
基于深度强化学习的数据探索性会话自动生成
2024-06-01 19:03:40汪洋
现代信息科技 2024年4期

收稿日期:2023-07-08
DOI:10.19850/j.cnki.2096-4706.2024.04.014
摘 要:探索性数据分析(EDA)是一种数据分析方法,旨在通过对数据集进行可视化和摘要统计等方式揭示数据的结构、模式和关系。数据分析人员可通过操作交互式地探索不熟悉的数据集,并为用户提供先导性见解。深度强化学习(DRL)已被证明可以用来解决众多难以解决的人工智能挑战,可尝试将EDA与DRL进行结合,提出了一个名为AEDAS的系统。该系统将EDA建模为一个控制决策问题,从而结合一个新颖的DRL架构来自动生成有说服力的探索性会话,并以EDA笔记本的形式呈现。实验表明,该系统生成的EDA笔记本,可以使用户获得切实有效的先导性见解。
关键词:探索性数据分析;深度强化学习框架;控制性问题;探索性会话;EDA笔记本
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2024)04-0066-09
Auto-generation of Data Exploratory Sessions Based on Deep Reinforcement Learning
WANG Yang
(Tobacco Company in Xinjiang Uyghur Autonomous Region, Urumqi 830026, China)
Abstract: Exploratory Data Analysis (EDA) is a data analysis method aimed at revealing the structure, patterns, and relationships in a dataset through visualization and summary statistics. Data analysts can interactively explore unfamiliar datasets through operations and provide users with preliminary insights. Deep Reinforcement Learning (DRL) has been proven to address many difficult Artificial Intelligence challenges. One can attempts to combine the EDA and DRL, proposing a system called AEDAS. The system models EDA as a control decision problem, combining a novel DRL architecture to automatically generate the persuasive exploratory sessions and present them in the form of EDA notebooks. Experiments show that the EDA notebooks generated by the system can provide users with tangible and effective preliminary insights.
Keywords: exploratory data analysis; Deep Reinforcement Learning architecture; control problem; exploratory sessions; EDA notebook
0 引 言
探索性數据分析(EDA)[1-3]是数据科学中不可或缺的技术,它有助于数据分析人员更好地了解数据的性质和特点。然而,EDA过程烦琐,为了提高效率,许多系统被设计出来促进这一过程。这些系统包括简化的可视化界面,如Northstar[4]和Tableau[5],数据驱动工具[6],即展现数据立方体中感兴趣子部件的工具,以及数据可视化和推荐下一个探索步骤的系统[7]和相关数据集[8]。这些能够大大提高EDA的效率和准确性,为数据分析人员提供更好的工作体验。
