
改进的共享布尔逻辑进位选择加法器设计
2024-06-01 19:03:40吴盛林
现代信息科技 2024年4期
关键词:功耗
收稿日期:2023-10-12
DOI:10.19850/j.cnki.2096-4706.2024.04.013
摘 要:在当今高度数字化和计算密集型的环境下,设计出高速和低功耗的加法器,例如进位选择加法器(Carry Select Adder, CSLA)是至关重要的。基于此提出一种改进共享布尔逻辑进位选择加法器。与现有设计相比,该设计在牺牲部分功耗和速度的基础上,减少了晶体管数量。该设计采用TSMC65 nm工艺在Cadence中实现了4位的设计。仿真结果显示,相对于Fast Adder Module-2(FAM2)进位选择加法器,该方案的晶体管数量、功耗和功耗延时积分别降低了8.91%、8.13%和6.02%。
关键词:进位选择加法器;晶体管数量;功耗;延迟
中图分类号:TP332.2;TP391.9 文献标识码:A 文章编号:2096-4706(2024)04-0061-05
Design of an Improved Shared Boolean Logic Carry Select Adder
WU Shenglin
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan 232001, China)
Abstract: In today's highly digitized and computationally intensive environment, it is crucial to design high-speed and low-power adders, such as Carry Select Adders (CSLA). Based on this, an improved shared Boolean logic Carry Select Adder is proposed. Compared to existing designs, this design reduces the number of transistors on the basis of sacrificing some power consumption and speed. This design utilizes TSMC65 nm technology to achieve 4-bit design in Cadence. The simulation results show that compared to the Fast Adder Module-2 (FAM2) Carry Select Adder, this scheme reduces the number of transistors, power consumption, and power consumption delay product by 8.91%, 8.13%, and 6.02%, respectively.
