
基于Python语言的中国革命历史知识图谱数据预处理技术研究
2024-06-01 10:36:24景文会刘伟黄炳程覃兴刚任佳祺
现代信息科技 2024年4期
关键词:数据处理
景文会 刘伟 黄炳程 覃兴刚 任佳祺
收稿日期:2023-06-07
基金项目:2022年广西壮族自治区区级大学生创新创业训练计划项目资助(S202210603152)
DOI:10.19850/j.cnki.2096-4706.2024.04.025
摘 要:中國革命历史数据蕴含丰富的历史信息和文化价值,充分利用这些数据对传承中华民族的优秀传统文化有重要意义。文章针对中国革命历史数据预处理的问题,阐述了基于Python语言的中国革命历史数据处理和分析的步骤和方法,介绍了中国革命历史数据从文字图片提取,到文字图片的储存处理,再到为数据中的人物和事件实体绑定链接的详细流程。此外,项目还取得了大量中国革命历史相关的文字数据,并进行了文本预处理和分析,成功地实现了对中国革命历史相关文本的知识图谱的构建。文章所提方法具有一定的实用性和优越性,对于推进中国革命历史的传承和发展具有一定的参考价值。
关键词:Python;中国革命历史;数据处理
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)04-0116-05
Research on Data Preprocessing Technology of Chinese Revolutionary History Knowledge Graph Based on Python Language
JING Wenhui, LIU Wei, HUANG Bingcheng, QIN Xinggang, REN Jiaqi
(School of Computer and Information Engineering, Nanning Normal University, Nanning 530100, China)
Abstract: The historical data of the Chinese revolution contains rich historical information and cultural value, and fully utilizing these data is of great significance for inheriting the excellent traditional culture of the Chinese nation. This paper elaborates on the steps and methods of processing and analyzing Chinese revolutionary historical data based on Python language, focusing on the issue of preprocessing Chinese revolutionary historical data. It introduces the detailed process of Chinese