国内已经出现了一些成熟的系统,可以帮助数据分析人员开展EDA工作。例如,阿里云大数据可视化分析平台MaxCompute可以提供丰富的可视化功能和数据挖掘技术,支持用户进行数据的探索性分析。此外,国内的BI软件如FineBI、DataV等也提供了强大的数据可视化功能,支持数据分析人员进行EDA工作。还有像DataCastle等数据科学竞赛平台也提供了丰富的数据集和EDA笔记本。对于数据分析人员来说,查看EDA笔记本——即由其他数据分析人员经过策划组织的具有说明性的探索性会话[9,10],是更为常用的方法。这些笔记本通常以笔记本界面呈现,允许用户记录和共享一系列编程操作及结果,帮助数据科学家快速开始EDA工作。
现有的EDA笔记本通常可在数据科学(DS)或代码共享平台(如Kaggle和GitHub)上使用,其中,已经在特定数据集(也托管在平台上)上执行 EDA 的用户将其汇总并整理成一个可以信赖的EDA笔记本,以与社区共享。之后,当其他数据科学家开始研究相同数据集时,他们可先参考其随附的 EDA 笔记本并跟踪其中的探索步骤,了解其他用户如何处理该数据集并获得之前已有的见解,以便在以后自己进行EDA时有进一步的研究。然而,现有的EDA笔记本并不总是可用,例如在数据集是新的、保密的或尚未在特定数据科学平台上审查过的情况下。
为了解决这一问题,本文提出了一种名为AEDAS的系统,用于自动生成EDA笔记本。AEDAS接受关系数据集作为输入,并自动产生和执行一个有意义的、可靠的探索性会话,即一个EDA操作序列。操作结果将在笔记本界面上呈现给用户,帮助用户了解数据集的关键点和重要特征。因此,即使没有现有的EDA笔记本,AEDAS也能为用户提供初步的见解并协助进行更深入的探索。
为了使EDA笔记本具有价值,本文指出了两个关键因素。首先,EDA笔记本应该全面涵盖数据集的各个方面,以便用户能够深入了解其各个属性。其次,笔记本应该具有连贯性和易于理解性,即EDA操作需要按照合理的顺序进行,后续操作在逻辑上与之相关。AEDAS的设计充分考虑了这些目标做出以下贡献:
1)基于马尔可夫决策过程(Markov Decision Process, MDP)模型建立了一个控制问题。同时,设计了一个奖励信号,该信号旨在确保笔记本中的每个EDA操作可以揭示数据的新信息或潜在关系,从而激发用户的兴趣,同时整个操作序列应具备多样性、连贯性并与输入数据集的相关性。因此,在生成EDA笔记本时,需要确定一系列合适的操作和决策,以在满足这些要求的同时,最大化奖励信号。
2)采用了深度强化学习(DRL)框架,专门针对庞大且离散的行动空间进行设计和处理,以实现对MDP涉及的大量状态和行动空间的优化
3)AEDAS生成的EDA笔记本具有较强的洞见性和易于理解性,为用户提供了关于数据集的实际初步认识。
1 相关工作
数据游览和投影追踪是指发现有分析价值的数据“视图”,并以连贯的序列呈现,以达到数据探索的目的。在烟草行业中,EDA的应用可以帮助业务人员更好地分析烟草制品的性质和特点。例如,烟草营销业务数据集包含各种类型的属性,包括品牌、规格、销量、业态等。业务人员可以使用各种EDA工具来探索这些属性之间的关系,并发现分析价值的数据“视图”。
本文的EDA笔记本可以被看作是数据“游览”经验的延伸,但具体的实现在两个参数上有根本的不同:
1)本文假设数据集包含异构(不一定是数字)类型的属性,包括文本和分类数据。
2)本文更着重于常用的EDA操作,例如过滤、分组和聚合(具有可视化扩展,连接等)。
数据驱动生成分析价值的视图是指通过不同类型的操作从输入数据集中自动生成分析价值的视图。在烟草行业中,这个概念可以被应用于探索烟草相关的数据集,以发现潜在的可利用信息,如烟草品牌、销售渠道等。AEDAS在这个领域也有所突破。AEDAS依赖于一个兴趣度的概念,并使用额外的手段来产生一个可以信赖的操作序列。这些手段包括复合奖励信号和有效的、新颖的DRL学习方案,以进行对整个操作序列的优化。在烟草行业中,这些手段可以帮助业务人员更好地理解烟草数据集[11-13],并探索其中的潜在关联和趋势,例如特定品牌的销售趋势、不同渠道的销售额等。
交互式EDA推荐系统是指在进行探索性数据分析的过程中,为用户推荐下一步的EDA建议。这些建议可以通过数据驱动手段或者外部手段得到,例如EDA操作日志[14],以及来自用户的实时反馈[15]。在烟草行业中,交互式EDA推荐系统可以帮助业务人员更快地了解烟草数据集,并找到潜在的可利用信息,例如特定品牌的销售趋势、不同渠道的销售额等。
综上所述,交互式EDA推荐系统和其他协助EDA的工作在烟草行业中具有重要意义。它们为业务人员提供了更快速、更准确的EDA分析方法,并帮助他们更好地理解和探索煙草数据集。同时,它们还为业务人员提供了更多的工具和资源,以便更好地进行EDA分析。
2 系统流程
简而言之,AEDAS的工作方式如下。首先,用户向系统上传一个表格数据集,然后被提示选择其最感兴趣的一组关键属性,接下来,一个EDA控制问题的实例(即一个EDA环境和一个目标函数)将根据用户的数据集和重点属性被创建。