Keywords: Carry Select Adder; the number of transistors; power consumption; delay
0 引 言
隨着超大规模集成电路(Very Large Scale Integration, VLSI)系统在消费电子产品和便携式设备中的持续进步,迫切需要解决的挑战之一是实现高速计算、低功耗和小面积开销。这种需求不仅仅源自我们日常所使用的智能手机、平板电脑,还延伸至医疗设备、智能家居系统以及各种便携式智能设备。在如今高度数字化和计算密集型的环境下,一个巧妙设计的高速低功耗加法器成为VLSI系统设计中的关键挑战。加法器被认为是包含算术模块的基本单元,在计算中扮演着不可或缺的角色。它主要用于实现二进制加法,但其重要性不仅限于此。实际上,许多算术运算,包括减法、乘法、除法和滤波等,都需要加法器的参与。因此,加法器在整个算术模块中具有至关重要的地位。然而,由于加法器的重要性,提高它的性能成为迫切需求。在现代VLSI系统中,尤其是在中央处理器(Central Processing Unit, CPU)和图形处理器(Graphics Processing Unit, GPU)等系统中,高速和低功耗的加法器设计变得尤为关键。一个高速低功耗的加法器不仅能够显著提升整个算术逻辑单元(Arithmetic and Logic Unit, ALU)的性能,还能够为整个CPU和GPU等系统的性能带来质的提升。不止如此,在如今的数字化世界中,高性能的VLSI系统已经无处不在,尤其是在人工智能(Artificial Intelligence, AI)训练中,处理大量数据的需求愈发迫切。因此,加法器的性能不仅关系到特定功能的实现,也影响到整个系统的性能和稳定性。在这个背景下,提高加法器的性能,特别是在保持高速和低功耗的前提下提高加法器的性能,已经成为VLSI系统设计的重中之重。其中,行波进位加法器(Ripple Carry Adder, RCA)是一种基本的加法器,它由多个全加法器(Full Adder, FA)组成。虽然它在面积和功耗方面相对较小,但它的关键路径延迟较高[1]。为了克服这一缺陷,研究者们提出了一些新的结构,旨在降低延迟,提高整体性能。超前进位加法器(Carry-Lookahead Adder, CLA)、并行前缀加法器(Parallel-Prefix Adder, PPA)引入了大规模的组合逻辑,以降低延迟。尽管这种方法在延迟方面取得了进展,但也带来了额外的面积开销和功耗[2]。另外,为了降低延迟,进位跳越加法器(Carry Skip Adder, CSKA)采用了一种并联连接多个全加法器的设计。这种并行结构在一定程度上减小了延迟,但在加法器电路中引入了跳跃逻辑,导致了额外的功耗[3]。这些不同的结构,各自在性能和功耗方面有所权衡,提供了在特定应用场景下选择适当结构的灵活性。在现代集成电路设计中,选择最合适的加法器结构对整体性能至关重要。