revolutionary historical data from extracting text image, storing and processing text images, and then binding links for characters and event entities in the data. In addition, the project also obtained a large number of text data related to the history of the Chinese revolution, and carried out text preprocessing and analysis, successfully realizing the construction of the Knowledge Graph of the text related to the history of the Chinese revolution. The method proposed in the paper has certain practicality and superiority, and has certain reference value for promoting the inheritance and development of Chinese revolutionary history.
Keywords: Python; Chinese revolutionary history; data processing
0 引 言
中国革命精神是中华民族宝贵的精神财富,激励了一代又一代中国人民为理想和信仰拼搏奋斗。了解中国革命历史、研究中国革命历史对中华民族的文化传承具有重要意义。知识图谱是将中国革命历史知识数字化的有效工具。为了构建中国革命历史知识图谱,需要从大量的中国革命历史文档资料中,抽取人物、地点、事件等实体。为了实现文字和图片的关联展示,需要将文档资料中图片和文字分离,按知识图谱框架结构将图片和文字分别存储及处理。本文将介绍基于Python技术的中国革命历史知识图谱构建数据预处理过程。大概分为以下3个步骤:分离文档中的文字和图片;文字和图片的存储及实体识别处理;为人物和事件实体绑定百度百科的链接。下面将对3个步骤逐一详细介绍。
1 分离文档中的文字和图片
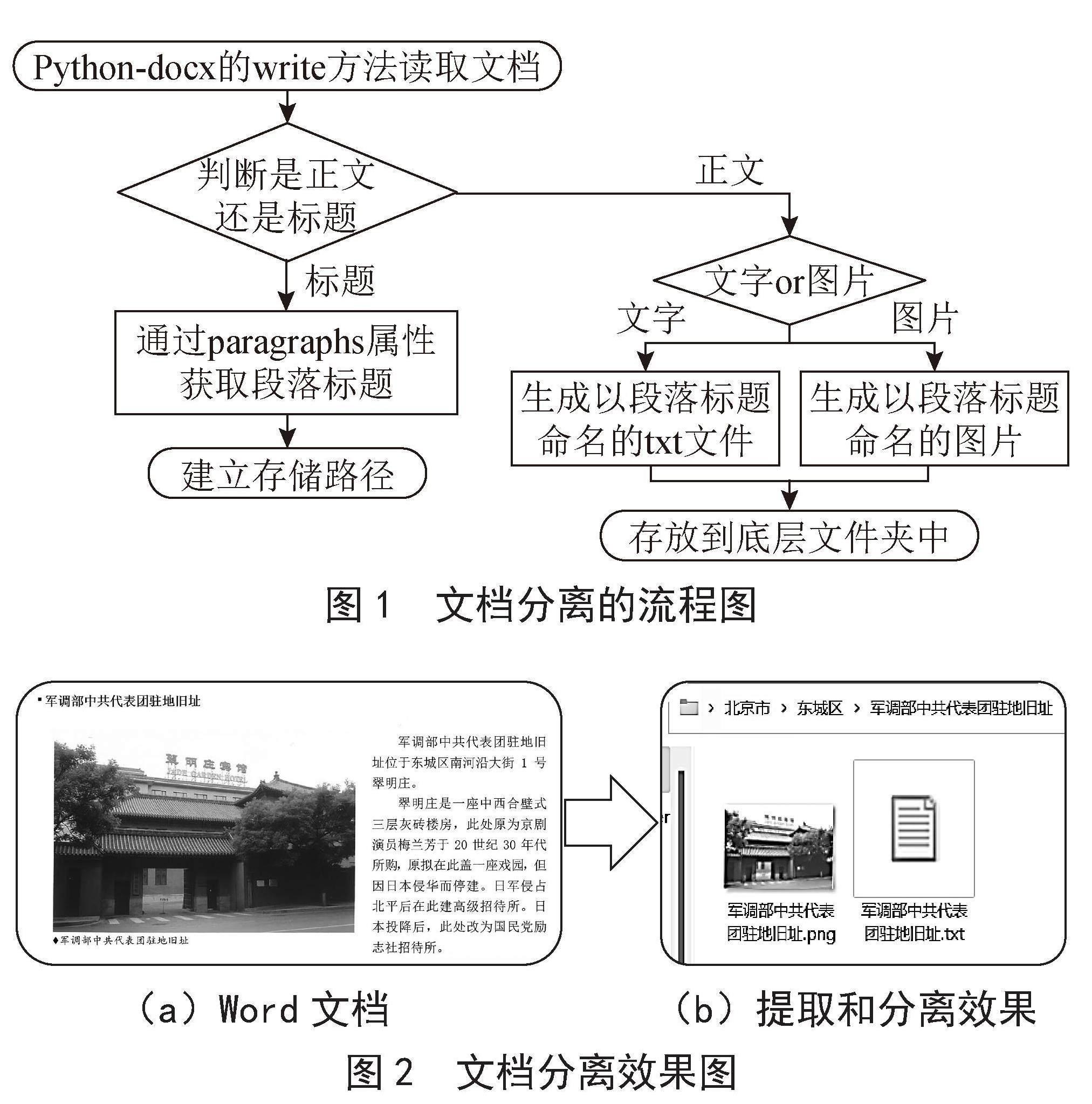
Python是一种强大的编程语言,可用于各种数据处理和文档抽取任务,本文通过Python的Python-docx库的write方法来提取Word文档中的文本内容和图片内容。文档和图片分离的流程图如图1所示。
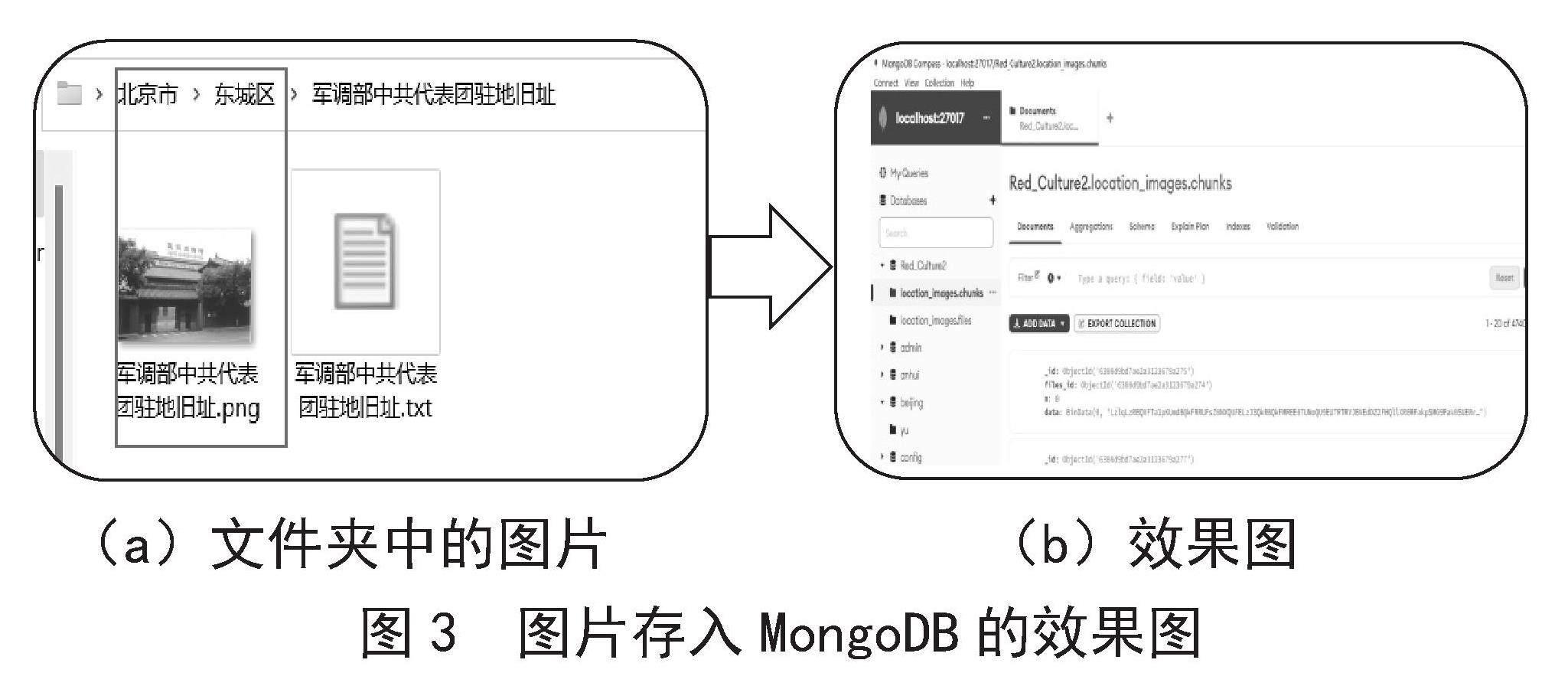
首先使用Python-docx库的write方法读取Word文档,判断读取到的文档内容,如果为段落标题,则调用paragraphs属性获取文檔的段落标题,并根据段落标题建立对应的文件夹。如果读取到docx的正文部分则将分别用write方法来提取文字和图片,并分别生成txt文件和图片(如图2(b)),以文档名称命名后写入生成的文件夹中。