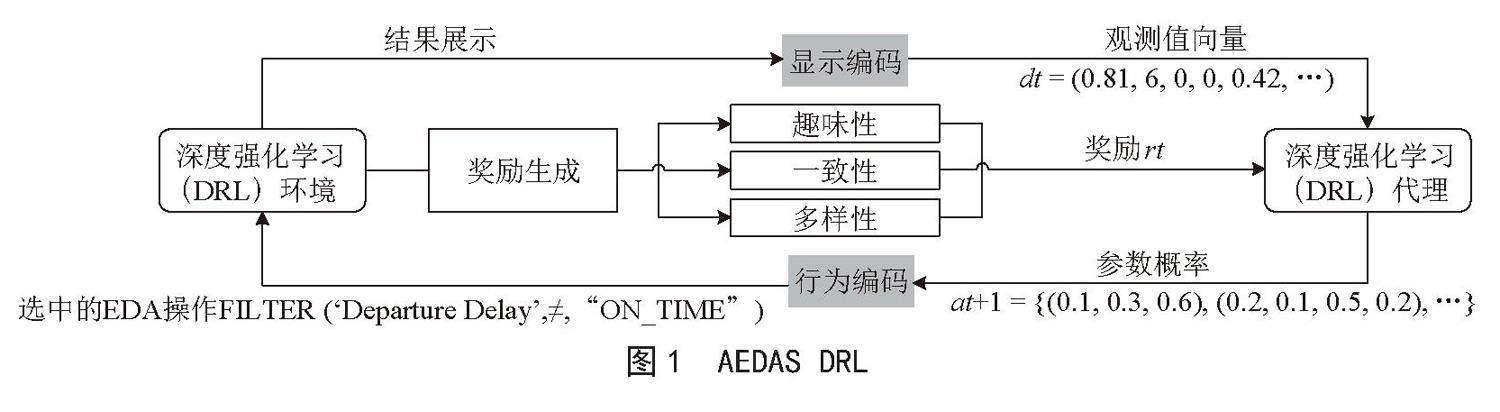
本文的EDA环境目前支持过滤、分组和聚合操作,也可以扩展到可视化和连接操作。如图1所示,采用DRL学习方案,通过DRL代理的神经网络以进行权重的随机初始化。接着,代理通过EDA环境与输入数据集进行自我交互,对数据集进行“训练”。该环境(见图1)允许代理采用EDA操作接收观察结果得到一个总结其结果的向量,以及一个由目标函数(见第3.2节)得出的正/负奖励值。DRL代理的目标是,通过与环境的重复互动,学习如何执行N个(预定义的)EDA操作序列,以获得最大的累积奖励。
3 EDA控制问题
接下来,本文解释如何使用MDP模型将EDA塑造成一个控制问题并描述奖励信号。
3.1 用于EDA的MDP模型
通常,在EDA中,用户检查一个数据集D=
本文用一个偶发的MDP来模拟EDA过程,它由一组可能的状态和一组可能的动作组成。直观地说,在本文的案例中,行动集是所有可能的(和支持的)EDA操作的集合,而状态集对应于其结果显示。在单一的情节中,代理通过执行预定数量的N个行动来探索一个特定的数据集D。在每个步骤中,代理获得描述其在EDA会话中的当前状态的观察向量,被要求选择一个行动。根据所选择的行动,代理被授予负面/正面的奖励,然后过渡到一个新的状态。整个事件的效用被定义为累积奖励,由当前事件中的行动获得。
接下来,本文将解释AEDAS模型如何表示行动和状态观测并介绍奖励信号。EDA行动空间。本文的模型允许组成参数化的EDA操作,其中代理先选择操作类型,再选择适当的参数。每个这样的操作都需要一些输入参数,并在时间t对当前显示的dt-1(即t-1时最后执行的操作的结果屏幕)进行操作。然后它输出一个相应的新的结果显示dt。由于AEDAS主要是一个概念验证,所以本文仅使用一组有限的分析操作,并在今后的工作中将加以扩展,其中包括以下EDA操作:
1)FILTER(attr,op,term),用来选择符合标准的数据图集。它接受一个属性,一个比较运算符(例如=,≥,包含符等),和一个数字/文本术语,并产生一个代表相应的数据子集的新显示。
2)GROUP(g_attr,agg_func,agg_attr)用来对数据进行分组和聚合。它包含一个要被分组的单一属性,聚合函数(例如SUM,MAX,COUNT,AVG等)和另一个要使用聚合函数的属性。
3)BACK(),允许代理回溯到之前的显示(即在t-1执行的行动的结果显示),以便采取另一种探索路径。
形式上,行动空间的定义如下。令OP是行动类型的集合,OP = {FILTER,GROUP,BACK}。每个动作类型o ∈ OP有一个相应的参数集 ,每个参数p有一个有限的值域V(p)。一个动作是一个元组(o,v),其中o ∈ OP,v是参数po的有效赋值。这样整体的动作空间被定义为A = Uo∈OPUv∈V(po){(o,v)}。以类似的方式,本文的模型可以用其他操作类型进行扩展,如投影、可视化、连接等。
行动空间的优点是:1)动作是原子性的,相对容易组成(例如,没有语法上的困难)。2)复杂的显示是逐步形成的(例如,首先采用FILTER操作,然后按某一列进行GROUP,再按另一列进行聚合等),而不像SQL查询为“一次性”组成。由于每个原子操作都会获得自己的奖励(见3.2节),因此后者允许对代理进行细粒度的控制。
状态观察向量。MDP模型的第二部分是定义正在进行的事件中达到一个新的状态时,应该向代理提供的信息。本文使用一个简单的向量表示,基于获得的先前结果显示中提取的关键描述性特征。当前的结果显示dt被编码为一个数字向量,表示为 ,它代表了dt的一个紧凑的、具有以下特征的结构性总结。1)每个属性的三个描述性特征:其值的熵、不同值的数量和空值的数量。2)每个属性的一个特征,说明它目前是否被分组/聚集,以及三个全局特征,存储组的数量和组的大小平均值和方差。为了同时记录当前显示产生的更广泛的背景,本文将会话中最近三次操作的显示向量串联到dt,即最后的观察向量由 和 组成,与 串联(如果dt-1和dt-2不存在,则提供一个零的向量代替)。
3.2 奖励信号
如第1节所述,数据驱动系统[16]使用趣味性措施来评估分析操作的效用,并向用户展示获得最高分数的操作。本文在AEDAS中也采用趣味性措施来评估代理执行的EDA操作,但使用了两个额外的信号,即多样性和连贯性,以确保整个操作序列是可以信赖和易于理解的。单个EDA操作的奖励信号是以下元素的加权和:
1)趣味性奖励。本文的系统实现了两个不同的兴趣度信号,一个用于分组操作,一个用于过滤操作。