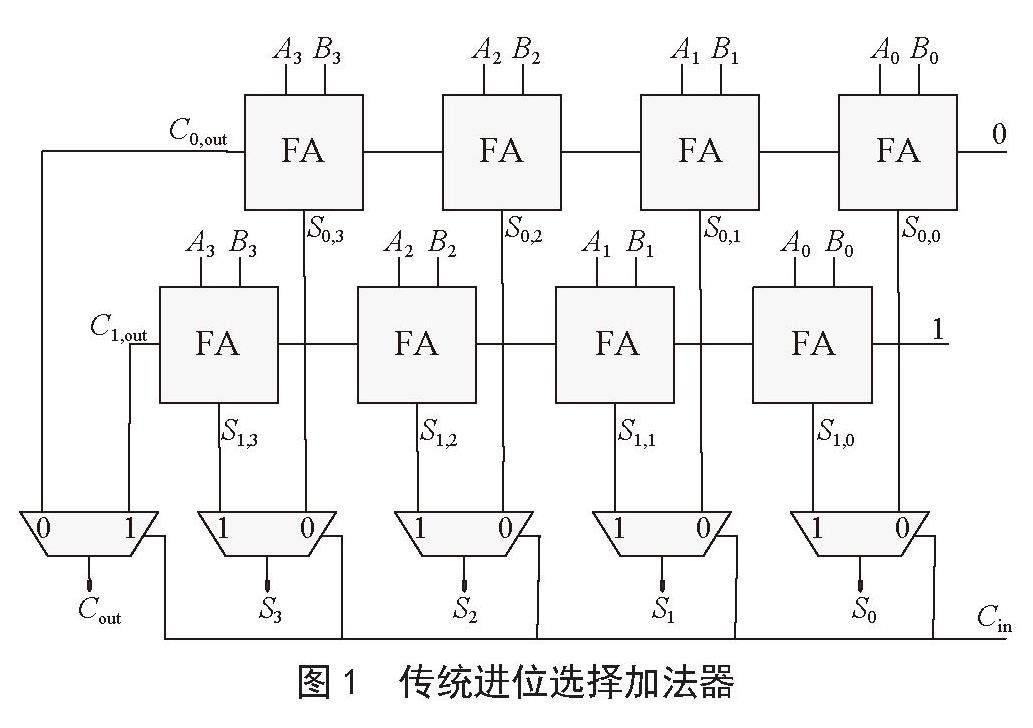
在1962年, Bedrij提出了传统进位选择加法器(Conventional Carry Select Adder, Con-CSLA)的设计方案。这个设计采用了多级体系结构,由多个短位宽的单级CSLA级联而成。它的每级都包括两个RCA模块和一个二路选择器(2 to 1 Multiplexer)模块,相较于RCA,其运算速度更快。图1展示了一个4位Con-CSLA电路的原理图,更加直观地呈现了这个设计的内部结构。在这个原理图中,An和Bn(n = 0,1,2,…)分别代表了第n位的被加数和第n位的加数。而Cn和Sn(n = 0,1,2,…)则分别代表了第n位的进位输出和第n位的本位和。Si, n和Ci, n分别表示了初始进位为i(i =“0”或“1”)时,第n位的本位和以及进位。这两个RCA模块的结果将会输入到一个MUX(Multiplexer)模块中。Cin被用作这个模块的选择信号,以控制这个模块输出最终的加法结果。这两个RCA模块并行地执行加法,每个单独的CSLA级也在并行地执行操作。因此,Con-CSLA的设计显著降低了延迟。100位的Con-CSLA相比于RCA,其延迟只有RCA的1/20。但由于该设计中电路中存在两组RCA模块,导致Con-CSLA的面积和功耗相对较高[4]。为了提高进位选择加法器的性能,研究者们采用了多种新的设计方案。这些新设计引入了更简单的电路替代Con-CSLA中的第二个RCA块,包括加一电路、BEC(Binary to Excess-1 Converter)电路和ZFC(Zero Finding Circuit)电路。这些方法的提出使得CSLA的性能得到了改善,特别是在处理大规模数据和高速计算方面表现出色。同时,其他研究文献中提出的CSLA结构也通过逻辑优化提高了整体性能[5-11]。
图1 传统进位选择加法器
1 共享布尔逻辑进位选择加法器
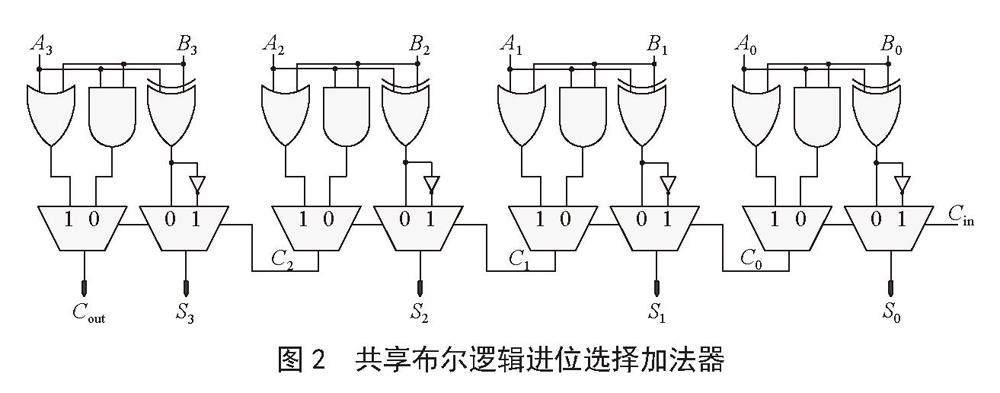
共享布尔逻辑进位选择加法器(Common Boolean Logic Carry Select Adder, CBL-CSLA)与传统的CSLA不同,CBL-CSLA采用了一种共享公共布爾逻辑的策略,而不是简单地通过替换硬件结构来提高性能。这一新方法的引入提供了更为高效的设计思路。通过这种方式,CBL-CSLA成功减少了晶体管的使用数量,降低了功耗,并且使功耗-延迟积(Power-Delay Product, PDP)下降。逻辑表达式(1)可以用来解释CBL的工作原理,图2描述了4位CBL-CSLA的原理图。
如果第i位的输入进位Ci-1 = 0,则Sn = An ⊕ Bn,Cn = An · Bn,否则:
(1)