图1 文档分离的流程图
(a)Word文档 (b)提取和分离效果
图2 文档分离效果图
其中图2(a)是未处理的图文混排Word文档,图2(b)则是经过Python提取和分离过后的效果,最底层的文件夹以提取的段落标题命名。
2 文字和图片的存储处理
2.1 图片存储
本文采用MongoDB数据库存储图片。存储图片的主要步骤为:
1)连接本地MongoDB数据库。在名为“Redculture”的数据库中创建一个名为“my_collection”的集合。具体代码为:
from pymongo import MongoClient as MC
MClient = MC('localhost', 27017) # 连接MongoDB
db = MClient['Redculture'] # 指定数据库
collection = db['my_collection']
2)遍历文件夹中的所有图片并插入到集合中。首先使用Pillow库打开图像,再将图像数据通过tobytes()方法转换为二进制文件,最后将二进制文件通过insert_one方法(insert one方法是在pymong库里,不需要定义可以直接使用)将二进制文件存入数据库。具体代码为:
for filename in os.listdir('/path/to/folder'):
if ilename.endswith('.jpg') or filename.endswith('.png'):with open(os.path.join('/path/to/folder', filename), 'rb') as f:
img = Image.open(f)
img_data = img.tobytes()
img_doc = {'filename': filename, 'data': img_data}
collection.insert_one(img_doc)
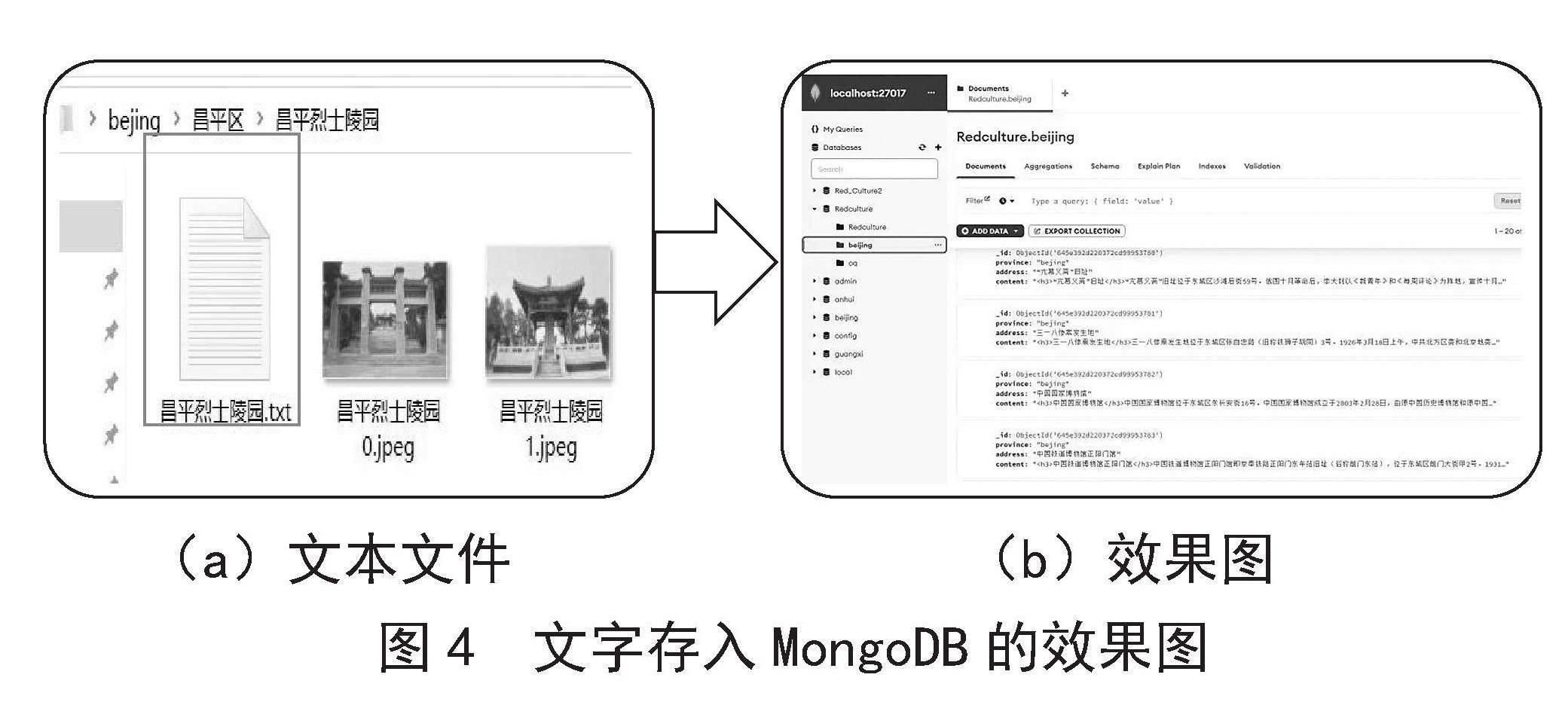
其中图3(a)是存放在文件夹中的图片,图3(b)为图片存放在MongoDB中的效果图,其中id是集合中文件的键(图片文件名),用于区分文件(记录)。默认情况下,_id字段的类型为ObjectID,是MongoDB的BSON类型之一。data则是存储图片的二进制数据,采用BinData形式,BinData提供了一种声明性方式来读取和写入结构化二进制数据
(a)文件夹中的图片 (b)效果图
图3 图片存入MongoDB的效果图
2.2 文字存储
文本数据存储到MongoDB需要完成以下2个步骤:
1)连接MongoDB数据库。连接MongoDB数据库并选择要存储数据的集合,使用PyMongo库连接到本地MongoDB实例,在名为“Redculture”的数据库中创建一个名为“beijing”的集合。具体代码为:
from pymongo import MongoClient as MC
client = MongoClient('mongodb://localhost:27017/')