分组操作的趣味性奖励:衡量标准遵循类似的简洁性衡量标准[9,17],这些标准认为涵盖许多图元的紧凑的分组结果既具有信息量又易于理解。衡量标准考虑了组的数量、当前被分组的属性数量以及基础图元的数量,分别表示为g、a、r,奖励信号由h1 ( g · a) / h2 (r)给出,其中h1 ( · )和h2 ( · )是归一化的sigmoid函数,具有预定的宽度和中心。
过滤操作的趣味性奖励:为奖励过滤操作,本文遵循文献中常见的衡量标准,将趣味性奖励偏向于那些结果显示dt明显偏离先前显示dt-1的过滤操作。为了量化这种偏差,使用Kullback-Leibler(KL),即KL散度作为度量指标,它衡量了一个概率能力分布与另一个概率能力分布的不同。在dt没有分组的情况下,本文定义一个属性的价值概率分布 ,A ∈ Attr是其值的相对频率(即对于dt中属性A的每个值ev,p (v)是随机选择v的概率)。趣味性奖励定义为: ,其中,sigmoid h ( · )被用于获得更显著的数值差异。在dt被分组的情况下,KL散度只在当前聚合的属性上进行比较(相较于上面的在所有属性上进行比较)。
2)多样性奖励。为鼓励代理选择诱发新的观察结果的行动,并显示与迄今所检查的数据不同的部分。通过进一步利用每个结果显示的数字向量表示(),即通过计算观察向量 和之前所有显示的向量之间的最小欧几里得距离。
3)连贯性/一致性奖励。依靠一个外部分类器,以确定一个给定的EDA操作在笔记本的某一点上是否是连贯的。本文的分类器是基于弱监督学习的,使用Snorkel [17]从一组启发式分类规则中构建分类模型。这种解决方案有以下好处:克服缺乏包含注释EDA操作的训练数据的问题;在需要时,根据具体的模式和用户给定的焦点属性集,轻松地对分类器进行微调。
本文的分类器中的每个分类规则都将EDA操作的子序列q1,q2,…,qt及其结果显示作为输入,并检查输出操作qt前面的操作中是否连贯。本文使用两种类型的规则:
1)一般规则——考虑操作序列的一般属性。例如,“对四个以上的属性进行分组是不连贯的”,“对一个连续的数字属性进行分组是不连贯的”。这种规则适用于所有的输入数据集。
2)数据相关规则——为输入数据集的语义和用户预定的焦点属性编写更多的规则(有选择性地)。本文在第5.1节中,详细介绍了实验中使用的规则类型。
4 深度强化学习(DRL)代理架构
这部分首先解释对EDA优化MDP模型的困难程度,以及為什么DRL是解决它的合理方法。然后,讨论了还需要克服的挑战,并提出了针对这个问题的DRL架构。
为什么使用DRL解决EDA控制问题?优化本文的 EDA模型具有挑战性,主要有两个原因:
1)MDP模型是指数级(相对于输入数据集)且高维的。因为状态的数量与输入数据集上任何可能的探索性操作的所有中间结果的数量相一致。因此,该模型不能被完全具体化。
2)奖励信号是复合的、不可分的,并且是在N个连续步骤中累积的。这样的设置使得分析性优化(如线性编程、策略迭代)难以采用[18],经典的强化学习解决方法[19]也难以采用。而DRL已经被证明对解决高维复杂控制问题非常有用。
但由于本文的MDP模型,不仅状态的数量很大,而且行动空间也是参数化的,非常大,而且是离散的。即使在本文的原型环境中,只支持过滤、分组和聚合操作,每个点上可能的独特操作的数量也超过100k。所以现成的DRL解决方案对于EDA问题来说是低效的。正如本文在第5.4节中证实的那样,当使用现有的DRL架构时,代理的学习过程会非常缓慢地收敛到一个局部的最大值,离最佳状态很远。
解决方案概述。本文采用了一种新颖的解决方案,既减少了网络的规模,又促进了有效的探索/开发。该解决方案可以很容易地注入现成的DRL架构和算法(如DQN、Advantage Actor-Critic等)中。它包括三个部分:
1)一个“两倍输出”层结构,可有效地利用EDA行动空间的参数化性质,允许代理选择EDA操作类型和每个参数的值。
2)一种专门的“分档”方法,它通过进一步减少了过滤器术语参数的值域,包括所有可用的数据集标记。
3)一种开发/探索策略,利用所获得的经验,选择在每个状态下采用的正确行动,同时进行智能探索选择。接下来本文将对这些组成部分进行详细介绍。
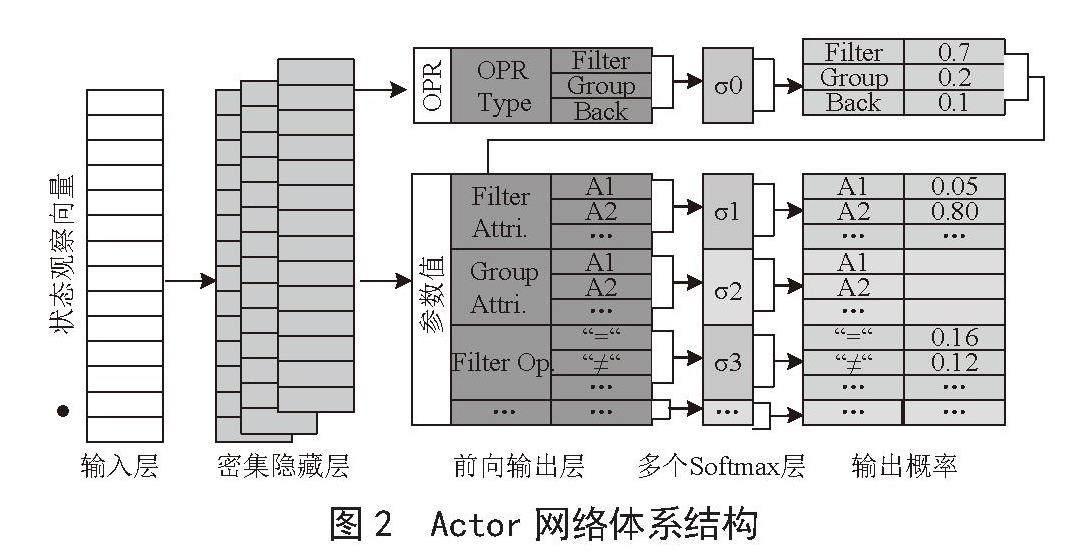
双层输出层结构。图2提供了本文的网络结构的说明。
图2 Actor网络体系结构
如图所示,状态观察向量首先经过几个具有ReLU激活函数的密集隐藏层(这是DRL架构的常见做法[20])。之后经过两个新的子层,输出预测概率。本文设计的这两个新层来代替标准的、非常大的Softmax输出层是为了减少网络的大小。细节如下:
1)预/前向输出层。该层(图2中为青色)包含每个EDA操作类型的一个节点,以及每个参数值的一个节点。每个节点都与前一个隐藏层相连。预输出层的大小等于参数值域的大小和操作类型的数量。
2)多重Softmax计算层。在DRL结构中,通常在最后一个隐藏层的输出上应用Softmax计算,以便为每个不同的动作产生一个概率值(总和为1)。当动作空间很大时,不仅计算时间长,而且学习过程也很慢,效果也不好(如第5.4节中所述)。因此,本文使用了一个新的多重Softmax计算层,其中Softmax计算被分割开来,对每个操作类型和参数单独执行。也就是说,Softmax段σOP只与对应于操作类型的预输出节点相连,然后为每个参数p定义一个单独的段OP,只与对应于V(p)值的预输出节点相连。
Multi-Softmax层的工作原理如图2所示。首先,段σo用于生成操作类型OP的概率分布,从中抽取所选操作类型o ∈ OP(例如,在图2中描述的工作流程示例中,获得最高概率的所选操作是“过滤器”)。接下来,通过只激活相应的片段σp ? p ∈ Po来实例化o的参数(见图2中Multi-Softmax层的粉色部分)。
高效地选择数据集值的过滤器“term”参数。即使选择只限于出现在当前结果显示中的标记物,过滤操作的参数项也可能过大。所以,为了避免在预输出层中为每个数据集标记设置专门的节点,本文使用了一个简单而有效的分档解决方案,根据每个标记在当前显示中出现的频率,将单个标记(即数据集的值或其部分)映射到一个固定大小的B档阵列中。然后,代理不是选择一个特定的标记,而是选择一个频率范围b[i,j]。反过来,一个实际的token,其出现的频率在这个范围内,被均匀地随机抽样。
探索/开发策略。本文的结构有利于有效的探索策略,基于Boltzmann探索[21],其中,行动是根据Softmax层产生的输出概率分布进行采样。使用两层输出层允许代理对每个操作类型和参数做出独立的探索/利用决定,因为每个参数都有一个专门的Softmax层。这允许代理利用其经验(如果有的话)对一些参数进行探索,并对其他参数的值进行探索。另外,本文使用了熵正则化[22],它可以防止代理过早地收敛到局部最优。通过熵正则化,代理收到的奖励与策略的熵成正比。
5 实验结果
本文的实验旨在回答三个主要问题:1)用户能否通过被动检查自动生成的EDA笔记本获得实际见解?2)AEDAS生成的notebook与其他方式生成的notebook相比效果如何?3)DRL框架对于生成高质量的EDA笔记本是否是必要的?本文进行了两个互补的质量评估实验:人工评估(第5.2节),即参与者手动审查生成的EDA笔记本,以及EDA笔记本的自动基准(第5.3节),它将生成的笔记本与一组黄金标准的笔记本进行比较(该基准完全开源,并可在Aeda[23]中获得)。最后,本文进行了额外的实验(第5.4节),将AEDAS的收敛性与其他操作架构进行比较。
5.1 实验设置
数据集。本文使用了两个独立无关联的数据集,每个数据集都有不同的模式和应用领域:烟草销售和网络安全。选择这两个数据集是因为它们提供了比较和评估自动生成的笔记本的方法。接下来,本文将解释每个集合的特点和它们在实验中的作用。
烟草销售模拟数据集。本文使用了一个模拟的数据集,烟草销售数据集。数据集属性包括烟草品类、单期销量、同期销量、销量排名、單品类销量占比等。
网络安全数据集。这个数据集由4个(完全不相关的)子数据集组成,这些数据集来自4个不同的网络分析挑战[24],在这些挑战中,参与者需要探索每个数据集,以揭示数据集中传达的特定的潜在网络攻击。
基准。本文将AEDAS笔记本的质量与4种不同类型的基准笔记本进行了比较。首先,由人类EDA过程产生的两种不同类型的笔记本。
1)“gold-standard”:基于真实的EDA笔记本/教程。由于笔记本和教程包含文字说明以及AEDAS尚未支持的EDA操作,所以本文使用相同的过滤、分组和聚合操作创建了等效的EDA笔记本,以促进所有基线之间平衡的质量比较。
2)“EDA-Traces”:由有经验的分析员从EDA会议的记录中产生的笔记本。对于每一个记录下来的会话,本文都会生成一个相应的EDA笔记本。这些痕迹主要包含AEDAS支持的相同EDA操作,因此几乎不需要进行整理。每个数据集的所有探索性会话都是根据相同的探索目标进行。
3)“仅有趣味性”:仅根据趣味性评估而自动生成的笔记本。为了研究复合奖励信号的必要性,本文使用只对EDA操作的趣味性进行优化的基准。本文使用两种不同的方法来优化整个会话的趣味性:(3A)Interestingness-Only Greedy(Greedy-IO)在每一步计算所有可能操作的趣味性得分,并贪婪地选择获得最大趣味性的操作;(3B)Interestingness-Only AEDAS(ATN-IO)Only 使用第4节所述的DRL架构,但目标是仅对趣味性信号进行优化。
