLabV3+算法中,使用复杂的Xception网络结构可能会导致在道路提取这种小目标的任务中存在精确度不够的问题,因为Xception网络可能在提取细节特征时不够准确。此外,Xception网络的参数量庞大,需要消耗大量的计算资源和时间。为了解决这些问题,本文采用了轻量级的MobileNetV2结构作为主干特征提取网络。相比于Xception,MobileNetV2具有更少的参数量,训练速度更快,能够更快地提取道路图像中的特征,从而使模型更容易捕捉到道路的细节和纹理,更适用于道路提取任务。
MobileNetV2是一种轻量级的卷积神经网络结构,用于图像分类和特征提取任务。它是MobileNetV1的改进版本,通过引入一系列的设计技巧来提高模型的性能,MobileNetV2采用了深度可分离卷积(Depthwise Separable Convolution)作为基础的卷积操作,将标准卷积分解为深度卷积和逐点卷积两个步骤,从而减少了计算量和参数量。此外MobileNetV2还引入了线性瓶颈(Linear Bottlenecks)、倒残差结构(Inverted Residuals)和线性激活函数等技术,进一步提高了模型的效率和表达能力。总体而言,MobileNetV2在保持较高准确性的同时,大大减少了模型的参数量和计算复杂度。
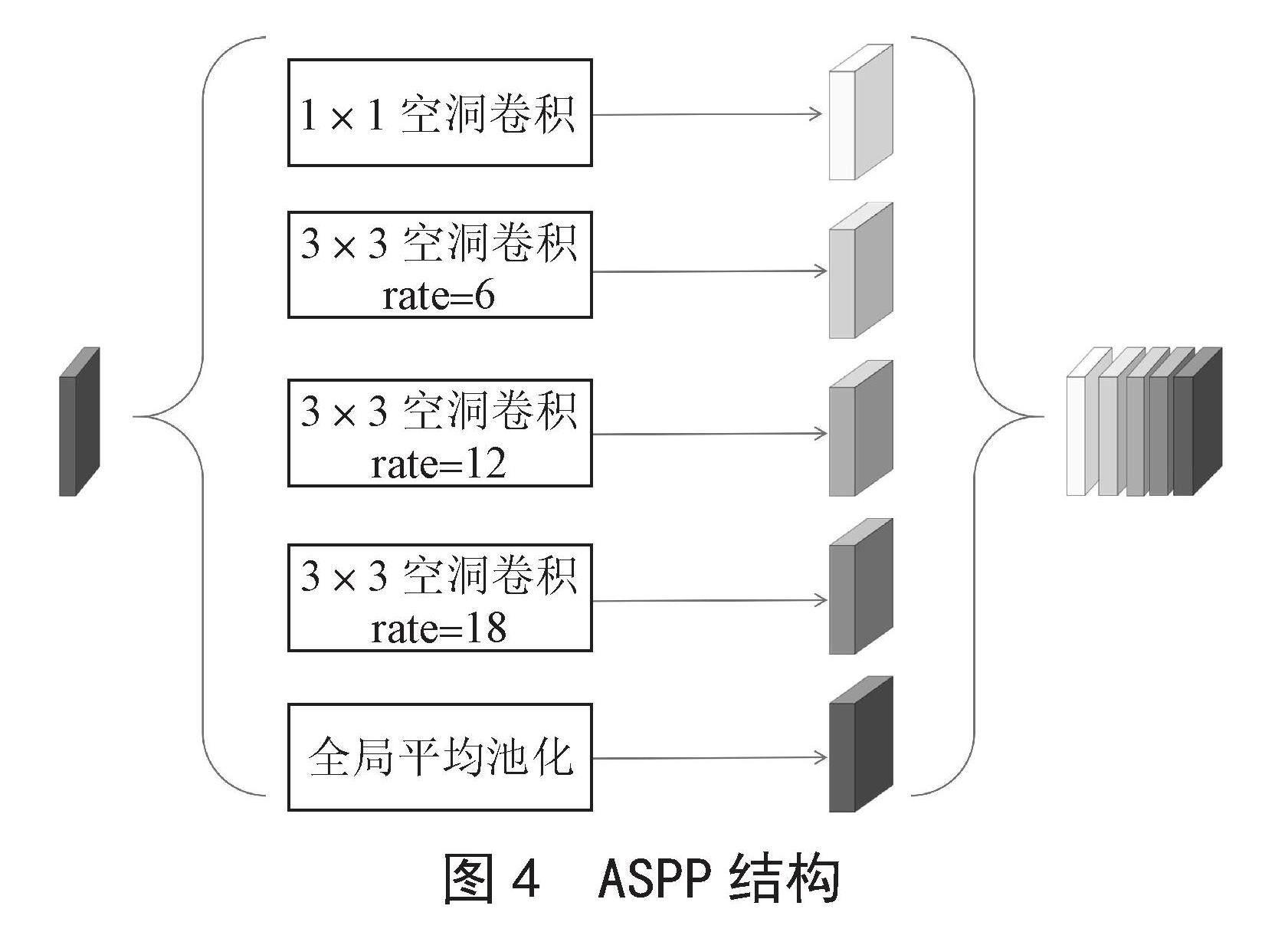
2.2 改进的ASPP模块
ASPP为了更好地获取特征信息,直接使用不同倍率的空洞卷积来提高分割精度。ASPP结构如图4所示。
图4 ASPP结构
原始ASPP结构扩张率分别采用的是6、12、18,直接将不同扩张率下的特征图进行融合,会造成特征信息的缺失和感受野的不足。为了解决信息的不连续和感受野的不足,本文提出在原始ASPP中融合不同倍率下的特征图来解决上述问题,如图5所示。
改进DeepLabV3+网络的ASPP模块,将原本并行的分支进行交叉融合,实现更大的视野和更强的特征提取能力。改进之后的ASPP模块在原有3个空洞卷积并行的基础上增加了串联结构,将扩张率小的输出与其他分支融合,再送入较大的空洞卷积,获得更好的特征提取效果。
图5 改进的ASPP结构
2.3 多尺度融合
当输入一张图像时,首先通过编码端的MobileNetV2网络进行特征提取。当下采样4倍时,获得低阶特征图。通过主干网络下采样完成时获得中阶特征图。接下来,将下采样16倍的中阶特征图输入ASPP-S模块进行处理。ASPP-S模块采用了空洞空间金字塔池化的方式,通过不同采样率的空洞卷积来捕捉多尺度上下文信息。通道拼接是将两个特征图的通道维度连接在一起,以增加特征的多样性和丰富性。在解码端,我们获得了3个分辨率不同的特征图。我们先将中阶和高阶特征图进行通道调节然后进行融合,再通过注意力模块进行进一步的特征提取之后进行4倍上采样与低阶特征图融合,进一步提取图像中的语义信息和边缘细节。最后,对融合后的特征图进行4倍上采样将特征图恢复到原始图像的分辨率,以得到最终的分割结果。这个网络架构的目标是通过多尺度特征融合和后续处理步骤来提高图像分割的精度,并保留细节信息,从而得到更准确的分割结果。
3 实验验证与分析
3.1 实验设置
3.1.1 数据集及评价标准
本文实验所采用数据集为CHN6-CUG[15]道路数据集,其由中国地质大学(武汉)HPSCIL的朱琪琪团队制作并共享,是道路提取任务中广泛应用的数据集之一。该数据集是人工标记的像素级高分辨率卫星影像,遥感影像底图来自谷歌地球。根据路面覆盖度,标示的道路包括有轨道覆盖的路面和无轨道覆盖的路面。根据地理因素的物理角度,标示道路包括铁路、公路、城市道路和农村道路等。CHN6-CUG包含4 511張标记图像,图像分辨率大小为512×512,将3 608张用于模型训练,903张用于测试和结果评估。
3.1.2 语义分割实验评估指标