db = client['Redculture ']
collection = db['beijing ']
2)打开文件夹并遍历文件。使用Python内置的os库打开文件夹,并使用os.listdir()函数列出文件夹中的所有文件,再使用内置的open()方法打开以txt为后缀的文件并读取内容,最后使用read()方法将读取的内容通过insert_one()方法存入到MongoDB数据库中。具体代码为:
fileList = 'C:/Users/winner/Desktop/bejing/'
for filelists in os.listdir(fileList):
for filelistslistinos.listdir(fileList + filelists):
for text_listinos.listdir(fileList + filelists + '/' + filelistslist):
if text_list.split('.')[1] != 'txt':
break
else:
dataSource = fileList + filelists + '/' + filelistslist + '/' +text_list
province = 'bejing'
with open(dataSource, 'r', encoding='utf-8') as f_text:
title_h3 = '
' + text_list.split('.')[0] + '
dataLines = f_text.read()
date_insert =dataLines.replace('\n', '')
collection.insert_one({'province': province, 'address': text_list.split('.')[0], 'content': title_h3+date_insert})
其中图4(a)是存放在文件夹中的文本文件,图4(b)是文本存入MongoDB的效果图。其中id是集合中文件的键(文本文件名),用于区分文件(记录)。默认情况下,_id字段的类型为ObjectID,是MongoDB的BSON类型之一。Content用于存储文本提取出来的文本内容。
(a)文本文件 (b)效果图
图4 文字存入MongoDB的效果图
3 为人物和事件实体绑定百度百科的链接
3.1 对txt文本进行分词操作以获取实体
提取文档中的人名和历史事件实体,是实现中国革命历史知识图谱必不可少的就环节,由于近代战争中的历史人物和事件,在百度百科中都有相关词条,因此本文将采用将实体名链接到百度百科词条的方式,来实现实体查询的信息共享。
我们首先使用open函数读取一个txt文件,然后遍历内容找到以“起义”“革命”和“运动”结尾的一段文字,这样可以找到存在历史事件的一段文字,后期再手动筛选其中的历史事件。
接下来使用Python中的pyltp库和shutil库,实现对人名和地名的分词,pyltp是一个用于自然语言处理的Python库,它是LTP(Language Technology Platform)的Python接口,支持多种自然语言处理任务,如分词、词性标注、命名实体识别等。shutil是Python中的一个文件操作库,可以用于复制、移动、重命名和刪除文件或目录等操作。