为了提前计算输入进位,CBL-CSLA引入了一个创新的设计,包括一个或门和一个与门,用于进位传播路径。通过这个设计能够事先确认输入的进位值,进而根据MUX的选择确定输出进位。这一特性使得CBL-CSLA能够在进位生成电路和求和生成电路之间实现并行操作,极大地提高了其计算效率。在CBL-CSLA的设计中,进位生成电路由或门和与门来驱动,而求和生成电路则由异或门和反相器组成。这种设计使得CBL-CSLA在延迟方面略有优势,尤其是在相对短位宽的加法计算中。与传统的RCA相比,CBL-CSLA的性能有所提升。不同于Con-CSLA需要额外的RCA模块来完成任务,CBL-CSLA无须这样的设计,从而减少了晶体管的数量和功耗。这一设计上的巧妙之处在于,它保持了高性能的同时,减少了冗余的硬件结构,使得电路设计更为精简。然而,需要注意的是,虽然CBL-CSLA在短位宽加法中具有速度优势,但在处理长位宽的加法时,其并行路径相对较短,导致速度慢于Con-CSLA。这种权衡是一个设计上的挑战,需要根据具体的应用场景和需求做出权衡和选择[7]。
2 改进的共享布尔逻辑进位选择加法器
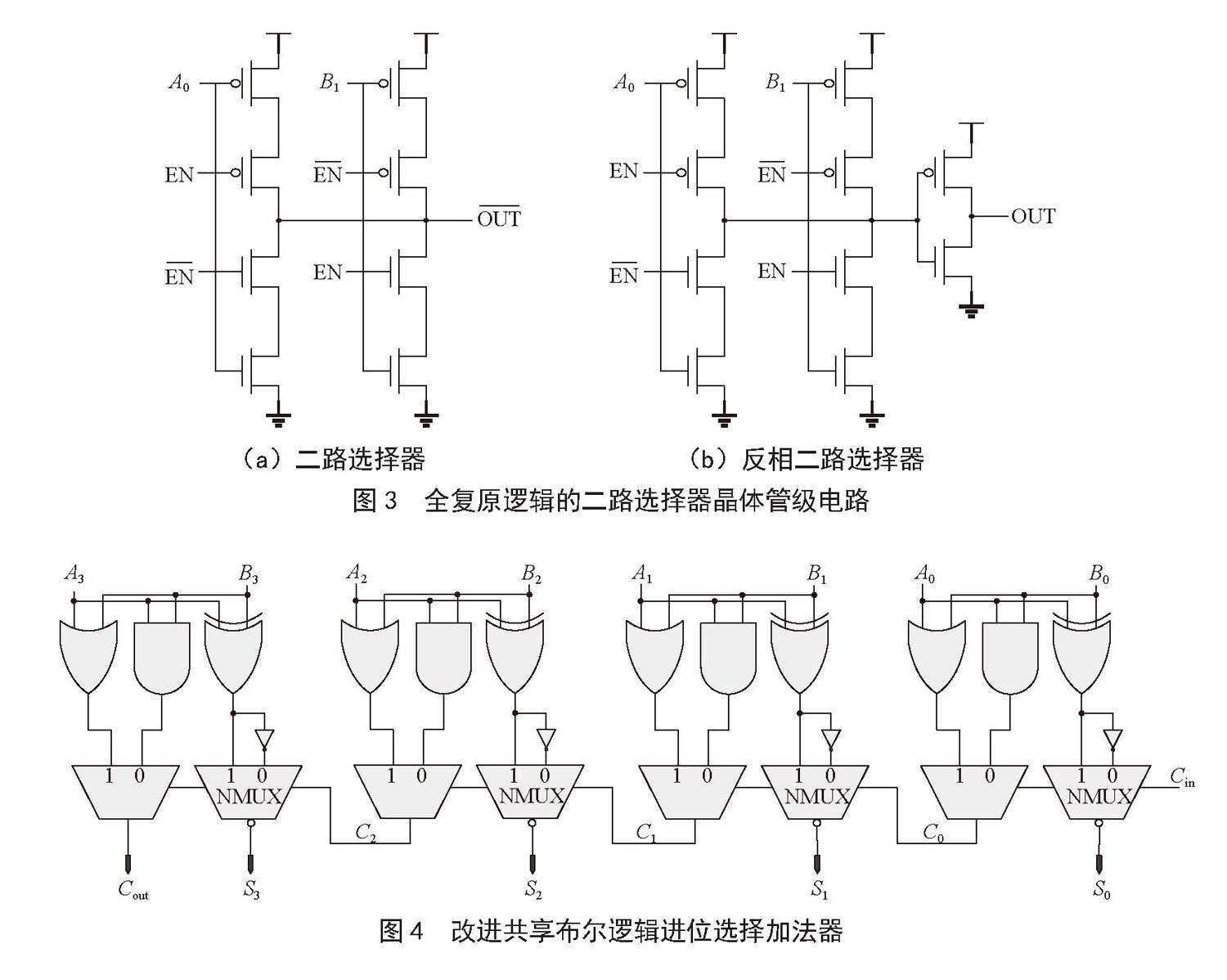
在共享布尔逻辑进位选择加法器的设计中,常常需要大量串联的二路选择器。如果采用不复原的二路选择器,随着串联级数的增加,这些不复原的二路选择器的驱动能力会逐渐下降,影响整体性能。为了解决这个问题,提高电路的鲁棒性和抗噪性,以及确保电路的安全性,通常使用全复原逻辑来设计这些二路选择器[12]。全复原逻辑的二路选择器晶体管级电路如图3所示。在图3(a)中,展示了一个典型的二路选择器,而图3(b)则是相应的反向二路选择器。很明显,一个二路选择器由一个反相二路选择器和一个反相器串联而成。这种设计方案的背后是为了确保电路在高度串联的情况下依然能够维持较强的信号驱动能力。确保信号在整个电路中的传输质量。需要强调的是,这种全复原逻辑的设计不仅仅是为了提高驱动能力,同时也是为了提高电路的稳定性和可靠性。
在现代VLSI系统中,这种设计策略被广泛应用,因为它能够有效地解决在大规模集成电路中信号传输面临的挑战,特别是在高度串联的情况下。因此,全复原逻辑的采用不仅仅是一种技术选择,更是一种对电路性能和稳定性负责任的设计决策。
注意式(1),每一位的可能的本位和都是相反的,因此在选择每一位的本位和时,传统的设计通常使用二路选择器。然而,本文提出了一种更为高效的方法,即采用反相二路选择器。这样的设计策略在每一位的本位和选择中不仅能够保持信号的稳定性,同时能够显著减少晶体管的数量。相比传统设计,减少了4.16%的晶体管数量。这不仅意味着在实际制造中可以节省成本,同时相对于串联不复原的二路选择器,提高了电路的可靠性。这种设计的优势不仅仅体现在晶体管数量的减少上,同时也在功耗和延迟方面具有显著的改善。采用全复原反相二路选择器,信号传输更为稳定,降低了功耗。而相对较短的传输路径也使得延迟得到有效控制。这意味着,新设计不仅在性能上更为出色,而且在实际应用中能够更好地满足高速、低功耗的需求。图4是提出的改进共享布尔逻辑进位选择加法器的原理图。
3 仿真结果