评价指标用来评价语义分割模型的分割效果。在遥感影像目标提取领域,常用的评价指标有像素精度(PA)、平均交并比(mIoU)等。mIoU是指模型对每一类预测的结果和真实值的交集与并集的比值求和后再计算平均值的结果,其反映了模型能够正确预测的能力。PA是指正确预测的像素数与总的像素数的比值。其公式分别为:
(1)
(2)
其中:k+1为类别总数,pii为正确分类的像素数,pij为i类被预测为j类的数量,pji为j类被判断为i类的数量。
3.1.3 训练策略
本文实验是在Windows系统下搭建的PyTorch深度学习框架中进行具体实现。训练过程采用了如下参数设置:网络的初始学习率设置为5×10-4,选择了Adam优化器,相比与其他优化器,Adam优化器能够同时考虑一阶动量和二阶动量,并动态调整每个参数的学习率,从而使模型更快收敛至性能最优,batchsize为4,每一轮的迭代次数为516次,epochs设置为100,损失函数使用交叉熵损失函数。
3.2 实验结果及分析
为了验证本文方法在分割任务中的有效性,将所有网络模型在实验环境和相关参数一致的情况下进行对比试验,分别为原图、标签图、本文方法测试结果(Our)、DeepLabV3+测试结果、UNet测试结果、SegNet测试结果,各项性能指标对比如表1所示。
表1 不同模型评价指标对比
模型 mIoU mPA
SegNet 0.59 0.71
UNet 0.61 0.74
Deeplabv3+ 0.65 0.84
Our 0.70 0.86
DeepLabV3+是在DeepLabV3网络基础上添加了解码器模块,但该网络中的ASPP由于特征采样不够密集,大量信息被忽略,使道路的分割完整性較差。UNet也是基于编解码器的网络模型,它主要是在每个解码层之间添加了跳跃连接,对于复杂的遥感图片而言效果不是很好。而本文改进模型在CHN6-CUG数据集上的指标mIoU达到70%,效果最佳。相较于基础网络,本文方法的mIoU提高了5%。
图6给出了本文方法与其他模型可视化分割结果。其中,SegNet表现最差,错分、漏分严重,分割不完整;UNet和DeeplabV3+从分割结果来看,针对边界模糊的道路分割还是不完整,部分边界存在粘合。本文利用多尺度特征提取结构和通道注意力机制,提升了网络特征提取的能力,使得网络能够更加准确地识别不同尺度的道路目标,并且能够更加敏锐地捕捉边缘细节信息,可视化结果优于其他模型,并且每项指标均高于其他模型的精度,证明本文方法的有效性。
图6 在CHN6-CUG数据集上的分割结果对比
4 结 论
本文提出一种适用于遥感道路分割的改进DeepLabV3+网络。网络中通过改进的空间金字塔池化获得密集的采样和更大的感受野,丰富上下文信息;通道注意力加强道路的分割精度与边缘完整度。从分割结果来,对较小尺寸和复杂重叠道路的边界模糊和阴影干扰等,还是会出现分割不精确和目标粘连问题。因此,未来工作中在提升密集小目标建筑分割精度方面还要做进一步的研究。
参考文献:
[1] 徐辉,祝玉华,甄彤,等.深度神经网络图像语义分割方法综述 [J].计算机科学与探索,2021,15(1):47-59.
[2] 杨国亮,洪志阳,王志元,等.基于改进全卷积网络的皮肤病变图像分割 [J].计算机工程与设计,2018,39(11):3500-3505.
[3] 侯腾璇,赵涓涓,强彦,等.CRF 3D-UNet肺结节分割网络 [J].计算机工程与设计,2020,41(6):1663-1669.
[4] YANG G,ZHANG Q,ZHANG G X. EANet: Edge-Aware Network for the Extraction of Buildings from Aerial Images [J/OL].Remote Sensing,2020,12(13):2161[2023-09-16].https://doi.org/10.3390/rs12132161.
[5] 陈小龙,赵骥,陈思溢.基于注意力编码的轻量化语义分割网络 [J].激光与光电子学进展,2021,58(14):225-233.