1)连接pyltp分词模型:
# pyltp模型目录的路径
LTP_DATA_DIR = '/path/to/ltp_data_v3.4.0'
# 分词模型路径,模型名称为`cws.model`
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model')
# 初始化实例
segmentor.load(cws_model_path)
# 加载模型
segmentor = Segmentor()
2)遍历文件夹中的所有文本文件,对每个文件进行分词处理并保存到新文件:
# 遍历文件夹中的所有文本文件
for filename in os.listdir('/path/to/folder'):
if filename.endswith('.txt'):
# 读取文件内容
with open(os.path.join('/path/to/folder', filename), 'r', encoding='utf-8') as f:
text = f.read()
# 进行分词处理
words = segmentor.segment(text)
# 将分词结果转换为字符串
result = ' '.join(words)
# 保存分词结果到新文件
new_filename = os.path.splitext(filename)[0] + '_seg.txt'
with open(os.path.join('/path/to/output/folder', new_filename), 'w', encoding='utf-8') as f:
f.write(result)
需要注意的是,在实际应用中,我们还可以对分词结果进行过滤、去重、归一化等操作,以便更好地提取文本信息和洞察数据趋势。图5(a)是存储在txt中未分词的文字,结合Python中的pyltp库和shutil库实现图5(b)的效果,后期再手工过滤筛选出其中正确的人名。
(a)未分词的txt文档 (b)提取出人名的文档
分词效果图
图5 txt文本进行分词效果图
3.2 为人物和事件实体绑定百度百科的链接
百度百科作为一个维基百科式的平台,是中国最大的中文百科全书之一,其收录了人物、历史事件、地理位置、生物、科技、文化艺术等领域全面、权威、准确的知识。因此我们打算将人物和事件实体与百度百科链接相绑定,首先我们通过Python代码读取想要采集的人名和事件名称,利用爬虫技术获取到百度百科链接的URL,将实体的URL链接与实体进行配对,最后将抓取到的链接存入Excel文件中去,以便后期的数据清洗。
3.2.1 爬取实体的百度百科链接URL
近年来互联网的发展速度是迅猛的,在庞大的网络信息中,用户们可以通过一定的手段获取想要的知识,但是由于网络上的信息众多,想要获取目标信息的难度却很大,因此人们就需要一个工具。因此就有了搜索引擎,而网络爬虫正是搜索引擎的核心组成部分。