4)“备选优化架构”:使用不同优化架构/技术自动生成的笔记本。为了研究DRL,特别是本文在第4节中描述的架构地必要性,本文对复合奖励信号(有三个组成部分)使用三种替代优化技术。首先,使用了与AEDAS架构不同的两种DRL架构:(4A)现成的DRL(OTS-DRL)使用一个标准的DRL架构,其输出层为Softmax,包含每个不同EDA操作的节点。为了特别考察本文的双重输出层的必要性,本文还使用了(4B)OTS-DRL With Binning(OTS-DRL-B),它具有与(4A)中相同的标准DRL架构,但它没有采用明确的滤波器,而是使用了第4节中描述的基于频率的分选解决方案。最后,为了检验DRL对本文的问题是否真的有效,本文使用了(4A)复合奖励贪婪法(Greedy-CR),它不使用DRL,而是使用贪婪的、非学习的策略来选择引起最高奖励的操作。
代码实现。本文采用Python 3实现了EDA环境,并使用Pandas库执行EDA操作。针对烟草销售数据集,本文将烟草品类、同期销量单品类销量占比信息作为重点属性,设置了相应的权重值以获得奖励成分之间的学习平衡。同时,为了保持一致性,本文还对网络安全数据集进行了探索,将焦点属性设置为“源IP”和“目标IP”,以揭示潜在的网络攻击。
该神经网络代理使用了目前DRL最先进的Asynchronous Actor Critic(A3C)[22],并以近似策略优化Proximal Policy Optimization(PPO)[25]来加强。本文的双重输出层被注入到 "Actor"网络中,取代了其Softmax输出层。这些算法和神经网络是在ChainerRL中实现的(一个常见的DRL Python库)。为了训练代理网络,本文使用了一台基于Intel Xeon CPU的服务器,包含24个内核和96 GB的内存。
5.2 定性的人为评估
定性评估。在对每本笔记本进行检查后,用户根据以下标准对其进行评分,评分标准从1(最低)到7(最高):1)信息性——笔记本的信息量有多大?它能捕捉到数据集的亮点吗?2)可理解性——笔记本在多大程度上是可理解的和易于理解的?3)专业性——笔记本作者的专业水平如何?4)人类的等同性——笔记本与人类产生的会话有多大的相似性?图3显示了AEDAS和基线笔记本在每个标准下的平均得分。基线包括人工生成的Gold-Standard和EDA痕迹,以及每个类别中的代表自动生成的笔记本——Greedy-IO和OTS-DRL-B(如第5.3节所述,这些基线在各自的类别中表现优异)。使用配对T检验,每两个基线之间的分数差异被验证为具有统计学意义,P值远远低于0.000 01。
金标准的笔记本用虚线标出(误差限为±1个标准差),在所有的标准领域几乎获得了最高分(平均为6.8/7)。生成的笔记本中,替代性的自动生成方法Greedy-IO和OTS-DRL-B获得了最低的排名,平均得分是1.4/7和3.4/7。EDA痕迹生成的笔记本获得了4.3/7的平均分,但与金标准笔记本相比,分数上的巨大差异是由于EDA-traces笔记本并不是为了演示而产生的,而是为了让其他用户观看的。相比之下,AEDAS的笔记本获得了5.4/7的平均分,比EDA-traces笔记本好了不止一个等级。这是因为AEDAS是專门为生成连贯性和易懂的笔记本而设计的(使用复合奖励号)。
获得的见解的比较。图4显示了用户通过检查AEDAS生成的笔记本和上述基线所收集的见解的(平均)百分比。本文可以看到,AEDAS与用户在所有标准中的评分相对应,胜过其他方法。通过被动地检查AEDAS生成的笔记本,用户就成功地得出了平均46%的数据集相关见解。
图4 人为定性评估——从浏览EDA笔记本中收集的见解
5.3 自动化基准
用户研究表明,AEDAS明显优于通过其他方式生成的笔记本。然而,由于用户研究很难重现,本文接下来描述一个自动生成EDA笔记本的基准(称为A-EDA),它可以很容易地在其他场合重现,从而促进未来模型和方法的比较。A-EDA与其他生成模型的基准类似,根据笔记本与一组经过策划的真实笔记本的距离来评估其质量。作为基础事实,本文使用上述的金标准笔记本,它们在人类评估中获得了接近完美的分数。对于每个数据集,本文使用一组5~7个金标准笔记本。然后,本文用几个指标来评估生成的笔记本和金标准笔记本之间的距离,有不同程度的灵活性。
1)精度。该指标将EDA笔记本视为不同观点的集合(忽略它们的顺序),如果一个观点出现在黄金标准笔记本中,则算作“命中”,否则算作“未中”。它的计算方法是hits / (hits+misses)。