采用Cadence工具(包括Virtuoso和Spectre)进行模拟实验。在这个过程中,首先验证了每个电路的功能,并计算了它们的关键路径延迟和平均功耗,这是评估性能的关键指标。模拟实验使用了TSMC 65 nm工艺和典型的NMOS和PMOS(TT)工艺角,设置标准电源电压为1.2 V,工作温度为27 ℃,频率设定为500 MHz。为了计算功耗,采用了随机选择的1 024个输入向量,并将它们馈送到每个CSLA电路中。通过这样的操作,得到了1 024个功耗值,然后取其平均值作为CSLA的平均功耗。这个过程确保了对CSLA性能有全面的了解,尤其是在不同输入条件下的表现。在模拟过程中,Cadence记录了每个输入电路的瞬时总功耗曲线。基于这些数据,使用Cadence内置的计算工具来精确计算每个结构的平均功耗。在电路的设计中,需要特别关注进位从最低有效位(LSB)向最高有效位(MSB)传播的过程,因为这个过程中产生了关键路径延迟。理论上,传播延迟指的是输入信号从穿过VDD/2点过渡到输出信号同样穿过VDD/2点所需的最大时间[12]。这个时间是由计算工具计算得出的。仿真过程如图5所示,该图展示了在进行仿真实验时,各个输入向量下的关键路径延迟和功耗的计算过程。由这些精细的分析计算出关于CSLA性能参数的详细信息,从而与其他新电路结构进行对比,分析出不同电路的优劣所在。
图6展示了上述所有4位CSLA的延迟、功耗、晶体管数量和PDP。通过详细的模拟和分析,得出了关于这些CSLA性能的全面数据,这对于进一步的电路优化和设计改进提供了有力的支持。这些数据不仅仅是对现有设计的验证,同时也为未来的研究和实际应用提供了有益的参考。在表1中,负数表示改进的结构相较于其他进位选择加法器在性能参数上有所改善,而正数则表示相较于其他结构,性能参数有所负优化。从表格中可以清晰地看到,改进共享布尔逻辑进位选择加法器相比于未改进的共享布尔逻辑进位选择加法器在晶体管数量方面减少了4.17%。同时,其延迟降低了4.62%,功耗降低了9.38%,PDP降低了13.57%。相较于综合性能最差的传统进位选择加法器,改进的设计在晶体管数量上减少了27.56%。此外,延迟降低了25.93%,功耗降低了33.17%,PDP降低了49.9%。在表中综合性能最好的FAM2进位选择加法器方面,改进的设计以增加2.30%的延迟为代价,在晶体管数量、功耗和功耗延迟积方面分别降低了8.91%、8.13%、6.02%。
4 结 论
本文提出了一种改进共享布尔逻辑进位选择加法器的设计,通过优化共享布尔逻辑进位选择加法器的结构,采用反向二路选择器替代二路选择器,以减少功耗和晶体管数量。这项改进的设计在性能方面取得了显著的成果。与FAM2进位选择加法器相比,改进的结构在晶体管数量、功耗和功耗延迟积方面分别降低了8.91%、8.13%和6.02%。这种改进通过引入反向二路选择器,成功地改善了加法器的性能,同时在维持设计的基本功能的前提下,实现了晶体管数量、功耗、功耗延迟积的三重优化。
参考文献:
[1] KOREN I. Computer Arithmetic Algorithms: 2nd Edition [M].Natick:A K Peters/CRC Press,2002.