网络爬虫能够对网页进行自动获取。在本次数据处理过程中,我们需要找到人名和历史事件的百度链接,面对如此庞大的数据工作量,我们决定使用网络爬虫技术,来进行数据收集。为此我们采用谷歌的Chromedriver搭配Python代码来实现百度链接抓取。利用运行已经编辑好的代码,对已经提取出来的人名和事件(图6(a))进行读取。通过在百度百科中搜索读取到的人名或事件名,将其链接进行抓取并存入Excel文件中,后期再经过人工筛查,将无效数据删除,进行数据清洗,从而得到一组干净的数据,图6(b)是通过Python代码抓取百度百科链接并存入Excel文件的效果图。
(a)取出来的实体名 (b)存入Excel文件的效果图
图6 数据收集、清洗样例
3.2.2 设置人物和事件实体的链接
经过上一步的数据清洗后,我们得到了一组干净的数据。本文选择使用MongoDB数据库进行数据存储,首先通过网络爬虫得到带有实体链接的Excel文件,如图6所示,将Excel文件的链接写回txt文本中,最后把带有链接的实体的文本数据存入MongoDB数据库中。通过这种存储方式可以提高数据管理和查询效率,方便数据存储和共享,提高数据安全性和可靠性。
要实现Excel文件存入MongoDB数据库,首先我们需要调用Python的pandas库来读取Excel文件里的内容,再通过pymongo库来连接MongoDB数据库,再依次将文件里的实体及链接存入到MongoDB数据库中。
1)连接MongoDB数据库:
# 连接MongoDB数据库
client = pymongo.MongoClient('localhost', 27017)
db = client['Redculture']
# 文件所在路徑
collection = db["cq"]#集合名(navicat里面生成的集合名)
2)读取txt文件并将内容存入到集合中:
# 读取Excel文件
data = pd.read_excel('实体链接.xlsx')
# 将数据插入到MongoDB中
for index, row in data.iterrows():
name = row['姓名']
link = row['链接']
collection.insert_one({'姓名': name, '链接': link})
需要注意的是,在存储过程中需要手动将client值的设置改为需要存入的数据库名称,不然会造成存入数据混乱、后期管理不方便的问题。最终得到的红色文化有关数据库的可视化局部效果图,如图7所示。
4 结 论
Python语言语法简单清晰,具备丰富的标准库和第三方库,功能强大且免费使用,利用Python语言进行数据分析处理十分灵活和高效。本文主要是利用Python语言对中国革命历史知识文化数据进行处理,主要可分为3个步骤:提取文档中的文字和图片,对文字和图片进行存储处理,为人物和事件实体绑定百度百科的链接并将最终数据存入MongoDB数据库。文章通过实例讲解了中国革命历史文化知识数据处理过程中各个步骤的可行性,最终得到红色文化有关数据库的可视化局部效果图。希望能为类似的技术研究和功能开发提供借鉴。
参考文献:
[1] 沈成飞,连文妹.论红色文化的内涵、特征及其当代价值 [J].教学与研究,2018(1):97-104.