[6] ABDOLLAHI A,PRADHAN B,ABDULLAH A M. An ensemble architecture of deep convolutional Segnet and Unet networks for building semantic segmentation from high-resolution aerial images [J].Geocarto International,2022,37(12):3355-3370.
[7] RONNEBERGER O,FISCHER P,BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation [C]/MICCAI 2015: Medical Image Computing and Computer-Assisted Intervention. Munich:Springer,2015:234-241.
[8] BADRINARAYANAN V,HANDA A,CIPOLLA R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling [J/OL].arXiv:1505.07293 [cs.CV].[2023-09-16].https://arxiv.org/abs/1505.07293.
[9] CHEN L C,ZHU Y K,PAPANDREOU G,et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation [C]//Proceedings of the European Conference on Computer Vision (ECCV 2018). Munich:Springer,2018:833-851.
[10] 齐建伟,王伟峰,张乐,等.基于改进DeepLabV3+算法的遥感影像建筑物变化检测 [J].测绘通报,2023(4):145-149.
[11] 马冬梅,黄欣悦,李煜.基于特征融合和注意力机制的图像语义分割 [J].计算机工程与科学,2023,45(3):495-503.
[12] ZHU R H,XIN B J,DENG N,et al. Semantic Segmentation Using DeepLabv3+ Model for Fabric Defect Detection [J].Wuhan University Journal of Natural Sciences,2022,27(6):539-549.
[13] 王云艳,王重阳,武华轩,等.基于改进型Deeplabv3的城市道路图像语义分割 [J].计算机仿真,2022,39(10):148-152+158.
[14] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,42(8):2011-2023.
[15] ZHU Q Q,ZHANG Y Y,WANG L Z,et.al. A Global Context-aware and Batch-independent Network for road extraction from VHR satellite imagery [J].ISPRS Journal of Photogrammetry and Remote Sensing,2021,175:353-365.
作者簡介:葛振强(1997—),男,汉族,安徽亳州人,硕士研究生在读,研究方向:图像处理。
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
航海(2016年6期)2017-01-09 11:28:24
科技视界(2016年13期)2016-06-13 12:01:14
中国科技博览(2016年1期)2016-04-25 20:19:32
现代电子技术(2015年17期)2015-09-23 21:35:58