2~4)T-BLEU-1、T-BLEU-2、T-BLEU-3。这些度量是基于众所周知的BLEU [26]得分,用于比较图像说明中的句子和机器翻译(在本文的例子中,“句子”是笔记本中的视图序列)。T-BLEU比Precision更严格,因为它还考虑了每个视图在金标准集中的普遍性,以及它们的顺序,通过比较n大小的子序列(而不是单个视图)。本文在T-BLEU-1到T-BLEU-3中使用1到3的n。
5)EDA-Sim [7]。EDA-Sim也考虑了视图的顺序,但允许对其内容进行精细的比较(即,在上述措施中,几乎相同的视图被认为是“失误”,但EDA-Sim将评估它们为高度相似)。對于最终的EDA-Sim得分,本文将生成的笔记本与每一个金标准笔记本进行比较,并取其最大的EDA-Sim得分。
表1 总体A-EDA基准测试结果
Baseline Precision T-
BLEU-1 T-
BLEU-2 T-
BLEU-3 EDA-Sim
ATN-IO 0.10 0.10 0.05 0.03 0.22
Greedy-IO 0.12 0.11 0.07 0.04 0.23
OTS-DRL 0.26 0.16 0.12 0.06 0.23
Greedy-CR 0.27 0.21 0.16 0.07 0.23
OTS-DRL-B 0.33 0.24 0.21 0.16 0.27
EDA-Traces 0.45 0.30 0.27 0.22 0.40
AEDAS 0.49 0.51 0.38 0.36 0.49
实验结果。表1描述了所有基线的得分,是第5.1节中提到的两类实验数据集的平均得分。首先,可以看到A-EDA的分数与人类评估和收集的见解比较的总分数密切相关。所有替代的自动生成方法都获得了较低的分数,被EDA-traces notebooks超过,然后被AEDAS在上述每个评价指标上超过。接下来,检查所有替代自动生成基线的得分,本文可以得出以下结论:
1)忽略EDA操作的一致性和多样性的“仅感兴趣”基准获得最低得分——无论是使用简单的贪婪优化(Greedy-IO)还是使用DRL(ATN-IO)时。这意味着生成有用的EDA笔记本需要一个更详细的奖励信号,而不仅仅是数据驱动的趣味性得分。
2)事实上,基线4A、4B和4C(根据本文的复合奖励信号进行优化)获得了比仅有兴趣的基线更好的分数,即它们的表现仍然明显优于AEDAS。现成的DRL架构(OTS-DRL)与基于贪婪的优化(Greedy-CR)不相上下,但两者都被OTS-DRL-B超越,后者使用了本文基于频率的分选方案。然而,所有的替代性优化方案都明显优于AEDAS的表现。因此,DRL,特别是本文在AEDAS中使用的新型架构,对于生成有用的EDA笔记本非常有效。本文还从学习融合的角度得出了一个类似的结论,如下文第5.4节所述。
5.4 学习收敛性比较
本文将AEDAS的解决方案与其他优化架构(基线4A-4C)进行了比较,并通过图5展示了两个代表性数据集的平均情节奖励与AEDAS获得的训练步骤数之间的关系(其他数据集也有类似趋势)。由于Greedy-CR使用了非学习性的贪婪策略,它对训练步骤的数量无动于衷,因此在每张图中被描绘成虚线水平线。Greedy-CR获得的奖励比AEDAS低得多。基线OTS-DRL,对应于带有Softmax输出层的标准DRL架构,显示出较差的学习效果,因为它需要超过一百万个训练步骤才能稳定在次优奖励(接近0)。
图5 学习收敛性比较
OTS-DRL-B采用了与OTS-DRL相同的架构,并使用了基于频率的分选解决方案。与OTS-DRL相比,OTS-DRL-B的有效性更高,因为它能够在超过一百万步(在本文的服务器上为6~11小时)后收敛,并达到更高的重值。完整的AEDAS优于所有三个基线,它的收敛速度快了2~3倍,并且达到了明显更高的平均报酬。AEDAS的收敛是稳定的,无论探索的数据集如何,都能达到高回报,而其他基线的性能则各不相同。
6 结 论
本文提出了一个基于MDP模型和DRL架构的自动生成EDA笔记本的系统。该系统不仅可以生成一组有分析价值的数据观点,而且这些观点在一个连贯的叙述中显示了数据集的不同方面。实验结果表明,生成的笔记本质量高,用户可以通过检查它们来获得有价值的洞察力。然而,作为这一领域中的第一个系统,AEDAS还有一些局限性,需要在未来的工作中加以解决,例如扩大其支持的探索性操作集、促进个性化会话的生成,以及在不同的数据集中推广其学习过程。进一步开发可定制和更精细的EDA会话,以实现减少EDA中的人工努力的长期目标,可为烟草行业及其他领域提供更有效的数据分析和决策支持。
参考文献:
[1] 朱钰,张颖. 谈探索性数据分析 [J].统计教育,1997 (3):18-19.