[2] 周宿峰. 红色文化基本问题研究 [D].长春:吉林大学,2014.
[3] 朱志强,林岚,杨书,等.国内红色旅游研究发展知识图谱——基于CiteSpace的计量分析 [J].旅游论坛,2016,9(6):32-39.
[4] XIE R B,LIU Z Y,JIA J,et al.Representation Learning of Knowledge Graphs with Entity Descriptions [C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence.Phoenix:AAAI Press,2016:2659-2665.
[5] RATNAPARKHI A.A Maximum Entropy Model for Part-Of-Speech Tagging [EB/OL].[2023-05-20].http://www.delph-in.net/courses/07/nlp/Ratnaparkhi%3a96.pdf.
[6] MCCALLUM A,FREITAG D,PEREIRA F C N.Maximum Entropy Markov Models for Information Extraction and Segmentation [C]//Proceedings of the Seventeenth International Conference on Machine Learning.San Francisco:Morgan Kaufmann Publishers Inc,2000,17:591-598.
[7] AUGENSTEIN I,RUDER S,S?GAARD A. Multi-task Learning of Pairwise Sequence Classification Tasks Over Disparate Label Spaces [J/OL].arXiv:1802.09913 [cs.CL].[2023-05-20].https://arxiv.org/abs/1802.09913.
[8] BERYOZKIN G ,DRORI Y,GILON O,et al. A Joint Named-Entity Recognizer for Heterogeneous Tag-setsUsing a Tag Hierarchy [J/OL].arXiv:1905.09135 [cs.CL].[2023-05-16].https://arxiv.org/abs/1905.09135v1.
[9] HUANG Z H,XU WEI,YU KAI. Bidirectional LSTM-CRF Models for Sequence Tagging [J/OL].arXiv:1508.01991 [cs.CL].[2023-05-16].https://arxiv.org/abs/1508.01991.
[10] MAO MINGYI,WU CHEN,ZHONG YIXIN,et al. BERT named entity recognition model with self-attention mechanism [J].CAAI Transactions on Intelligent Systems,2020,15(4):772–779.
[11] YANG H Q. BERT Meets Chinese Word Segmentation [J/OL].arXiv:1909.09292 [cs.CL].[2023-05-16].https://doi.org/10.48550/arXiv.1909.09292.
作者简介:景文会(2002—),女,仡佬族,贵州铜
仁人,本科在读,主要研究方向:自然语言处理;刘伟(2001—),男,土家族,贵州铜仁人,本科在读,主要研究方向:自然语言处理;黄炳程(2001—),男,壮族,广西钦州人,本科在读,主要研究方向:自然语言处理;覃兴刚(2001—),男,壮族,广西兴业人,本科在读,主要研究方向:自然语言处理;任佳祺(2002—),男,汉族,山东威海人,本科在读,主要研究方向:自然语言处理。
猜你喜欢
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
当代化工研究(2016年9期)2016-03-20 16:22:13
西华师范大学学报(自然科学版)(2015年3期)2015-02-27 15:31:22
测绘科学与工程(2013年3期)2013-03-11 15:07:36
测绘科学与工程(2013年3期)2013-03-11 15:07:35