[2] BAI P A,LAXMI M V. Design of 128- bit Kogge-Stone Low Power Parallel Prefix VLSI Adder for High Speed Arithmetic Circuits [J].International Journal of Engineering and Advanced Technology(IJEAT),2013,2(6):415-418.
[3] DURAIVEL N,PAULCHAMY B. Simulation and performance analysis of 15 Nm FinFET based carry skip adder [J].Computational Intelligence,2020,37(2):799-818.
[4] BEDRIJ O J. Carry-Select Adder [J].IRE Transactions on Electronic Computers,1962,11(3):340-346.
[5] TYAGI A. A Reduced-Area Scheme for Carry-Select Adders [J].IEEE Transactions on Computers,1993,42(10):1163-1170.
[6] KANDULA B S,VASAVI K P,PRABHA P I S,et al. Area Efficient VLSI Architecture for Square Root Carry Select Adder Using Zero Finding Logic [J].Procedia Computer Science,2016,89:640-650.
[7] WEY I C,HO C C,LIN Y S,et al. An Area-Efficient Carry Select Adder Design by Sharing the Common Boolean Logic Term [C]//Proceedings of the International MultiConference of Engineers and Computer Scientists 2012 Vol II.Hong Kong:International Association of Engineers,2012:1091-1094.
[8] RUDPOSHTI M A,VALINATAJ M. High-speed and low-cost carry select adders utilizing new optimized add-one circuit and multiplexer-based logic [J].Integration,2021,79:61-72.
[9] MOHANTY B K,PATEL S K. Area–delay–power efficient carry-select adder [J].IEEE Transactions on Circuits and Systems II:Express Briefs,2014,61(6):418-422.
[10] KUMAR G K,BALAJI N. Reconfigurable delay optimized carry select adder [C]//2017 International Conference on Innovations in Electrical,Electronics,Instrumentation and Media Technology (ICEEIMT).Coimbatore:IEEE,2017:123-127.
[11] NAM M,CHOI Y,CHO K,et al. High-speed and energy efficient carry select adder (CSLA) dominated by carry generation logic [J].Microelectronics Journal,2018,79:70-78.
[12] WESTE N H E,HARRIS D M. CMOS VLSI DESIGN: A Circuits and Systems Perspective:4th ed [M].Boston:Addison-Wesley,2010.
作者簡介:吴盛林(1999—),男,汉族,安徽铜陵人,硕士在读,研究方向:进位选择加法器的高性能设计。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06 07:28:12
电脑爱好者(2022年15期)2022-05-30 02:15:04
计算机工程与科学(2021年2期)2021-03-01 03:33:34
中国资源综合利用(2017年4期)2018-01-22 02:46:56
个人电脑(2016年12期)2017-02-13 15:24:40
电子制作(2016年19期)2016-08-24 07:49:54
电子世界(2015年22期)2015-12-29 02:49:44
电源技术(2015年11期)2015-08-22 08:51:02
空间控制技术与应用(2015年3期)2015-06-05 14:30:32
计算机工程与科学(2015年11期)2015-03-19 00:36:34