[2] 张璇.探索性数据分析的方法在职工平均工资中的应用 [J].中国市场,2013(46):99-100.
[3] 彭红星,邹湘军,郭艾侠,等.基于探索性数据分析的柑橘部位颜色模型分析与识别 [J].农业机械学报,2013,44(S1):253-259+235.
[4] KRASKA T. Northstar:An interactive data science system [J].Proceedings of the VLDB Endowment,2018,11(12):2150-2164.
[5] Tableau software [EB/OL].[2023-04-23].https://www.tableau.com/.
[6] SARAWAGI S,AGRAWAL R,MEGIDDO N. Discovery-driven exploration of olap data cubes [C]//Proceedings of the 6th International Conference on Extending Database Technology:Advances in Database Technology.Springer-Verlag,1998:168-182.
[7] MILO T,SOMECH A. Next-step suggestions for modern interactive data analysis platforms [C]//KDD '18:Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York:Association for Computing Machinery,2018:576-585.
[8] CHIRIGATI F,DORAISWAMY H,DAMOULAS T,et al. Data polygamy:the many-many relationships among urban spatio-temporal data sets [C]//SIGMOD '16:Proceedings of the 2016 International Conference on Management of Data.New York:Association for Computing Machinery,2016:1011-1025.
[9] KERY M B,RADENSKY M,ARYA M,et al. The story in the notebook:Exploratory data science using a literate programming tool [C]//CHI '18:Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems.New York:Association for Computing Machinery,2018:1-11.
[10] RULE A,TABARD A,HOLLAN J D. Exploration and explanation in computational notebooks [C]//CHI '18:Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems.New York:Association for Computing Machinery,2018:1-12.
[11] 密紅,何利力,杨秀梅.烟草数据中心ETL技术应用 [J].计算机系统应用,2011,20(5):184-187.
[12] 章惠民.福建烟草数据中心数据质量监控技术应用 [J].中国烟草学报,2017,23(2):117-120.
[13] 周玉婵.数据挖掘在烟草企业CRM中的应用 [D].广州:华南理工大学,2013.
[14] EIRINAKI M,ABRAHAM S,POLYZOTIS N,et al. Querie:Collabo- rative database exploration [J].IEEE Transactions on Knowledge and Data Engineering,2014,26(7):1778-1790.
[15] HUANG E,PENG L,PALMA L D,et al. Optimization for active learning-based interactive database exploration [J].Proceedings ofthe VLDB Endowment,2018,12(1):71–84.
[16] JOGLEKAR M,GARCIA-MOLINA H,PARAMESWARAN A G. Interactive data exploration with smart drill-down [C]//2016 IEEE 32nd International Conference on Data Engineering (ICDE).Helsinki:IEEE,2016:906-917.
[17] RATNER A,BACH S H,EHRENBERG H,et al. Snorkel:Rapid training data creation with weak supervision [J].Proceedings of the VLDB Endowment,2017,11(3):269-282.
[18] GOSAVI A. Reinforcement learning:A tutorial survey and recent advances [J].INFORMS Journal on Computing,2009,21(2):178-192.
[19] LI Y. Deep reinforcement learning:An overview [J/OL].arXiv:1701.07274 [cs.LG].(2017-01-25).https://arxiv.org/abs/1701.07274v5.
[20] HAUSKNECHT M,STONE P. Deep reinforcement learning in parame-terized action space [J/OL].arXiv:1511.04143 [cs.AI].(2015-11-13).https://arxiv.org/abs/1511.04143v1.
[21] KAELBLING L P,LITTMAN M L,MOORE A P. Reinforcement learning:A survey [J].Journal of Artificial Intelligence Research,1996,4:237-285.
[22] MNIH V,BADIA A P,MIRZA M,et al. Asynchronous methods for deep reinforcement learning [C]//ICML'16:Proceedings of the 33rd International Conference on International Conference on Machine Learning.New York:JMLR.org,2016:1928-1937.
[23] EL O B,MILO T,SOMECH A. A-eda:Automatic benchmark for auto-generated eda [EB/OL].[2023-04-27].https://github.com/TAU-DB/ATENS-A-EDA.
[24] SPITZNER L. The honeynet project:Trapping the hackers [J].IEEE Security & Privacy,2003,1(2):15-23.
[25] SCHULMAN J,WOLSKI F,DHARIWAL P,et al. Proximal Policy Optimization Algorithms [J/OL].arXiv:1707.06347 [cs.LG].(2017-07-20).https://arxiv.org/abs/1707.06347.
[26] PAPINENI K,ROUKOS S,WARD T,et al. Bleu:a method for automatic evaluation of machine translation [C]//ACL '02:Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Stroudsburg:ACL,2002:311-318.
作者簡介:汪洋(1988—),男,汉族,新疆哈密人,工程师,硕士研究生,研究方向:计算机技术。
